안녕하세요, 서른 네번째 x-review 입니다. 이번 논문은 2024년도 CVPR에 게재된 SAI3D: Segment Any Instance in 3D Scenes 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
지금까지의 3D instance segmentation은 supervision으로 어노테이션에 매우 의존적이었습니다. 따라서 ScanNet이나 KITTI와 같이 현재 segmentation 라벨링이 존재하는 특정 데이터셋 내의 좁은 범위에 포함되는 물체에 국한되어 task가 진행되었습니다. 이러한 흐름은 실제로 자율주행이나 로봇 어플리케이션 관점에서의 적용이 제한적이게 되죠. 그래서 CLIP과 같은 vision-language foundation 모델(VLM)이 등장하면서 이를 기반한 방식을 통해 오픈 셋에서의 의미론적인 추론이 가능해지면서 foundation model이 3D scene을 이해하는데 어떤 도움을 줄 지에 대한 연구가 시작되었습니다. 제가 바로 이전에 리뷰한 논문 역시도 foundation model이 3D scene을 표현하는 능력에 대한 논문이었습니다. 하지만 이전 리뷰 논문에서도 보았듯이 VLM은 3D scene의 모든 물체에 대해 쉽게 사용할 수 없게 특정 프롬프트에 의존하기 때문에 3D scene을 표현하는 능력 자체는 가지고 있지만 활용 가능성이 낮습니다. 그래서 최근에는 SAM이 등장하였고 이를 활용하려는 흐름이 3D segmentation에서 나타났습니다. 대표적으로 제가 리뷰했었던 SAM3D는 SAM의 결과를 반복적으로 scene 수준까지 병합하는 프로세스를 통해 3D scene에 투영하고 있습니다. SAM3D의 결과는 ScanNet의 실제 GT 주석보다 더 세분화된 마스크를 생성할 수 있었지만, 로컬하게 인접한 프레임 간의 병합 과정을 반복하기 때문에 넓은 범위의 정보 통합이 부족했다는 한계가 있었습니다.
그래서 본 논문에서는 복잡한 3D scene에서의 instance segmentation을 위해서 기하학적인 prior와 멀티뷰 사이의 일관성을 더 잘 활용하는 방식을 분석합니다. 어노테이션이 필요한 학습이나 finetuning 없이 zero-shot 3D instance segmentation을 수행하기 위해 SAM을 활용하는 SAI3D를 제안합니다. SAI3D는 3D scene을 기하학적인 primitive로 나누고 SAM에서 생성한 마스크를 기반으로 쌍 별로 유사도를 계산하고 있습니다. 이러한 방식은 region growing이라는 알고리즘을 통해 기하학적인 primitive들을 점진적으로 합쳐서 멀티뷰에서 일관된 3D instance segmentation을 얻을 수 있게 됩니다. 이러한 SAI3D는 여러 segmentation 데이터셋에서 평가하였으며 기존 SAM3D 뿐만 아니라 open-vocaulary sementation보다 훨씬 높은 성능을 달성하였다고 하는데, 이는 실험 파트에서 살펴보도록 하겠습니다. 여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 기하학적인 prior과 SAM을 이용한 이미지 segmentation을 사용한 효율적인 zero-shot 3D instance segmentation SAI3D 제안
- 이미지 마스크를 서로 다른 뷰 사이의 일관성 있는 3D segmentation으로 합치는 통합 방식 설계
- 생성된 3D 마스크의 정확도를 검증하면서 unsupervised 3D 학습의 새로운 가능성 확인
2. Method
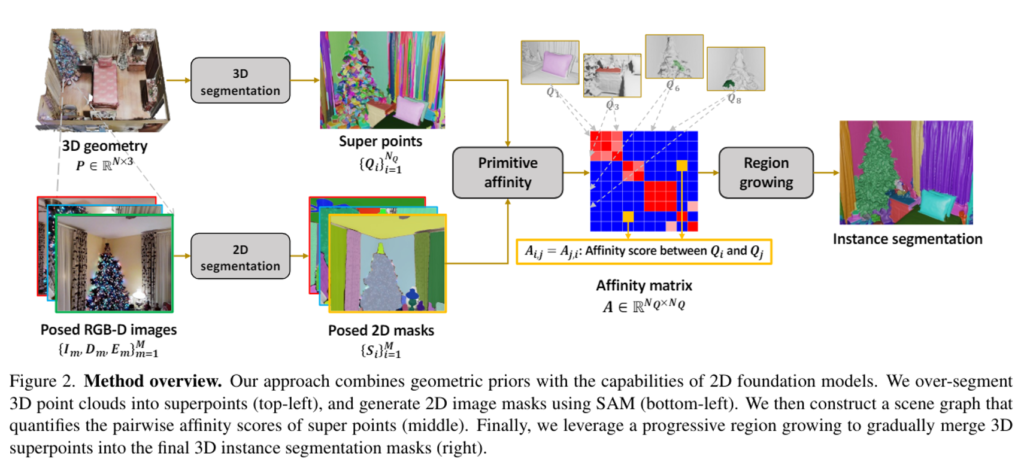
인트로에서 이야기한 것처럼 VFM(SAM)을 기반으로 zero-shot instance segmentation 프레임워크를 구축하였는데, 먼저 간단하게 입출력 형태를 살펴보고 본격적인 방법론으로 넘어가도록 하겠습니다. 입력으로는 3D scene을 표현한 포인트 클라우드 P \in \mathbb{R}^{N \times 3}와 RGB-D 이미지 \{I_m, D_m, E_m\}^M_{m=1}이 주어지는데, 여기서 I_m, D_m은 RGB 이미지와 depth map이 되며 E_m은 대응하는 카메라 외부 파라미터를 의미합니다. 이러한 입력을 받아서 해당 scene에서 다양한 물체의 instance를 나타내는 마스크 집합을 예측하는 것이 최종 목적이 되겠죠.
