안녕하세요, 서른 여섯번째 x-review 입니다. 이번 논문은 2023년도 CVPR에 게재된 Open-Vocabulary Point-Cloud Object Detection without 3D Annotation 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
3D detection은 현재까지 제한된 클래스로 이루어진 데이터셋을 대상으로 학습하는 흐름으로 수행되고 있기 때문에 real-world 관점에서 다양한 물체를 고려하지 못하고 있습니다. 이렇게 학습 때 보지 못한 unseen 물체에 대한 일반화를 위해서 본 논문에서는 임의의 텍스트 설명이 포함된 물체를 검출하는 open-vocabulary 포인트 클라우드 검출을 수행하게 됩니다. 일반적으로 open-vocabulary 검출은 모델이 representation을 학습하고, 이러한 representation고 텍스트 사이의 연관성을 찾아야 하는데요, 3차원 task의 포인트 클라우드 형태는 데이터를 모으고 어노테이션을 하기가 모두 cost가 훨씬 많이 들기 때문에 많은 수의 클래스가 포함된 데이터를 수집하는 것이 어려우며 특히나 대규모 포인트 클라우드와 매칭되는 캡션 데이터를 구성하는 것이 현재로서는 거의 불가능한 상황이라고 합니다. 이런 detector와 텍스트 프롬프트 사이의 representation을 연결하기 어려운 상황을 감안하여 본 논문에서는 기존의 사전학습된 2D 이미지 모델을 사용해서 open-vocabulary 3D object detection 문제를 해결하고자 합니다.
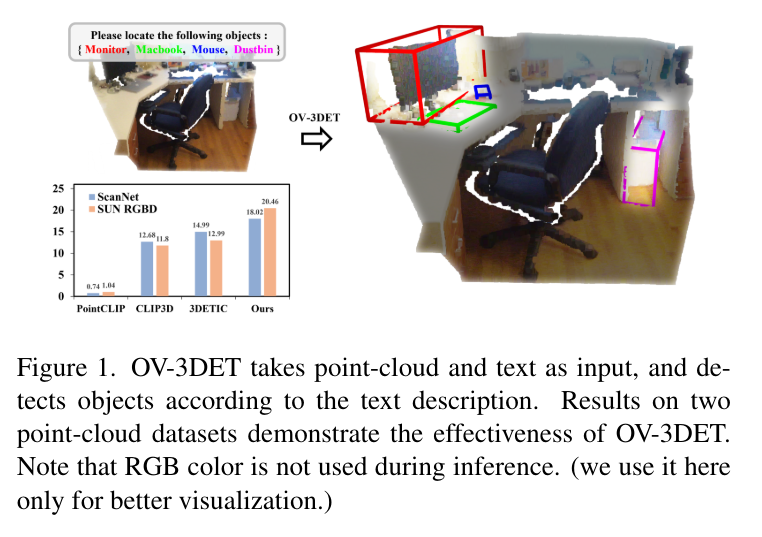
많은 분들이 아시다시피 이미지 차원에서는 일반화된 representation을 학습할 수 있는 Foundation 모델이 등장하였죠. 당시에는 그 중에서도 CLIP이 이미지와 텍스트 표현을 잘 연결하면서 2D에서 open vocabulary detection과 segmentation에 활발하게 사용되고 있었습니다. 저자는 이런 2D에서의 FM을 3D task에서 대규모 포인트 클라우드-텍스트 쌍이 포함된 데이터셋의 부재에 대한 문제를 해결하는데 사용하는 OV-3DET를 제안하게 됩니다. OV-3DET는 이전처럼 seen 클래스에 대한 supervision이 필요없이 이미지 차원 FM에서의 일반화된 representation을 가지고 와서 bounding box와 클래스 사이의 주석 없이 open vocabulary 3D detection을 직접 처리할 수 있다고 합니다.
OV-3DET는 크게 두 파트로 나누어 볼 수 있는데요, 먼저 일반적인 포인트 클라우드를 입력으로 하는 3D detector가 unseen 물체의 위치를 찾은 다음, 텍스트 프롬프트에 따라 물체의 라벨을 할당하는 방식을 학습합니다. 사전학습된 2D 모델로 이미지에서 2D 바운딩 박스 혹은 인스턴스 마스크를 생성합니다. 예측한 클래스 라벨은 사용하지 않고, coarse한 바운딩 박스 혹은 마스크를 3D detector의 supervision을 위해 사용하여 3차원 물체의 위치를 학습합니다. 두번째 파트는 이제 포인트 클라우드, 이미지, 텍스트 모달리티를 연결해서 3차원 검출기가 물체를 해당하는 텍스트 프롬프트와 연관지을 수 있도록 하는 debiased triplet cross model contrastive learning 방식을 제안하게 됩니다.
이러한 OV-3DET는 open-vocabulary 관련 방법론들 사이에서 높은 성능을 달성하였고 특히 많은 ablation study를 통해 방법론의 효과를 증명하였는데요, 이는 실험 파트에서 자세히 살펴 보도록 하고 방법론으로 넘어가도록 하겠습니다.
