Introduction
Automatic Speech Recognition이란 speech에서 text를 인식하는 것을 의미하며, 최근에는 딥러닝 기술을 적용한 ASR이 널리 활용되고 있습니다. 그러나 ASR 모델을 real-world에서 사용하고자 하는 경우, 입력 speech에 background noise가 포함되는 경우가 많아 ASR 성능이 크게 저하되는 문제가 발생합니다. 초기 ASR 연구들은 이러한 소음 문제를 해결하기 위해 speech enhancement를 도입하고자 하였고, 그 결과 inference 시 front-end 모델로 dnn 기반 speech enhancement 모델을 사용하였습니다. 즉, noisy speech를 speech enhancement model로 전처리한 뒤 생성된 enhanced speech를 ASR 모델의 입력하는 방식을 사용하였습니다.
그러나 앞부분에 enhancement model를 사용하면, dnn모델로 인한 비선형적인 신호의 왜곡이 발생하여 enhanced speech의 ASR 성능이 떨어질 수 있었다고 합니다. 이 때문에 일반적으로 SE + ASR 사용하는 framework에서는 두 모델을 동시에 학습하여 SE에 의해 발행할 수 있는 왜곡을 최소화 하고자 하였는데 두 모델을 동시에 학습하다 보니 보다 복잡한 네트워크 구조와 학습 전략이 필요하였다고 합니다.
self-supervised learning은 대규모의 unlabeled data에서 데이터의 representation을 학습함으로써 downstream task에 유용한 representation을 얻는 방법입니다. Speech 관련 분야에서는 wav2vec과 같은 self-supervised network를 통해 mel-spectrogram같은 기존의 hand-crafted feature 보다 효과적인 성능을 보여주고 있습니다. self-supervised learning architecture는 generative/predictive learning과 contrastive learning으로 나눌 수 있는데 generative는 입력값이 일부를 masking하고 원래의 입력값을 예측하도록 학습하며, contrastive learning은 embedding space 내에서 contrastive task를 해결하도록 학습합니다.
다시 speech recognition으로 돌아와서, 본 논문에서는 기존의 supervised 방식을 따르지 않고 self-supervised 방식을 통해 noise에 강인한 ASR 모델을 제안하였습니다. 구체적으로는, 널리 사용되는 audio self-supervised 모델인 wav2vec 2.0의 contrastive learning framework에 reconstruction model을 결합하였습니다.
논문의 contribution을 요약하면 아래와 같으며, 구체적인 방법론은 이어서 설명드리겠습니다.
- Reconstruction learning을 wav2vec 2.0의 contrastive learning에 통합하고 continual pre-training을 통해 noisy input으로부터 clean speech를 생성함
- 1)의 방법론을 통해 합성된 noise data에서 model의 robustness를 향상시킴.
- Preprocessing 모듈 없이 real-world noise speech 데이터셋인 CHiME-4에서 지도 학습 방식의 성능을 달성함. 특히 supervised 방식의 sota 성능을 16%의 labelled 데이터로 달성함.
Network Architecture
Wav2vec 2.0
저자들의 방법론이 wav2vec 2.0의 contrastive learning framework를 기반으로 하고 있는데요, wav2vec 2.0의 framework는 아래 그림과 같습니다.
