안녕하세요,
이번에는 Amazon에서 제안한 instance-level 6D pose estimation 논문을 읽어보았습니다.
최근 큰 기업들이 6D와 관련된 분야에 관심을 많이 보이는 것 같습니다. 이번 논문은 단일 RGB 기반의 방법론으로, 아키텍처가 직관적이라 읽는 데에 무리가 없을 것으로 보입니다.
리뷰 시작하겠습니다.
Introduction
단일 RGB 이미지에서 카메라를 기준으로 3차원 물체에 대한 pose(rotation, translation)를 추정하는 것은 로봇 공학, 자율 주행, 증강 현실을 비롯한 많은 컴퓨터 비전 애플리케이션에서 근본적인 문제로 볼 수 있는데요. 실제 물체의 복잡한 모양과 조명, 표면 색상, 배경 흐림, 물체 대칭 및 폐색으로 인한 물체 모양의 다양성이 존재하기 때문에 까다로운 과정으로 볼 수 있습니다.
이러한 문제를 해결하기 위한 일반적인 솔루션은 딥러닝 모델을 이용하여 이미지에서 물체의 pose를 direct regression 하는 것이 있겠네요. 또는 discrete bucket(pose sampling)의 관점에서 pose를 예측하는 classification의 문제로 문제를 구성할 수도 있습니다. MRC-Net은 앞선 두 가지를 결합하여 coarse한 pose를 의미하는 class를 예측한 다음, 해당 class로부터 residual pose를 regression하는 선행 연구에 대한 영감을 받아 선행 연구에서 사용되는 residual regression은 classfication error를 어느 정도 줄이는 데 어느정도 영향이 있었으나, 특히 물체에 대한 텍스처가 부족하거나 occlusion이 심한 경우는 성능이 급격하게 떨어지는 현상을 보였다고 하네요.
저자는 해당 문제가 발생하는 이유는 classification과 regression을 high-level feature를 parallel하게 수행하기 때문에 발생하는 문제라고 합니다. 이러한 구조를 가지는 경우regression이 classification 과정에서 관련된 어떤 정보를 볼 수 없기 때문이라고도 볼 수 있겠네요. 자세한 내용은 method에서 다루어 보겠습니다.
이번 논문의 contribution은 다음과 같습니다.
- 3D CAD 모델 기반의 단일 RGB 방법론인 MRC-Net을 제안하여 (soft label-based)classification + regression을 수행하여 pose를 추정
- Multi-scale Resiudal Correlation(MRC)로부터 입력 이미지와 렌더링(합성)된 이미지 간의 상관관계를 암시적으로 파악할 수 있으며 이는 end-to-end 학습이 가능하므로 이러한 상관관계 feature들에 대한 구별력이 향상됨
- BOP challenge 벤치마크 데이터셋에서 SOTA 달성
Method
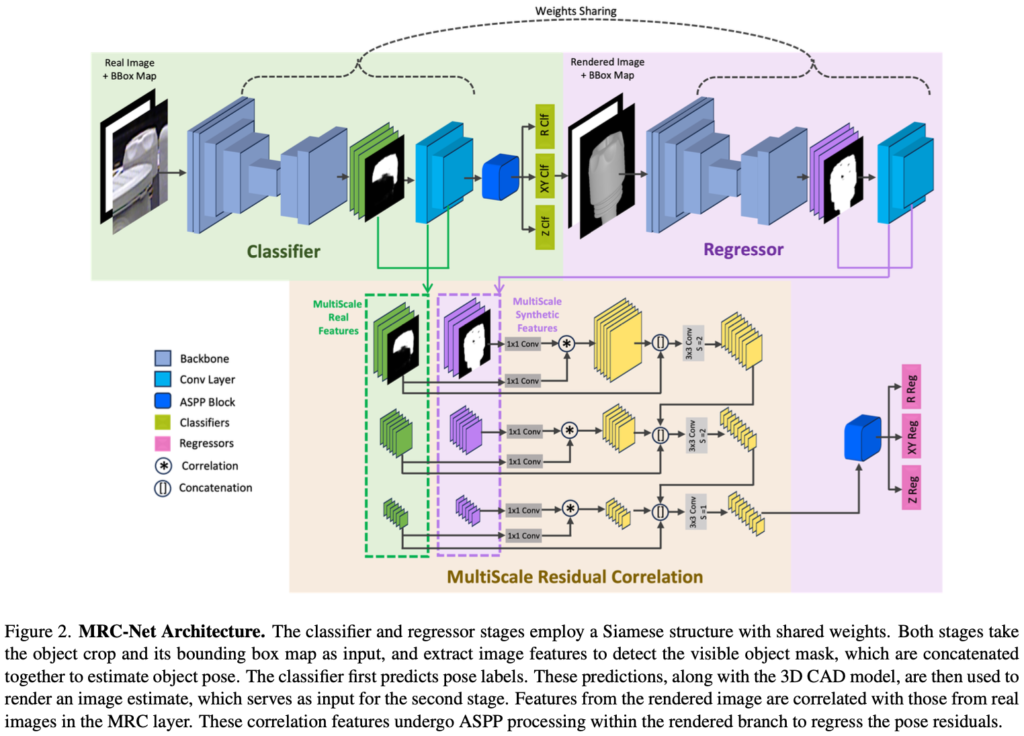
