이번 리뷰는 Scene Graph Generation 관련 논문이지만, Closed-Set 이고 Fully Supervised 세팅에서의 연구 입니다. Best paper award candidate로 선정된 논문이라 제가 관심 있는 Open-Vocabulary는 아니지만 읽어보게 되었습니다.
네이버랑 고려대학교에서 같이 진행한 연구네요. 네이버는 국내 기업이지만 정말 다양한 연구를 하는 것 같습니다. Video Understanding 팀이 따로 있다고 들었는데 정확히 무슨 연구를 하고 있는지 한번 알아보고 싶네요.
무튼 준비한 논문 리뷰 시작하겠습니다.
Introduction
Scene Graph Generation (이하 SGG)는 이미지 내에 존재하는 객체를 node로 표현하고 객체끼리의 관계를 edge로 표현하여 이미지를 설명할 수 있는 Scene Graph를 생성하는 것을 목표로 합니다. 단순히 객체를 탐지하는 object detection 보다 더 어려울 수 밖에 없는 것이 객체끼리의 상호 작용을 나타내는 predicate를 동시에 예측해야 하기 때문 입니다.
초기의 연구들은 객체를 먼저 검출하고, 관계 (predicate)를 예측하는 two-stage 기반으로 진행 됐습니다. 기본적으로 two-stage 기반의 방식들이 높은 검출 성능을 보여주지만, 연산 복잡도가 높아서 연구자들은 객체와 관계를 동시에 검출하는 one-stage 기반 방법들로 연구를 시작하였습니다.
Object detection 분야에서 DETR이 detection에 대한 prior 없이 완전한 end-to-end 기반의 one-stage framework를 성공적으로 도입 하였습니다. Scene Graph Generation에서도 DETR을 활용하여 one-stage 기반의 framework를 많이 연구하였습니다. DETR 기반의 기존 one-stage SGG 연구들은 아래와 같이 세가지 방식으로 분류할 수 있습니다.
Object-Triplet Detection Models
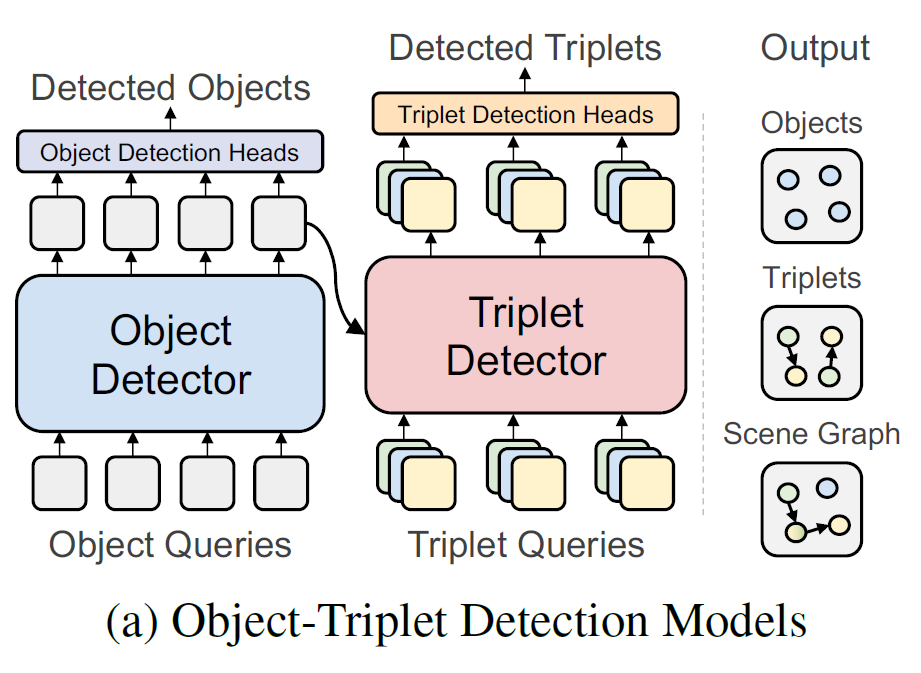
그림에서 볼 수 있는 것 처럼, 해당 방법들은 Triplet Query를 별도로 정의하고 Object Detector 위에 Triplet Detector를 추가로 사용하고 있습니다. One-Stage 이지만, 추가적인 Triplet Query와 Triplet Detector를 활용하고 있어서 연산량이 꽤 존재한다고 하네요. 또한 Triplet Query를 위해 Object Detector로 필요한 정보를 잘 전달해주기 위해 정교하게 설계된 Triplet Detector가 필요하다고 합니다.
어느 방법이든 정교한 Detector가 중요한 것은 사실이니 해당 방법론은 우선, One-Stage 중에서는 연산 복잡도가 제일 높은 것이 나름의 한계라고 정리할 수 있을 거 같습니다.
