안녕하세요. 지난 2번의 리뷰 간 MSDA OD, Mulit-Source Domain Adaptation for Object Detection 논문을 리뷰하였습니다. 맨 처음 리뷰한 논문은 DMSN으로 DAOD, Domain Adpataion for Object Detection에서 처음으로 Source와 Target의 1:1 매칭이 아닌 N(다):1 매칭을 통한 DAOD의 성능 향상을 소개하였습니다. DMSN의 저자는 “Source 도메인의 데이터셋을 둘 이상 사용함이 더 현실적인 활용방법이며 성능 향상에 도움이 될 수 있지만, Source 도메인 간의 Domain shift 현상을 고려해야하므로 도전적인 과제임”을 주장합니다. 최근 리뷰한 논문은 MSDA OD의 세 번째 논문인 PMT는 코드가 공개되어 있어 리뷰하였으며, Prototype과 Mean teacher를 사용하였으나 직접 깃헙을 확인하니 코드는 절반만 공개되어 있었습니다. 이번에 리뷰하는 통칭 TPKP는 두 논문(2021, 2023)의 중간 시점인 2022년에 나온 논문으로 읽어보니 신박한 아이디어는 없었지만 MSDA OD의 흐름 중 하나로 편히 읽을 수 있었습니다. 내용이 어렵진 않고 복잡한 수식은 쉬운 방식으로 설명할테니 가볍게 읽어보시면 좋을듯 합니다.
Introduction
이전 두 리뷰한 논문과 동일한 내용입니다. CNN은 Training에서 경험하지 못한 Unseen 환경의 데이터에 대해 Domain shift 현상으로 인해 성능이 하락합니다. Domain shift의 일례로는 MS-COCO에서 학습한 데이터로 Pascal VOC에서 평가하였을 때는, 데이터의 수가 MS-COCO가 더 방대함에도 Pascal VOC로 학습한 모델에 비해 성능이 하락하며 이는 곧 즉 한 데이터에서 학습한 모델이 일상적인 센서에서 획득한 데이터에서 좋은 성능을 보이지 못할 것임을 의미합니다. 해당 태스크를 수행하는 이유는 우리가 실시간 센서에서 획득한 데이터는 실시간으로 Annotation하기는 어려우며 대용량으로 학습한 이후에도 모델은 좋은 성능을 보여야하기 때문입니다. 이에 대처하고자 UDA(Unsupervised Domain Adaptation)에 관한 연구가 진행되었으며 주로 Classification에서 수행되었습니다. DAOD(Domain Adaptive Object Detection)는 Localization이 포함되어 있으므로 특히 Background가 영향을 많이 받는 특성 상 Domain shift로 인한 성능 저하가 더욱 두드러집니다.
진행되어오던 DAOD 연구들은 주로 Adversarial feature alignment, Semi-supervised learning등에 초점이 맞춰져 있으며 전자는 GRL(Gradient Reversal Layer)을 통해 Source와 Target의 image/instance/category-level의 feature alignment를 수행하며 후자는 Pseudo-label을 활용하여 모델을 학습합니다. 앞선 글 소개에서 언급한 바처럼, MSDA는 Multi-Source를 사용함이 더 현실적이며 다양한 응용이 됨을 언급하는데, 이때는 Source 간의 Domain shift를 해결함이 중요합니다. 본 논문 등장 시점까지 MSDA OD의 연구는 DMSN 논문이 유일하였는데, 저자는 DMSN이 Multi-source를 이른 시점에서 Alignment하려는 시도가 각 Source 도메인의 지식을 저하시키며 Target 도메인과 관련된 Alignment를 위한 Loss memory bank를 활용하지만, 저자는 이 부분이 데이터셋 수준에서 일어남이 아닌 배치 단위에서만 수행되므로 Local-optimum에 빠진다고 합니다. 저자는 이 문제를 극복하고자 본 논문에서 Target-relevant knowledge를 학습함을 목표로합니다. 다른 Source 도메인 간의 Domain knowledge degradation을 줄임과 동시에 Target에 adaptive한 학습을 목표로 합니다. 방법론은 어렵지 않으니, 살펴보겠습니다.
