
안녕하세요. 허재연입니다. 한동안 계속 Self-Supervised Learning쪽 논문을 읽고 있습니다. 이번에 다룰 논문도 image data의 visual feature를 어떻게 unsupervised방법으로 학습할 지를 다룬 visual representation learning 분야 논문입니다. Facebook에서 나온 논문으로, SSL 논문을 읽을 때 실험 부분에서 자주 등장하는 방법론이기도 하고 인용수도 높아서(24년 5월 말 기준 약 3580회) 읽어보게 되었습니다. 리뷰 시작하겠습니다.
Introduction
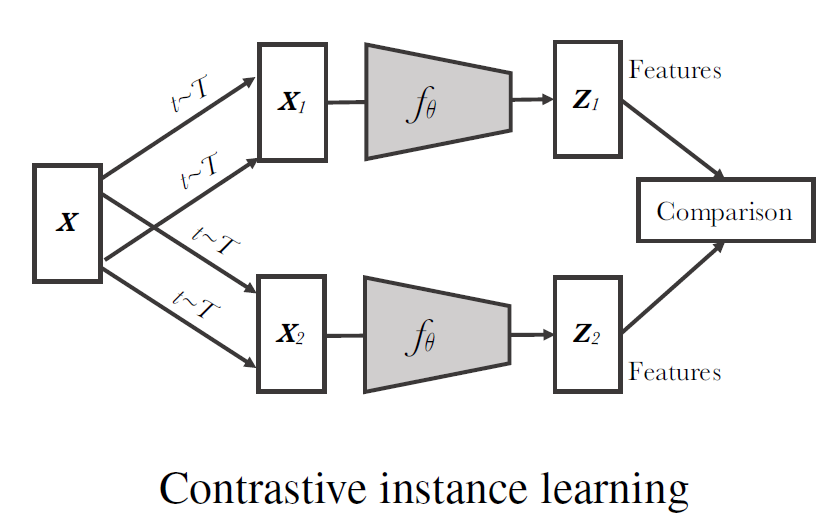
Self-Supervised Learning(SSL)은 unlabeled dataset을 이용해서 좋은 visual representation을 얻는 것을 목적으로 합니다. 데이터 자체의 라벨값을 활용할 수 없으므로 임의로 특정 task를 설계해 학습을 진행하게 되는데, 특히 contrastive learning을 이용한 방법론이 많이 사용됩니다. Contrastive Learning을 이용하는 다양한 방법론들이 있는데, 대부분은 바로 위 그림의 프레임워크를 이용합니다. 일단 한 이미지 x에 대해 서로 다른 random augmentation을 가해 x1과 x2를 만들고 ResNet과 같은 feature extractor에 태워 representation vector z1,z2을 얻습니다. 그리고 이렇게 얻은 z1,z2에 대해 contrastive loss를 이용한 contrastive learning을 진행합니다(보통은 z1,z2끼리 바로 contrastive learning을 진행하기보다는, 작은 MLP인 projector를 한번 더 거쳐 얻은 임베딩 벡터끼리 contrastive learning을 진행합니다). contrastive learning은 동일한 이미지에서 나온 벡터 쌍(positive pair)끼리는 거리가 가까워지도록, 다른 이미지에서 나온 벡터 쌍(negative pair)끼리는 거리가 멀어지도록 학습합니다. 일반적으로 코사인 유사도를 계산하여 hypersphere 위에 임베딩된 벡터 간 유사도가 커지도록/작아지도록 합니다. 이러한 방법들은 결국 data instance끼리 비교를 통해 학습이 진행되기 때문에 비교할 negative pair가 많아져야 제대로 된 성능을 낼 수 있고, 따라서 매우 큰 batch size를 사용하거나 데이터를 저장하는 memory bank 등의 구조를 이용하게 됩니다. 즉, 큰 메모리가 필요하다는 한계점이 있습니다.
방금 설명한 contrastive learing은 data instance끼리 비교하는 방법인데, 클러스터링을 이용해 각각 이미지 데이터가 아닌 비슷한 특징을 가진 이미지 그룹 간 discrimination을 이용할 수도 있습니다. 하지만 클러스터링 방법들은 학습 도중 계속 전체 데이터에 대해 이미지의 code(cluster assignments)를 할당해 주어야하기 때문에 학습 도중 이용하기 쉽지 않고(학습 과정과 step이 분리되어있기 때문에 offline learning이라고 합니다), 그 규모를 늘리기도 쉽지 않습니다.
