안녕하세요! 조현석연구원 입니다. 오늘 소개시켜드릴 논문은 신입 교육기간 동안 다룬 Self-Supervised Monocular Depth Estimation Task의 마지막 일정인 TransDSSL입니다. 본 논문은 RAL 2022년에 게재된 것으로 저희 sejong RCV 출신이신 한대찬 연구원님, 신정민 연구원님 등이 저자로 있는 논문입니다.
간략한 소개를 드리자면, 그때 당시 새로운 backbone으로 나왔던 ViT를 기존 테스크에 적용하는 연구가 이어지고 있었는데요. 마찬가지로 ViT를 supervised 방식으로 Depth Estimation Task에 적용한 방법들이 연구되었고, long-range spatial dependency를 모델링할 수 있는 능력으로 좋은 결과를 얻었다고 합니다.
그러나 ViT를 Self supervised depth estimation task에 적용하였더니, 예상한 성능 향상 폭보다 많이 미치지 못하는 결과를 얻게 되었다고 합니다. 해서 저자들은 크게 아래의 두 가지로 문제를 정의하였는데요
- problematic multi-scale photometric loss function when using transformer
- self-attension연산의 local detail 모델링 능력의 부재
특히 2번째 문제를 해결하고자 attention based decoder module인 “Pixel-Wise Skip Attention(PWSA)”를 설계하였습니다. 해당 모듈을 사용함으로 2번 문제인 fine detail의 부족 현상을 완화하면서도 global context를 모델링 할 수 있는 능력을 부여하였습니다. 그리고 1번 문제를 해결하기 위한 self-distillation loss와 single scale phtometric loss를 사용하여 학습의 안정성을 강화하였다고 합니다.
해당 논문은 Self-Supervised Monocular Depth Estimation Task에 Vision Transformer를 적용한 논문으로 앞서 리뷰한 monoViT와는 어떻게 보면 유사한 컨트리뷰션을 주장하는 측면이 있습니다. 그러나 단순히 새로운 backbone을 적용했다는 것에서 끝나는게 아니라, ViT를 적용함으로 생긴 문제들에 가설을 정의하고 그것들을 해결하여 원활히 Supervised Monocular Depth Estimation Task에 ViT를 적용할 수 있게 만들었다는 부분에서 더 큰 의미를 지니는 논문이라고 생각합니다. 그럼 X-Riew시작하겠습니다!
1. Introduction
1.1. self-supervised monocular depth-estimation Review
기존의 self-supervised monocular depth-estimation테스크에 대한 배경지식을 간단히 리뷰하겠습니다. depth estimation 테스크는 3D scene을 이미지로 투영시키는 과정에서 소실된 depth정보를 모델로 하여금 예측하도록 하는 테스크입니다. 이걸 단안(monocular)카메라로 촬영한 비디오 데이터를 사용하여 진행하는 것이 monocular depth-estimation이 되겠습니다.
초기 연구는 supervised learning방식으로 진행이 되었는데요. labeled 데이터셋 구축의 어려움. 일반화 성능저하 등의 이유로 self-supervised learning(SSL)방식으로의 연구의 흐름이 바뀌게 됩니다.
깊이 추정을 SSL의 방식으로 진행하기 위한 pretext-task로 “target image reconstruction”테스크를 수행합니다. “target image reconstruction”은 단순히 인접 카메라 프레임(-1, +1)을 통해서 현재 시점(0)의 프레임(타겟프레임)을 reconstruction하는 테스크입니다. 이것 위해서 depth정보와 인접 프레임과 타겟프레임 간의 상대적인 pose를 필요로 하는데요. 그래서 연구자들은 depth를 예측하는 depth network와 pose를 예측하는 pose network, 두 종류의 네트워크를 구성합니다
depth network가 예측한 depth정보와 pose network가 예측한 두 프레인 간의 relative 6D pose정보를 통해서 타겟 프레임을 인접 프레임으로의 warpping을 구현합니다. 그리고 인접프레임에 와핑된 타겟프레임의 관계를 이용하여 bilinear sampler를 통해 인접프레임을 샘플링하여 합성 타겟프레임을 생성하게 됩니다.
그런 다음 합성 타겟프레임과 실제 타겟프레임 간의 Photometric-Error를 계산하여 SSL을 위한 supervision을 줍니다. 본 논문도 위위의 파이프라인을 통해서 학습이 진행됩니다. 그리고 inference시에는 원하는 depth정보를 얻기 위해서 depth network만 사용하는데요. 한 장의 이미지를 학습된 depth network에 넣어서 해당 이미지의 depth를 얻습니다.
다음은 기존의 self-supervised depth estimation을 위한 목적함수들에 대한 간략한 소개입니다. 본 테스크의 Loss는 크게 두 가지로 구성됩니다. 바로 수식(6)에 해당하는 “Photometric Loss”와 식(7)에 해당하는 “Smoothness Loss”입니다.
