안녕하세요, 서른다섯 번째 X-Review입니다. 이번 논문은 2020년도 ECCV에 게재된 Shape Adaptor: A Learnable Resizing Module입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
딥러닝 성능은 네트워크 구조에 굉장히 민감합니다. 이 때문에 성능을 높이기 위해 아키텍처와 하이퍼파라미터의 튜닝이 많이 요구되고 있죠..
일반적으로 사람이 설계한 신경망 구조는 1) Normal layer 2) Resizing layer 두 가지의 계산적인 모듈로 구성되어 있습니다. Normal layer 같은 경우는 stride를 1로 갖는 convolution이나 identity mapping과 같이 입력 feature map의 spatial dimension(height x width)를 유지하는 것들이며, resizing layer는 이름에서도 알 수 있듯이 입력 feature map을 reshape하는 것들로 max/average 풀링이나 bilinear sampling, stride가 2인 conv 등이 있겠습니다. 본 논문에서는 신경망의 Shape은 각 layer의 feature shape의 구성으로 정의를 하고 architecture는 여러 개의 normal layer와 resizing layer를 쌓아 올린 것으로 정의하고 시작합니다.
사람이 설계한 네트워크 구조의 한계를 해결하기 위해서 NAS(Neural Architecture Search)라고 알려진 AutoML 알고리즘이 개발되어 왔었습니다. 네트워크 탐색을 자동화한 NAS가 좀 powerful한 네트워크 구조를 발견하기도 했지만,, 이런 알고리즘들은 여전히 사람이 설계한 네트워크에 크게 의존하고 있으며 layer간의 연결성만을 학습한다는 단점이 존재합니다. 자세히는 모르겠지만,,,,, NAS는 일반적으로 reshaping factor로 0.5(down sampling)과 2(up-sampling)을 선택하고, 전체 reshape layer의 개수도 수동으로 사람이 정하게 되는데 이게 layer간의 연결성만을 학습한다는 NAS의 단점을 의미하는 것 같습니다. 하지만, 저자들은 네트워크 구조를 직접적으로 최적화해야 한다는 inductive bias가 있다고 말하고 있습니다. 즉, 네트워크 shape이 최적화 과정에서 고려되어야 하는 요소라는 의미입니다.
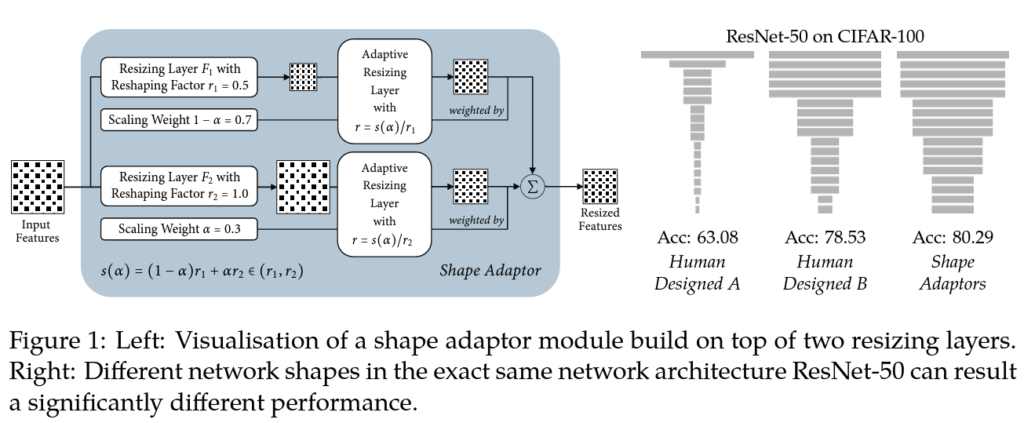
위 그림 1의 오른쪽 그림은 네트워크 구조가 완전히 동일하며 shape만 다른 3개의 네트워크입니다. 왼쪽과 가운데 네트워크의 경우 사람이 설계한 두 네트워크(resnet50)인데요, 각 네트워크 아래 쓰여져 있는 성능은 cifar100 데이터셋에 대한 성능입니다. B 네트워크는 A보다 성능이 15% 향상되었는데, B는 cifar100 데이터셋용으로 특별히 설계된 모델입니다. 이따 메소드 단에서 소개드릴 shape adaptor를 사용할 경우 성능이 더 향상된 것을 확인할 수 있습니다. 즉, 본 논문의 shape adaptor를 사용하면 네트워크 모양을 수동으로 설계하지 않고, 학습을 통해 보다 최적의 네트워크 구조를 찾을 수 있다는 의미입니다.
