안녕하세요. 오늘의 X-Review에서 소개해드릴 논문은 2024년도 CVPR에 게재된 <Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection> 입니다. 우선 본 논문은 제가 계속해서 관심갖고 살펴보고있는 비디오 분야의 Moment Retrieval (MR)과 Highlight Detection (HD)을 동시에 수행하는 task를 다루고 있습니다. 직전에 리뷰하였던 Task-Reciprocal DETR (AAAI, 2024), 즉 TR-DETR이 두 task 간의 상관관계를 살펴보고 성능 향상을 위해 각자의 task가 서로에게 도움받다는 컨셉을 제시하고 그에 맞는 파이프라인을 구성했습니다. 이번 리뷰에서 소개해드릴 방법론인 TaskWeave도 이름에서부터 알 수 있듯 두 task 간 공통점, 차이점, 상호작용을 좀 더 명시적으로 모델링하여 성능을 올리게 됩니다.

1. Introduction
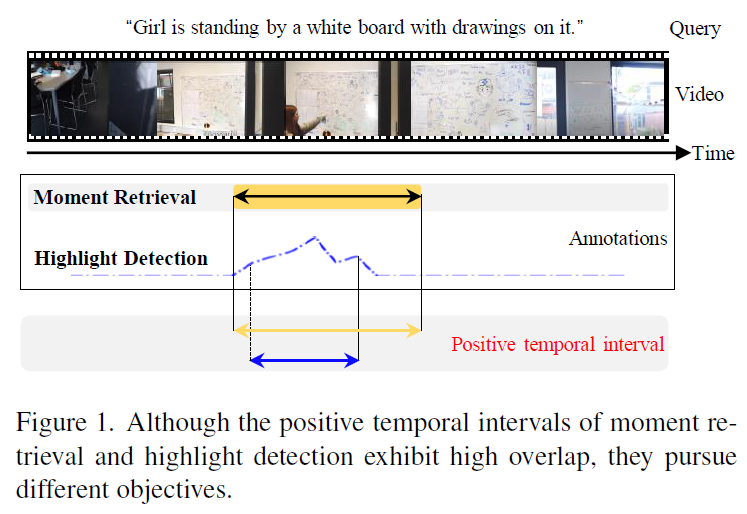
위 그림 1에는 특정 텍스트 쿼리와 비디오 쌍에 대한 MR과 HD의 annotation이 시각화되어있습니다. 두 task에 대한 annotation은 기본적으로 구간이 겹치지만 세부적으로 보았을 때 MR은 정말 구간을 찾기만 하면 되고, HD은 구간 중에서도 각 비디오 clip이 얼마나 텍스트 쿼리와 상응하는지 score를 좀 더 fine-grained하게 추출해야하는 상황입니다. 두 task의 궁극적 목적은 살짝 다르다는 점을 이야기하는 것입니다.
개인적인 생각으로 두 annotation의 구간이 겹치는 이유는, 유일하게 두 task를 동시에 수행할 수 있도록 annotation 되어있는 데이터셋인 QVHighlights에서 MR 상응 구간으로 이미 라벨이 붙은 비디오 clip에 대해서만 HD의 점수가 매겨져있기 때문인 것 같은데, 우선 두 task가 찾아야하는 목적에는 공통점도 있고 차이점도 분명히 존재한다는 주장으로 이해해볼 수 있습니다.
제가 지금까지 리뷰로 남겼던 여러가지 DETR 기반의 MR&HD 방법론들은, 일반적으로 DETR 구조를 따라 task를 수행하며 궁극적으로는 MR과 HD라는 두 task를 수행하기 위해 공통의 feature를 사용하였습니다. 보통은 DETR의 Transformer encoder-decoder 구조 중 encoder를 타고 나온 memory를 FFN에 입력하여 HD을 먼저 수행하였고, memory와 moment query를 decoder에 태워 얻은 feature를 FFN에 입력하여 MR을 수행하였습니다.
이렇게 두 task를 동시에 수행하기 위해 공통된 encoder로부터 feature를 추출하여 사용하는 기존의 방식을 backbone은 공유하고 데이터에 의존하여 두 task를 수행할 공동의 feature를 추출한다는 의미로, bottom-up, data-driven paradigm이라고 칭합니다. 이러한 방식은 두 task를 수행하는 데에 있어 모델 설계의 구조론적 관점보다는 data로부터 학습되는 feature에 크게 영향을 받는다는 특징이 있어 궁극적으로 수행해야하는 MR과 HD 각각의 특성에 대해서는 간과하게 된다고 저자는 이야기합니다.