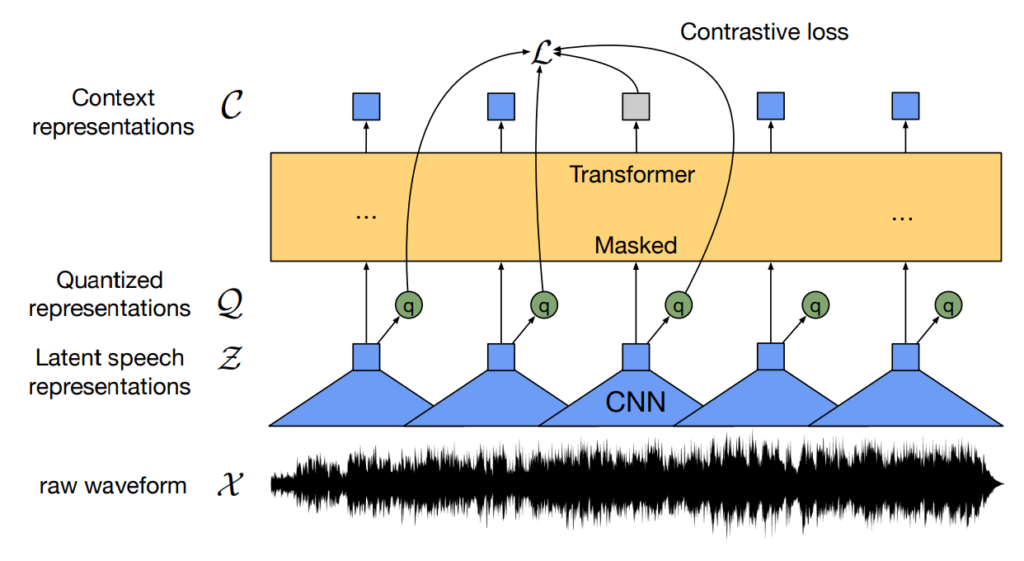
먼저 CNN feature encoder를 통해 raw waveform에서 latent speech representation Z 를 추출하고, Z 를 Gumbel Vector quantizer를 사용해 quantized representation Q 로 변환합니다. 마지막으로, Z에 mask를 적용하고, 이를 transformer-based context network에 전달하여 downstream task에 사용될 contextual representation C 를 생성합니다.
이때 contextual representation C 와 quantized embedding Q 에 대해 contrastive loss를 구하여 학습을 진행하는데요, context network의 masking된 부분 c를 기준으로 Q에서 동일한 시간대의 sample q는 positive, 다른 시간대에서 sampling된 q들은 negative로 pairing 하게 됩니다.
Proposed Architecture
저자들이 제안하는 방법론은 아래의 [그림 1]과 같으며, 좌측에 있는 CNN, Transformer, Quantizer는 wav2vec 2.0을 그대로 차용하였고, 오른쪽 부분의 Reconstruction Module이 추가된 형태입니다.
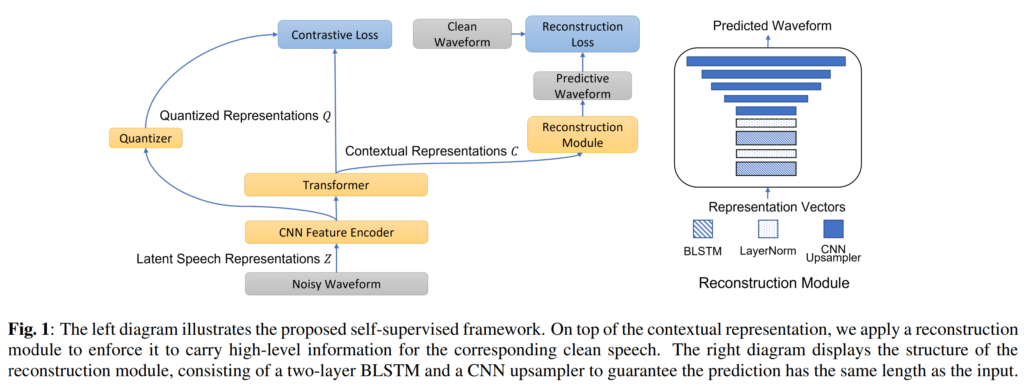
전체 모델의 입력으로는 동일하게 noisy waveform을 사용하고, reconstruction module에서는 wav2vec 2.0에서 생성contextual representation C를 입력으로 받아 clean waveform을 예측하게 됩니다. 학습은 multi-task learning, 즉, 모델이 clean speech를 reconstruct하는 동시에 positive/negative sample간의 constrastive task를 해결하도록 진행되었습니다.
Reconstruction module의 구조는 [그림 1]의 오른쪽에 부분과 같습니다. 이는 speech enhancement 모델인 convolutional recurrent network (CRN)을 기반으로 설계되었다고 하는데요, CRN은 CNN encoder, temporal dependencies를 모델링하는 RNN 기반의 bottleneck, 그리고 CNN decoder로 구성되어 있습니다. 이에 따라 저자들은 contextual representations 이전의 모듈을 encoder로 간주하고, reconstruction module은 Bi-LSTM bottleneck과 그 뒤에 오는 CNN decoder로 구성하였습니다. bottleneck에서는 BLSTM 뒤에 layer normalization을 수행하였고, CNN decoder는 wav2vec 2.0의 CNN feature extractor와 대칭적으로 설계되어 입력 waveform의 원래 형태를 완전히 복구하는 구조를 띄고 있습니다. 이때 reconstruction은 pre-training에서만 수행되며, fine-tuning 및 inference 단계에서는 수행하지 않았다고 합니다.
