안녕하세요. 오늘 리뷰할 논문은 디퓨전을 사용해 Moment Retrieval을 다룬 MomentDiff 논문입니다.
Abstract
비디오 Moment Retrieval은 주어진 텍스트 설명에 해당하는 특정 구간을 비디오 영상으로부터 식별하기 위한 효율적이고 동시에 일반화된 솔루션을 추구합니다. 저자는 이러한 목표를 달성하기 위해 사람의 식별 과정과 비슷하게 무작위 노이즈로부터 원래 구간을 학습하는 디퓨전 기반의 Moment Retrievla 모델인 MomentDiff를 제안합니다. 이를 통해 모델은 임의 위치에서 실제 순간으로 매핑하는 방법을 학습하여 임의로 초기화에서 구간을 찾을 수 있습니다. MomentDiff는 학습이 완료되면 임의의 시간 segment를 랜덤하게 초기화하고 이를 반복적으로 개선하는 것으로 정확한 시간 경계를 생성할 수 있습니다. discriminative한 기존의 방법론들과 다르게 MomentDiff는 데이터셋의 편향의 영향을 받지 않고 예측을 수행할 수 있습니다. 시간적 위치의 편향의 영향을 받지 않는다는 것을 증명하기 위해서 저자는 Charades-STA-Len과 Charades-STA-Mom이라는 위치 분포의 변화가 있는 두개의 데이터셋에서 평가를 진행합니다.
Introduction
저자는 본 논문에서 Moment Retrieval을 Video Moment Retrieval로 칭하며 VMR로 설명하고 있습니다. 따라서 리뷰에서도 Moment Retrieval을 VMR로 표기하겠습니다. VMR은 주어진 비디오 내에서 의미론적으로 텍스트에 제일 잘 대응하는 순간 경계 즉, 구간의 시작 시간과 끝 시간을 식별하는 것을 목표로 하는 task입니다.
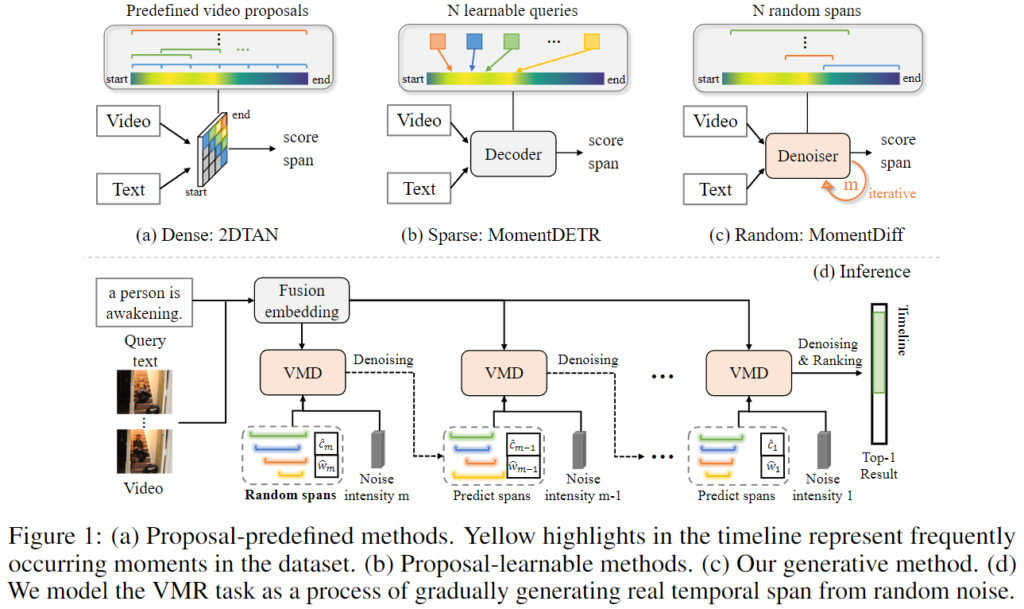
Figure 1의 (a)에서 확인할 수 있듯이 VMR의 초기 작업은 미리 정의된 anchor를 설정하는 sliding window방식 등의 방식을 활용했습니다. 그런 후 쿼리 텍스트와 많은 proposal들 사이의 유사성 점수를 활용하여 예측 segment를 결정합니다. 하지만 위 방식은 중복성이 크고 positive proposal과 negative pair의 수가 불균형하여 학습 효율성이 좋지 않습니다.