2. Method
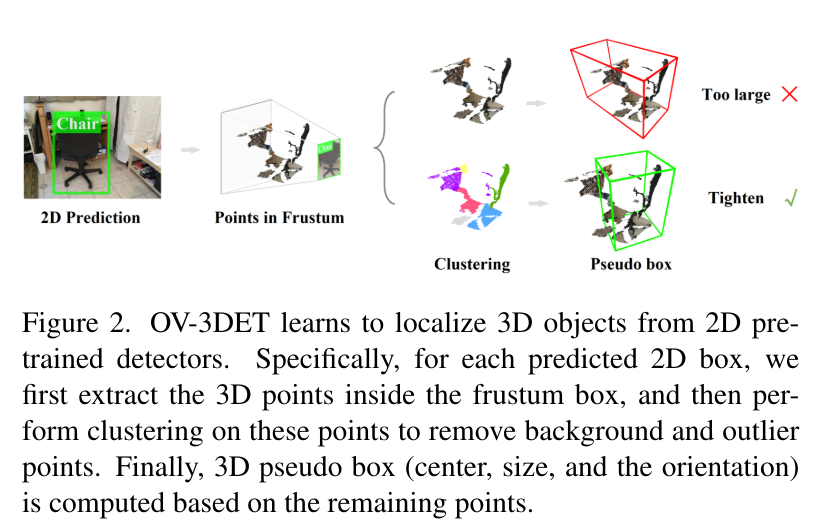
2.1. Overview
intro에서 이야기하엿 듯 OV-3DET는 두 단계로 구성되는데, 먼저 localization을 수행하고 그 다음 classification을 처리합니다. localization은 2D에서 사전학습된 모델 (예를 들면 Mask R-CNN이나 Fast R-CNN이 있겠죠)로 학습하고 Fig.2와 같이 frustum 형태의 포인트 클라우드를 타이트한 바운딩 박스로 변환한 다음에 예측한 2D 바운딩 박스를 3D detector의 수도 바운딩 박스로 사용합니다. classificaiton에서는 논문에서 새롭게 제안한 contrastive learning을 통해 세 가지 모달리티를 연결하여 모델이 텍스트 프롬프트에 속하는 물체를 인식할 수 있게 됩니다. 이런 과정을 통해 2D 사전학습 모델만을 활용하고 3차원 포인트 클라우드에 대해서는 어노테이션이 필요하지 않다는 것을 강조하고 있습니다.
2.2. Notation
본 논문에서는 notation이 좀 많이 나오기 때문에 자주 사용하는 noation을 한번에 정리하고 넘어가려고 합니다.
- T, I, P : 각각 텍스트, 이미지(I \in \mathbb{R}^{3 \times H \times W}) 그리고 포인트 클라우드 (P = \{p_i \in \mathbb{R}^3, i = 1, 2, 3 …, N\})
- \mathcal{D}^{pc} = {P_j}^{|\mathcal{D}^{pc}|}_{j=1}, \mathcal{D}^{img} = {P_j}^{|\mathcal{D}^{img}|}_{j=1} : 학습 동안 사용하는 라벨링 되지 않은 포인트 클라우드와 그와 pair한 이미지 데이터셋
- \hat{b}_{3D} \in \mathbb{R}^7 : 3차원 검출기에서 예측하는 3차원 바운딩 박스
- f_{3D} : \hat{b}_{3D} \in \mathbb{R}^7에 대응하는 RoI feature
- \hat{b}_{2D} \in \mathbb{R}^4 : 2차원으로 사용된 3차원 바운딩 박스
- f_{2D} : \hat{b}_{2D} \in \mathbb{R}^4에 대응하는 패치 feature
- f_{1D} : text feature
2.3. Learn to Localize 3D Objects from 2D Pretrained Detector
먼저 1단계인 localization에 대해 살펴보도록 하겠습니다. 포인트 클라우드에서는 원래 제한된 클래스 어노테이션으로 인해서 detector가 다양한 물체에 대한 localziation을 학습하는 것이 쉽지 않았습니다. 반면에 2D 검출기는 비교적 다양한 물체에 대한 사전 학습으로 인해서 이미 다양한 물체 검출이 가능하기 때문에, 이를 활용해서 3D 검출기의 localization 학습을 유도하고자 합니다.
\mathcal{D}^{pc}와 \mathcal{D}^{img}에 대해서 사전 학습 모델은 2차원 바운딩 박스 혹은 인스턴스 마스크를 예측하는데요, 이를 3차원 공간으로 reprojection하면 Fig.2와 같이 완전한 3D 바운딩 박스 모양이 아닌 frustum 형태로 물체를 감싸고 있는 박스가 우선적으로 생성됩니다. 그러나 본래 바운딩 박스는 물체를 타이트하게 둘러싸고 있어야 하기 때문에 포인트 클라우드의 지오메트리를 활용해서 박스를 물체 크기에 맞게 조정합니다. 무슨 말이냐 하면, frustum 박스 안에 포함된 포인트들을 가지고 클러스터링을 한번 해서 배경이나 outlier에 해당하는 포인트를 제거하는 것 입니다. 널널하게 frustum 형식으로 박스가 만들어져 있기 때문에 안에 있는 물체에 해당하지 않는 포인트들을 필터링해서 더 타이트한 박스를 만들이 위함이죠. 이렇게 포인트들을 제거한 유의미한 포인트들의 중심 위치, 크기 그리고 방향을 계산해서 ( 이걸 포인트의 지오메트리라고 합니다. ) 식(1)에 따라 3D detector의 supervision을 위해 사용합니다.
