제가 이번에 리뷰할 논문은 제안서와 관련하여 논문을 서베이하면서 보게 된 논문입니다. Affordance segmentation이라고해서 물체에서 기능(Grasp/Cut/Scoop/Contain/Pound/Support/Wrap-Grasp 등 데이터에 따라 세부 분류가 조금씩 달라지는 것으로 보입니다)에 따라 segmentation을 수행하는 task가 있어서 one-shot 기반의 방법론을 가져왔습니다. 해당 논문에서 DINO와 SAM의 encoding 능력에 대한 비교도 수행하여 다른 task에서 모델을 선택하는 데 도움이 될 수 있을 것 같습니다. 이제 리뷰를 시작해보겠습니다.
Abstarct
본 논문에서는 기본 객체의 카테고리당 하나의 예시로 학습하여 새로운 객체와 affordance를 식별하는 One-shot Open Affordance Learning(OOAL)을 제안합니다. Vision-Language 모델이 새로운 객체와 장면에 대한 이해력을 높였으나 객체의 세부적인 기능을 인식하는 affordance와 같은 작업에서는 여전히 어려움이 존재하였다고 합니다. 이를 해결하기 위해 기존 foundation 모델의 affordance 이해 능력과 데이터가 한정되었을 때의 affordance 학습 가능성에 대한 비교 분석을 수행합니다. 저자들은 image feature와 text embedding의 정합을 맞추기 위한 프레임워크를 디자인하였으며, 실험을 통해 두가지 벤치마크에서 SOTA를 달성하였고 학습하지 않은 객체와 affordance에 대해 일반화가 가능함을 보였습니다.
Introduction
Affordance는 객체에서 특정 행동이 일어날 수 있는 영역(potential “action possibilities” regions)으로, 예를 들어 칼의 경우 칼 날은 어떤 것을 자르는 행동이 일어날 수 있고, 손잡이 부분은 사람이 물체를 잡는 행동일 일어날 수 있어 cut과 grap 두 영역으로 세분화하여 segmentation을 수행하는 것 입니다. 이러한 affordance는 동적인 환경에서 객체와 action 및 효과 사이의 연관성에 대한 이해를 높여 장면 이해, 사람-객체 상호작용 등 다양한 응용 분야에 중요한 작업입니다.
그러나 객체의 affordance는 기능적으로 동일하더라도 객체마다 형태와 크기 등이 매우 다양하여 어려움이 있습니다.예를 들어 요리사의 칼과 오피스의 가위는 무언가를 자르는 칼날과 잡는 손잡이로 동일하게 구분할 수 있으나 형태가 매우 달라서 이를 인식하는 것에 어려움이 있습니다.
기존의 대부분의 연구는 2D 이미지와 RGB-D, 3D Point cloud 등 다양한 자료를 입력으로 이용하여 visual feature와 affordance label의 mapping을 학습하였으며, 이는 라벨링 된 데이터가 필요하다는 한계가 있고, 대용량 데이터의 부족과 객체 카테고리의 부족으로 인해 새로운 객체와 장면으로 확장이 어렵다는 문제가 있습니다. 이처럼 비용이 많이 드는 annotation에 대한 의존도를 높이기 위해 최근 일부 연구들은 sparse keypoint를 이용하여 사람과 행동 비디오와 인간과 객체 사이의 상호작용을 학습하였습니다. 그러나 여전히 dense한 annotation의 요구는 완화하였으나 여전히 많은 학습 데이터가 필요하다는 문제가 존재하며 unseen 객체에 대한 일반화와 새로운 affordance 식별이 불가능하였습니다.
이러한 한계를 해결하고자 본 논문에서는 대용량 데이터에 의존하지 않고 새로운 객체와 affordance 클래스를 이해할 수 있는(가위 날의 cut으로 학습하고 도끼나 칼의 칼날이 동일한 기능이 가능함을 이해) 모델을 학습하고자 하였으며 사전 정의된 affordance 뿐만 아니라 hold와 grap, cut과 slice와 같이 의미론적으로 유사한 어휘에 대하여 추론이 가능하도록 하기 위한 연구를 수행하였습니다.
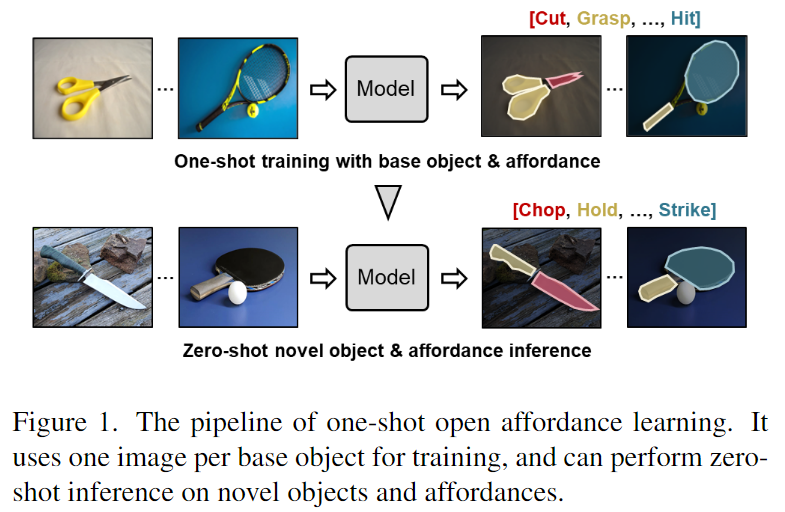
각 기본 object 카테고리에서 단 하나의 예시만 사용하는 상황을 대상으로 하여 One-shot Open Affordance Learning(OOAL)이라고 문제를 정의하고, 소량의 데이터로 학습하여 새로운 객체와 affordance를 추론할 수 있도록 합니다. 이러한 OOAL의 파이프라인은 위의 Figure 1에서 확인하실 수 있으며, OOAL의 연구를 통해 대규모 데이터 셋의 필요성을 완화하고 추론의 범위를 확장하고자 하였다고 합니다.