Triplet Detection Models
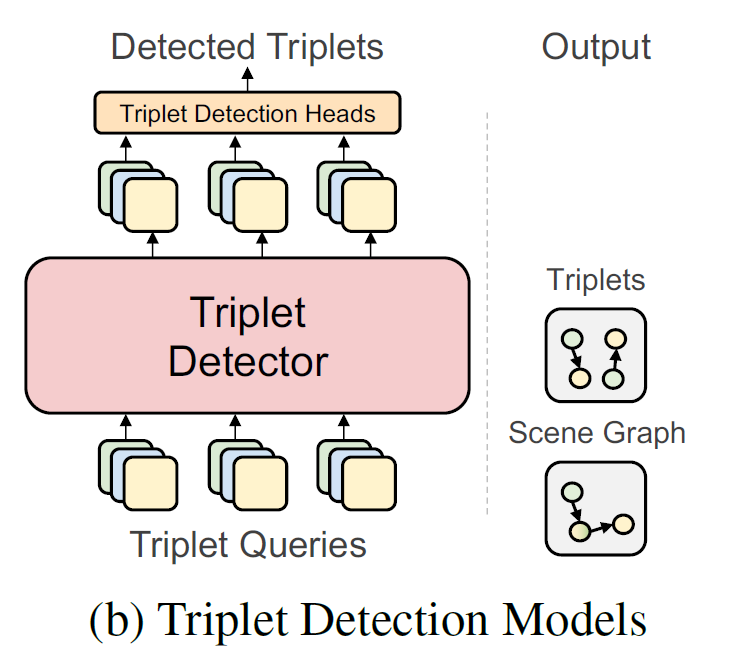
다음으로는 Object Detector 없이 Triplet Detector만 활용하는 방법 입니다. 앞서 Object Detector를 활용 하는 방식보다는 당연히 효율적이라 볼 수 있지만, relation 없이 혼자 존재하는 object를 검출하는 능력은 떨어진다고 합니다. 아무래도 object detector 없이 triplet detector만 활용하기 때문에 이런 문제가 발생한다고 하네요.
하지만 벤치마킹 데이터 중 하나인 Visual Genome에는 이렇게 relation 없이 혼자 존재하는 object의 비율이 전체에서 42%나 차지한다고 합니다.
기존의 연구들을 좀 정리해봤을 때, 연산량과 검출 능력은 trade-off 관계에 있다고 보시면 됩니다.
Relation Extraction Models
마지막으로 Relation extraction model들은 triplet query 없이 굉장히 가벼운 relation predictor와 object detector를 바탕으로 SGG를 수행합니다. 제안하는 연구도 해당 방법에 속하게 됩니다. 가장 관련된 연구로는 Relationformer 라고 해서 특별한 토큰인 [rln]을 활용하여 object query 끼리의 global information을 담을 수 있게 하였다고 하네요.
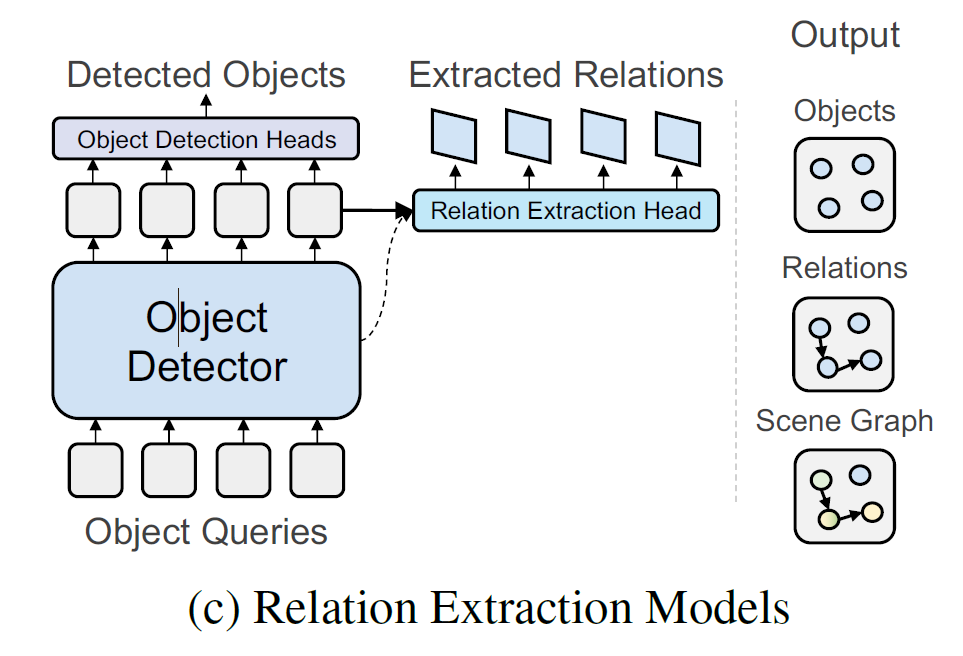
그렇다면 본 논문의 가장 큰 motivation은 무엇일까요? 기본적으로는 Triplet Detector와 Query 없이 굉장히 가벼운 모델을 만들고자 하는데 어느 정도의 검출 능력을 보장하기 위해서는 새로운 insight가 필요합니다.