저자들은 code를 온라인으로 계산하며 동일한 이미지에서 얻은 code 간 일관성을 유지하도록 합니다. cluster assignments를 비교하는 것은 이미지를 pairwise로 비교하는것에 의존하지 않고 다른 image views에 대해 잘 동작하게 된다고 합니다. 저자들은 이에 다른 view의 representation에서 얻은 code를 예측하는 swapped prediction problem을 푸는 방법론을 제안합니다. 이 방법을 Swapping Assignments between multiple Views of the same image (SwAV)를 통한 특징 학습이라고 합니다. code와 feature는 online으로 학습되어 데이터의 양에 의존하지 않도록 할 수 있습니다(기존 contrastive learning은 pairwise 비교를 통해 학습하므로 한번에 많은 데이터가 필요했었죠). 이 방법을 통해 배치 사이즈를 작게, 그리고 memory bank나 momentum encoder의 구조 없이 학습이 가능하도록 만들었다고 합니다.
저자들은 online clustering 기반 방법 이외에도 새로운 augmentation기법을 제안합니다. 학습 과정에서 많은 view를 사용하는것이 성능 향상에 유리함에도 불구하고, 기존의 contrastive learning 방법들은 이미지 당 한 쌍만을 사용하여 contrastive learning을 진행했다고 합니다(아마 계산 비용 급증때문에 그런 것으로 생각됩니다). 저자들은 학습 도중 메모리나 계산 자원을 크게 증가시키기 않으며 작은 이미지를 사용해 view의 수를 늘리는 ‘multi-crop’이라는 방법을 제안합니다.
저자들은 제안하는 방법론은 ImageNet linear evaluation에서 SimCLR, DeepCluster 등 당시의 SOTA 모델들보다 좋은 성능을 달성하는데 성공했다고 합니다. 저자들은 본인들의 contribution을 다음과 같이 주장합니다 :
- 저자들은 큰 memory bank나 momentum encoder 없이 작은/큰 배치 사이즈 모두에서 잘 작동하는 scalable online clustering loss를 제안한다.
- 저자들은 추가적으로 큰 계산 및 메모리를 필요로 하지 않고 이미지의 view 수를 늘리는 multi-crop 전략을 소개한다
- 위 두 방법을 결합하여 ImageNet 평가에서 기존보다 4%에 달하는 성능 개선을 보였으며, 여러 downsteram task에서의 평가에서도 좋은 성능을 보였다.
Method
(공식 github에서 가져온 자료입니다. 이해에 도움이 될 것 같아 첨부합니다)
Swapped prediction problem
저자들의 목적은 supervision 없이 online 방식으로 visual feature를 학습하는 것이기에, online-clustering 기반 self-supervised learning 방법을 설계하였습니다. 일반적인 clustering 방법들은 전체 데이터셋의 image feature를 클러스터링하는 cluster assignment 단계와 cluster assignments(codes)가 다른 이미지에 대해서 예측되는 training step으로 나눠져 있습니다. 이러한 방법은 모든 데이터에 대해 feature를 매번 새로 추출해야 하기 때문에 target이 계속 변하는 online 학습에는 적합하지 않습니다. 이에 본 논문에서는동일한 이미지에서 나온 다른 view에 대한 code 간 consistency를 유지할 수 있는 online-clustering based self-supervised learning mehtod를 제안합니다. 이 방법은 contrastive instance learning에서 아이디어를 얻은건데, code를 target으로 간주하지 않고 동일 이미지에서 나온 view 간의 매핑을 일관성있게 하도록 합니다. 이는 multiple image views들의 instance feature 대신 cluster assignment를 비교하는 contrasting으로 해석할 수 있습니다.