저자는 이러한 문제를 해결하기 위하여 VMR에서의 생산적인 관점을 제안한다고 강조합니다. 그림 1. (c)와 (d)에서 볼 수 있듯이 비디오와 해당 텍스트 쿼리가 주어지면 먼저 초기의 예측으로 여러개의 무작위 예측 범위를 도입합니다. 그 후에 무작위 범위를 반복적으로 개선하여 텍스트 쿼리와 비디오 프레임 간의 유사 관계에 대해 설명합니다. 이러한 방법은 인간이 영상 내에서 텍스트에 관련된 영상 내 구간을 찾는 방법과 비슷한 방법으로 영상이 주어졌을 때에 인간은 먼저 임의의 컨텐츠를 훑어보며 대략적인 위치를 파악한 우에 마지막으로 핵심적으로 의미적 순간에 반복적으로 집중하여 시간적인 좌표를 생성합니다.
해당 논문의 contribution은 1) 저자가 아는 한 저자는 사전 정의되거나 학습 가능한 제안에 의존하지 않고 데이터 셋의 시간적 위치 편향을 완화하는 생성적 관점에서 VMR을 다뤘습니다. 간단하게 다시 설명하자면 VMR에서 Diffusion을 활용하여 문제를 해결한 첫 논문입니다. 2) 저자는 Diffusion 모델을 활용하여 랜덤한 범위의 노이즈를 반복적으로 제거하여 올바른 결과를 얻는 프레임워크를 제안합니다. 3) 두가지의 anti-bias 데이터셋인 Charades-STA-Len과 Charades-STA-Mom을 제안하여 저자가 제안하는 MomentDiff가 여러가지 시간적 편향을 가지는 데이터셋들에 대해서 일관적으로 좋은 성능을 가지는 것을 증명합니다.
Method
untrimmed video V=\{v_i\}^{N_v}_{i=1}와 자연어 쿼리 T=\{t_i\}^{N_i}_{i=1}이 주어질 때에 VMR은 모델 \Omega가 구간 \hat{x}_0=(\hat{c}_0, \hat{w}_0)을 예측하는 task입니다.
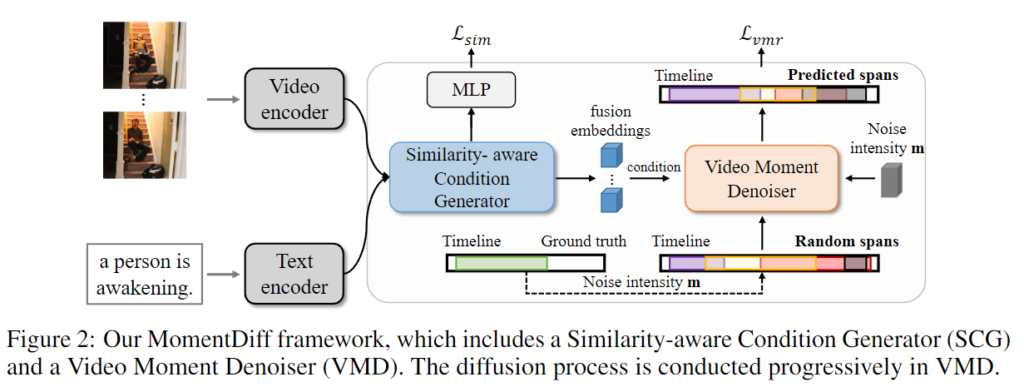
Figrue 2.은 MomentDiff의 전체적인 framework를 보여주는 figure입니다. 먼저 Video Encoder와 Text Encoder를 활용하여 프레임 수준 및 단어 수준의 feature를 추출합니다. 그런 다음 similarity-aware condition generator를 활용하여 텍스트와 시각적 특징을 융합하여 융합 임베딩으로 상호작용합니다. 마지막으로 융합 임베딩과 결합된 Video Moment Denoiser를 활용하여 무작위 노이즈로부터 정확한 시간적 목표를 점진적으로 생성하게됩니다.
Visual and Textual Representations
저자는 visual representation을 얻기 위해 2D 인코더인 VGG와 3D 인코더인 C3D과 CLIP, 그리고 SlowFast를 활용합니다. Text의 경우에는 Glove를 활용하여 텍스트 특징을 추출하고 CLIP의 text 인코더를 활용합니다.