방금 전 언급했듯이, 저자는 task-specific한 네트워크 모양을 학습하기 위해서, 모든 신경망에 사용할 수 있는 새로운 resizing module인 shape adaptor를 제안합니다. Shape Adaptor 모듈은 fig1의 왼쪽에서 구조를 살펴볼 수 있는데요, 보시면 shape adaptor는 feature map을 입력으로 받아서 두 개의 중간 feature map으로 변환합니다. 각 변환은 resizing layer F_i(x, r_i), i=1, 2를 사용해서 수행되는데, 이때 각 resizing layer는 사전에 정의된 resizing factor r_i를 갖게 됩니다. 다시 말해서 두 resizing factor r_1, r_2가 사전에 지정이 되고, 이로 인해 Shape Adaptor 모듈의 search space가 (r_1, r_2)가 된다는 말입니다. (r_1 < r_2라 가정)
무튼 이렇게 서로 다른 resizing factor를 사용하여 중간 feature map이 생성되게 되면, 두 feature map은 가중치 α를 통해 결합하게 됩니다. 이때 결합하기 위해서는 resizing한 feature들을 동일한 spatial dimension을 갖도록 해야하는데요 이는 search space s(a) ∈ (r1, r2) 내에서 학습된 resizing factor를 통해 동일한 spatial dimension으로 변환하게 됩니다.
최종적으로 shape adaptor 모듈이 출력하는 것은 두 중간 feature map을 결합한 것입니다. 여기서 가중치 α는 task-specific한 loss와 SGD를 기반으로 학습할 수 있습니다. 결국 이 scaling 가중치 α를 최적화함으로써 네트워크 shape을 학습할 수 있게 되는것입니다.
아래에서 shape adaptor 모듈에 대해 더 자세히 살펴보도록 하겠습니다 !
2. Shape Adaptors
2.1 Formation of Shape Adaptors
Intro에서도 설명했었지만 다시 한 번 설명드리자면, Shape Adaptors 모듈은 두 resizing layer(F_i(x, r_i) i=1, 2 )로 구성된 구조를 가지고 있으며, 입력으로 들어온 feature map을 사전에 고정한 서로 다른 resizing factor를 사용하여 resizing합니다. 각 resizing layer는 max pooling이나 avg pooling, bilinear sampling 혹은 strided convolution 등과 같은 sampling layer수 있습니다. 이후, 학습 가능한 resizing factor를 가진 adaptive resizing layer가 이 중간 feature map들을 동일한 spatial dimension으로 변환한 뒤, weighted sum을 통해 결합하여 최종 output을 생성하게 됩니다.
각 shape adaptor 모듈에는 학습할 수 있는 파라미터 α가 있는데, 이 α는 0과 1 사이의 값을 갖습니다. 이 파라미터 α는 adaptive한 resizing layer G를 통해 변환된 두 중간 feature map을 최적으로 결합하는 역할을 하는데요,, 이때 파라미터 α는 단조 함수 s를 사용하여 α를 search space인 r_1, r_2사이의 값으로 매핑합니다. (단조 함수란,,, 입력 값에 따라 출력값도 일정하게 증가하거나 감소하는 함수를 일컫습니다) 이 함수 s(α)에 대해서는 아래에서 다시 언급하도록 하겠습니다. 무튼, , 이렇게 하면 shape adaptor는 r_1, r_2 사이의 다양한 scale로 resizing할 수 있게 되어서 기존에 수동으로 설계했던 네트워크 아키텍처의 단점인 고정된 scale 문제를 극복할 수 있게 됩니다.
정리하자면 shape adaptor 모듈은 입력 feature map x와 학습 가능한 파라미터 α, 그리고 두 resizing factor r_1, r_2를 사용하여 두 가지의 서로 다른 크기의 중간 feature map을 생성해내고 이 두 feature map을 결합해서 output으로 내뱉는 역할을 하는 모듈입니다. 이 모듈은 아래와 같은 식으로 표현할 수 있습니다.