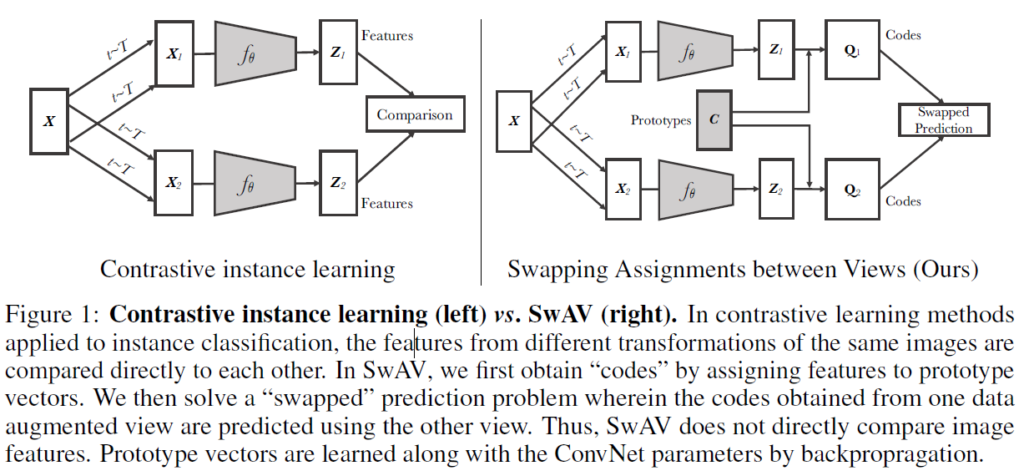
논문에서 제시한 Figure를 보면서 설명드리겠습니다. 일단, 왼쪽에는 기존에 사용되던 contrastive learning 방법이고, 오른쪽 그림이 저자들이 제안한 SwAV framework입니다. X는 input image, X1,X2는 서로 다르게 증강된 이미지, f는 feature extractor(ResNet 등), z1,z2는 feature extractor를 거치고 나온 representation vector입니다. SwAV가 왼쪽과 다른 점은 Prototypes C와 Codes Q가 있다는 점, 그리고 feature 간 비교가 아닌 swapped prediction을 통해 학습을 한다는 점입니다. SwAV에서는 일단 features를 prototype vector C로 할당(assign)하여 code를 얻습니다. 그 이후에는 representation 끼리 서로 직접 비교하지 않고, 동일 이미지의 다른 augmentation zt에서 다른 Code qt를 예측하는 작업을 통해 학습을 진행합니다. 여기서 prototype은 학습 가능한 벡터이고, Codes Qt,Qs는 각각 두 image features zt, zs를 c에 매핑하여 계산된 code입니다. 최종 prototype은 K개의 column prototype vectors를 나열한 행렬 형태로 기술하며, C = {c1, … , ck}와 같이 표현됩니다.
swapped prediction problem은 다음 loss함수로 학습하게 됩니다 :
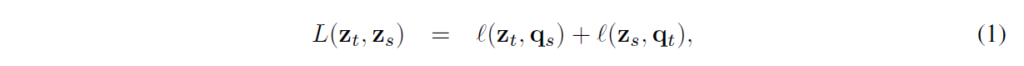
2개의 각 loss term은 z가 q에 얼마나 매칭되는지를 측정하는데, 각각이 그냥 cross-entropy입니다, z와 c간 내적한 값에 softmax를 거친 확률과 code q를 비교합니다.
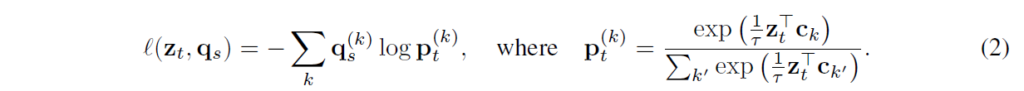
이를 통해 z로 다른 view의 code를 예측하는 학습을 설계하였습니다. (1), (2)번 식을 풀어서 정리하면 다음과 같이 기술할 수 있습니다 :
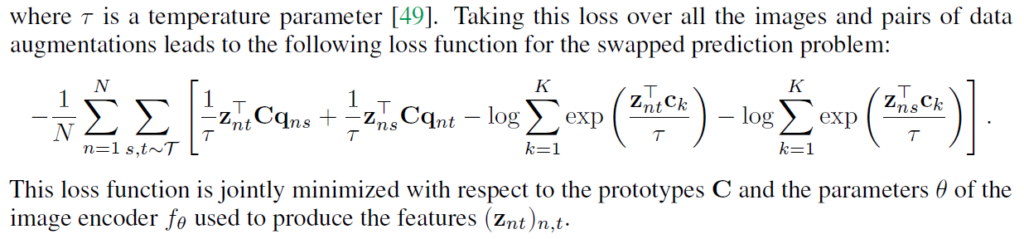
이 loss함수를 이용하면 prototype C와 학습의 본래 목표인 feature extractor(image encoder) f를 함께 최적화할 수 있습니다.
Computing codes online
위에서 z를 학습가능한 prototype vector C와 매칭해 Q라는 code를 구한다고 했었는데, prototype이 무엇이냐? 라는 의문이 드실 수 있습니다. 여기 부분에서 해당 내용이 다루어지는데, 낯선 개념이 등장해서 이해가 상당히 힘들었습니다.