Similarity-aware Condition Generator
VMR 작업에서는 비디오와 문장의 유사성을 이해하고 멀티모달 공간에서의 암묵적인 관계를 학습합니다. denoising 네트워크가 이러한 암묵적인 관계를 학습하기 위하여 저자는 멀티모달 공간에 멀티모달 정보를 제공합니다. 저자는 다른 멀티모달 방법론에서 자주 활용되는 것처럼 다층 트랜스포머를 사용해서 두 모달의 정보를 융합합니다.
위 과정의 수행을 위해 먼저 두개의 MLP를 사용하여 feature를 공통 멀티모달 공간으로 매핑합니다. D가 임베딩 차원이라고 할때, V \in \mathbb{R}^{N_v \times D}, T \in \mathbb{R}^{N_t \times D}로 표현되어 임베딩되고, 다층 트랜스포머를 사용하여 비디오와 텍스트의 정보를 상호작용합니다. 그런 다음 비디오 임베딩 V가 쿼리 Q_v로, 텍스트 임베딩 T가 키K_t와 밸류V_t로 cross-attention을 수행합니다. 수식으로 표현하면 \hat{V}=softmax(Q_vK^T_t)+Q_v로 표현됩니다. 여기서 \hat{V}는 어텐션 연산에서의 밸류가 아니라 쿼리 정보다 포함된 비디오 임베딩입니다. 더 나은 비디오 sequence relation을 위해 최종적으로 저자는 \hat{V}를 self-attention을 수행해 융합 임베딩 F를 생성합니다.
F = softmax(Q_v, K^T_v)+Q_v그런 다음 span값을 생성합니다. span값이란 예측 구간의 중앙 좌표값과 그 구간의 길이를 뜻합니다. 이러한 span값 예측에서 같은 영상이라고 하더라도 서로 다른 텍스트 쿼리에 해당하는 올바른 영상 구간을 서로 다릅니다. 위에서의 융합 임베딩 F는 denoiser의 입력 조건의 역할을 하기에 F의 퀄리티는 denoising 과정에서 중요한 역할을 합니다. 멀티모달 공간에서 F에 대한 유사성 관계를 학습하기 위해 L_{sim}을 사용합니다. L_{sim}에는 point-wise cross entropy와 pairwise margin loss가 포함되어 있습니다.
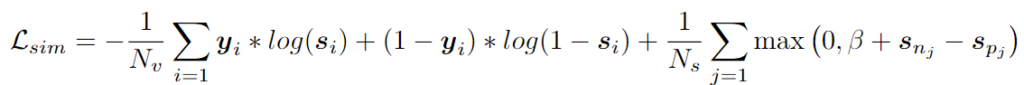
여기서 s \in \mathbb{R}^{N_v}는 유사성 점수이며, y \in \mathbb{R}^{N_v}는 유사성 라벨입니다. 여기서 i번째 프레임이 실제 시간 순간 내에 있으면 y_i는 1이고 그렇지 않으면 0입니다. s_{pj}와 s_{nj}는 각각 positive프레임과 negative 프레임입니다.
Video Moment Denoiser
Video Moment Denoiser 모듈은 Diffusion이 포함된 모듈로 설명에 앞서 Diffusion모델이 익숙치 않으신 연구원님들은 김태주 연구원의 [NeurIPS 2020] Denoising Diffusion Probabilistic Models Diffusion모델 리뷰를 참고해주시길 바랍니다. 정말 간단하게 요약하자면, 순방향 프로세스에서 원본 데이터에 가우시안 형태의 노이즈(사람이 다루기 쉬운 형태의 노이즈)를 더하고 역방향 프로세스에서는 가우시안 형태의 노이즈가 더해진 데이터를 원본 데이터로 복원하는 과정을 학습하는 모델입니다.
저자는 기존의 모델들이 위치 편향에 의존하여 겉보기에는 좋은 예측을 달성하지만 실제로는 좋은 예측을 하고 있다고 볼 수 없다는 것을 지적합니다. 여기서 위치 편향이란 데이터셋을 annotation하는 과정에서 쿼리에 해당하는 구간이 특정 시간대에 많이 위치하고 있어 학습과 추론 과정에서 이 위치의 영향을 받는 것을 의미합니다. 다시 돌아와 이러한 위치 편향에 의존하는 문제를 해결하기 위해서 저자는 distribution-specific proposal이나 쿼리를 개선하는 대신에 실제 span값을 반복적으로 얻기 위해 무작위 위치의 span값을 초기화하여 생성합니다. 그런 후 모델의 video moment denoiser의 diffusion 생성 과정이 모델의 분포 q_0(x_0)로부터 데이터의 분포 q(x_0)을 학습합니다.
