안녕하세요, 오늘 소개할 논문은 “MonoViT: Self-Supervised Monocular Depth Estimation with a Vision Transformer”입니다. 해당 논문은 처음으로 self-supervised monocular depth estimation이라는 테스크에 ‘Vision Transformer(ViT)의 Multihead self-attention(MHSA)을 적용한 논문인데요.
기존에 conv연산으로 구성된 CNN archtecture는 한정된 receptive field를 사용하여 국소부분(local)에 대해서 특징추출 및 추론을 할 수 밖에 없는 구조였습니다. 이러한 부분이 Figure 1와 같은 문제점을 발생시켰다고 하는데요.(부정확한 depth 예측, fine-grained details 상실 등)

(제가 생각하기에 이런 local 특징을 사용하는 것이 Figure 1의 문제를 야기한다라기 보다는 적어도 ViT를 활용하여 이미지 전체를 고려한 semantic한 특징을 뽑는 것을 추가하니 기존의 단점들이 보완되었다. 라고 보는 것이 맞을 듯 싶습니다.)
해당 문제를 해결하고자, 저자들은 ViT의 Multihead self-attention(MHSA) block을 적용하여 이미지 전체를 고려한 특징추출과 추론(global reasoning)을 가능하게 하였습니다.
최종적으로 기존 CNN으로 부터 얻은 local 특징, ViT block으로부터 얻은 global 특징을 모두 사용하여 더 디테일하고 정확한 depth 추정을 가능하게 한 방법론 입니다.
그럼, 2번째 x-review를 시작하겠습니다.
1. Introduction
1.1. self-supervised monocular depth-estimation Review
해당 논문도 추가된 아이디어를 제외한 모든 부분에서 기존의 self-supervised monocular depth-estimation테스크의 파이프라인을 그대로 따라갑니다. 그래서 해당 테스크에 대해서 간단히 Review를 하겠습니다. depth estimation 테스크는 3D scene을 이미지로 투영시키는 과정에서 소실된 depth정보를 모델로 하여금 예측하도록 하는 테스크입니다. 이걸 단안(monocular)카메라로 촬영한 비디오 데이터를 사용하여 진행하는 것이 monocular depth-estimation이 되겠습니다.
초기 연구는 supervised learning방식으로 진행이 되었는데요. labeled 데이터셋 구축의 어려움. 일반화 성능저하 등의 이유로 self-supervised learning(SSL)방식으로의 연구의 흐름이 바뀌게 됩니다.
깊이 추정을 SSL의 방식으로 진행하기 위한 pretext-task로 “target image reconstruction”테스크를 수행합니다. “target image reconstruction”은 단순히 인접 카메라 프레임(-1, +1)을 통해서 현재 시점(0)의 프레임(타겟프레임)을 reconstruction하는 테스크입니다. 이것 위해서 depth정보와 인접 프레임과 타겟프레임 간의 상대적인 pose를 필요로 하는데요. 그래서 연구자들은 depth를 예측하는 depth network와 pose를 예측하는 pose network, 두 종류의 네트워크를 구성합니다
depth network가 예측한 depth정보와 pose network가 예측한 두 프레인 간의 relative 6D pose정보를 통해서 타겟 프레임을 인접 프레임으로의 warpping을 구현합니다. 그리고 인접프레임에 와핑된 타겟프레임의 관계를 이용하여 bilinear sampler를 통해 인접프레임을 샘플링하여 합성 타겟프레임을 생성하게 됩니다.
그런 다음 합성 타겟프레임과 실제 타겟프레임 간의 Photometric-Error를 계산하여 SSL을 위한 supervision을 줍니다. 본 논문도 위위의 파이프라인을 통해서 학습이 진행됩니다. 그리고 inference시에는 원하는 depth정보를 얻기 위해서 depth network만 사용하는데요. 한 장의 이미지를 학습된 depth network에 넣어서 해당 이미지의 depth를 얻습니다.
1.2. Motivation
해당 파트에서는 저자들이 제안하는 MonoViT가 나오게 된 계기에 대해서 기존 연구들을 근거로 소개하겠습니다.
