이번 리뷰 논문은 LangSplat이라는 3D Language Fields (3DLF) 분야의 기법 중 3D Gaussian Splatting (3DGS)을 적용한 방식을 처음 제안한 논문입니다. 3DLF라는 분야도, 3DGS라는 분야도 많이 생소하실 것 같습니다. 차차 설명 드리도록 하겠습니다.
+ 해당 기법을 완전히 이해하려면 사전에 알고 있어야 하는 지식들이 꽤 요구하여 진입 장벽이 있는 편입니다. 허나, 해당 기법 자체는 기존 기법에서 크게 변화가 된 기법은 아니기에 알지 못하는 태스크가 나온다면 일단은 그런 기법이 있구나 하고 넘어가시고 추후 제가 작성하는 혹은 외부 글을 통해 이해하시면 좋을 것 같습니다.
Intro
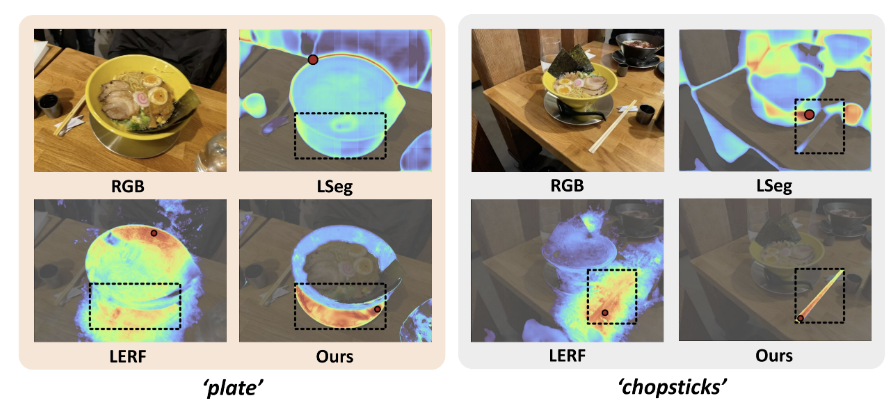
3DLF?. 우리가 살고 있는 세계는 3차원 공간으로 구성되어 있으며, 사람들은 일반적으로 언어 정보를 사용하여 3차원 장면과 상호 작용하는 방식으로 삶을 살아 갑니다. 이러한 특성을 모사하기 위해 최근 들어 open-ended language quries를 3차원 공간에서 상호작용 가능한 3D Language Fields (3DLF)라는 기법이 각광 받고 있습니다. 3DLF는 3차원 장면을 구성하는 데이터들이 해당 하는 객체들을 시각-언어적 특징을 표현 가능하도록 구성한 공간에 해당 합니다. 즉, 위 그림과 같이 ‘plate’나 ‘chopsticks’라는 개방형 언어가 쿼리로 입력된다면, 해당 쿼리의 임베딩 벡터와 3차원 공간의 영역을 구성하는 임베딩 벡터 간의 유사성을 측정하여 쿼리에 해당하는 3차원 공간에 대한 인식이 가능해집니다.
3DLF에 대해서 조금 더 자세히 설명하자면 LERF, CVPR 2023라는 기법에서 처음 제안된 태스크로 novel view synthetic 태스크 중 하나인 NeRF의 렌더링 작업에 CLIP 혹은 DINO와 같은 시각-언어 정보를 표현 가능한 FM 모델의 특징 정보들을 렌더링한 기법이라고 보시면 됩니다. 이번에 소개해드릴 논문은 NeRF의 가장 큰 단점인 느린 학습과 추론 속도를 보완하기 위해 제안된 3D Gaussian Splatting 기법에 SAM과 CLIP을 활용한 시각-언어 정보를 래스터링을 수행한 기법에 해당합니다.
Novel view synthetic. 아마 지금 이 글을 읽고 계신 분들은 위 그림이 3차원 공간인가? 라는 의문을 가질 수 있습니다. 그쵸. 너무 자연스러워서 의심을 할 겁니다. 그럴 수 밖에 없는 것이 해당 기법에서는 novel view synthetic 기법인 NeRF와 3DGS를 기반으로 수행하기 때문에 자연스러운 결과물이 나온 것을 보시면 됩니다. 그럼, novel view synthetic가 무엇인가에 대해서 저희 시각에서 가볍게 설명하고자 합니다. 일단 novel view synthetic라는 태스크는 새로운 카메라 포즈에서도 현실적인 영상 및 깊이 정보를 생성하도록 하는 컴퓨터 비전과 컴퓨터 그래픽스 분야의 교합점인 태스크에 해당합니다. 해당 기법의 파이프라인은 다음과 같습니다.