순방향 프로세스
학습 과정에서는 먼저, 실제 세그멘트 spanx_0 ~ q(x_0)를 노이즈가 있는 데이터x_m으로 변환하는 과정을 거칩니다. 여기서 m은 노이즈의 강도를 뜻합니다. 위 과정을 순방향 프로세스 (Forward Process)라고 하며 두 개의 연속적인 강도의 가우시간 노이즈 프로세스를 거치게 됩니다.
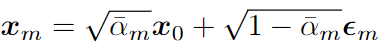
수식에서 노이즈 \epsilon \sim N(0,I)이고 \bar{\alpha} = \Pi^m_{i=1}(1-\beta_i)입니다. \beta_i는 분산\epsilon \sim N(0,I)이고 \bar{\alpha} = \Pi^m_{i=1}(1-\beta_i)입니다. \beta_i는 variance schedule로 Diffusion에서 가우시안의 폭을 결정하는 파라미터입니다.
역방향 프로세스
denoising 과정으로 순방향 프로세스에서 더한 노이즈를 점진적으로 제거하는 것을 학습합니다. Diffusion의 점진적으로 노이즈를 제거하는 과정의 한 스텝을 수식으로 표현하면 밑의 수식과 같습니다.
p_0(x_{m-1}|x_m) = N(x_{m-1};\mu_0(x_m,m),\sigma^2_m\mathbf{I})\sigma^2_m는 순방향에서의 \beta_m와 연관이 있고, \mu_0(x_m,m)는 예측 평균입니다. 해당 논문에서 저자는 span값을 예측하기 위해 nosining과 denoising과정을 거치기 때문에 기존의 Diffusion모델의 \mu_0(x_m,m)대신에 VMD네트워크 f_o(x_m,x,\mathbf{F})를 사용합니다.
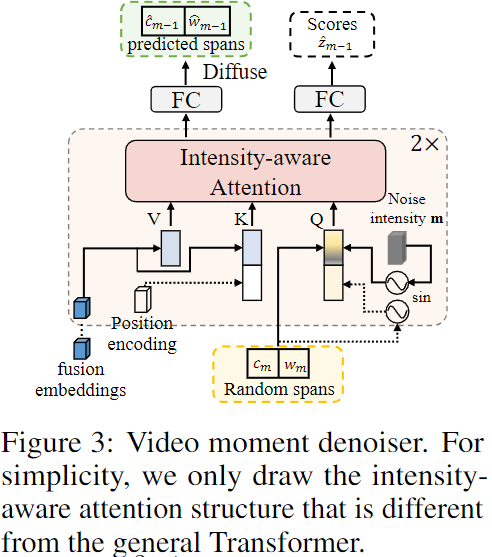
Denoiser Network
Figure 3에서 볼 수 있듯이, VMD 네트워크는 2단게의 cross-attention 트랜스포머 층으로 구성됩니다. VMD는 다음과 같은 과정을 거쳐 진행됩니다. 편의를 위해 입력과 출력은 Figure 3.과 마찬가지로 1차원 벡터로 고정시켜 설명하겠습니다.
- Span Normalization: 생성 작업과 달리, 실제 정답 시간 span은 정답 구간의 중앙 좌표와 길이로 존재하고 모두 [0, 1]로 정규화되어 있습니다. 따라서 순방향 프로세스에서는 가우시안 분포에 더 가깝게 유지하기 위해 그 범위를 확장해야 합니다. 노이즈 추가가 완료된 후 저자는 span을 정규화하는 과정을 거쳐 범위를 맞춰줍니다.
- Span Embedding: 다중 모달 공간에서 데이터 분포를 모델링하기 위해, 저자는 완전 연결층(FC)을 통해 이산 span을 직접 임베딩 공간으로 투영합니다. 여기서의 선형 투영은 유연하고 조건 정보(즉, 융합 임베딩)와 분리되어 있어 더 많은 중복을 피할 수 있습니다.
- Intensity-aware Attention: denoiser는 denoising 중에 추가된 노이즈 강도(m)를 이해해야 하므로, 저자는 강도 크기를 명시적으로 인식하는 강도 인식 어텐션을 사용합니다. Figure 3에서, 노이즈 강도 ?을 sine 매핑하여 다중 모달 공간에서 span embedding에 추가합니다. 저자는 쿼리 임베딩으로 투영하고 위치 임베딩을 sine 매핑합니다. x'_m=\mathbb{e}_m를 쿼리 임베딩 pos_m \in mathbb{R}^D를 포지셔널 임베딩으로 추영시킵니다. 그래서 최종 intensity-aware attention은 다음과 같습니다.