예전부터 Object Detection을 수행할 때 객체 간의 context나 relation을 모델링하면 더 좋은 검출 성능을 기대할 수 있다는 믿음이 있었습니다. 그리고 DETR의 self-attention 연산이 이런 객체들간의 relation을 모델링하기 위해 사용되었다고 볼 수 있습니다.
저자는 이러한 insight를 바탕으로 사전학습된 DETR의 self-attention 가중치가 triplet 형성을 위해 중요한 정보들을 가지고 있을 것이라 가정합니다. 아래 그림을 보면 (a)와 같은 입력 이미지를 설명하는 (b) Scene Graph가 있다고 했을 때, 사전 학습된 DETR의 (c) attention 가중치를 보면 triplet 형성에 나름 의미 있는 정보를 포함하고 있습니다.
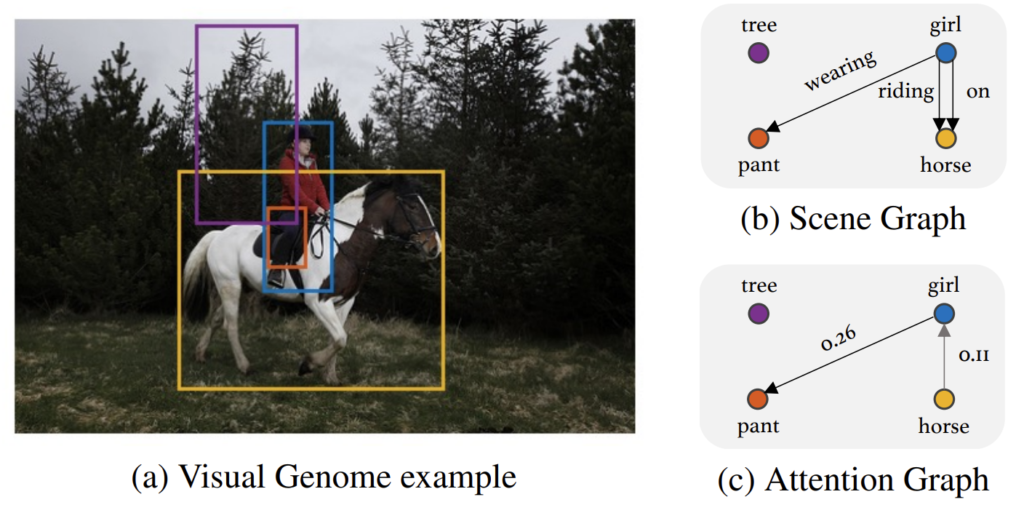
높은 attention 가중치를 가지는 object query 끼리 연결 시켜주는 작업만 진행을 해도 어느 정도 의미 있는 triplet이 나온다는 것이죠. 이것이 본 논문에서 제안하는 가장 큰 motivation 입니다.
저자는 이렇게 사전 학습된 Transformer에서 그래프를 추출하는 Extracting Graph from TRansformer (EGTR)을 제안합니다. 사전 학습된 DETR의 self-attention 가중치는 어느 정도 object 끼리의 관계를 나타내는 정보를 담고 있기에 triplet query와 detector 없이도 강인한 성능을 보장할 수 있다고 하네요.
또한 제안하는 EGTR의 학습을 보조하기 위해 curriculum learning과 비슷한 방식의 label smoothing 방법을 제안하여 모델의 학습을 안정화 시킵니다.
그렇다면 이제 제안하는 EGTR의 방법에 대해서 좀 더 구체적으로 알아보도록 하겠습니다.
Method
Preliminaries (DETR)
Backbone
DETR의 Transformer 구조는 ViT가 아니라 patch embedding이 아닌 CNN feature를 활용하여 Transformer의 입력으로 넣어줍니다. 여기서 CNN feature는 가장 널리 사용되는 ResNet50 혹은 ResNet101을 보통 사용 합니다.
- x_{\text{img} }\in \mathbb{R}^{3\times H_{0}\times W_{0}} \rightarrow f\in \mathbb{R}^{C\times H\times W}
이 때 채널 C는 2048차원을 가지고 있으며 공간적 해상도는 32배 (H,W=\frac{H_{0}}{32} ,\frac{W_{0}}{32} ) 다운 샘플링 된다고 합니다.
Transformer encoder
Transformer encoder는 우리가 흔히 아는 Transformer encoder가 맞습니다. Backbone을 통해서 얻은 CNN feature를 그대로 사용해주는 것은 아니고 1 by 1 Convolution을 통해 channel dimension을 수행합니다.
- f\in \mathbb{R}^{C\times H\times W} \rightarrow z\in \mathbb{R}^{d\times H\times W}
그리고 여기 공간적 구조를 1d로 flatten 하여 encoder에 얻을 수 있는 형태로 reshape 해 줍니다.