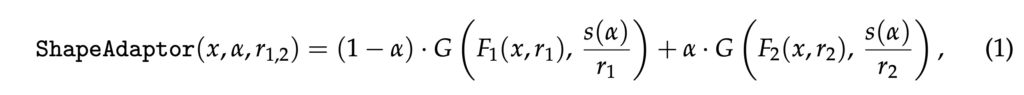
여기서 G는 중간 feature map들을 동일한 크기로 resizing하는 함수(bilinear interpolation)이고, s(α)는 단조함수로 아래 식 2에서 볼 수 있는 것처럼 α가 0일 때 r_1에 가까워지고, 1일 때 r_2에 가까워지는 함수입니다.
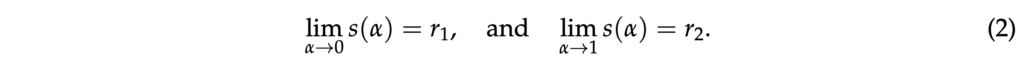
이 s(a)같은 경우 (r_2 - r_1)α + r_1 형태의 함수인데요, 보시면 convex combination 형태 즉, r_1과 r_2 사이의 가중 평균입니다. 저자가 이렇게 reshaping factor s(α)를 정의한 이유는 사전에 네트워크의 형태나 구조를 미리 알지 못하는 상황이 있을 수도 있기 때문에 이를 사전에 알지 못해도 s(a)를 통해 유연하게 shaping factor를 조절하기 위해서입니다.
Shape Adaptor 모듈은 두 개의 resizing layer로 구성이 되는데요, 하나는 입력 feature map의 spatial dimension을 유지하는 identity layer와 다른 하나는 spatial dimension을 변경하는 layer입니다. 그래서 VGG나 ResNet같은 네트워크에 쉽게 붙일 수 있습니다.
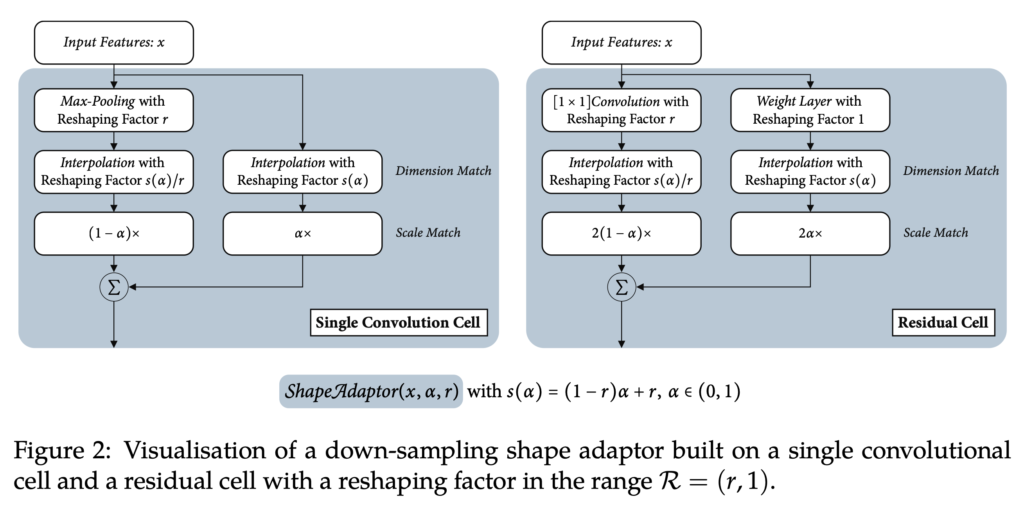
위 Fig2에서는 VGG와 ResNet같은 신경망에 Shape Adaptor 모듈을 적용하는 방법을 보여주는 그림입니다. 예를 들어 VGG-style의 네트워크에서 단일 convolution cell에는 max pooling을 down sampling layer로 사용하고 identity layer에서는 단순히 입력을 그대로 출력하도록 했습니다. 또 ResNet-style의 네트워크에서는 shortcut 1×1 conv layer를 downsampling layer로사용하고, 여러 conv layer로 쌓인 가중체 레이어를 identity layer로 사용합니다. 또 보시면 resnet은 vgg와 달리 scale match가 2배인것을 보실 수 있는데 이는 원래 resnet 디자인과 동일한 feature map scale을 유지하기 위해 residual cell에서는 가중치를 두 배로 설정한 것입니다.
2.2 The Optimisation Recipe
Implementations of Shape Adaptors
shape adaptor를 각 layer에 넣을 때 입력 feature map의 spatial dimension인 D_{in}와 각 Shape Adaptor 모듈의 출력 차원 D(k)를 계산하는데는 local type과 global type 이 두가지가 있습니다.
