안녕하세요. 최근에 계속해서 LLM 관련으로 논문을 읽게 되는 것 같습니다. LLM 논문을 볼 때마다 아쉬웠던 점이, 멀티모달 LLM 관련하여 vision-text 분야 LLM은 굉장히 논문이 많이 나오는데 그에 비해서 audio나 다른 modality에 대해서 LLM을 이용한 논문은 별로 없다는 점이였는데요. 그래서 text, image, video, audio, point cloud 등의 modality를 모두 다루는 OneLLM을 발견했을 때 와 이건 꼭 읽어봐야겠다 싶어서 가져오게 되었습니다. 그럼 리뷰 시작하겠습니다.
<Introduction>
Large Language Model (LLM)은 강력한 language understanding과 추론 능력으로 연구와 산업 분야에서 계속해서 인기를 키워가고 있는데요. GPT4와 같은 LLM은 여러 학술 관련된 시험에서 인간과 비슷한 성과를 얻었을 정도로 굉장한 이해 능력을 가지고 있습니다. 이에 language에 그치지 않고 multimodal로 확장해서 vision-language, audio, speech recognition과 같은 분야에도 적용될 수 있도록 최근에는 연구되고 있습니다.
이 중에 vision-language learning은 최근 반년 동안에만 무려 50개 이상의 vsion LLM이 제안되었다고 하는데 굉장히 활발하게 연구되고 있다는 것을 알 수 있습니다. 일반적으로 vision LLM은 visual encoder, LLM, 그리고 이 둘을 연결하는 projection module로 구성됩니다. vision LLM은 먼저 vision-language alignment를 위해서 대량의 image-text pair 데이터를 학습한 다음 visual instruction dataset를 fine-tuning해서 사용할 수 있습니다.
vision 외에도 audio, vidio와 같은 다른 modality별 LLM이 개발되었는데, 대부분 vision LLM의 architectual framework와 학습 방법을 이용하여 사전학습된 modality별 encoder와 잘 선별된 instruction tuning dataset에 의존하여 만들어집니다.
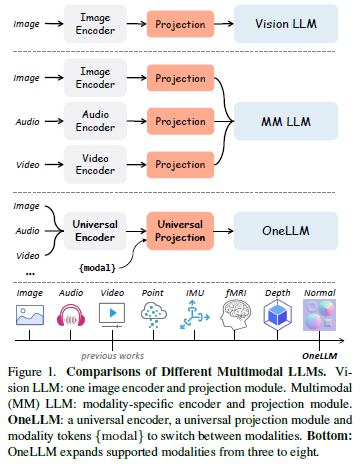
여러 modality를 하나의 LLM에 통합하려는 연구도 존재했는데, vision LLM의 확장으로, 대부분 modality별 encoder와 projection module을 사용하여 각 modality를 LLM에 align합니다. Figure1의 가운데 부분을 참고하면 각 modality별로 encoder와 projection을 가져가는 것을 확인할 수 있습니다. 그러나 이러한 modality별 encoder는 일반적으로 architecture가 다르며 single framework로 통합하는데 상당한 어려움이 있습니다. 또한, 일반적으로 image, audio, video와 같이 널리 사용되는 modality 한정으로 안정적인 성능을 제공하는 사전 학습된 encoder를 제공하기 때문에 앞에서 언급한 modality 외의 modality를 사용하기에는 확장하기 힘든 부분이 있습니다. 그래서 MLLM(Multmodal Large Language Model)에서 주요한 challenge는 “다양한 modality를 처리할 수 있는 통합 및 확장 가능한 encoder를 구축하는 것”입니다.
본 논문의 저자는 사전 학습된 transformer를 downstream 방식으로 transfer하는 연구에서 영감을 얻어 문제를 해결하고자 하였습니다. 이전의 연구[51]에서 frozen된 language 사전 학습 transformer가 image classification과 같은 downstream에서 높은 성능을 달성함 보였고, Meta-Transformer[103]는 prozen visual encoder가 12개의 서로 다른 데이터 modality에서 경쟁력 있는 결과를 얻을 수 있음을 보였는데요. 이러한 연구를 통해서 각 modality에 대해 사전 학습된 encoder가 필요하지 않을 수 있음을 시사할 수 있습니다. 대신 잘 학습된 transformer가 universal cross-modal encoder의 역할을 할 수 있겠죠.
