Preliminary
하나의 비디오에서 다양한 콘텐츠를 가지고 있는 Untrimmed Video를 분석 하기 위해 다양한 연구들이 진행 되었는데, 오늘은 [2022 CVPR] UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection 에서 제안된 방법에 대해서 간단하게 알아보고 리뷰 시작하겠습니다.
내용 자체는 사건의 변화 지점을 탐색하는 방법에 대한 것이라 보면 됩니다.
Temporal Similarity Matrix (TSM)
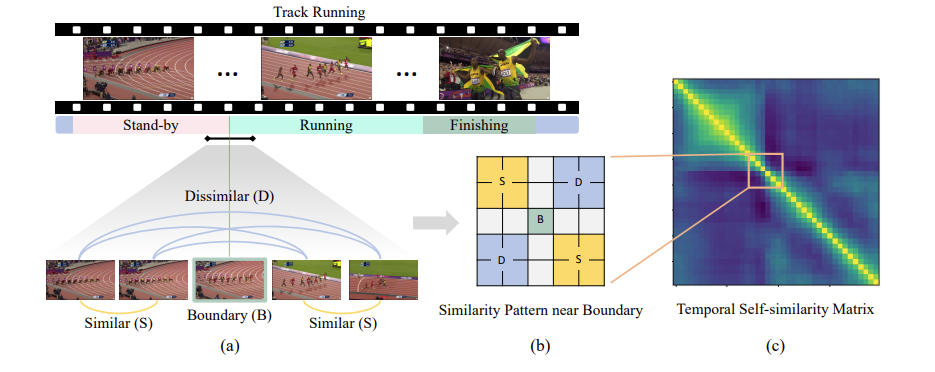
일반적인 Untrimmed Video는 위의 그림과 같이 Stand-by, Running, Finishing 등 하나의 영상에서 다양한 콘텐츠, 장면이 등장하게 됩니다. 이전의 연구들은 Untrimmed Video를 사건이나 장면 단위로 분할하여 이해하고 싶어 했습니다. 하지만 그러기 위해서는 경계 지점을 찾아야 했습니다.
이러한 boundary를 찾기 위해서 비디오 분야에서는 자주 사용되는 테크닉이 있습니다. 바로 Temporal Self-Similarity Matrix(이하 TSM)이죠. 비디오를 구성하는 T개의 frame이 있다고 하면, 각각의 frame feature끼리 하나씩 코사인 유사도를 계산하고 T \times T의 Similarity Map을 생성하는 것 이죠.
일반적으로 동일한 콘텐츠, 장면이라면 시각적 유사도가 높기 때문에 장면이 전환되는 부분에서는 (b)와 같은 형태가 관측 됩니다.
T개의 프레임을 1초에 하나씩 샘플링 했다고 가정하면 TSM에서 하나의 값은 1초의 temporal length를 책임지게 됩니다. 0초에서 2초가 evnet A, 2초~3초가 boundary, 3초~5초가 event B라 가정하면 Boundary를 경계로 전후의 Similarity Map의 양상이 아래와 같이 나옵니다.
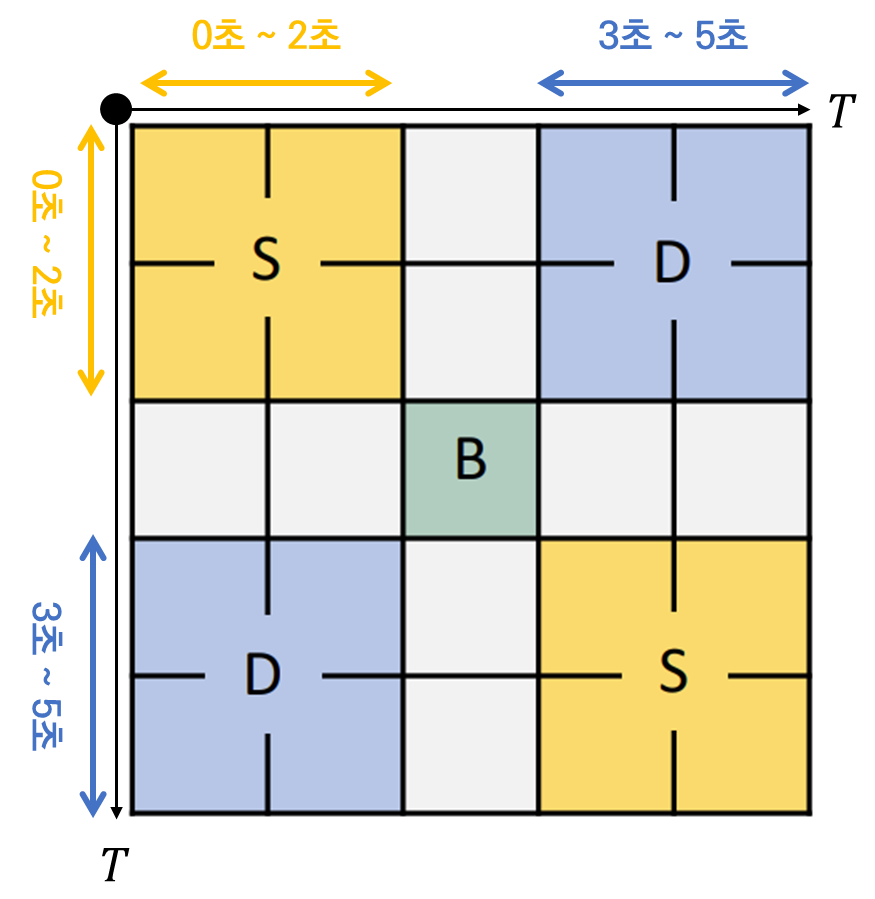
같은 event에 속한 feature들의 similarity가 높고 다른 event간 similarity가 낮게 나오는 것이 boundary를 찾는데 이상적이기 때문 입니다. 이러한 local diagonal pattern이 boundary를 찾는데 굉장히 중요한 learning signal로 작용할 수 있습니다.
이는 TSM에서 대각 방향으로 edge를 찾는 것과 비슷하기 때문입니다. 저러한 pattern을 찾을 수 있다면 우리는 그 지점을 pseudo boundary로 사용할 수 있겠네요.
본 연구는 이러한 TSM의 local pattern에 집중하여 event boundary를 찾는데 더욱 적합한 feature representation을 얻을 수 있는 방법을 제안합니다.
즉, (b)와 같은 패턴을 가지는 지점을 TSM에서 찾을 수만 있다면 장면이나 사건이 전환되는 지점을 찾을 수 있게 되는 것이죠.
Recursive TSM Parsing (RTP)
그렇다면 (b)와 같은 패턴을 가지는 지점을 어떻게 찾을 수 있을까요? 이를 위해 이전의 연구인 [2022 CVPR] UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection 에서는 분할 정복 방식으로 접근합니다.
