안녕하세요. 오늘의 X-Review는 24년도 AAAI에 게재된 <TR-DETR: Task-Reciprocal Transformer for Joint Moment Retrieval and Highlight Detection> 논문입니다. 비디오 도메인에서 Moment Retrieval과 Highlight Detection task를 동시에 수행하는 DETR 기반의 방법론이며, Moment Retrieval (MR)과 Highlight Detection (HD)라는 두 task가 굉장히 유사한 점이 많음에도 기존 DETR 기반 방법론들은 이 포인트를 제대로 살리지 못했다는 문제점을 지적하는 논문입니다.

1. Introduction
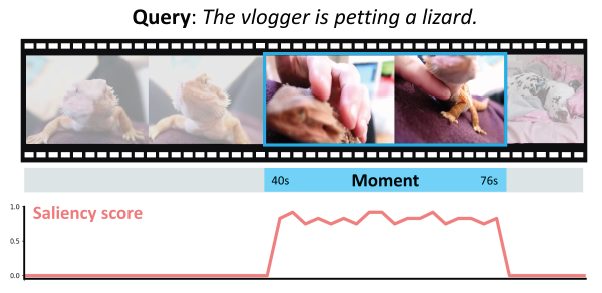
먼저 본 방법론이 수행하는 task에 대해 간단히 설명드리겠습니다. Moment Retrieval (MR)은 사용자로부터 입력받는 텍스트 쿼리를 기준으로 텍스트 쿼리가 설명하고 있는 구간을 비디오 내에서 특정하는 task입니다. 위 그림에서 모델이 찾아낸 구간이 하늘색으로 표시되어있습니다. Highlight Detection (HD)은 마찬가지로 사용자로부터 입력받는 텍스트 쿼리의 의미론적 상황을 가장 잘 설명하는 하이라이트 클립을 찾는 것이 목적이며, 클립 별로 텍스트 쿼리와 상응하는 정도의 score를 그림의 분홍색 선과 같이 뽑아내는 task입니다. Score가 가장 높은 지점이 모델이 예측한 하이라이트 클립이라고 볼 수 있겠죠.
MR과 HD 두 task 모두 입력받은 텍스트 쿼리를 기준으로 비디오를 모델링한다는 공통점이 있습니다. 이렇게 두 가지 task를 동시에 수행하는 기존의 DETR 기반 multi-task 방법론들을 살펴보겠습니다. 지금이야 여러 DETR 기반 방법론들이 등장했지만, 해당 논문이 작성된 시점에는 베이스라인 방법론인 Moment-DETR과 QD-DETR, MH-DETR 방법론이 존재했었습니다.
Moment-DETR은 MR&HD task를 수행하는 DETR 기반 방법론들의 베이스라인입니다. 최초로 MR&HD를 동시에 수행하는 초석을 다졌으며 이후의 모든 방법론들이 Moment-DETR의 코드 베이스를 따르고 있는 상황입니다. 방법론 측면에서 살펴보면, 우선 비디오 토큰과 텍스트 쿼리 토큰을 concat한 후 Transformer Encoder에 입력해줍니다. 이후 Encoder의 출력을 FFN에 태워 HD를 수행하고, 동시에 Moment Query와 Encoder의 출력을 Decoder에 입력해 얻은 출력값을 FFN에 태워 MR을 수행합니다. 어떠한 추가 모델링도 없이 단순 concat 후 Object Detection의 DETR 파이프라인을 그대로 따랐다고 보시면 됩니다. 이렇게 간단했음에도 불구하고 MR&HD에서 기존 방법론들보다 높은 성능을 보여주었습니다.
이렇게 굉장히 naive한 Moment-DETR을 기반으로 등장한 후속 연구들은 각자 Moment-DETR의 여러 문제점을 지적하며 성능을 크게 올립니다. QD-DETR은 Query-Dependent DETR의 약자로, MR&HD task는 텍스트 쿼리를 기반으로 수행됨에도 불구하고 Moment-DETR이 텍스트 쿼리에 대한 모델링을 간과했다고 이야기합니다. 이를 지적하며 텍스트 쿼리에 대한 모델링을 개선하기 위해 여러 모듈과 loss를 제안한 방법론입니다.