(5)번 수식은 실제 타겟이미지\mathcal{I}와 합성된 타겟이미지\mathcal{\tilde{I}}가 얼마나 유사한 지를 바탕으로 합성이미지가 타겟이미지를 닮아가는 방향으로 학습이 진행되도록 설계한 Loss입니다. Structural Similarity를 반영한 SSIM의 텀과 intensity difference를 고려한 |.| 연산인 L1 difference 텀으로 구성됩니다.
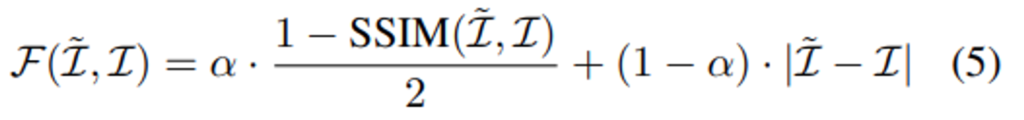
수식(6)이 실제 “Photometric Loss”에 해당하는 데요. 해당 loss는 (5)번 수식에 min을 취한 꼴입니다. 두 인접프레임(1, -1)중에 작은 \mathcal{F(\mathcal{I},\mathcal{I})}를 가져가는 것인데요. 이렇게 함으로서 occlusion되어 Loss연산에 방해가 되는 픽셀을 연산에서 제외하기 위한 의도입니다. 자세한 설명은 Monodepth2논문을 참고해주시면 감사하겠습니다.
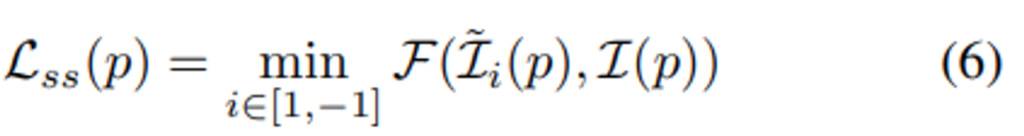
아래 수식(7)은 “Smoothness Loss”에 해당하는 데요. 해당 Loss는 depth map과 타겟이미지의 gradient를 고려하여 depth가 너무 튀지 않게 패널티를 준 텀이라고 생각해주시면 됩니다.
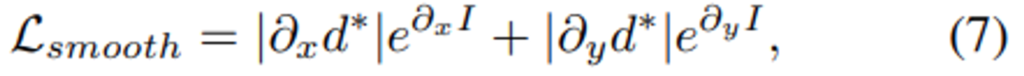
마지막으로 수식(6)과 (7)을 종합하여 수식(8)의 Total Loss를 정의합니다. 여기서 s는 Figure 3.을 확인하시면, 총 4개의 다른 scale로 아웃풋을 뽑는데 그것들을 평균내주기 위함입니다.
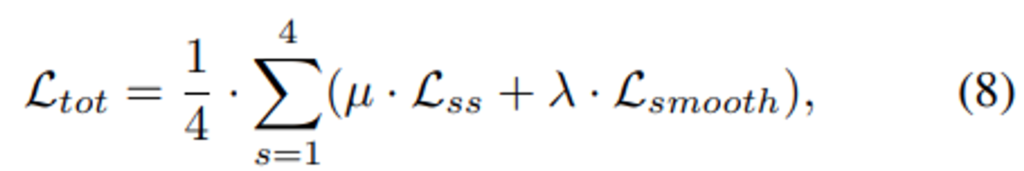
최종적으로 수식 (8)을 통해서 SSL의 supervision을 주게 됩니다.
여기서 본 논문과 밀접한 연관이 있는 부분이 수식(6)과 (8)입니다. 수식(6)의 photometric loss를 결국에 (8)에서 4개의 서로 다른 해상도의 disparity 예측에 대하여 sum을 때려서 total loss를 산출하는데요. 이것을 multi-scale을 고려한 Loss라고 부릅니다. 그리고 특별히 본 논문에서 수식(6)을 multi-scale로 고려한 것을 multi-scale photometric loss라고 부릅니다.
1.2. Motivation
이어서, 아래는 저자들이 문제를 정의하고 해결책을 제시하는 과정을 간략하게 정리하였습니다.
먼저 CNN대신에 ViT를 적용함으로서 생기는 feature enginnering 관점에서 발견한 문제점입니다. CNN의 근본적인 문제는 long-range spatial relationship을 고려하지 못하고 특징을 추출한다는 점인데요, 그것을 완화하고자 어떻게든 receptive field를 키워서 더 많은 부분을 보려는 노력들이 있었습니다. 예를 들어서 dilation conv, deformable conv, attention mechanism, aggregating multi-scale features 등이 있겠네요. 그래도 conv를 사용한다는 것 자체가 locality of convolution operation이라는 근본적인 문제가 내재되어 있기 때문에 이런 문제의 해결책으로 제시된 것이 NLP분야에서 long-range dependency를 모델링하기 위해서 제안되었던 Transformer였다고 합니다. 그러나 transformer의 연산방식으로는 local details을 모델링할 수 없었고, 그 결과로 pixel-level의 inference를 수행하는 task에 있어서 좋지 못한 예측을 수행하는 경향이 있었다고 합니다.