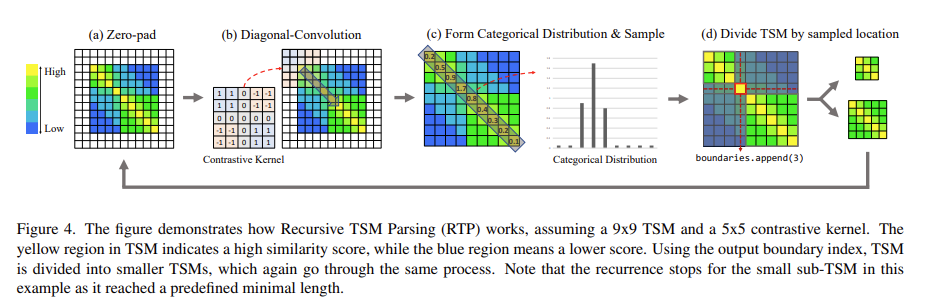
4가지 단계로 구성되어 있는데 하나씩 살펴보도록 하겠습니다.
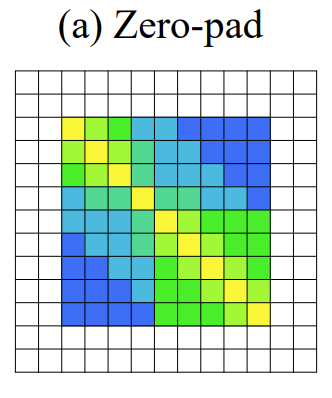
가장 처음으로 Zero-pad 입니다. Padding은 보통 사이즈를 맞춰주기 위해 사용하지만 corner 정보를 살려주기 위해 사용하기도 합니다. 여기서는 corner 정보를 살려주기 위해 사용해주고 있습니다. Corner 정보를 살려줘야 하는 이유는 바로 corner에 boundary가 있는 경우도 고려해주기 위함입니다. 사소할 수 있지만 이러한 디테일이 중요하게 작용한다고 합니다.
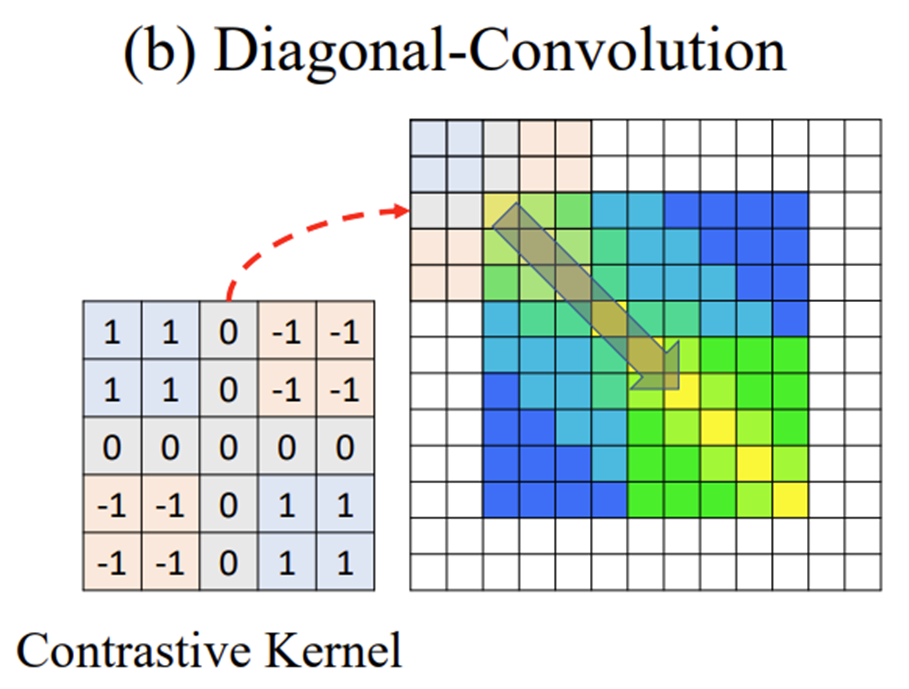
다음으로 Diagonal Convolution 입니다. Convolution이라고 해서 학습이 되는 filtering을 해주는 것은 아니고 위의 그림과 같이 사전에 정의된 Contrastive Kernel을 바탕으로 대각 방향 Sliding을 합니다. 그럼 저 Contrastive Kernel이 찾고자 하는 패턴은 무엇이냐면 바로 우리가 찾고자 했던 Boundary Local Pattern 입니다. 좀 더 자세히 설명해보도록 하겠습니다.
우리가 Cosine Similarity를 바탕으로 TSM을 정의하면 -1 ~ 1 사이의 값을 가지게 됩니다.
만약에 이상적인 Boundary Pattern이라 한다면 Similar한 부분에서는 1에 근접한 값이 나타날 것이고 Disimilar한 부분에서는 -1에 근접한 값이 나타나게 되겠죠.
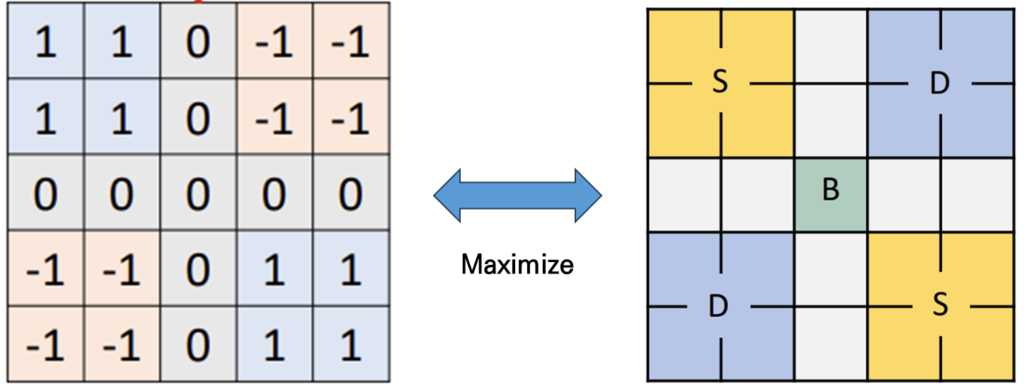
이때 Kernel을 5 by 5로 정의하고 4개의 구역으로 나누어 Similar한 부분에는 1을 채워주고 Disimilar한 부분에는 -1을 채워 줍니다. 그리고 나서 이상적인 Boundary Pattern에 filtering을 해주면 가장 최대 값이 발생하게 됩니다.
자 그럼 이러한 kernel을 가지고 대각 방향으로 필터링을 해주다 보면 우리가 찾고자 하는 boundary 인지 아닌지 나타낼 수 있는 스칼라 값을 얻을 수 있습니다.