- 시퀀스한 영상들로부터 structure from motion을 수행하여 3D reconstruction을 수행하여 각 영상의 카메라 포즈와 포인트 클라우드를 추정함
- (Training) 1에서 사용된 프레임 혹은 카메라 포즈를 알고 있는 다른 프레임 셋을 학습/평가 데이터 셋으로 나눠 구성
- (Training) 각 영상들은 서로의 카메라 포즈와 서로의 영상들을 GT 삼아 novel view를 잘 생성하기 위한 함수를 학습 합니다.
- NeRF는 영상의 픽셀과 카메라 포즈를 잇는 ray를 기반으로 렌더링을 수행하는 volume rendering 기법을 근간으로 학습을 진행합니다. 조금 더 구체적으로 설명하면 ray로부터 균등하게 위치한 샘플 포인트의 color와 density를 추정하는 MLP를 구성하여 학습을 진행하는 방식입니다.
- 3D Gaussian Splatting는 1에서 추정된 포인트 클라우드로부터 정해진 양만큼 샘플링을 진행한 뒤, 해당 포인트 클라우드에 타원구 형태의 3D Gaussian을 배치?흝뿌리고(splatting), 3D gaussian들을 구성하는 형태, 스케일을 조절하는 공분산과 컬러, 투명도에 대한 파라미터를 SGD를 통해 직접 최적화하며 학습을 진행합니다. 즉, NeRF랑 다르게 3D Gaussian으로 3차원 장면을 직접적으로 구성하는 기법이기에 3D gaussian을 이용한 rasterization 기법으로 분류됩니다.
- (inference) 새로운 카메라 포즈를 학습된 모델에 입력으로 넣어 새로운 뷰를 생성
해당 기법에 대해서 정리하자면 NeRF와 3DGS는 카메라 기하학을 통해 sparse한 3차원 복원된 영역을 영상들을 활용해 dense 할 뿐만 아니라, 카메라 기하학으로는 얻지 못할 공간에 대해서도 3차원 공간 정보에 대한 추론 가능합니다. 여기서 집중해야 하는 포인트는 해당 기법은 생성 모델이 아니라는 점과 카메라 좌표계와 월드 좌표계 간의 연관성이라는 명확한 큐를 기반으로 학습하는 (과하게 말하면 convex optimaization으로) 문제로 풀어나간다는 점입니다.
그럼 한 발 더 나아가서 이번 리뷰 논문에서는 NeRF가 아닌 3DGS를 사용한 기법을 사용한 이유가 무엇일까요? NeRF는 현재도 가장 높은 정확도를 가진 기법으로 어플리케이션으로도 많이 개발되고 있습니다. 하지만 몇 가지 치명적인 단점이 존재합니다. NeRF의 단점은 다음과 같습니다.
- 느린 학습 속도 (7.5min~2days 소요)
- 느린 추론 속도 (9~0.75fps)
- 한 장면 당 하나의 모델만 사용 가능
- 장면에 대한 일반화가 불가능하기 때문에 관련 연구 진행 중
- 동적 객체에 대한 대응 불가능
- + 기존 3DGS에서도 동적 객체는 해결하기 힘드나, 3D gaussian->4D gaussian으로 확장하여 표현이 가능함. 이에 대한 관한 연구들도 활발히 진행 중
위와 같은 한계로 실시간성이 중요한 로보틱스와 다른 분야에서는 적극적으로 활용하기에는 큰 제약 조건이 존재합니다. NeRF의 느린 실시간성을 해결하기 위해 제안된 기법이 3DGS로 최초의 기법(Kerbl. Benrhard. et.al SIGGRAPH 2023)에서 조차 학습 속도는 6.1min, 추론 속도는 167.9fps를 달성하면서도 성능은 NeRF의 SOTA에 준하는 성능을 보여줍니다. 저자는 3DGS의 NeRF 대비 강한 장점을 활용하고자 3DGS를 적용한 것으로 보입니다.