공동의 backbone으로부터 feature를 추출함으로써 두 task의 공통점만을 학습하는 기존 방식의 문제점을 해결하고자 저자는 task-specific한 특성을 top-down 방식으로 끌어내고자 합니다. 아직 bottom-up, top-down이 이 방법론에서 정확히 무엇을 의미하는지 감이 잘 오지 않으실 수도 있는데, 대략 feature로부터 MR과 HD의 output을 만들고 끝내면 bottom-up, 이렇게 얻은 output을 MR과 HD 각각을 수행하는 데에 있어 도움을 다시 주면 top-down이라고 이해하시면 됩니다.
결론적으로 TaskWeave는 MR과 HD의 joint한 수행을, 비디오 도메인의 feature 모델링보다는 다른 도메인에서도 활발히 연구되고 있는 Multi-task learning 관점에서 들여다 본 방법론이라고 이해하시면 좋을 것 같습니다. TaskWeave는 MR과 HD의 공통점, 차이점, 상호작용을 모두 모델링하여 성능을 올리고자 설계된 방법론입니다. 대략적으로만 먼저 설명드리면 공통점을 잡아내기 위한 shared expert, 구별되는 특성을 잡아내기 위한 2개의 task-specific experts를 포함하고 있고, 마지막으로 상호작용을 잘 모델링하기 위해서 저자는 inter-task feedback mechanism을 소개합니다. 이 부분이 바로 MR/HD의 출력이 HD/MR 수행에 도움을 주는 부분입니다. 마지막으로 제안하는 task-dependent joint loss는 task-specific weight들을 동적으로 조정할 수 있도록 만들어줍니다.
자세한 내용은 contribution을 정리한 뒤 방법론에서 알아보겠습니다.
Contribution
- It proposes a novel task-driven, top-down framework for joint MR and HD.
- It introduces a task-decoupled unit, an inter-task feedback mechanism, and a principled task-dependent loss.
- It achieves SOTA performance on three datasets. The ablation study validates the methods.
2. Methodology
2.1 Overview
Notation에 대해 간단히 정리하고 방법론 설명 시작하겠습니다.
W개의 word로 이루어진 텍스트 쿼리와 N개의 클립으로 구성된 비디오의 쌍이 입력됩니다. 그럼 MR의 목표는 상응 구간의 중간 지점 q_{c}와 구간의 너비 q_{w}를 얻는 것이고, HD의 목적은 각 클립에 대한 saliency score를 얻는 것입니다.
Architecture Overview.
앞서 말씀드린대로 본 논문에서 제안하는 TaskWeave 방법론의 핵심은 모델 설계적 관점으로 두 task의 공통점, 차이점, 상호작용을 모델링해주는 것입니다. 아래 그림 2는 TaskWeave의 overall pipeline입니다.
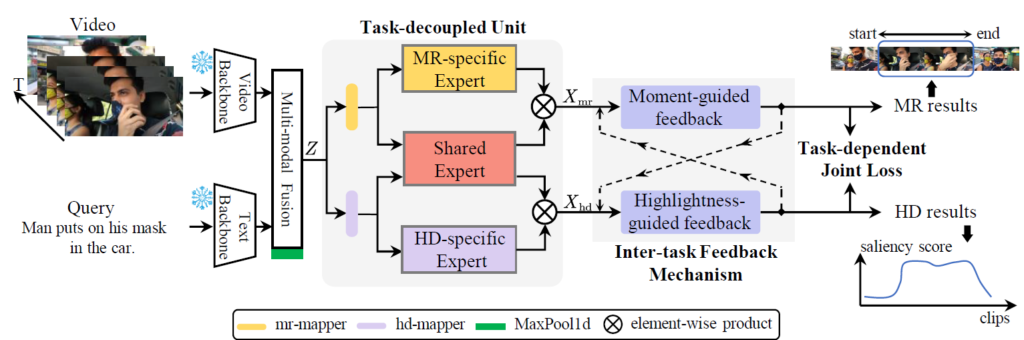
가장 먼저 frozen backbone으로부터 비디오와 텍스트 쿼리에 대한 각각의 feature를 추출합니다. 각 modal의 feature 차원이 서로 다르기 때문에 projection을 통해 둘의 차원을 D로 맞춰줍니다. 기존에는 이후 단계에서 두 모달의 feature를 합쳐주기 위해 기존에는 cross-attention 또는 단순 concat을 진행해주었습니다. 본 방법론에서는 cross-attention을 수행해 query-related video representations Z \in{} \mathbb{R}^{N \times{} D}를 얻습니다.