이번 MRC-Net의 전체적인 아키텍처를 나타내고 있는 그림(2)입니다. 먼저, 이미지 내 주어진 3D CAD 모델과 동일한 물체 영역을 검출하는 단계가 우선적으로 진행됩니다. 검출기는 Mask RCNN을 사용하여 물체를 찾고 해당 영역에 대한 crop된 마스크 이미지를 입력으로 받아 아키텍처의 입력으로 들어가게 됩니다.
Classifier와 regression 과정에서는 동일한 ResNet34-UNet 구조의 weight sharing 하는 구조로 구성되어 있으며 로컬한 영역과 글로벌한 영역의 특징을 활용하기 위해 ASPP(Atrous Spatial Pyramid Pooling) 모듈을 적용하였다고 하네요.
MultiScale Residual Correlation(MRC)
MRC는 입력으로 들어오는 앞단(classifier)의 실제 이미지와 뒷단(regressor)의 입력으로 들어가는 렌더링된 이미지 각각의 feature volume에 대한 상관관계를 3가지 scale로 구성된 구조로 계산이 진행됩니다. 이때 상관관계가 있다고 판단된 feature는 regression head에 입력으로 들어가게 residual pose를 생성합니다. 그림(2)에서 보면 입력의 feature를 활용하는 것을 확인할 수 있는데요. 입력은 real feature, *(correlation) 연산을 이후는 correlation feature, [ \ ](concat) 이후는downsampling feature를 나타내고 있습니다. 해당 과정을 통해 Multi-scale을 가지는 상관관계와 이미지의 컨텍스트한 정보를 활용하여 regression을 하도록 디자인을 하였다고 하네요. 상관관계를 연산하기 전에 1 \times 1 conv 연산을 수행하는 것을 확인할 수 있는데, 이는 실제 이미지/렌더링(합성, synthetic) 이미지 두개의 branch 모두 가중치를 공유하기 위해 linear한 projection을 얻기 위함이라고 합니다. 상관 관계를 계산하기 위한 과정은 선행 연구[1]로부터 제안된 formula를 그대로 따른다고 하네요.
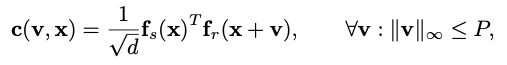
실제 이미지 feature volume \mathbf f_{r}와 합성(렌더링) 이미지 feature volme \mathbf f_{r}이 주어지면 위 식과 correlation volume \mathbf c를 정의할 수 있습니다. \mathbf x는 각 픽셀 위치, \mathbf v는 spatial sift의 정도를 나타내게 됩니다.
[1] Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. PWC-Net: Cnns for optical flow using pyramid, warping, and cost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8934–8943, 2018.