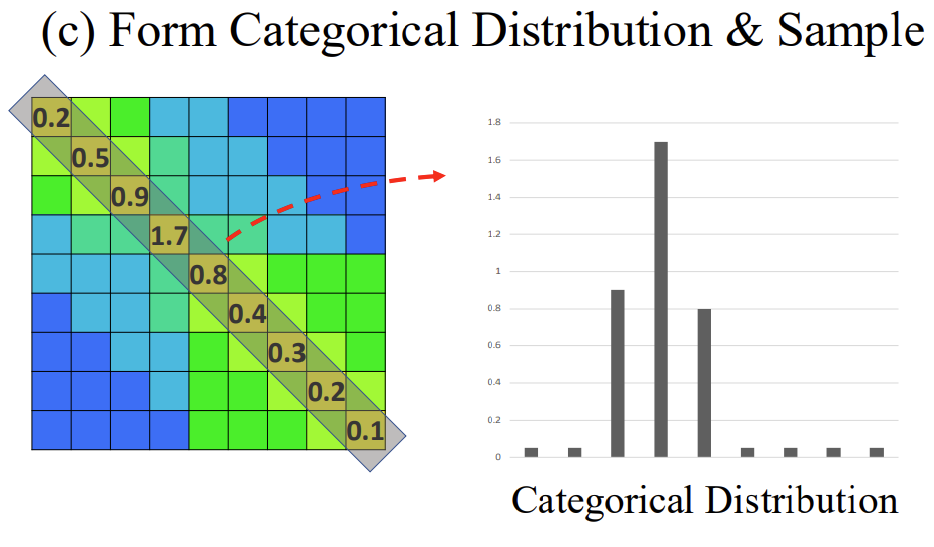
위의 그림 처럼 [0.2, 0.5, 0.9, 1.7, 0.8, 0.4, 0.3, 0.2, 0.1] 의 리스트를 얻을 수 있죠.
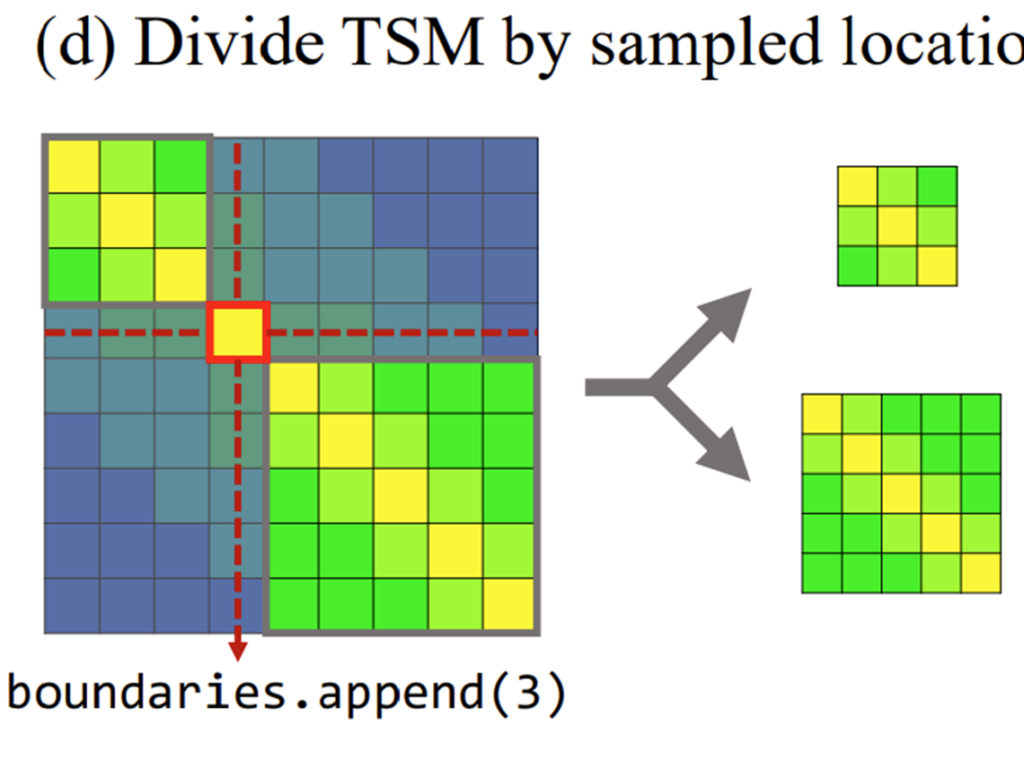
그리고 위에 리스트에서 [0.2, 0.5, 0.9, 1.7, 0.8, 0.4, 0.3, 0.2, 0.1] 최대 값에 해당하는 index를 바탕으로 다시 TSM을 분할 합니다. 여기서는 1.7이 가장 max 값이기 때문에 1.7에 해당하는 index=3을 pseudo boundary라 정의하고 이를 바탕으로 다시 TSM을 위의 그림과 같이 분할 합니다.
이렇게 쪼개진 TSM은 다시 위의 과정을 종료 조건까지 반복합니다. 그리고 우리는 그 과정에서 얻어지는 boundary를 pseudo boundary로 사용하는 것이죠.
종료 조건은 두 가지가 존재합니다.
- 분할되는 TSM의 temporal length가 사전에 정의한 threshold 보다 작을 경우, 이는 event가 정의될 수 있는 최소 길이에 대한 가정을 나타냅니다.
- 분할되는 TSM에서 max boundary score와 mean boundary score의 차이가 사전에 정의한 threshold보다 작을 경우, 이는 해당 TSM이 나타내는 구간에서는 boundary라 정의할 수 있는 distinctive한 point가 없는 경우 입니다.
이렇게 비디오에 대해서 N개의 pseudo boundary point를 얻을 수 있습니다. 본 논문에서는 자세한 설명 없이 이전의 접근을 취함으로 이러한 boundary point을 얻었다고 나와 있는데 제가 이전에 리뷰한 논문의 내용이라 다시 한번 간단하게 정리해보았습니다.
Introduction
Temporal Video Grounding은 텍스트 쿼리에 대응되는 비디오 구간을 검색하는 연구 입니다. 현재의 유튜브 검색 시스템을 보면 사용자가 던진 텍스트 쿼리와 관련된 영상들의 목록만 반환해주고 해당 쿼리와 영상들이 정확히 어디 구간에 매칭 되는지는 알려주지 않죠.
고도화된 영상 검색 플랫폼을 위해서 혹은 영상 편집 시스템을 위해서 사용자 맞춤 텍스트 쿼리와 이에 대응되는 영상 구간을 찾는 Temporal Video Grounding은 이제는 중요한 연구로 자리 잡아 많은 주목을 받고 활발하게 연구되고 있습니다.
영상 구간을 검출한다는 것은 예전부터 이미지 도메인의 객체 검출 (Object Detection)과 비슷한 성격을 가졌습니다. Sliding Window 방식과 NMS 등 구간을 검출한다는 것은 객체를 검출한다는 것과 비슷한 성향의 방법이기 때문이죠.
그렇다면 빠질 수 없는 것이 DETR 입니다. Object Detection 분야에서 DETR이 등장하고 많은 후속 연구들이 Video Grounding 분야에서 이루어졌습니다. Video Grounding 분야에서도 One-stage 기반의 end-to-end 방식을 위해 많은 연구들이 이뤄졌습니다.
가장 대표적인 연구는 [NIPS 2021] QVHIGHLIGHTS: Detecting Moments and Highlights in Videos via Natural Language Queries 로 학습 가능한 Moment Query를 이용하여 구간을 예측하는 것이죠. 기존 DETR 구조와 굉장히 비슷합니다.