Method
Framework Overview
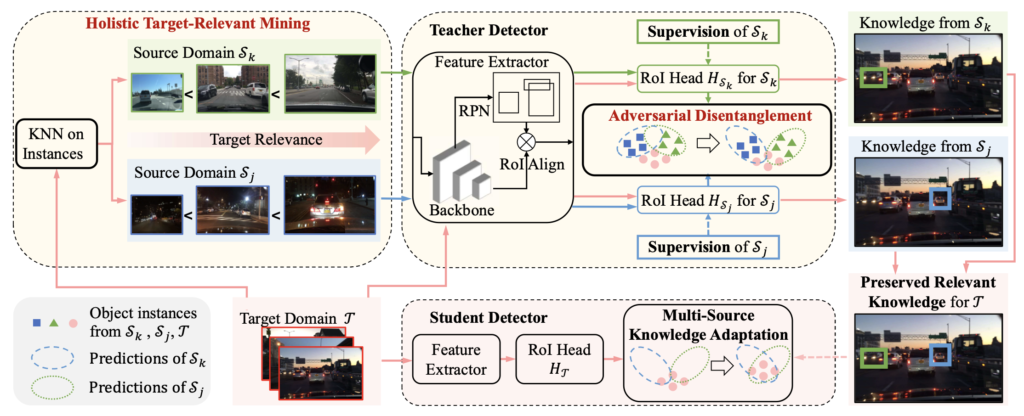
MSDA는 K개의 Labeled-source 도메인과 1개의 Unlabeled-target 도메인으로 구성되어 있습니다. MSDA의 목표는 Unlabeled-target 도메인에서 좋은 성능을 보여야하므로, 이 목적을 위해선 Source에서 학습한 모델이 Target과 관련된 knowledge를 잘 보존해야할 필요가 있습니다. 저자는 이를 위해 Teacher-student 프레임워크를 도입하며, 이 프레임워크는 앞서 말한 Source와 Target간의 Knowledge 전달, 그리고 두 도메인 간의 Gap을 줄일 수 있습니다. 위 Figure에서 보이는 바와 같이 Teacher Detector와 Student Detector가 각각 존재하며, Student(StDet)는 Teacher(TeDet) 모델의 EMA를 통해 파라미터를 전달받습니다. Source 도메인과 달리 Target 도메인에 대해서는 Annotation이 존재하지 않으므로 Pseudo-label을 생성하고, 이 Pseudo-label은 Student 모델을 지도학습 방식으로 학습시킵니다. 우리가 이미 잘 아는, Teacher-Student를 도입한 외에는 자세한 모듈들은 뒤에서 다시 살펴보겠습니다.
Knowledge Degradation in MSDA
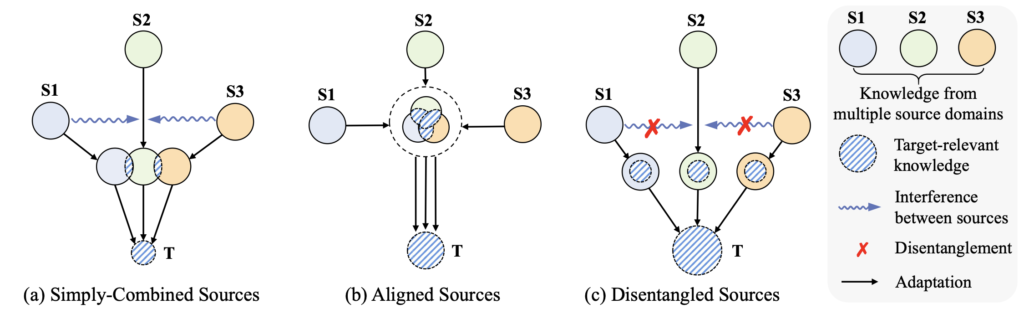
현재의 MSDA 접근법은 위 Figure의 (a): 모든 Source 도메인 (S1, S2, S3)를 하나로 묶어 학습시키는 단순한 방법이 있습니다. 이 방법은 하나의 Source (S1)가 다른 Source (S2, S3)에 대해 부정적인 간섭을 주어 결과적으로 성능 하락을 불러옵니다. 그러면서 이 방법은 Source간의 Domain shift로 인해 Target-relevant knowledge도 저하됩니다. 반면, MSDN에서 취한 (b)의 방식은 다른 Source 도메인 간의 Alignment를 진행하는데, Target 도메인에 대한 Guidance 없이 Knowledge를 이전하므로 성능이 좋지 않다고 합니다. 반면, 본인들의 (c): Disentangled Sources는 Multiple-source의 각 도메인이 Target과 어떤 관련된 Weight을 만들 수 있는지에 대해 학습한 이후 이를 통해 Target에 Adaptation하는 방법입니다.