2.1. Scene Graph Construction
3차원 scene 수준의 포인트 클라우드를 primitive로 그룹화하고 이러한 영역을 scene 노드로 표현하였다고 합니다. 각 노드에 대해서 관련 이미지 집합과 해당 이미지 마스크를 합치는 것이죠. 인접한 노드를 연결하기 위해서 그래프 엣지를 만들고 3차원 primitive에 해당하는 두 집합의 이미지 마스크를 비교하여 계산된 primitive의 유사성을 통해서 각 엣지에 가중치를 부여한다고 합니다. 그럼 여기서 3차원 primitive가 계속 나오는데, 비슷한 기하학학적인 특성을 가진 포인트들을 3차원 primitive로 그룹화를 하는 것 입니다. 노말 기반의 그래프 컷 알고리즘을 적용하여 P를 superpoint \{Q_i\}^{N_Q}_{i=1}의 집합으로 나누게 됩니다. 포인트 레벨에서 만들어진 scene 그래프와 비교했을 때, 비정형 데이터인 3차원 포인트를 기하학적인 속성을 기반으로 한 preimitive로 변환함으로써 좀 더 효율적인 데이터 처리가 가능합니다. 이보다 더 중요한건 preimitive 사이에 계산된 affinity 점수가 각각의 포인트 간에 계산된 affinity 점수보다 더 신뢰할 수 있다는 강점이 있습니다.
이렇게 3차원 포인트에 대한 처리가 이루어지고, 멀티뷰 이미지에 대해서는 어떻게 처리될까요 ? SAM의 마스크 생성 기술을 사용해서 이미지에서 물체에 대한 마스크를 우선 얻습니다. 한 픽셀이 만약 여러 개의 마스크에 겹쳐지는 경우, 겹치지 않는 뚜렷한 단독 마스크를 얻기 위해서 예측된 IoU가 가장 높은 마스크만 사용합니다. Fig.2에서 보이는 것 처럼 SAM의 마스크는 preimitive 기반 영역 확장을 통해 scene에 통합됩니다.
2.2. Preimitive Affinity
두 3차원 primitive Q_i, Q_j가 있을 때 두 primitive 사이의 affinity 점수 A_{i,j}는 동일한 물체 instance에 속할 가능성이 얼마나 높은지를 계산하는 것 입니다. 이 affinity 점수는 사영된 3차원 primitive가 차지하는 마스크의 영역을 비교하여 계산하게 됩니다. 이러한 계산 결과는 인접성 행렬 A \in \mathbb{R}^{N_Q \times N_Q}가 만들어지고 affinity 점수가 높은 primitive끼리 병합하는데 사용하는 것 입니다. 여기서 먼저 premitive를 사영하는 것은 핀홀 카메라 행렬을 통해 계산되며 i번째 3차원 premitive Q_i는 주어진 카메라 외부 파라미터, 즉 포즈 E_m를 통해 m번째 이미지에 대한 projection을 얻게 되죠.