이를 위해 이미지-텍스트 데이터로 학습된 VLM을 활용하여 학습하지 못한 객체와 장면, 개념에 대한 추론을 수행하고자 하였습니다. 그러나 VLM모델은 affordance나 객체의 일부분에 대한 차이를 이해하지 못하는 경우가 많았으며, 저자들은 이에 대해 학습 과정에 affordance와 객체의 특정 부분에 대한 정보를 학습하지 못한 것으로 가설을 세우고, foundation 모델이 affordance와 같이 사물의 미묘하고 세부적인 정보를 학습할 수 있도록 연구를 수행하였습니다.
먼저 일부 foundation 모델에 대한 비교 분석을 통해 affordance에 대한 이해가 가능한 지와 데이터가 제한적인 상황에서 affordance를 학습하기 위한 시각적 정보가 무엇인 지 파악이 가능한 지를 확인하고, 분석을 기반으로 학습 구조를 설계하였습니다. 이를 SOTA 방법론들과 비교하여 전체 학습 데이터의 1%미만을 이용하여 더 높은 성능 달성이 가능함을 실험적으로 확인하였다고 합니다.
본 논문의 contribution을 정리하면 다음과 같습니다.
- 대규모 학습 데이터 없이 새로운 object와 affordance 카테고리로 일반화 가능한 모델을 개발하기 위해 OOAL(One-shot Open Affordance Learning) 문제 정의
- 기존 foundation 모델에 대한 분석을 통해 OOAL에 대한 가능성을 확인한 후, VLM 모델을 이용하여 학습 구조를 설계하고 visual feature와 affordance에 대한 text label 사이의 정합을 개선하기 위한 네트워크 설계
- 본 논문에서 제안한 학습 방식의 효과를 입증하기 위해 affordance segmentation에 대한 2가지 데이터로 실험을 수행하여 일반화 가능성과 기존 방법론 대비 성능 개선을 확인
Problem Setting
One-shot Open Affordance Learning(OOAL)은 기본 객체에 대한 하나의 예시를 이용하여 affordance를 예측하는 모델을 학습한 뒤 새로운 객체 클래스로 일반화 하는 것을 목표로 합니다.(예시_가위로 학습하여 도끼와 칼로도 확장)
- 픽셀 레벨의 segmentation을 예측하는 task로, 객체를 먼저 base classes N_b와 novel classes N_o로 구분합니다. 이때 N_b와 N_o는 교집합이 없도록 구성합니다.
- 학습 과정에는 N_b만을 이용하며 각 클래스마다 이미지 I \in \mathbb{R}^{H⨉W⨉3}와 픽셀 수준의 affordance 정보가 포함된 annotation 정보M \in \mathbb{R}^{H⨉W⨉N}(N은 데이터 셋의 affordance category 수)로 이루어진 한 쌍의 데이터를 이용합니다.
- 평가 과정은 N_b와 N_o에 대하여 수행되며 이를 통해 일반화 성능을 측정합니다. 또한 Affordance label은 의미론적으로 유사한 새로운 어휘로 대체하여 평가를 수행합니다.(예시_”cut”을 “chop”, “slice”, “trim”과 같은 단어로 대체)
저자들에 따르면 기존의 One-Shot Semantic Segmentation(OSSS)[1]과 One-Shot Affordance Detection(OS-AD)[2]연구는 학습 과정에 카테고리당 하나의 샘플을 사용하지만, iteration마다 샘플이 달라지므로 다양한 이미지를 학습할 수 있었으며, 사전 정보를 제공하기 위해 support 이미지가 필요하다는 제약 조건이 있었으나, OOAL은 하나의 샘플만을 이용하고 다른 객체로 일반화 해야 하므로 학습한 객체와 미학습한 객체 사이의 의미론적 관계를 이해하는 능력이 필요합니다. 이를 위해 기존의 foundation 모델에 대한 분석을 다음 파트에서 수행합니다.
[1] Amirreza Shaban, Shray Bansal, Zhen Liu, Irfan Essa, and Byron Boots. One-shot learning for semantic segmentation
[2] Hongchen Luo, Wei Zhai, Jing Zhang, Yang Cao, and Dacheng Tao. One-shot affordance detection. In IJCAI, 2021
Method
1. Analysis of Foundation Models
컴퓨터비전에서 CLIP, SAM, DINO와 같은 대규모 foundation 모델이 연구되었으며, 이러한 모델들은 강력한 zero-shot 일반화 성능을 보여주었으므로 저자들은 해당 모델을 활용하고자 하였습니다. 이를 위해 3가지로 나누어 foundation 모델에 대한 분석을 수행합니다.