본 논문의 저자는 최종적으로 하나의 통합 framework를 사용하여 무려 8가지 modality를 language에 맞게 align하는 MLLM인 OneLLM을 제안합니다. OneLLM은 lightweight modality tokenizer, universal encoder, unversal projection module (UPM), LLM으로 구성됩니다. 이전 연구와 달리 OneLLM의 encoder와 projection module은 모든 modality에서 공유한다는 특징이 있습니다. 각각 하나의 convolution layer로만 구성된 modality별 tokenizer는 input을 일련의 token으로 변환합니다. 또한 학습 가능한 modality token을 추가하여 modality 전환을 가능하게 하고 다양한 길이의 input token을 고정된 길이의 token으로 변환합니다.
이렇게 input을 tokenizer를 통해서 token으로 변환했으면 그 다음은 학습인데, 이렇게 복잡한 모델을 처음부터 학습하는 것은 굉장히 여러운 일인것은 분명합니다. 그래서 본 논문의 저자는 vision LLM에서 시작하여 점진적인 방식으로 다른 modality를 LLM에 align하는 방식을 사용하였습니다. 구체적으로는 아래와 같습니다.
(1) image encoder로 사전학습된 CLIP-ViT[67]를 사용하고 image projection module로 여러 transformer layer를, LLM으로 LLaMA2[78]를 사용하여 vision LLM을 구축합니다. 대량의 image-text pair data를 사전 학습한 후, projection module은 visual representation을 LLM의 embedding space에 mapping하는 방법을 학습합니다.
(2) 더 많은 modality에 align하기 위해서는 universal encoder와 projection module이 필요한데요. 앞에서 설명한 것처럼 사전 학습된 CLIP-ViT가 universal encoder 역할을 할 수 있습니다. UPM의 경우, 여러 image projection module을 여러 개 결합하여 universal X-to-language inferface로 사용할 될 수 있도록 합니다. 여기에 추가로 모델 성능을 높이기 위해 주어진 input에 대해 각 module의 weight를 제어하는 dynamic router도 같이 설계하여 UPM이 module을 부드럽게 혼합할 수 있도록 합니다. 마지막으로 데이터 규모에 따라 점진적으로 더 많은 modality를 LLM에 맞춰 align합니다.
또한, 본 논문에서는 imgae, audio, video, point cloud, depth/normal map, Inertial Measurement Unit (IMU), functional Magnetic Reasonance Imaging (fMRI) 등 8가지 modality에 걸쳐 caption, question answering, reasoning task를 포함한 대규모 multimodal instruction dataset을 curating합니다. 이러한 데이터셋을 fine-tuning함으로써 OneLLM은 강력한 mulimodal understanding 기능을 제공할 수 있습니다.
본 논문의 contribution을 정리하면 아래와 같습니다.
- multimodal input을 language와 align하기 위한 통합 프레임워크를 제안함. modality별 encoder를 사용하는 기존 연구와는 달리, 사전 학습된 vision language model과 projection module들의 혼합을 통한 multimodal encoder가 MLLM의 일반적이고 확장 가능한 구성 요소로 사용될 수 있음을 보임
- 단일 모델 내에 8개의 서로 다른 modality를 통합한 MLLM은 OneLLM이 최초임.
- large-scale multimodal instruction dataset을 큐레이팅함. 이 데이터셋 기반으로 fine-tuning한 OneLLM은 기존 MLLM을 모두 능가하는 성능을 달성함.