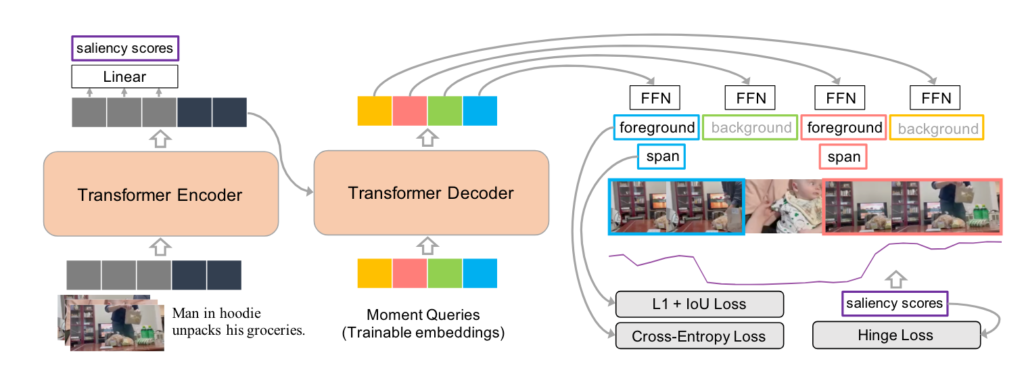
저렇게 Moment-DETR이라는 연구가 등장하고 DETR 구조를 Video Grounding 분야에 활용하는 많은 연구들이 진행 됐는데 기존 연구들이 한가지 간과한 것이 있습니다.
기존 연구들은 비디오에서 발생하는 event를 고려하지 않고 input과 무관한 moment query를 활용 했다는 점 입니다.
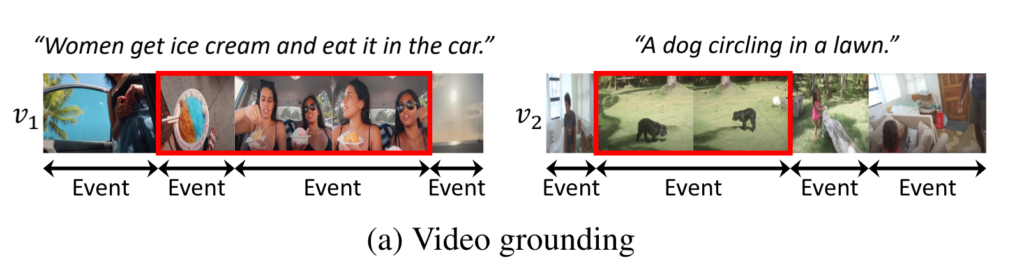
위의 그림을 보면 영상마다 Event가 발생하는 구간들이 모두 다릅니다. 비디오를 구성하는 프레임들이 제각각 복잡한 상호작용을 통해 서로 다른 event 구간을 가지게 되는데 기존의 연구들은 이러한 점을 전혀 고려하지 않았다는 것 입니다.
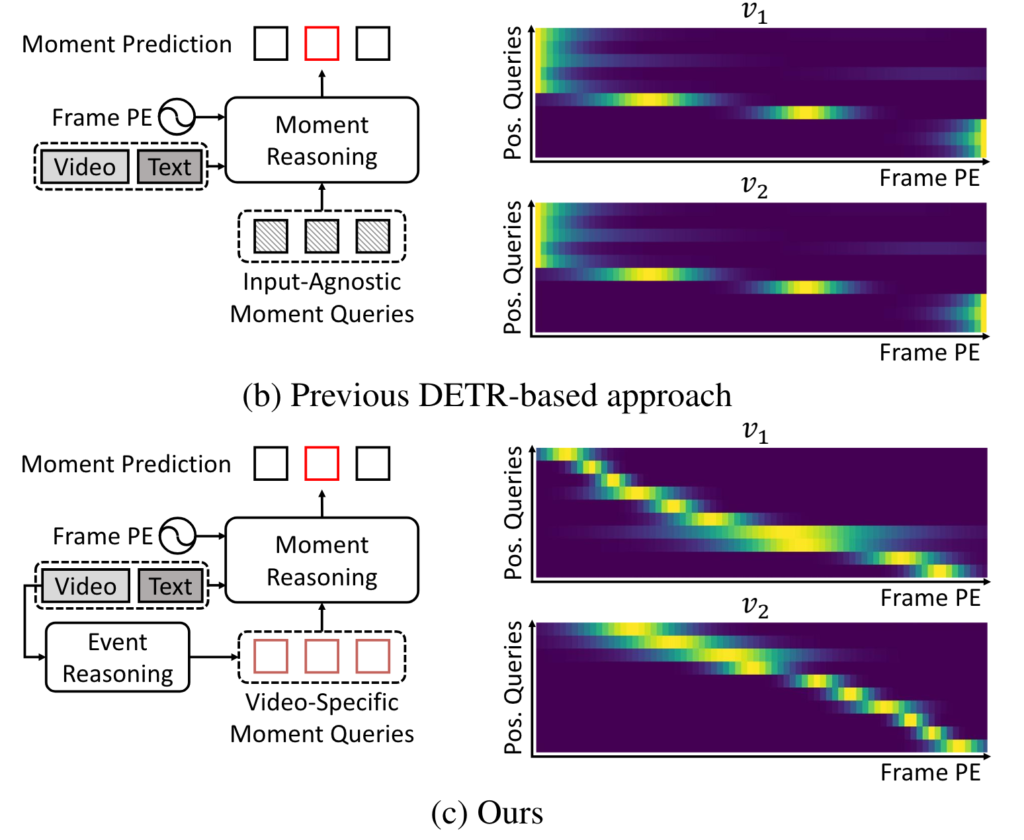
위의 그림 (b)를 보면 Input-Agnostic Moment Query를 활용하면 서로 다른 비디오라 할 지라도 동일한 positional query를 활용 했습니다. 비디오 마다의 event를 고려하지 않고 모두 동일한 기여를 한다고 가정하는 것이죠.
그림에서 (c)를 보면 저자가 제안하는 방식 입니다. Event Reasoning이라는 과정을 거쳐 Video-Specific한 Moment Query를 생성합니다. 그렇기 때문에 비디오 마다 서로 다른 positional query를 정의하고 이를 학습에 활용하게 됩니다.
저자는 Video Specific한 Moment Query와 이를 활용하여 정확한 구간 예측을 위해 두가지 모듈을 제안합니다.
제안하는 두가지 모듈이 무엇인지는 이어지는 방법론 설명에서 하도록 하겠습니다.
Proposed Method
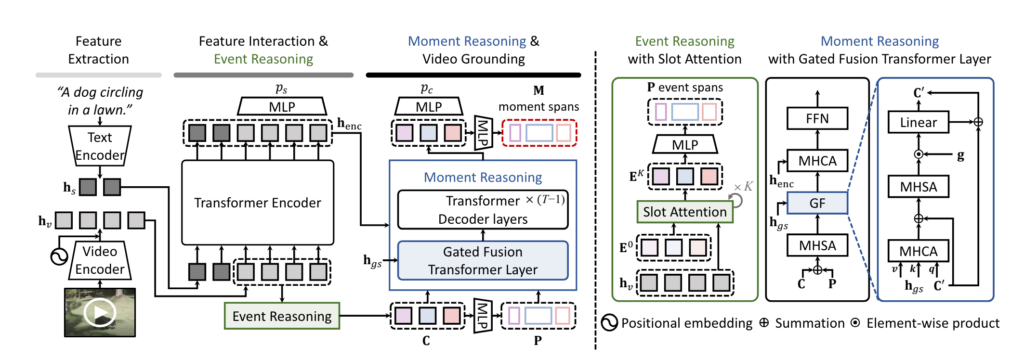
Feature extraction and interaction
우선 길이가 L_{v}인 비디오와 L_{s}이 텍스트 문장이 있다고 할 때 아래와 같이 feature를 인코딩 합니다. (논문에서는 L_{s}가 L_{v}로 잘못 표기되어 있네요. feature 자체는 사전학습된 백본 (SlowFast, CLIP)을 이용해서 백본은 freeze를 하고 feature만 미리 뽑아두고 사용합니다.
