Introduction
Speech Emotion Recognition(SER)이란 인간의 음성에서 감정을 인식하는 것을 의미합니다. 논문에서는 라벨링된 감정 데이터셋이 부족하여 SER 연구에 제악이 존재한다고 언급하고 있습니다. 또한 수집되는 대부분의 음성 감정 데이터셋은 시뮬레이션 혹은 유도된 시나리오에서 수집하여 실제 상황에 존재하는 다양한 감정을 반영하기 어렵다는 문제가 발생하게 됩니다. 또한 사람마다 감정을 다르게 인식할 수 있기 때문에, 강도가 약한 감정의 경우 데이터 라벨링에서 ambiguity가 발생할 수 있다고 합니다. 게다가 데이터셋이 수집되었다 하더라도 서로 다른 감정들 사이의 데이터 불균형은 “Neutral”과 같이 자주 등장하는 감정에 대해 overfitting 문제가 발생할 수 있습니다.
이러한 문제를 해결하기 위해 사용되는 방법으로는 data augmentation이 있다고 합니다. SER에서는 보통 음성 인식(ASR) task의 augmentation 방법들인 SpecAugment, Vocal Tract Length Perturbation (VTLP), speed perturbation, pitch shift, noise injection등을 사용합니다. 그러나 speech의 언어적 정보만을 필요로 하는 ASR과 달리 SER은 언어와 비언어적 정보를 함께 사용하기 때문에 단순 augmentation을 적용하기 어렵다는 한계점이 있습니다. 예를 들어, ‘sad’ 감정은 느리게, ‘angry’ 감정은 빠르게 표현되는 경향이 있기 때문에 speech의 pitch나 speed를 번형하게 되면 semantic한 정보에 영항을 미칠 수 있게 됩니다.
Augmentation 대신 GAN과 같은 생성 모델을 사용하여 intermediate emotional feature를 생성하거나 음성 내용의 변동 없이 감정을 변형하는 방식을 채택하기도 하였습니다. 그러나 생성된 feature는 직관적으로 평가하기 어렵고, 운율적인 표현은 음성의 내용과 강한 연관성이 있어 GAN에 의해 감정이 변경된 speech는 그 자체가 부자연스럽거나 모호해 질 수 있다는 단점이 있습니다.
인간은 동일한 언어 내용을 유지하면서 다양한 운율 속성을 쉽게 변경하여 주어진 감정을 표현할 수 있습니다. 예를 들어, “I am not happy today”라는 문장이 있을 때, 슬픈 감정을 표현하려면, “not happy”를 강조하도록 비언어적 표현을 추가하게 됩니다. 저자들은 이러한 인간의 발화 능력에 영감을 받아 EmoAug라는 augmentation 기법을 제안하였습니다. EmoAug는 원본 음성의 감정을 그대로 유지한 채 운율 속성만을 변형한다고 하며, unsupervised 방식으로 학습된다고 합니다.
- Proposes a novel unsupervised speaking style transfer model which enriches emotion expressions by altering stress, rhythm and intensity while keeping emotions, semantics and speaker identity invariant.
- Implements quantized units to represent semantic speech content instead of using a well-trained ASR model, which enables us to work on emotional audio without text transcriptions.
- SER models trained with EmoAug outperform the state-of-the-art models by a large margin, effectively overcoming overfitting issues caused by data scarcity and class imbalance.
Method
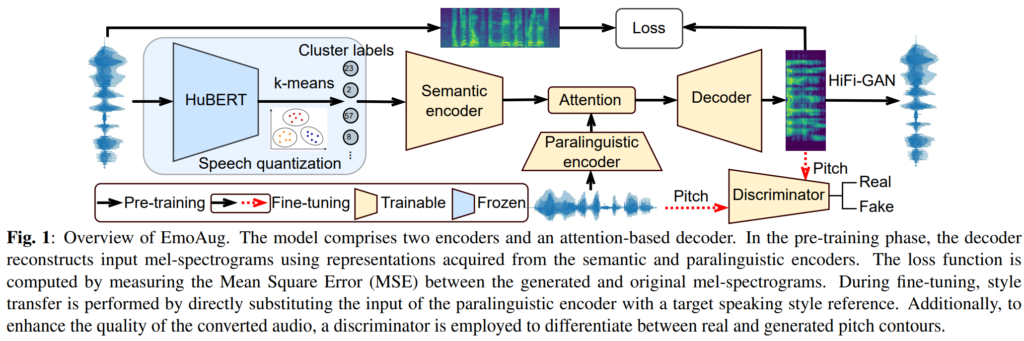
EmoAug는 [그림 1]과 같이 speech quantization module, semantic encoder, paralinguistic encoder, attention-based decoder로 구성되어 있습니다. 아래 부분에 있는 discriminator는 fine-tuning 단계에서 사용되며, 각각에 대해서는 아래에서 자세히 설명드리겠습니다.