첫 번째 연구는 depth estimation과 semantic segmentiation 두 task의 유사성에 주목한 연구인데요. 결론만 말씀드리면, depth estimation task가 semantic segmentation task와 유사하며, semantic segmentation처럼 이미지의 semantic information과 spatial information를 기반으로 학습한다는 연구입니다.
또한 다른 연구들에 따르면, 모델의 backborn을 좋게 만드는 것이 더 좋은 특징들을 추출을 한다는 점에서 테스크 성능 향상에 기여한다고 하는데요. 그런 관점에서 깊이 추정이 테스크에서는 특징을 추출하는 인코더의 중요성이 부각됩니다.
따라서 해당 분야는 “인코더의 특징 추출 능력과 처리능력을 향상시키기”라는 갈래로 연구가 지속되었는데요.
ex) HR net등에서 언급된 feature fusion 방식적용, 어텐션 메커니즘 적용을 통한 특징 강화 등이 그 예시입니다.
본 논문의 저자들은 CNN의 한정된 receptive field를 통한 특징추출 및 추론이 이러한 “좋은 특징 추출하기”라는 측면에 성능을 떨어뜨리는 ‘Bottle Neck’으로 지목합니다. 특히 CNN의 구조적 문제. 즉, 특정 receptive field로 한정된 구간에 대해서 컨볼루션 연산을 하여 특징추출을 한다는 점이 한 이미지 내에서 long-range relationship을 잃게 만든다고 지적합니다.
이를 SSL을 위한 reconstruction task 관점에서 해석한다면,
Review파트에서 소개드렸듯, SSL 위한 loss로 실제 타겟이미지와 합성된 타겟이미지 간의 photometric Error(두 이미지간의 유사도)를 사용하는데요. 이때 합성된 타겟이미지를 구하는 과정에서 모델의 scene structure에 대한 정확한 이해가 필요합니다. 그래야 모델이 정확한 scene을 reconstruction할 수 있을 테니까요.
그러나 전경과 배경의 texture와 intensity가 유사한 부분에 대해서 CNN연산은 전경과 배경을 구분하기 어려워하는데요. 이는 전경과 배경을 같은 semantic context로 임베딩하여 동일 depth로 추정한다는 결과를 초래한다고 합니다.
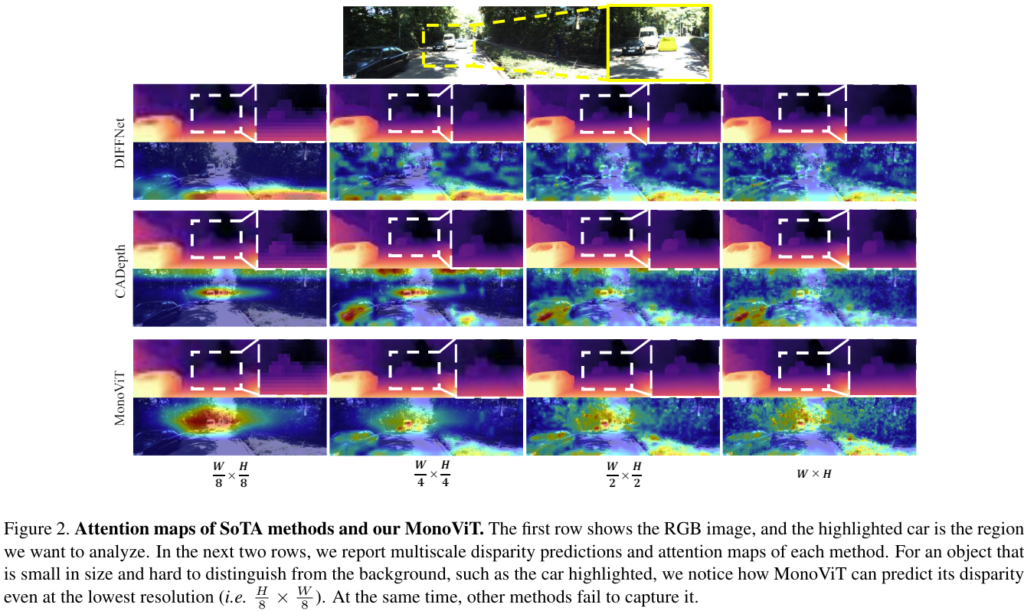
위의 Figure 2.를 보시면, 맨 위의 이미지에서 노랗게 하이라이트 된 차량이 햇빛 때문에 길(road)과 구분하기 힘든 상황인데요. 이것에 대해서 기존 CNN기반의 Depth network(DIFFNet, CADepth)들은 차량의 depth와 배경인 길(road)의 depth를 유사하게 예측하고 있는 것을 확인할 수 있습니다. 그 이유는 depth map아래의 CAD이미지를 보시면 확인 할 수 있는데요. 바로 CNN기반의 모델들은 depth를 예측함에 있어서 모든 스케일에서 차량보다는 길과 배경에 attention을 하고 있기 때문입니다.