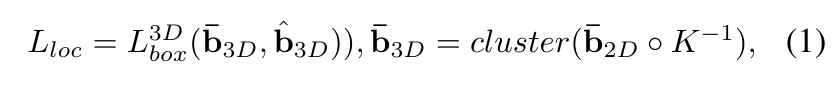
- \bar{b}_{2D} \in \mathcal{R}^4 : 사전학습 모델로부터 예측된 2D 바운딩 박스
- \bar{b}_{3D} \in \mathcal{R}^7 : reprojection한 2D 바운딩 박스로부터 클러스터링하여 생성된 타이트한 3D 수도 바운딩 박스
- L^{3D}_{box} : 3차원 검출기인 3DETR에서 기존에 사용하는 바운딩 박스 regression loss (3DETR에 대한 자세한 내용은 제 예전 리뷰를 참고해주시면 좋을 것 같습니다.)
해당 섹션에서 얘기하는 단계에서는 3차원 검출기가 사전학습 모델로부터 localization을 학습하는데 초점을 맞추기 때문에 사전학습 모델의 classification 예측은 사용하지 않습니다.
2.4. Learn to Classify 3D Objects from 2D Pretrained vision-language Model
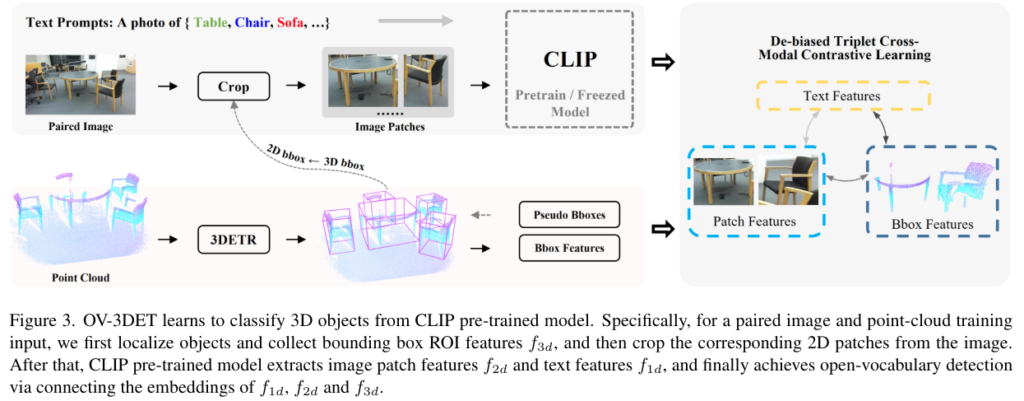
이번 단계에서는 텍스트 프롬프트를 통해 localization한 바운딩 박스에서 물체를 찾는 것을 목적으로 합니다. 2D open vocabulary detection에서는 사전학습된 vision-langauge 모델(VLM)로 이미지와 텍스트를 연결하는데, 3차원 분야에서는 아직 이런 사전학습 모델이 존재하지 않기 때문에 2D에서 VLM을 활용하려고 합니다. 기존 3차원 분야에서는 보통 멀티 모달이라고 하면 이미지-포인트 클라우드를 떠올리기 쉬운데 이런 흐름을 따라 이미지를 포인트 클라우드와 텍스트를 연결할 수 있는 매개체로 삼았으며, 이런 매개체가 있음에도 텍스트와 포인트는 본질적으로 매우 다른 도메인에 존재하기 때문에 연결성을 위해 제안하는 것이 De-biased Triplet Cross-Modal Contrastive Learning (DTCC) 입니다.
Fig.3을 보면 학습 중에 f_{3D}가 얻을 수 있는 \hat{b}_{3D}로 포인트 클라우드 예측을 한 다음 projection을 위한 내부 파라미터 행렬 K로 2차원으로 투영해서 투영한 영역으로 이미지 패치를 구성합니다. 그 다음 다시 사전학습 된 VLM (여기서는 CLIP을 사용)에 텍스트 프롬프트와 함께 보내게 됩니다. 그러면 텍스트 feature f_{1D}와 이미지 패치 feature f_{2D}을 얻을 수 있습니다. 이렇게 추출한 모든 모달리티의 feature을 연결하기 위해 DTCC를 마지막으로 사용합니다. 여기서 저자가 강조하고 싶은 점은 원래 이미지 classification으로 설계된 CLP에서 제공하는 hand-crafted 프롬프트를 직접 재사용하는 것으로, 실질적으로 제공된 문장의 빈 위치에 클래스 이름을 넣기만 하면 된다고 합니다.