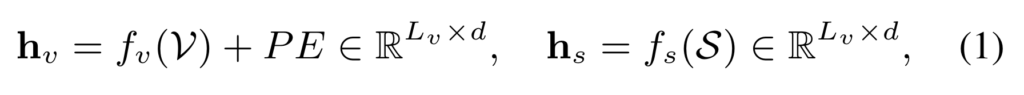
그리고 나서 video feature와 text feature를 concat하고 다시 encoding을 시킵니다.
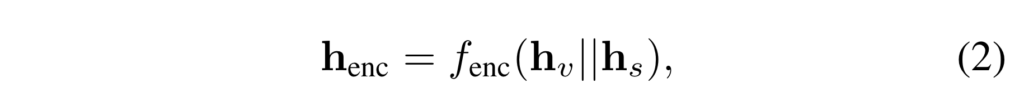
이 encoding 된 \mathbf{h}_{enc}를 통해서 각 프레임마다 saliency score를 예측합니다. 문장과 관련이 있는 프레임과 없는 프레임의 특징 표현력을 구분하기 위함이라 보시면 됩니다.
margin loss로 정의 되어 있고 해당 loss는 본 논문에서 제안하는 것은 아니고 기존 연구들이 활용하는 방식을 그대로 따라했다고 합니다.
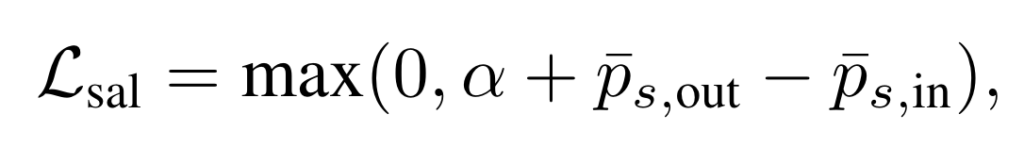
Event reasoning
이제 본격적으로 저자가 제안하는 모듈에 대한 얘기를 해보도록 하겠습니다.
기존의 Moment Query는 Content Query와 Positional Query로 구성되어 있었습니다. 이 때 Positional Query의 경우 입력 비디오와 상관 없이 항상 0으로 초기화를 시키고 학습을 시작하였습니다.
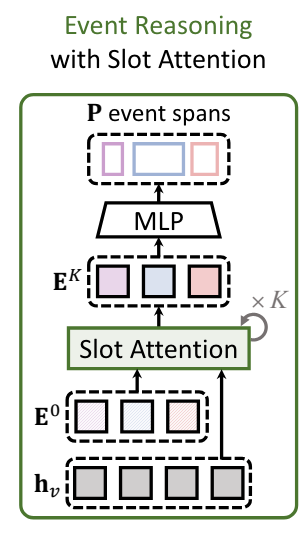
저자는 비디오 마다 서로 다르게 발생하는 event 구간을 특정하기 위해 Event Reasoning 과정을 거쳐 입력 비디오 마다 가변적인 Positional Query를 생성할 수 있게 합니다.
처음에는 N개의 학습 가능한 event slot \mathbf{E}^{0} \in \mathbb{R}^{N \times d} 을 초기화 합니다.
그리고 나서 video feature \mathbf{h}_{v}와 반복적인 slot attention 과정을 거쳐 \mathbf{E}^{K}를 생성합니다.
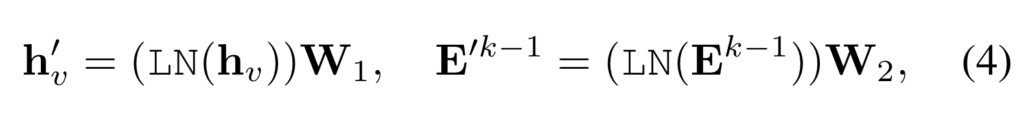
이 때 특정한 k 번 째 iteration에서 video feature와 event slot 간의 interaction matrix는 아래와 같이 정의합니다. 수식이 attention weight 계산하는 것과 비슷하게 생겼네요.
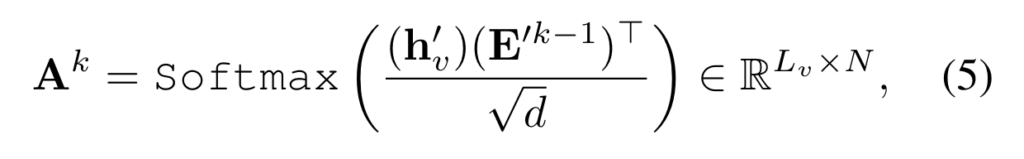
이렇게 정의한 interation matrix를 가지고 \mathbf{E}^{k}를 아래와 같이 update 합니다.
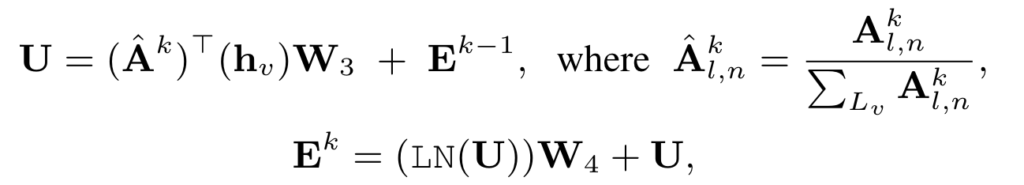
위의 과정에 대해서는 아마 slot attention을 적용하면서 진행하는 일반적인 과정인 것 같습니다.
K번 반복 되고 나온 event slot의 경우 비디오 내의 각각의 event에 대한 visual information을 내포하고 있다 볼 수 있습니다.
따라서 Content Query는 \mathbf{E}^{K}를 그대로 활용하고 positional query만 \mathbf{E}^{K}를 다시 한번 projection 시켜서 정의합니다.
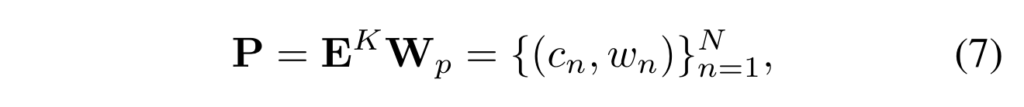
특정 moment의 중앙 시간 포인트와 양 옆 너비를 나타내는 두가지 값으로 projection 시켜 줍니다.
이 때 각각의 positional query 들이 특정 event를 잘 나타낼 수 있도록 앞서 preliminary에서 정의한 pseudo event boundary를 학습에 활용합니다.