- z\in \mathbb{R}^{d\times H\times W} \rightarrow z\in \mathbb{R}^{d\times HW}
이 때 기본적인 transformer encoder는 permutation-invariant 합니다. 왜냐하면 self-attention 연산이 permutation invariant 하기 때문이죠. 하지만 여기서는 이미지의 locality에 대한 순서가 중요하기 때문에 permutation-invariant한 성질을 좀 죽여야 합니다. 그래서 매 attention layer마다 고정된 positional encoding을 더해줘서 이를 방지하고자 합니다.
Transformer decoder
Decoder는 N개의 학습 가능한 token 즉, object query를 입력으로 받아서 여러번의 self attention 연산 진행하고 입력 이미지 내에 존재하는 object query 간의 특징을 학습 합니다.
DETR 기본 구조에서 attention을 진행할 때는 causal masking 연산을 하지 않기 때문에 온전히 N \times N의 attention weight가 학습이 됩니다.
따라서 multi-head attention을 통해 N개의 object query 끼리의 관계를 학습하게 되는 것 입니다.
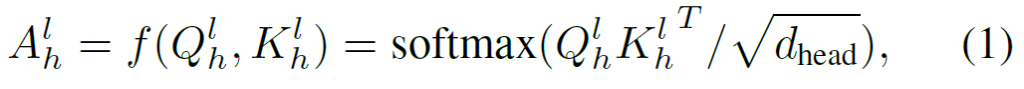
위의 수식에서 A_{h}^{l} \in \mathbb{R}^{N \times N}은 l번째 레이어에서 h 번재 헤드에서 생성된 attention weight 입니다.
Object Detection Heads
Detection Head는 Category 분류를 위해서는 Linear Layer를 활용하고 Box 예측을 위해서는 three-layer MLP를 활용한다고 합니다. Object Query의 가장 마지막 representation을 바탕으로 예측을 수행한다고 보시면 됩니다.
Object Detection Loss
Detection Loss는 이제 Object Query를 통해 예측된 Prediction Set과 Ground Truth 간의 matching이 가장 작아지는 방향으로 설계 되어 있습니다. 이 과정에서는 헝가리안 알고리즘을 통해 matching을 수행해주게 됩니다. 최적의 matching을 찾아주면 해당 matching을 바탕으로 원래의 예측을 permutation 시켜줍니다. 어려운 용어인 거 같지만 그냥 정답이랑 matching 된 것들을 올바르게 짝 지어준다고 보시면 됩니다.
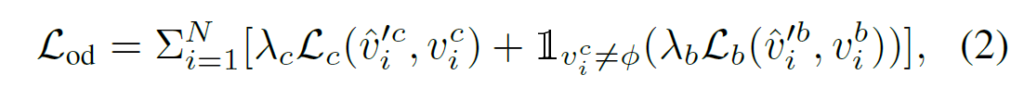
여기까지가 DETR 기본 구조 입니다. 더욱 자세하게 알아보고 싶다면 End-to-End Object Detection with Transformers 을 읽거나 저의 리뷰를 참고하시길 바랍니다.
EGTR
자 그럼 이제 제안하는 EGTR에 대해서 알아보도록 하겠습니다. 사실 제안하는 framework에서 크게 복잡한 부분은 없습니다. 관건은 attention weight를 어떻게 활용하여 predicate feature를 정의 하는 지에 집중하여 읽으시면 될 거 같습니다.
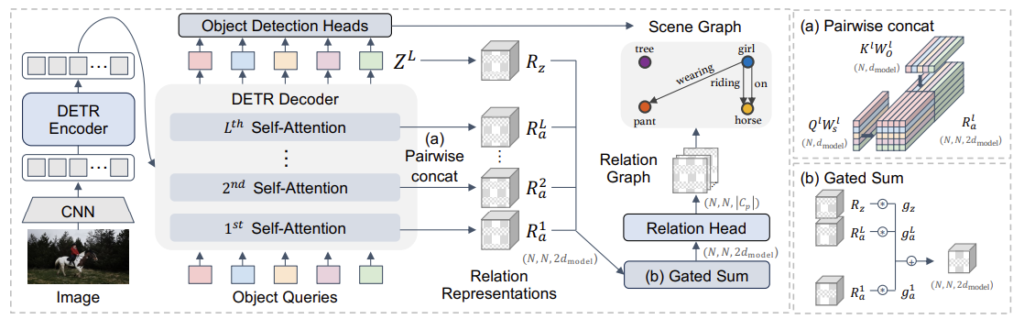
앞서 DETR 구조의 decoder 부분에서 attention weight가 생성 됐습니다.
결국 attention weight는 N \times N matrix로 N개의 object query 끼리의 가중치 그래프라고도 볼 수 있습니다. 제안하는 relation extractor는 predicate 정보를 self attention weight로부터 잘 추출하는 것을 목표로 합니다.