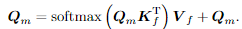
여기서 쿼리, 키, 밸류 값은 각각
Q_m = Concat(Proj(x'_m+\mathbb{e}_m), pos_m),
K_f = Concat(Proj(\mathbf{F}), pos_f),
V_f = Proj(\mathbf{F}) 입니다.
4. Denoising training: 마지막으로, 생성된 트랜스포머 출력은 예측된 span과 신뢰도 점수로 변환되며, 이는 간단한 FC 층을 통해 구현됩니다. 마지막의 denoising loss는 다음과 같이 정의됩니다.
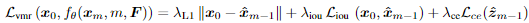
여기서 \lambda_{L1}, \lambda_{iou}, \lambda_{cd}는 하이퍼파라미터이고, L_{iou}는 일반화된 IoU loss이며 L_{ce}는 cross-entropy loss입니다.
데이터셋에 하나 이상의 실제 정답 span이 있을 수 있음을 고려해서 저자는 입력 및 출력 span 수를 N_r로 설정합니다. 입력의 경우, 실제 정답 외에도 추가 span은 무작위 노이즈로 패딩됩니다. 출력의 경우 저자는 헝가리안 매칭에 따라 각 예측된 span과 실제 정답의 matching cost을 계산하고, 가장 작은 cost의 span을 찾아 loss을 계산합니다. 저자는 가장 잘 예측된 span에 대해 신뢰도 라벨을 1로 설정하고, 나머지 span에 대해서는 0으로 설정합니다.
Inference
훈련 후, MomentDiff를 적용하여 훈련 중에 보이지 않았던 video-text 페어에 대해서도 올바른 구간을 생성할 수 있습니다.
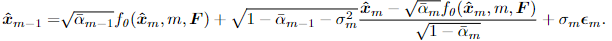
저자는 다음과 같은 update 규칙을 통해 denoising할 수 있다고 강조합니다. Figure 1. (d)에의 그림처럼 MomentDiff는 위의 과정을 반복하여 점진적으로 노이즈를 제거해 쿼리에 해당하는 비디오의 구간을 예측합니다.
Experiments
데이터셋은 Charades-STA, QVHighlights, TACoS를 활용했으며 평가지표로는 R@1, MAP@n, MAP(avg)를 활용했습니다. R@1은 상위 1개의 VMR 결과 중에 IoU값이 n이상인 결과의 비율입니다. MAP@n는 n보다 큰 IoU를 갖는 mean average Precision을 의미하고 MAP(avg)는 여러 IoU 임계값 [0.5:0.05:0.95]에 걸쳐 평균 MAP@n으로 결정됩니다.