이런 문제들을 해결하고자 본 논문에서 MonoViT라는 self-supervised monocular depth estimation을 위한 새로운 아키텍쳐를 제안하였는데요. MonoViT는 CNN과 Transformer를 혼합하여 적용하는 구조로, 모델로 하여금 한 이미지에서 지역 특징 뿐 만 아니라 long-range relationship을 반영한 전역 특징을 종합적으로 사용하도록 해줍니다. 이로서 CNN으로만 이루어진 모델의 한계를 제거하였다고 합니다.
2. Proposed Framework
2.1. DepthNet Architecture
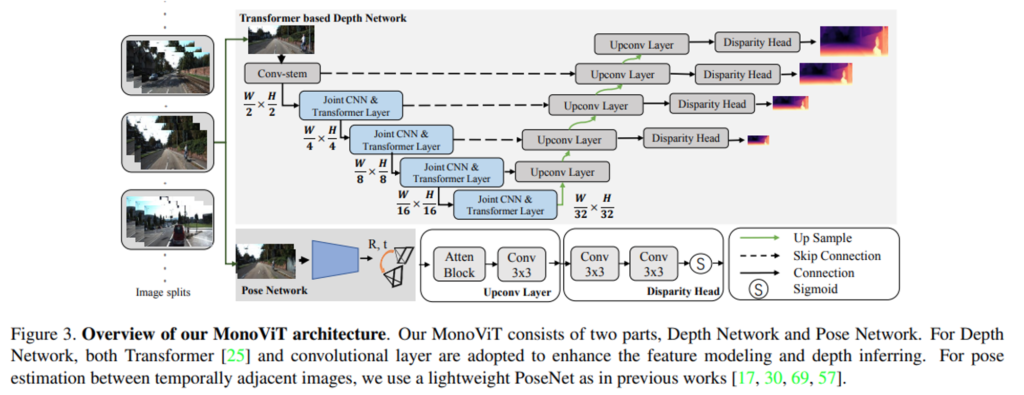
depth 모델은 기존의 다른 모델들과 동일하게 encoder-decoder구조로 아래 Figure 3.과 같이 구성되어있습니다
2.2. Depth Encoder
먼저 Depth Network의 인코더 부분에 대해서 설명드리겠습니다. 먼저 “Conv-stem”모듈을 거칩니다. 해당 모듈은 두 개의 3×3 conv레이어로 구성됩니다. 첫 conv에서 stride=2를 주어 아웃풋의 resolution을 절반으로 줄여줍니다. 그리고 앞서 소개한 연구 방향성에 따라서 저자는 “좋은 특징 추출”을 위해서 MPViT라는 당시 최신 Transformer의 주요 모듈에 영감을 받은 모듈을 설계합니다. 바로 “Joint CNN & Trasnformer Layer”인데요.
해당 모듈은 아래 Figure 4.와 같습니다.