이러한 결과들을 토대로 저자는 Pixel-Wise Skip Attention(PWSA) module을 설계하여 global context와 local detail을 모두 모델링 하고자 하였습니다.
또한 ViT를 self-supervised monocular depth estimation을 위해서 학습하는 과정에서 기존의 multi-scale photometric loss가 noisy signal을 제공하는 것을 확인하였고 그로 인한 optimization 문제가 발생하였다고 합니다. self-distillation loss로 기존의 mult-scale photometric loss를 대체하여 올바른 학습 시그널을 줄 수 있는 방식으로 바꾸었고, 또한 가장 해상도가 높은 예측에 대해서만 기존의 Photometric loss를 적용하여 부가적인 시그널을 제공하였다고 합니다. self-distillation loss에 대해서 부가적인 설명을 하자면, 가장 고해상도의 disparity예측을 중간해상도의 disparity예측을 위한 슈도라벨로 하여 supervision을 주는 것인데요. 해당 loss를 추가함으로서 중간 scale의 예측의 표현력이 더 좋아지고 학습의 안정성이 생겼다고 합니다. 이를 위해서, detachable module구조로 extra-decoder를 설계하여 학습 시에 fine details을 위한 pseudo label을 생성하게 하였다고 합니다. 또한 학습초반에 나타나는 부정확한 슈도라벨로 인한 error가 전파되는 것을 최소화하기 위해서 multi-scaleself-distillation loss에“adaptive weighting”을 추가했다고 합니다. 자세한 내용은 3.Proposed Method에서 소개하도록 하겠습니다.
3. Proposed Method
저자들은 기존의 이미지 데이터에 효율적인 hierarchical구조와 shifted windowing scheme을 사용하는 “Swin Transformer” 를 인코더로 채택하였습니다. 또한 spatial detail을 모델링하기 위해서 기존에 연구되었던 이미지 단에서 attention을 넣는 방식(CBAM모듈, SE모듈 등)의 방법론을 사용하였습니다. 기존의 depth estimation task에서 사용하는 인코더-디코더 구조를 동일하게 따라가는 것 또한 확인 할 수 있습니다.
3.1. proposed architecture
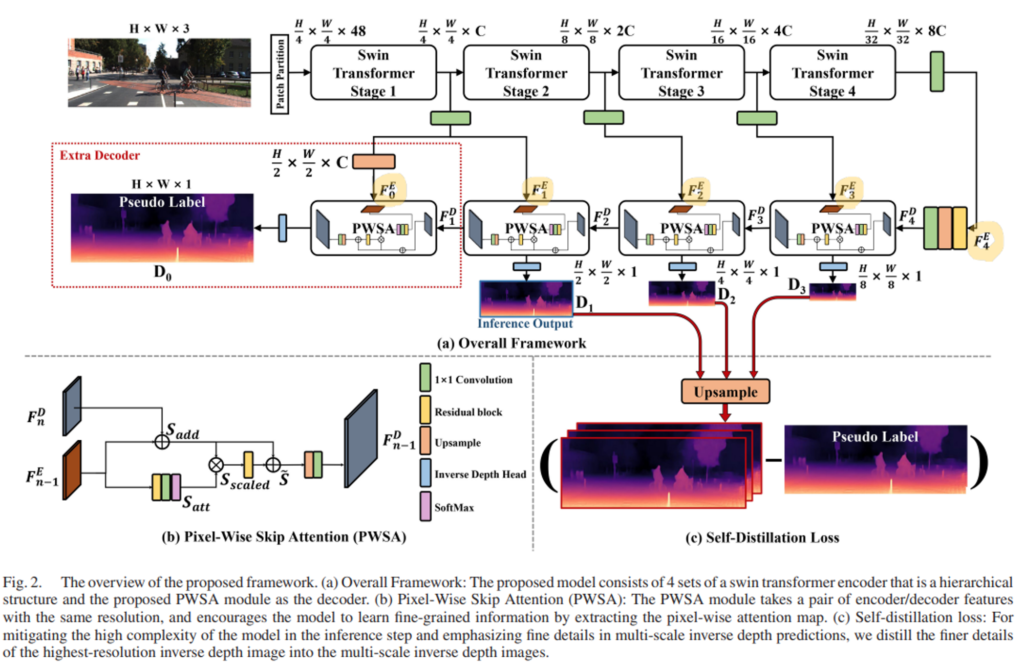
3.1.1. Depth Network Encoder
저자들은 global context와 local context(detail)을 효과적으로 모델링할 수 있는 아키텍쳐를 고안하였는데요. 먼저 global context를 위해서 Swin Transformer를 backbone encoder로 사용하였는데요. swin transformer는 효율적인 window based SA연산과 hierarchical feature map을 통한 다양한 스케일의 visual entity에 대한 학습을 가능하게 한 구조입니다.