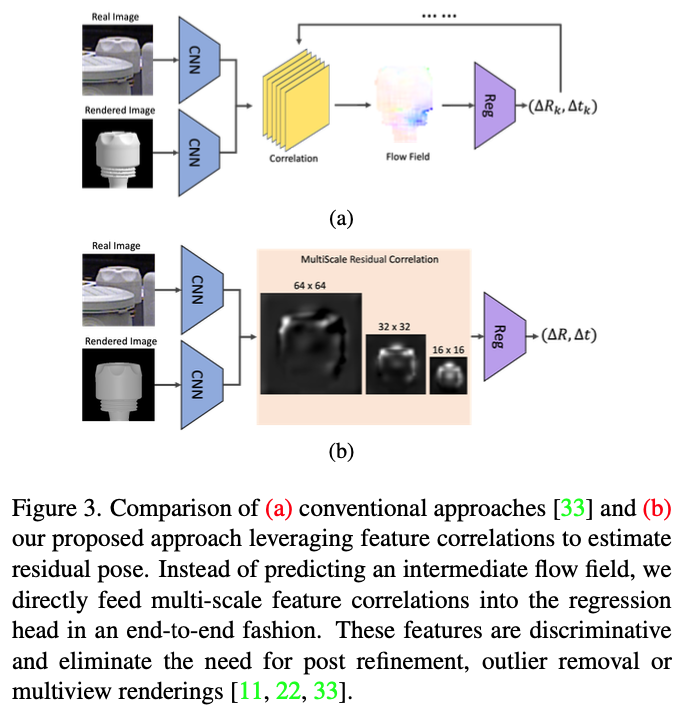
저자는 렌더링 이후의 방법을 optical flow와 MRC를 서로 비교하였는데요. flow field를 사용하는 경우 부정확하거나 중복된 correspondence를 생성시키는 현상이 발생할 수 있으므로 해당 correspondence를 반복적으로 refinement를 해줘야하는 상황이 발생하게 됩니다. 이때 기존의 방법론들은 이러한 현상에 대해 RASNAC + PnP 과정을 통해 문제를 해결하였는데요. 이는 end-to-end 과정이 아닌 알고리즘으로 문제를 해결하는 것이기 때문에 학습 가능한 MRC feature를 사용함으로써 refinement 과정을 추가/반복적으로 할 필요가 없다는 것을 강조하고 있네요. 또한 MRC 모듈 같은 경우 명시적인 visible mask를 입력으로 주어 occlusion 상황에 대한 학습을 통해 강인한 효과까지 줄 수 있을 것으로 보이네요.
Technical Details
Soft labels for classification
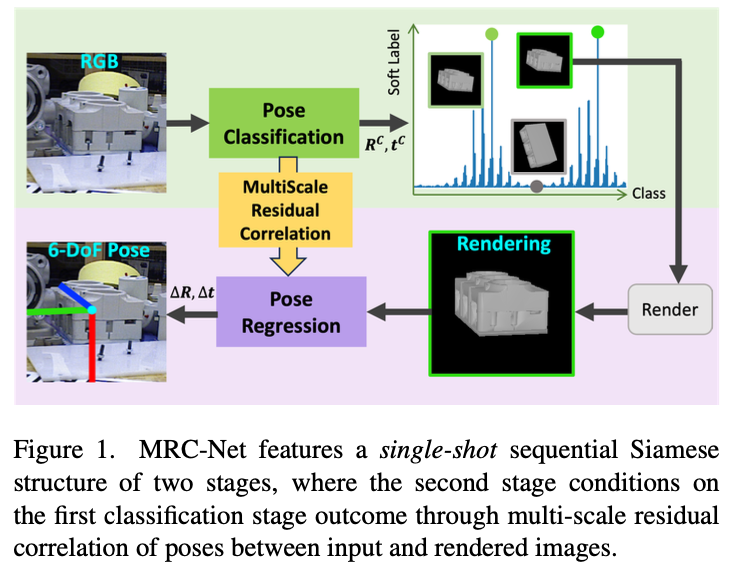
제가 이번에 읽은 MRC-Net에서의 가장 흥미로운 부분이라고 보는 부분입니다. pose(rotation, translation)를 classification 하는 것인데요. 그림(1)의 soft label 파트를 나타냅니다.