여기까지는 대부분의 방법론 공통의 feature extraction 방식이며, 이제부터 TaskWeave에서 제안하는 구조가 등장합니다. Z는 Task-decoupled Unit에 입력되어 task-related feature X_{mr} \in{} \mathbb{R}^{N \times{} D}, X_{hd} \in{} \mathbb{R}^{N \times{} D}를 추출합니다. 각각의 feature는 task-specific decoder에 입력되어 inter-task feedback mechanism을 거쳐 MR과 HD의 출력물을 만들어내고 이는 principled task-dependent loss에 의해 최적화됩니다.
이제 Task-decoupled Unit, Inter-task Feedback Mechanism, Task-dependent loss 각각에 대해 알아보겠습니다.
2.2 Task-decoupled Unit
Task-decoupled unit의 설계 목적은 기존의 data-driven 관점과 다르게 task-driven 관점에서 task-related feature (task-speicifc features, common features)를 추출하는 것입니다. 공통점과 차이점을 모델링하는 것이죠. 유닛의 구조는 그림 2에서도 볼 수 있는데, 앞선 단계에서 얻은 Z는 두개의 task-specific mapper인 mr-mapper와 hd-mapper로 입력됩니다. 각 mapper는 단순 FC Layer를 의미합니다. 이후 각 mapper의 output은 task-specific expert network (MR-specific expert 또는 HD-specific expert) 와 Shared Expert network로 입력됩니다.
Network의 forward 흐름 자체는 위와 같이 고정적이지만, 덕분에 해당 network를 어떤 구조로 가져갈 것인지에 대해서는 선택을 할 수 있게 됩니다. 각 expert는 CNN, Transformer, MLP 등등이 될 수 있겠습니다. 여러 구조를 실험해보고 최적의 구성을 가져갈 수 있겠죠.
Task-decoupled Unit의 output은 task-specific feature X_{mr}, X_{hd}입니다. 이 중 X_{mr}을 얻는 과정은 아래 수식 (1)과 같습니다.
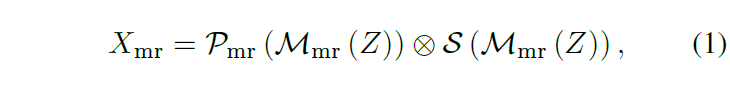
수식을 살펴보면 먼저 Query-related video feature Z를 FC layer에 해당하는 mr-mapper \mathcal{M}_{mr}(\cdot{})에 태워줍니다. 이후에는 Shared expert \mathcal{S}(\cdot{})와 MR-specific expert \mathcal{P}(\cdot{}) 각각에 태워 구조에 맞는 연산(CNN, Transformer, MLP 등)을 진행해줍니다. 이후 각 expert를 타고 나온 feature를 element-wise 곱하여 X_{mr}을 얻습니다. X_{hd}도 HD-specific expert를 활용하면 동일한 과정으로 추출할 수 있습니다.
2.3 Inter-task Feedback Mechanism
두 task간 상호작용을 잡아내기 위해 inter-task feedback mechanism을 제안합니다. 이는 두 개의 task-specific decoder로 구성되어있으며 MR decoder는 Transformer, HD decoder는 CNN으로 구성됩니다. HD의 출력과 MR의 출력은 각각 mask가 되어 MR과 HD 수행에 도움을 줍니다.
Transformer Decoder for MR
MR decoder는 Transformer decoder입니다. 기존 방법론인 QD-DETR과 동일하게 dynamic anchor box를 변형한 dynamic anchor moment query를 줍니다. Moment query 자체가 중심 지점과 너비인 q_{c}, q_{w}로 구성되어있고 Transformer decoder의 출력은 Y_{mr} \in{} \mathbb{R}^{N_{q} \times{} 2}입니다.