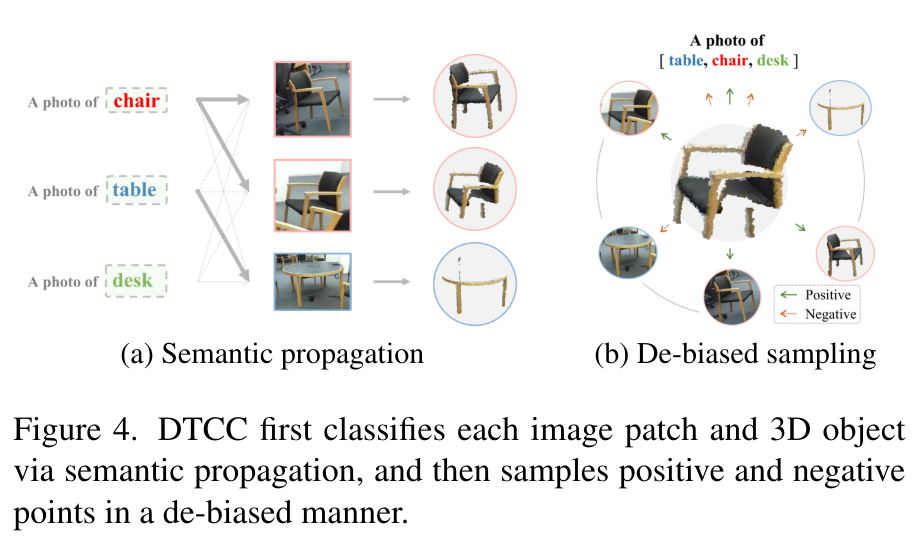
그럼 이제 계속 얘기한 DTCC에 대해 알아보도록 하겠습니다. 먼저 기존의 contrastive learning은 postivie/negative을 대상으로 계산되는데, 본 논문의 케이스는 negatvie 샘플은 일반적으로 어노테이션이 없기 때문에 무작위로 샘플링된 포인트 데이터 입니다. 그래서 FN 포인트로 간주되어 편향된 contrastive learning을 수행하는 결과로 이어질 수 있습니다.
그래서 DTCC에서는 잘못된 샘플링을 바로잡기 위해서 Fig.4와 같이 (a) semantic propagation을 통해 각각의 이미지 패치와 3차원 물체를 텍스트 프롬프트와 연결한 다음 (b) 서로 다른 프롬프트에 대해 neagative 샘플링을 수행합니다. 구체적으로 semantic propagation은 VLM을 활용하는데요, 이미지 패치를 semantic한 라벨과 매칭한 다음 패치와 pair한 3차원 박스로 semantic 정보를 3차원 물체로 옮기는 흐름 입니다.
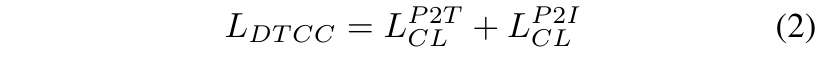
DTCC loss는 식(2)와 같은데, 크게 L^{P2T}_{CL}과 L^{P2I}_{CL}로 구성되어 있습니다. 각각 포인트-텍스트, 포인트-이미지 사이의 contrastive loss를 의미합니다. 여기서 contrastive loss는 식(3)과 같이 정의할 수 있습니다.
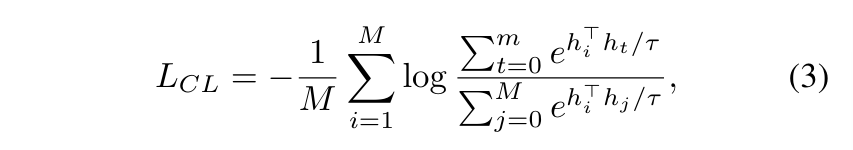
- h : contrastive learning과 관련된 샘플
- m : i번째 샘플 h_i에 해당하는 positive 샘플 수
여기서 3D 검출기의 가중치만 학습하고 CLIP은 freeze 하기 때문에 텍스트-이미지 사이의 contrastive loss를 계산하지 않아도 됩니다. 즉, DTCC는 VLM의 임베딩을 통해 텍스트-이미지-포인트 임베딩을 연결하고 있으며 전체 loss는 식(4)로 정의합니다.
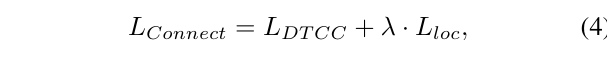
3. Experiment
실험은 3D Object Detection 데이터셋인 SUN RGB-D와 ScanNetV2을 사용하며 pair한 포인트 클라우드와 이미지를 입력으로 사용합니다. OV-3DET에서는 두 데이터셋에서 20-200개의 클래스에 대해 평가하고 있습니다.
3.1. Main Results
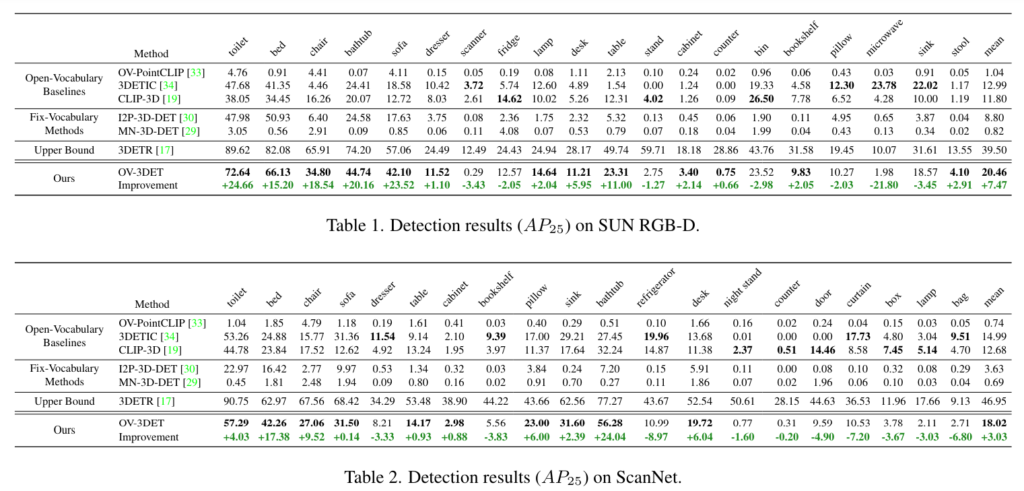
당시에 open vocabulary 3D detection에 대한 직접적인 베이스라인이 없었기 때문에 비교 모델로 일반적인 3D detection이나 2D에서의 open vocabulary 연구와 비교하고 있는데, 실험 결과를 보기 전에 베이스라인을 먼저 정의하면 다음과 같습니다.
