안녕하세요,
이번에는 instance-level에 속하는 6D pose estimation 관련 논문을 읽어보았습니다.
기존 리뷰 했던 내용들은 주로 RGB/RGB-D를 사용하는 방법론이었는데, PS6D 같은 경우는 포인트 클라우드만을 입력으로 사용하여 최종 pose를 추정하게 됩니다. 코드를 좀 살펴보고 싶은데, 없는 게 아쉽네요.
리뷰 시작하겠습니다.
Introduction
물체를 파지하는 산업용 로봇 팔의 사용은 다양한 제조 및 자동화 어플리케이션에서 중요한 역할을 하고 있습니다.
이러한 자동화 기술은 산업 공정에서 효율성, 속도, 정밀도를 달성하는 데에 필수적인 요소로 보이는데요. 6D pose를 추정하는 분야에서 기존의 방법론들은 occlusion이 되거나 쌓여있는 물체에 대한 pose를 추정하게 되면 성능이 저하가 되는 경우가 많았습니다. 최근 연구들은 딥러닝 기반의 6D pose estimation을 많이 제안하고 있는데요. 그러나 이러한 대부분의 방법론들은 RGB, RGB-D 정보에 주로 의존하고 있습니다. 이러한 방법들은 일상적인 물체 파지와 관련된 시나리오에서는 적합할 수 있지만 표면이 녹슬거나 다양한 배치마다 다른 색상 변화로 인해 풍부하다고 생각했던 RGB 정보가 오히려 방해 요소가 될 수 있다는 점, 반사율이 높은 표면이나 낮은 대비, 부족한 텍스처 정보로 인해 RGB 정보를 기반으로 하는 딥러닝 모델이 유용한 특징을 추출하기 어려울 수 있다는 점과 같은 이유로 산업용 물체 파지에 어려움을 겪을 수 있다고 합니다.
또한, 저자는 기존 공개 데이터셋에 있는 대부분의 물체들은 일상 생활에서 접근하기 쉽지, 산업 현장과 딱히 관련이 없어 실제 사용되는 물체를 기반으로 bin-picking 데이터셋을 구축을 강조하며 이러한 문제들을 다루기 위해 PS6D(symmetry-aware instance-level 6D pose estimation)을 제안합니다.
contribution은 다음과 같습니다.
- 포인트 클라우드 기반의 방법론인 PS6D라는 새로운 프레임워크 제안
- center distance-sensitive translation loss와 symmetry-aware rotation loss를 설계하여 특히 길쭉하거나 다중 대칭인 물체에 대해 강인한 pose estimation을 수행하도록 2-stage clustering 제안
- 실제 산업 어플리케이션에 부합한 PS6D 데이터셋을 구축 및 평가를 진행
Method
PS6D Network Architecture
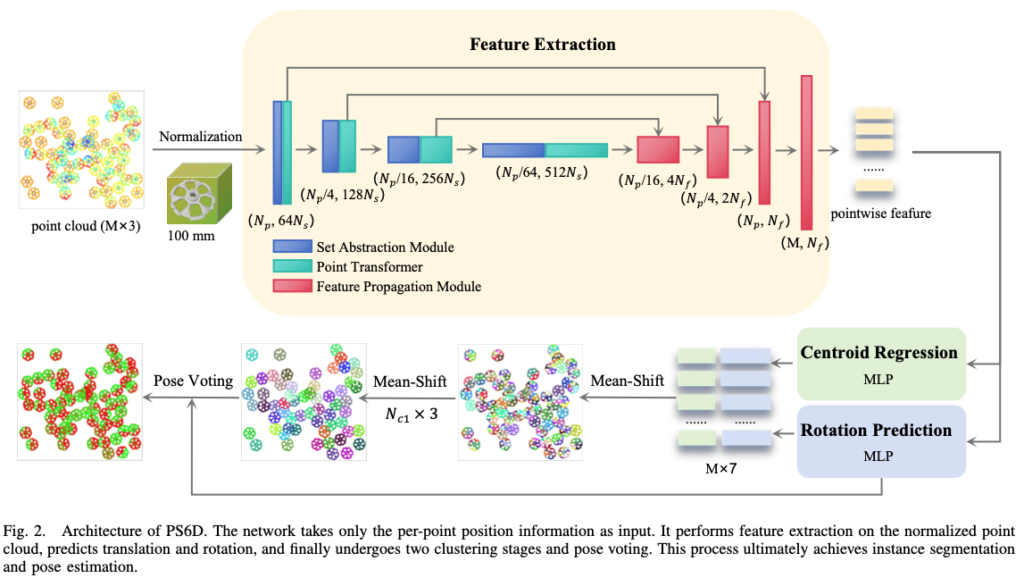
이번 PS6D의 전체적인 구조는 그림(2)와 같은데요.