Lightweight Decoder for HD
기존 방법론들은 공통의 encoder 출력에 FFN을 태워 saliency score를 얻었습니다. TaskWeave에서는 FFN이 아닌 CNN 구조를 deecoder로 활용합니다. CNN이 local한 detail을 잘 잡아낸다는 특성이 있고 이 점이 비디오 clip 별 saliency score를 만들기 적합하다고 판단한 것입니다. 이는 Linear-Conv1d-Linear로 구성됩니다. HD decoder의 입력은 \mathcal{J} \in{} \mathbb{R}^{N \times{} d}, 출력은 saliency score Y_{hd} \in{} \mathbb{R}^{N \times{} 1}입니다.
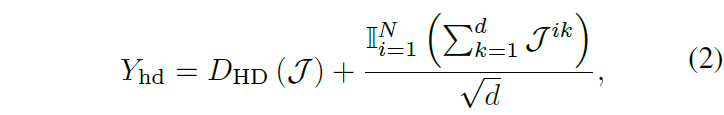
출력 Y_{hd}는 위 수식 (2) 연산을 거쳐 얻을 수 있으며 앞 term은 decoder D_{HD}의 output, 뒤 term은 각 비디오 클립에 대해 차원 축 summation 및 normalization에 해당합니다.
Moment-guided Feedback
이제 MR의 출력을 어떻게 HD 과정에 주입시켜 도움을 주는지 살펴보겠습니다.
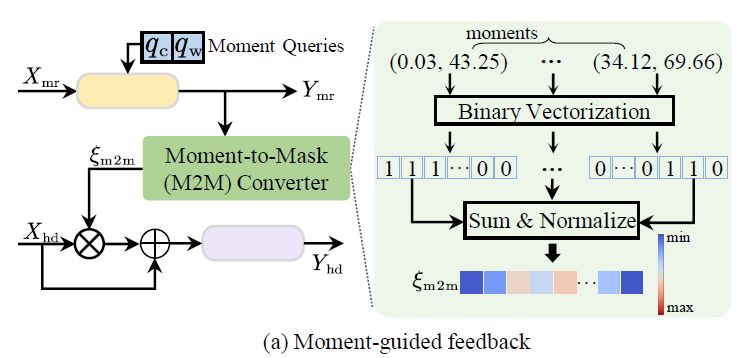
위 그림 3 – (a)가 해당 과정을 나타내며 처음에 얻은 MR 출력인 “(center, width)”를 “(start, end)”로 변환해줍니다. 변환된 구간들은 Moment-to-Mask (M2M) converter (그림에서 초록색 모듈)의 입력으로 들어가고 결국 moment-aware mask \xi{}_{m2m}을 만들어냅니다.
Mask \xi{}_{m2m}을 만들기 위해 먼저 “(start, end)” 형태로 변환된 모든 구간에 대해 GT 값을 활용해 0, 1로 이진화해줍니다. GT 구간에 상응하면 1, 아니면 0이 되겠죠. 이후에 길이 N의 이진화된 모든 벡터를 더한 뒤 L2 normalize해주는 것이 전부입니다.
위 그림에서도 볼 수 있듯 Y_{hd}를 얻는 과정에서, HD Decoder에 태우기 전 \xi{}_{m2m}를 고려해주고 있습니다. MR의 결과물을 HD 수행 시 일종의 attention 값으로 활용하는 것입니다.
Highlightness-guided Feedback
HD의 출력값을 MR에 활용하기 위해 어떤 과정을 거칠까요? 이는 아래 그림 3 – (b)에서 확인해볼 수 있습니다.
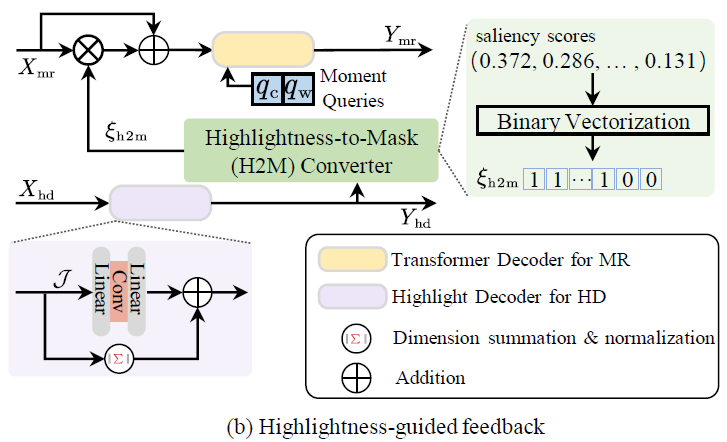
앞선 feedback 과정과 비슷하게 Highlightness-to-Mask (H2M) converter를 활용합니다. \xi{}_{h2m}은 마찬가지로 0 또는 1 값을 갖는 이진 마스크에 해당하는데, saliency score를 평균 값으로 thresholding하여 이진화합니다. 이렇게 얻은 \xi{}_{m2m}는 그림 3 – (b)와 같이 MR decoder를 태우기 전 feature에 곱해집니다.