- Visual-Language foundation 모델들이 affordance나 객체의 부분에 대한 프롬프트를 통해 affordance를 인식할 수 있는가?
- Visual Foundation 모델의 특징이 이미지에서 affordance 영역을 구별할 수 있는가?
- 새로운 객체로 affordance를 일반화하고 low-shot 세팅에서도 잘 작동하는가?
<1. Visual-Language foundation 모델들이 affordance나 객체의 부분에 대한 프롬프트를 통해 affordance를 인식할 수 있는가?>
이 질문을 기반으로 4가지 대표 모델로 vanilla CLIP[3], CLIP기반의 설명가능한 모델인 CLIP Surgery[4], open vocabulary segmentation에서 SOTA 방법론인 CAT-Seg[5], open vocabulary detection 방법론인 GroundingDINO[6]를 선정하였다고 합니다. “somewhere to [affordance]”라는 형식으로 text prompt를 주어 visual feature에서 해당하는 영역을 찾았으며 이에 대한 시각화 결과는 Figure 2에서 확인하실 수 있습니다.
[3] Alec Radford, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021
[4] Yi Li, Hualiang Wang, Yiqun Duan, and Xiaomeng Li. Clip surgery for better explainability with enhancement in open- vocabulary tasks. arXiv preprint arXiv:2304.05653, 2023.
[5] Seokju Cho, Heeseong Shin, Sunghwan Hong, Seungjun An, Seungjun Lee, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. arXiv preprint arXiv:2303.11797, 2023.
[6] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023
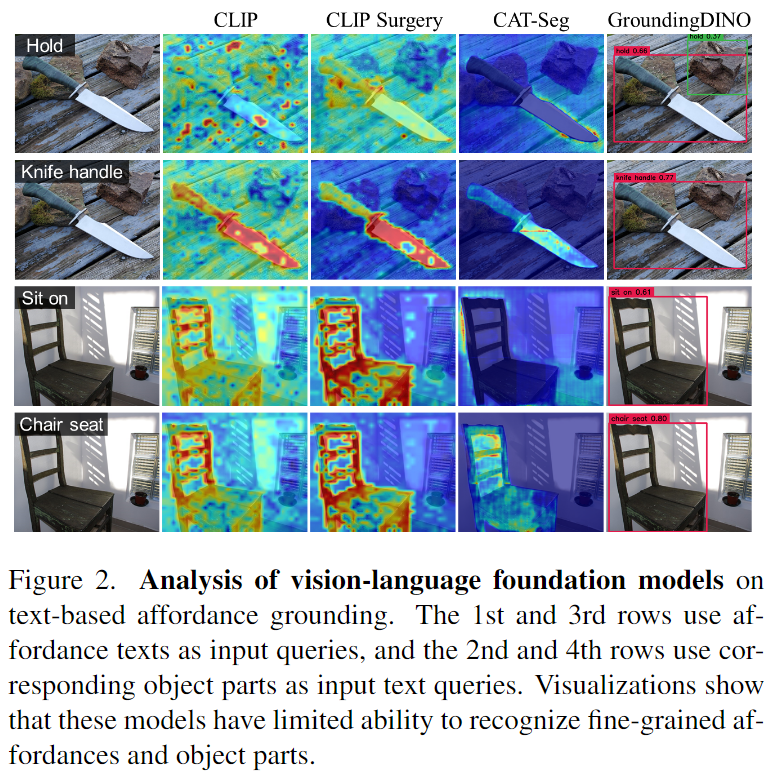
Figure 2에서 확인할 수 있듯 GroundingDINO를 제외하고 대부분의 모델이 affordance를 잘 이해하지 못하며, 대부분 객체의 특정 부분이 아닌 전체 객체에 집중하는 경향이 있음을 확인할 수 있습니다. CLIP은 배경과 전경에 모두 활성화되었으며, CAT-Seg의 경우 affordance 영역이 배경에서 활성화 되는 경향이 있습니다. 이에 비해 CLIP Surgery는 “hold”에 해당하는 영역은 인식하지 못하였지만 “sit on”에 대해서는 의자라는 것을 인식하였습니다. 또한, affordance text가 객체의 부분을 지칭할 경우 CLIP과 GroundingDINO는 객체에 주로 활성화되는 반면 CLIP Surgery와 CAT-Seg는 잘못된 부분에 활성화가 되는 경향을 보였습니다. 이러한 실험 결과는 CLIP이 객체의 특정 부분을 인식하는 능력이 제한적이라는 기존의 연구와 일치한다고 합니다.
<2. Visual Foundation 모델의 특징이 이미지에서 affordance 영역을 구별할 수 있는가?
3. 새로운 객체로 affordance를 일반화하고 low-shot 세팅에서도 잘 작동하는가? >
2번과 3번 질문에 답하기 위해 low-shot 세팅에서 좋은 affordance 모델의 필수 특성을 2가지로 고려합니다.
(1) Part-aware representation
- affordance는 자전거의 안장, 칼의 손잡이와 같이 객체의 특정 영역을 의미하는 경우가 많으므로 객체의 부분을 인식할 수 있어야 함.