Speech Quantization and Semantic Encoder
먼저 speech에 있는 의미론적 표현을 학습하는 semantic encoder 부분부터 설명드리겠습니다.
Speech task에서는 의미 있는 음성 정보를 획득하기 위해 ASR 시스템을 활용하는 것이 일반적인 방법이라고 합니다. 그러나 신뢰할 만한 ASR 모델을 학습시키는 것은 방대한 양의 라벨링 데이터가 필요하며, ASR 모델은 unseen noise나 emotional speech에 대해 강인하지 않습니다. 이에 저자들은 HuBERT representation을 사용하여 semantic speech content를 포착하고자 하였다고 합니다. HuBERT는 self-supervised 방식으로 학습하며 emotion speech를 포함하여 다양한 style의 speech를 처리할 수 있어 ASR 모델의 성능이 저하되는 문제를 해결할 수 있었다고 합니다.
먼저 speech x가 입력되면, x = (x_0, \ldots, x_t) 는 사전 학습된 HuBERT 모델에 의해 continuous vector로 임베딩되며, 이후 k-means 알고리즘에 의해 continuous speech representation이 discrete cluster label인 u = (u_0, \ldots, u_t) 로 양자화됩니다. 이를 수식으로 나타내면 아래의 [수식 1]과 같습니다.
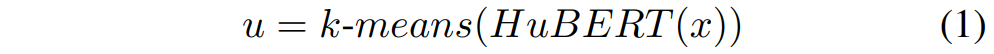
저자들은 HuBERT의 다양한 어휘 크기가 모델 성능에 미치는 영향을 조사했습니다. 이 연구에서는 200개의 클러스터로 구성된 어휘 크기를 사용했으며, 이는 50개 또는 100개의 클래스 사용 시보다 상당히 향상된 성능을 보였습니다. 의미적 내용을 세밀화하기 위해 반복을 제거하고 템포 정보를 필터링합니다 (u → ũ), 예를 들어 “23, 23, 2, 2, …, 57” → “23, 2, …, 57″과 같이 변환됩니다. 양자화 후, 저자들은 클러스터 라벨을 의미 인코더(Sem)를 사용하여 잠재 표현으로 매핑합니다. 이 의미 인코더는 커널 너비가 5이고 패딩 크기가 2인 3개의 512채널 Conv1D 레이어와 지역 및 전역 컨텍스트 정보를 각각 캡처하기 위한 256차원의 양방향 LSTM으로 구성됩니다.
Paralinguistic Encoder
Paralinguistic encoder(Par)는 발화 수준의 비언어적 정보를 학습하는 것을 목표로 합니다. 이는 입력 음성 x에서 화법 스타일, 감정 상태, 화자 정체성 등을 포함합니다. 준언어적 인코더는 화자 검증 작업을 위해 제안된 ECAPA-TDNN 모델을 기반으로 합니다. 모델은 Conv1D 레이어 하나, ReLU 함수, 배치 정규화(BN)로 시작하여 세 개의 SE-Res2 블록이 뒤따릅니다. SE-Res2 블록 사이의 잔여 연결은 다양한 수준의 출력을 특징 집계 레이어(Conv1D+ReLU)로 전달합니다. 그 후, 집계된 출력은 주의 통계 풀링 레이어(Conv1D+Tanh+Conv1D+Softmax)에 의해 동적으로 가중되며, 마지막 완전 연결(FC) 레이어에 의해 고정된 차원으로 매핑됩니다. 저자들은 사전 훈련된 모델을 사용하여 ECAPA-TDNN을 초기화합니다. 주의 통계 풀링, 고정 차원 매핑 및 가중치 초기화는 준언어적 인코더에서 의미적 정보의 누출을 방지합니다.
Decoder
저자들의 decoder는 Tacotron2라는 wavenet 기반의 decoder를 기반으로 하며, [수식 2]와 같이 location-aware attention (Att)을 사용하여 encoder와 decoder를 연결하였습니다.