2.4 Task-dependent Joint Loss
많은 Multi-task learning 방법론들 뿐만 아니라 여러 가지 loss를 사용하는 방법론들도 마찬가지이겠지만, 일반적으로 여러 loss의 balancing weight를 직접 실험해가며 수동으로 조정해줍니다. 하지만 이는 task마다 다른 loss 크기를 유동적으로 고려해주지 못하고, 특정 task가 다른 task에 비해 dominance하게 최적화되는 문제를 일으킬 수 있습니다. 저자는 이러한 점을 개선하기 위해 task-dependent joint loss를 제안하여 효과적이고 유동성 있는 최적화를 진행하고자 합니다.
MR Loss
MR을 수행할 때 구간의 상응 확률을 Gaussian distribution으로 모델링합니다. 분포의 평균은 neural network의 출력 f^{\theta{}_{mr}}(x)가 됩니다. 분포의 분산이자 uncertainty 값인 \delta{}_{mr}은 learnable parameter입니다.
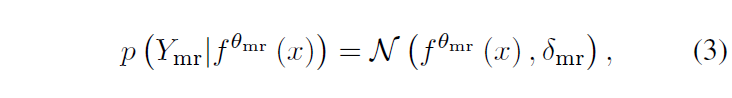
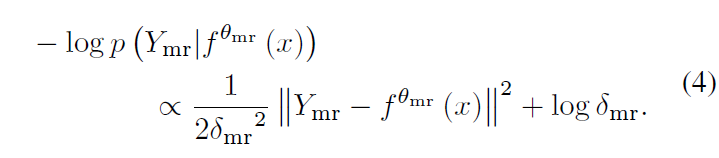
수식 (3)과 같이 Gaussian distribution을 구축하였다면 이후에는 수식 (4)와 같이 Negative Log-likelihood를 적을 수 있습니다. 수식 (4)에서 ||Y_{mr} - f^{\theta{}_{mr}}(x)||^{2}는 GT와 예측 중심 구간과의 offset을 의미합니다.
수식 (4)로부터 아래 수식 (5)와 같이 Moment Retrieval loss \mathcal{L}_{mr}을 도출할 수 있습니다.
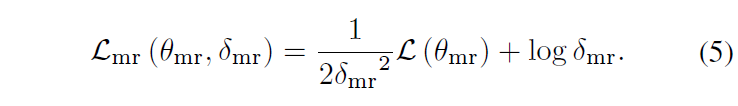
기본적으로 \mathcal{L}_{mr}은 기존 방법론들과 동일하게 구간에 대한 L1 loss, fgd-bgd를 분류하는 BCE loss, 구간에 대한 temporal gIoU loss로 구성됩니다. 앞의 term은 현재 샘플의 uncertainty가 클수록 각 loss의 영향력을 줄이면서 뒤 term에서 uncertainty를 줄이도록 만들어줍니다. 다만 여기서 특정 sample에 대한 uncertainty를 정량화하는 것이 아니라 learnable parameter를 사용하고 있는데, 정확히 learnable parameter가 해당 역할을 해주는지는 의문이 들긴 합니다.
HD Loss
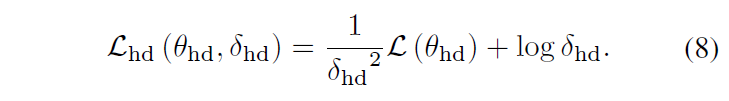
HD에 대해서도 MR과 동일하게 수식 (8)을 도출할 수 있습니다. TaskWeave에서 사용하는 \mathcal{L}_{hd}도 기존 방법론들과 동일하게 Saliency score에 대한 hinge loss와 QD-DETR에서 사용한 negative pair loss, rank-aware contrastive loss로 구성됩니다.