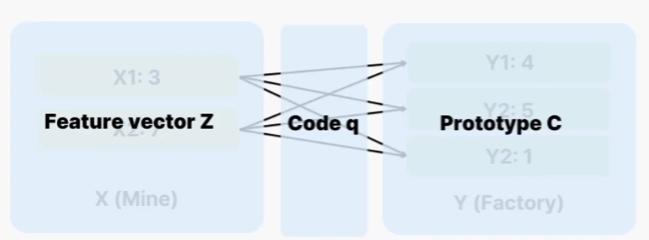
online으로 작동하게 하기 위해 배치 안의 image feature들에 대해서 code가 계산합니다. 이 때 모든 sample이 같은 code로 mapping되는 trivial solution을 방지하기 위해 batch 안의 서로 다른 sample들이 prototype C에 의해 균등하게 분배되도록 합니다. 여기서의 목적은 주어진 B개의 feature vectors Z={z1, … , zB}를 prototype C={c1, … ck}에 매핑하는 것이며, 이 매핑(code)를 Q=[q1, … , zB]로 표기했습니다. 그리 feature와 prototype 간 유사도가 최대가 되도록 Q를 최적화하게 됩니다. 이를 transportation problem이라고 한다고 합니다. transportation problem은 처음 보는 개념인데, 정리하면 cost를 고려하여 X에서 Y로 가는 최적의 transportation plan을 찾는 문제입니다.

위 그림에서 마트 X1,X2가 있고, X1에는 매일 3개의 사과가, X2에는 매일 7개의 사과가 입고된다고 가정해봅시다. Y1,2,3은 각각 빵집인데, 사과파이를 만들기 위해 각각 4,5,1개의 사과가 필요합니다. 이 때 모든 마트의 사과를 모든 빵집에 운송하기 위애 어디서 얼만큼 어디로 운송할 지 매핑하는 전략에 관한 문제가 transportation problem이라고 한다고 합니다. 이를 본 논문의 매핑 전략에 대입해보면 다음과 같습니다 :
cost를 최소화하는 transport plan을 찾는것이 목표이며, 여기에는 Sinkhorn Algorithm이라는 알고리즘이 사용된다고 합니다. 최적화는 다음 식을 통해 진행됩니다 :
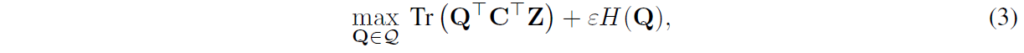
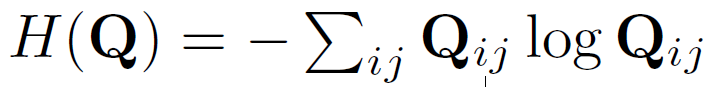
H는 entropy function으로, 파라미터를 통해 매핑의 강도를 조절해준다고 합니다.
최종적인 SwAV의 학습 과정은 다음과 같습니다 :

Multi-Crop : Augmenting views with smaller images
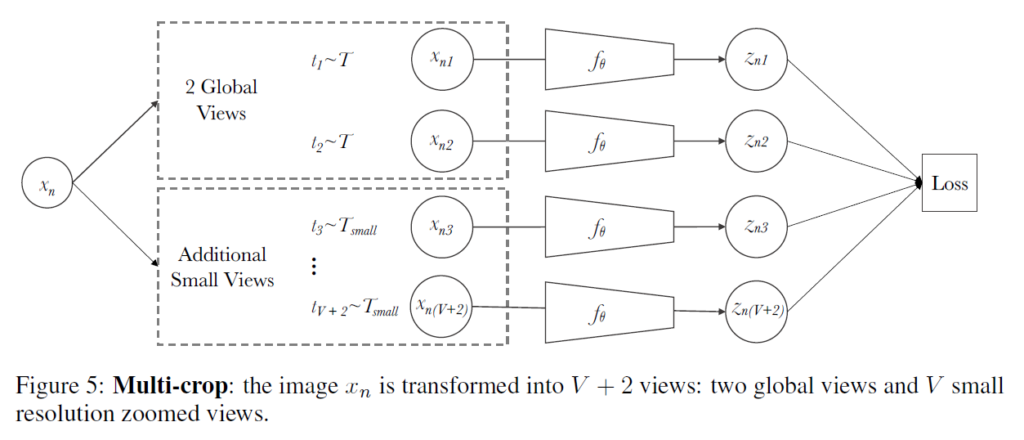
contrastive learning의 view 수를 늘리는것은 성능 향상에 좋은 영향을 끼치지만, view 수를 늘리면 연산량 및 메모리 요구량이 급증하기 때문에 쉽지 않다고 합니다. SwAV에서는 2개의 일반적인 crop/resized 이미지와 추가적으로 V개의 저해상도 random crop/resized 이미지를 사용합니다(V+2개). 새로운 augmentation 이라고 해서 이미지를 다르게 변환할 줄 알았는데 그냥 저해상도 이미지를 loss에 추가해 연산량이 크지 않도록 했네요. 최종 loss는 다음과 같이 다시 작성할 수 있습니다.