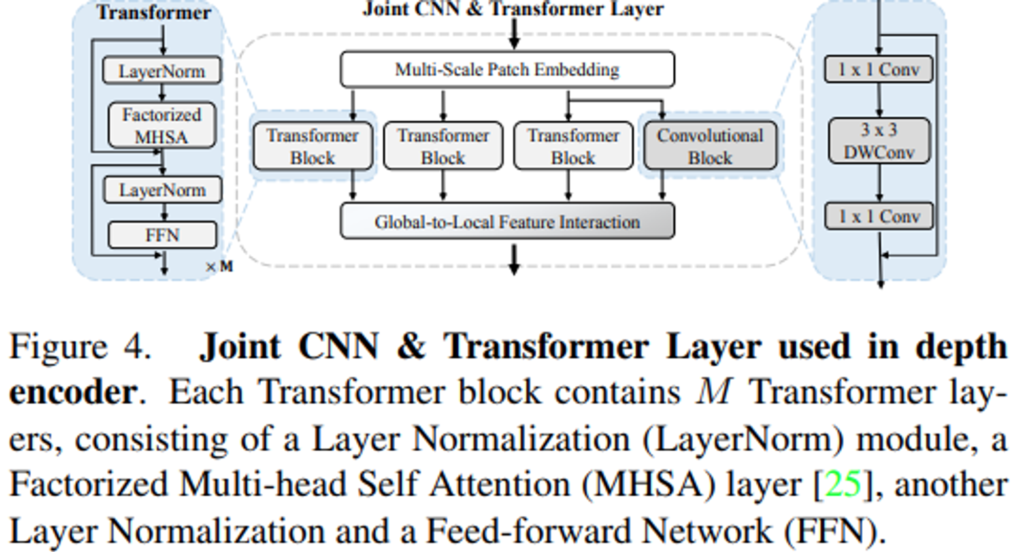
그 구조는 굉장히 심플합니다. 먼저, Multi-Scale Patch Embedding을 거쳐서 여러 종류의 feature patch로 embedding을 하는 데요. 단순히 모듈의 인풋으로 들어온 feature map에 대해서 3×3, 5×5, 7×7의 receptive field를 갖는 conv연산을 해주는 것 입니다. 이로서 서로 다른 3종류의 visual token으로 임베딩 해줍니다.
(이를 통해서 같은 인 feature level 단에서 다양한 사이즈의 피쳐에 대하여 어텐션을 적용할 수 있게 됩니다.)
이후 3개의 Transformer Block과 1개의 Convolutional Block을 통해서 feature를 뽑습니다.
(이때 두 갈래로 분기되는 data-flow가 3×3 feature map이 됩니다.)
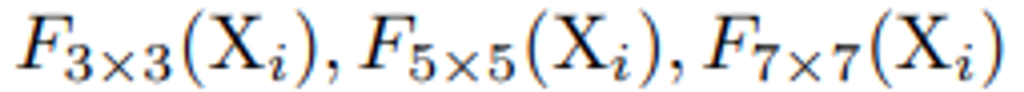
각 block에 대한 정보는 Figure 4.의 왼쪽, 오른쪽에 나와있습니다. conv branch를 통해서 local relationship(\bold{L})을, Transformer branch를 통해서 모든 visual token들 사이의 관계(\bold{G}_{0}, \bold{G}_{1}, \bold{G}_{2})를 모델링 해줍니다.
Transformer Block의 주요 연산인 Factorized MHSA은 일반적인 query-key-value를 이용한 self-attention 메커니즘을 효율적인 factorized 방식으로 구현한 것으로 수식(1)과 같습니다.
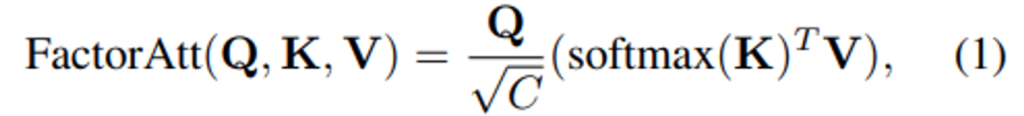
여기서, C는 embedding dimension을 의미합니다.
마지막으로 “Global-to-local feature interaction” 모듈을 태우게 됩니다. 각 branch로 부터 얻어낸 feature map을 수식(2), (3)처럼 concat후 1×1 conv를 태워 feature fusion을 진행합니다. (여기서\mathcal{H}(.)는 1×1 conv를 의미합니다.)
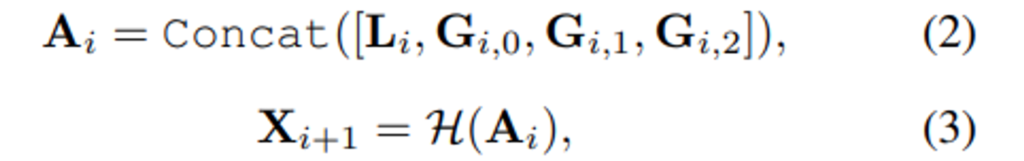
그리고 그렇게 만들어진 해당 Block의 feature를 다음 인코더노드의 인풋과 skip-connection으로 디코더에 전달합니다.