저자는 self-attention layer의 풍부한 정보를 보존하기 위해서 dot-production 기반의 연산보다는 정보를 그대로 살려줄 수 있는 concatenate 연산을 통해 relation representation을 정의합니다.
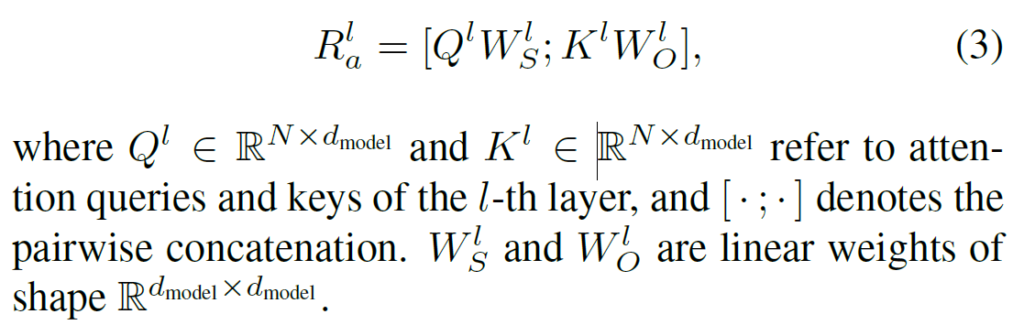
Q와 K는 각각 attention query와 key 입니다. 저자는 이를 subject와 object로 간주하기 위해 한번 더 linear projection을 시켜주고 있습니다. 추상적인 개념이지만, 그냥 저 attention token들이 subject와 object의 역할로써 작용하는 것을 기대하기 위함이라 생각하면 될 거 같습니다.
그리고 이렇게 정의한 relation representation을 모든 레이어에서 추출해줍니다. 다양한 관점으로 보기 위함이라 생각하면 될 거 같습니다.
마지막 relation representation은 또 notation을 한번 더 정리해주고 있습니다. 여기서는 attention query, key가 아니라 가장 마지막 object query를 그대로 활용하여 정의해주고 있습니다.
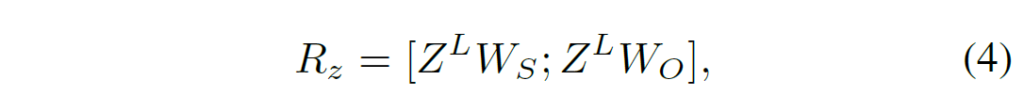
다음으로 각 계층으로부터 추출한 relation representation을 취합해주는 과정이 필요합니다. 이를 위해 저자는 gating mechanism을 활용 합니다. gating 연산은 weighted sum이랑 비슷하다고 보시면 될 거 같습니다. 각 계층으로부터 추출한 relation representation이 동일한 가중치를 가지지 않기 때문에 각각의 representation을 얼마나 gating (막을 것 인지)를 나타내는 weight를 생성하여 aggregate 하는 것이죠.
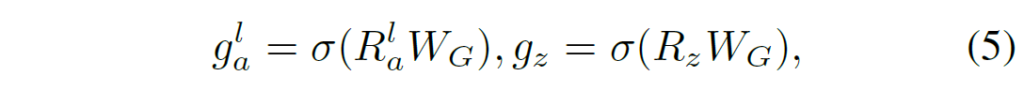
이 때 W_{G}는 gating value를 추출하는 linear project layer 입니다. 이렇게 각 계층으로부터 추출한 relation representation에 대한 gating value를 얻었으면 Gated Suim을 통해 graph를 생성합니다.
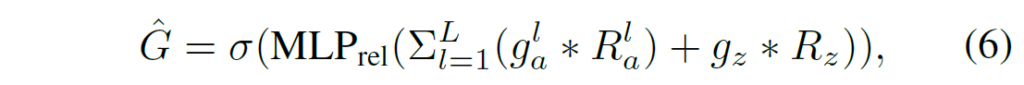
이 때 MLP는 d_{model}의 차원을 가지는 latent vector들을 predicate score로 바꿔주는 layer 입니다.
이렇게 최종적으로 예측은 \hat{G} \in \mathbb{R}^{N \times N \times |\mathcal{C}_{p}|} 로 relation graph라고 보시면 됩니다. 이 때 저자는 sigmoid function을 가장 마지막에 활용 했기 때문에 multiple relationship이 가능하다고 하네요.
Learning and Inference
EGTR을 학습 하기 위해서 저자는 multi-task learning을 활용합니다. 1) Object Detection, 2) Relation Prediction, 3) Connectivity Prediction 입니다. Object Detection은 DETR 구조를 그대로 활용 했다고 보면 됩니다.
그렇다면 Relation Prediction부터 이제 설명을 해볼 건데, 사실 Relation Prediction을 위해 예측 값을 어떻게 만드는지는 위에서 다 설명을 마쳤습니다.
따라서 이제 Relation Prediction을 위한 Loss가 어떻게 정의 되는지 알아보도록 하겠습니다.
