안녕하세요, 이번에는 Bop Challenge에서 새롭게 추가된 HANDAL을 읽어보았습니다.
NVIDIA는 데이터셋도 참 잘 만드네요.. 데이터를 취득하는 과정 중에 애플 제품으로 무언가를 하는 게 좀 특이하네요. 자세한 방법은 해당 논문에서 다루지 않아 아쉽네요.
참고로 affordance는 물체의 잡는 영역을 의미합니다. 예를 들어 후라이팬이 있으면 손잡이 부분을 affordance 영역으로 합니다.
리뷰 시작하겠습니다.
Introduction

로봇이 단순한 작업 뿐만 아니라 이를 넘어 어려운 작업을 수행하기 위해서는 주변 환경에 대한 3차원적인 인지 능력을 갖추어야 합니다. 딥러닝이 발전하면서 로보틱스에서도 신경망을 통한 학습 및 평가를 진행하기 위해서 high-quality를 가지는3D 데이터셋을 필요로 하게 됩니다. 대규모의 2D 데이터셋(ImageNet, COCO)에 비해 로보틱스에서 사용할만한 데이터셋의 크기는 많이 부족한 편입니다. 하지만 규모가 커질수록 발생하는 것은 역시 annotation의 문제가 있죠. 차원이 올라갈수록 비용이 커지는 것은 당연합니다.
이러한 문제를 해결하기 위해 HANDAL 데이터셋을 제안합니다. 쉽게 접할 수 있는 카메라를 이용하여 데이터를 취득하고, 반자동화된 파이프라인을 통해 쉽게 annotation을 진행함으로써 많은 사람의 노동 없이 대규모의 annotation이 된 데이터셋을 만들 수 있게 되었다고 합니다.
contribution은 다음과 같습니다.
- 17개 카테고리의 물체 인스턴스에 대한 시퀀스 영상에 대한 모든 이미지 프렝미에 대한 6D pose 및 스케일 정보가 포함되어 있음
- affordance annotation과 모든 물체에 대한 3D reconsturction mesh 제공
- 정적 뿐만 아니라 동적인 상태에서도 annotation 정보 제공
Dataset overview
이번 HANDAL 데이터셋의 목표는 로봇이 단순한 작업이 아닌 그 이상의 작업을 수행할 수 있도록 인지를 서포트 하는 것이라고 합니다. 또한, 목표에 걸맞는 물체에 대해 정의도 하였는데요. 물건에 대한 기능적인 부분을 로봇이 파악하는 것에 용이하도록 손잡이가 있는 카테고리에 대해 초점을 맞추었다고 합니다.
A. Object categories
17가지의 파지할 수 있는 기능적인 물체들에 대한 카테고리를 정의했습니다. 그런데 막상 기능이 있는 물체들을 구성해보니 일반적으로 공구 종류이거나 주방 용품으로 큰 상위 카테고리 중 하나에 속하게 됩니다. 웬만한 물체들은 사람이 다룰 수 있도록 설계가 되었을텐데요. 따라서, 로봇이 사람을 대신하여 무언가를 수행하기 위해서는 사람을 위한 물체들을 잘 다루어야 할 필요가 있겠네요. 여기서 주의해야할 점은 구성된 일부 물체들은 로봇이 조작하기에 너무 무거울 수도 있습니다. 또한, 모든 물체는 무작정 파지하는 게 아니라 특정 용도에 맞게 파지를 해야합니다. 그럼 로봇에는 의인화된 로봇 손이 필요할 수도 있겠네요. 저자는 이번 데이터셋을 통해 파지 분야에 대한 추가 연구를 위한 길을 열어줄 것으로 기대하네요.
반사가 되는 표면, 구멍이 뚫림 등과 같은 다양한 재질과 형태로 물체들이 구성되어 있는데요. 이러한 특성으로 인해 발생하게 되는 문제점은 실제 시나리오를 다루는 인지 연구를 발전시키는 데에 HANDAL 데이터셋이 유용하게 활용이 될 수 있을 것으로 보이네요.