이후 MH-DETR이라는 방법론도 등장했지만 마찬가지로 비디오와 텍스트 쿼리 간 상호작용 모델링에 집중한 방법론으로, 본 방법론인 TR-DETR과 같이 두 task 간 상호 관계를 파악하고 이를 활용한 방법론은 없었습니다. HD을 위해 텍스트 쿼리와 관계없는 클립의 score는 낮추고 관계있는 클립의 score는 높이게 되는데, 이는 MR 수행에 도움을 줄 수 있습니다. 마찬가지로 MR을 수행하여 얻은 상응 구간을 활용해 각 클립의 saliency 정도를 판단할 수 있고, 이를 활용하면 HD 성능을 향상시킬 수 있게 됩니다.
두 task 간 상호보완을 주 컨셉으로 하는 TR-DETR의 파이프라인을 조금 더 자세히 알아보겠습니다. 우선 사전학습 모델로부터 visual feature와 textual feature를 추출합니다. 이 feature를 바탕으로 TR-DETR을 구성하는 첫 번째 모듈은 local-global multi-modal alignment입니다. 두 모달리티의 interaction을 수행하기 전 각 모달리티에 내부적으로 local-global alignment를 한 번 수행해주는 것입니다.
두 번째는 visual feature refinement 모듈입니다. 여기서는 text feature를 활용해 visual feature 중 텍스트 쿼리와 관계 없는 클립들을 최대한 배제하는 것이 목적입니다. TR-DETR을 구성하는 마지막 모듈은 task cooperation 모듈입니다. 두 task간 상호 관계를 모델링할 수 있는 MR2HD과 HD2MR이 포함되어있습니다. HD2MR은 highlight score를 feature로부터 추출하여 MR을 위해 활용하고, MR2HD은 추출한 구간 정보를 클립 단위의 highlight score 추출에 사용합니다. 각 모듈이 어떻게 목적을 달성하는지에 대한 세부 사항은 방법론 부분에서 알아보겠습니다.
2. Method
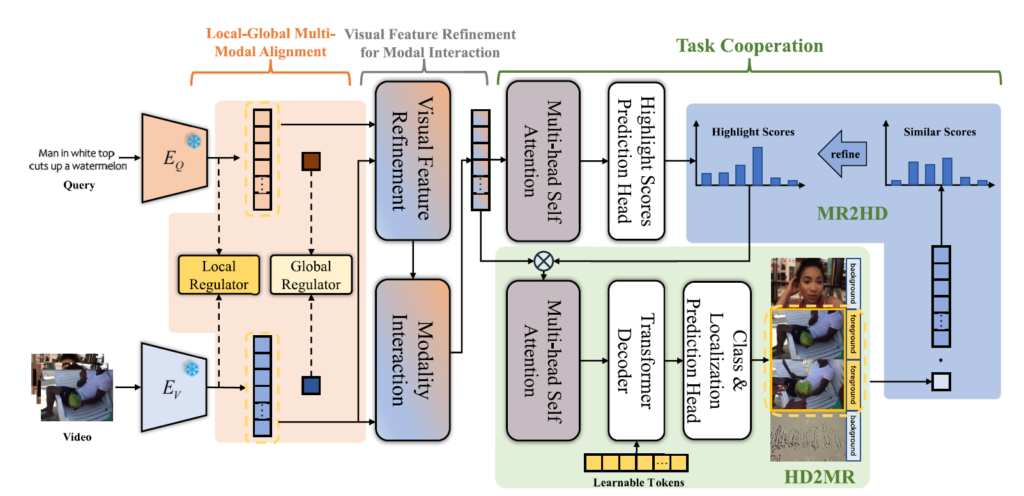
TR-DETR 방법론 전체 구조도는 위 그림 1과 같습니다. 각 모달리티에 대한 feature 추출 후 앞서 설명드렸던 Local-Global Multi-Modal Alignment, Visual Feature Refinement for Modal Interaction, Task Cooperation 순서대로 진행됩니다. 기본적으로 Moment-DETR 방법론의 구조를 따라 Transformer의 Encoder 출력으로부터 HD을 수행하고, Decoder에는 Encoder의 출력과 Moment query (Learnable Token)을 주어 MR을 수행하고 있는 모습입니다. 각 단계에 대해 천천히 알아보겠습니다.
2.1 Feature Extraction
Visual Features.
Visual feature와 Text feature의 추출은 기존 연구와 동일합니다. 이에 대해 설명드리자면, 우선 비디오를 겹치지 않는 2초 단위의 클립으로 잘라줍니다. 각 클립을 CLIP image encoder와 SlowFast 백본에 입력하여 clip-level visual feature F_{v} = [f_{v}^{1}, \cdots{}, f_{v}^{L}] \in{} \mathbb{R}^{L \times{} d_{v}}를 얻어주게 됩니다. 실제로 SlowFast feature는 2304차원, CLIP feature는 512차원인데 이를 concat하여 클립 별 2816차원의 feature를 사용합니다.