(2) part-level semantic correspondence
- 일반화를 위해 모델이 의미 관계에 대하여 이해할 수 있어야 함.
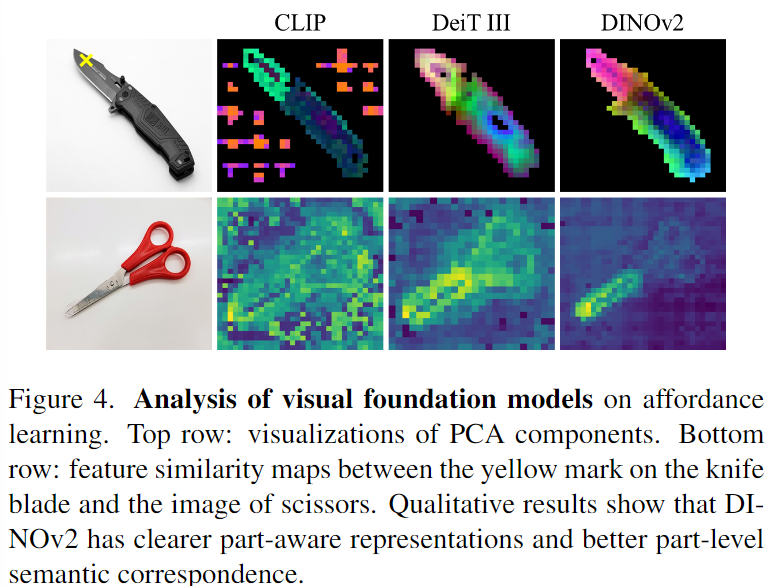
저자들은 세가지의 대표적인 visual foundation 모델인 CLIP, 완전 지도학습 기반의 DeiT Ⅲ[7], self-supervised 학습 기반의 DINOv2[8] 에 대해 평가를 수행합니다.
[7] Hugo Touvron, Matthieu Cord, and Herv´e J´egou. Deit iii: Revenge of the vit. In European Conference on Computer Vision, pages 516–533. Springer, 2022.
[8] Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- 먼저 부분에 대한 인식 성능을 평가하기 위해 각 모델에서 추출된 feature에 대해 PCA를 적용합니다. 위의 Figure 4의 1행이 이에 대한 시각화 결과로 세 모델 모두 어느 정도는 객체에 대한 파트를 구분할 수 있으나, CLIP의 경우 배경에 대해 잘 구분하지 못하며, DeiT Ⅲ은 칼의 기능적인 차이를 충분히 구분하지 못하는 것을 확인할 수 있습니다.
- 의미론적 관계에 대한 평가를 위해 칼과 동일한 affordance로 이루어진 가위를 이용하여 분석을 수행합니다. Figure 4의 2행은 칼날에 해당하는 패치(칼 이미지에서 노란색 x표시 된 부분의 feature)와의 cosine 유사도를 나타낸 것으로, DINOv2에서 칼날에 대응되는 영역을 잘 인식할 수 있음을 확인할 수 있습니다. 반면 CLIP은 전경과 배경에서 불분명한 대응이 이뤄짐을 확인할 수 있으며, DeiT Ⅲ는 객체에 대해서는 인식이 가능하지만, 그 안에서 객체의 칼날과 손잡이에 대한 구분이 어려운 것을 확인하실 수 있습니다.
이러한 분석을 바탕으로 저자들은 DINOv2가 의미론적으로 대응되는 객체의 특정 부위를 찾는 데 적합하다는 결론을 내립니다. (3가지 모델을 이미지의 encoder로 이용할 경우의 정량적 결과는 ablation study에서 확인하실 수 있습니다.)
2. Motivation and method
앞선 분석을 통해 DINOv2가 affordance의 일반화에 활용 가능함을 확인하였으나, DINOv2는 Visual-only 모델이므로 새로운 affordance에 대한 대응이 어렵다는 한계가 있습니다. CLIP과 같은 text encoder를 함께 활용하는 것이 하나의 해결책이 될 수 있으나, 입력되는 프롬프트에 메우 민감하며, 이를 위한 프롬프트 디자인 복잡하다는 문제가 있습니다. 또한, DINOv2의 경우 feature가 객체의 부분을 나타낼 수 있으나, layer마다 세분화 되는 수준이 다르며, 적절한 affordance 수준을 결정하는 것이 중요하다는 문제가 있습니다. 마지막으로 DINOv2의 Vision Encoder와 CLIP의 Text Encoder가 독립적으로 학습되었으므로 두 인코더사이의 정합이 맞지 않다는 문제가 있습니다. 이러한 3가지 문제를 해결하기 위해 저자들은 3가지 모듈을 제안하여 네트워크를 설계하였습니다.