먼저 local type 방식에서는 각 Shape Adaptor 모듈의 출력 차원 D(k)가 이전 layer의 출력 차원 D(k-1)과 현재 resizing factor r(k)의 곱으로 정해집니다.
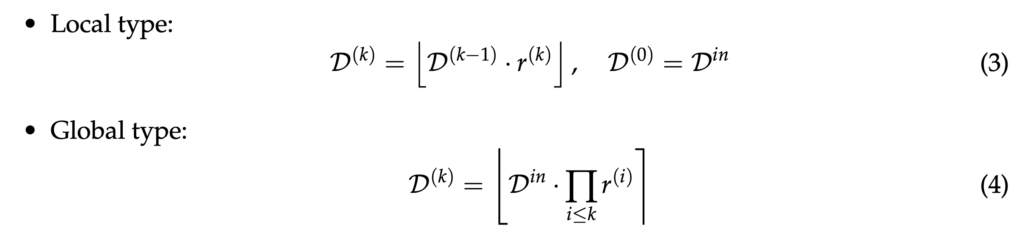
식3에서 local type의 식을 확인해볼 수 있는데요, [.]은 floor(내림)함수입니다.
또, global type의 식은 4에서 확인할 수 있으며, 이 방식에서는 입력 feature map의 spatial dimension인 D_{in}과 현재까지의 모든 resizing factor r(i)의 곱으로 계산할 수 있습니다. 식4에서 [] 함수는 round 함수입니다.
즉, local type은 각 layer 별로 독립적으로 dimension을 조정하고(전통적인 resizing layer와 동일), global type은 입력 feature map의 초기 spatial dimension과 모든 layer의 resizing factor를 고려해 전역적으로 dimension을 조정한다고 보면 되겠습니다.
global type은 많은 resizing layer를 삽입하거나, 작은 spatial dimension을 갖는 학습 데이터셋을 학습할 때 유용하게 사용할 수 있다고 하는데요, local type은 각 layer에서 최소 한 번 spatial dimension을 줄이는 반면에 global type은 spatial dimension을 유지하는 것도 가능합니다. 예를 들어서 입력 feature map 32×32 shape일 때 resizing factor=0.95로 두고 20개의 resizing layer를 사용한다면 local type은 output feature map이 6×6으로 작아지지만, global type은 11×11로 더 크게 유지됩니다.
Number of Shape Adaptors
이제 shape adaptor의 개수에 관한 설명입니다. 이론적으로는 모든 네트워크 layer에 shape Adaptor 모듈을 넣어서 최대한의 search space를 확보해야 합니다. 하지만, 실제로 실험해본 결과 일정 개수 이상의 shape adaptor모듈을 사용하게 되면 오히려 성능이 하락했다고 합니다. 따라서 저자는 적절한 모듈의 개수를 선택하는 방법을 제안하였습니다.
예를 들어, 각 shape adaptor 모듈이 입력 feature map을 (r_{min}, r_{max})로 resizing 한다고 가정할 수 있겠고, input spatial dimension D_{in}을 직접 설정한 output spatial dimension D_{lats}로 변경하기 위해서는 일련의 resizing 작업을 적용해야 합니다. 각 resizing 과정은 ~ r_{min} 만큼 크기를 조절하며, 따라서 각 모듈의 scale에 기반해 네트워크의 input, output사이의 전체 비율의 로그 함수로 최적의 모듈 수를 표현할 수있습니다.
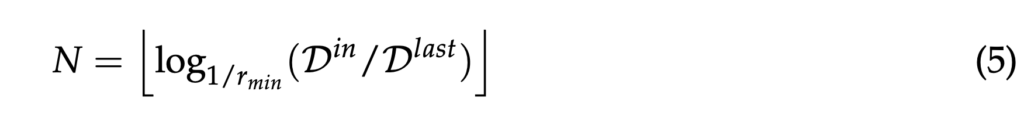
식은 위와 같은데,,, 간단히 말해 input과 output feature map의 spatial dimension 사이의 비율에 기반해 최적의 shape adaptor 모듈 개수를 계산하는 방식을 제안한 것입니다.
3. Experiments
3.1 Experimental Setup
본 논문에서는 shape adaptor의 일반화를 평가하기 위해 크기와 복잡도가 다른 7개의 image classification dataset을 사용하여 classification 성능을 평가하였습니다. 7개의 데이터셋은 다음과 같이 3가지 범주로 나뉩니다.