- PointCLIP
- CLIP을 포인트 레벨로 확장하여 포인트-텍스트 임베딩 공간 연결 시도한 classification 모델
→ localization을 추가하기 위해 사전학습된 수도 박스 3DET를 사용해서 물체 localization 찾은 후 예측한 박스의 포인트를 추출합니다. 마지막으로 해당 PointCLIP을 통해 예측한 바운딩 박스의 classification을 예측합니다. 이러한 예측 결과를 베이스라인으로 삼고, OV-PointCLIP으로 정의합니다.
- Detic
- 이미지에서 21K개의 클래스를 검출하는 모델
→ 2차원에서 3차원으로 reprojection하고 3차원 박스를 타이트하게 변형하여 두번째 베이스라인인 3DETIC로 사용합니다.
- Detic + CLIP
→ Detic를 사용하여 3차원 물체 찾고, CLIP 사용하여 open vocabulary classification 수행하며 CLIP-3D로 정의합니다.
- Image2Point
- 가중치를 copy하거나 inflating하여 사전학습된 이미지를 포인트 클라우드로 옮기는 방법론
→ DETR에서 3DETR로 트랜스포머 가중치를 copy해서 SA 모듈과 detection head fine tuning 하여 3D-DET 베이스라인을 설정합니다. ( 사전 정의한 vocabulary만 분류 가능하며 open vocabulary 3D 검출기는 X)
- ModelNet
- 3차원 classification을 위한 40개 클래스에 대한 데이터셋
→ OV-PointCLIP과 마찬가지로 수도 라벨을 사용해서 물체를 localization하고, classification head를 ModelNet으로 사전 학습된 분류기로 대체하여 베이스라인 MN-3D-DET을 설정합니다. (open vocabulary 3D 검출기 X)
이제 실험 결과를 보면 Tab.1과 Tab.2가 각각 ScanNetV2와 SUN RGB-D에서 베이스라인들과의 비교를 하고 있습니다. 결과적으로 inference시에 이미지에 의존하지 않는 본 논문의 방법론이 open vocabulary에 해당하는 베이스라인 대비 최대 7% 이상의 성능 향상을 달성하고 있습니다. 이러한 차이를 통해 텍스트-포인트 클라우드의 명시적인 연결이 성능 향상에 도움이 된다는 것을 확인할 수 있습니다. OV-PointCLIP과 MN-3DDET는 ModelNet에서 포인트를 분류하는 방법을 학습하곤 있지만, 두 방식 모두 CAD 모델과 RGB-D 센서로 취득한 포인트 사이의 큰 차이로 인해서 성능이 하락한다고 합니다. I2P-3D-DET는 이미지 사전학습 모델에서 3D detector로 가중치를 직접 copy하는 것이 효과가 있다는 것을 보여주면서, 이를 통해 3D task에서 2D 사전학습 모델의 활용성을 입증하고 있습니다.
3.2. Analysis of the Influence of Text Prompts

이제 ablation study인데요, 먼저 텍스트 프롬프트 효과에 대한 실험 결과 입니다. OV-3DET에서 텍스트 프롬프트는 (1) 수도 3차원 바운딩 박스 생성 (2) DTCC (3) inference 이렇게 세 부분에서 사용됩니다.