B. Comparison with other datasets
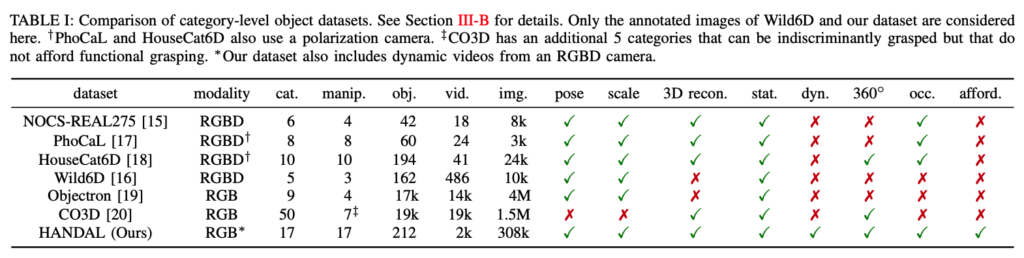
표(1)은 HANDAL 데이터셋과 기존의 category-level에 해당하는 데이터셋들과 비교한 결과를 나타내고 있습니다. 2열부터 모달리티, 카테고리 수, 조작 가능한 카테고리 수, 물체 인스턴스 수, 동영상(스퀀스) 수, 이미지(프레임) 수, pose annotation 여부, 실제 스케일 제공 여부, 3D reconstruction 제공 여부, 정적(물체 고정) 장면 포함, 동적(물체 고정X) 장면 포함, 360뷰 캡처 여부, occlsuion 여부, affordance annotation 여부입니다.
HANDAL 데이터셋은 인스턴스당 여러 개의 시퀀스 영상에서 프레임 단위로 가져와 사용했기 때문에 instance-level과 category-level 둘 다 커버 가능한 pose annotation 정보를 가지고 있다는 점이 새롭네요. 따라서, 특정 3D CAD 모델에 대해 작동하는 instance-level pose estimator를 학습하는 것에도 해당 데이터셋을 사용할 수 있다는 것입니다. 또 특이한 점은 3D CAD 모델은 reconstruction하여 만들어졌으므로 해당 시퀀스 영상 전체에 대해 align된 pose 정보들을 가지고 있으므로 수동으로 annotation 한 것 보다 훨씬 정확한 pose 정보를 생성할 수 있었다고 합니다.
물체의 조작 가능 여부를 결정하는 것은 다소 저자의 주관적인 판단으로 보이는데요. 위 표에서 NOCS-REAL275, Wild6D, Objectron에서 제공하는 cam, notebook 카테고리는 깨지기 쉽고 교체 비용이 많이 드는 이유로 포함하지 않았다고 합니다. Objectron에서 제공하는 bike, chair 카테고리는 너무 커서 포함하지 않았다고 합니다. CO3D에서 제공하는 사과, 당근 오렌지, 바나나, 공 카테고리는 기능적인 파지를 알 수 없으므로 포함하지 않았지만, pick-and-place를 고려한다면 포함할 수도 있겠네요.
NOCS-REAL275, PhoCaL, HouseCat6D는 3D CAD 모델에 대한 reconstruction을 위한 별도의 스캔 과정이 있지만 HANDAL, CO3D는 단순히 몇 개의 프레임을 통해 reconstruction 결과를 얻었다고 하네요. 하지만 CO3D 같은 경우 단일 시퀀스의 각 물체 인스턴스에 대한 camera pose는 포함하고 있지만, 시퀀스 간 대응되는 정보는 없어서 category-level pose estimator를 학습하기에는 부적절해 보이네요.
Method
HANDAL 데이터셋은 어떻게 데이터를 취득하고 annotation은 어떻게 했는지 본격적으로 알아보겠습니다.
A. Data collection

그림(2)는 데이터셋의 샘플 이미지를 나타내고 있습니다. 각 카테고리별로 최소 12개의 서로 다른 물체 인스턴스로 구성합니다. 즉, 브랜드나 크기가 다른 물체들로 구성하여 총 17개의 카테고리에서 총 212개의 물체들로 구성하였다고 하네요. 각 물체에 대해 다양한 조명 조건, 배경, 다양한 방해 요소가 있는 환경에 놓인 물체에 대해 정적인 상태로 약 10개의 정적 장면을 촬영했다고 합니다.