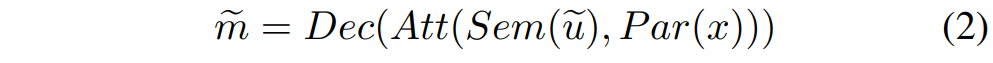
디코더(Dec)는 auto-regressive 방식으로 한 번에 한 프레임씩 생성합니다. 두 개의 fully connected (FC) 레이어는 ground-truth mel-spectrograms x를 잠재 표현으로 매핑하며, 이는 LSTM 모듈에서 teacher-forcing 훈련에 사용됩니다. 마지막으로, FC 레이어는 중간 특징을 입력 mel-spectrograms의 차원으로 매핑합니다. 생성된 mel-spectrograms tilde{m}는 HiFiGAN을 통해 waveforms tilde{x}로 변환됩니다.
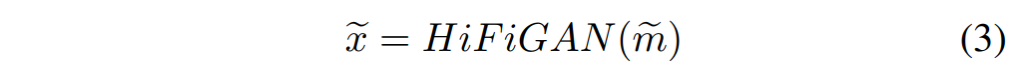
Discriminator
사전 학습 이후, style transfer를 위해 paralinguistic encoder에 다른 reference audio를 입력할 때 생성된 speech signals에 일부 distortions가 발생하는 것을 관찰했습니다. 생성된 speech의 품질을 향상시키기 위해, genuine 음성과 synthesized speech를 구별하는 discriminator를 구현했습니다. 중요한 점은 discriminator가 semantic content를 유지하면서 pitch changes만을 구별한다는 것입니다. discriminator는 세 개의 convolutional blocks (Conv1D+ReLU+BN+dropout)로 시작하여 두 개의 linear projection layers로 이어집니다.
Speaking Style Transfer
어떠한 감정 e를 가진 화자 s의 모든 speech를 X_{s,e}로 나타내었을 때, speaking style transfer는 아래의 [수식 4]와 같이 paralinguistic encoder 입력 x_{s,e}를 speaking style y_{s,e}로 변경하는 방식으로 진행됩니다. 이때, x_{s,e} \in X_{s,e}, y_{s,e} \in Y_{s,e}이며, Y_{s,e} = X_{s,e} - \{x_{s,e}\}입니다.
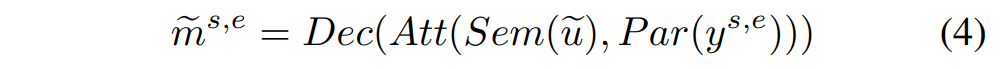
따라서 변환된 mel-spectrograms {m}{s,e}는 원래 오디오 x{s,e}와 동일한 speaker identity, semantic content 및 emotions를 유지하지만, y_{s,e}에서 전달된 다른 rhythms 또는 intensities를 가지고 있습니다. 또한, 데이터 불균형을 해소하기 위해 논문에서는 각 감정에 대해 서로 다른 수의 샘플을 생성하였다고 합니다.
Experimental Setups
Datasets
논문에서는 LRS3-TED데이터셋과 IEMOCAP 데이터셋을 각각 pre-training, fine-tuning에 사용하였습니다.
간단히 설명드리자면 LRS3-TED 데이터셋은 TED 강연에서 추출한 데이터로, 약 5000명 이상의 발화자와 다양한 발화 스타일 및 감정으로 구성되어 있는 large dataset으로 모델이 보다 풍부한 언어 표현을 학습하도록 하였습니다. IEMOCAP 데이터셋은 SER task에 fine-tuning하기 위해 사용된 데이터셋으로, 전체 감정 중 ‘happy’, ‘sad’, ‘angry’, neutral’의 네 감정만을 활용하여 학습 및 평가에 사용하였다고 합니다.
EmoAug Training
EmoAug는 augmentation을 위한 generation모델을 학습하기 위해 먼저 LRS3-TED에서 사전학습하고, IEMOCAP에 대한 discriminator로 fine-tuning을 진행하였습니다.
SER Model Training
SER은 앞서 사전 학습된 HuBERT 모델에 분류기의 역할을 수행할 FC 레이어를 하나 추가하는 것으로 구성하여 iemocap 데이터셋으로 학습하였다고 합니다.
Experimental Results and Discussion
Comparison of Different Augmentation Times
먼저 저자들은 augmentation에 다른 SER 성능 변화를 확인하고자 하였고, 화자가 동일하고 같은 감정을 가지는 speech를 n개 선택하여 style transfer를 진행하였습니다. 그리고 augmented time을 증가시키면서 성능의 변화를 관찰하였는데, 그 결과는 아래 [그림 2]와 같습니다.