Text Prompts Used in Pseudo Bounding Box Generation
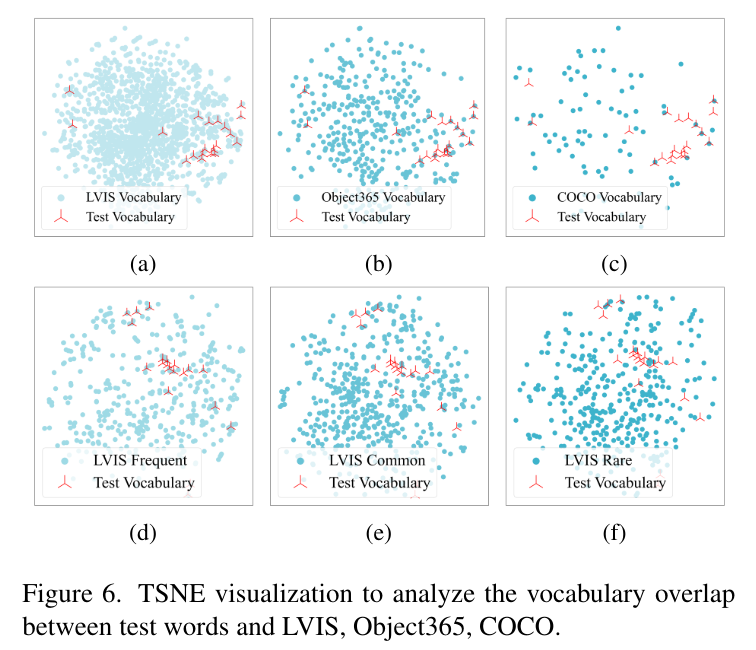
LVIS 데이터셋에서 수도 바운딩 박스 생성에 사용하는 텍스트 프롬프트의 효과를 먼저 확인합니다. Tab.4의 rare, common, frequent는 학습 이미지 수에 따라서 나누어졌으며, 이 세 그룹과 테스트 카테고리 간의 관계는 Fig.(d)-(f)를 통해 확인할 수 있습니다. rare, common, frequent 물체의 수도 바운딩 박스로 OV-3DET를 세 번 재학습 하는데, 각각의 재학습된 모델을 OV-3DET-{}로 정의하는 것 입니다. 결과적으로 모든 LVIS vocabulary를 사용해서 수도 바운딩 박스를 생성하는 all이 가장 높은 성능을 보여주면서 수도 바운딩 박스 생성에 사용하는 텍스트 프롬프트의 차이가 성능에 영향을 미친다는 점을 보여주고 있습니다. 또한 Fig.6(e),(f)에서 볼 수 있듯이 rare가 common보다 성능이 높은데, 이는 rare의 상자가 이미지 물체에 대한 스케일, 위치나 shape 측면에서 더 다양하게 존재하기 때문에 새로운 클래스를 localization할 가능성이 더 높다는 것을 알 수 있습니다.
Text Prompts Used in Evaluation
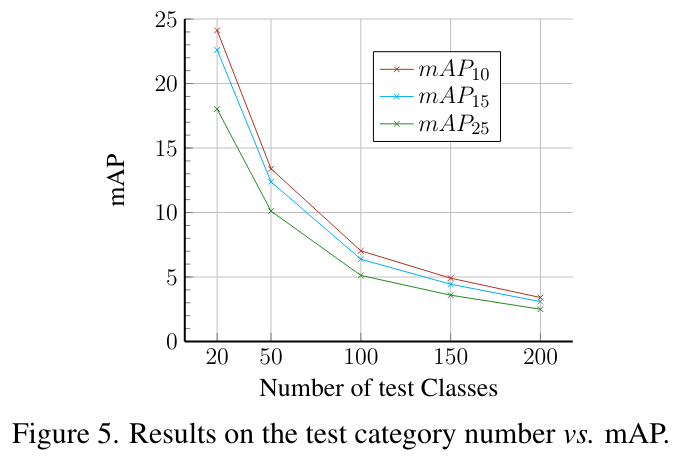
Fig.5에서 ScanNet200의 vocabulary를 사용해서 테스트 vocabulary 크기와 최종 성능 간의 관계를 분석하고 있습니다. 테스트 vocabulary 크기가 커질수록 mAP가 점차 감소하고 있는데, 이는 포인트 클라우드 데이터의 sparse함과 불완전성 때문에 이미지 대비 분별력이 떨어질 수 밖에 없어서 테스트 vocabulary의 크기가 커질수록 비슷한 형태를 가진 물체를 구별해야 하는 경우가 많아질 수 밖에 없어서 supervised 기반 3D detector에게도 어려운 경우라고 합니다.
3.3. Ablation on De-biased Contrastive Learning
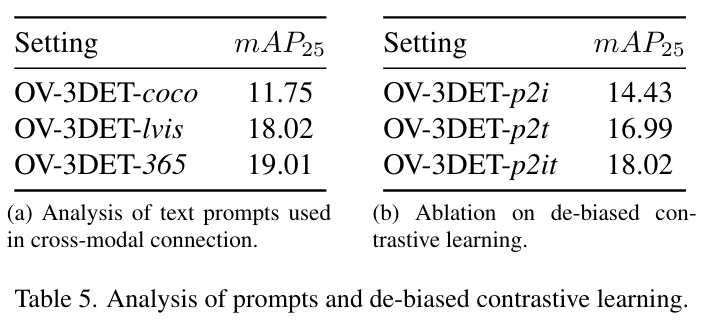
이번에는 DTCC의 효과를 보여주는 실험으로, pair 관계를 사용하여 포인트를 이미지에 align을 맞추고 다른 세팅으로는 pair 이미지와 VLM을 통해 포인트를 텍스트에 align 맞출 수 있습니다. 마지막으로는 포인트를 이미지-텍스트에 동시에 align을 맞추는 것인데 이 세 가지 방식을 p2i, p2t, p2it로 표시하고 있습니다. OV-3DET-p2i는 biased contrastive learning이며 OV 3DET-p2t와 p2it는 debiased contrastive learning 입니다. 결과적으로 Tab.5에서 확인할 수 있듯이 p2it가 타 방식보다 더 높은 성능을 보이고 있습니다.