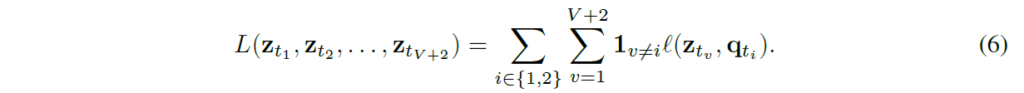
Experiment
저자들은 다양한 데이터셋에 대한 전이학습으로 SwAV를 평가하였습니다.
일단 ImageNet에 대해서는 2가지 방식으로 평가가 진행됐는데, 학습한 feature를 고정하고 linear classification으로 평가하는 linear evaluation과 적은 개수의 라벨만 이용하여 fine-tuning한 semi-supervised learning측면에서 평가가 진행되었습니다.
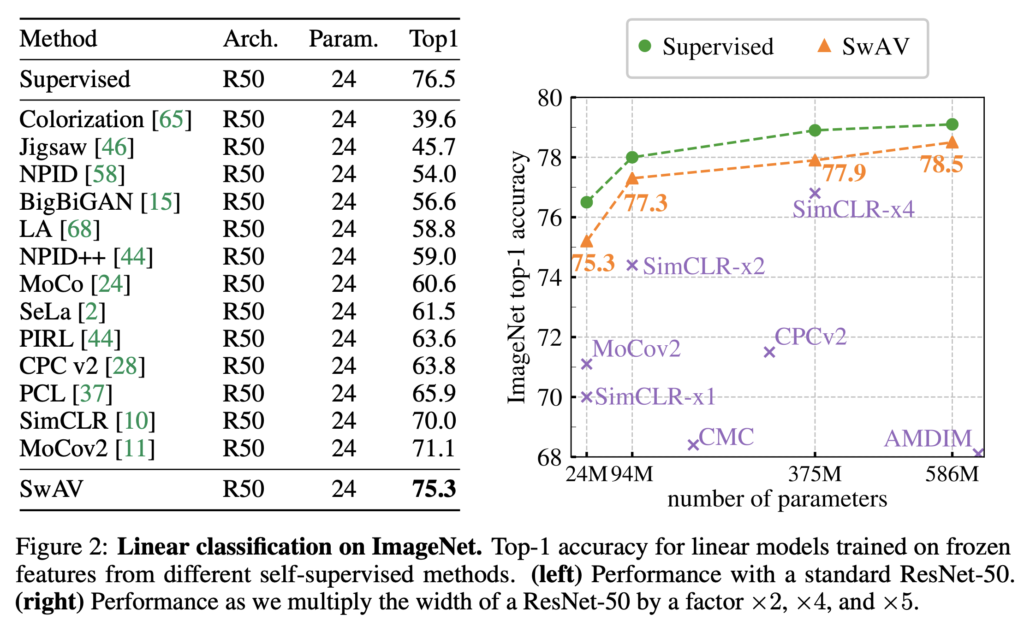
Figure2는 linear evaluation의 결과입니다. SwAV는 실험 결과 당시 SOTA였던 SimCLR를 4%가까운 성능 개선으로 제치고, supervised learning과는 1%정도의 차이를 보이며 거의 근접한 결과를 보였습니다.
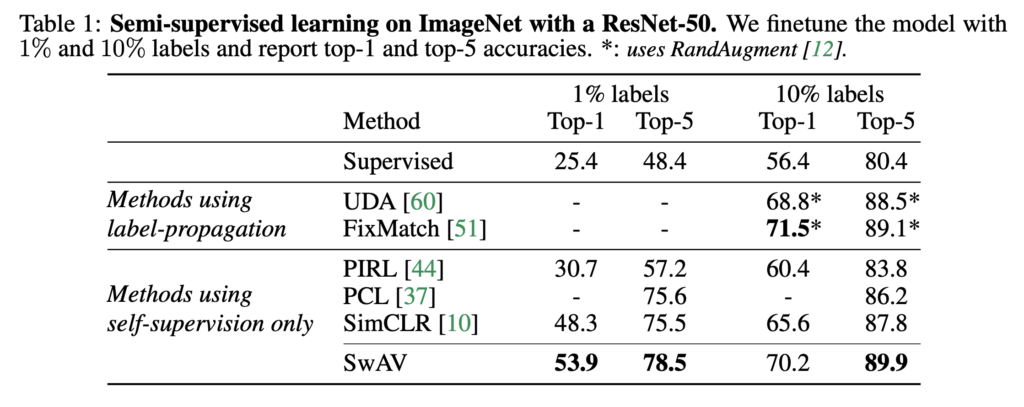
Semi-Supervised Learning 측면에서의 평가는 전체 labeled data의 1% 및 10%만 사용하여 finetuning 한 뒤 진행되었습니다. 해당 실험에서도 self-supervised learning 방법들(PIRL, PCL, SimCLR)과의 비교에서는 큰 폭으로 가장 좋은 결과를 보여주었습니다.