<Method>
<Model Architecture>
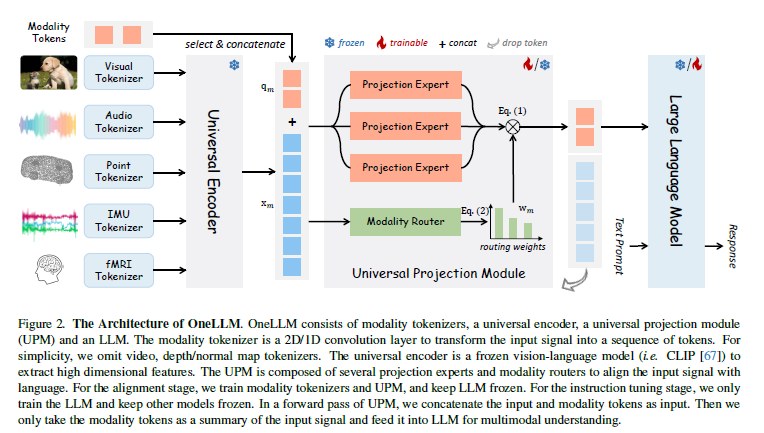
Figure 2를 통해서 OneLLM의 전체적인 구조를 확인할 수 있는데요. OneLLM은 modality별 tokenizer, universal encoder, universal projection module (UPM), LLM으로 구성됩니다. 각 요소에 대해서 차근차근 설명드리겠습니다.
<LightWeight Modality Toekenizers>
modality tokenizer는 input을 token sequence로 변환하여 transformer 기반 encoder가 이러한 token을 처리할 수 있도록 합니다. input token은 $x \in \mathbb{R}^{L\times{D}}$로 표시하며, 여기서 L은 sequence length이고 D는 token dimension을 의미합니다. 본 논문에서는 다양한 modality data에 내재된 특성(여기서 내재된 특성이란 다른 종류의 modality가 가진 고유한 특성을 의미합니다) 고려하여 각 modality에 대해 별도의 tokenzer를 설계합니다.
image, video와 같은 2D position information이 포함된 visual input의 경우, single 2D convolution layer를 tokenizer로 사용합니다. 다른 modality의 경우, input을 2D 또는 1D sequence로 변환한 다음 2D/1D convolution layer를 사용하여 토큰화합니다. audio를 예를 들어 설명해보겠습니다. audio input이 들어오면 이를 2D spectrogram으로 변환하여 토큰화합니다.
<Unversal Encoder>
앞에서 언급한 바와 같이 사전 학습된 frozen transformer는 강력한 modality transfer capability를 보여주는데요. 따라서 모든 modality를 위한 universal encoder로 사전 학습된 vision-language model을 활용합니다. 광범위한 image-text data로 학습된 vsion-language model은 일반적으로 vision과 language 간의 align을 강하게 학습하기 때문에 다른 modality로 쉽게 transfer할 수 있습니다. OneLLM에서는 universal computation engine으로 CLIP-ViT을 사용합니다. 학습 중에서는 CLIP-ViT 파라미터를 prozen하여 학습합니다. video를 예시로 들면, 모든 video frame을 병렬로 encoder에 비력하고 frame간 token-wise averaging 수행하여 학습 속도를 높이는 방식으로 CLIP-ViT를 사용할 수 있습니다. 이렇게 하면 video 데이터를 효율적으로 처리할 수 있고, toekn concat 등의 방식을 사용하여 모델의 video understanding capability을 더 향상시킬 수 있습니다.
<Universal Projection Module>
modality별 projection module을 사용하는 기존 연구와는 달리, 본 방법론에서는 모든 modality를 LLM의 embedding space에 projection하기 위해 universal projection module (UPM)을 사용하였습니다. Figure 2에서 볼 수 있듯이 UPM은 $k$개의 projection module(그림에서는 projection expert라고 표현했습니다) {$P_k$}로 구성되며, 각 module은 image-text data에 대해 사전 학습된 trasnformer layer의 stack입니다. 여기서 더 많은 modality로 확장 할 때는 병렬로 추가하여 사용할 수 있습니다.