포인트 클라우드가 입력으로 들어가게 되고, 해당 포인트 클라우드를 정규화를 거쳐 네트워크의 입력으로 들어가게 됩니다. 이후에는 Attention-guided 특징 추출기를 태우고 centroid(translation) regression과 rotation prediction 모듈을 통해 translation/rotation에 대한 예측 결과를 얻을 수 있겠네요.
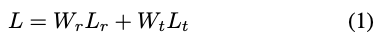
해당 과정에서 사용하는 loss function은 식(1)과 같이 간단하게 나타낼 수 있습니다. W는 weight를 나타내고, L_{r}, L_{t}는 rotation/translation에 대한 loss 값을 의미합니다.
Attention-Guided Feature Extraction Module
앞서 이번 섹션에서 사용하는 모듈을 태운다고 했는데, 이 모듈이 어떤 것인지 알아보겠습니다.
PointNet++은 포인트 클라우드의 입력을 받아 특징을 추출하는 유명한 backbone입니다. 이번 PS6D에서는 기존의 PointNet++를 기반으로 transformer를 적용한 Point Transformer라는 backbone을 통해 특징을 추출했다고 합니다. self-attention의 메커니즘은 inherent permutation invariance(순열 불변성)로 인해 정렬되지 않은 포인트 클라우드를 점의 순서에 영향을 받지 않고 처리할 수 있는 효과가 있다고 합니다. 이를 통해 포인트 클라우드 데이터를 다루는 것에는 transformer를 적용하는 것이 적절해 보이긴 하네요.
PS6D의 아키텍처를 보시면 파란색 모듈을 같이 사용하는 것을 확인할 수 있습니다. 해당 encoder는 SA(Set Abstraction) 모듈로, 포인트 클라우드를 down-sampling 하는 과정으로 보시면 되겠습니다. 초록색(?) 모듈인 point transformer 모듈을 통해 서로 다른 포인트 간의 관계에 대한 가중치를 학습하도록 설계하였다고 하네요. 저자는 이를 adaptability(적응력)이라고 표현을 쓰며 이러한 적응력을 통해 모델은 다양한 모양, 밀도, 분포를 가진 포인트 클라우드 데이터를 학습하면서 로컬/글로벌 한 특징들을 multi-scale로 추출할 수 있겠네요. 이후 decoder쪽은 up-sampling을 하고 최종적으로는 feature를 fusion 하여 MLP의 입력으로 넣어주게 됩니다.
Symmetry-Aware Rotation Prediction Module
이번 PS6D 논문에서 제목에서 다루는 Symmetry-Aware는 어떻게 설계하였는지 살펴보겠습니다.
물체에 대한 pose를 추정에서 대칭성은 물체가 다른 pose에서 유사한 projection을 생성하기 때문에 챌린지한 문제 중 하나인데요. 이러한 대칭성 문제는 카메라에서 보는 뷰포인트에 대해 물체의 여러 pose에 대응이 될 수 있어 학습 과정에 모호성을 유발하기 때문에 안 좋은 영향을 끼치기 마련입니다.
저자는 이러한 문제를 해결하기 위해 Symmetry-Aware rotation에 대한 loss function을 제안합니다.