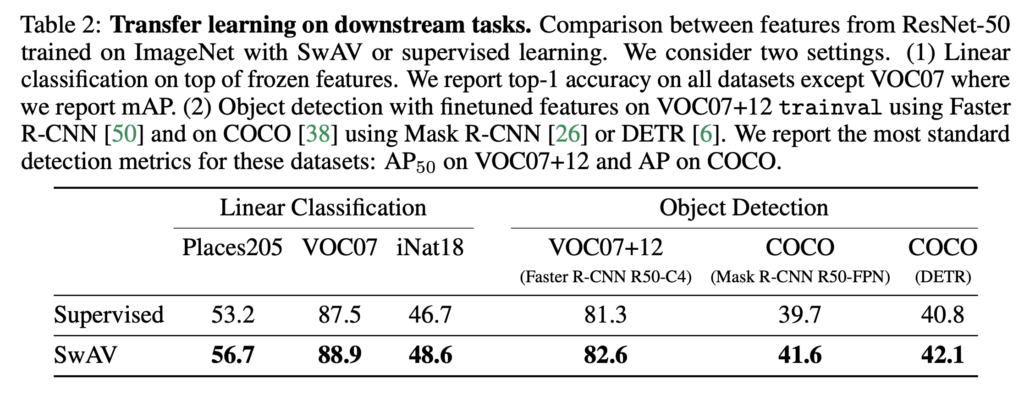
downstream task에 대한 transfer learning 실험에서는 VOC, COCO, Places205 등의 데이터셋으로 평가가 진행되었습니다. linear classification에서는 top-1 accuracy 및 mAP(VOC07)를, Object detection에서는 AP50(VOC)와 AP(COCO)로 평가했다고 합니다. 해당 실험에서는 모두 supervised feature보다 개선된 성능을 보인 것을 확인할 수 있습니다. 아무래도 classification에서 평가하는 것은 supervised learning 자체가 ImageNet에서 classification으로 학습된 feature이기때문에 supervised learning보다 약간 부족한 결과를 보였지만, 이외의 task에서 사용하기에는 충분히 좋은 representation을 학습한 것을 확인할 수 있습니다(OD에서 self-supervised learning을 제친 것이 SwAV가 최초인것은 아닙니다).
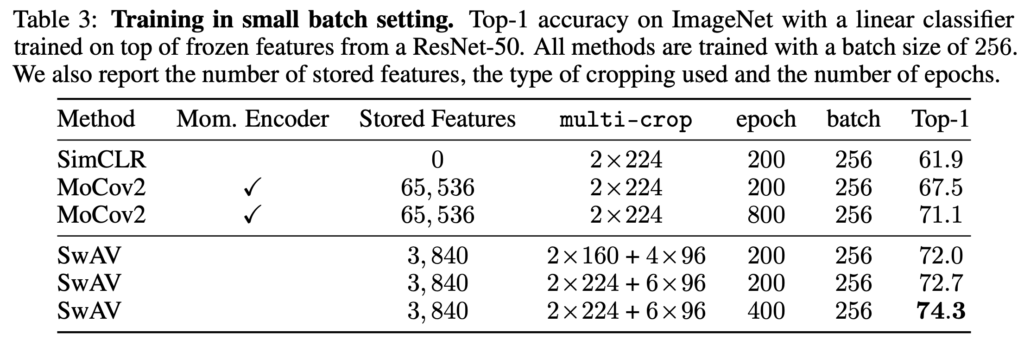
앞에서 SwAV의 장점이 큰 배치를 활용하지 않아도 되는 것이라고 언급했었는데, 이에 대한 실험 결과입니다. 작은 배치 환경에서 실험이 수행되었습니다. contrastive learning 방법론들은 negative pair의 수가 많아야 좋은 성능을 보이기에 SimCLR는 큰 배치 사이즈를, MoCo는 메모리 뱅크 및 momentum encoder network를 이용해 많은 pair를 확보했었습니다. 해당 실험 환경에서 SwAV는 적은 epoch 학습으로 SimCLR와 MoCo를 크게 능가하는 것을 확인할 수 있습니다.