최종적인 joint loss \mathcal{L}_{joint}는 아래 수식 (9)와 같이 두 loss의 합으로 구성됩니다. Task-specific한 모듈들을 앞서 계속 제안했기 때문에 loss에 대해서도 task 서로 간의 출력을 명시적으로 활용해주나 기대하였는데, 실질적으로는 learnable parameter \delta{}_{mr}, \delta{}_{mr}를 uncertainty로 삼아 학습에 기대어 각 task 별 loss balancing weight를 조절해주고 있는 모습입니다.
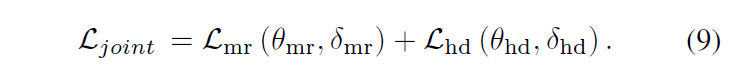
3. Experiments
3.1 Experimental Setup
벤치마킹을 위한 데이터셋으로 QVHighlights, TVSum, Charades-STA를 사용합니다. QVHighlights는 MR과 HD을 동시에 평가 가능한 유일한 데이터셋이고, TVSum은 HD, Charades-STA는 MR 평가에 사용됩니다.
3.2 Comparison with State-of-the-arts
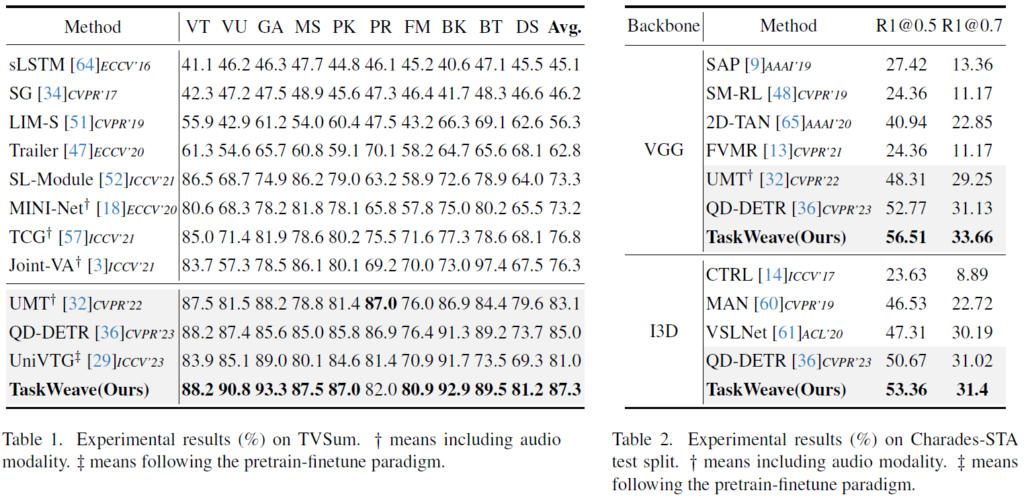
표 1, 2는 각각 TVSum, Charades-STA 데이터셋에 대한 벤치마크 성능입니다. 우선 표 1에서 아래 회색으로 어둡게 칠해진 모델들은 모두 MR&HD 또는 그 이외의 task까지 동시에 수행하는 multi-task 방법론들입니다. TVSum 데이터셋에 대해서는 10개의 클래스 중 9개에 대해 SOTA를 달성하고 있으며 평균 관점에서는 기존 방법론과 큰 차이로 SOTA를 달성하고 있는 모습을 볼 수 있습니다. Charades-STA 데이터셋에 대해서는 동일하게 MR&HD를 수행하는 QD-DETR보다 두 feature 모두에 대해서 큰 차이로 성능을 올린 것을 볼 수 있습니다.