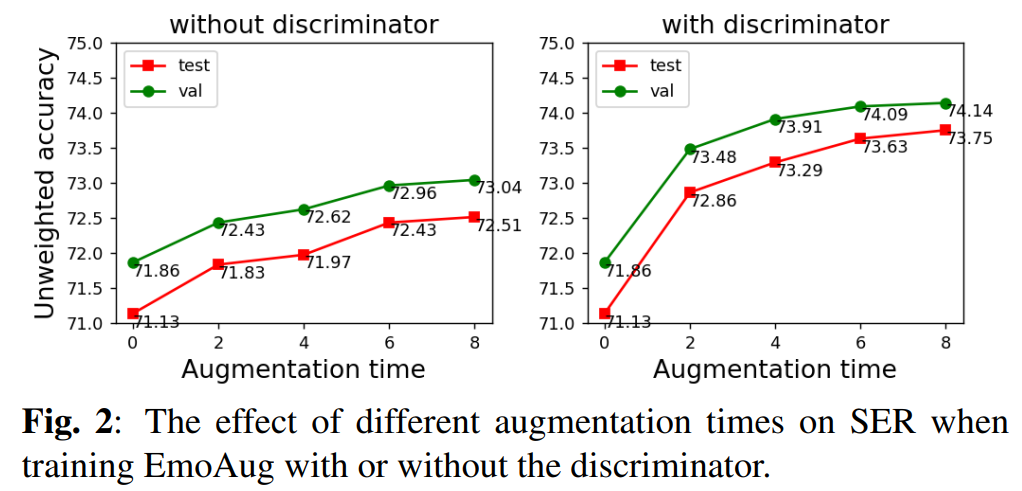
[그림 2]에서 확인할 수 있듯, augmented time이 길어질수록 정확도가 크게 증가하며, 여기서 augmented time이 0인 것은 raw audio만을 사용하여 학습한 것을 나타내는 것입니다. 또한 discriminator를 사용하면 성능이 더 향상되었는데, 논문에서는 discriminator를 통해 생성된 augmented audio의 품질이 향상되었기 때문이라고 언급하였습니다.
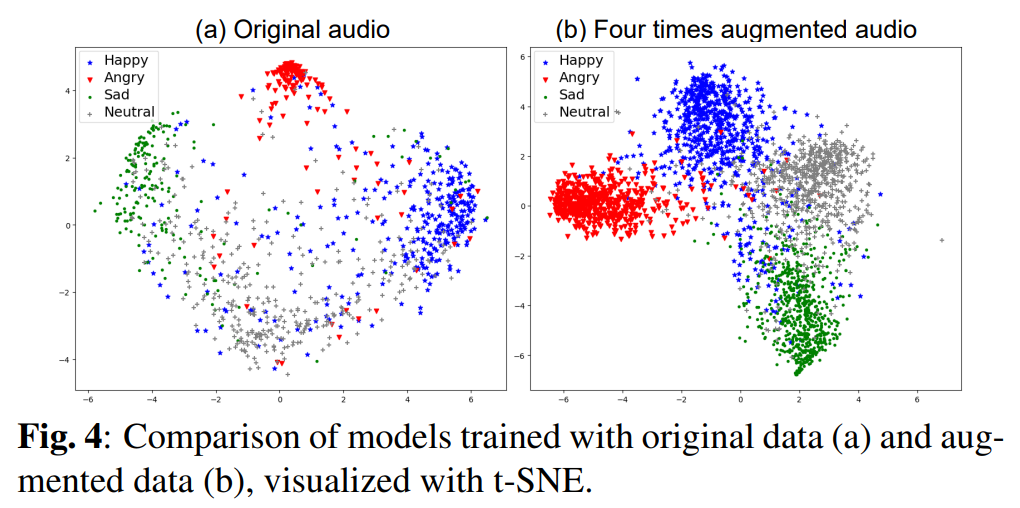
위의 [그림 4]는 원본 데이터로만 학습된 모델과 원본의 4배 만큼 augmentation을 진행하여 학습한 모델에서 test data의 tsne를 확인한 것입니다. [그림 4(a)]를 보면 원본 데이터로만 학습된 모델은 neutral, sad, happy의 감정을 명확하게 구분하지 못 하는 모습을 볼 수 있으나, [그림 4(b)]의 EmoAug는 네 가지 감정을 보다 명확하게 구분하는 것을 확인할 수 있습니다.