Loss
저자들은 원래의 wav2vec 2.0 loss와 동일하게 contextual representation C 와 quantized embedding Q 를 기반으로 contrastive loss L_c 를 계산하였습니다.
이 부분은 위의 그림을 보면 이해하기 쉬울 것 같은데요, t 시점에서의 context vector c_t (위 그림에서는 회색으로 표시된 c_3)가 있을때, 같은 speech 내에서 생성된 quantized embedding Q에서 K개의 negative sample \bar{q}_1, \bar{q}_2, \ldots, \bar{q}_K 을 추출하게 됩니다. 이때 c_t 와 동일한 시점에 해당하는 q_t 가 positive sample이 되며, 이에 따른 contrastive loss는 아래의 [수식 1]과 같습니다.
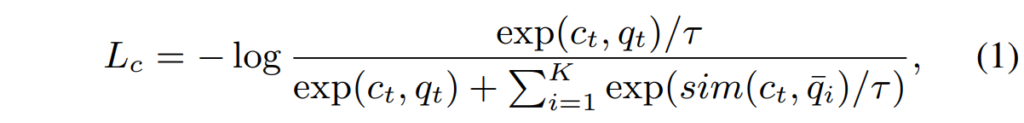
여기서 \tau 는 temperature parameter이며, \text{sim}(\cdot) 은 코사인 유사도를 의미합니다.
또한 wav2vec의 quantizer를 그대로 차용하였기에 quantizer에 사용되는 diversity loss를 아래와 같이 정의하였습니다.
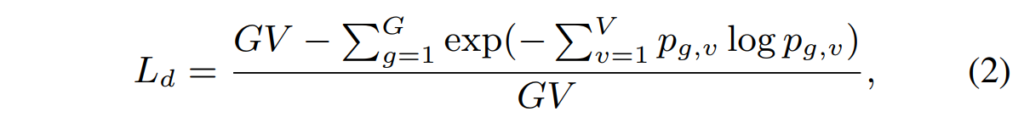
여기서 여기서 G 는 quantizer codebook의 수, V 는 codebook 내 항목의 수를 의미하며, 해당 loss는 quantizer 내부의 codebook에 대해 모든 항목을 균등하게 사용하기 위한 목적으로 사용하였다고 하네요. 해당 부분에 대한 설명은 블로그를 참고하시면 좋을 것 같습니다.
마지막으로, reconstruction module에 사용되는 reconstuction loss에 대해 설명드리겠습니다. Reconstruction loss L_r 은 아래의 [수식 3]과 같이 나타내었습니다.
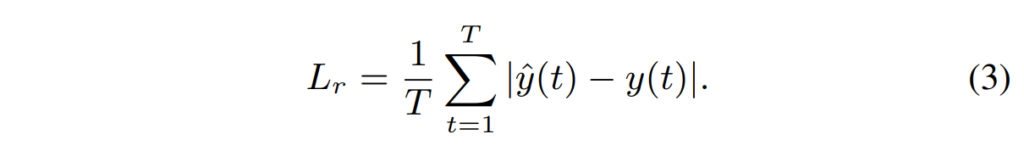
L_r 은 predicted waveform, 즉, enhanced speech \hat{y} 과 clean waveform y 사이의 MSE를 계산하여 얻었다고 합니다.
본 논문에서 제안하는 모델 학습을 위한 최종 loss는 아래의 [수식 4]와 같이 앞선 세 loss의 합으로 구성되었습니다.
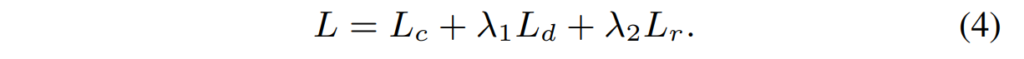
Experiment
Dataset
본 논문에서는 ASR 모델의 noise에 대한 강인성을 평가하기 위해 noise를 합성한 데이터와 real-world noisy 데이터에 대한 실험을 진행하였습니다.