Knowledge degradation을 극복하고자 저자는 Teacher 모델 (TeDet)의 학습에 AMSD (Adversarial Multi-Source Disentangle)를 제안하는데, 이 AMSD는 Domain-specific knowledge를 각 Source로부터 인코딩하며, 서로 간의 간섭을 없애는 일입니다. 아래의 Figure를 살펴보면 TeDet은 각 Source 도메인을 입력으로 받는 하나의 Bace network(Backbone과 Region Proposal Network)와, 각각의 RoI detection head (H)를 가지며, Base network를 통과한 이후 거치는GRL(Gradient Reversal Layer)를 가집니다. 저자는 이렇게 설계한 프레임워크가 각각 Source 도메인의 knowledge를 보존하며 (각각의 RoI detection head 덕분에) 동시에 GRL을 통해 Source 도메인 간의 역방향 Gradient 학습을 통해 만든 Feature를 서로 다른 Source 도메인의 detection head에 통과시키니, 각각의 RoI detection head는 Source 간의 Domain shift도 방지할 수 있다고 언급합니다.
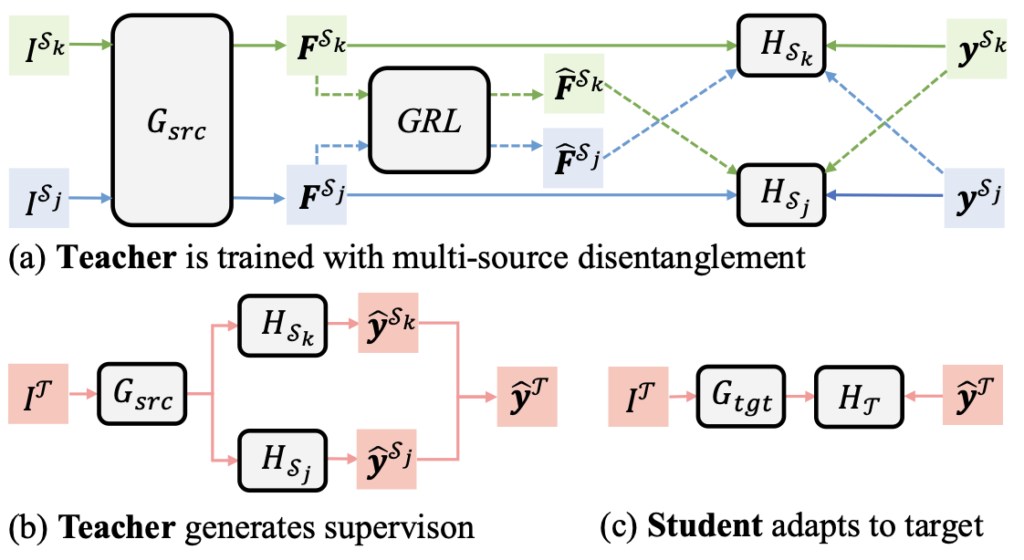
(b) Target에 대한 Teacher 모델은 Teacher와 동일한 구조로, Base network 이후 각 Source 도메인에서의 RoI detection head를 그대로 가져오며, 이들에서 나온 통합하여 하나의 Pseudo-label을 생성하며, 이 Pseudo-label이 (c)의 동일한 프레임워크 구조를 가져가는 Student 모델의 학습에 사용됩니다. 하지만 저자이 프레임워크에서 GRL을 통해 거친 서로 다른 Source 도메인의 Feature가 서로 다른 RoI detection head의 입력으로 들어감 외에는 기존의 GRL을 사용하는 방식과의 큰 차이점은 느끼지 못합니다. 물론 저자가 이전 DMSN 논문의 약점으로 Target-relevant한 knowledge가 없음을 언급하고 배치 내의 Memory bank만을 사용함이 Local-optimum에 빠진다고 언급은 하였으나, 현재의 구조가 과연 Source 도메인 간의 Shift를 방지하는지에 대해 큰 도움이 되는지는 와닿진 않습니다. 그럼 다음 방법을 살펴보겠습니다.