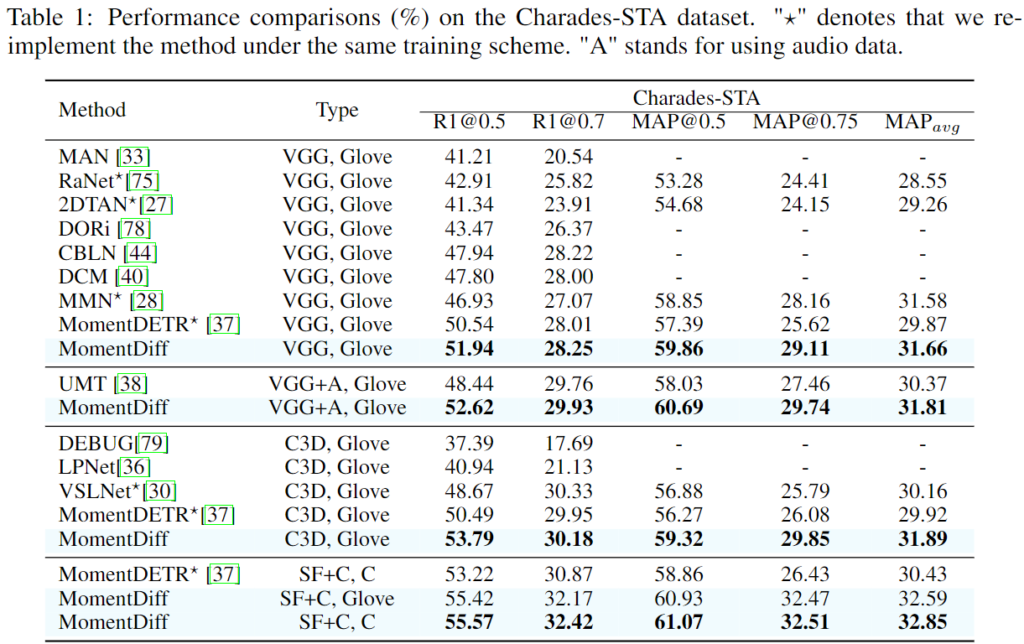
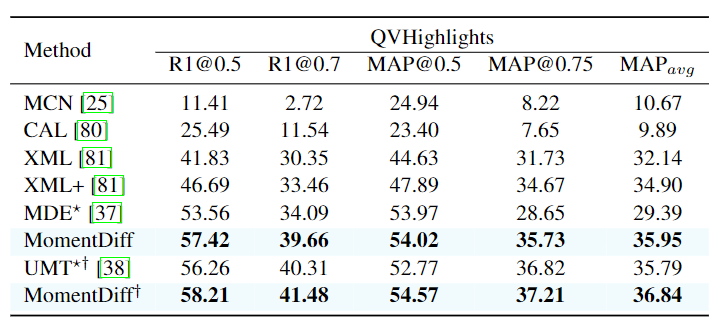
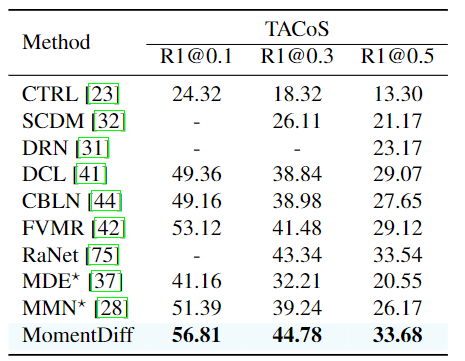
위 결과는 순서대로 Charades-STA, QVHighlights, TACoS 데이터셋에서의 Moment Retrieval 결과입니다. 기존의 다른 방법론들보다 모두 좋은 성능을 보여주는 것을 확인할 수 있습니다. 특히 저자는 TaCoS데이터셋이 조리기구, 음식 등 서로 다른 사건이 조금씩만 다른 긴 영상의 요리 영상이 존재한다는 점을 조명하고 있습니다. MomentDETR 기반의 방법론들은 이러한 fine-grained dynamic 변화에 약하다는 것을 지적하며 MomentDiff의 similarity-aware condition 정보와 점진적 노이즈 제거는 fine-grained 변화에 유리하다고 언급하는데 그에 따른 저자의 근거가 없네요. MomentDETR이 fine-grained dynamic 변화에 약하다는 것은 알겠지만, 왜 MomentDiff의 디퓨전 기반 방법론이 fine-grained에서 유리한지는 조금 더 생각해봐야할 것 같습니다.
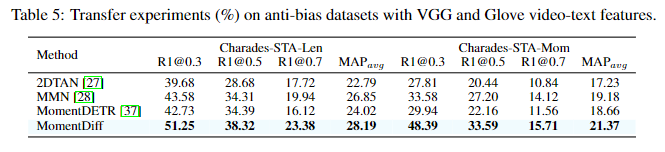
다음은 저자가 Introduction에서도 언급했었던 Charades-STA-Len과 Charades-STA-Mom을 포함하는 정답 구간의 위치가 데이터셋에 골고루 여러군데 존재하도록 수정한 데이터셋에서의 평가결과입니다. Charades-STA-Len은 원래 Charades-STA의 훈련 셋에서 w_0 \leq 10s인 페어를 전부 활용하고 w_0 \geq 10s인 훈련 셋은 일부만 활용하고 훈련 셋에서 활용하지 않은 데이터들은 모두 평가 셋에 추가한 데이터셋입니다. Charades-STA-Mom 데이터셋은 비슷하게 종료시간 c_0 + w_0/2 \leq 15s인 데이터는 전부 활용하고, 시작시간 c_0 - w_0/2 > 15s인 데이터는 일부만 활용하여 그 외의 데이터는 평가 셋에 추가한 데이터셋입니다. 두 데이터셋 모두에서 기존의 SOTA 모델보다 더 이러한 변화에 강인한 모습을 보이는 것을 확인할 수 있습니다. 저자는 위 표 4, 5를 강조하며 MomentDiff모델의 일반화능력이 다른 모델들에 비해 뛰어나다는 것을 강조합니다.