2.3. Depth Decoder
디코더는 Figure 3.과 같이 인코더로부터 skip-connection을 형태로 feature를 전달받고, 이전 디코더 노드의 아웃풋을 전달 받습니다.
Upconv Layer, disparity Head의 구조는 단순하므로 대부분 스킵하고 Upconv Layer의 “Atten Block”에 대한 설명만 간단하게 드리자면, 해당 블록은 “CBAM”의 spatial & channel-wise 어텐션 메커니즘을 사용합니다. skip-connection과 이전 디코더 노드의 output으로 부터 fine-grained detail 정보와 semantic 정보를 퓨전하는 과정에서 한번 더 집중할 부분을 강조해주 모습입니다.
그렇게 만든 feature map을 disparity Head를 지나, 해당 resolution의 depth예측으로 뽑게 됩니다.(depth는 disparity의 역수로 예측합니다.)
2.4. Self-supervised Learning
앞서 Self-supervised Monocular Depth Estimation Review에서 간략하게 언급드렸던 본 테스크에서 국룰처럼 사용되는 목적함수들 인데요. 크게 두 가지로 구성됩니다. 바로 수식(6)에 해당하는 “Photometric Loss”와 식(7)에 해당하는 “Smoothness Loss”입니다.
(5)번 수식은 실제 타겟이미지\mathcal{I}와 합성된 타겟이미지\mathcal{\tilde{I}}가 얼마나 유사한 지를 바탕으로 합성이미지가 타겟이미지를 닮아가는 방향으로 학습이 진행되도록 설계한 Loss입니다. Structural Similarity를 반영한 SSIM의 텀과 intensity difference를 고려한 |.| 연산인 L1 difference 텀으로 구성됩니다.
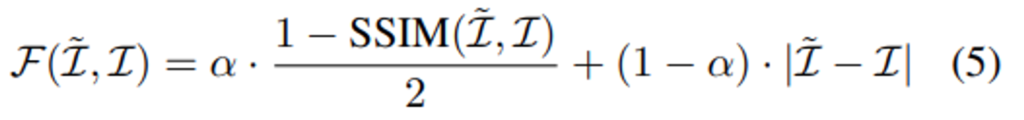
수식(6)이 실제 “Photometric Loss”에 해당하는 데요. 해당 loss는 (5)번 수식에 min을 취한 꼴입니다. 두 인접프레임(1, -1)중에 작은 \mathcal{F(\mathcal{I},\mathcal{I})}를 가져가는 것인데요. 이렇게 함으로서 occlusion되어 Loss연산에 방해가 되는 픽셀을 연산에서 제외하기 위한 의도입니다. 자세한 설명은 Monodepth2논문을 참고해주시면 감사하겠습니다.
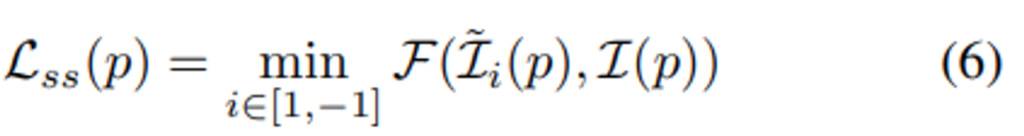
아래 수식(7)은 “Smoothness Loss”에 해당하는 데요. 해당 Loss는 depth map과 타겟이미지의 gradient를 고려하여 depth가 너무 튀지 않게 패널티를 준 텀이라고 생각해주시면 됩니다.
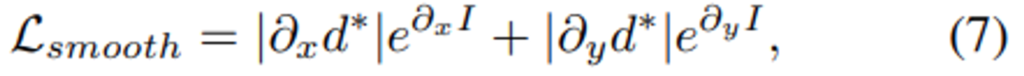
마지막으로 수식(6)과 (7)을 종합하여 수식(8)의 Total Loss를 정의합니다. 여기서 s는 Figure 3.을 확인하시면, 총 4개의 다른 scale로 아웃풋을 뽑는데 그것들을 평균내주기 위함입니다.