- small resolution dataset : cifar10,100 / svhn. [32×32]
- fine-grained classification dataset : FGVC-Aircraft, CUBS-200-2011, Stanford Cars. [224 x 224]
- ImageNet
베이스라인의 경우 VGG16, ResNet50, MoblieNetv2로 널리 사용되고 있는 네트워크를 베이스라인으로 삼았습니다. 이 세 네트워크는 다 사람이 설계한 네트워크로 각 데이터셋의 resolution에 따라 resizing layer 수를 직접 조정해줘야 했습니다.
모든 실험에서는 최적의 네트워크 구조에 대한 사전 지식이 없다고 가정하기 때문에 shape adaptor를 마지막 레이어를 제외하고 모든 layer에 균일하게 사용하였습니다.
3.2 Results on Image Classification Datasets
이제 classification에 대한 실험 결과를 보도록 하겠습니다. 먼저, 저자는 추가적인 parameter를 사용하지 않고도 shape adaptor가 사람이 설계한네트워크보다 더 나은 shape을 찾아서 성능을 향상시킬 수 있는지 확인해봤습니다. 이때 공정한 실험ㅇ르 하기 위해 사람이 설계한 네트워크와 shape adaptor 네트워크의 하이퍼파라미터는 모두 동일하며, 옵티마이저 및 스케쥴러도 다 동일하게 세팅하였습니다.
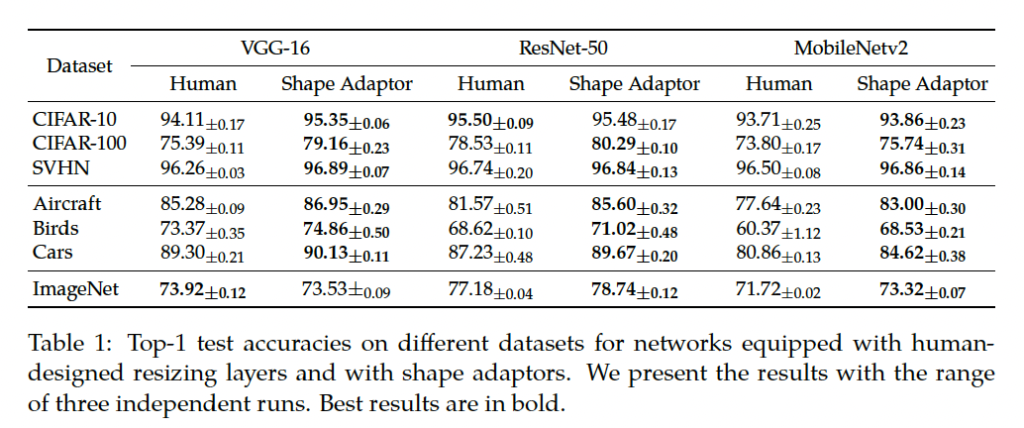
위 Table1이 이에 대한 결과인데요, 3번의 개별적인 실험을 한 후 평균낸 성능이 리포팅되어 있습니다. 보시면, 거의 모든 경우에 shape adaptor로 설계한 네트워크가 사람이 설계한 네트워크보다 더 성능이 높은 것을 확인할 수 있습니다.
3.3 Ablative Analysis & Visualisations
이제 ablation study에 대해 살펴보도록 하겠습니다.
3.3.1 Number of Space Adaptors
먼저 방금 전 classification 실험에서 사용한 모든 하이퍼파라미터를 fix하고 네트워크에 사용된 shape adaptor 개수를 바꿔가면서 실험한 성능을 살펴보도록 하겠습니다.