합성 데이터는 clean speech에 background noise 데이터를 합성한것으로 clean speech는 speech recognition datset인 LibreSpeech를, noise audio는 DNS-challenge1의 noise dataset에서 20000개의 audio를 random하게 선택하였다고 합니다.
Real-world noisy 데이터는 CHiME-4 challenge의 real noisy 데이터를 사용하였다고 합니다. 해당 데이터는 bus, cafe, pedestrain area street junction 등 주변 소음의 영향이 큰 환경에서 녹음을 진행하였다고 합니다.
Results
아래에 설명드릴 실험들은 평가 metric으로 WER(Word Error Rate)를 사용했습니다. 이는 ASR에서 보편적으로 사용되는 metric으로, 인식된 text와 정답 text를 단어 단위로 오차를 측정하는 것으로 낮을수록 좋은 성능을 보이는 것이라고 이해하시면 됩니다.
Results on Synthesized Noisy Speech
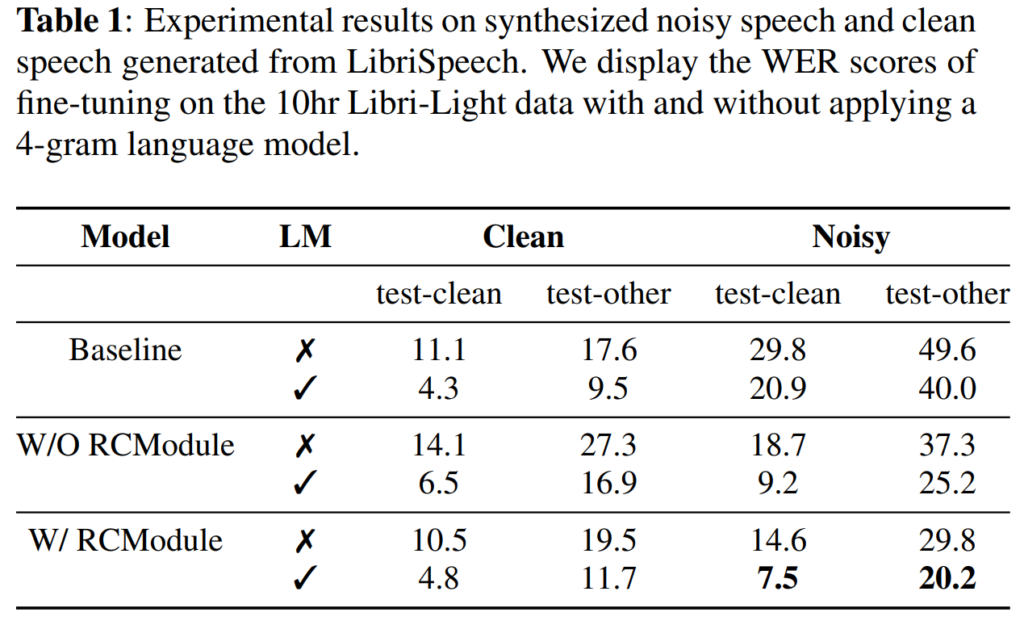
[표 1]은 합성 데이터에 대한 결과로, LibriSpeech의 test-clean 및 test-other에 대한 평가 결과입니다. [표 1]에서 baseline의 경우, clean speeh에 대해서는 좋은 성능을 보였으나, noisy speech를 인식할 때는 성능이 크게 저하되는 것을 확인할 수 있습니다.
다음으로는 baseline에 reconstruction 모델을 추가하지 않고 continual learning을 통해 noisy 데이터애 대한 학습을 추가한 경우, noisy 환경에서 성능이 개선되었으나, 오히려 clean speech에서의 성능이 저하된 것을 확인할 수 있습니다.
마지막으로 reconstuction 모듈을 추가한 저자들의 모델은 clean speech에 대한 성능을 유지하면서도 noisy speech의 성능 또한 개선된 것을 확인할 수 있습니다. 추가로 4-gram 언어 모델을 적용하면, 저자들이 제안한 모델은 test-clean의 WER을 20.9%에서 7.5%로, test-other의 WER을 40.0%에서 20.2%로 변화하는 것을 확인할 수 있는데, 논문에서는 이러한 저자들의 접근 방식이 사전 학습된 모델의 noise robustness을 향상시키는 데 도움이 되었기 때문이라고 언급하였습니다.