우리가 예측한 \hat{G} \in \mathbb{R}^{N \times N \times |\mathcal{C}_{p}|} 와 Ground Truth인 G \in \mathbb{R}^{N \times N \times |\mathcal{C}_{p}|} 간의 matching을 수행하기 위해 object detection 때 찾았던 optimal matching을 통해 permutation (\hat{G'} \in \mathbb{R}^{N \times N \times |\mathcal{C}_{p}|} ) 된 그래프 예측을 정의합니다.
그렇게 permutation된 \hat{G'} 와 ground-truth인 G 를 비교할 수 있는 binary-cross entropy loss (\mathcal{L}_{rel}=\mathcal{L}_{bce}(\hat{G'}, G) )를 통해 relation extraction을 수행합니다.
그런데 여기서 한가지 문제가 있습니다. 그래프의 크기는 N \times N 인데, 실제 이미지에 존재하는 tripelt은 굉장히 sparse 하다는 것 입니다. 따라서 저자는 그래프를 세 개의 구역으로 나누어 각기 다른 loss를 사용합니다.
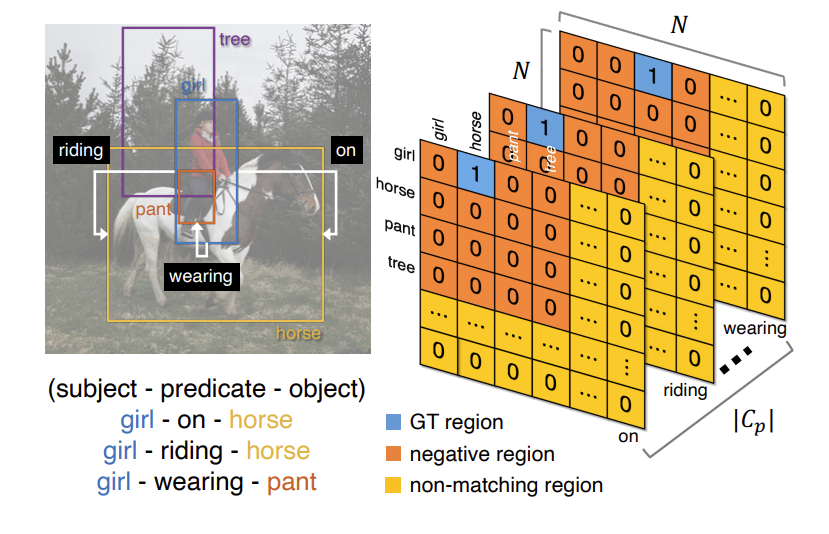
- GT region : 말 그대로 이미지 내에 존재하는 객체들끼리 실제 관계가 정의되는 구역 입니다.
- Negative region : 말 그대로 이미지 내에 존재하는 객체이지만, 관계는 정의 되지 않는 구역 입니다.
- Non-matching region : 이미지 내에서 존재하지 않는 객체 (No Object)들의 구역 입니다.
우선 GT region을 고려할 때 저자는 학습 초반에 subject와 object 간의 predicate를 정확하게 예측하기에는 부족한 표현력을 가지게 된다는 점을 강조합니다. 따라서 처음부터 predicate score을 1로 가이드를 주는 것이 모델 입장에게는 적절하지 않다는 것 입니다.
Label Smoothing
기본적으로 object를 잘 표현할 수 있게 detection performance가 보장되어야 하기 때문에 저자는 detection performance에 따라 uncertainty를 정의하고 label smoothing 기법을 활용 합니다.
일단 아래와 같이 특정 object에 대한 uncertainty를 계산합니다.
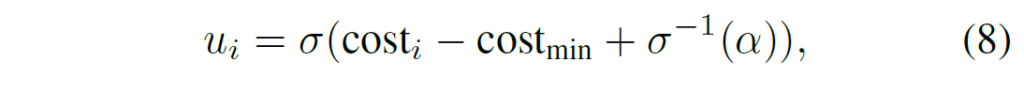
조금 헷갈리기는 하지만 제가 이해한 내용을 바탕으로 설명을 해보자면 \text{cost}_{i}는 초기의 matching cost이고, \text{cost}_{min}은 ground truth랑 완벽하게 맞았을 때의 cost입니다. 뒤에 \alpha 항이 있는데 이는 가장 최소의 uncertainty를 나타내는 일종의 하이퍼 파라미터라고 합니다.
따라서 uncertainty의 크기는 \text{cost}_{i} - \text{cost}_{min}에 달려있습니다. 현재의 performance가 좋지 않다면 \text{cost}_{i} - \text{cost}_{min}은 높은 값을 가질 것이고 당연히 uncertainty도 증가합니다. 반대로 performance가 좋다면 \text{cost}_{i} - \text{cost}_{min}은 낮은 값을 가질 것이고 uncertainty는 감소합니다.
이러한 원리를 바탕으로 저자는 현재의 detection performance를 간접적으로 나타내는 matching cost를 바탕으로 uncertainty를 정의하였습니다.