3DLF. 다시 3DLF로 돌아와서, 3DLF는 novel view synthetic으로부터 추정된 3차원 공간에 시각-언어를 이용한 인지 능력을 부여하는 기법에 해당합니다. 앞서 설명한 바와 같이 novel view synthetic는 여러 카메라 포즈와 이와 대응되는 영상을 이용하여 서로의 뷰를 잘 추정하도록 학습을 진행합니다. 즉, 각 영상 내 RGB 값들이 GT로 활용되는 방식입니다. 3DLF는 이러한 특징을 이용한 트릭을 사용합니다. 영상 정보로부터 시각-언어 모델로 추정된 특징을 영상 크기와 동일하게 업샘플링하여 픽셀에 RGB와 해당 픽셀의 시각-언어 특징을 배치하도록 하여 해당 특징 정보들을 렌더링/래스터링을 수행하도록 합니다. 이를 통해, 3차원 공간은 색상 정보 뿐만이 아니라 시각-언어 특징 정보들도 추정 할 수 있게 됩니다.
그럼, 3DLF는 어디에 활용 가능할까요? 해당 기법을 처음 제안한 논문에서는 해당 태스크의 평가 방법으로 open-vocalbulary langugage qeyry를 입력으로 Localization & 3D Semantic Segmentation을 수행하여 평가를 진행합니다. 즉, 상단의 그림과 3차원 복원을 수행하는 것 뿐만이 아니라 같이 학습을 한 적도 없는 ‘chospsticks’를 입력으로 넣고 3D Semnatic Segmentation을 수행하는 태스크에 해당합니다.
생소한 태스크라 설명이 길어졌습니다. 다음 파트에서는 해당 기법의 method를 설명하도록 하겠습니다. 아마… 매우 간단할거라 겁 먹지 않으셔도 됩니다.
Method
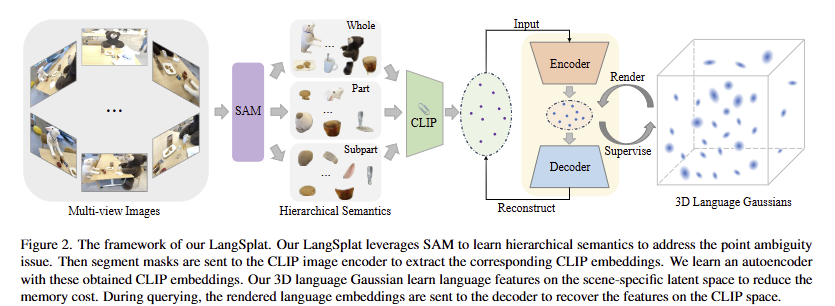
Revisiting the Challenges of Language Field. 먼저, height H와 width W로 구성된 입력 이미지 I가 있고, 해당 이미지에 대한 캘리브레이션 이미지 셋 [latext] \{ I_t | t = 1, 2, … T\} [/latex]가 존재하며, 해당 이미지들을 이용해 학습하는 3D language field Φ가 있다고 정의합니다. 기존 기법에서는 CLIP image encoder V로부터 영상 특징을 추출하고 해당 특징 정보를 활용해 3D language field Φ를 지도 학습 하는 방법을 채택합니다. 허나, CLIP image encoder V로부터 생성된 정보들은 픽셀 수준의 특징이 아니라 영상 수준의 특징으로 직접적으로 렌더링을 수행하기에는 어려움이 존재합니다. 기존 기법 중 픽셀 수준의 특징을 생성(DINO v2 기반)하는 경우, 객체의 단일 지점에서 여러 의미 수준의 영역에 모호성 문제에 직면합니다. 즉, 고양이 귀를 한 지점으로 보았을 때, 해당 지점에 대한 의미론적인 정보는 고양이 귀 뿐만이 아니라 고양이 머리 및 고양이 자체를 동시에 텍스트 쿼리에 활성화 되어야만 합니다. 이러한 문제를 해결하기 위해서 기존 방법론에서는 잘린 이미지 패치에서 CLIP을 추출하는 계층 구조의 특징 정보를 추정합니다. 즉, 영상을 여러 스케일의 패치로 쪼갠 이미지 패치를 CLIP으로 특징을 추출하고 계층적 특징을 concat하여 활용하는 방식을 사용합니다. 허나, 해당 기법은 패치 내 대상 객체 외의 정보들을 포함하는 경우가 존재하여 부정확하며, 패치 수에 따라 추론 속도가 크게 증가하는 문제점이 존재합니다.
또 다른 관점은 기존 기법들은 NeRF를 활용하여 렌더링을 수행하나, 해당 기법은 실시간 렌더링을 달성 할 수 없기 때문에 한계가 존재합니다.