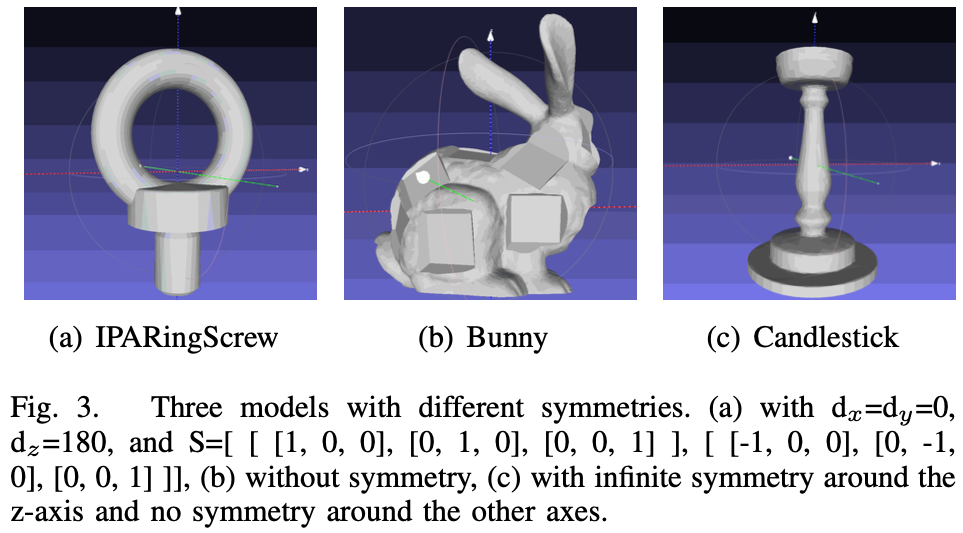
위 그림3(a)에 나타나있는 것처럼, 학습하기 전에 물체에 대한 대칭 정보를 d_{x}, d_{y}, d_{z}, T_{s}로 표현을 해야 합니다. 즉, 각축을 기준으로 하여 대칭 정도를 나타냅니다. T_{s} 같은 경우 무한 대칭(infinity symmetry)에 대한 threshold로, 대칭 정도가 해당 임계값을 초과하는 경우 해당 물체는 무한 대칭으로 취급합니다. 무한 대칭은 (c)와 같은 물체를 의미합니다. 대칭 회전 행렬인 \mathbf S 행렬 같은 경우, 단위 행렬(identity matrix)과 회전 행렬이 들어가 있는 것을 확인할 수 있는데 여기서 회전 행렬을 계산하는 파트는 (a)의 역할을 하겠네요.
(즉, z축 기준 회전 행렬에 \frac {\pi}{2}를 대입한 값입니다.)
(a)와 같은 유한 대칭(finite symmetry) 물체들은 \mathbf S행렬의 리스트 중 회전에 따르는 회전 행렬 결과를 계산하여 표현하게 되고, (b), (c)같이 대칭이 아니거나 무한 대칭인 경우엔 \mathbf S 행렬의 리스트에는 단위 행렬만 들어갑니다.
무한 대칭을 갖는 물체 같은 경우, 무한한 대칭을 갖도록 하는 특정 축이 있을텐데 그 축을 vector로 사용합니다. 원 같은 경우 무한한 vector가 생성되므로 구의 중심점 자체를 vector로 사용합니다. 이러한 중심점을 \overrightarrow 0(zero vector)로도 정의할 수 있습니다. 즉, 저희가 선형대수에서 다루었던 vector space를 정의할 때 zero vector가 포함(성립)되어야 하는 것을 고려한 것이라고 볼 수 있겠습니다.
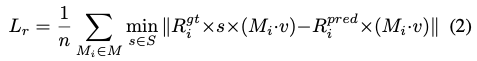
예측된 rotation이 적용된 포인트 클라우드와 GT rotation이 적용된 포인트 클라우드 간 거리를 최소화하는 회전 행렬 s를 \mathbf S에서 선택하고 식(2)와 같이 저자가 제안한 loss function을 통해 rotation에 대한 loss를 계산합니다. M은 포인트 클라우드 집합, n은 프레임 내에 존재하는 물체의 수를 의미합니다. v는 물체에 대한 무한 대칭성을 나타내는 vector로, 앞서 설명한 것처럼 무한 대칭 갖도록 하는 특정 축을 1로 설정하고 이외의 축은 모두 0으로 설정되고 예를 들면 [1, 0, 0] 이런식으로 나타낼 수 있겠고, 유한 대칭인 경우는 모두 1로 설정이 되므로 [1, 1, 1]으로 나타낼 수 있습니다.
Center Distance Sensitive Centroid Regression Module
rotation을 구하는 모듈을 다루었으니 이제 translation은 어떻게 regression을 하였는지 살펴보겠습니다.
해당 모듈에서는 특정 프레임에 내에 존재하는 물체에 대한 포인트 클라우드를 각각 물체의 중심으로 regression시키는 것을 목표로 하게 됩니다. 저자는 길쭉한 물체의 경우 중심점에서 끝점까지 거리가 멀어 regression 시키는 것은 어려울 것이라고 판단하여 해당 모듈을 설계합니다.
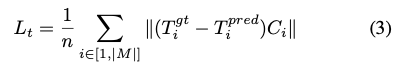
식(3)은 프레임에 존재하는 각 물체에 대한 GT translation과 예측 translation에 대한 차이에 포인트 클라우드의 중심점을 정규화한 C_{i}에 대한 값을 모든 물체에 대한 대한 평균을 취하여 사용합니다.