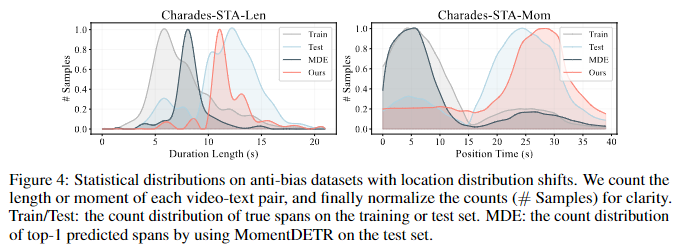
Figure 4. 는 위의 설명에 더해 Charades-STA 데이터셋의 분포 변화를 나타내는 그림입니다.
Ablation Study
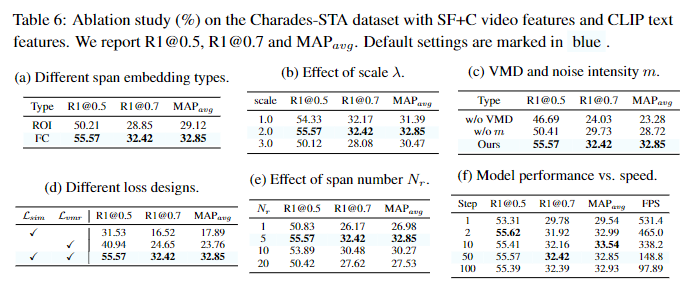
표 6. (a)는 이산 span을 임베딩 공간에 매핑하는 방법과 관련하여 ROI와 FC를 비교합니다. ROI의 경우, 퓨전 임베딩인 F를 슬라이스(분할) 한 후에 슬라이스된 특징에 대한 평균 풀링을 통해 진행했다고 합니다. ROI의 성능이 FC에 비해 많이 낮은 것을 확인할 수 있는데 저자는 이것을 ROI는 hard projection 전략이라고 하며 영상의 프레임별 중요성은 많이 다르기 때문에 좀더 soft한 방법인 FC가 더 좋다고 분석했으며 또 FC는 F(퓨전 임베딩)에서 분리되기 때문에 모델이 F에 과한 의존성을 띄는 문제를 예방할 수 있다고 분석했습니다.
(b)와 (c)는 표에서 나와있는 결과대로 scale값을 2로 했을때 실험적으로 제일 좋았으며 과하게 커지면 일반화 성능이 떨어진다는 언급과 VMD모듈을 노이즈강도 m과 활용할때 제일 좋았다는 언급만 있었기에 자세한 설명은 하지 않고 넘어가겠습니다.
(d)는 loss 디자인들의 ablation으로 L_{sim}은 pointwise, pairwise, 그리고 token-wise 상호작용으로 denoising을 위한 reliable conditions을 제공합니다. L_{vmr}은 모델이 정확한 span값을 예측하는 것으로 두 loss는 적절한 멀티모달 상호작용과 노이즈 제거에서 상호보완적이기에 각각의 loss는 성능이 좋지 않지만, 같이 사용할 때는 효과적입니다.
(e)는 span의 개수로 5개면 충분하다고하네요. 실제로 moment retrieval은 object detection에 비하면 영상 내에 쿼리에 해당하는 올바른 구간의 수가 적습니다. 따라서 span의 수가 늘어나게되면 오히려 모델을 학습시키기 어렵게 만듭니다.
마지막으로 (f)는 diffusion step의 수에 따른 성능과 속도의 trade-off를 위한 ablation입니다. ablation의 표에 따르면 step이 2일때가 속도가 빠르면서도 꽤나 준수한 성능을 보여주고 있습니다. 어떠한 데이터셋에 평가한 결과인지를 해당 섹션에서 언급을 하지않아 Experiment를 확인해보니 Charades-STA 데이터셋에서의 성능임을 확인할 수 있었습니다. ablation에서는 step=2가 효율이 좋다고 언급하고 실제로 논문에 리포팅한 성능은 step=50의 성능을 사용했네요. 아무래도 다른 모델과의 비교를 위해서 비슷한 속도를 갖는 step으로 비교를 한건지 성능이 높아서 그런건지 정확한 저자의 생각은 잘 모르겠네요. 리뷰에서는 생략했지만, Implementation Detail에서는 속도를 위해 step=50 사용했다고 언급하는데 다른 모델과의 속도를 비교하지는 않아 정확한 비교는 어려울 것 같습니다.