Results on Real-world Noisy Speech
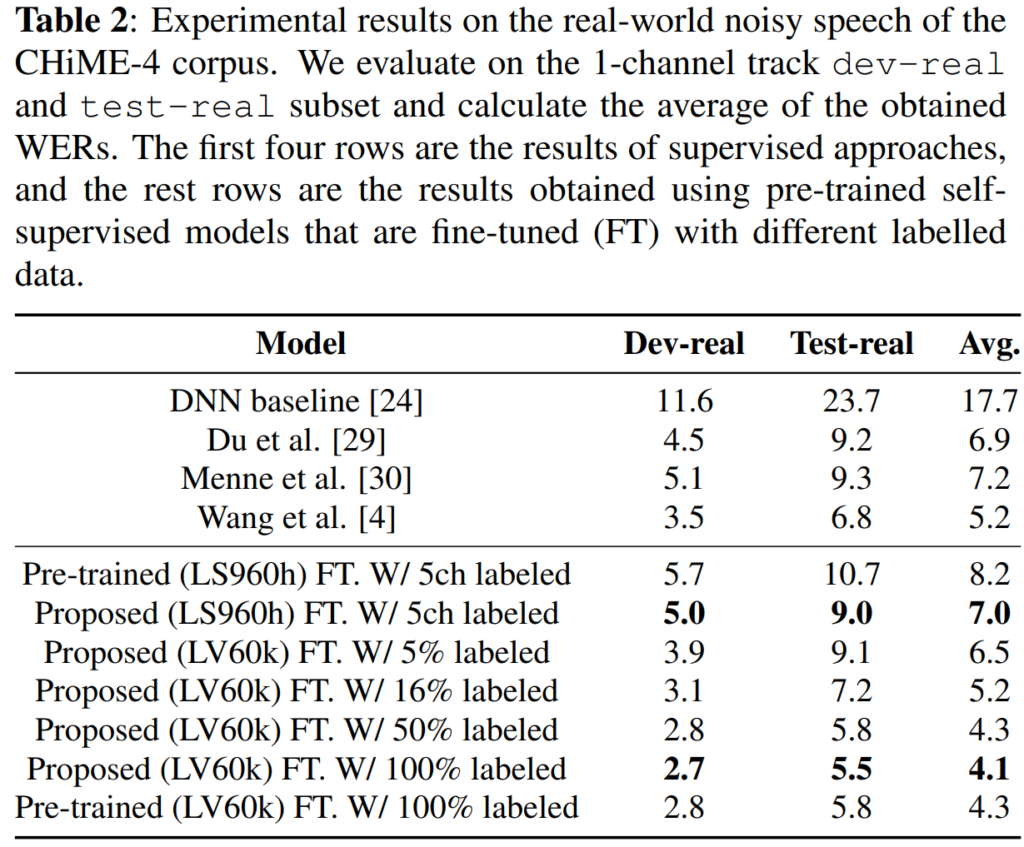
[표 2]는 real-world noisy 데이터에 대한 결과로, CHiME-4 challenge의 real noisy 데이터에 대한 결과입니다. [표 2]를 보시면 두 가지 section으로 나뉜 것을 확인할 수 있는데 윗 부분은 supervised 방식, 아래 부분은 다양한 비율의 labelled data로 fine-tuning된 self-supervised 방식의 결과를 의미합니다.
상단 section의 1~3번째 행은 CHiME-4 challenge에서 높은 성능을 기록한 모델들이며, 마지막은 해당 데이터셋의 sota를 나타낸다고 합니다. 하단 section의 결과는 사전 학습된 self-supervised 모델로부터 얻어진 것으로, labelled 데이터의 비율에 따라 fine-tuning 된 결과들입니다.
결론적으로 해당 실험 결과를 통해 언급하고자 하는 것은 supervised 방식보다 더 적은 양의 labelled 데이터로 더 좋은 성능을 달성하였다는 것입니다. 구체적으로 살펴보자면, 아래 section의 결과에서 5%의 labelled 데이터를 사용하여 평균 6.5%의 WER을 달성한 것을 확인할 수 있는데, 이는 challenge에서 달성한 최고 성능보다 0.4% 개선되었다고 합니다. 더 나아가, 모든 labelled 데이터를 사용하여 fine-tuning한 경우, 평균 4.1%의 WER을 달성한 것을 달성한 것을 확인할 수 있는데, 이는 supervised 방법론으로 얻은 WER보다 21.1% 낮은 수치에 해당하게 됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
1) 본 논문의 모델의 input으로 noisy waveform만 들어간다고 생각했는데, 다시 생각해보니 clean waveform이 있어야 loss를 구할 수 있겠구나 싶은데 모델의 input으로 noisy, clean waveform이 동시에 필요한가요?