그리고 나서 ground truth label을 다음과 같이 smoothing 합니다.
G_{ijk} = (1-u_{i})(1-u_{j}) 로 정의 합니다. 결국 subject와 object의 uncertainty가 높으면 ground truth는 비교적 낮은 confidence로 가이드를 하다가 uncertainty가 낮아지면 높은 confidence로 수렴할 수 있게 난이도를 점점 높이는 방식 입니다.
Negative and Non-matching Sampling
모든 Negative와 Non-matching 영역을 활용하여 unbalance 문제가 발생하기 때문에, 저자는 각 region 마다 top-k개의 sample 만을 활용하여 loss를 계산한다고 합니다.
여기서 negative mining에 대한 디테일은 알려주지 않고 이전의 연구를 참조했다고 하네요. 결론만 얘기하면 Negative와 Non-matching 영역에서는 비교적 어려운 sample만 일부 샘플링하여 loss를 계산했다고 합니다.
Connectivity Prediction
Connectivity Prediction은 말 그대로 연결성을 예측하는 것 입니다. 두 객체간의 관계를 예측하는 것이 아니라 두 객체끼리는 임의의 관계가 있는지 없는지를 예측하는 것 이죠.
Relation Graph를 얻는 것과 비슷하게 Connectivity를 나타낼 수 있는 그래프도 동일한 relation representation을 활용하고 다른 MLP를 활용하여 정의한다고 합니다.
Object Detection에서 objectness를 고려하는 것과 비슷하다고 보시면 되고 본 논문에서 제안하는 새로운 방법은 아니고 기존 연구에서 많이 활용하는 보조 task 라고 하네요.
Experiments
가장 먼저 벤치마킹 실험 입니다.
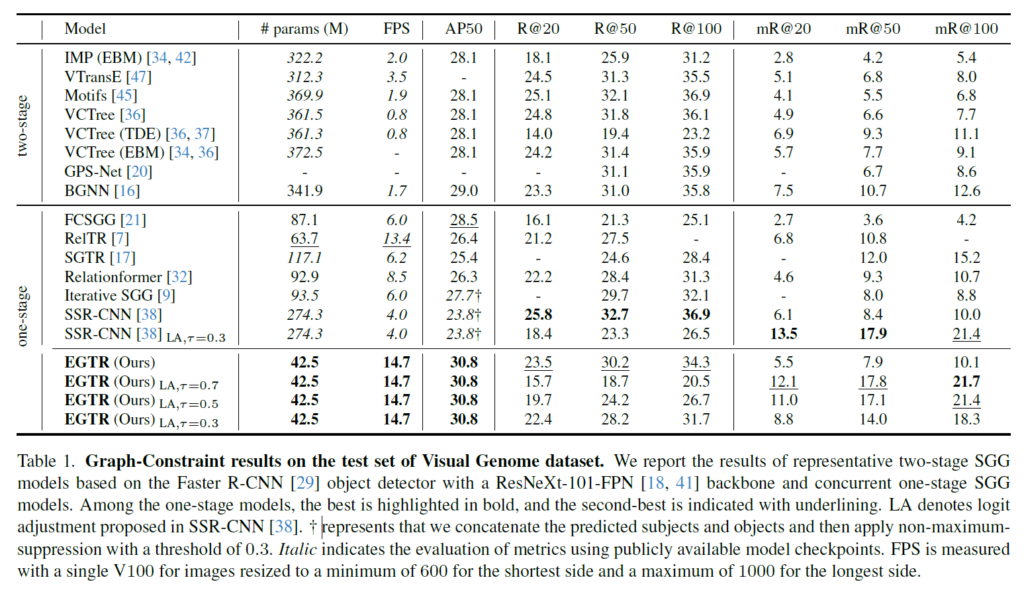
아래의 테이블은 Visual Genome 데이터 셋에서의 벤치마킹 실험 입니다. 벤치 마킹 테이블을 보시면 리스트 업 한 방법론들 중에서는 가장 적은 parameter와 빠른 FPS를 보여주고 있습니다.
저자는 triplet query와 detector가 없이도 굉장히 경쟁력 있는 성능을 보여주고 있습니다.
LA라는 것은 logit-adjustment라는 방법의 약자라고 합니다. Predicate를 예측할 때 tail 분포에 해당되는 predicate 예측에 도움이 된다고 합니다.
그런데 LA를 활용할 때 파라미터인 \tau 값에 굉장히 민감하게 작동하는 것으로 보여집니다.
정리하면 제안하는 방법은 one-stage 내에서도 굉장히 가볍고 빠른 모델을 제안하면서도 경쟁력 있는 performance를 보여주었다고 볼 수 있습니다.