본 논문에서는 여러 개의 projection expert를 하나의 module로 통합하기 위해 각 expert의 기여도를 제어하고 modal capacity를 늘리기 위해 daynamic modality Router $R$를 제안하였습니다. router $R$은 input token을 받아 각 expert에 대해 routing weight를 계산하는 Multi-Layer Perceptron, 즉 soft router로 구성됩니다. 또한, 학습 가능한 modality toekn $\{q_m\}_{m \in M}$을 추가하여 modality를 전환할 수 있도록 합니다. 여기서 M은 modality set이고, $q_m \in \mathbb{R}^{N\times{D}}$는 dimension $D$의 $N$ token을 포함합니다. modality $m$의 forward pass에서는 input token $x_m \in \mathbb{R}^{L\times{D}}$와 modality toekn $q_m$의 concat을 UPM에 입력합니다.
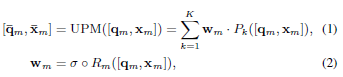
여기서 $w_m \in \mathbb{R}^{N\times{K}}$는 routing weight이고, SoftMax function σ은 $\sum^K_{k=1} w_{m,k} = 1$을 보장합니다. 모든 modality $m$에 대해 input의 summary으로서 projection된 modality token $\bar{q_m}$만 추출하여, 다양한 길이의 $x_m$을 일정한 고정된 길이의 token으로 변환합니다.
<LLM>
본 논문에서는 오픈소스인 LLaMA2를 OneLLM framework의 LLM으로 사용합니다. LLM에 대한 input에는 projection된 modality token $\bar{q_m}$과 word embedding 후의 text prompt가 들어갑니다. 논문의 저자는 단순화를 위해서 항상 input sequence 시작 부분에 modality token을 넣었다고 합니다. 그런 다믕 LLM은 modality token과 text prompt에 따라 답변을 생성합니다.
<Progressive Multimodal Alignment>
multimodal alignment를 위한 나이브한 접근 방식은 multimodal-text data에 대해 모델을 공동으로 학습시키는 것인데 이렇게 multimodal data에 대해 모델을 직접 학습하게 되면 data scale의 불균형으로 인해 modality간에 편향된 representation이 발생할 수 있습니다. 그래서 여기서는 먼저 image-text를 이용하여 학습한 뒤에 그 후에 점진적으로 다른 modality를 LLM에 적용하는 방법을 제안하였습니다.
<Image-Text Alignment>
먼저 image tokenizer, 사전 학습된 CLIP-ViT, image projection module $P_I$와 LLM으로 구성된 vsion LLM framework를 이용하여 학습합니다. image-text data가 다른 modality에 비해서 상대적으로 풍부하다는 점을 고려하여 먼저 imgae-text data로 모델을 학습하여 CLIP-ViT와 LLM을 잘 align하는, 즉 좋은 image-text projection module을 학습합니다. 사전 학습된 $P_I$는 imag와 language를 연결하는 다리 역할을 할 뿐만 아니라 multimodal text alignment를 위한 좋은 초기값을 제공합니다. 그런 다음 사전 학습된 여러 $P_I$를 혼합하여 UPM을 구축합니다. $P_I : UPM =\{P_k\} = \{Init(P_I)\}$로 표현할 수 있고 여기서 $Init$은 weight initialization을 의미합니다. 이를 통해 다른 modality를 language에 align하는 cost를 효과적으로 줄일 수 있습니다.
<Multimodal-Text Alignment>
Multimodal-Text alignment를 continual learning process로 구성합니다. timestamp $t$에서 $M_1 ∪ M_2, …, M_{t-1}$ modality set에 대해 모델을 학습시킵니다. 이때 현재 학습 데이터는 $M_t$ 입니다. 여기서 catastrophc forgetting을 방지하기 위해서 이전 학습 데이터와 현재 데이터 모두에서 균등하게 sampling합니다. 본 논문의 경우, multimodal text alignment 학습할 때 데이터 크기에 따라 1단계(image), 2단계(video, audio, point cloud), 3단계(depth/normal map, IMU, fMRI)로 학습 단계를 나눠 가져갔습니다. 만약에 새로운 modality를 추가하고 싶다면 이전 modality에서 비슷한 양의 데이터를 sampling하고 현재 modality와 공동으로 모델을 학습하는 식으로 학습하여 modality를 추가할 수 있습니다.