Textual Features.
텍스트 쿼리에 대한 feature는 CLIP text encoder를 활용합니다. N개의 토큰을 갖는 텍스트 쿼리에 대한 feature F_{t} = [f_{t}^{1}, \cdots{}, f_{t}^{L}] \in{} \mathbb{R}^{N \times{} d_{t}}를 추출해줍니다. 실제로는 CLIP image feature와 동일하게 512차원이겠죠.
2.2 Local-Global Multi-Modal Alignment
Moment-DETR과 EaTR과 같은 기존 방법론들은 비디오 토큰과 텍스트 토큰을 단순하게 concat하여 Transformer Encoder에 입력해줍니다. 이는 멀티모달 입력을 다루는 가장 간단하고 쉬운 방식이겠지만, 두 모달리티의 alignment가 중요한 MR&HD task 특성 상 최적이라고 보기엔 어려울 것입니다. QD-DETR이라는 방법론에서도 이를 지적하며 시작하자마자 두 feature에 대한 cross-attention을 수행하고 그 출력을 DETR에 입력해 task를 수행합니다.
본 모듈도 이와 비슷하게 두 모달리티의 interaction을 수행하기 전 모달 간 gap을 줄이고자 설계되었습니다. 그림 1에서도 본격적으로 Transformer Encoder에 들어가기 전 위치에 해당 모듈이 존재하는 것을 볼 수 있습니다. 내부적으로는 local에 대한 regularization component와 global에 대한 regularization component가 설계되어 있는데요, 이 중 local regulator는 의미론적으로는 유사하지만 실제 GT 구간에 상응하지 않는 클립들을 걸러내는 역할을 해줍니다. 또한 global regulator는 두 모달리티의 공동 embedding space가 좀 더 단단하게 구성되어 이후 더 align된 feature로 두 task를 수행할 수 있도록하는 역할을 수행합니다. 사실 여기까지만 설명드리면 너무 막연하여 아직 감이 잘 오지 않는데, 실제 어떤 연산들이 수행되는지 알아보겠습니다.
현재 F_{v}와 F_{t}의 feature 차원이 맞지 않기 때문에 MLP에 태워 동일 차원으로 임베딩해줍니다. 이는 아래 수식 (1), (2)와 같습니다. 두 모달의 feature 모두 d차원으로 통일시켜주는 것입니다.
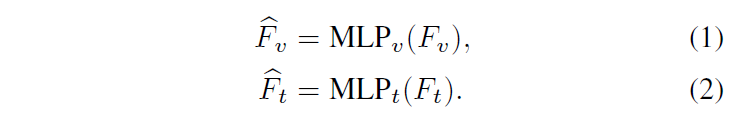
우선 local regulator는 말 그대로 local한, 즉 비디오의 L개 클립, 텍스트의 N개 단어 간 유사도를 계산해줍니다. 아래 수식 (3)과 같이 cosine 유사도를 계산하고 sigmoid 함수에 태워줍니다.
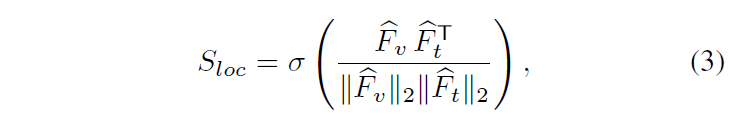
이렇게 얻은 S_{loc} \in{} \mathbb{R}^{L \times{} N}에 대해 단어 축으로 평균 풀링을 해 아래 수식과 같이 \hat{S}_{loc}을 얻을 수 있습니다.
\hat{S}_{loc} = \text{MeanPooling}(S_{loc}) \in{} \mathbb{R}^{L}
\hat{S}_{loc}은 각 클립이 텍스트 쿼리와 유사한 정도를 나타내는 벡터라고 볼 수 있습니다. 이후 아래 수식 (4)와 같은 loss \mathcal{L}_{loc}을 학습합니다.