2) 실험 결과에서 추가로 궁금한 점이 4-gram 언어 모델을 적용했을 때 error율이 굉장히 낮아지는 것을 확인할 수 있는데, 본 모델에서 추가로 4-gram 언어 모델을 어떻게 적용한지 감이 오지 않아 이에 대해서 질문 드리고 싶습니다. 그리고 왜 4-gram 언어 모델을 사용했을 때 error가 굉장히 낮게 나오는지에 대해서도 궁금합니다.
감사합니다
댓글 감사합니다.
1) 모델의 input으로 noisy waveform과 clean waveform이 동시에 필요한가요?
넵. 모델 학습 시 clean과 noisy가 둘 다 필요합니다. 구체적으로는 wav2vec 2.0 부분은 noisy로만 학습하는 self-supervised 방식으로, reconstruction module은 clean을 gt로 학습하는 supervised 방식으로 학습이 이루어집니다.
2) 4-gram 언어 모델
언어 모델은 asr에서 speech signal을 text로 변환하는 모델에 해당하는데요, n-gram 방식은 직전 n개의 단어를 보고 다음에 나올 단어에 대한 확률을 모델링하는 방식을 의미합니다.
본 논문에서는 4-gram 방식으로 단어를 4 단어씩 묶어서 이후에 나올 단어를 예측하는 방식으로 ASR을 수행하였다고 합니다. 그리고 4-gram LM에서 성능이 향상된 이유는 논문에서 직접적으로 언급되어 있지는 않지만 고려하는 단어의 범위가 증가함으로 인한 문맥 정보가 퐁부해졌기 때문이 아닐까 생각됩니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
설명을 들었을 때 입력으로 noisy한 데이터만 들어간다고 이해를 했는데, 중간에 마스킹을 하는 것은 결국 noisy 데이터에서 또 한번 마스킹을 진행해주는 것인가요 .. ? reconstruction을 위해서는 clean한 데이터도 함께 들어가야되지 않나 의문이 들었는데, 뒷쪽에서 loss 설명을 해주실 때 clean한 데이터와의 비교를 한다고 설명해주셨습니다. 그럼 결국 noisy 데이터 + 마스킹 / clean 데이터와의 reconstruction loss를 진행하는 것일까요 .. ?
그리고 제가 전에 혜원님 SE 관련 리뷰를 읽었을 때 speech 관련 데이터셋에서부터 기본적으로 여러 요인으로 인해 왜곡이 발생하여 품질이 저하된 형태를 띄고 있다고 설명해주셔서, 노이즈가 없는 품질이 향상된 데이터를 구축하는 방향의 연구는 없는지 질문 드렸던 기억이 납니다. 그런 관점에서 여기서 GT로 제공해주는 clean 데이터라고 함은 정확히 어떻게 제공이 되는 것인가요 ?? 데이터 레벨부터 노이즈가 이미 존재하는데, 이를 clean data로 정의하여 GT로 제공해도 enhancement 효과가 있을 지 궁금합니다.
감사합니다.
댓글 감사합니다.
넵 맞습니다. 중간에 masking을 진행하는 부분은 noisy 데이터에 진행되는 것이 맞습니다.
speech 데이터를 수집할 때 기본적으로 왜곡이 발생하는 것은 맞지만, 본 논문 및 대부분의 speech enhancement 연구에서 사용되는 clean 데이터는 스튜디오(실험실) 환경, 즉, 외부 소음이 최소화된 공간에서 녹음된 데이터를 의미합니다. 여기에 외부 noise를 합성하거나 소음 환경에서 녹음된 데이터를 noisy 데이터으로 제공합니다.
clean도 데이터 레벨에서 노이즈가 존재하는 것은 맞지만 이러한 clean데이터가 gt로 제공되었을 때 noisy 데이터셋에 포함되는 noise에 대해서는 enhancement 효과가 존재하게 됩니다.