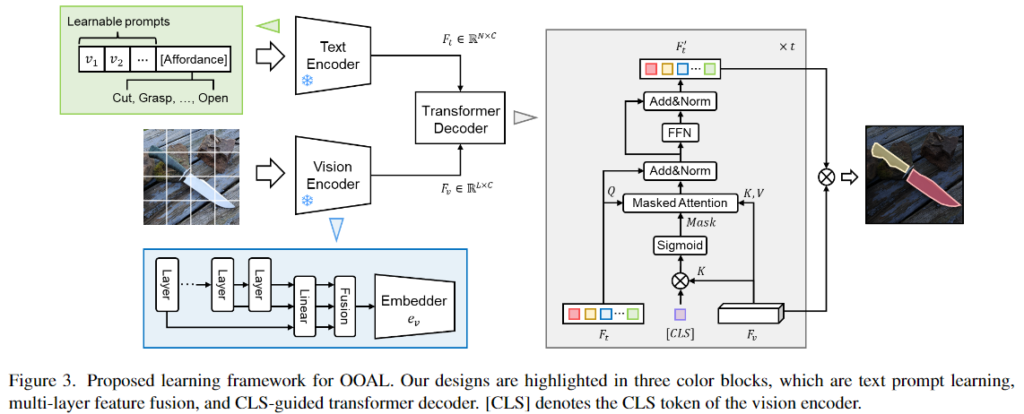
<Overview>
위의 Figure 3이 제안된 프레임워크로, Vision Encoder와 Text Encoder, transformer decoder로 구성됩니다. 사전학습된 DINOv2를 Vision Encoder로 사용하여 dense patch embedings \hat{F}_v \in \mathbb{R}^{L⨉C_v}(L은 패치 수)를 추출하고, affordance 라벨을 CLIP text encoder로 처리하여 text embeddings F_t \in \mathbb{R}^{N⨉C_v}(N은 affordance category 수)를 얻습니다. text와 visual 정보의 차원을 맞추기 위해 MLP 레이어 e_v: \mathbb{R}^{L⨉C_v}→\mathbb{R}^C를 이용하여 차원을 맞춰주고 Transformer Decoder에 두 embeddings를 입력으로 하여 affordance 예측 결과를 출력합니다.
<모듈1: Text Prompt Learning>
프롬프트를 수동으로 디자인하는 것이 복잡한 작업이므로 과적합 문제를 완화하고 CLIP의 text 인식 능력을 유지하고자 CLIP text encoder를 미세조정하는 대신 학습 가능한 파라미터를 프롬프트에 추가하여 학습을 수행하였다고 합니다. 학습 가능한 context vector \{ v_1, v_2, ... , v_p \}가 affordance CLS 토큰 앞에 삽입되며, 모든 클래스에서 해당 파라미터를 공유하도록 설정합니다.
<모듈2: Text Prompt Learning>
DINOv2의 레이어마다 서로 다른 수준의 세분화가 가능하며, 적당한 수준을 설정하기 위해 다양한 세분화 레이어의 정보를 모두 활용하고자 모든 레이어의 feature를 집계하는 네트워크를 설계합니다. 각 레이어는 선형 결합을 통해 처리되며, 모든 feature에 대해 가중합을 적용하여 feature를 생성합니다. 수식으로 나타내면 아래의 식(1)로 정의되며,
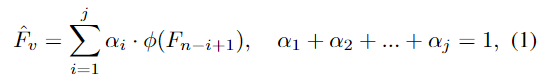
F_n은 마지막 레이어, \alpha는 학습가능한 파라미터로 레이어의 가중치를 의미하며, \phi는 선형 transformation을 의미합니다. 이렇게 모든 레이어를 융함하여 모델이 다양한 수준의 part에서 적절한 feature를 선택할 수 있도록 합니다.
<모듈3: CLS-Guided Transformer Decoder>
저자들은 visual과 text feature의 정합이 맞지 않는 문제를 해결하기 위해 cross-attention 메커니즘을 통해 두 branch 사이의 정보 겨환을 촉진하는 lightweight transformer decoder을 제안합니다. [CLS] 토큰인 L_{cls}는 객체에 대한 이해를 돕기 위해 제공되며, [CLS]토큰을 활용하여 이미지에서 객체에 대한 전경 영역 정보를 제공하는 마스크를 생성하도록 합니다.
decoder는 F_t, F_v, L_{cls} 를 입력으로 받아 query, key, value를 생성합니다.
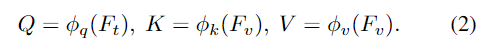
이때 text embedding이 query가 되고, visual feature가 key와 value가 되도록 하여 모델이 affordance text에 해당하는 시각 영역을 찾아 text embedding 업데이트에 집중할 수 있도록 합니다. 그 다음, [CLS] 토큰과 key 사이의 행렬곱을 통해 CLS-guided mask를 계산합니다.
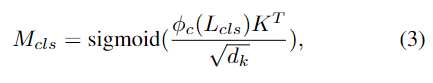
- d_k: key의 크기와 동일한 배율의 scaling factor
masked cross-attention은 아래의 식(4)로 계산되며
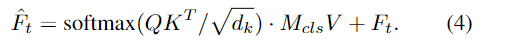
해당 과정을 거친 뒤 \hat{F}_t를 Feed-Forward Network에 통과시켜 text embeddings F'_t를 구합니다. Decoder는 t개의 layer로 구성되며 최종적으로 마지막 transform layer의 출력과 DINOv2에서 추출된 visual feature F_v 사이의 행렬곱을 통해 representation을 생성하고 binary-cross entropy를 이용하여 네트워크를 학습합니다.