CNN과 유사하게 각각의 feature map들이 spatial axis에 대해서 2배씩 다운 셈플링이 되기 때문에, 그러한 특징이 CNN backbone을 대체하여 Swin이 쓰일 수 있었던 이유 중 하나라고 합니다.
3.1.2. Depth Network Decoder
디코더의 구조를 보시면 PWSA 모듈이 주를 이루고 있습니다. 해당 모듈은 앞서 언급한 것처럼 기존 Swin을 통한 global context에 local details들을 추가해주는 역할을 합니다.
PWSA모듈은 Fig. 2(b)를 보시면 그 구조를 확인할 수 있습니다. 먼저 해당 모듈은 두 갈래로 나뉘는데요. 위쪽 갈래가 “long skip connection”을 아래 쪽 갈래가 “pixel wise attention”을 수행합니다.
먼저 위쪽 갈래를 보시면, 이전 디코딩 노드의 아웃풋(F^{D}_{n})과 인코더의 skip-connection(F^{E}_{n-1})을 element-wise summation하여, long skip connection이 적용된 특징 S_{add}를 만듭니다.
그리고 그 아래 갈래를 보시면 F^{E}_{n-1}를 Residual block, 1×1 conv, Softmax를 태워서 “pixel-wise spatial attention map”인 S_{att}를 만들어주는데요.
S_{att}는 S_{add}의 spatial축에 대한 attention weight로 사용됩니다. 이후에 S_{add}와 pixel-wise multiplication을 통하여 spatial-wise attention이 적용된 특징 S_{scaled}를 만듭니다. S_{scaled}는 spatial축에 중요한 feature를 강화하고 그렇지 못한 특징을 약화 시키도록 가중치가 매겨진 feature가 되겠습니다.

각각의 과정에 대한 수식은 위의 (2)와 같습니다. 그리고 식(3)을 보시면, 학습 초반에 S_{scaled}가 overly emphasized 되거나 ignored되는 것을 방지하기 위해서 resblock을 이후에 한번 더 적용해주었다고 합니다. 그리고S_{add}와 더하여 \tilde{S}를 만들어줍니다. 그렇게 만들어진 \tilde{S}를 upsampling을 하고 1×1 conv를 태워서 해당 노드의 아웃풋으로 냅니다.
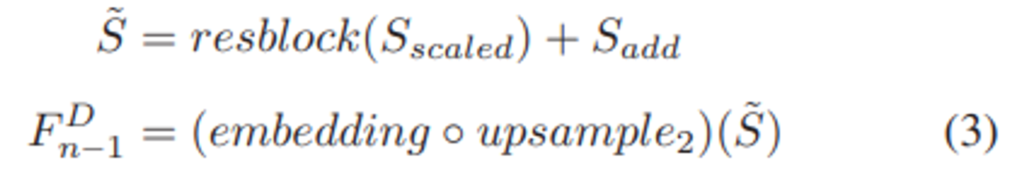
아래 Fig. 3은 PWSA module 적용한 것과 그렇지 않은 것에 대한 feature map 시각화자료입니다.

PWSA module을 적용을 한 feature map에 대해서 자글자글한 디테일적인 부분들도 모델링이 되었고, 전경과 배경에 대한 boundary도 뚜렷하게 구분 되는 것을 확인 할 수 있습니다. 이것으로 저자들이 제시한 PWSA 모듈이 이미지에서 디테일적인 부분을 더해주는 역할을 한다는 것을 확인 할 수 있습니다.
3.2. Proposed Loss
기존에 Photometric loss는 완벽하게 Depth Network를 학습 시킬 수 없었는데요. 바로 textureless/occluded region에 대한 부분과 움직이는 물체에 해당하는 픽셀들에 대해서 잘못된 supervision을 받기 때문입니다. 또한 낮은 해상도의 예측이 갖는 디테일적인 표현력이 부족하다는 문제점을 통해서 잘못된 학습시그널이 가는 것을 문제점이 있었는데요. 이를 방지하고자, 가장 해상도가 높은 disparity map(D_{0})에서만 photometric loss를 계산하는 single-scale photometric loss를 사용하였다고 합니다.
이와 더불어 저자들은 낮은 해상도를 갖고 있어 표현력이 부족하다는 근본적인 문제점을 갖는 중간 feature map(F^{D}_{n}, F^{E}_{n})에 대해서 표현력을 완화하고자 하였습니다. 이에 가장 높은 resolution의 disparity map에 대해서 self-distillation loss를 적용하였는데요. 저자들은 가장 높은 해상도의 disparity map에서 가장 좋은 예측을 낼 것이라고 가정하였고, 그 가장 좋은 disparity map의 fine detail을 예측하는 능력을 이후 단계의 feature map에 전의하고 싶었다고 합니다.
해서 Figure 2.(c)와 같이 가장 좋은 disparity map(D_{0})를 슈도라벨로하여 나머지(D_{1},D_{2},D_{3})를 비교하는 loss를 설계하였습니다.