일부 물체의 경우는 pose annotation 과정에서 registration mesh를 생성하기 위해 추가적으로 촬영하여 reference 정보를 주었다고 합니다. 하지만 이러한 reference 정보를 가지고도 잘 안될 수도 있겠죠. 이러한 경우에 대해서는 가장 reconstruction된 mesh를 선택하여 사용했다고 합니다. 즉, 물체의 최종 mesh에는 모든 장면의 모든 이미지 프레임을 사용하여 reconstruction하여 구성했다고 보면 되겠네요.
비디오 시퀀스는 휴대폰 후면 카메라를 이용하여 촬영을 했다고 합니다. HD(1280×720)로 캡처를 하고 이와 동시에 내장된 ARKit2 또는 ARCore3 라이브러리르 사용하여 센서 퓨전을 통해 대략적인 카메라 pose를 추정했다고는 하는데 칼 같이 끝나버리네요. 업계 비밀인 걸까요..?
또한, 640×480으로 촬영한 아이패드 프로의 전면 카메라에 있는 TrueDepth 카메라로 51개의 동적 시퀀스를 촬영했다고 합니다. 깊이 감지가 가능하다고 판단되는 물체들을 선별하여 물체당 하나의 시퀀스의 형태로 촬영합니다. 이때, 두 가지 방법으로 나누어 촬영을 진행하게 되는데요.
- 물체를 최대한 많은 각도에서 볼 수 있도록 고정된 카메라 앞에서 회전하여 BundleSDF를 사용하여 high-quality의 3D reconstruction을 생성
- 사람이 기능적인 방식으로 물체를 직접 잡고(망치의 손잡이 부분을 잡음), 기능적인 동작 방식에따라 슬로우 모션으로 움직임(망치로 못을 치는 시늉함)
이처럼, 자연스럽게 물체를 조작함으로써 물체에 대한 affordance와 연관된 물체에 대한 pose 추정을 위한 현실적인 시나리오를 제공할 수 있었다고 하네요. 이전에 존재하는 모든 데이터셋들은 정적인 장면에만 한정되어 있었기 때문에 HANDAL 데이터셋에서만 있는 유일한 점이라고 볼 수 있습니다.
B. Data annotation of static scenes
이전 섹션에서 ARkit/ARCore로 모든 프레임에 대해 camera pose에 대한 추정치를 얻었다고 했습니다. 하지만 해당 camera pose를 이용하여 3D reconstruction과 annotation을 하기에는 noise가 너무 많은 문제가 있었다고 합니다. 따라서, COLMAP을 사용하여 이미지만을 사용하여 camera pose를 추정하였다고 하는데요. 배경에 대한 텍스처 정보를 활용하기 위해 crop 하거나 segment mask를 하지 않은 이미지에서 수행했다고 합니다. 이후 XMem을 적용하여 전경에 대한 물체를 배경으로부터 segmentation 하게 되는데, 첫 프레임에서 1-2번의 마우스 클릭을 수동으로 입력을 줘야 작동을 하고 이후로는 자동으로 작동하는 하는 것으로 보입니다. 이후 segmentation 된 이미지에 대해 3D representation을 생성하는 instant NGP[1]을 적용하여 mesh를 생성하였다고 하네요. COLMAP에서 생성된 camera pose에는 절대 스케일이나 절대 방향이 없기 때문에 이전에 얻은 ARKit/ArCore로부터 얻은 pose 정보를 활용하여 COLMAP으로부터 얻은 pose의 스케일을 rescaling하고 IMU 센서가 있으니 중력 방향에 대한 수직 방향을 alignment 할 수 있겠네요. 해당 변환 값들은 3D reconstruction mesh에도 적용을 했다고 합니다.
각 카테고리에 대한 표준 좌표계의 룰을 설정하여 instance 간에 일관성을 유지하도록 했다고 하는데, 자세하게 풀어보면 일반적으로 회전 대칭에 있는 카테고리의 경우 대칭 축을 x축으로 설정하고, 나머지 카테고리들은 대칭 평면을 xy평면으로 설정하는 것을 원칙으로 합니다.