Learning Hierarchical Semantics with SAM. 저자는 앞서 언급한 여러 의미 수준의 영역에 대한 모호성 문제를 해결하기 위해서 SAM을 활용하는 방법을 제안합니다. 객체 중심으로 계층적 분할을 목적으로 whole, part, subpart로 구분되도록 point prompt를 입력합니다. 구체적으로 32×32 point prompt를 SAM에 공급하여 3개의 다른 의미 수준 마스크 M_0^s, M_0^p, M_0^w 를 얻습니다. 그런 다음 예측된 IoU score, stability score와 overlap rate between masks를 기반으로 3개의 마스크 셋에서 중복 마스크를 제거합니다. 그런 다음, 객체 중심으로 분할된 마스크에 해당 하는 영상 영역에 대한 CLIP 특징을 추출합니다.
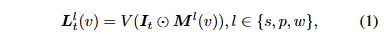
이로써, 픽셀 수준으로 계층적 의미 맥락이 일치 특징맵을 생성하게 됩니다.
3D Gaussian Splatting for Language Fields. 여기서는 3D 점과 2D 픽셀 간의 관계를 모델링 하면서 이미지로부터 컬러 정보에 대한 모델링과 동일하게 언어 임베딩된 특징 정보를 학습 할 수 있습니다. 기존 NeRF를 활용한 기법에서는 렌더링 프로세스에서 많은 비용이 든다는 문제점이 있습니다. 이러한 문제점을 해결하기 위해 3D Gaussian Splatting 기반의 3D language field modeling을 제안합니다. 3D Gaussian splatting은 3D 장면을 anisotropic 3D Gaussians 모음으로 명시적으로 표현하며, 각 gaussian G(x)는 평균 μ ∈ R3와 공분산 행렬 Σ로 특성화됩니다.
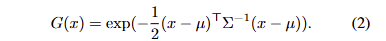
3D gaussian의 parameters를 최적화하기 위해 각 값들은 2차원 영상 평면으로 렌더링되고 tile-based raterizer를 사용하여 렌더링을 수행합니다.
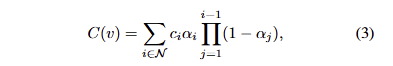
여기서, c_i 는 i-th gaussian의 color, N은 tile 수, C(v)는 픽셀 v에서 렌더링된 color, \alpha_i = o_iG+i^{2}(v) , o_i 는 i-th gaussian의 opacity, G_i^{2D}() 는i-th gaussian porjected onto 2D의 함수를 의미합니다.
+ 해당 방법 외에도 생략된 내용이 많은데 3DGS에 대한 자세한 내용은 다음 리뷰에서 다시 다루도록 하겠습니다. 여기서는 기존 3DGS에서는 수식 3을 이용하여 2D 영상과 3D의 연관성을 학습하는 구나 하고 넘어가시면 됩니다.
해당 논문에서는 3가지 언어 임베딩 \{ f^s, f^p, f^w \} 으로 각 3D gaussian을 증강하는 3D language Gussian Splatting을 제안합니다. 방법은 아주 간단합니다. 앞서 SAM과 CLIP으로 추출한 계층적 의미 특징맵을 활용합니다.
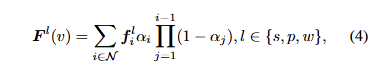
이를 통해, color를 렌더링 하듯이 언어 임베딩을 렌더링 수행이 가능해집니다.
추가로 저자는 CLIP 임베딩 특징의 차원이 512차원이기에 해당 특징을 그대로 사용할 경우에는 메모리가 35배 이상 증가하여 학습이 불가능해진다고 이야기합니다. 이러한 문제를 해결하기 위해 CLIP 특징을 저차원 공간에 맵핑하기 위한 autoencoder를 사용합니다. 이는 다음과 같은 목적 함수로 학습이 진행됩니다.
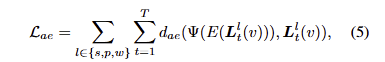
여기서 저차원 공간에 맵핑하기 위한 encoder E와 원래 CLIP 임베딩으로 복원하기 위한 decoder Ψ에 해당합니다. 여기서 loss (d_ae)는 L1과 cosine distance loss를 활용합니다.
저자는 d=3으로 H_t^l(v) = E(L_t^l(v)) 의 차원 축소하여 래스터링을 수행합니다. 저차원으로 맵핑된 언어 임베딩은 다음과 같은 목적 함수로 최적화를 수행합니다.
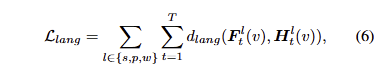
여기서 d_lang은 L1을 사용합니다.
+ 수식 6이 오류가 있는 것 같습니다. 코드를 확인해보니 둘 다 동일한 H를 이용하며, d_lang에 대한 정보가 누락되어 있네요.