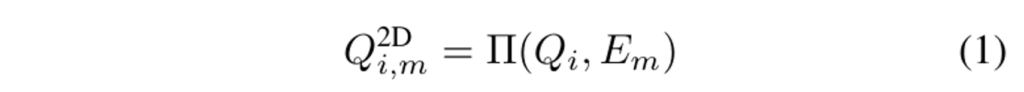
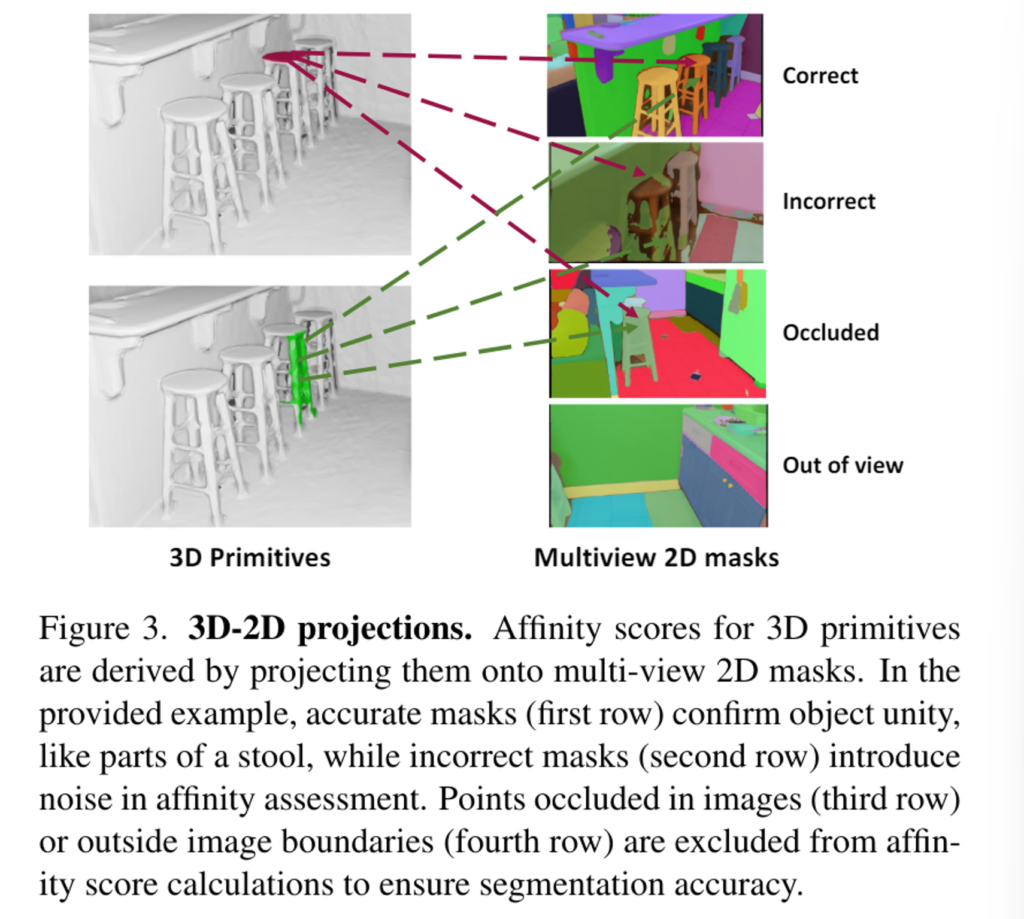
Fig.3을 보면 사영된 3차원 primitive는 이미지에서 부분적으로 보이거나 완전히 가려질 수도 있는데, 사영된 primitive의 가시성은 이미지에서 보이는 3차원 포인트의 비율로 계산합니다. 각 primitive에 대해서 만약 가시성이 0이면 주어진 primitive가 포함되지 않은 다은 scene일 가능성이 높기 때문에 해당 이미지는 삭제하고 나머지 가시성이 조금이라도 있는 이미지는 유효한 이미지로 유지하게 됩니다.
이제 affinity 점수를 계산해야 하겠죠 ? 사영된 primitive Q^{2D}_{i,m}에 포함되는 마스크 라벨과 그 마스크 라벨의 정규화된 히스토그램을 벡터로 계산하여 h_{i,m}으로 나타냅니다. 즉 이 히스토그램은 사영된 primitive에 해당하는 2D instance 마스크 라벨의 분포를 나타내는 것 입니다. 다시 Fig.3을 보면 하나의 사영된 primitive는 서로 다른 색깔로 표현되는 여러 개의 마스크 라벨을 가질 수 있습니다. 하나의 view에 사영된 서로 다른 primitive 사이의 affinity 점수를 계산하기 위해 식(2)과 같이 두 히스토그램 벡터 사이의 코사인 유사도를 계산하게 됩니다.