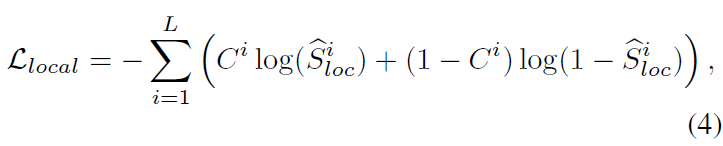
위 수식 (4)에서 \hat{S}_{local}^{i}는 비디오의 i번째 클립이 텍스트 쿼리와 유사한 정도를 나타내는 [0, 1] 사이의 값입니다. 라벨로 주어진 C^{i}는 MR 라벨로, 실제 텍스트 쿼리에 상응하는 구간이라면 1, 아니면 0으로 설정됩니다. 정리하자면 코사인 유사도를 활용해, 실제 텍스트 쿼리에 상응하는 구간일수록 비디오 feature가 구별력 있게 생성되도록 만들어주는 loss가 설계되어 있는 것입니다.
이렇게 하나의 비디오와 텍스트 쿼리 쌍 내부적으로 구별력을 갖도록 동작하는 local regulator에 대해 알아보았습니다. 다음으로 소개해드릴 global regulator는 배치 단위의 multi-modal contrastive loss에 해당합니다.
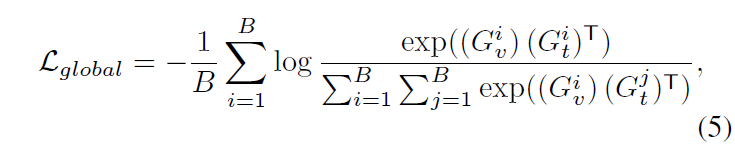
B는 미니 배치를 의미하며 G_{v}^{i} \in{} \mathbb{R}^{d}, G_{t}^{i} \in{} \mathbb{R}^{d}는 각각 비디오와 텍스트의 global feature를 의미합니다. B=16이라면 각각 16개씩 존재하겠죠. 한 비디오에 대한 global feature G_{v}^{i}는 수식 (1)의 비디오 feature를 temporal 축으로 average pooling, 한 텍스트 쿼리에 대한 global feature G_{t}^{i}는 수식 (2)의 텍스트 feature를 단어 축으로 average pooling하여 얻게 됩니다. 대각선 원소만 내적값이 커지도록 만들어준다고 수식 (5)를 해석할 수 있겠죠.
두 개의 loss \hat{S}_{local}^{i}, \hat{S}_{global}^{i}을 통해 추후 interaction 할 두 모달의 feature가 조금 더 joint하고 align 된 embedding space를 구축할 것으로 기대해볼 수 있습니다
2.3 Visual Feature Refinement for Modal Interaction
두 번째 모듈도 마찬가지로 기존 방법론들이 두 모달리티의 feature를 단순 concat하여 Encoder의 입력으로 넣어준다는 점을 개선하기 위해 고안되었습니다. 비디오를 구성하는 클립 중 실제 텍스트 쿼리에 상응하지 않는 구간이 훨씬 더 많은데, 원본 비디오 feature를 그대로 활용하면 말 그대로 중요한 클립에 집중할 cost를 관계 없는 클립에 집중하는 데에도 사용하겠죠. 이러한 상황을 방지하고자, 텍스트 쿼리 기준으로 조금이라도 더 중요한 클립을 선별하여 이에 집중할 수 있도록 만들어주는 모듈을 제안합니다.
본 모듈의 역할은 텍스트 쿼리로부터 가이드를 받아 연관이 적은 비디오 내 클립의 feature 중요도를 낮추면서 기존의 temporal cue는 유지하는 것입니다. 이를 위해 기존 연구를 조금 변형해서 사용했다고 합니다. 우선 클립들과 텍스트 feature의 유사도 맵 A \in{} \mathbb{R}^{L \times{} N}는 아래와 같이 계산됩니다.
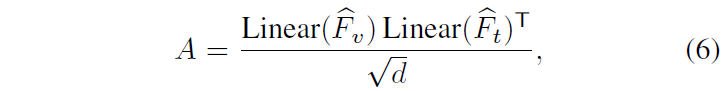
이후 A를 활용해 각 모달에 대한 상대 모달의 weight score를 아래 수식 (7), (8)과 같이 만들어줍니다.
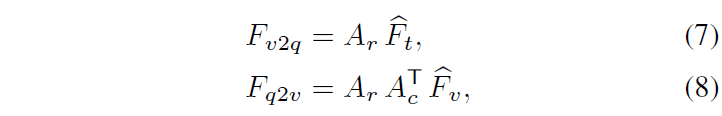
A_{r}과 A_{c}는 각각 row 방향, column 방향으로의 softmax를 적용한 attention map을 의미합니다. 이에 따라 F_{v2q}, F_{q2v}는 각각 clip-level textual feature와 word-level visual feature를 의미하게 됩니다.