Two-Stage Clustering
저자는 얇거나, 다중 대칭인 물체에 대한 부정확한 pose를 추정하는 문제를 해결하기 위해 Two-Stage Clustering 과정을 도입하게 됩니다. 그림(2)에서 mean-shift 과정을 의미합니다. 첫 번째 clustering에 대한 입력은 MLP로부터 예측된 translation/rotation 정보가 들어가게되어 겹쳐져 있는 물체를 효과적으로 구분할 수 있게 됩니다. 두 번째 단계에서는 위치 정보만 고려하기 때문에 이전 단계에서 생성된 동일한 인스턴스에 속하는 pose를 하나의 카테고리로 합칠 수 있고, 해당 카테고리 내에서 오차가 가장 작은 pose voting 과정을 통해 최종 예측 pose를 얻을 수 있습니다.
Experiment
Dataset Selection and Generation
저자는 LM, YCB-V 데이터셋의 물체들은 일상 생활에서 흔히 다룰 수 있으며, 풍부한 텍스처 정보를 가지고 있는 경우가 많지만 실제 산업 현장에서 사용되는 파지를 위한 물체들은 일반적으로 반사율이 높고 텍스처 정보가 부족한 경우가 많아 평가 요소로 적합하지 않다고 하네요. 그러면 T-LESS는 적절하지 않나? 라는 생각을 하였지만, 물체와 상관관계를 잘 고려해야 하는데 데이터셋의 양이 적어 파지를 위해 흩어져 있거나 쌓여 있는 물체의 시나리오를 고려하기 어렵다고 하네요.
어떤 데이터셋을 사용했는지 보니 공개 데이터셋으로는 Sile ́ane[1] 데이터셋과 IPA[2] 데이터셋에서 사용되는 일부 물체들을 가지고 저자가 제안한 방법론을 평가하였다고 합니다. 산업 시나리오를 최대한 고려하기 위해 산업 환경에서 널리 사용되는 물체들로 5개를 선정하여 PS6D 데이터셋을 구성하였다고 합니다.
데이터를 생성하는 방법은 Blender를 사용하였다고 하는데요. 물체에 대한 CAD 모델이 있으면 해당 툴을 사용하여 물체가 특정 높이에서 무작위로 bin 안에 흩어지거나 쌓이는 효과를 쉽게 구현할 수 있다고 합니다.

저자는 물체에 대한 선정을 Sile ́ane에 있는 bunny, Tless 20, Candlestick과 IPA 데이터셋에서는 gearshaft, ringscrew를 추가하여 구성하였고 산업 현장이라는 실용적인 고려 사항을 결합하여 데이터를 생성하여 그림(4)와 같은 5개의 물체를 다루는 데이터셋을 만들었다고 합니다.
(해당 데이터셋에 대한 깃허브가 있어 들어가봤는데 아직 accept이 되지 않아서 비공개로 해둔 건지 레포지토리가 뜨지가 않네요)
[1] D.Cai,J.Heikkia ̈andE.Rahtu,”OVE6D:ObjectViewpointEncoding for Depth-based 6D Object Pose Estimation,” 2022 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 2022, pp. 6793-6803.
[2] K. Kleeberger, C. Landgraf and M. F. Huber, ”Large-scale 6D object pose estimation dataset for industrial bin-picking”, Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), pp. 2573-2578, Nov. 2019.
Evaluation Metrics
저자는 평가지표를 다음과 같이 설계 합니다.
- 놓친 검출과 잘못 검출한 것을 모두 반영하여 검출된 물체 수가 실제 물체 수와 일치해야 함
- 포인트별 매칭 정확도를 반영하여 예측된 pose가 GT pose와 거의 일치해야 함
이렇게 디자인된 평가지표는 두 개의 파트로 구성되게 되는데요.