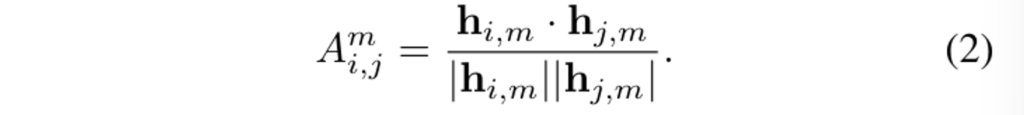
이렇게 하나의 이미지에서 서로 다른 premitive 사이의 유사도는 식(2)와 같이 계산하는데, 결국 scene 레벨로 합치려면 다른 뷰에 대해서도 affinity 점수를 계산할 수 있어야겠죠.
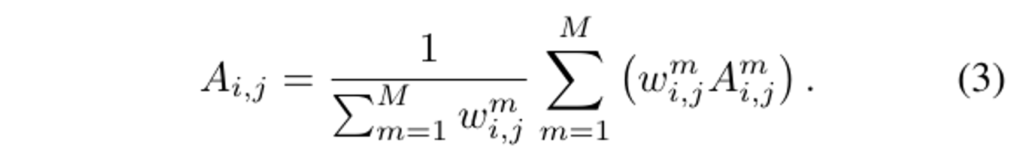
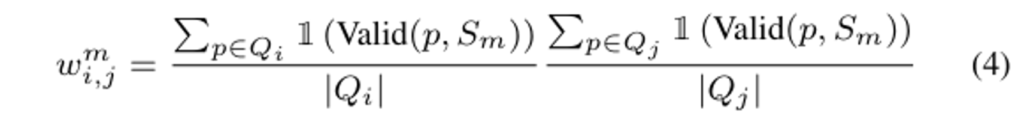
뷰에 따라서 affinity 점수 A^m_{i,j}는 달라질 수 있는데, 각 affinity 점수들을 어떤 후보로 삼고 voting 방식을 사용해서 이들을 합쳐서 뷰 간의 일관성을 유지하고자 합니다. 식(3)을 통해서 보면, 각 후보 A^m_{i,j}에 대한 가중치를 계산하고나서 가중치 합을 사용하여 최종적인 affinity 점수를 얻을 수 있습니다. 여기서 가중치 w^m_{i,j}는 식(4)와 같이 Q^{2D}_{i,m}, Q^{2D}_{j,m}의 가시성의 곱으로 계산되며 그러한 가시성에 대한 판단은 Valid()는 사영된 포인트 p가 2D 마스크에 보이는 지 여부를 나타냅니다. 두 개의 premitive 중에서 하나가 보이지 않아서 유효하지 않은 이미지라면 w^m_{i,j} = 0으로 간주합니다.
2.3. Primitive Merging
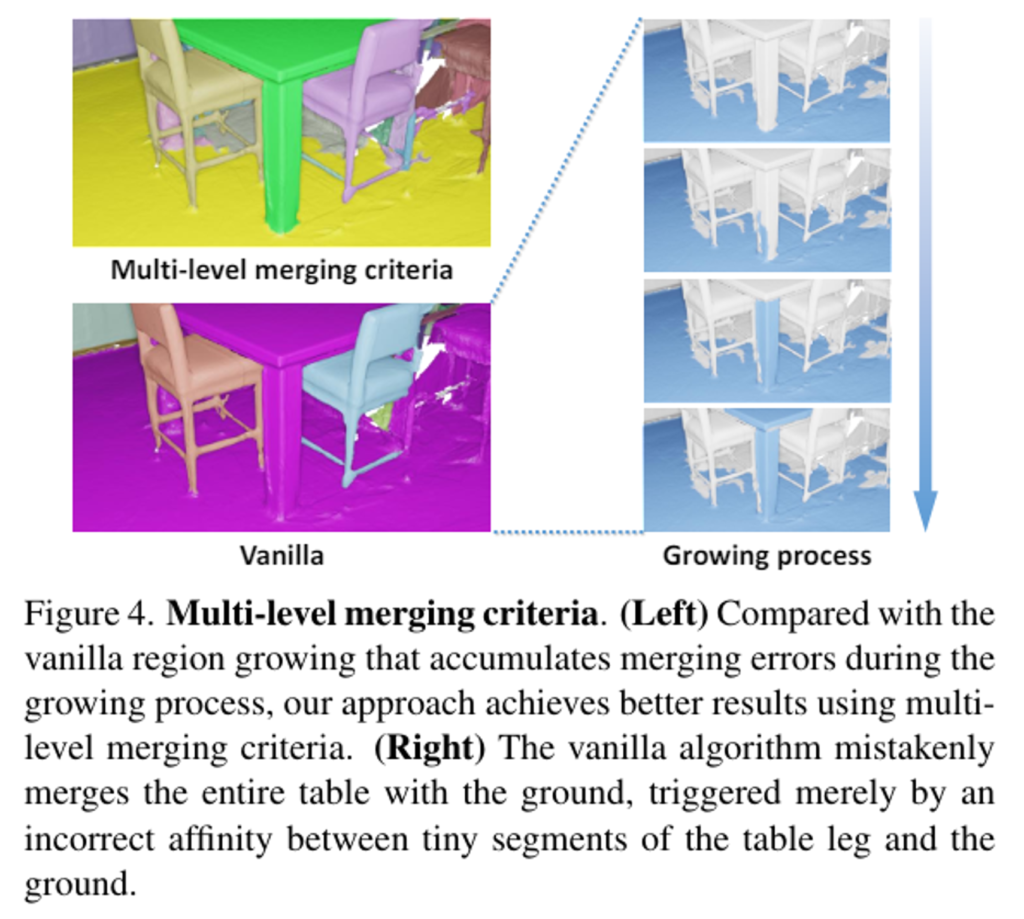