사실은 앞에서 multi-scale loss를 사용하지 않고, single-scale loss 즉, 가장 고해상도 예측에 대해서만 photometric loss를 계산하도록 하므로서 중간 단계의 feature map을 학습시킬 supervision이 없었고 이것을 제공하기 위해서 고안하였다고 실험파트에서 언급하기도 합니다. (맨 마지막 해상도에서만 loss를 계산하면 앞 단을 학습 시킬 에러역전파가 존재하지 않게 되는 문제점)
최종적으로 기존에 사용하였던 multi-scale photometric loss를 single-scale photometric loss와 self-distillation loss의 합으로 대체하였다고 합니다.
3.2.1. Self-Distillation Loss(\mathcal{L}_{sd})
Figure 2.(c)를 참고하시며 해당 설명을 읽어주시면 감사하겠습니다. 먼저 아래 수식의 과정을 거치는 데요.
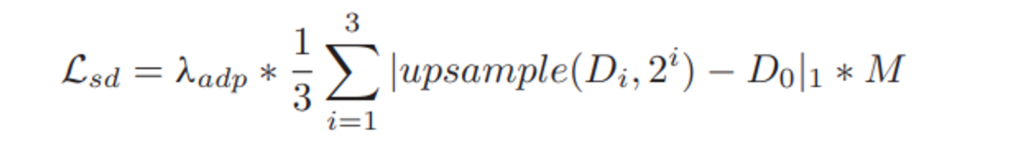
pseudo label인 가장 해상도가 높은 disparity예측(D_{0})과 나머지(D_{1},D_{2},D_{3})를 비교하기 위하여 중간 단의 disparity 예측(D_{1},D_{2},D_{3})을 upsampling하여 D_{0}와 동일한 해상도로 만들어줍니다.(upsample(.)과정), 2^{i}이 붙은 이유는 i가 커짐에 따라서 해상도가 2배씩 작아지기 때문입니다.
이렇게 슈도라벨의 해상도를 나머지 해상도에 맞춰서 줄이는 방향이 아니라, 나머지를 upsampling하여 슈도라벨(D_{0})의 해상도로 만듦으로서 슈도라벨의 fine details을 지킬 수 있다고 합니다.
그리고 아래 수식처럼 pseudo label(D_{0})과 중간 단의 disparity prediction(D_{1},D_{2},D_{3}) 사이의 L1 loss를 구합니다.( |.|연산 )
이때, auto-masking(M)을 적용합니다. 또한 이른 학습 단계에서 부정확한 슈도라벨로 인해 생길 수 있는 에러 전파를 막기 위해서 \lambda_{adp}을 두어서 특정 에포크 이하일 때는 self-distillation loss에 반영하는 가중치를 줄이는 방식으로 규제를 가합니다.
아래 수식(4)는 (\lambda_{adp})가 정의되는 조건을 나타냅니다.

여기서 (epoch_{thr})는 10으로 설정합니다.
4. Experiments
4.1. Evaluation Metrics
기존의 다른 self-supervised monodepth estimation task에서 사용하였던 아래의 평가Metrics를 그대로 사용하였습니다.

간단한 설명을 드리면, Accuracy under threshold는 예측\hat{d_{p}}과 G.T인 d_{p}간의 두 비율 중 큰 것을 선택하여, 특정 threshold(\delta_{1}=1.25, \delta_{2}=1.25^{2}, \delta_{3}=1.25^{3}) 이하이면 TP로 판단을 하는데요. 그리고, TP/total_samples 연산을 하여 Recall을 구해주고, 이것 accuracy성능으로 생각을 하는 지표입니다. 따라서 높을 수록 좋은 성능을 나타냅니다. Accuracy under threshold를 제외한 4종류의 평가지표들은 pred와 G.T.가 수치적으로 얼마나 유사한 지 평가하는 것으로 작을 수록 더 좋은 성능을 나타냅니다.
4.2. 성능실험
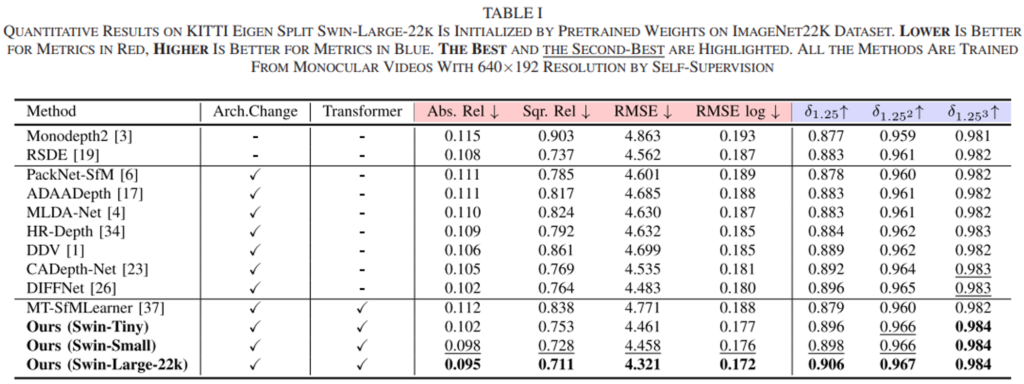
아래의 table 1은 기존의 SoTA 모델들과의 비교입니다. 또한 MT-SfMLearner라는 transformer기반의 이전 방법론을 높은 수치로 능가하는 것을 보여줍니다.