<Multimodal-Text Dataset>
본 논문에서 어떻게 각 modality에 대해 X-text pair를 수집하였는지 대해서 설명하는데, 각 modality별로 데이터셋을 수집하여 pair를 구성하였습니다. 아래는 참고용으로 작성하였으니 간단히 어떤 데이터셋을 사용했는지만 봐주시면 감사하겠습니다.
- image : LAION-400M, LAION-COCO 사용
- video : WebVid-2.5M
- audio : WavCaps
- point cloud : cap3D
- depth/normal map : large-scale depth/normal map-text 데이터셋이 없기 때문에 사전 학습된 DPT 모델을 사용하여 depth/normal map을 생성하였다고 합니다. source image와 text는 CC3M에서 가져왔다고 합니다.
- IMU : Ego4D
- fMRI : NSD
<Unified Multimodal Instruction Tuning>
Multimodal text alignment가 끝나면 OneLLM은 모든 input에 대한 간단한 description을 생성할 수 있는 multimodal captioning model이 됩니다. OneLLM의 multimodal understanding, reasoning capabilities를 최대한 활용하기 위해서 large-scale multimodal instruction dataset을 cureting하여서 OneLLM을 fine-tuning 할 수 있습니다.
<Multimodal Instruction Tuning Dataset>
본 논문에서 각 modality에 대한 instruction tuning (IT) dataset을 구성하였는지에 대해 설명하였는데, 아래는 참고용으로 작성하였으니 어떤 데이터셋을 사용했는지만 봐주시면 감사하겠습니다.
- image : LLaVA-150K, COCO Caption, VQAv2, GQA, OKVQA, AOKVQA, OCRVQA, RefCOCO, Visual Genome
- video : MSRVTTCap, MSRVTT-QA
- audio : AudioCaps
- point cloud : PointLLM에 사용된 70K point cloud description, conversation, reasoning dataset
- depth/normal map : image IT 데이터셋를 사용하여 생성 (LLaVA-150K에서 30K visual insturction data를 random하게 sampling하고 DPT 모델을 사용해서 depth/normal map을 생성)
- IMU : Ego4D에서 random하게 sampling
- fMRI : NSD에서 random하게 sampling
<Prompt Design>
multimodal IT 데이터셋 내의 다양한 modality와 task를 고려하여서 Prompt를 설계하였는데요. 서로 다른 modality를 사용하다 보니 이들 간의 충돌을 피하기 위해서 Prompt를 설계할 필요가 있습니다. 그래서 논문의 저자는 아래와 같이 prompt를 구성하였습니다.
(a) GPT4에서 생성된 IT 데이터셋 (예를 들어서 LLaVA-150K)를 활용할 때는 데이터셋에서 제공하는 원래 prompt를 사용하였습니다.
(b) captioning task의 경우, 다음과 같이 prompt를 사용합니다 : “Provide a onesentence caption for the provided {modal}.”
(c) opended question answering task의 경우, “Answer the question using a single word or phrase.”를 사용하여 question을 강조하여 가져갑니다.
(d) option이 있는 question answering task의 경우, 다음과 같이 prompt를 사용합니다 : “{Question} {Options} Answer with the option’s letter from the given choices directly.”
(e) IMU, fMRI 데이터셋의 경우, “Describe the motion” 혹은 “Describe this scene based on fMRI data.”과 같은 prompt를 사용합니다.
instruction tuning 단계에서는 input sequence를 {$\bar{q}, Sys, [Ins_t, Ans_t]^T_{t=1}$}와 같이 구성하여 가져갑니다. $\bar{q}$는 modality token, $Sys$는 system prompt, $[Ins_t, Ans_t]$는 conversation에서 t번째 instruction-answer pair를 말합니다.