rotation에 대한 quantization을 수행하기 위해 저자는 K개의 prototype \{\mathbf R_{k}\}^{K}_{k=1}를 균일하게 생성하고, 선행 연구[2]와 동일한 방법을 적용하였다고 합니다. 이를 통해 nearest neighbor assignment가 가능하게 되었다고 합니다. K=4608개를 사용하였다고 하는데 GPU 메모리에 올라가는 가장 큰 값을 넣었다고 하네요. 마찬가지로 translation에서는 결국 scale을 고려해야 하므로 quantization을 해야합니다. translation 같은 경우 SITE(Scale-invariant Translation Estimation)[3]를 적용하여 가장 잘 정의된 translation 분포를 고려하여 진행하였다고 합니다. 이렇게 생성된 prototype을 저자는 discrete pose bucket이라고 표현을 하네요.
하지만, discrete pose bucket을 생성하는 과정 중에 rotation에 대해 문제가 발생하게 됩니다. 물체의 rotation 은 여러 prototype이 존재한다고 했을 때, SO(3) 공간(3차원 공간에서 가능한 모든 rotation을 의미)에서 특정 rotation이 여러 bucket의 decision boundary에 위치를 하게 된다고 했을 때, 해당 rotation은 어느 bucket에 속하는지 모르는 모호한 상황(uncertainty)이 발생하게 됩니다. 이런 모호함은 이후 회전에 대한 classification에 어려움을 줄 수 있겠네요. 또한 물체에 대한 대칭성도 동일한 현상을 발생시키게 됩니다.
저자는 이러한 문제를 해결하기 위해 classification 과정 중에 soft label을 적용하게 되는데요. 이를 통해 pose error metric을 기반으로 물체가 각 viewpoint에 대한 bucket에 속하는지 여부를 먼저 판단하는 binary 형태로 모델링을 합니다.
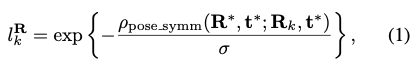
GT pose R^{<em>}, t^{</em>}가 주어지면 rotation에 대한 label은 식(1)과 같이 정의할 수 있습니다. \rho_{\text {pose\<em>symm}}(R</em>{1}, t_{1}; R_{2}, t_{2})는 물체에 대한 각각의 pose (R_{1}, t_{1})와 (R_{2}, t_{2})간 symmetric-aware 거리를 측정하는 것을 나타내고, \sigma는 classification label의 가중치를 조절하는 하이퍼파라미터입니다.
[2] Anna Yershova, Swati Jain, Steven M Lavalle, and Julie C Mitchell. Generating uniform incremental grids on SO(3) using the Hopf fibration. The International Journal of Robotics Research, 29(7):801–812, 2010. [3] Zhigang Li, Gu Wang, and Xiangyang Ji. CDPN: coordinates-based disentangled pose network for real-time rgb-based 6-DoF object pose estimation. In IEEE International Conference on Computer Vision, pages 7677–7686, 2019.
Loss function
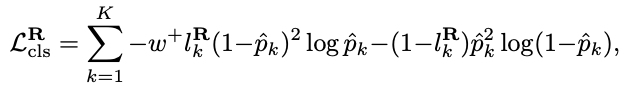
위 식은 먼저 rotation에 대한 classification을 수행하기 위한 loss function으로 focal loss를 적용하였네요. 식을 살펴보면 \hat p_{k}는 calssifier가 예측한 확률을 나타내고, l^{\mathbf R}_{k}는 식(1)을 나타냅니다. w^{+}는 가중치 파라미터를 의미하고, 100으로 고정하였다고 하네요.
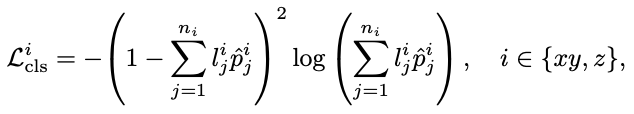
위 식은 translation에 대한 loss function입니다. 동일하게 focal loss를 적용하였으며 l^{xy}<em>{j}, l^{z}</em>{j}는 soft label, \hat p^{xy}<em>{j}, \hat p^{z}</em>{j}는 예측 확률을 의미합니다.
다음은 regression 파트입니다.