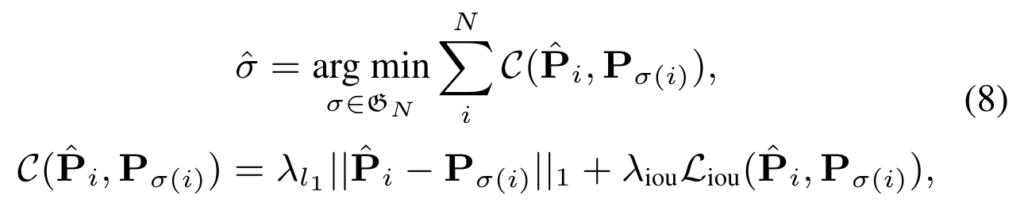
Recursive TSM Parsing을 통해 비디오 마다 N개의 pseudo boundary point를 얻을 수 있고 이를 positional query와 헝가리안 알고리즘을 통해 매칭을 수행시켜주고 L1 Loss와 IoU Loss를 통해 구간을 매칭시켜줍니다. DETR을 활용하는 다른 Video Grounding에서 활용하는 Loss의 형태는 동일하지만 Label이 TSM을 통해 얻은 pseudo label이고 목적은 가변적인 positional query를 정의하기 위함이라 보시면 됩니다.
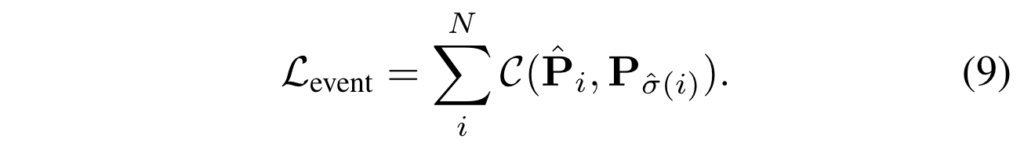
이렇게 N개의 Positional Query와 헝가리안 알고리즘을 통해 매칭된 pseudo boundary 구간과의 event loss를 N번 반복하여 \mathcal{L}_{event}를 정의합니다.
Moment reasoning
앞서 Content Query와 가변적인 Positional Query를 Slot attention과 TSM을 활용한 pseudo boundary를 통해 정의하였습니다. 이제는 Content Query와 가변적인 Positional Query를 활용해 실제 Moment를 예측하는 과정인 Moment Reasoning에 대해서 설명하겠습니다.
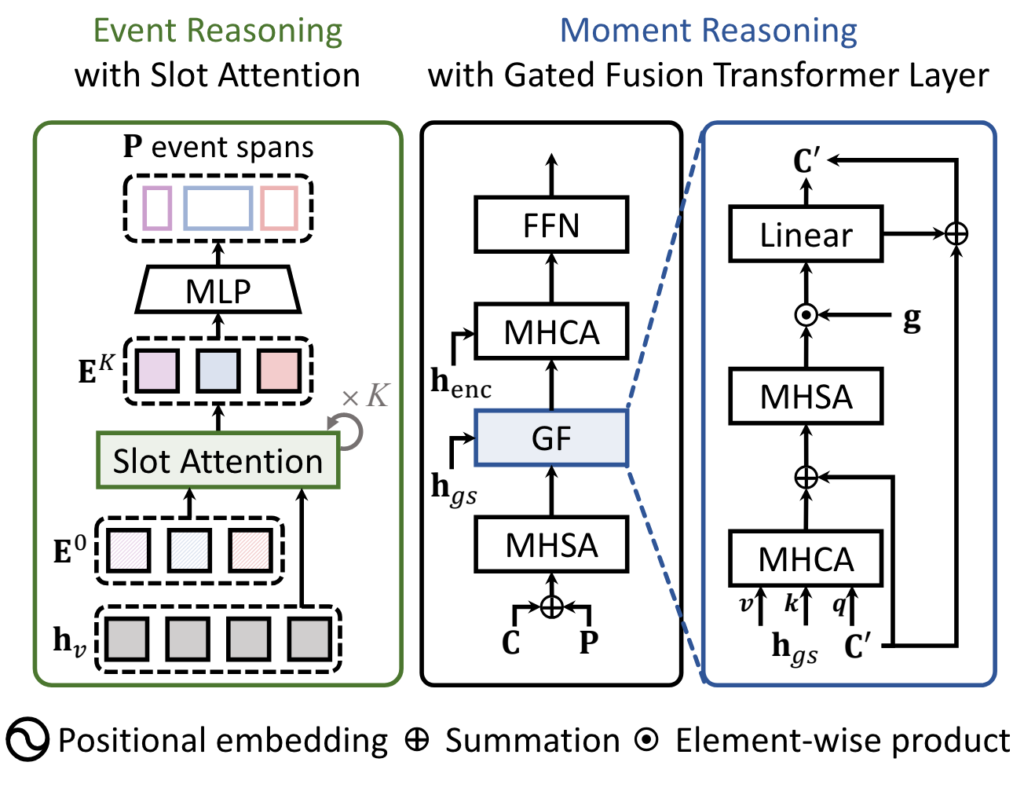
먼저 content query \mathbf{C}와 positional query \mathbf{P}를 활용하여 enhanced momeny query를 정의합니다.
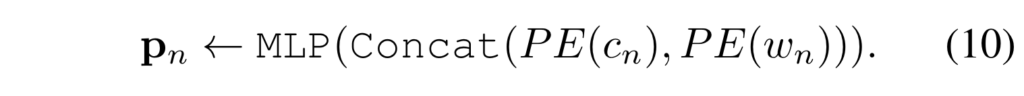
먼저 positional query \mathbf{P}를 다시 d차원의 임베딩이 될 수 있게 sinusoidal position embedding과 projection layer를 통하여 content query와 동일한 차원으로 투영시킵니다.

다음으로는 content query \mathbf{C}와 d차원으로 투영된 positional query \mathbf{P}를 더하고 multihead self attention을 적용하여 enhanced moment query \mathbf{C'}를 정의합니다.
다음으로는 enhanced moment query \mathbf{C'}와 global text representation인 \mathbf{h}_{gs}와의 attention을 적용하여 문장 표현이 적용된 \hat{\mathbf{C}}를 정의합니다. 이 때 global text representation인 \mathbf{h}_{gs}은 text representation인 \mathbf{h}_{s}를 average pooling 한 것이고 global representation이 key, value로 작용합니다.
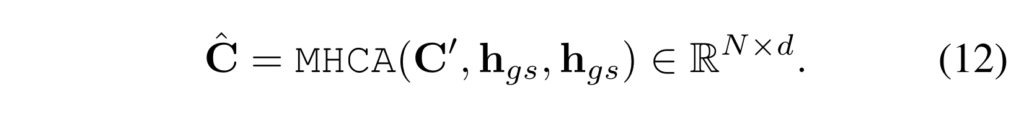
이제는 enhanced moment query \mathbf{C'}와 문장 표현이 적용된 \hat{\mathbf{C}}간의 유사도를 바탕으로 텍스트 문장과 관련 없는 moment query를 gating 하여 attention을 수행합니다. 관련이 없는 query의 영향력을 줄이겠다는 의미로 보시면 됩니다.

자 이렇게 해서 최종적으로 gate fusion까지 타고 나온 \mathbf{C'}를 가지고 moment prediction을 수행합니다.
Gate fusion을 거치고 나서 나머지 T-1의 transformer decoder layer를 거치고 FFN (Feed Forward Network)를 통해 moment query마다 구간을 예측합니다.