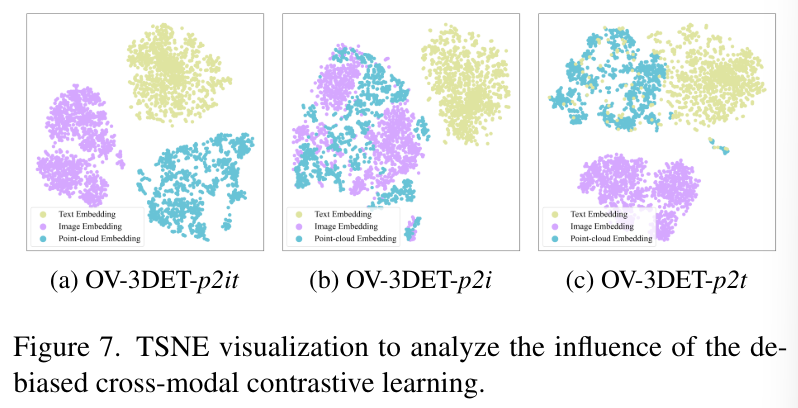
debiased contrastive learning을 분석하기 위해 Fig.7에서 TSNE를 통해 각 모델의 임베딩을 시각화하고 있습니다. 분석 결과를 보면 먼저 CLIP은 이미지-텍스트 feature가 개별적으로 클러스터링 되어 두 모달 사이의 균형을 이루고 있습니다. (b)는 이미지와 포인트가 연결되고 있으며 p2t는 텍스트-이미지 사이의 연결이 되고 있습니다. p2it는 고정된 클립 임베딩에서 텍스트와 이미지가 분리되어 있고, 두 모달리티에 포인트를 align 맞춰야 하기 때문에 어느 한 모달리티에 치우치지 않고 균형을 맞춤으로써 더 나은 결과를 얻을 수 있었다고 분석하면서 리뷰를 마무리 하도록 하겠습니다.
리뷰 잘 읽었습니다. 3D Domain에서도 Open-Vocabulary 연구가 활발하게 진행되고 있나 보네요.
혹시 해당 연구 방향으로 논문 작성을 계획 중이신걸까요? 개인적으로 궁금해서 질문 드립니다.
논문의 방법론을 보면 결국 전적으로 3D unseen 객체의 카테고리 예측은 2D Foundation Model (CLIP)에 의존하고 있는 거 같은데 이로 인해 발생할 수 있는 한계점(?)에 대해서 생각하고 계신게 있을까요? 개선 방향이나..
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
Open-Vocabulary 쪽으로 논문 작성을 계획하고 있는건 아니고 .. 3D task에서 FM 활용 방향을 살펴보다 보니 해당 논문까지 읽게 되었습니다.
2D FM에 대한 의존보다는 CLIP을 사용했을 때의 한계를 얘기할 수 있을 거 같은데, 24년도 CVPR에 다른 VFM 대비 CLIP과 같은 VLM을 사용하게 되면 3차원 representation 능력이 저하되는 분석 논문이 나오면서 CLIP의 명확한 한계를 확인할 수 있었습니다.
감사합니다.
좋은 리뷰 감사합니다.
2D의 open-vocabulary를 3D detection에 적용하기 위해 활용한 방식이 흥미롭습니다..
해당 논문과 관련하여 몇가지 질문이 있습니다.
먼저, figure 2에서 2D detection결과를 이용하여 localization을 수행한다고 하셨는데, tight한 박스를 만들 때 잘못하면 실제 객체 영역보다 작아지는 경우는 따로 고려하지 않나요?? L_loc를 통해 2D로 구한 박스를 3D 정보로 적용하므로써 대략적인 객체 형태를 커버할 수 있는 것으로 이해하면 될까요??
또한 3D에서의 open vocabulary 문제를 해결하고자 한 논문인데 이에 대한 평가 세팅은 따로 고려되어있지 않아서 아쉬운 것 같습니다.. 최근 연구에는 3D open vocabulary 평가 기준이 있는 지 찾아보시면 좋을 것 같습니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 우선 가장 큰 목적이 frustum한 바운딩 박스를 필요없는 영역을 제외한 물체만 포함되도록 줄이는 것이다 보니 실체 객체 영역보다 작아지는 경우는 따로 고려하지는 않습니다. 말씀하신거처럼 2D로 구한 박스를 3D 정보로 적용하기도 하고, 박스 내에서 물체인 것 같은 포인트에 대한 grouping을 진행함으로써 최대한 물체의 shape에 맞게 맞추고 있다고 이해해주시면 좋을 것 같습니다.
2. 아무래도 본 논문이 3D detection을 open vocabulary 문제로 해결하고자 한 첫번째 논문이다 보니 다른 모델과의 비교를 위해 기존에 사용하는 평가 메트릭을 사용한 것 같습니다. 말씀하신 것처럼 최근 연구에는 평가 기준이 설정되었을 것 같아 한번 찾아보도록 하겠습니다.
감사합니다.
안녕하세요 리뷰 잘 읽었습니다.
1. Frustum형태가 무엇인가요? 물체를 감싸고 있는 형태라고 뒤편에 쓰여져 있으나, 이 것이 3D bounding box와 무엇이 다른지 궁금합니다. 육면체의 형태는 맞을까요?
2. 방법론 자체는 굉장히 간단해보이는데, 몇몇 제약점 (필요해보이는 요소가 많아 보임)이 필요해보이네요. 기존 일반적으로는 아는 3D Point Cloud 외, 해당 논문에서 Unseen을 위해 전체 파이프라인에서 부가적으로 필요한 요소들이 있으면 설명해주시면 감사합니다.