Ablation Study
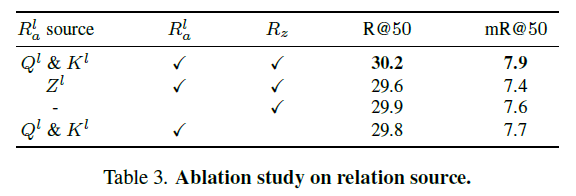
Relation Sources
첫 번째로는 relation source에 대한 ablation 입니다. 성능 차이가 그렇게 드라마틱 하지는 않아서 의미가 있는지는 모르겠지만… 결론적으로는 relation을 정의할 때 attention query와 key를 모두 활용하면서 모든 계층과 마지막 계층에서 relation representation을 정의하는 것이 가장 좋은 성능을 보여준다고 합니다.
개인적으로 궁금한 건 저기 저 세팅마다 모두 동일한 파라미터를 사용 했는지 궁금하네요.
Training Techniques
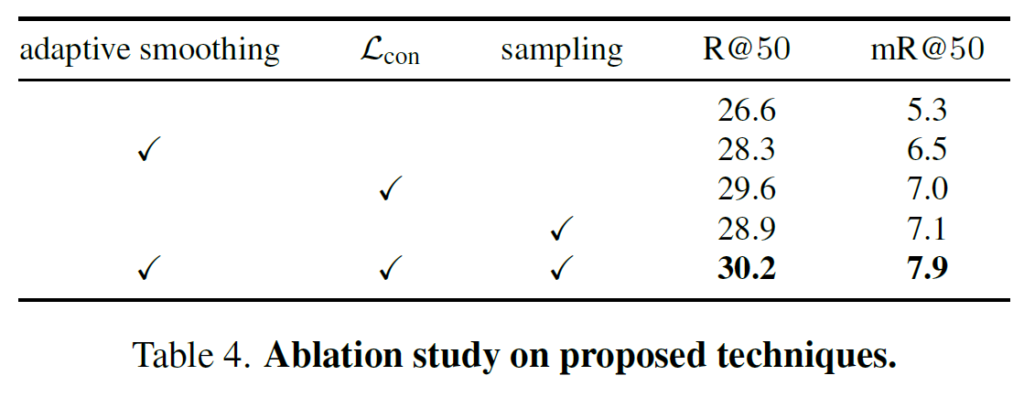
다음으로는 module wise ablation 입니다.
해당 실험 부분에서는 기본적으로 제안하는 모듈을 모두 활용하는 것이 가장 좋은 성능을 보여주는데
제가 한가지 궁금한 부분은 adaptive smoothing 만을 했을 때의 성능 향상이 sampling을 했을 때의 성능 향상 폭 보다 낮게 나오고 있습니다. 즉, hard negative sampling 만을 잘 해줘도 성능이 26.6->28.9까지 올라가고 있는데 여기서 adaptive smoothing과 \mathcal{L}_{con}을 차례대로 붙였을 때의 성능 향상 폭이 궁금해지네요.
뭔가 negative sampling 자체는 사실 contribution이 아니고 기존에도 많이 활용하던 테크닉이고 제안하는 모듈만으로의 성능 향상 폭은 조금 낮아 보이게 느껴지네요.
Sampling Methodology
마지막으로 negative sampling을 할 때는 negative와 non-matching rehgion 모두 해주는 것이 가장 좋은 성능을 보여준다고 합니다.

Discussion
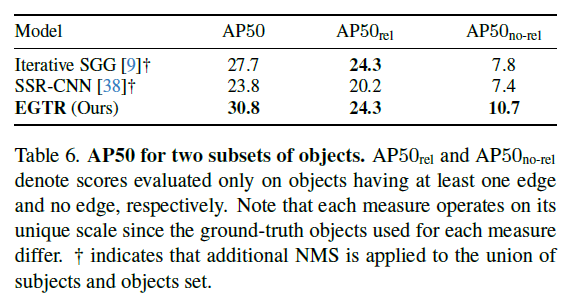
앞서 벤치마킹 실험에서 AP50의 성능이 높았던 이유에 대해 조금 더 분석하기 위한 실험이라 보시면 됩니다.
아래의 실험에서 rel은 relation이 있는 object만을 가지고 평가한 것이고 no-rel은 반대로 relation이 없는 object를 가지고 평가한 것 입니다.
그리고 위의 방법들은 triplet detection-based model 들을 가지고 와서 비교하였다고 합니다. triplet detection based model들은 relation이 있는 object 들은 비교적 잘 잡고 있지만 relation이 없는 object들에 대해서는 상대적으로 많이 낮은 성능을 보여주지만
제안하는 EGTR은 두 가지 상황에서 모두 적절하게 좋은 성능을 보여주어 최종적인 AP50이 가장 높게 나온다고 주장합니다.
Conclusion
리뷰가 좀 길어졌네요.
논문의 내용 자체는 굉장히 깔끔했습니다. Supplementary에 더 다양한 실험이 있는데 저는 그 부분까지는 읽지 않았습니다. 관심 있으시면 직접 읽어봐도 좋을 거 같네요.
후속 연구로는 EGTR의 복잡도를 유지하면서 더 성능을 높일 수 있다면 가장 좋겠네요.
감사합니다.