Multi-Source Knowledge Adaptation & Holistic Target-Relevant Mining
Teacher 네트워크의 학습 이후, 각 RoI detection head로부터 나온 Domain-specfic knowledge는 Student 모델의 학습을 통해 Adaptation됩니다. Target 도메인에 대한 이미지를 받은 이후 각 Detection head는 각각의 예측을 생성한 이후, 평균 내어 최종 하나의 Pseudo-label을 생성하며, 이를 통해 Stduent 모델을 학습시키는데, 이 때 저자는 Student가 Teacher를 그대로 사용하면 Overfitting되어 학습이 안될 수 있으므로 EMA(Exponential Moving Average) 방식으로 Teacher 모델의 평균을 Student 모델 파라미터 업데이트에 사용하는 방식을 그대로 사용합니다. 또한, Teacher 네트워크에 대해 Source로 학습할 때는 Target에 대한 Guidance가 없이 Source 만으로 학습되기 때문에, Target 도메인과 연관이 있는 이미지인지, 그렇지 않은 이미지인지와 상관 없이 (음, 제가 이 문장을 읽고 궁금한 점은 Target 도메인과 연관이 있는/없는 이미지가 Source에서 알아야하는지, 그렇다면 연관성은 어떻게 알 수 있는지가 먼저 궁금합니다만, 제 이해가 부족한지 이 부분에 대한 이해력이 떨어집니다).
따라서 저자는 HTRM(Holistic Target-Relevant Mining)을 제안하는데, 이는 Teacher 네트워크가 Target과 관련이 있는 knowledge를 Global-level에서 인코딩하며, 각 Source 도메인의 이미지에서 Target-relevant한 Weight을 부여할 수 있습니다. 이를 위해서 저자는 우선 위의 Base network로부터 Feature를 추출하고, (이 때 Background의 영향성을 없애고자 RoI에 대해서만 수행됨) 이 과정을 전체 Domain의 전체 이미지에 대해 반복하고 나면 최종으로 Source 도메인에서 Instance-level의 Feature set을 얻게 될 것 입니다. 이제 Target 도메인도 Annotation이 존재하진 않지만 Pseudo-label이 있으니, 이 Pseudo-label로부터 Target 도메인에서의 Instance-level Feature set을 구축합니다. 여기서 저자는 KNN을 적용시키는데, Cross-domain 간의 연관성을 보고자 Target 도메인의 각 Feature에 대해 KNN을 수행하고, Source 도메인의 Feature set으로부터 Consine distance를 통해 유사성을 측정합니다. 이후 K번째 Source 도메인의 Feature에 대해 Target 도메인의 KNN 결과의 Cluster에 대해 얼마나 속하는지 (몇 번 Counting되는지의 빈도를 측정한 이후, 이를 Target-relevance로 선정하고 다음의 Weight으로 Loss function을 구성합니다.

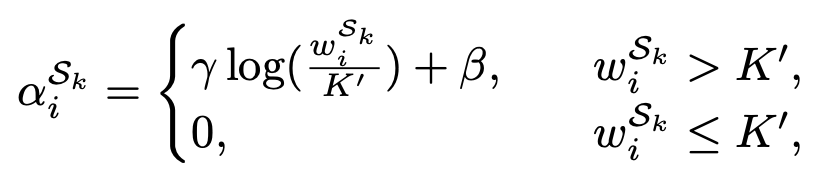
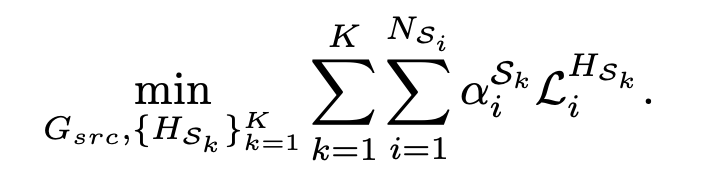
위 Relevance weigt가 커지면 Source와 Target간 연관성이 높음을, 그렇지 않으면 낮음을 의미합니다. 이는 결국 (Target-relevant) Teacher 네트워크의 학습에 적용되며 기존의 Focal loss 등의 loss에 곱해져 Re-weighting하는 효과를 보입니다. 방법론을 여기서 끝입니다. 전체적으로 보면 결국 저자는 Teacher-Student 구조를 가져오며, EMA 방식을 통해 Student를 업데이트하며 Teacher에 대해선 Source 도메인과 Target 도메인 간의 연관성을 보고자 Target-relevant Reweighting을 KNN을 통해 구현하였습니다. 이 방식에 사용된 KNN, EMA 등이 다소 흔히 사용된 방법들이라 어렵진 않았으나, 이 방식이 어떻게 Target-relevance를 측정하는지 살펴보는게 굉장히 쉽지 않았습니다. 방법론을 읽을 때만 해도 “아, 아, 그래 아는 것 들이지”하고 넘어가며 읽었는데, 다 읽고 나서 리뷰를 쓸 때는 굉장히 어렵네요. 실험으로 넘어가겠습니다.