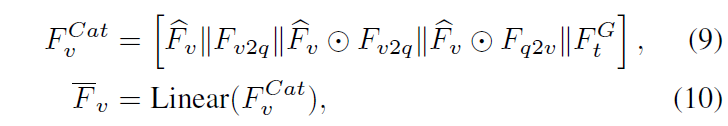
수식 (9)에서 ||는 concat, \odot{}은 아다마르 곱을 의미합니다. 총 5개의 video feature들이 concat 되어있는 모습을 볼 수 있는데, 마지막에 있는 F_{t}^{G} \in{} \mathbb{R}^{L \times{} d}는 text feature를 copy하고 slice하여 만들어낸 feature인데, N차원의 text feature를 어떻게 copy하고 slice하여 L차원으로 만들었는지에 대해서는 정확히 나와있지 않습니다. 아무튼 이렇게 concat한 feature F_{v}^{Cat}을 FC layer에 태워 다시 d차원으로 맞춰줍니다.
이 과정은 visual feature refinement에 해당하고, 마지막으로 refine된 visual feature \bar{F}_{v}와 text feature 간 cross-attention을 수행해 이후 interaction에 사용할 feature Z \in{} \mathbb{R}^{L \times{} d}를 만들어줍니다.
Q_{v} = \text{Linear}_{q}(\bar{F}_{v})
K_{t} = \text{Linear}_{k}(\hat{F}_{t})
V_{t} = \text{Linear}_{v}(\hat{F}_{t})
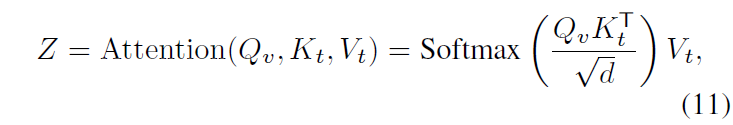
Z는 cross-attention을 통해 modal interaction이 수행된 feature로, 이후 Task Cooperation에 사용되게 됩니다.
2.4 Task Cooperation
TR-DETR의 마지막 모듈이자 가장 핵심적인 contribution입니다. MR과 HD 두 task가 서로의 도움을 받을 수 있도록 설계한 모듈입니다. 앞서 말씀드린대로 본 모듈은 MR2HD, HD2MR 두 갈래로 구성됩니다.
HD2MR
HD2MR에서는 MR 수행 시 관계 없는 비디오 클립을 배제하기 위해 HD의 highlight score를 빌려옵니다. 우선 앞서 뽑은 joint feature Z를 self-attention, FC layer에 태워 클립 단위의 highlight score H \in{} \mathbb{R}^{L}를 추출합니다. 이는 아래 수식 (12)와 같습니다.
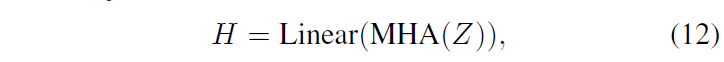
그리고 Z에 highlight score H/latex]를 고려해주기 위해 아다마르 곱을 수행해 [latex]\bar{Z}를 얻어주고, 이를 Z와 더해 다시 self-attention을 수행합니다. 이는 아래 수식 (13)과 같습니다.
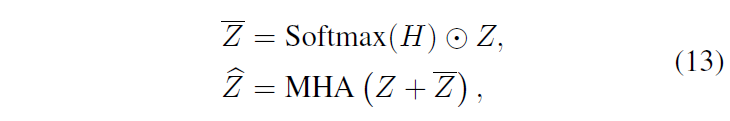
최종적으로 얻은 \hat{Z}은 Transformer Decoder에 들어가 Moment query와 연산되어 상응 구간을 내뱉는 데에 사용됩니다. 사실 Introduction에서 이야기한 바에 따르면 HD2MR을 위해 GT highlight score라도 활용하는 줄 알았는데 실제로는 그렇지 않은 모습입니다.
MR2HD
MR2HD에서는 HD2MR 과정을 통해 얻은 구간의 feature m을 활용합니다. m은 \hat{F}_{v} 중 구간만을 떼어낸 feature를 의미하며, 이에 대한 global한 정보를 추출하기 위해 GRU에 태워줍니다.