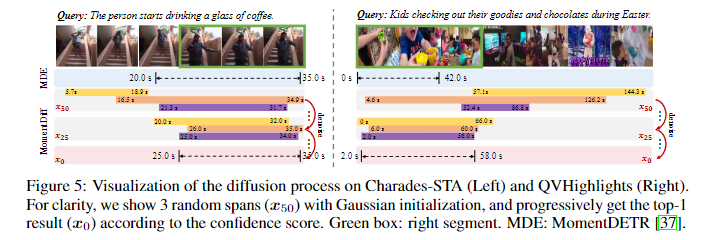
Figure 5.는 점진적으로 denoising을 거치며 MomentDiff가 정확한 timestamp예측을 하는 것을 보여줍니다. MomentDETR과 비교를 하며 점진적으로 noise를 제거하며 x_0 즉, noise를 전부 제거하고 난 이후에는 GT와 거의 일치하는 예측을 보여줍니다.
Conclusion
저자는 기존 방법론들과 저자가 제안하는 MomentDiff 방법론을 비교해보았을 때에 diffusion 과정이 여러 번의 반복 과정이 필요하기에 추론 속도에 영향을 줘 추론시에 속도가 느린것을 제안하는 MomentDiff의 한계점으로 지적합니다. 이 한계점을 극복하기 위해서 저자는 적절한 반복 횟수를 지정하는 것으로 성능-속도 trade-off 관계에서의 최적화된 반복횟수를 찾는 것이 중요하다고 언급하고 있습니다. 이 부분은 다른 방법론과 직접 비교를 해줬으면 하는데 비교가 없어 살짝 아쉽네요.
저자는 Diffusion 모델을 Moment Retrieval에서 활용하는 MomentDiff 모델을 제안합니다. 랜덤한 노이즈에서 시각적 구간으로의 denoising 과정을 통해 예측 결과를 정제하고, 기존의 방법론들이 갖는 위치 편향 문제를 해결할 수 있습니다. MomentDiff는 여러 다양한 데이터셋에서 이러한 편향 방지를 통해 효율성과 일반화를 입증했습니다. 저자는 이러한 과정을 통해 Moment Retrieval에서의 불완전성을 해결하고 Moment Retrieval에서 추가 연구가 지속되길 바란다고 언급하며 논문을 마칩니다.
Diffusion이 생성모델에서 활용되는 것은 알고 있었지만, 이런식으로 비디오 task에서도 활용할 수 있다는 것이 신기하네요. 멀티모달 도메인에서도 Diffusion이 활용되는 경우가 많다고 저자가 언급하고 있는데 한계점이 추론속도가 개선될 수만 있다면 Diffusion이 다른 여러 멀티모달에서도 자주 활용될 수 있을 것같네요. 이상 리뷰를 마치도록 하겠습니다.
감사합니다.
리뷰 잘 봤습니다. Difussion을 활용하여 VMR을 해결하는 첫 논문인거 같네요.
리뷰에 대한 질문은 없고 조금 다른 코멘트를 달자면
일단 리뷰를 두번 정도 읽어봐도 query를 생성적 관점에서 정의 해야하는 이유나 실제 노이즈가 제거되는 과정에서 구조가 잘 이해가 안가네요. 리뷰를 그냥 옮겨 적었다는 느낌을 받았는데, 본인의 생각이나 이해한 내용을 자세히 적었으면 좋겠습니다.
그리고 논문에 있는 다른 실험들은 일부러 뺀건가요? (실험 부분을 읽었는지 궁금)
벤치마킹 실험만 딱 보여주고 제일 높은 성능이니깐 제안하는 방법이 우수하다 이런식으로 대충 작성하지 마세요.
다음 리뷰도 이런식이면 가만두지 않겠습니다.
안녕하세요 임근택 연구원님 코멘트 남겨주셔서 감사합니다.
논문을 다시 한번 정독하고 리뷰를 보완했습니다.
query를 생성적 관점에서 정의하는 이유는 기존 방법론들이 데이터셋의 GT구간의 위치에 영향을 많이 받아 일반화 성능이 부족하다는 문제점이 있었는데 이 문제를 해결하기 위해 생성적 관점에서 정의합니다. MomentDiff는 Diffusion기반의 방법론으로 임의의 구간 위치로부터 실제 구간으로 denoising하는 과정을 통해 일반화 성능을 올렸습니다. 이는 저자가 구간을 수정한 데이터셋에서 실험적으로 보여줍니다(Table 5). 실제 노이즈가 제거되는 과정은 Video Moment Denoiser 모듈을 설명하는 파트에 다시 설명했으니 확인부탁드립니다.
실험 파트 또한 본문에 내용을 추가하여 다시 작성했습니다.