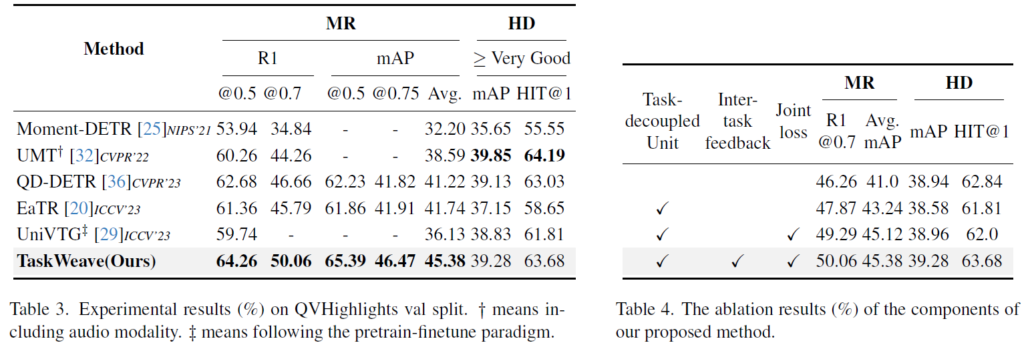
표 3은 QVHighlights 데이터셋에 대한 벤치마크 성능 표입니다. 베이스라인 방법론인 Moment-DETR 직후에 등장한 후속 연구 EaTR, QD-DETR에 비해 큰 성능 향상을 보여주고 있고, 비슷한 시기에 등장한 EaTR과 QD-DETR의 후속 연구들과 비슷한 성능 향상 폭을 보여주고 있습니다. HD에 대해서는 UMT 방법론보다 조금 모자른 성능을 보여주는데, UMT는 오디오 모달리티를 추가로 사용한 방법론이라 직접 비교하기엔 무리가 있습니다. 항상 이러한 성능을 볼 때마다 왜 MR의 성능 향상 폭과 HD의 성능 향상 폭이 방법론마다 다른지 궁금합니다. 이 부분은 저도 직접 실험을 여러번 돌려봐야 알 수 있거나 이를 분석한 논문이 있어야만 알아볼 수 있을 것 같습니다.. 아무튼 저자가 제안한 TaskWeave가 세 가지 벤치마크 데이터셋 모두에서 가장 높은 성능을 보여주고 있습니다.
3.3 Ablation Studies and Discussions
Ablation of components
위 표 4에서 모듈 별 ablation 성능을 확인할 수 있습니다. 총 3개의 모듈을 제안하였고 각각을 붙일 때마다 성능이 조금씩 올라가는 것을 볼 수 있습니다. 저자도 별다른 분석을 내놓고 있지는 않네요. 개인적으로 Inter-task feedback의 성능 향상치를 보고 싶었는데, Task-decoupled unit과 joint loss를 적용하지 않고도 inter-task feedback 모듈을 붙일 수 있었을 것 같음에도 불구하고 성능을 따로 리포팅하고 있진 않습니다.
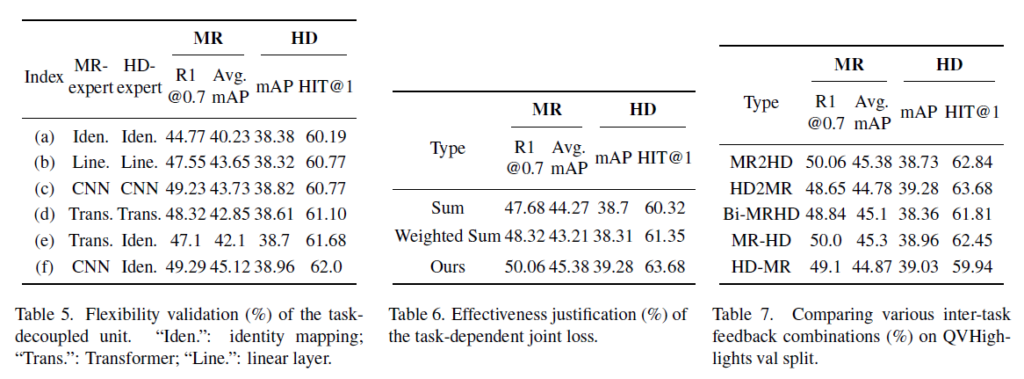
Flexibility of the task-decoupled unit.
표 5는 Task-decoupled unit 내 task-specific expert의 연산 종류에 따른 성능입니다. 유닛 내 Shared expert는 2-layer Transformer로 고정한 채 나머지 expert들의 연산 종류를 비교하고 있는 것입니다. 표 1에서 Iden.은 identity mapping, Line.은 Linear layer, Trans.는 Transformer를 의미합니다.