또한 저자들은 DDAD라는 다양한 시나리오의 주행데이터셋을 기반으로 추가적인 평가를 진행하였습니다. 그것에 대한 reporting은 아래 Table 2에 정리되어있습니다.
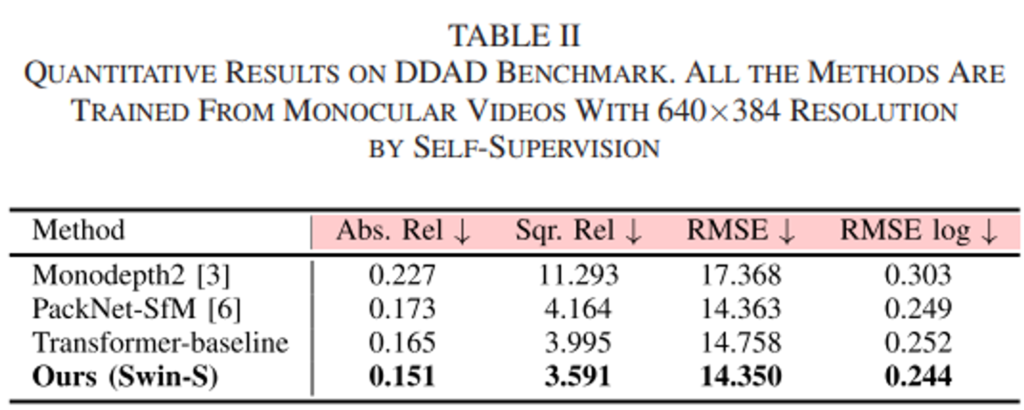
보시는 것처럼 해당 데이터셋에서도 가장 좋은 성능을 보임을 입증하였습니다. 특히 CNN기반의 방법론인 PackNet-SfM을 12.7%정도의 성능차이로 크게 앞서는 것을 볼 수 있습니다. 아래 Figure 4. 는 각 모델들의 예측한 깊이에 따른 RMSE를 구한 것인데요. 그림과 같이 40~60m에 해당하는 range를 제외하고는 기존의 모델보다 낮은 예측 에러를 보여줍니다.
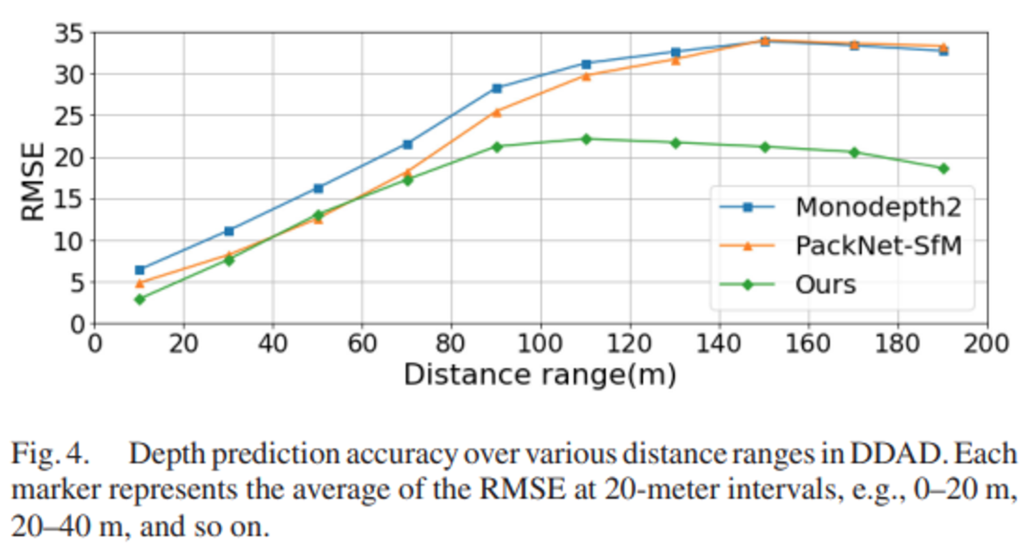
특히나 100m이상이 되는 먼 region에 대한 예측에서 다른 모델들보다 월등히 낮은 RMSE를 보여주는 데요. 이는 100m이상의 먼 region에 대한 예측은 기존의 두 모델처럼 local context만을 고려하는 것으로는 예측이 불가능함을 보여줍니다 또한 본 모델처럼 ViT를 사용하여 global context를 모델링하는 것이 정말로 효과가 있다는 것을 입증하는 것이고, 저자들이 제안한 transDSSL이 이를 잘 해내고 있는 것을 보여줍니다.