<Inference on novel objects and affordances>
학습을 통해 visual feature와 text token의 임베딩의 alignment를 맞추었으며, inference 과정에는 새로운 객체가 주어졌을 때 text embedding이 DINOv2의 의미론적 대응이 가능하다는 특성(위의 분석에서 확인함)을 활용하여 객체의 affordance에 대응되는 영역을 찾습니다. 또한 새로운 affordance text가 주어질 경우에도 생성된 text embedding은 기본 affordance와 의미론적 유사성을 기반으로 visual feature를 찾을 수 있습니다.
Experiments
Datasets
대량의 object 카테고리로 이루어진 AGD20K와 UMD part affordance에 대하여 평가를 수행합니다.
- AGD20K
- 36개의 affordance, 50개의 객체 카테고리로 구성된 대규모 데이터 셋
- 23,716 이미지로 구성되며 인간과 사물의 상호작용 이미지에서 affordance를 학습하고, 객체 중심적 이미지에서 affordance localization을 수행하는 것을 목표로 함.
- weakly supervised 학습을 위한 데이터 셋으로, 이미지-level의 라벨 정보만 존재하므로, 저자들이 각 객체 카테고리에서 50개의 이미지를 무작위로 선택하여 annotation을 수행하였다고 함.
- Seen/Unseen 세팅으로 학습 및 평가 데이터가 분할되어있으며, 이를 기반으로 평가를 수행함.
- GT가 affordance 영역 내의 keypoint 에 대하여 가우시안 커널을 적용하여 annotation을 생성함. (아래의 예시를 확인해주세요.)

- UMD part affordance
- 7개의 affordance와 17개의 객체 카테고리로 구성
- 각 객체는 턴테이블에서 촬영된 28,843개의 RGB-D 이미지로 구성
- train-test split이 category split과 novel split으로 구성되며, category split은 base 객체에 대한 평가에, novel split은 학습하지 않은 객체에 대한 평가에 사용됨

Comparison to state-of-the-art methods
- AGD20K
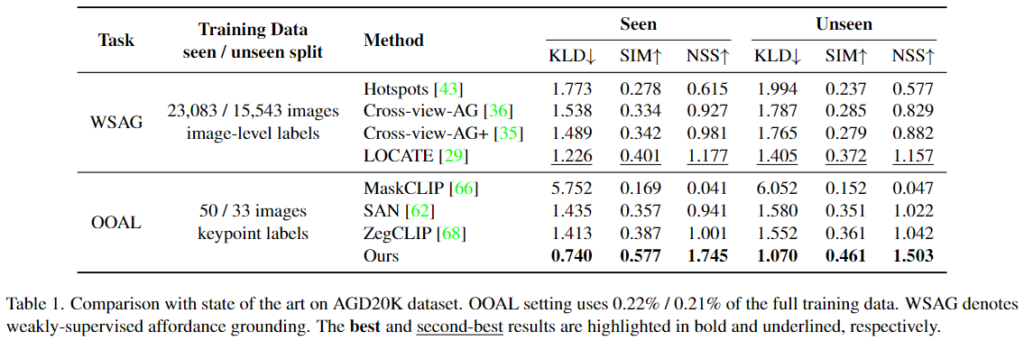
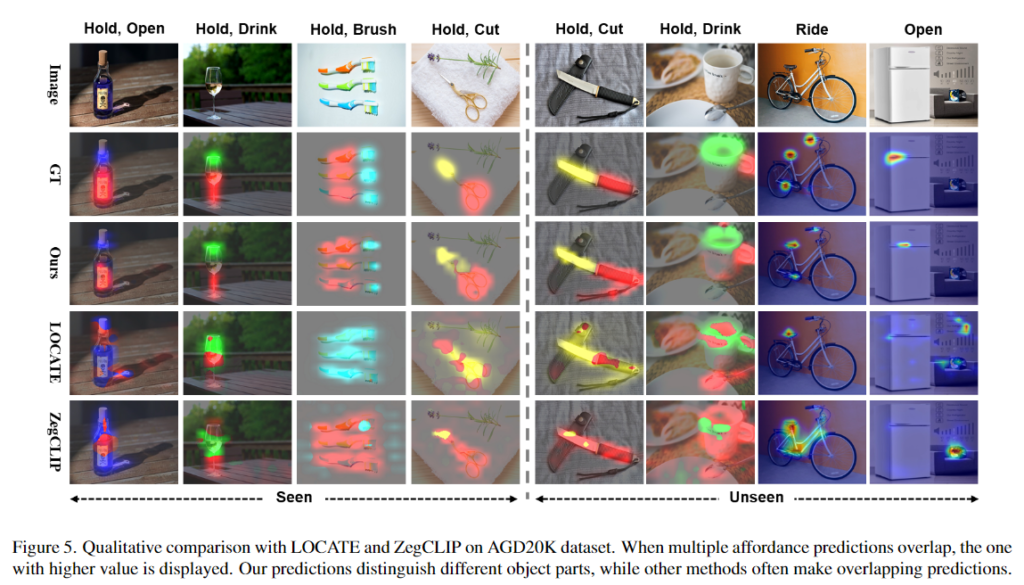
AGD20K 데이터는 이미지 수준의 weakly-supervised affordance 방식(WSAG)과 비교를 수행합니다. WSAG는 이미지 수준의 라벨을 활용하지만, 저자들이 사용한 방법론과 비교했을 때 460배가 넘는 학습 데이터를 사용합니다. 위의 Table 1은 WSAG 방법론과 비교했을 때도 가장 좋은 성능을 보이는 것을 확인하였으며, OOAL 세팅에서 평가를 위해 open vocabulary segmentation 방식인 MaskCLIP, SAN, ZegCLIP와도 비교를 하였으며, 큰 성능 개선이 이루어짐을 확인하였다고 합니다. 정성적 결과는 위의 Figure 5에서 확인하실 수 있습니다.