Ablation Study
- Clustering-based self-supervised learning
해당 세션에서 저자들은 과거의 클러스터링 기반 모델들을 SimCLR와 같은 instance 단위 contrastive learning 방법론과 비교하기 위해 일부분을 재구현했다고 합니다. Clustering 방법론으로는 DeepCluster-v2와 SeLa-v2를 고려했다고 합니다.
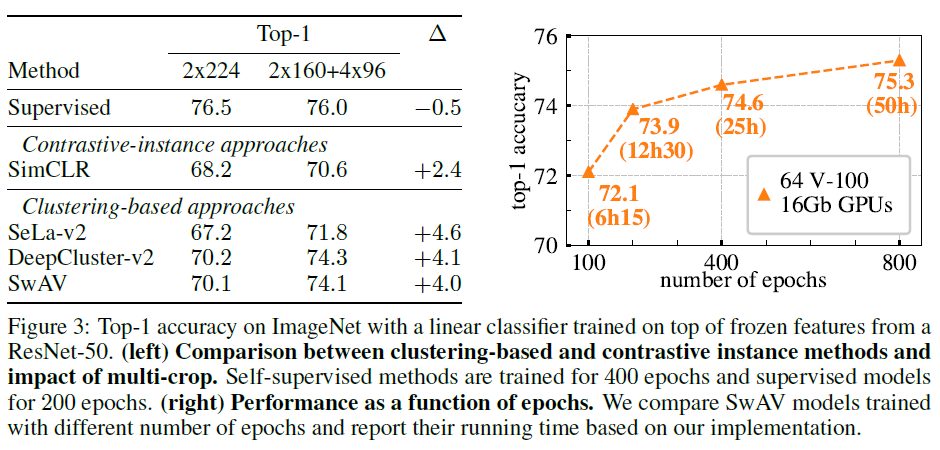
Fig3의 왼쪽에서는 contrastive-instance 방법과 clustering 기반 방법을 최대한 동등하게 비교하기 위해 세팅을 맞췄다고 합니다(data augmentation, 학습epoch, batch크기 통일 등). 해당 실험에서 SwAV와 Deepcluster가 multicrop의 유무와 관계없이 SimCLR를 능가한다고 합니다. 해당 실험은 instance classification 기반 방법론 대비 클러스터링 기반 방법론들의 포텐셜을 어필하기 위해 리포팅 한 것 같네요. 여기서 DeepCluster가 좋은 성능을 보이기는 하지만, SwAV와 달리 online learning이 불가능하다는 단점이 있음을 강조합니다.
- Applying the multi-crop strategy to different methods
Fig3의 왼쪽을 다시 보면, multi-crop 의 추가적인 적용으로 상당한 성능 개선이 이루어짐을 확인할 수 있습니다. 저자들은 본인들이 제안한 multi-crop이 일관된 성능 향상을 보임을, 특히 클러스터링 기반 방법론의 성능 향상에 도움이 되는 경향을 확인했다고 합니다(SSL이 아닌 supervised 학습에서는 개선이 딱히 되지 않습니다)
Conclusion
기존의 instance 단위 학습이 아닌, 클러스터링 기반 contrastive learning을 활용한 Self-supervised learning을 살펴보았습니다. 중간에 매핑 전략 부분에서 처음 보는 알고리즘이 나와 온전히 이해하기는 쉽지 않았지만, 기존과는 꽤 다른 framework 설계가 인상적이었습니다.
감사합니다.
허재연 연구원님 리뷰 잘 읽었습니다
가장 근본적인 질문인데, 본 논문의 저자는 “online-clustering 기반 self-supervised learning “를 제안하셨다고 했는데요, online learning은 무엇인가요?
그리고 저자가 말하는 “online-clustering 기반 self-supervised learning” 이 필요한 이유와 그 online에 최적화되었음을 실험으로 보인건가요? 실험에는 따로 등장하는 것 같지 않아서 질문드립니다
기존 클러스터링 방법들은 중간중간 데이터 전체에 대한 cluster assignment가 필요했는데 이는 학습 과정과 분리되어 있어(offline clustering) 비효율적이었습니다. 하지만 SwAV는 code 계산을 학습되는 prototype으로 하기에(프로토타입 벡터에 feature assign) 학습 과정과 step이 분리되지 않고, 이에 따라 online learning이라는 표현을 사용한 것으로 이해됩니다.