scene grpah와 위에서 계산한 affinity 행렬을 기반으로 affinity 점수가 큰 3D premitive를 중심으로 점차적으로 병합하는 영역 확장 알고리즘을 사용하여 최종적인 3D instance 마스크를 얻습니다. 먼저 Fig.4에서 기본(Vanilla) 영역 확장 알고리즘을 먼저 보면 바닥 노드와 높은 affinity 점수를 공유하는 테이블 다리 노드가 영역에 추가되는데, 이러한 쌍 별 비교는 영역을 확장하는 과정에서 오류로 누적되기 쉽습니다. 이러한 문제를 해결하기 위해 후보 노드와 영역 내의 모든 노드 간의 affinity 점수를 그래프 거리에 따라서 가중치를 부여하여 합치는 멀티 레벨의 병합 기준을 제시합니다. 또 하나 이렇게 영역을 확장할 때 중요하게 여겨지는 하이퍼 파라미터는 두 영역의 병합 여부를 결정하는 affinity 임계값 입니다.
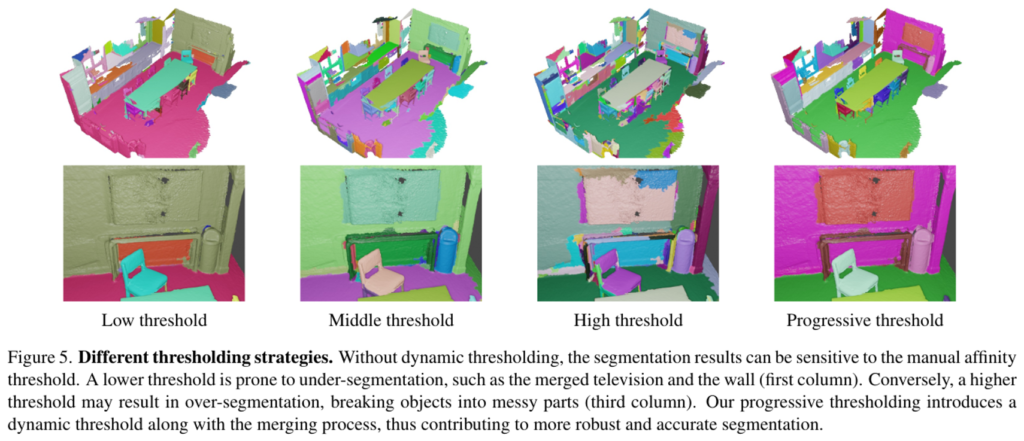
ig.5와 같이 영역 확장 과정은 임계값에 민감하게 반응하여 고정된 임계값을 설정하면 과하게 segmentation되거나 또는 segmentation이 잘 되지 않는 결과가 나타납니다. 이러한 경향을 바탕으로 점진적인 확장 알고리즘을 제안하는 것이죠. 이 점진적 확장 알고리즘은 확장 과정을 임계값이 높은 단계부터 낮은 단계까지 여러 단계로 나누는 것을 의미합니다. 이렇게 처음엔 높은 기준으로 작은 영역을 합쳐서 잘못된 병합이 누적되는 것을 방지하면서 영역이 점차 신뢰할 수 있을만 만큼 큰 영역으로 확장이 되면 초기보다 낮은 기준을 사용해서 병합하게 됩니다. 이렇게 동적인 임계값은 확장 과정이 진행되면서 확실한 노드들끼리 연결되는지에 민감하게 반응할 수 있기 때문에 최종 segmentation 결과의 정화도를 향상시킬 수 습니다.