3. 결국 2D VLM?, 2D Localization?은 어떤 방식을 사용하나요? 또한 Occlusion, Truncated 정도에 따라 Image Patch로 내뱉을 때 CLIP에서 오히려 오예측을 하거나 하는 문제점은 없을까요? 그렇다면 Segmentation이 좋을텐데, 또한 물체의 수에 따라 Unseen의 수에 대한 예측이 달라질텐데 이들은 어떻게 설정되는지 등의 Experiments Detail도 설명해주시면 감사합니다.
4. Figure 6에 대해 조금 더 자세히 설명해주실 수 있을까요? 본문 중 “Fig.6(e),(f)에서 볼 수 있듯이 rare가 common보다 성능이 높은데,“로 적혀있는데, T-SNE에서 성능을 판단하는 기준점이 있었나요?
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 먼저 Frustum의 예시 사진에서 보이는 그대로이며, 물체를 감싸고 있는 육면체 형태의 박스를 의미하고 있습니다. 3D bounding box와 다른점은 아무래도 직육면체, 정육면체의 형태를 띄는 bounding box와는 다르게 육면체이지만 단순히 8개의 점을 찍고 도형을 그린것과 같은 frustum은 좀 더 coarse한 형태라고 이해해주시면 좋을 것 같습니다.
2. 기존 3D point cloud외 부가적으로 필요한 요소들이 있냐는 질문이 .. 입력으로 어떤 데이터가 더 들어가야하는지에 대한 질문이 맞을까요 ? 맞다면 학습 시에는 포인트 클라우드, 이미지, 그리고 텍스트가 필요하고 inference에는 포인트와 텍스트를 필요로 합니다.
3. localization은 방법론에 적혀있는 것처럼 2D 사전학습 모델을 통해 예측한 박스나 마스크를 3D로 옮겨서 supervision에 사용하는 방식을 사용합니다. VLM은 여기서 사용하는건 아니구요, 여기서 사전학습 모델은 FM이 아니라 정말 일반적인 사전학습 모델을 의미합니다. experimental detail은 제가 리뷰에 적어놓은 것이 전부로 .. 물체 수나 unseen 수에 따른 설정에 대한 설명은 논문에 있진 않았습니다.
4. Fig.6이 아니라 Tab.4를 기준으로 적으려고 했는데 제가 본문에 잘 못 적은 것 같습니다.. 하하 표의 정량적인 수치를 보고 성능이 높다고 표현하였습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
CLIP의 인기로 인해서 텍스트를 이용해서 연구를 확장하는 것이 확실히 요즘 연구의 트렌드인거 같습니다. 본 연구도 이를 잘 이용한 논문인것 같습니다. 궁금한 점이 있는데, Figure 6같은 경우, test vocabulary는 test에 사용되는 vocab에 대한 임베딩 벡터가 vector space상에서 어떻게 표시되는지를 표시한 건가요? Figure 6의 (a),(b),(c)는 단순한 데이터셋 차이를 나타낸 것인지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
말씀하신거처럼 Fig.6의 (a), (b), (c)는 데이터셋마다 test에서 사용하는 vocabulary에 대한 임베딩 벡터가 vector space에서 표시되는 것을 정성적으로 보여주는 자료 입니다.
감사합니다.
흥미로운 논문 리뷰 감사합니다.
아주 간단한 질문 하나 남기고 갈게요!
1. 해당 기법에서 3d bbox를 예측하는 아키텍쳐는 그림에서는 표현되지 않은 모델이 예측하는 걸까요? 그럼 어떤 모델을 사용하는 것일까요?
2. DTCC에서 L_P2T와 L_P2I는 CLIP의 text feature, image feature를 teacher로 두고 학습하는 걸까요?
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 3차원 바운딩 박스를 예측하는건 만든 수도 3D 바운딩 박스를 이용해서 3DETR를 이용하게 됩니다.
2. 넵 CLIP의 text feature와 image feature을 사용하는 것이 맞습니다.
감사합니다.
안녕하세요 손건화 연구원님. 좋은 리뷰 감사합니다. 2D에서 사전학습한 Foundation Model의 representation이 3D detection에 효과가 있다는게 신기하네요.
질문이 한가지 있습니다. 제가 3D detection에 대해서 몰라서 생기는 의문인 것 같은데, 사전학습된 2d detector를 어떻게 3d detector로 가져와서 활용하나요? 2d의 input은 3차원 텐서이지만 3d 데이터는 point cloud여서 처리하는 모델도 상당히 다를 듯 한데, 3D 데이터 처리 모델이 어떤 식으로 동작하는지 설명해주실 수 있을까요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
사전 학습된 2D detector로 추출한 feature와 3D detector는 보통 2D↔3D 사이의 차원 변환을 통해 한 feature가 다른 feature의 차원으로 이동하여 하나의 차원 공간으로 모으게 됩니다.
3D 데이터 처리라는건 포인트 클라우드를 어떻게 처리하냐고 질문 주신 거 같은데, 포인트 클라우드를 복셀 형태로 변환하여 CNN으로 통과할 수 있도록 하거나 혹은 PointNet/PointNet++와 같이 raw 포인트 클라우드를 모델에 그대로 집어넣어서 연산이 가능한 백본 네트워크를 사용해서 처리하게 됩니다.
감사합니다.