4.3 Ablation Study
아래 table 3.은 저자들이 진행한 ablation study에 대한 것인데요.
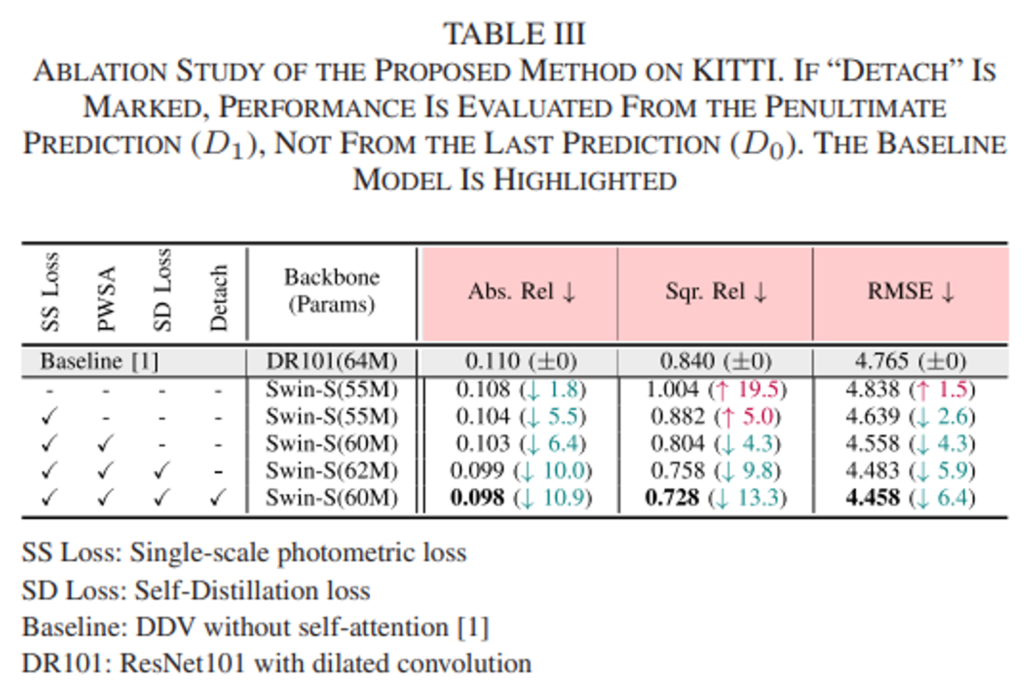
저자는 총 5종류의 실험을 진행하였는데요. 각각에 대하여 설명드리겠습니다.
실험(1) CNN인코더에서 Transformer기반 인코더로 대체의 효용성 분석
먼저 2nd row에 보이는 Baseline은 기존의 CNN 인코더를 사용한 모델인데요. 그리고 3rd row는 naive한 방식으로 인코더를 Swin-Transformer로 대체한 것이라고 합니다.(저자가 제안하는 다른 방법론들은 사용하지 않고, 단순히 vanila SwinTransformer를 사용)
ViT를 통해 global context를 모델링하여 기존의 CNN기반의 모델보다 성능이 좋을 것으로 예상이 되었지만, 예상과 다르게 성능을 보시면 AbsRel에서만 약간의 성능 향상을 보이고 나머지 평가지표에서는 오히려 떨어진 것을 확인 할 수 있습니다.
해당 원인에 대하여 저자들은 아래의 2가지 분석을 제공합니다. 1) local details을 검출할 수 없는 부적절한 디코더 모듈 사용, 2)multi-scale 방식의 photometric loss를 사용함으로서 약한 supervision을 주었다는 것이 그것입니다. 이는 인코더를 ViT기반으로 무턱대고 바꾸면, 이처럼 예상했던 결과가 나오지 않는다는 것을 입증하였고, 위 두 가지 문제점을 저자들이 제안하는 loss와 모듈로 변경하여 해결하는 것을 보여 그들의 방법론의 우수성을 부각 시켜주네요. (앞으로 나올 실험들 입니다!)
실험(2) Multi-scale loss vs single-scale loss
앞서 언급드렸듯, 2)multi-scale 방식의 photometric loss를 사용함으로서 약한 supervision을 주었다는 문제점을 해결하기 위해서 저자는 single-scale loss(SS Loss)를 제안하였는데요. 그것을 적용한 4th row와 multi-scale방식을 적용한 3rd row의 모델을 비교함으로서 SS Loss의 효용성을 보이고있습니다. 실제로 성능이 꽤 많이 좋아진 것을 확인 할 수 있습니다.
실험(3) Effect of PWSA decoder
1) local details을 검출할 수 없는 부적절한 디코더 모듈 사용이 성능 하락을 야기하였다고 저자들은 분석하였고, 이것을 해결하기 위한 PWSA디코더를 사용한 모델과 그렇지 않은 모델을 비교하고 있습니다. 4th row의 모델과 5th row의 모델을 비교함으로서 저자들이 제시한 분석이 맞다는 것을 정량적으로 입증하고 있습니다.