Comparison with Previous Work
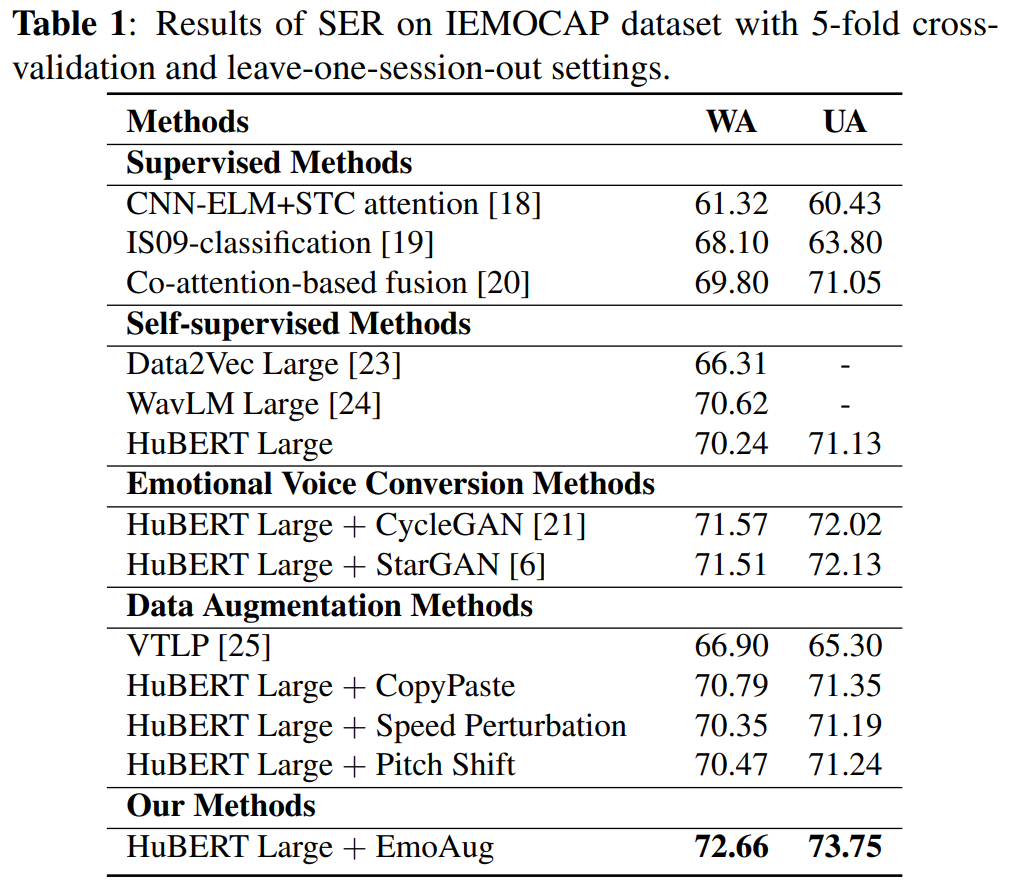
[표 1]은 저자들이 사용한 HuBERT Large 모델과 기존에 사용되던 다양한 모델과의 비교를 수행한 결과를 나타내고 있으며, 본 논문의 EmoAug가 이전 방법론들과 비교했을 때 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
안녕하세요 혜원님 좋은 리뷰감사합니다.
본문의 ‘Speaking Style Transfer’ 부분에서 paralinguistic encoder 입력 x는 어떤 감정e를 가진 화자 s의 모든 speech를 X와 어떻게 다른지 궁금합니다.
그리고 본문에서 언급된 HiFiGAN은 저자가 제안한 gan인건지 아니면 이전 연구에서 개발된 방법론인지 궁금한데 혹시 후자가 맞다면 어떤 특징을 가지고 있는지 설명해주시면 감사하겠습니다!
댓글 감사합니다.
‘Speaking Style Transfer’ 에서 언급한”어떤 감정e를 가진 화자 s의 모든 speech를 X”는 X_{s, e}로써, speaker가 s이며 emotion이 e인 모든 speech를 의미하며, paralinguistic encoder 입력에 해당하는 x_{s,e}는 X에 포함되는 임의의 speech를 나타냅니다.
그리고 HiFiGAN은 저자들이 제안한 것이 아닌 해당 논문에서 제안된 방법론으로, mel-slectrogram 등의 음성 feature로부터 speech를 생성하는 모델에 해당합니다. 모델의 자세한 특징까지는 파악하지 못하였으나, 첨부한 논문을 확인해 보시면 좋을 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
ECAPA-TDNN 모델은 conv1d, relu, bn으로 시작하여 3개의 SE-Res2 블록이 뒤따른다고 하셨는데 SE-Res2 블록이 무엇인지 알 수 있을까요 ?
또, genuine과 synthesized speech를 구별하는 discriminator를 fine-tuning 단계에서 사용한다고 하셨는데, 구체적으로 어떻게 사용되는 것인지 궁금합니다.