모든 카테고리는 물체의 앞쪽을 x+(x축 양의 방향), 위쪽을 y+가 되도록 설정을 해두어 위의 그림과 같은 장도리(claw hammer)의 경우 손잡이는 x축을 따라 헤드 부분이 x+가 되겠고, 헤드에 대한 기능적인 부분들은 y축을 따라 구성되어 있으므로 면(나사를 박는 곳)은 y+, 갈고리쪽은 y-가 되도록 방향을 잡았다고 보시면 되겠습니다.
COLMAP으로부터 얻은 물체의 pose에서 reference pose(이전에 설정한 좌표계)로의 변환과 COLMAP으로 부터 얻은 camera pose를 사용하여 카메라에 대한 물체의 pose를 모든 프레임에 대해 계산할 수 있습니다. 간간히 camera pose의 오류로 인해 pose가 올바르지 않은 경우가 있으면 해당 프레임은 제거하는 방식으로 진행했다고 합니다.
[1] T. Mu ̈ller et al., “Instant neural graphics primitives with a multiresolution hash encoding,” ACM Trans. Graph., 2022.
C. Data annotation of dynamic scenes
동적 장면에 대한 GT mask를 얻기 위해 정적 장면에서의 취득과 마찬가지로 XMem을 활용하였다고 합니다. camera pose localization을 이용하여 물체에 대한 GT pose를 간단하게 추정할 수 있는 정적 장면과 다르게 동적 장면에서 pose를 추정하는 것은 쉽지 않습니다. 이러한 문제를 해결하기 위해 저자는 동적 시퀀스 영상에 대해 BundleSDF를 적용하여 물체에 대한 3D reconstruction 모델을 생성하는 동시에 이미지 프레임 전체에서 물체의 6D pose를 tracking 합니다. 이러한 BundleSDF에 대한 결과를 평가하기 위해 각 프레임의 출력으로 나오는 pose에 임의로 noise를 추가하여 ICP를 적용한 mesh를 depth 이미지와 align을 맞추게 하여 high-quality 결과만을 보장하기 위해 모든 프레임을 수동으로 검사를 했다고 하네요. 결과는 대부분의 프레임에서 BundleSDF와 ICP의 결과는 거의 동일하였다고 합니다.
BundleSDF는 전체 시퀀스 영상에 대한 tracking을 수행하기 때문에 일반적으로 정적 상태에 있는 테이블 위에서는 해결할 수 없는 밑면에 대해서도 reconstruction을 할 수 있게 됩니다. 이러한 과정을 통해 시퀀스 영상에 존재하는 모든 프레임에 대해 category-level의 물체에 대한 pose를 얻을 수 있게 됩니다.
D. Annotating affordance

그림(3)과 같이 affordance의 경우는 각 물체에 대한 reconstruction에서 3D mesh의 handle 영역에 대해 수동으로 라벨링을 진행했다고 합니다.
Results
A. Dataset statistics
모든 annotation 기준은 표준(COCO; 2D bbox, instance mask / BOP; 6D pose)형식으로 저장되어 제공합니다.

또한 그림(4)와 같이 다양한 환경에서 데이터를 취득한 것을 확인할 수 있습니다. 극한의 조명 조건, shiny(눈 부시는 환경?), 그림자, 반사되는 물체, 구멍이 많은 물체 등을 포함하고 시퀀스마다 임의의 물체들로 구성하여 제공하는 것을 확인할 수 있습니다.