저자들이 online learning에 관한 실험을 따로 수행하지는 않은 듯 합니다. 다른 clustering 방법들과의 비교 실험이 있기는 하지만, 성능에 대한 비교이기에 online learning을 타겟팅한 실험으로 보기는 어려울 듯 합니다.
안녕하세요. 좋은 리뷰 감사합니다.
1. 우선 본문 중 “클러스터링을 이용해 각각 이미지 데이터가 아닌 비슷한 특징을 가진 이미지 그룹 간 discrimination을 이용할 수도 있습니다.” 해당 부분을 이해하지 못하여 질문드립니다. 이미지 데이터가 아닌 비슷한 특징을 가진 이미지 그룹이 의미하는 바가 무엇인가요?
2. 결국 본 논문의 Online-clustering이라는 것이 KNN과 같은 방식이 아닌 Prototype을 활용하는 Clustering으로 보면 될까요? – 사실 그럼 너무 단순한거같은데, 뭔가 제가 잘못이해했나 싶긴 해서 질문드립니다!
1. 이미지 데이터 하나하나에 대한 feature를 비교하는 instance discrimination이 아닌, 유사한 데이터가 군집화된 클러스터를 비교하거나, 해당 클러스터를 대표하는 code를 비교한 것이라는 뜻입니다.
2. 네 그렇게 이해하면 될 듯 합니다. 단순하긴 한데.. 기존 SimCLR같은 방법론들보다는 비교적 복잡하고, 또 2020년에 나온 논문인것도 감안해야 할 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
클러스터링 방법들이 학습 도중에 계속 전체 데이터에 대해 이미지의 code를 할당해줘야 한다고 했는데 이 code라는게 무엇인가요 ?
또, cluster assignments를 비교하는 것은 이미지를 pairwise로 비교하는 것에 의존하지 않고 다른 image views에 대해 잘 동작한다고 하셨는데 왜 그런건가요 !?!?
마지막으로 Sinkhorn algorithm이 무엇인지 궁금합니다 ..
감사합니다 .
1. 여기서 code는 주어진 B개의 feature vector z를 prototype C에 매핑한 것(Q)입니다. 이미지의 code는 cluster assignment로 생각하면 될 듯 합니다. Method 시작 부분에 공식 github에서 가져온 GIF를 첨부했으니, 참고하시면 이해하기 편할 것입니다.
2. 해당 부분은 저자의 주장입니다. 저는 해당 부분을 읽으며 이미지 데이터 하나하나에 대한 비교로 학습하는 instance discrimination보다는 cluster의 code를 이용한 비교가 더 좋지 않느냐.. 라는 주장으로 이해했습니다.
3. 주어진 B개의 feature vector z를 prototype C에 매핑한 것(Q)입니다. 이미지의 code는 cluster assignment로 생각하면 될 듯 합니다. Method 시작 부분에 공식 github에서 가져온 GIF를 첨부했으니, 참고하시면 이해하 편할 것입니다.
Sinkhorn-Knopp 알고리즘은 최적의 Q를 구하는데 사용되는 알고리즘으로, transportation prolem에서 cost를 최소화하는 transport plan을 찾는 알고리즘이라고 합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
리뷰를 읽으면서 제가 이해한 바로는 Method에서 code를 target으로 간주하지 않고 동일 이미지에서 나온 view 간의 매핑을 일관성있게 하도록 하는 프로토타입 C를 학습하는 것으로 이해를 했습니다.
그런데 이해가 안가는 부분은 본문의 ‘Computing codes online’ 부분에서 마트와, 사과를 통해 예시를 들어주셨는데 이 그림에서는 X(feture vector z)를 Y(Prototype C)로 균등하게 배분하는 매핑(Code q)를 학습하는 것처럼 나와있고 설명해주신 부분에도 ‘cost를 고려하여 X에서 Y로 가는 최적의 transportation plan을 찾는 문제’라고 설명이 되어있습니다. 그래서 최종적으로 학습시키는것이 프로토타입 C인지 아니면 매핑(Code q)를 학습시키는 것인지가 궁금합니다.
감사합니다.
학습 과정에서는 feature vector Z를 prototype C에 매핑하는 코드 q를 최적화하하게 됩니다. 근데 결국 의사코드에서 확인할 수 있듯 prototype score는 z와 C의 행렬곱이기 때문에 C와 Q중 하나가 결정되면 다른 하나도 결정됩니다. 학습을 통해 둘 다 최적화된다고 생각하셔도 될 것 같습니다.