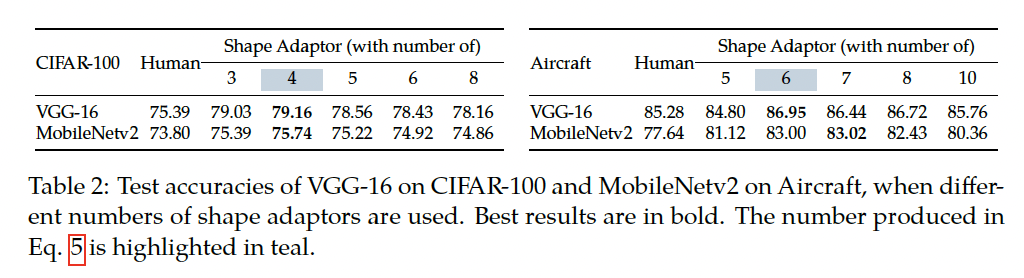
표2를 보시면, shape adaptor의 성능은 개수에 상관없이 거의 일관되게 나타났는데요, 특히 aircraft 데이터셋에서 vgg16 shape adaptor 5개를 사용한 경우를 제외하고는 모두 사람이 설계한 네트워크의 성능을 뛰어 넘은 것으로 보입니다. 이는 domain 지식이 없어도 shape adaptor가 최적의 shape을 자동으로 학습할 수 있는 능력을 보여주고 있습니다. 본문에서 최적의 shape adaptor 개수를 계산하는 식5로부터 얻은 최적의 모듈 수는 파란색으로 표시된 것인데요, 이의 성능이 가장 높은 것으로 보아 최적의 모듈 수를 계산하는 좋은 근사치임을 알 수 있습니다.
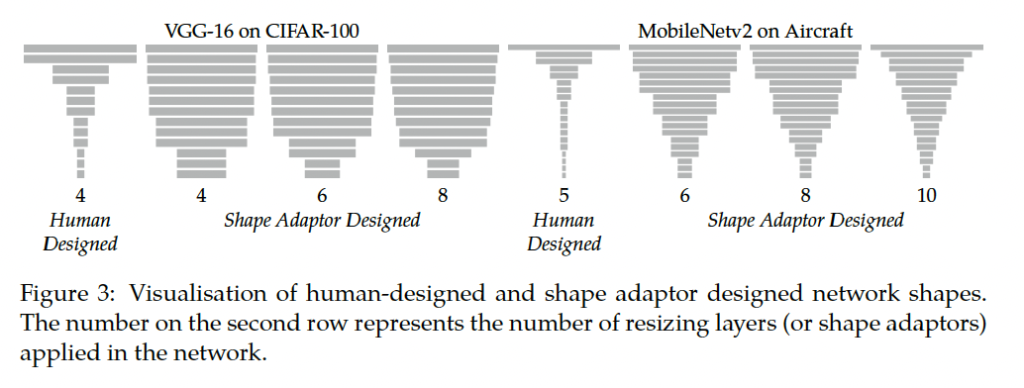
그림 3에서는 사람이 설계한 네트워크와 Shape Adaptor로 설계된 네트워크의 네트워크의 shape을 보여줍니다. Shape Adaptor에 의해 설계된 네트워크의 형태는 사용된 Shape Adaptor 모듈 수에 상관없이 유사함을 확인할 수 있네요.
3.3.2 Initialisations in Shape Adaptors
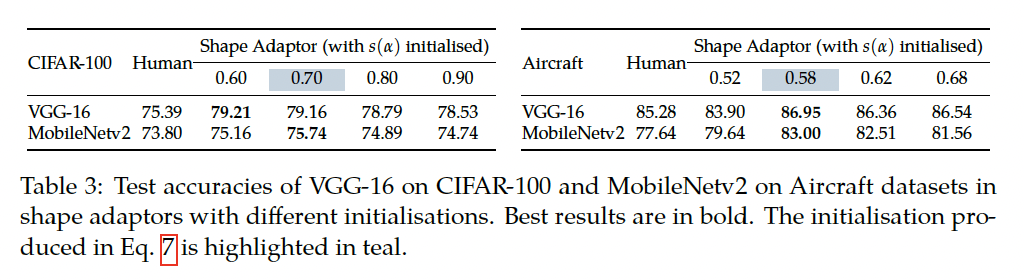
이제 a의 초기화를 어떻게 하느냐에 따른 성능 비교 실험인데요, 결국 초기화를 어떻게 하든가에도 성능이 일정하게 나오는 shape adaptor의 robust함을 평가하기 위한 실험이라고 보면 되겠습니다. 표3을 보시면 모든 shape adaptor를 사용한 네트워크 성능이 사람이 설계한 아키텍처보다 높은 것을 확인할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
이전 리뷰도 봐왔지만 윤서님이 최근에 읽고 있는 논문들의 특징이 있다면 학습을 하면 자동으로 최적의 하이퍼파라미터를 찾아주는 방법론이라는 특징이 있는거 같은데요. 사람의 개입 없이 즉, 사람이 직접 조정하는 cost를 들이지 않고 성능 향상을 하는 논문들을 주로 읽으시는거 같은데 앞으로 이런 쪽으로 연구를 진행하실 계획인가요? 리뷰를 읽다보니 개인적으로 궁금하여 질문합니다. 혹은 이러한 방법론을 모아서 정말 사람의 cost 없이도 최최최적의 성능을 내는 모델을 만드시려는 멋진 계획이 있으신지???? 궁금합니다ㅎㅎ
감사합니다.