<Experiment>
자 그럼 이제부터 이 OneLLM이 어느정도의 성능을 보이는지 실험으로 확인해보고자 합니다.
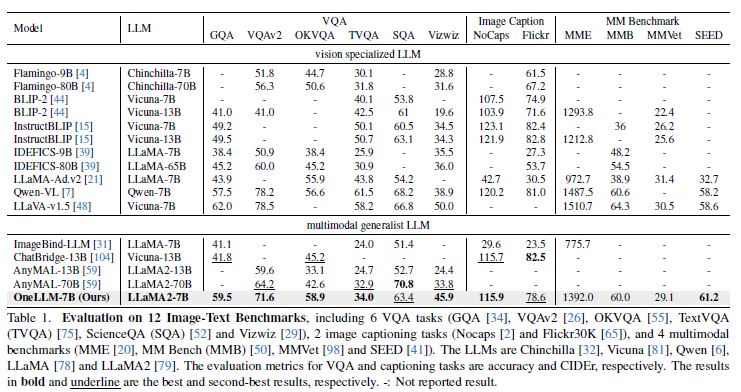
Table 1을 통해서 OneLLM이 VQA, image captioning과 최근의 multimodal benchmark에서 어느정도의 성능을 발휘하는지 확인할 수 있습니다. VQA task에서 OneLLM이 다른 MLLM에 비해서 높은 성능을 달성한 것을 확인할 수 있습니다. ChatBridge, AnyMAL과 비교하면 큰 폭으로 높은 성능을 달성하였습니다. image captioning task에서는 OneLLM이 ChatBridge와 비슷한 성능을 달성한 것을 볼 수 있습니다. 이러한 결과를 확인하면 OneLLM이 vision task를 위해서 특별히 설계된 것이 아님에도 불구하고 OneLLM이 vision 특화 LLM와 견주할 수 있다는 것을 통해 MLLM과 vision LLM 간의 격차가 굉장히 좁혀진 것을 확인할 수 있습니다.
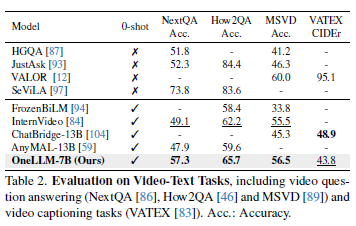
Table 2를 통해 Video QA, captioning task에서 OneLLM 성능을 확인할 수 있습니다. OneLLM이 MLLM과 video-specific model에서 모두 성능이 뛰어난 것을 확인할 수 있습니다.
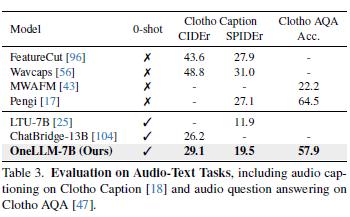
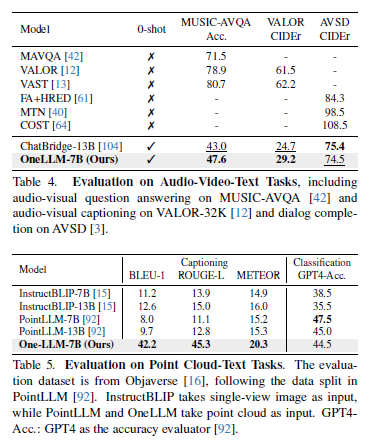
Table3, 4, 5는 차례대로 Audio-Text, Audio-Vidio-Text, Point Cloud-Text task에서의 OneLLM 성능을 표시합니다. 위에서 언급한 것처럼 각 task에 특화된 모델에 비해서 OneLLM이 MLLM과 비교해서도 높은 성능을 달성한 것을 확인할 수 있습니다.