3. Experiments
3.1. Experiment Setup
데이터셋은 ScanNet++, ScanNetV2, ScanNet200, 그리고 Matterport3D을 사용하여 실험을 진행하였습니다. 비교할 베이스라인은 closed-vocabulary와 open-vocabulary로 나누어서 비교합니다. Mask3D는 supervision 방식의 트랜스포머 기반 SOTA 방법론이라고 합니다. open-vocabulary 방식의 경우 최근 SAM3D와 UnScene3D, 그리고 OVIR3D와 비교하고 있습니다. 특히 SAM3D는 SAM의 마스크 생성을 기반으로 한다는 점에 있어서 본 논문의 방법론과 유사하면서도 2D 마스크를 병합하는 과정에 차이가 존재하기에 유의미한 비교가 가능합니다.
3.2. Results
Fine-grained 3D segmentation
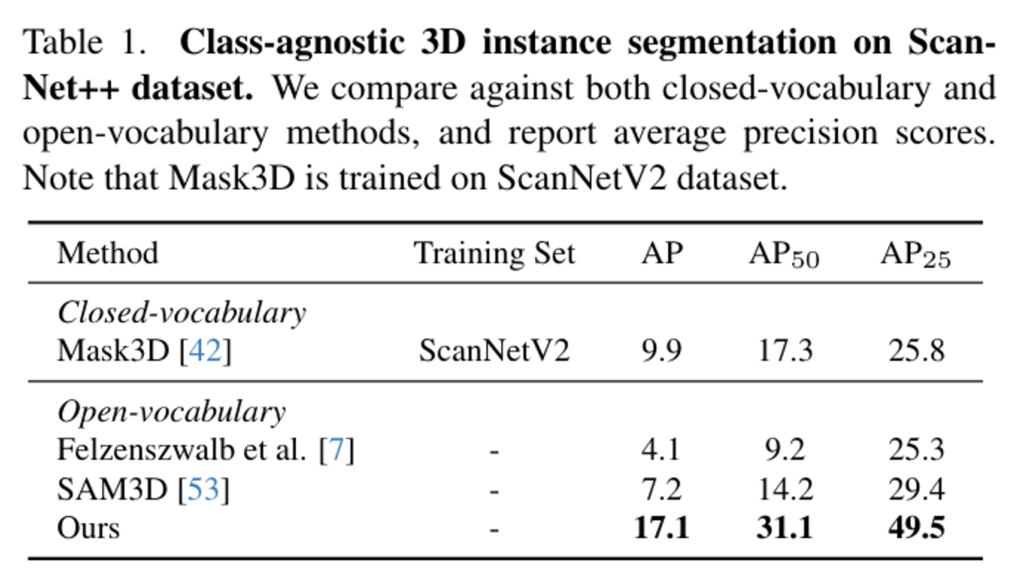

먼저 Tab.1은 ScanNet++ 데이터셋에서 class-agnostic한 instance segmentation 결과를 나타냅니다. 결과적으로 모든 평가 지표에서 이전의 방법론 대비 높은 성능을 달성하였고, unsupervised 방식 뿐만 아니라 ScanNetV2에서 closed-vocabulary 베이스라인인 Mask3D 보다 더 좋은 결과를 보여주고 있스빈다. 이러한 결과는 세부적인 물체와 다양한 의미론적인 카테고리를 더 효과적으로 처리하고 있는 것을 강조하고 있습니다. Fig.6의 정성적 결과를 보면 작은 크기의 물체에서 깔끔한 segmentation 마스크를 생성하고 복잡한 scene에서 맣ㄴ은 물체를 정확하게 분리할 수 있습니다. 예를 들어 이전 방법론들에서는 캐비닛에 보관된 여러 물건들을 하나의 인스턴스로 그룹화하는 방면, 본 논문의 방법론은 캐비닛에 보관된 여러 품목을 세분화시킬 수 있었습니다.