추론에서는 디코더를 통해 H를 복원하여 사용합니다.
Open-vocabulary Querying. 해당 파트에서는 쿼리로부터 어떻게 매칭시키는 방법에 대해 설명합니다. 해당 파트는 LERF를 따라 각 텍스트 쿼리에 대한 relevancy score를 계산하여 매칭을 수행합니다. 구체적으로 각 rendered language embedding \phi_{img} 와 각 텍스트 쿼리 \phi_{qry} 에 대한 relevancy score는 다음과 같은 수식으로 정의됩니다.
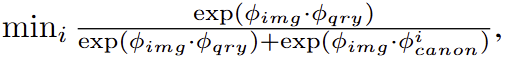
여기서 \phi_{canon}^i 는 사전 정의된 ‘object’, ‘things’, ‘stuff’, ‘texture’에 대한 표준 구문에 해당합니다.
따라서, 예측된 계층적 의미맵에 따라 3개(whole, part, subpart)의 relevancy scores를 얻게 됩니다. LERF를 따라 가장높은 값을 가진 계층적 의미맵을 선택하여 사용합니다.
Experiment
Datasets. LERF에서 제안한 데이터 셋과 3D-OVS datasets을 활용…
Implementation Details. OpenCLIP ViT-B/16, SAM (ViT-H) 사용. 학습 과정은 2,500,000 points를 샘플링하여 RGB를 먼저 30,000 iterations을 진행하고 나서, 다른 파라미터는 고정하고 언어 임베딩만 30,000 iterations 반복해서 학습을 진행. auto-encoder는 512->3차원으로 압축하는 MLP로 구현. GPU는 1440 x 1080 해상도에서 an NVIDIA RTX-3090에서 ~25분 동안 학습했으며, 대략 4GB 메모리 사용
Results on the LERF dataset
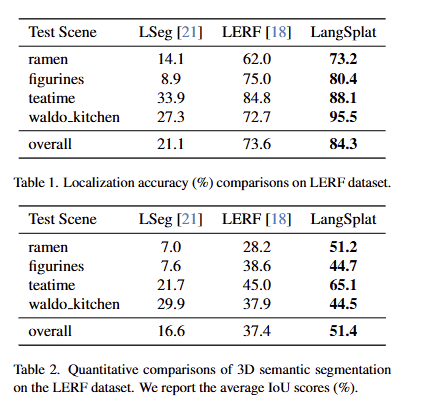

가장 우수한 결과를 보임
Ablation Study

SAM을 이용하는 기법을 추가하는 것만으로도 성능과 추론 속도 향상된 결과를 보여줌. 또한, AE를 사용하지 않고 3DGS에 적용하는 경우에는 Out-Of-Memory가 발생하는 것에 반해 AE를 추가하는 경우, 이 또한 해결되고 성능이 향상된 결과를 보여줌
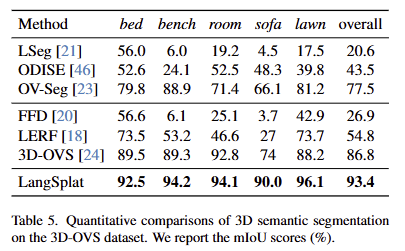
3D-OVS results

안녕하세요, 좋은 리뷰 감사합니다.
NeRF의 고도화 이어 또 굉장한 게 나와 발전이 정말 빠른 것 같습니다.
질문 몇 가지만 남겨놓겠습니다.
1. SAM을 거쳐 나온 mask를 3개의 수준으로 마스크로 얻을 때, 3개의 score를 이용하여 최종 mask를 사용하게 되는데, stability score는 어떻게 구하는 건가요?
2. 또한, 해당 마스크는 occlusion 같은 상황에서도 강인하게 동작하려면 visibility ratio(물체가 보이는 정도)를 고려하는 부분도 있는지 궁금합니다.
감사합니다.
1. SAM을 거쳐 나온 mask를 3개의 수준으로 마스크로 얻을 때, 3개의 score를 이용하여 최종 mask를 사용하게 되는데, stability score는 어떻게 구하는 건가요?
-> stability score는 SAM에서 나온 값을 사용합니다,
2. 또한, 해당 마스크는 occlusion 같은 상황에서도 강인하게 동작하려면 visibility ratio(물체가 보이는 정도)를 고려하는 부분도 있는지 궁금합니다.
-> 딱히 없지만… 시차에 따른 일관성을 유지하기 위해서 visibility ratio 추정 할 수 있다면 좋을 것 같긴 합니다.