나머지는 헝가리안 매칭을 통해 GT 구간과 매칭을 시키고 Loss를 정의하면 되겠네요.

이 부분은 흔하게 사용하는 구조라 자세하게 설명은 하지 않도록 하겠습니다.
Experiments
Comparison with state-of-the-art
먼저 QV Hightlights 에서 Video Grounding과 Highlight Detection 성능 입니다. 우선 Video Grounding에서 모든 지표에서 SoTA는 아니고 몇몇 metric에서 SoTA 모습을 보여주고 있습니다.
Highlight Detection에서는 [41, 74, 46] 방법들에 비해서는 낮은 성능을 보여주고 있는데, 이는 highlight detection 성능이 temporal reasoning 보다는 cross-modal interaction에 더 중요하기 때문에 비교적 낮은 성능을 보여준다고 합니다.
파라미터 관점에서는 그렇게 가볍지는 않고, GFLOPs도 가장 적은게 아니라 QVHightlights 벤치 마킹에서는 부분적 SoTA 정도를 달성했다 그렇게 정리하면 될 거 같습니다.
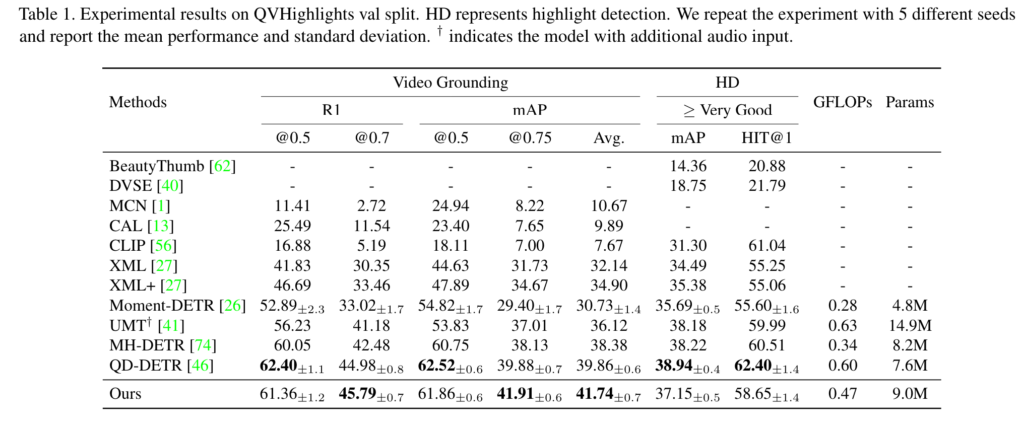
Charades-STA나 ActivityNet Caption 데이터에서는 모두 SoTA를 달성해주고 있습니다. 저자가 밝히기를 EaTR의 경우 다른 방법과 다르게 hand-crafted components가 부분적으로 존재합니다. TSM을 통해 pseudo proposal을 생성하고 후처리도 필요하죠.
대신에 적은 moment query로도 (10개) 정확한 예측을 수행할 수 있어 나름 효율적인 방법이라 어필합니다.
아까 QV Highlights 벤치마킹에서 GFLOPs가 다른 방법에 비해 많은 것도 아니였으니 연산 복잡도 측면에서 그렇게 큰 불편함은 없다고 하는 거 같네요.
Ablation study and discussion
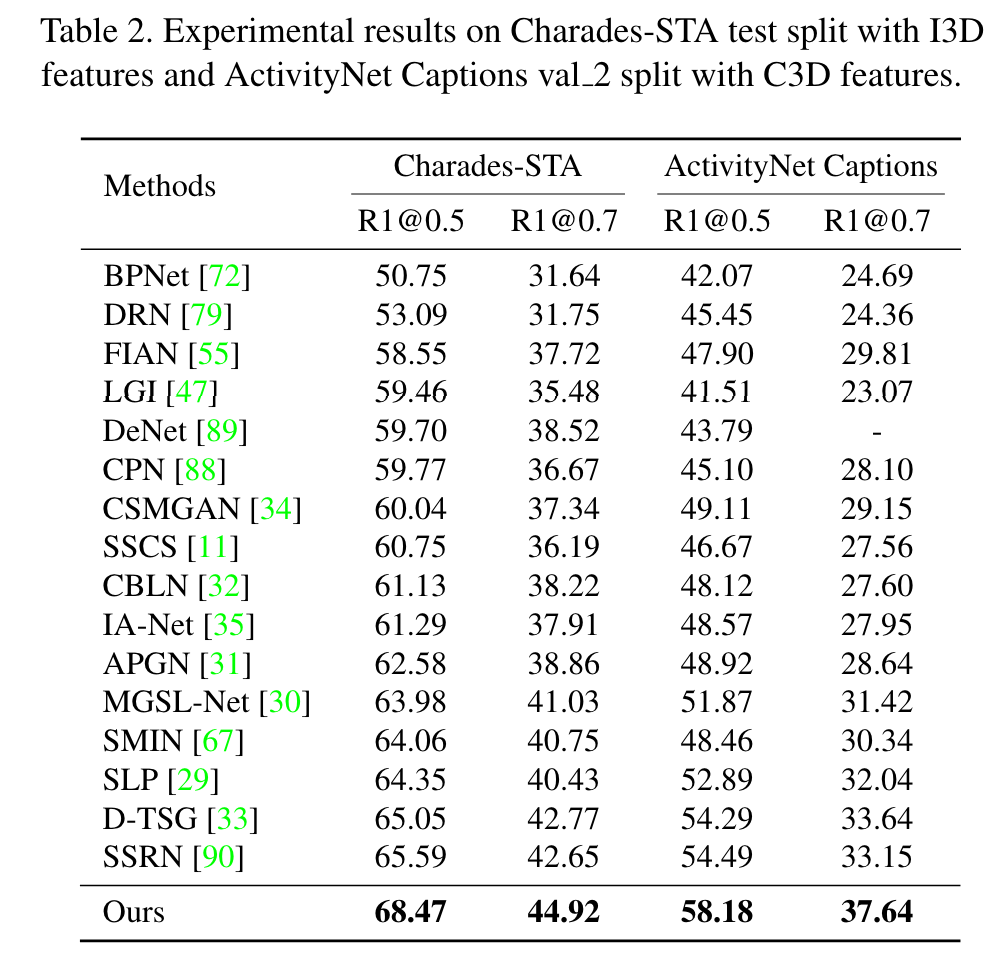
몇 가지 ablation 실험과 분석 실험을 위해서 QV Highlights의 validation set을 활용하여 진행했다고 합니다.
제안하는 모듈이 효과적이고 Event Reasoning 과정에서 mAP가 많이 상승하는 것을 확인할 수 있었습니다.