- UMD
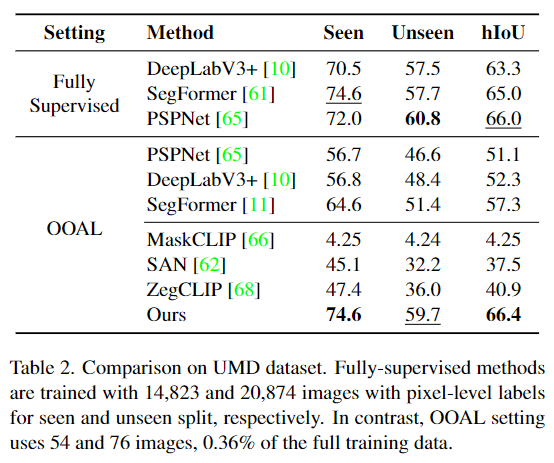
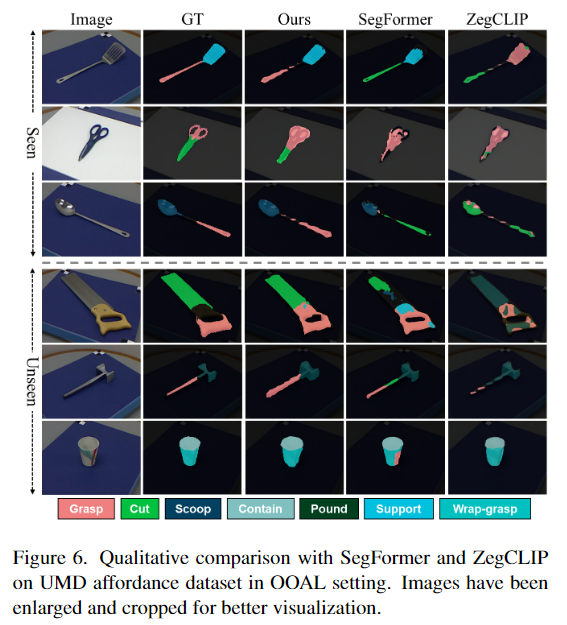
UMD 데이터 셋과의 정량적 비교는 Table 2에서 확인할 수 있으며, semantic segmentation 방법론인 PSPNet, DeepLabV3+, SegFormer와, open-vocaburary semantic segmentation 방식과 성능을 비교하였습니다. 공장한 비교를 위해 fully-supervised 방식은 전체 학습 데이터로 학습하고, ZegCLIP과 SAN과 같은 foundation 모델은 OOAL 설정에서 평가하였다고 합니다. 본 논문에서 제안된 방법론은 기존 학습 데이터의 0.36%를 이용하여 fully-supervised 방법론 만큼의 성능을 달성할 정도로 효과적임을 확인할 수 있습니다. 또한 fully-supervised 방법론들도 OOAL 세팅으로 평가하여 Seen과Unseen에서 모두 10%정도 성능이 저하되는 것을 확인하였으며, OOAL 세팅에서 CLIP 기반의 다른 open-vocabulary segmentation 방법론들과 비교해도 저자들이 제안한 방식이 뛰어난 성능을 달성하였습니다. 정성적 결과는 위의 Figure 6에서 확인하실 수 있습니다.

위의 Figure 7은 affordance에 변화를 주었을 때의 시각화 결과, Nove Aff#를 보시면 의미론적으로 유사하지만 Base와는 다른 Affordance로 추론이 이루어진 것을 확인하실 수 있습니다. 정량적 결과를 리포팅하기 위한 기준이 없어서 그런지 정량적 성능을 따로 리포팅되어있지는 않았습니다. 그러나 grasp 대신 hold, cut 대신 slice와 같이 의미론적으로 유사한 경우에 작동이 가능하다는 것이 굉장히 인상적입니다.
Ablation Study
- Different Vision Encoder
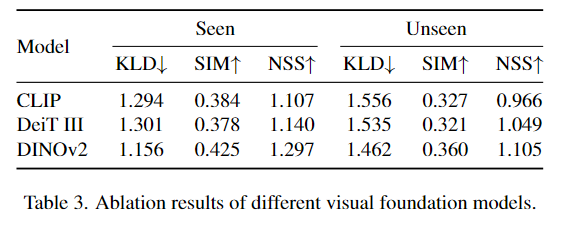
앞서 Vision Encoder에 대한 비교 분석 결과를 통해 DINOv2를 선정하였으며, Table 3은 다른 인코더를 사용할 경우의 정량적 성능입니다. 비교 결과 DINOv2가 정량적으로도 뛰어난 성능을 보여주는 것을 확인할 수 있습니다.