Experiments
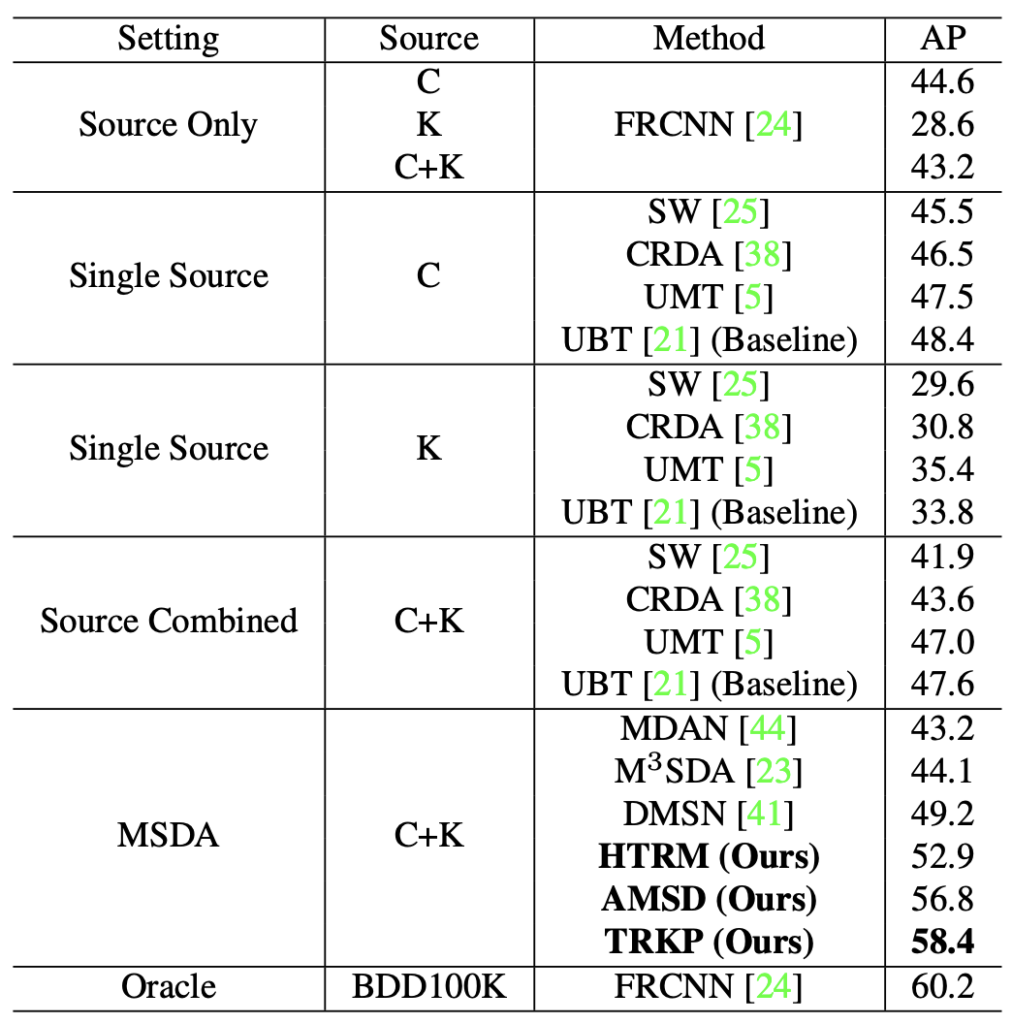
실험은 이전 두 번의 리뷰와 동일하게, Cross-Time, Cross-Camera, Mixed로 구성됩니다. 실험 세팅에 대한 아쉬움은 제가 이전에 몇번 언급하였으니 넘어가고, HTRM, AMSD, TPKP (HTRM+AMSD)의 Ablation을 표에 한 번에 넣어두었습니다. MSDA와 Source Combined가 현재 동일한 방법론으로 비교될 수는 없으나 확실히 Source domain discrepancy로 인한 성능 저하가 존재함을 알 수 있습니다. 위 표에서 C+K는 Cityscapes, Kitti로 Multi-source를 가져가며, BDD100K는 Target 도메인입니다. 현재 보이는 Oracle (Source, Target 모두 BDD100K)가 Upper bound로 보고 있습니다.