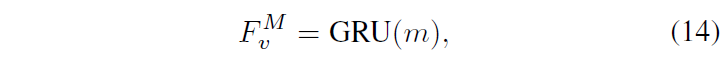
F_{v}^{m} \in{} \mathbb{R}^{d}는 찾아낸 구간의 global feature라고 볼 수 있습니다. 이를 HD에 잘 녹여내기 위해 F_{v}와 visual feature \hat{F}_{v} 간 유사도를 아래 수식 (15)와 같이 계산합니다.
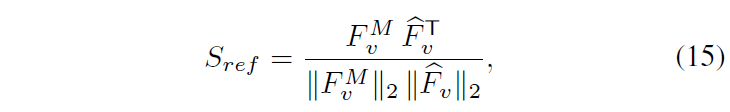
S_{ref} \in{} \mathbb{R}^{L}는 각 클립이 상응 구간의 global feature와 얼마나 유사한지에 대한 값을 담고 있습니다. 이후에는 아래 수식 (16)과 같이 joint feature를 활용해 refined highlight score \bar{H} \in{} \mathbb{R}^{L}를 만들어줍니다.
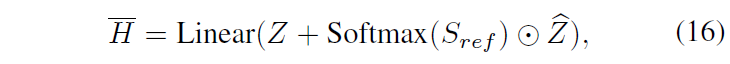
기본적으로 interaction을 위한 연산들이 간단하긴 해도 어떤 이유로 위와 같이 설계되었는지에 대한 설명이 포함되어있었다면 더욱 좋았을 것 같은데, 최대한 여러 각도에서 각 모달의 feature를 바라보고 웬만하면 모든 feature를 잘 활용해보자는 느낌이 강한 것 같습니다.
2.5 Objective Losses
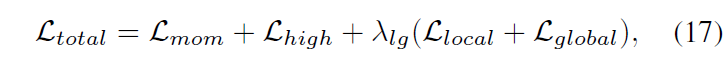
학습에 사용되는 loss \mathcal{L}_{total}은 위 수식 (17)과 같습니다.
- \mathcal{L}_{mom}: MR 학습 loss로, DETR과 동일하게 L1 loss 및 GIoU loss를 의미합니다.
- \mathcal{L}_{high}: HD 학습 loss로, highlight 구간 score를 조절하는 hinge loss를 의미합니다.
- \mathcal{L}_{local}: local regulator loss (CE loss)
- \mathcal{L}_{global}: global regulator loss (Contrastive loss)
\mathcal{L}_{mom}, \mathcal{L}_{high}에 대한 자세한 설명은 아래의 이전 리뷰를 참고해주시기 바랍니다.
3. Experiment
3.1 Datasets
MR&HD 메인 벤치마크는 QVHighlights 데이터셋으로 수행하였습니다. 총 10,148개의 비디오로 구성되어 있으며 test split에 대한 annotation은 공개되어있지 않아 데이터셋을 관리하고 있는 CodaLab competition platform에 예측 파일을 제출하는 방식으로 평가를 진행합니다.
MR 벤치마크는 Charades-STA 데이터셋으로, HD 벤치마크는 TVSum 데이터셋으로 각각 수행해줍니다.
3.2 Comparison with Other Methods
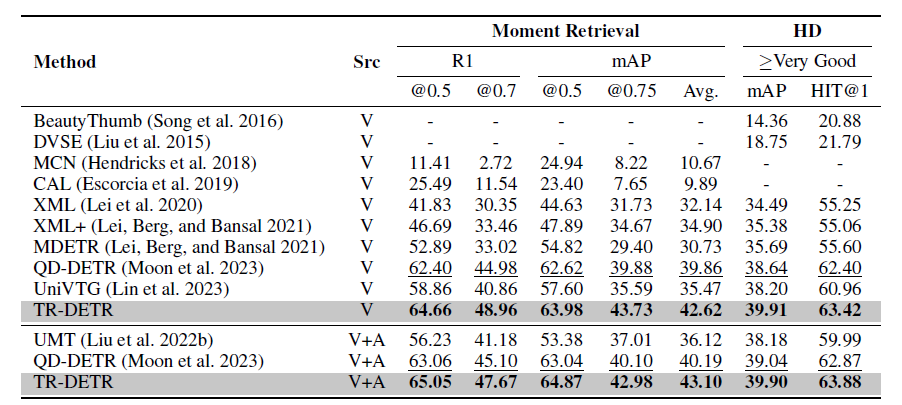
표 1은 QVHighlights 데이터셋에서의 MR&HD 벤치마크 성능입니다. Source는 비디오 feature만 사용하는 경우 'V', 오디오 모달리티를 함께 사용하는 경우 'V+A'로 표시되어있지만 기본적으로 오디오 모달리티에 대한 추가 모델링을 제안한 것은 아니므로 'V'만 살펴보겠습니다.