- Proposed Methods
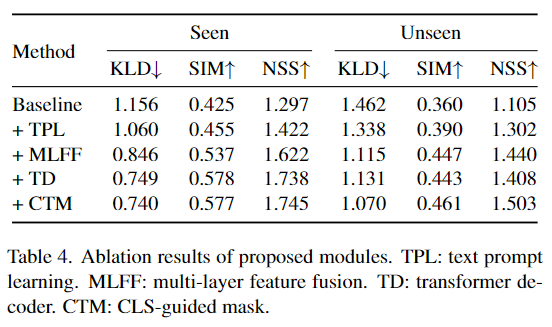
Table 4는 본 논문에서 제안된 방식에 대한 ablation 실험 결과로, 각 요소가 하나씩 추가될 수록 대체로 성능이 개선됩니다. 그러나 transformer decoder의 경우 seen 설정에서는 성능이 개선되지만, unseen에서는 성능이 저하되는 경향을 보입니다. 그러나 CLS-guided mask를 적용할 경우에는 두 설정에서 모두 성능이 개선되며, 이는 cross-attention과정에서 집중할 영역을 제한하므로써 unseen 객체에서도 효과적으로 작동한 것으로 분석합니다.
오 궁금한 논문이였는데, 리뷰를 해주셔서 감사합니다ㅏ
몇 가지 질문 남기고 가겠습니다.
1. “OOAL은 하나의 샘플만을 이용하고 다른 객체로 일반화 해야 하므로 학습한 객체와 미학습한 객체 사이의 의미론적 관계를 이해하는 능력이 필요합니다. ” 여기서 다른 객체라는 것이 다른 클래스를 의미하는 것일까요? 이전 태스크와 차별점을 설명하는 구문이였던 것 같은데… 뭔지 이해를 못하겠습니다.
2. CLIP과 DINO 임베딩 특징을 일치시도록 학습을 진행해도 affordance 수행이 가능하다는 것이 인상 깊은 논문인 것 같습니다. 근데 이런거면 SAM+CLIP 쓰면 더 효과적이지 않을까요?
질문 감사합니다.
1. 넵. 이해하신대로 다른 객체는 다른 클래스의 객체를 의미하는 것이 맞습니다. 본 논문의 예시를 통해 부가 설명을 드리자면, 칼이라는 객체로 학습하고, 다른 객체인 가위와 도끼로도 확장하는 것이 목표입니다. 기존 방법론은 support 이미지를 제공하여 새로운 객체에 대한 추가 정보를 제공하지만 해당 논문에서는 support 이미지를 사용하지 않고 다른 객체에서 affordance를 인식할 수 있어야 한다는 점에서 학습한 객체와 미학습 객체 사이에 의미론적 대응 관계를 예측할 수 있어야 한다는 것 입니다.
2. 저자들이 SAM에 대해 언급하긴 하는데, 1번 질문인 ‘ Visual-Language foundation 모델들이 affordance나 객체의 부분에 대한 프롬프트를 통해 affordance를 인식할 수 있는가? ‘를 기준으로 4가지 모델을 선정할 때는 SAM을 제외한 것으로 보입니다. 해당 논문은 아니고 이후에 SAM과 CLIP을 이용하는 방법론이 제안되기도 하였습니다.(SAM+CLIP 논문: https://arxiv.org/pdf/2405.12461)
안녕하세요 승현님, 좋은 리뷰 감사합니다.
affordance라는 개념을 승현님의 리뷰를 보고 처음 알게 되었습니다!
그래서 affordance에 대해 naive한 궁금증이 생겼는데,
Introduction의 figure 1아래서 언급된 ‘단 하나의 예시만 사용하는 상황을 대상으로 하여’ 가 정확히 무슨 뜻인가요?
어떤 물체의 여러 기능 중 단 하나의 예시 상황을 의미하나요?
그렇다면 해당 파이프라인은 한 물체가 한 기능만 한다고 가정하는 것이 되는 건가요?
한 물체가 여러가지 affordance를 가진 것(예를 들면, 장도리 망치의 경우 못을 박는 부분과 못을 빼는 부분이 있는 것처럼)에 대한 affordance segmentation 관련 연구도 있는 건가요?
질문 감사합니다.
‘먼저 단 하나의 예시 만을 사용하는 상황을 대상으로’ 한다는 것은 One-shot 방식임을 의미하는 것 입니다.
본 논문의 예시를 통해 부가 설명을 드리자면, 칼이라는 객체에 대한 이미지와 손잡이 부분과 칼날 부분에 대한 정답 마스크를 이용하여 네트워크를 학습하고, 도끼와 가위에 대해서도 칼날과 손잡이를 인식할 수 있도록 한 것 입니다.
또한 언급하신 예시처럼 장도리 망치는 못을 박는 부분과 못을 빼는 부분으로 나누고 싶을 경우 앞 뒤 영역을 나누어 라벨을 만들어 기존 affordance segmentation 연구로 적용하면 될 것으로 이해하였습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
affordance에 대한 VFM 분석 결과를 리포팅하고 있는데, 혹시 정량적 실험은 없었을까요 ?? affordance detection task를 잘 모르다보니, 정성적으로 비교 모델들의 상대적인 성능은 대략 파악할 순 있지만 정량적으로 절대적인 성능이 어느 정도인지 궁금합니다. 추가적으로 affodance에 대해 기존에 어떤 평가 메트릭을 사용하는지도 질문 드립니다 !
감사합니다.