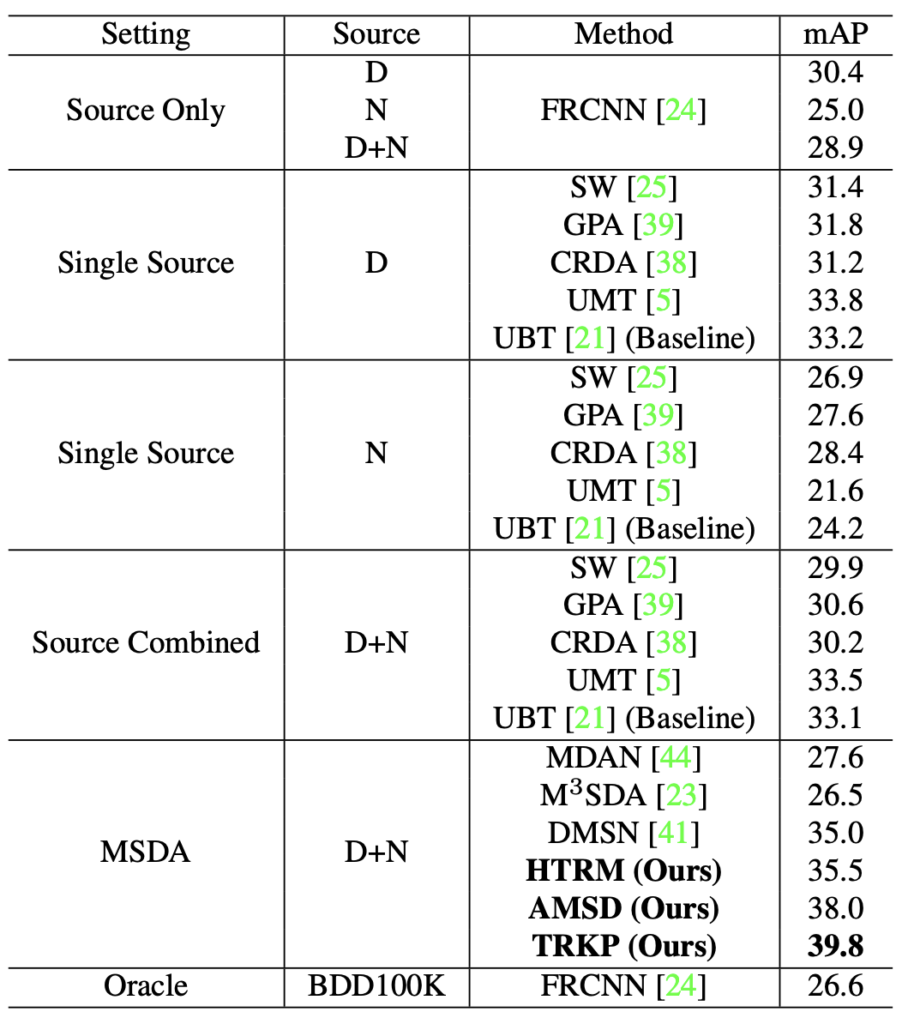
위의 Cross-Camera에 이어 이번에는 Cross-Time으로, BDD100K 데이터셋 즉 Camera는 동일한 환경에서 Daytime, Night을 Source 도메인, Dawn/Dusk를 Target 도메인으로 가져간 실험입니다. 실험 파트에선 주로 왜 이런 세팅을 적용하였는지에 대한 언급은 존재하나 특별한 인사이트는 보이지 않아 표만 살펴보고 넘어가겠습니다. 주목할 점은 Oracle로 보이는 BDD100K의 성능이 Upper bound가 아닌 오히려 26.6으로 더 낮은 모습을 보이는데, 이는 Dawn/Dusk의 Training 데이터가 굉장히 적기 때문입니다. (한 100-200장으로 알고 있습니다) 이것이 왜 DA가 필요한지에 대해 보여주고 있습니다.