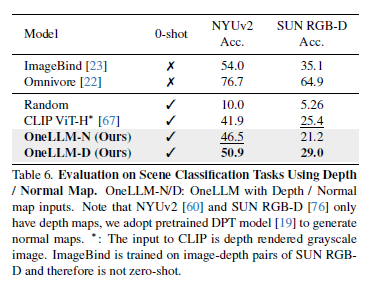
Table 6에서는 Depth/Normal map을 이용한 task에서의 성능을 확인할 수 있는데, OneLLM이 CLIP에 비해서 높은 zero-shot classification accuracy를 달성한 것을 볼 수 있습니다. 논문의 저자는 이러한 결과를 통해 synthetic depth/normal map 데이터로 학습된 OneLLM이 real world 시나리오에서도 잘 working할 수 있음을 보인다고 합니다.
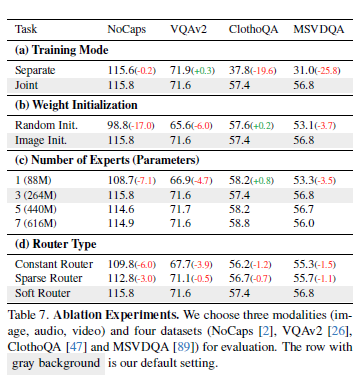
Table 7을 통해 ablation study를 확인할 수 있습니다. Table 7(a)는 ‘공동으로 학습된 MLLM이 modality별 MLLM보다 더 좋은가’를 확인하기 위한 실험입니다. 개별적으로 학습할 경우, 모델이 자신의 데이터에만 접근할 수 있지만, modality를 공동으로 학습하는 경우 모델이 모든 데이터에 대해 접근 할 수 있는데요. 여기서 주요한 포인트는 image-text task인 NoCaps, VQAv2에서는 Separate와 Joint 모두 비슷한 성능을 보이는 것에 비해서 audio, video task에서는 Separate가 Joint에 비해서 굉장히 성능이 떨어지는 것을 확인할 수 있는데, 이는 Joint training이 학습한 knowledge를 여러 modality에 걸쳐 transfer할 수 있게 함으로써 데이터가 부족한 modality에 상당한 이점을 제공한다고 말할 수 있습니다.
Table 7(b)를 통해서 image alignment가 multimodal alignment에 도움이 되는 가를 확인할 수 있는데, OneLLM이 random 초기화된 모델을 사용하여 모든 modality를 text에 직접 align하면 성능이 매우 떨어지는 것을 통해 image-text alignment가 multimodal alignment에 도움이 되었음을 확인할 수 있습니다.
Table 7(c)는 Projection Experts의 수에 따른 성능 변화를 실험을 통해 확인한 것입니다. UPM의 projection expert 수는 OneLLM이 수용할 수 있는 modality 수와 밀접한 관련이 있는데, 표를 통해 확인할 수 있듯이, expert의 수를 3으로 가져가는 것만으로도 모든 modality를 수용하기에 충분함을 확인할 수 있습니다.
Table 7(d)를 통해서 어떤 router type을 가져가는지에 따른 성능 변화를 확인할 수 있습니다. modality router는 여러 projection experts를 단일 module로 연결하는 역할을 합니다. constant router, sparse router, soft router 이렇게 3가지 type의 router가 있는데, (a) constant router는 k개의 experts를 constant number 1/K로 연결합니다. constant router의 output은 $\sum^K_{k=1} 1/K P_k(x)$입니다. (b) sparse router는 maximum routing weight를 가진 expert하나만 선택합니다. output은 $w_{k*} P_{k*}(x)$와 같습니다. Table을 통해 성능을 확인해보면 soft router가 다른 두개의 router에 비해서 높은 성능을 보이는 것을 확인할 수 있고, multimodal signal의 dynamic routing에 효과적임을 볼 수 있습니다.

각 8개 modality에 대한 Prompt가 주어졌을 때 OneLLM이 어떻게 대답하는지에 대해서 Figure 3을 통해서 확인할 수 있습니다. 정말 신기한 것이 fMRI랑 IMU 데이터에 대해서 잘 이해하고 잘 답변하는 것인데요. 물론 각 데이터셋에 대해서 fine-tuning을 했다고는 하지만 모든 modality에 대해서 잘 답변하는 것이 대단하다고 생각합니다.