안녕하세요. 윤서님!
좋은 리뷰 감사합니다.
리뷰를 읽던 중 두 가지 질문이 생겨서 댓글 남깁니다.
(1) Figure 1.에 저자가 제안한 shape adaptor의 구조를 보면, 처음에는 (r1, r2)라는 특정 scale factor로 reshaping을 한 후에 r이라는 adaptive한 scale factor로 한 번 더 reshaping을 해준다고 이해하였습니다.
또한, r1, r2라는 아이들는 모델이 학습을 해가는 과정에서 변화하지 않는 상수로 이해하였습니다.
그런데 잘못된 r1, r2가 설정이 된다면, 이전 layer로 부터 얻은 feature의 정보를 많이 소실시키는 결과를 내어 성능하락을 초래할 수 있다고 생각을 하였는데요. 해당 factor들을 초기값 설정에 대한 언급이나 ablation study는 없었는 지 궁금합니다.
(2) 해당 모듈이 성능에 기여하는 방식이 적당한 feature map의 spatial dimension을 reshaping factor r를 통해서 구해내는 것으로 이해하였는데요. Figure 2.에서 Max-pooling을 적용하는 방식과 1×1 conv를 적용하는 방식 모두 spatial dimension을 변화시키는 방법으로 stride를 건드는 방법이있고, 또 커널사이즈를 손보는 방법이 있을 텐데. 두 방식 중에 어떤 것을 선택하는 지에 따라서 성능 차이도 클 것으로 예상됩니다.
이런 관점에서 이 Reshaping Factor r이라는 아이는 어떤 파라미터를 건드는 것인가요?
감사합니다!
안녕하세요 ! 댓글 감사합니다.
1. 논문에서는 r1과 r2에 초기값에 대해서 최소값으로 0이상의 값을 갖도록 해야한다는 언급만 있지, 구체적인 언급이나 ablation study는 없습니답 . .
2. 각 모듈에는 learnable한 파라미터 a가 있는데요.. 이 a는 (0,1)범위의 값을 가지는데, 결국 a는 reshaping factor (r1, r2) 범위로 매핑하는데 사용하게 됩니다. 즉,,, reshaping factor r은 직접적으로 어떤 파라미터를 건든다기보다는 본질적으로 shape을 resize하는데 사용되는 factor a의 범위라고 보면 되겠습니다.
안녕하세요. 정윤서 연구원님. 좋은 리뷰 감사합니다.
제안한 방법론은 resizing layer 부분에서 최적의 resizing 크기를 학습하는 것으로 이해했는데, 그럼 downsampling / upsampling 전략을 어떻게 해야 하는지에 대한 언급도 있나요? downsampling만 해도 interpolation이나 pooling 등 방법이 있고, upsampling도 다양한 방법이 있을 것 같아 어떤 방법을 써야 하는지에 대한 분석도 있는지 궁금합니다
감사합니다!
안녕하세요. 댓글 감사합니다.
결국 feature map shape을 좀 유연하게 조정하기 위해서 resize하는데는 bilinear interpolation이 사용되게 됩니다.
안녕하세요, 좋은 리뷰 감사합니다.
다양한 adaptor들이 제안되고 있는 것 같습니다. 적절하게 resize 된 feature를 예측하도록 설계된 모듈로 이해를 했습니다.
1.. 구현에 대한 질문을 드리면, 말씀하신대로 resizing을 담당하는 layer 들이 여러가지가 있을텐데요 pooling, up/downsampling 등등 이런 layer에 제안된 adaptor 모듈을 붙이기만 하면 알아서 적절한 resizing feature를 다음 layer에 넘겨주는 건가요?
2. s(a)에 있는 a파라미터는 learnable 파라미터인 것으로 알고 있었는데 얘를 초기값에 따라 성능을 비교한 실험이 있어서 질문을 드리면, 0.5 이상으로 초기값을 주는 이유가 따로 있나요?
감사합니다.