직접 비교할만한 최근 방법론은 MDETR, QD-DETR, UniVTG입니다. UniVTG는 MR, HD, T2V Retrieval 3가지 task를 동시에 수행하는 unified model입니다. 우선 베이스라인인 Moment-DETR의 후속연구인 QD-DETR보다도 더욱 높은 성능을 보여주는 것이 인상깊지만 TR-DETR의 두 가지 모듈은 multi-modal 모델링이고 나머지 하나가 본 방법론의 컨셉이자 메인 contribution인데, 각 module 별로 얼마나 성능을 일으켰는지 뒤에서 알아보겠습니다.
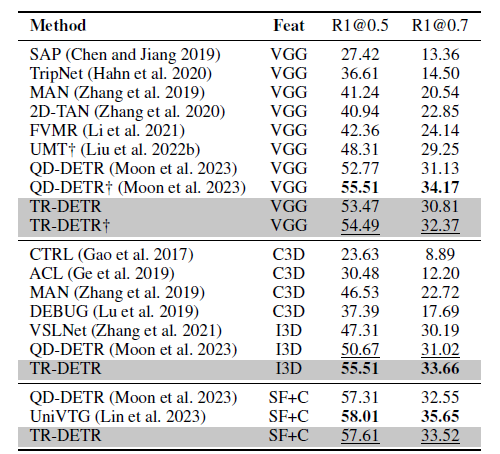
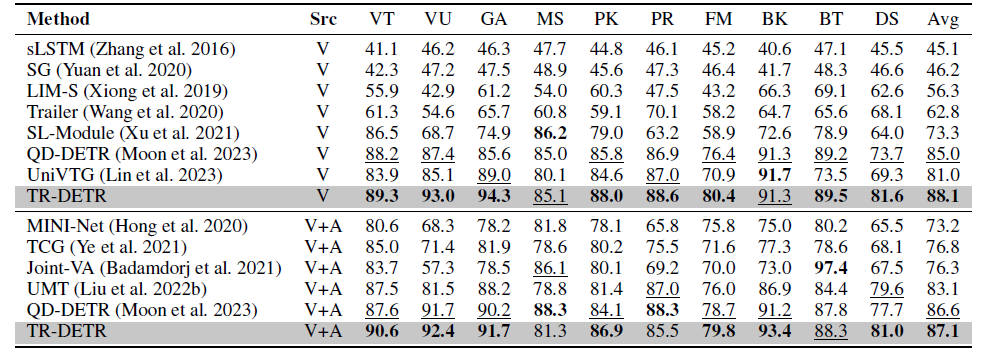
표 2와 3은 각각 Charades-STA 데이터셋에 대한 MR 벤치마크, TVSum 데이터셋에 대한 HD 벤치마크 성능 표입니다. 평균 수치로 봤을 때 HD에서는 TR-DETR이 높은 성능을 보여주고 있습니다. 하지만 Charades-STA 데이터셋에서의 MR 성능은 타 방법론들에 비해 낮은데, 저자는 이에 대해 VGG feature, text feature, audio feature 간 scale 차이가 너무 커 multi-modal align이 어렵기 때문이라고 이야기하는데.. 타 방법론들과 동일한 feature를 사용했기 때문에 합리적인 이유라 보기는 어려울 것 같습니다. 또한 SlowFast+CLIP feature를 사용했을 때의 성능은 UniVTG보단 낮지만 QVHighlights에서는 높았다라고만 이야기하고 있는데 맞는 분석인건지 잘 이해가 되지 않네요.
3.3 Ablation
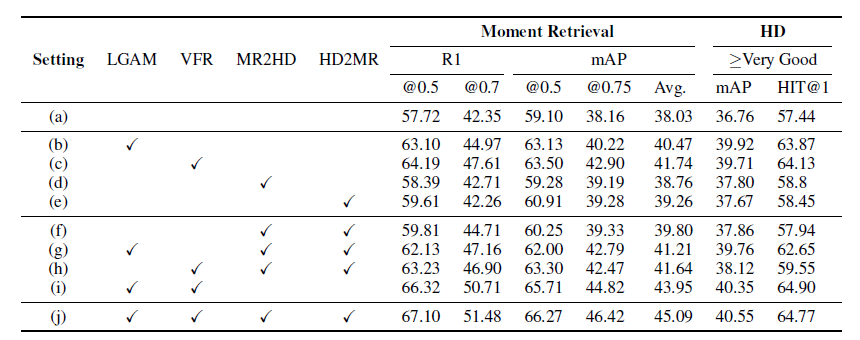
표 4는 모듈 별 ablation 성능입니다. LGAM은 Local-Global alignment module, VFR은 Visual Feature Refinement module을 의미합니다.