Instance-level F1 score
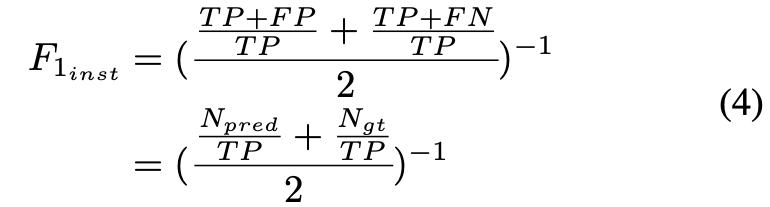
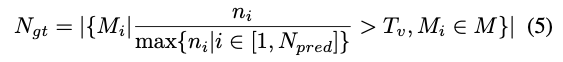
F_{1_{\text inst}}로 표기하며 식(4)와 같이 instance-level에 대한 F1 score를 계산하기 위해 사용되는 N_{\text {gt}}는 프레임 내에 존재하는 물체의 수를 나타내므로 N_{\text {pred}}는 그럼 예측된 물체 수를 의미하겠네요. 즉, 예측된 pose를 가장 가까운 GT pose와 pair를 이뤄야 옳은 pose로 간주하게 됩니다. 심하게 occlusion이 된 케이스에 속하는 물체는 파악할 수 없으므로, 평가 지표에 영향이 갈 수 있으므로 visibility가 0.4보다 큰 물체만을 고려한다고 합니다. 따라서 N_{\text {gt}}는 식(5)와 같이 계산되며 n_{i}는 i 번째 물체에 대한 샘플링된 포인트 클라우드의 수를 나타내고, T_{v}는 visibility에 대한 threshold 입니다.
Point-wise Recall
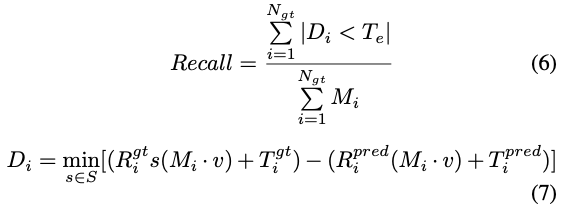
해당 평가 지표는 각 개별적인 포인트의 매칭 상태를 반영하게 됩니다. 식(6)과 같이 계산되며 특정 threshold 값보다 거리가 작은 유효한 총 포인트의 수와 원래 포인트 클라우드의 총 포인트 수의 차이를 계산합니다. 식(7)을 통해 D_{i}는 대칭 요소를 고려한 거리 지표로 사용됩니다. 또한, 거리가 T_{e}보다 작으면 물체는 true positive로 간주되며, 여기서 T_{e}는 허용 오차 임계값입니다.
Results
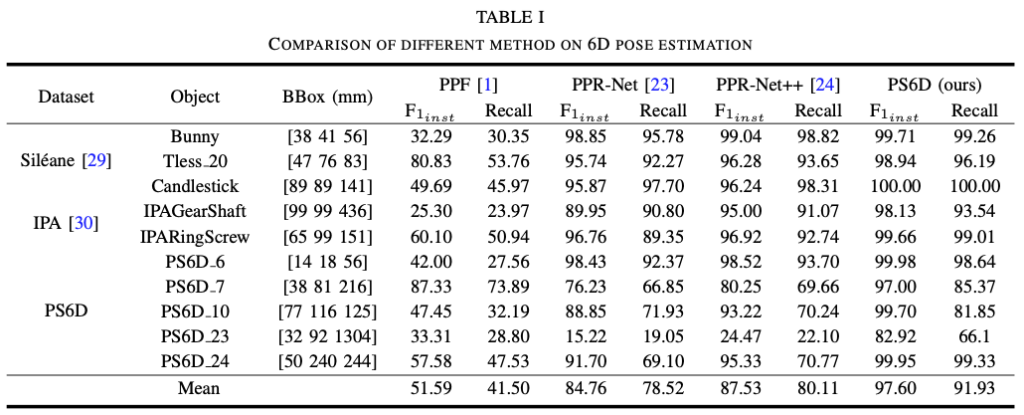
표(1)은 PS6D와 기존의 다른 방법론들과의 성능을 비교한 표입니다. PS6D는 pose를 추정할 때 포인트 클라우드에만 의존하기 때문에 특정 포인트 기반의 방법론을 선택해야 하는데요.
PPF는 포인트 매칭 기반의 전통적인 알고리즘이고, PPR-Net은 instance segmentation과 pose 추정을 동시에 수행하는 딥러닝 방법론입니다. 해당 방법론을 통해 Sile ́ane 데이터셋에서 좋은 결과를 얻었다고 하네요. PPR-Net++은 언급한 이름에서 알 수 있듯이, PPR-Net을 기반으로 하여 좀 더 개선된 모델입니다. 설명한 모델에 비해 많이 우세한 결과를 보여주고 있습니다. PPF의 경우 해당 데이터셋은 가려져 있거나 쌓여있는 데이터셋이므로 여기에 되게 어려움을 느끼는 것으로 보이며, PPR-Net, PPR-Net++은 PPF 보다는 우세하지만 PS6D 보다 성능 차이가 많이 나네요. 이번 논문에서 만든 PS6D 데이터셋의 경우, 다중 대칭(PS6D_24)과 얇고 길쭉한 모양(PS6D_23)을 가진 물체에서도 성능이 훨씬 개선된 모습을 보여주고 있네요.