Sqr. Rel측면에서 0.882 → 0.804로 8.8%의 큰 폭의 향상을 보여줍니다. 이렇게 큰 폭의 향상을 통해서 어떠한 high-error prediction에 대한 근본적인 개선이 있었다고 해석할 수 있는데요. 저자들은 이 부분이 바로 PWSA를 사용하여 local context를 고려할 수 있게 되었기에 발생하였다고 주장합니다.
실험(4),(5) Advantage of Self-Distillation Loss
5th row와 6th row의 모델 간의 비교로 Self-Distillation Loss를 통하여 또 한번의 성능 향상을 보여줍니다. 마지막으로 6th row와 7th row의 성능비교인데요. 6th row의 모델은 extra decoder를 제거하지 않은 것으로, 성능평가를 D_{0}로 진행한 것입니다. 반면, 7th row는 extra decoder를 제거한 것으로 성능평가를 D_{1}로 한 것입니다. 결과를 보시면, D_{1}이 D_{0}의 성능을 능가하며 Self-Distillation Loss가 가장 높은 해상도의 detail 예측 능력을 앞단의 depth 예측에 전의 시키는 것을 목적으로 하였고, 이를 supervision으로 한 D_{1}으로 평가한 성능이 더 좋게 나옴으로서 저자의 의도대로 Loss가 작동했다고 해석할 수 있겠습니다.
4.4. Speed vs. Accuracy Trade-off
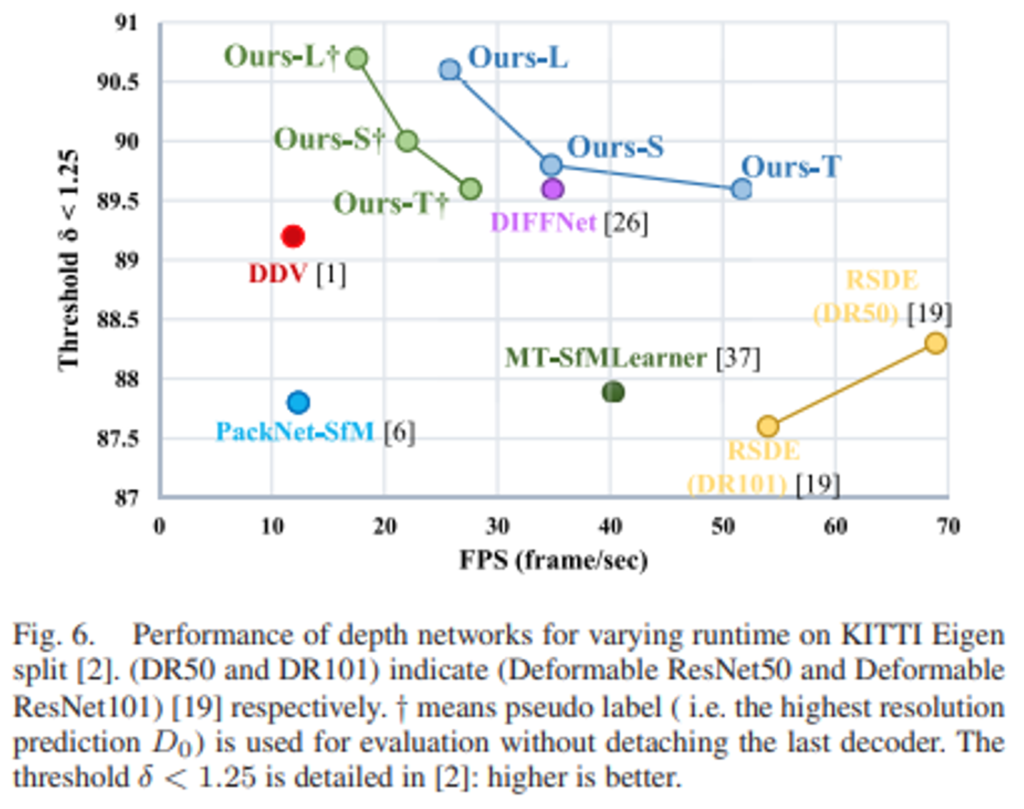
마지막으로 제안한 모델들과 다른 모델들 간의 FPS와 성능에 따른 그래프를 보여줍니다. 여기서 십자가가 첨가된 초록색 ours들은 Extra Decoder를 붙인 상태의 모델들로, inference시 원본과 동일한 해상도(D_{0})에서 예측을 진행하는 모델을 의미합니다. 그리고 파란색 ours들은 Extra Decoder를 제거한 상태의 모델들로, inference시 원본보다 2배 작은 해상도(D_{1})에서 예측을 진행하는 모델을 의미합니다.
가장 무거운 ours-L+를 제외한 모든 모델이 real-time 급은 FPS 20을 넘기고 있는 것을 확인할 수 있습니다.
따라서 실제 자율주행환경의 어플리케이션에서도 제안된 메모리만 괜찮다면 적용하는데 무리가 없을 것 같네요.
감사합니다.