우선 TR-DETR이 제안하는 모든 모듈이 베이스라인에 대한 성능 향상을 보여주고 있습니다. 다만 실험 (c)와 (h)를 비교하여 Task cooperation 모듈을 붙였을 때의 성능을 분석해보면, 오히려 떨어지는 것을 볼 수 있습니다. 이는 Local-Global alignment 모듈이 없기 때문에 발생하는 성능 저하라고 볼 수 있는데, 두 task 간 cooperation을 수행하기 전 반드시 두 모달리티 간의 align이 잘 맞아있어야 cooperation 모듈도 잘 동작함을 보여줍니다. 실험 (i)를 보았을 때 두 task 간 cooperation 없이도 큰 성능 향상이 일어나는 것을 볼 수 있는데, TR-DETR의 메인 contribution이라 생각했던 task cooperation보다 두 모달리티 간 상관관계를 잘 모델링해주는 것이 더 중요하다는 것이 아쉽긴하지만 모든 모듈이 사용되었을 때 가장 큰 성능 향상을 보여주고 있습니다.
4. Conclusion
MR&HD 두 task의 상호작용과 공통적 특성을 잘 살려 서로 돕는다는 컨셉의 TR-DETR 논문을 리뷰해보았습니다. 마지막 ablation 결과와 다른 방법론들을 종합적으로 생각해보았을 때 아직은 두 모달리티 간 관계를 잘 모델링해주는 것이 성능 향상에는 직접적으로 가장 많은 도움을 준다는 것을 알게해준 논문입니다.
리뷰 마치겠습니다. 감사합니다.
리뷰 잘 봤습니다.
뭔가 attention 연산이 꽤나 많이 들어간 방법인 거 같은데 FLOps 관점에서 비교는 없나요?
그리고 표3에서 칼럼 부분이 의미하는게 뭔가요? (VT, VU, GA 등등)
감사합니다.
안녕하세요, 질문 감사합니다.
attention 연산이 많이 들어간 방법론인것은 맞습니다. 하지만 연산량에 대한 리포팅은 따로 하고있지 않으며, 최근 등장하고 있는 DETR 기반 방법론들이 기존 DETR 구조 + 추가 attention 연산을 통한 feature modeling을 주 컨셉으로 하고있기에 저자나 리뷰어들도 딱히 이에 대한 고려는 해주고있지 않은 것으로 보입니다. 물론 이 타이밍에 연산량을 고려하는 효율적인 MR&HD 방법론이 하나의 contribution이 될 수도 있다고 생각합니다.
표 3의 칼럼은 TVSum 데이터셋에 존재하는 10개의 클래스를 각각 의미합니다.
안녕하세요 김현우 연구원님 좋은 리뷰 감사합니다.
Charades-STA 데이터셋과 TVSum 데이터셋은 각각 MR과 HD에 대한 annotation만 존재하는데 해당 방법론을 MR, HD 하나만 annotation되어있는 데이터셋에 적용하기 위해 저자가 따로 신경 쓴 부분이 있는지 궁금합니다.
감사합니다.
안녕하세요, 질문 감사합니다.
TR-DETR의 방법론 특성 상 두 task를 하나의 모델에서 joint하게 수행할 수 없다면, task cooperation 모듈이 완전히 빛을 보기 어려울 것 같습니다. Task cooperation 모듈을 제외한 나머지 모듈들만이 주요 성능 향상에 기여했을 것으로 생각됩니다. 모듈별 ablation도 QVHighlights 데이터셋만으로 수행되어 정확히 각 모듈이 나머지 데이터셋에서 어느 정도 성능 향상에 기여하는지는 알기 어려울 것 같습니다. 그러다보니 QVHighlights 데이터셋에 비해 Charades나 TVSum 데이터셋에 대한 성능 향상 폭이 미미했던 것으로도 이해해볼 수 있을 것입니다.
말씀해주신 부분을 위해 저자들이 특정 데이터셋만을 고려한 추가 모델링을 진행하지는 않았습니다.