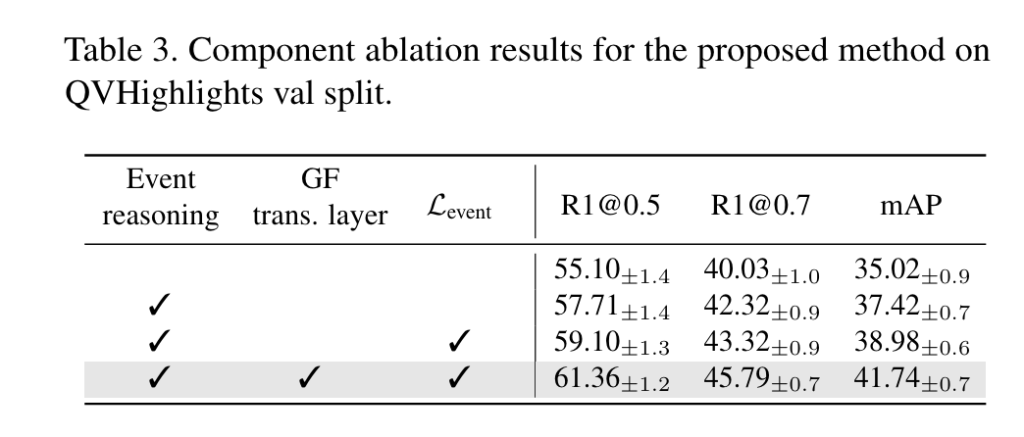
제가 Video Grounding 분야 실험은 아직 많이 돌려보지 못했는데 제가 이전에 많이 리뷰 했던 Weakly Supervised Temporal Action Localization (WTAL) 분야 만큼 파라미터에 민감한지 궁금했는데 바로 관련된 실험이 있네요.
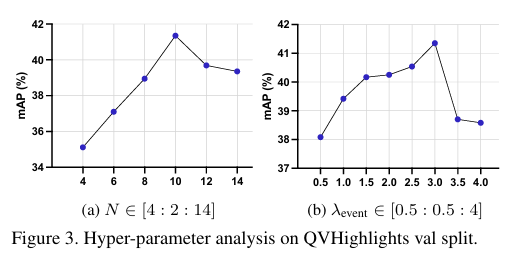
우선 moment query 의 개수 N에 대한 ablation study 입니다. N이 많아지면 referential search area의 개수가 많아지는 것이니 성능이 당연히 올라가지만 계속 많아지면 오히려 long event를 잡기 어렵다고 합니다. 최적의 개수로 설정 하였다고 하는데 이 부분은 데이터 셋 마다 민감한 파라미터로 작용할 거 같은 느낌이 드네요.
다음으로 loss balancing factor에 대한 ablation 인데, 이 부분은 데이터 셋 마다 바뀔 수 있으니 그냥 가볍게 참고하시면 될 거 같습니다.
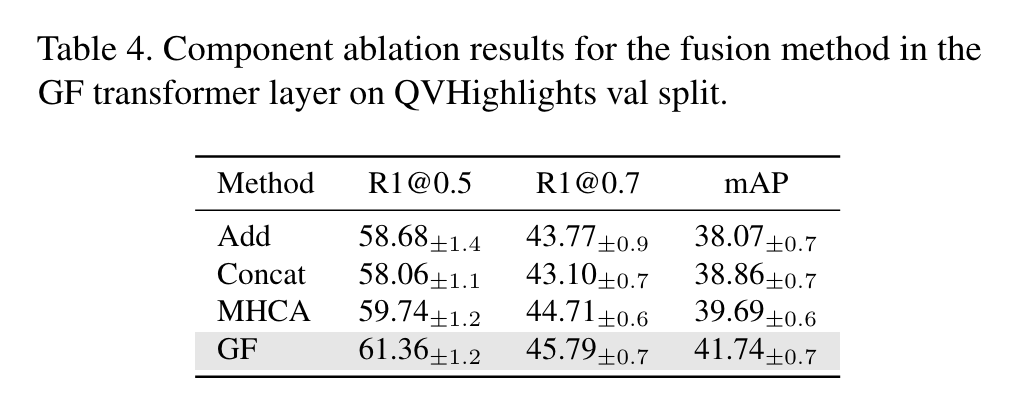
앞서 gate fusion 과정 (아래 수식)에서 선택할 수 있는 design choice 관점의 ablation 입니다. Add나 Concat과 같은 간단한 방식은 비교적 낮은 성능을 보여주고 있고 MHCA라는 attention 방식을 활용해도 만족할만한 성능은 나오지 않고 있습니다.
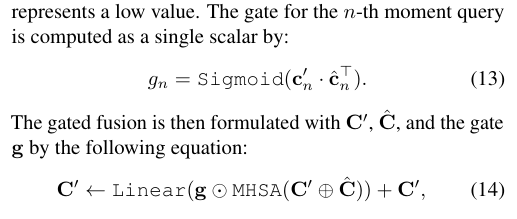
제안하는 방식으로 gate를 생성하고 이를 element-wise 방식으로 곱해주어 gating 연산을 취해 관련 없는 query를 억제해주는 방식이 가장 효과적으로 작용하여 가장 높은 성능을 보여주고 있습니다.
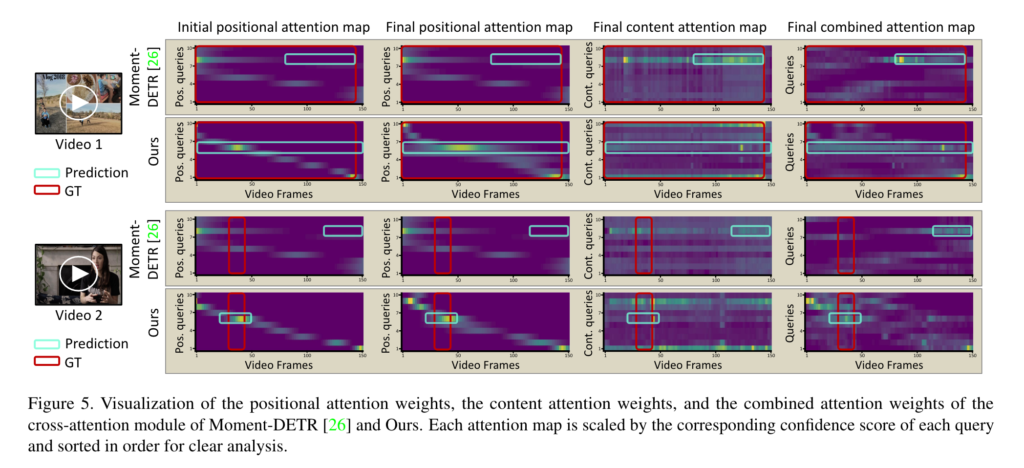
시각화 결과를 보면 Moment-DETR의 초기 positional query는 입력 비디오에 관계없이 고정된 입력에 무관한 검색 영역을 제공합니다. 따라서 Moment-DETR은 비디오-문장 상호 작용의 품질에 크게 의존하며 강조된 positional attention을 무시하고 잘못된 예측을 유발합니다. 한편, 제안하는 EaTR은 비디오에 따라 다른 검색 영역을 제공하여 콘텐츠와 위치 쿼리의 균형 잡힌 기여로 올바른 예측을 수행합니다.
Conclusion
김현우 연구원이랑 박성준 연구원이 앞으로 Video Grounding 분야로 논문 작성을 계획하고 있는데 저도 중간 중간 유의미한 discussion을 할 수 있게 간간히 Video Grounding 논문 좀 읽어야겠습니다.
리뷰 마치겠습니다.
감사합니다.