Standard 3D segmentation
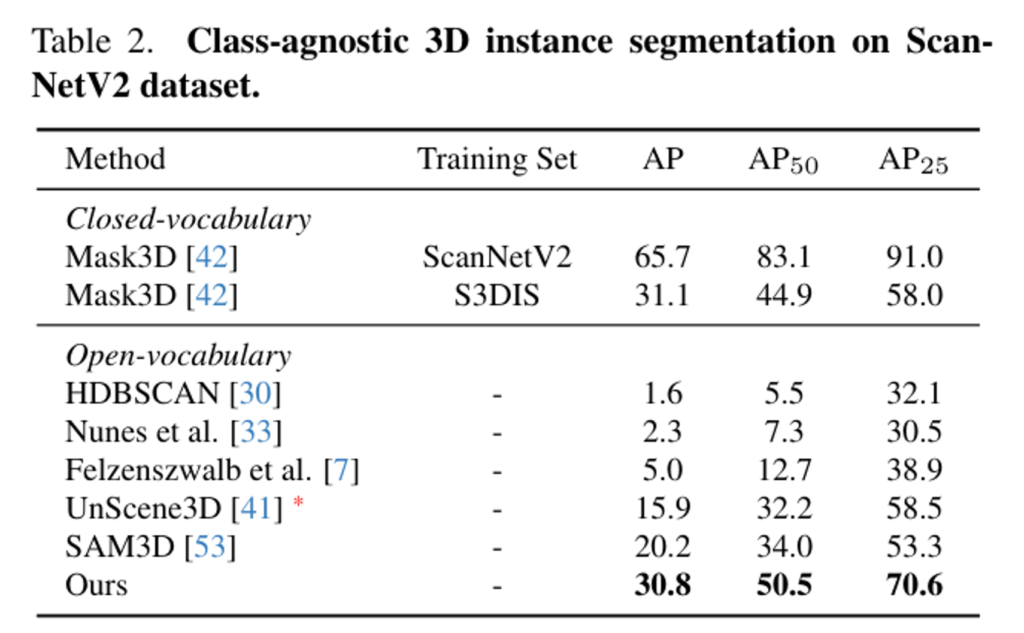
Tab.2는 ScanNetV2 데이터셋엣 class-agnostic instance segmentation 결과를 리포팅한 결과 입니다. 본 논문의 방법론은 어노테이션에 의존하는 supervision이나 finetuning 필요 없는 open vocabulary 베이스라인보다 훨씬 높은 성능을 보여줍니다. supervision 방식인 Mask3D는 다른 데이터셋에서 학습할 때 성능이 떨어지는 반면, 이는 supervision 방식이 학습 데이터를 과도하게 맞추게 되고 open scene에 대한 일반화 능력이 부족하다는 것을 의미합니다.
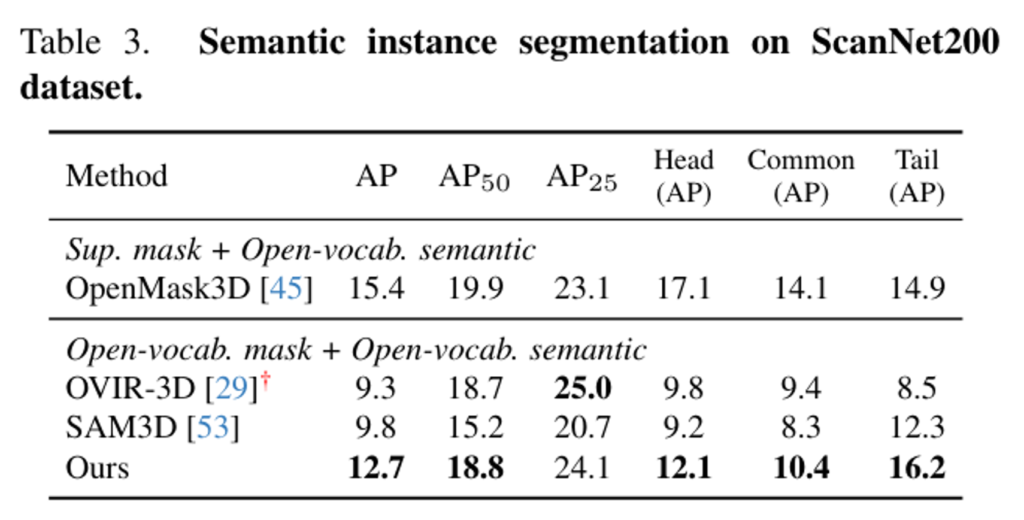
다음 Tab.3은 semantic instance segmentation을 ScanNet200 데이터셋에서 평가한 결과 입니다. 본 논문의 방법론은 semantic 라벨을 할당하기 위해 OpenMask3D의 파이프라인을 사용하였고, 그 결과 open-vocabulary 베이스라인보다는 높은 성능을 보이지만 supervision 마스크에 의존하는 OpenMask3D보다는 부족한 성능을 보입니다. 이러한 결과를 통해 zero-shot에서 본 논문의 방법론이 더 다양하고 덜 일반적인 라벨의 물체에 대해서도 더 잘 처리하고 있다고 분석할 수 있습니다.