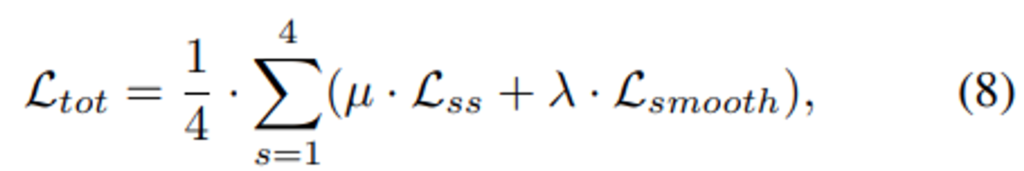
최종적으로 수식 (8)을 통해서 SSL의 supervision을 주게 됩니다.
3. Experiments
성능 평가를 위한 지표로 다음 5가지의 metric을 사용합니다.

간단한 설명을 드리면, Accuracy under threshold는 예측\hat{d_{p}}과 G.T인 d_{p}간의 두 비율 중 큰 것을 선택하여, 특정 threshold(\delta_{1}=1.25, \delta_{2}=1.25^{2}, \delta_{3}=1.25^{3}) 이하이면 TP로 판단을 하는데요. 그리고, TP/total_samples 연산을 하여 Recall을 구해주고, 이것 accuracy성능으로 생각을 하는 지표입니다. 따라서 높을 수록 좋은 성능을 나타냅니다. Accuracy under threshold를 제외한 4종류의 평가지표들은 pred와 G.T.가 수치적으로 얼마나 유사한 지 평가하는 것으로 작을 수록 더 좋은 성능을 나타냅니다.
아래 Table 1은 기존의 SOTA모델들과 저자들이 제안하는 MonoViT의 성능에 관한 reporting인데요.
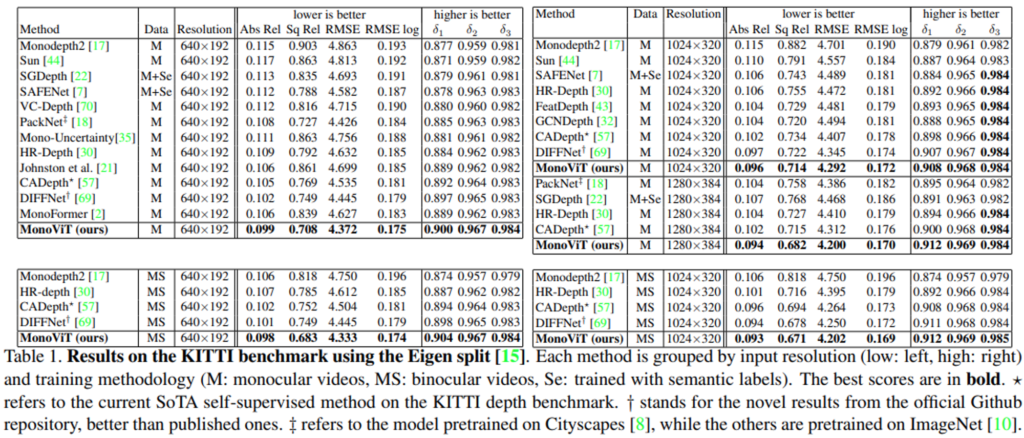
먼저 1st_row의 두 개의 표는 동일한 KITTI의 M(monocular videos) dataset으로 학습한 것을, 2nd_row의 두 개의 표는 동일한 KITTI의 MS(binocular videos) dataset으로 학습한 것입니다. 또한 왼쪽은 low resolution, 우측은 high resolution을 이미지를 통해 학습한 것을 나타냅니다. 결과들을 종합적으로 보자면, 저자들이 제안하는 MonoViT가 모든 실험에 대해서 SoTA를 달성한 것을 확인 할 수 있습니다.
아래 Table 2.는 Make3D라는 데이터셋을 통해서 평가한 결과입니다. 해당 실험을 통해서 학습을 데이터로 사용하였던 KITTI dataset이 아닌 유사하지만 데이터의 분포 다른 Make3D dataset으로 평가한 성능을 reporting하고 있습니다.