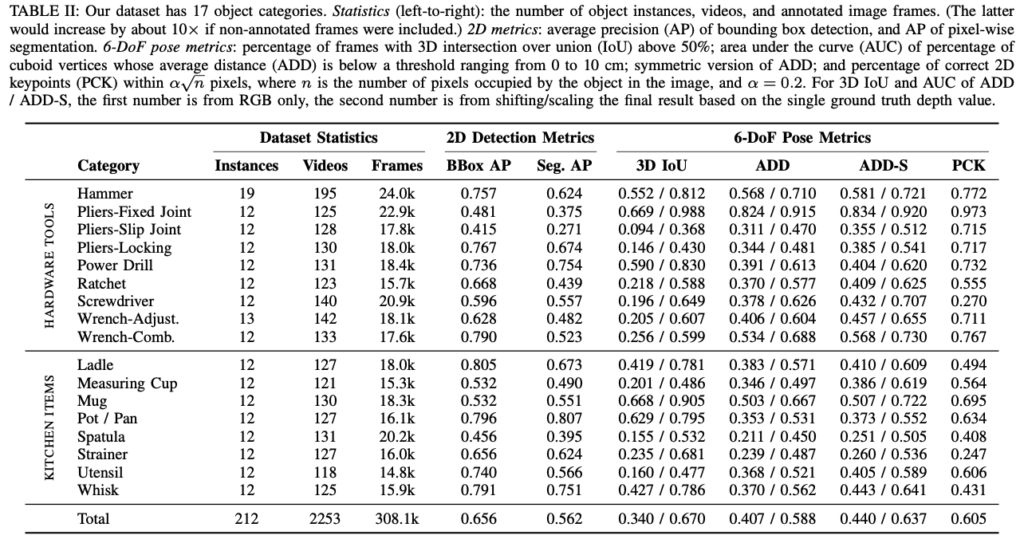
표(2)는 데이터셋의 전체적인 구성과 2D detection과 6D pose 추정에 대한 정량적인 결과를 보여주고 있습니다.
B. Object detection
데이터셋을 검증하기 위해 각 카테고리에서 그림(2)에 나와있는 3개의 물체가 등장하는 모든 장면을 포함하여 평가 데이터셋을 정의하였다고 합니다.
17개의 물체 카테고리의 인스턴스를 localization하고 segmentation하기 위해 Mask RCNN 모델을 학습하여 사용하였으며 COCO segmentation에 사전학습된 모델에 대한 가중치를 사용하여 학습을 진행하였다고 합니다. 표(2)의 정량적 결과를 통해 해당 데이터셋이 흥미로운 연구를 지원할 만큼 충분히 크고 다양하다는 것을 시사합니다.
C. Category-level object pose estimation

해당 데이터셋의 검증을 6D pose estimator로 한 내용을 살펴보겠습니다. 결과를 보았을 때 category-level pose 추정을 학습할 수 있다는 것을 일단 보여주고 있습니다. pose estimator로는 RGB 기반의 CenterPose[2]를 사용했다고 하네요. pose의 범위가 매우 다양하기 때문에 물체의 세로축과 이미지의 세로축을 가장 잘 정렬하는 90도 단위로 이미지를 회전하고, GT 물체의 스케일을 알 수 있다는 가정합니다.
[2] Y. Lin et al., “Single-stage keypoint-based category-level object pose estimation from an RGB image,” in ICRA, 2022.
Conclusion
로보틱스를 위한 category-level 6D pose와 scale 정보도 같이 annotation된 대규모의 데이터셋인 HANDAL을 살펴보았습니다. 해당 데이터셋은 최근에 제안된 데이터셋 중에 가장 큰 규모 뿐만 아니라 동적 장면, 360도 촬영, occlusion, affordance, 3D reconstruction 제공과 같이 여러 특성들을 제공함으로써 독보적으로 새로운 데이터셋이었습니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
해당 데이터 셋도 affordance를 고려하고 있다고 하니 흥미롭습니다. 제가 서베이해보니 rototics에서는 생각보다 affordance 연구가 상당히 많이 진행된 것으로 보입니다..
affordance에 대한 label은 handle만 존재하는것인가요?? 제가 봤던 affordance들은 기능에 따라 여러가지 카테고리가 존재하는데annotating affordance에는 handle만 존재하여 질문 남깁니다.
마지막으로 ‘데이터를 취득하는 과정 중에 애플 제품으로 무언가를 하는 게’ 특이하다고 하셨는데, annotation 과정에서 카메라의 pose를 구하는 부분을 이야기하시는건가요?? 올려주신 링크를 보니까 장면을 촬영해서 scene을 만들어서 카메라 위치를 구하는 것 같은데, 활용 가능성을 검토해보실 계획이신가요??
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 말씀하신대로 기능적인 부분에 대한 라벨링은 따로 없는 것으로 보입니다.