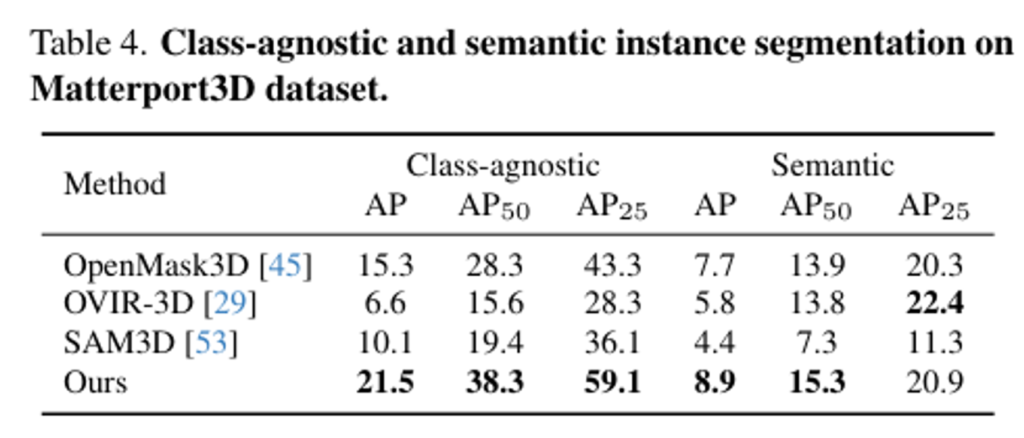
scene에 대한 일반화의 가능성을 더 평가하기 위해서 class-agnostic 및 semantic instance semgmentation 두 task에 대해 Matterport3D 데이터셋에서 실험한 결과가 Tab.4 입니다. zero-shot 방식은 다른 베이스라인 방법론들보다 일관되게 좋은 성능을 유지하는 반면, OpenMask3D는 ScanNet200 데이터셋에서 학습되었기 때문에 성능이 하락하는 것을 확인할 수 있습니다.
3.3. Ablation and Analysis
Effect of our desings on the region growing algorithm

이제 논문이 제안하는 방식들에 대한 ablation study를 살펴보도록 하겠습니다. 크게 3D primitive, 멀티 레벨의 병합 기준, 그리고 영역 확장이 성능에 미치는 영향을 확인하였다고 합니다. 3D primitive를 사용하지 않고 기존의 포인트 단위의 영역 확장 방식을 사용하면 성능이 눈에 띄게 하락하는 것을 확인할 수 있습니다. 멀티 레벨의 병합 기준과 영역 확장 알고리즘은 3D primitive를 사용한 상태에서 추가하였을 때 각각 성능 향상에 기여하고 있으며 세 방식을 모두 합쳤을 때 원래 기본 버전의 알고리즘에 비해 성능이 무려 약 50% 향상되며 본 논문이 설계한 알고리즘들이 효과적이라는 것을 강조하고 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
파운데이션 모델을 활용한 3D 관련 task에서도 활발하게 연구가 되고 있네요.
질문 몇가지만 남기겠습니다.
1. 제가 앞의 설명을 놓쳐서 질문을 드리면, 모델의 입력으로는 포인트 클라우드만 들어가고 RGB-D는 해당 포인트 클라우드로부터 특정 뷰포인트에 대해 RGB와 depth를 같이 추출을 하는 것으로 이해를 했는데, 맞나요?
만약 맞다면, SAM은 2D 이미지 상에서 SAM을 적용하는 것은 가능하겠지만 3D segmentation 과정에는 SAM을 적용한 것이 아니라, 기존의 3D segmentation 방법론을 적용하여 그림(2)에 있는 슈퍼포인트의 그림과 같이 instance segmentation이 되었다고 보면 되는 건가요?
2. scene graph construction을 하는 과정 중에 계속 강조하는 primitive affinity를 고려해야 좀 더 신뢰도 높은 그룹화가 가능하다고 이해를 하였는데, 그럼, 여기서 사용하는 멀티뷰 이미지는 몇장을 사용하여 primitive affinity를 계산하는 건지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 넵 우선 RGB-D는 realsense와 같이 RGBD 센서를 사용해서 획득합니다. 말씀하신거처럼 2D branch에서는 기존의 SAM 모델을 사용하는 것이 맞고, 3D branch에서는 슈퍼 포인트를 통해 우선적으로 segmentation 하게 됩니다.
2. 여기서 멀티뷰라고 이야기하긴 했지만 실질적으로는 싱글뷰와의 차이를 나타내기 위해 멀티뷰라고 이야기한 것 같고, affinity가 계산되는 대상은 서로 다른 두 이미지에서 계산됩니다.
감사합니다.