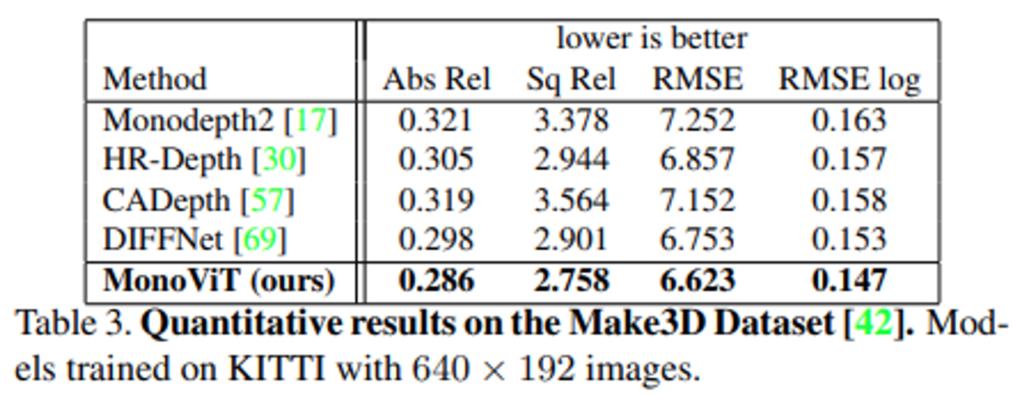
보시는 것처럼 기존 SoTA보다 좋은 성능을 보여줍니다.
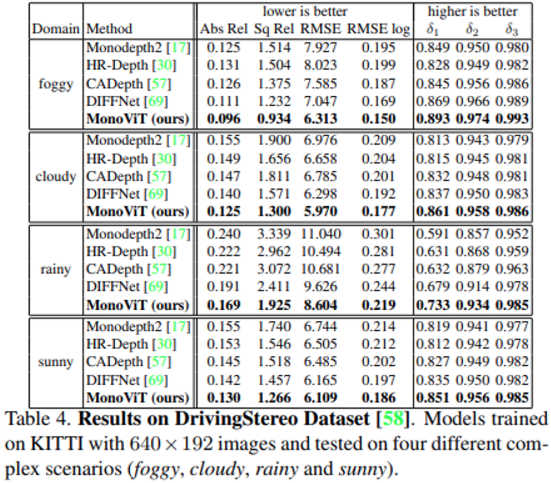
다음 실험은 MonoViT의 generalization 성능에 관한 실험입니다. 해당 실험에 사용된 DrivingStereo dataset은 아래 표와 같이 4가지 weather condition에 대한 stereo 이미지와 depth GT를 제공하는데요. 해당 데이터 셋을 통하여 MonoViT가 서로 다른 4개의 도메인 데이터에 대하여 기존 SoTA들을 월등히 앞서는 모습을 보여줍니다.
Ablation Study
마지막으로 ablation study입니다.
Table 5.의 위쪽 파트는 MPViT의 Variants와 PVT, Swin Transformer, ResNet을 backborn인코더로 사용하였을 때의 파라미터 수, FPS, 성능에 대한 reporting입니다.