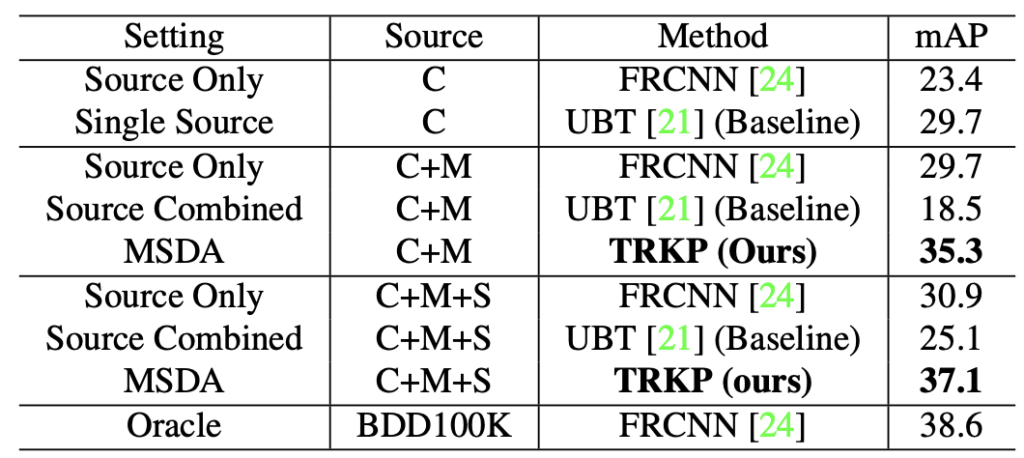
Mixed (Cityscapes + MS-COCO + Synscapes -> BDD100K)에서의 성능입니다. 확실히 더 많은 데이터를 섞으니, BDD100K에서도 성능이 괜찮게 보임을 알 수 있습니다. 35.3에서 37.1로 Synscapes (합성 데이터셋입니다)를 추가한 이후 더 좋은 성능을 보임을 알 수 있습니다.
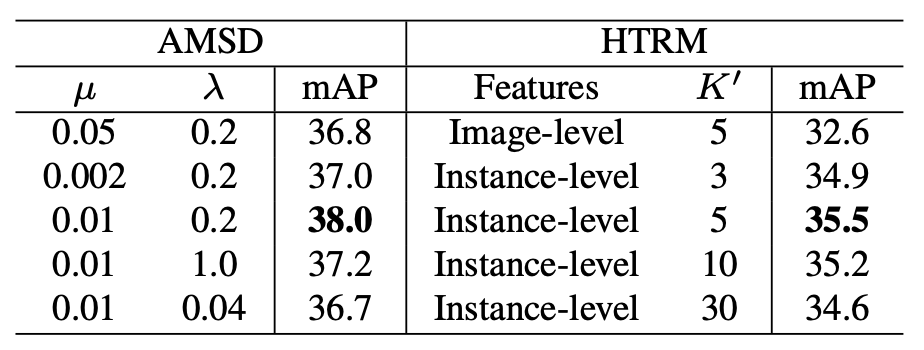
마지막은 Ablation study 하나를 들고 왔는데, 지켜볼 점은 HTRM의 Features에서 Image-level과 Instance-level, K’는 KNN의 K에서 왜 RoI로 진행하는 Instance-level이 더 좋은지를 알 수 있습니다. Image-level은 Classification 태스크에서는 몰라도 KNN에서 보면 Instance가 Background에 의해 영향을 받으면 좋지 않음을 알 수 있습니다. 그럼 이상으로 리뷰를 마치겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
실험 세팅 부분이 궁금한데,,,,, 해당 태스크에서는 왜 Cross-Camera와 Cross-Time이라는 주제로 실험 세팅을 진행하나요 ?!?? Domain Shift라는 현상이 Camera, TIme에 특히 취약한가요 ????
또, 왜 Target 도메인은 주로 BDD100K라는 데이터 셋을 활용하는지 궁금합니담.
감사합니다!
안녕하세요. 리뷰 읽어주셔서 감사합니다.
Cross-Camera와 Cross-Time이 현존하는 데이터셋의 세팅에서 일반적으로 활용할 수 있어 그렇게 설정하지 않았을까 (본 논문이 처음이 아니기에 첫 논문에서도 Domain Shift의 이미지 해상도 변경 등의 Camera, 또한 시간대에 따른 Time을 내세웁니다) 생각합니다.
더불어, Cross Time에서 Camera의 변경은 없어야하기 때문에 Day/Night/Others 의 환경이 있어야하는데, BDD100K가 여기에 알맞으며 (Target으로 설정), 그에 맞추어 다른 Crss-Camera에서도 BDD100K를 Target으로 선정하지 않았을까 생각합니다.