그림(5)는 다양한 물체에 대한 PS6D의 instance segmentation과 pose estimation 성능을 보여주고 있습니다.
Ablation Study
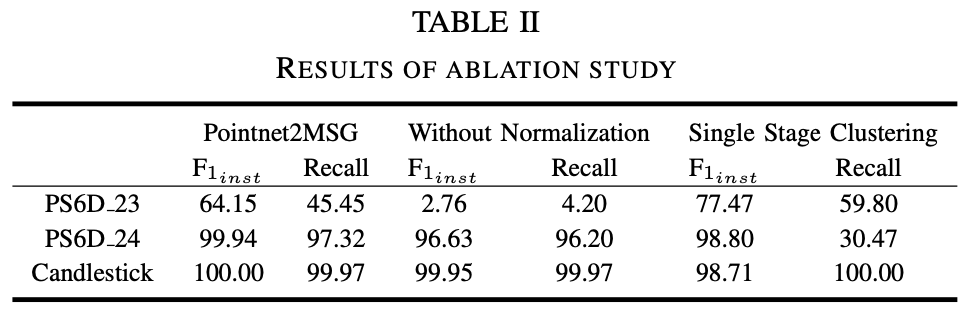
backbone으로 사용되는 transformer 구조는 매칭 성능을 어느 정도 향상시킬 수 있었고, 정규화 과정을 통해 네트워크가 다양한 크기의 물체에 동시에 adaptability을 학습하여 성능이 좋은 반면에, 정규화가 없는 네트워크는 작은 크기의 물체에서만 성능이 좋았다고 합니다. 2-stage 클러스터링은 다중 대칭과 길쭉한 모양의 물체에 대한 성능을 크게 향상시키는 반면에 무한 대칭의 물체에 미치는 영향도 크지 않아 적절하다는 것을 알 수 있었다고 합니다.
Conclusion
이번에는 포인트 클라우드를 기반으로 하는 pose estimation 방법론인 PS6D를 살펴보았습니다.
저자는 정규화된 포인트 클라우드를 입력으로 받아 특징을 추출하고 rotation과 translation을 예측하는 아키텍처를 제안하였습니다. instance segmentation과 pose voting를 수행하기 위해 2-stage clustering 이라는 방법론을 적용하여 정확한 pose estimation을 수행할 수 있었습니다.
이상으로 논문 리뷰 마치겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
해당 방법론은 point cloud를 입력으로 하는 Direct Method로 보입니다.
해당 논문은 최초로 point cloud만을 이용하는 방법론인건가요??
컨트리뷰션 1번이 단순히 ‘포인트 클라우드 기반의 방법론인 PS6D 프레임워크 제안’이라고 하셔서 궁금합니다.
Fig. 3-(a)에서 T_s를 확인하기 어렵습니다. T_s와 비교하는 대칭 정도는 어떻게 구해지나요??
또한 저자들이 introduction에서 언급했던 상황인, 금속 객체에 녹이 슨 경우가 포함되는 지도 궁금한데 혹시 이러한 케이스에 대한 언급은 없었나요??
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 실험 섹션에서 간단하게 설명을 해두었는데 PPR-Net과 같은 방법론이 이전에 제안되어서 최초의 방법론은 아닙니다. contribution에 제가 말을 애매하게 작성하긴 했네요. “포인트 클라우드 기반의 방법론인 PS6D라는 새로운 프레임워크 제안”으로 수정해두었습니다.
2. T_{s}는 무한대칭을 판별하기 위한 임계값을 의미하는데요. 물체에 대해 15도 보다 작은 각도만큼 회전을 했을 때 동일한 모습을 보이는 경우 무한 대칭성을 가진다고 판단하게 됩니다.
3. 녹이 슨 경우에 대해서는 introduction 이후 언급은 없었으며, 길쭉하거나 다중 대칭인 경우에 대한 물체만 언급을 합니다. 녹이 슨 경우는 RGB에 대한 특정 한 가지 물체에 대한 다양한 컬러 정보가 오히려 학습에 방해요소가 될 수 있다는 극단적인 예시로 들지 않았을까 합니다.
감사합니다.