Table 12를 통해서 다른 MLLM에 비해서 얼마나 많은 Modality를 지원하는지 확인할 수 있는데 OneLLM이 압도적으로 많고, Encoder 또한 많은 modality를 사용하는 것에 비해서 1개만 사용하는 것을 확인할 수 있습니다. Encoder Param도 다른 MLLM에 비해서 굉장히 작은 것도 엄청난 장점인 것 같습니다.
+) Table 12로 마무리하려고 했는데, GPU와 관련하여 질문이 들어올 것 같아 추가 작성합니다. GPU와 관련하여 간단한 실험 셋팅을 말씀드리면, 앞에서 multimodal text alignment 시에 단계별로 데이터셋을 나눠 학습한다고 말씀드렸는데, 1단계 학습시 A100 16개를 사용하였다고 합니다. 이때 batch size는 5120 이였다고 하네요…. 2단계와 3단계에서는 GPU를 8개 사용하여 학습했다고 합니다. 확실히 많은 modality를 다루다 보니 많은 GPU를 요구하는 건 어쩔 수 없는 부분인 것 같기도 합니다.
본 논문을 읽으면서 이전에 리뷰한 [CVPR 2024] Multimodal Representation Learning by Alternating Unimodal Adaptation 논문이 생각났는데요. 이전의 trend가 각 멀티모달에서 모달리티 encoder를 어떻게 가져가고 어떻게 통합하는지 였다면, 지금의 trend는 각 modality를 어떻게 함께 잘 학습을 시킬까가 중점인 것 같습니다. (뭔가 둘이 같은 말처럼 느껴지기도 하는데 좀더 구체적으로 말하면 어떻게 모달리티를 왔다 갔다 하면서 학습시킬 수 있을까?의 느낌으로 가져가시면 좋을 것 같습니다) 최근에 참신한 논문들이 많이 나와서 읽는 재미가 있는 것 같습니다. 지금까지 읽어주셔서 감사합니다.
[51] Kevin Lu, Aditya Grover, Pieter Abbeel, and Igor Mordatch. Pretrained transformers as universal computation engines. arXiv preprint arXiv:2103.05247, 1, 2021.
[67] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763. PMLR, 2021.
[78] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[103] Yiyuan Zhang, Kaixiong Gong, Kaipeng Zhang, Hongsheng Li, Yu Qiao,Wanli Ouyang, and Xiangyu Yue. Metatransformer: A unified framework for multimodal learning. arXiv preprint arXiv:2307.10802, 2023.
안녕하세요 김주연 연구원님 좋은 리뷰 감사합니다.
intro 부분에서는 여러 모달리티를 하나의 llm에 통합할 때 각 모달리티 별 encoder를 사용하기 때문에 통합이 어려웠다고 언급해 주셨는데요, 본 논문에서는 모든 모달리티에 대해 사전 학습된 vision encoder를 freeze하여 universal encoder로 사용했다고 이해하면 되는 걸까요?
universal projection module은 k개의 projection modlue로 이루어져 있으며 모달리티를 확장할 경우 projection module을 추가하여 사용할 수 있다는 설명을 보고 각 projection module은 하나의 모달리티에 대한 projection layer라고 이해하였는데요, 그렇다면 k는 기존에 학습된 모달리티를 의미하나요?
안녕하세요. 댓글 감사합니다.
1) 네 맞습니다. 근데 여기서 주의할 점은 모든 모달리티에 대해서 “이미” 학습된 vision encoder를 사용한 것은 아니라고 생각이 듭니다.
2) 여기서 반드시 하나의 모달리티 – 하나의 모듈로 매칭이 되는 것은 아니기 때문에 k 개는 기존에 학습된 모달리티로 이해하기 보다는 하이퍼파라미터라고 생각하시면 될 것 같습니다. Table 7을 보면 이를 조정하는 실험을 볼 수 있는데 여기서도 모달리티 수에 맞춰 모듈 수를 가져가지는 않은 것을 볼 수 있습니다.
감사합니다.