표 5의 (a)를 통해 두 expert 모두 identity mapping을 해주는 경우 성능이 best일 때보다 많이 떨어지는 것을 볼 수 있습니다. 또한 Transformer를 통해 성능이 (a)보다 많이 오른 것은 맞지만 타 조합에 비해 높은 성능을 보여주고 있지는 않습니다. 저자는 이에 대해 연산 복잡성이 높아 성능 하락이 발생했다고 주장합니다. (c)와 (f)를 함께 살펴보았을 때, MR의 성능이 전반적으로 높은 것을 볼 수 있습니다. CNN이 Local detail을 잘 잡아낸다는 특성이 상응 구간을 detail하게 잘 찾아내야 한다는 MR task 특성과 잘 맞아떨어지는 것을 볼 수 있습니다. 또한 ((c), (f))와 ((d), (e))를 각각 살펴보았을 때, 한 task의 연산 변화에 따라 성능이 내려가면 다른 task의 성능도 함께 내려가는 것을 볼 수 있습니다. 이를 통해 두 task가 joint하게 서로 잘 학습되고 있음을 반증할 수도 있다 생각이 듭니다.
Task-dependent joint loss
표 6은 저자가 제안한 joint task-dependent loss에 대한 ablation 실험입니다. 모듈 내부적으로 ablation을 수행한 것은 아니고, 단순히 MR과 HD 두 loss를 sum 했을 때, weighted sum 했을 때와의 성능을 비교하고 있습니다. 제안하는 uncertainty 기반의 joint task-dependent loss가 큰 차이로 높은 성능을 보이고 있습니다.
Inter-task interactions
TaskWeave의 main contribution은 task 간 feedback 모듈이겠죠. 이에 대해 저자는 feedback 방식을 어떻게 하는 것이 가장 효과적인지 실험하였습니다. 표 7에서 MR2HD는 MR->HD만 수행, HD2MR은 HD->MR만 수행, Bi-MRHD는 동시에 MR<->HD 수행, MR-HD는 MR->HD 후 HD->MR 수행, HD-MR은 HD->MR 후 MR->HD 수행을 의미합니다.
기본적으로 모든 방식에서 베이스라인보다는 높은 성능을 기록하고 있습니다. 그럼에도 표에서 HD2MR이 살짝 낮은 성능을 보여주고 있는데, 이는 GT 분포에서도 알 수 있듯 HD가 MR보다 좀 더 세세하고 높은 수준의 score까지 만들어내야 하기 때문에, HD가 어떠한 도움을 받지 못한다면 MR까지도 제대로 성능이 나오지 못하기 때문이라고 볼 수 있습니다. 해당 경향성은 MR-HD, HD-MR의 성능을 비교했을때도 확인할 수 있습니다.
4. Conclusion
지난번에 리뷰하였던 TR-DETR에 이어 비디오 도메인의 모델링에 치중하기보단 두 task간의 특성을 성능 향상에 활용하는 방법론 TaskWeave에 대해 알아보았습니다. 최근 DETR 기반의 joint MR&HD 방법론들을 쭉 follow-up 하다보니 결국은 Transformer encoder-decoder에 입력되는 feature를 어떻게 모델링할 것인가가 주요 관심사인 것 같고, 일부 TR-DETR이나 TaskWeave 같은 방법론에서 고정적인 DETR 구조를 깨려는 듯한 시도를 보여주는 것 같습니다.
이를 바탕으로 제가 하려는 연구의 방향성은 어떻게 잡아야할지 조금 더 고민해보아야 할 것 같습니다.
감사합니다.
리뷰 잘 읽었습니다.
점점 기술 레벨이 성숙해지고 있어서 그런건지는 모르겠지만 테크닉이 상당한 거 같습니다. 다음 논문을 쓸 수 있을지가 걱정이 되네요. (논문 작성을 위해 필요한 잡기술이 상당할 거 같다는 느낌)
제가 지난번에 읽었던 EaTR 논문에서는 MR Loss로 그냥 L1 Loss나 IoU Loss를 썼던걸로 기억하는데 해당 논문은 가우시안 분포의 최대 우도를 추정하는 방식으로 구하는 거 같습니다.
해당 테크닉은 본 저자의 contribution인가요 아니면 MR 분야에서 많이 활용하는 선택지 중 하나 인가요?
감사합니다.
안녕하세요 질문 감사합니다.
1. 아무래도 베이스라인 방법론인 Moment-DETR의 코드부터 잡기술이 들어가있어 점점 그게 고도화되는 분위기인 것 같습니다.. 두렵네요
2. EaTR을 포함한 대부분의 방법론이 말씀해주신대로 loss를 건드리지는 않았습니다. 그렇다고 해당 방식이 완전히 새로운 수식이라고는 또 볼 수 없기에, 타 task들에서 널리 적용되던 테크닉을 컨셉에 맞게 녹여 적용한 느낌이라고 보시면 될 것 같습니다.