2. 네 맞습니다. 애플 제품 내부 센서를 이용하는 ARKit를 활용하는 게 새로웠습니다. 범용적으로 사용되는 것이면 검토해볼 생각이 있으나, 그게 아니라면 상용 RGB-D 센서(RealSense, Kinect)를 그대로 사용할 예정입니다.
감사합니다.
리뷰 잘 읽었습니다.
엔비디아가 확실하게 애플이랑 손을 잡은건지.. 데이터셋까지 아이폰으로 촬영하나보네요
B. Object detection 에서 “표(2)의 정량적 결과를 통해 해당 데이터셋이 흥미로운 연구를 지원할 만큼 충분히 크고 다양하다는 것을 시사한다” 라고 하셨느데, 한가지 데이터셋만으로 여러 태스크에 대한 실험을 진행할 수 있어서인가요?
그리고 해당 데이터셋을 검증한 근거로 표 (2)를 말씀하셨는데,
표 (2)에 어떤 부분을 보고 이 데이터셋이 유의미한지 해석할 수 있나요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 여러 카테고리에 속하는 물체 인스턴스들을 제공함으로써 정량적인 결과도 얻었고, 또한 이런 결과를 말씀하신대로 여러 테스크(affordance, 6D)에도 접목할 수 있다는 것을 보여주는 것을 의미하는 것으로 보면 되겠습니다.
2. 데이터셋의 유효함을 검증하는 것 자체가 주관적일 수는 있으나, 2D detection / 6D pose estimation 자체에 대한 성능을 뽑아봤을 때 표(2)만큼의 정량적인 결과가 나왔고, 결과를 보았을 때 결코 쉬운(saturation된) 데이터셋은 아니라고 보이며, 앞으로의 연구 방향이 해당 데이터셋에서 얻은 베이스라인을 가지고 좀 더 고도화를 위한 방향으로 나아가도록 제시한 것으로 볼 수 있을 것 같습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
intro에서 인스턴스 당 여러 개의 시퀀스 영상에서 프레임 단위로 가져와서 사용하기 때문에 intstance level과 category level이 둘 다 커버 가능하다고 말씀하셨는데, 왜 여러 개의 시퀀스 영상으로 reconstruction한 결과를 3D CAD 모델로 사용하는 것이 두 level의 pose estimation이 가능해지는지 잘 이해가 안 가서 .. 추가적으로 설명해주시면 감사드리겠습니다.
그리고 이 데이터셋이 공개되고 해당 데이터셋에서 6D pose estimation을 수행한 연구들에서 처음으로 추가된 affordance에 대해 어떻게 처리하고 있는지 궁금합니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. reconstruction을 하면 camera pose를 알 수 있으니 카메라 pose에 대한 R,t 정보를 알고 있다면, 그만큼의 변환을 물체의 초기 pose에 적용하면 매 프레임 마다의 pose를 쉽게 알 수 있으니 level에 상관없이 커버가 가능하다는 의미입니다.
2. 지금까지 인용수가 7회로 아직까지는 해당 데이터셋을 사용한 연구가 많이 없지만, 주로 LLM을 이용하여 물체에 대한 affordance를 검출하거나 로봇팔을 이용하여 해당 영역을 잡는식의 연구가 진행이 되는 것으로 보입니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
BundleSDF의 결과를 평가하기 위해 각 frame의 출력으로 나오는 pose에 임의로 noise를 추가하여 ICP를 적용한 mesh를 depth이미지와 align을 맞추게 하여 검사를 하였다고 하셨는데,,,,, 여기서 ICP가 무엇인지 궁금합니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
ICP는 Iterative Closest Point의 약어로 3D-3D correspondences를 통해 3차원 상에서 정합을 맞추기 위한 R,t를 추정하는 알고리즘입니다. 6D pose estimation에서 사용되는 방법은 주로 입력으로 들어오는 depth 정보(intrinsic parameter를 이용하여 3차원으로 reprojection)와 3D CAD 모델로부터 얻은 포인트 클라우드 각각의 correspondence를 찾고, 이를 이용하여 서로 align을 맞추기 위한 최적화 과정을 통해 최종적으로 R,t를 추정하게 됩니다.
감사합니다.