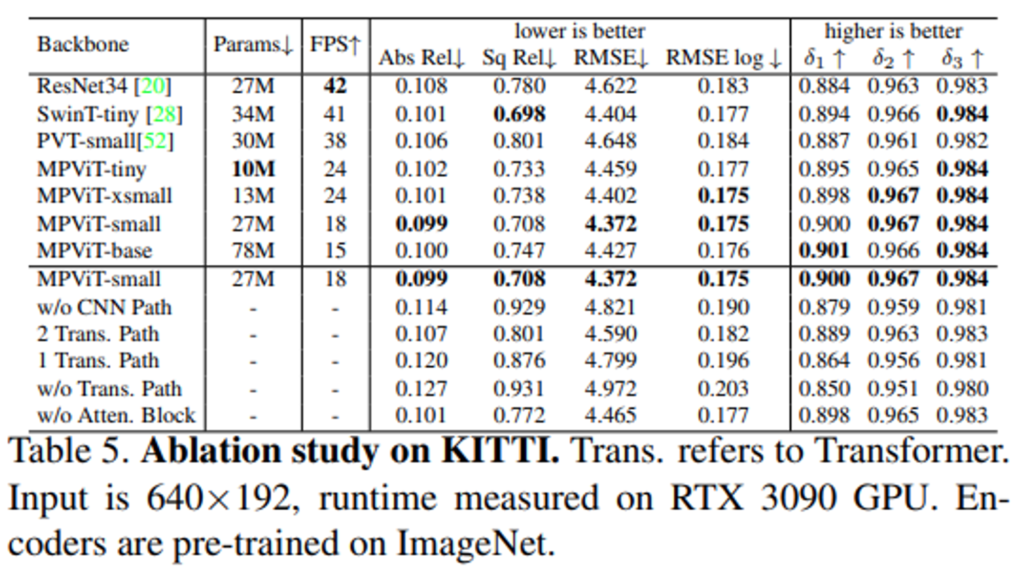
먼저 다른 backborn의 파라미터들 대략(30M)과 유사한 ours모델인 MPViT-small을 보게 되면, 다른 backborn을 사용하는 것보다 성능 면에서 가장 우수한 것을 확인 할 수 있습니다. 그러나 18FPS로 inference속도가 좀 느린 것을 확인할 수 있습니다. depth estimation task를 자율주행 상황처럼 실시간성이 보장되어야 하는 상황에서는 메모리 상황이 허락된다면 SwinT-tiny를 사용하는 것이 적절해 보입니다.
그리고 아래 표는 Figure 4의 MonoViT에 적용되는 각 모듈에 대한 ablation study 결과인데요. decoder부분의 Atten. Block과 Encoder 부분의 CNN. Path, Transformer.Path 적용 여부에 관한 실험입니다. 위의 표처럼 저자가 제안하는 모듈을 모두 사용한 것이 가장 좋은 성능을 보이는 것을 확인 할 수 있습니다.
4. Conclusion
이번 리뷰에는 Self-supervised Monodepth Estimation Task에 ViT를 적용한 논문이었는데요.
기존 SoTA들과의 사실상 유의미한 차이점이 ViT의 self-attention을 사용하였다는 점인데요.
ViT에 대한 background가 부족하여 읽는 데 고생을 좀 하였지만 그래도 해당 논문을 통해서 CNN의 conv연산과 ViT의 attention연산의 차이와 장단점에 대해서 명확하게 이해할 수 있었던 것 같습니다.
또한 결국에 주어진 테스크를 잘하기 위해선 backborn상에서 좋은 특징들을 뽑아야 한다는 점과 그런 관점에서 CNN과 ViT를 같이 사용하여 상호 보완적인 관계를 구성할 수 있다는 점이 흥미로운 소재였습니다.
읽어주셔서 감사합니다.
안녕하세요 현석님, 좋은리뷰 감사합니다.
depth 분야에 드디어 ViT가 들어간 논문을 읽게 되다니,, 저도 읽어야하는 논문인지라 상당히 난이도가 높게 느껴지는데요, 하지만 현석님이 고생하시며 읽으신 덕분에 정리를 굉장히 잘 해주셔서 추후 본 논문으로 읽어볼 때 더 이해가 잘 될 것 같습니다!
궁금한 점이 있습니다!
Joint CNN & Trasnformer Layer 에 대한 설명에서
1. 모듈의 인풋으로 들어온 feature map에 대해서 3×3, 5×5, 7×7 세 종류의 receptive field를 갖는 conv 연산을 통해 서로 다른 3종류의 visual token으로 임베딩되고, 그 다음 3개의 transformer block 과 1개의 convolultion block으로 들어가서 feature를 뽑게 되는데, 이 때 두 갈래로 분기되는 data-flow가 3×3 feature map인 이유가 무엇인가요? 해당 워딩이 우선 3×3 conv 연산을 통해 나온 feature map이란 뜻이 맞나요? 그렇다면 3×3 feature map인 이유는 5×5나 7×7 로 conv태워서 나온 visual token 보다 3×3 이 덜 semantic & 더 spatial-wise한 local 정보를 가지게 되고, 여기에 더해 transformer block의 경우 전역 특징에 대한 정보를 가지게끔 설계하기 위함으로 이해하면 될까요?
2. 추가로, Factorized MHSA의 Factorized 방식이 왜 일반적인 self-attention 방식보다 더 효율적인지 궁금합니다!