실제와 합성 간의 residual rotation \Delta R를 예측하는 과정으로, classification(coarse pose, R^{c})으로부터 얻은 pose와 함께 사용하여 refinement된 예측 pose \hat R(=\Delta RR^{c})를 얻을 수 있게 됩니다. translation도 유사하게 refinement를 하게 됩니다. \hat \tau_{i}= \tau^{c}<em>{i} + \Delta \tau</em>{i}로 나타낼 수 있습니다.
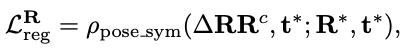
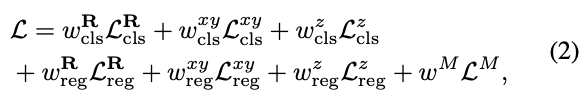
regression에 대한 loss function은 위 식과 같이 사용되며, 최종적인 전체 loss function은 식(2)로 나타낼 수 있습니다. \mathcal L^{M}은 visible mask를 의미합니다.
Perspective correction
RoI로부터 얻은 물체에 대한 검출된 영역으로부터 crop된 이미지가 입력으로 들어가게 되는데요. 이때 global context가 부족할 수 있습니다. 동일한 외관정보를 가지는 crop 이미지가 2개 있을 때 각각은 서로 다른 pose를 예측하는 상황이 발생하게 된다는 것으로 이해하시면 됩니다. 이러한 문제를 해결하기 위해 bbox로부터 얻은 정보 [\frac {b_{x}-c_{x}}{f}, \frac {b_{y}-c_{y}}{f}, \frac {b_{z}-c_{z}}{f}] 를 classifier에 추가적으로 넘겨주는 간단한 방법을 사용하여 해결할 수 있었다고 하네요.
Experiments
이번 MRC-Net은 BOP challenge의 벤치마크 데이터셋 중 T-LESS, ITODD, YCB-V, LM-O에서 평가를 진행하였다고 합니다.
Ablation study
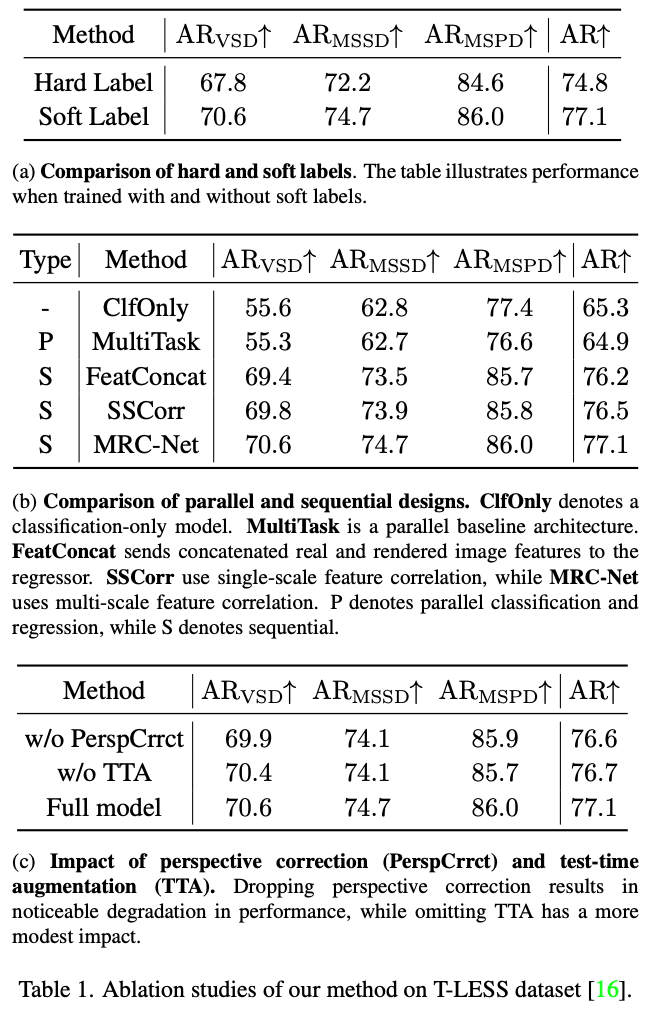
Hard label vs soft labels
표1(a)은 저자가 대칭이나 pose hypothesis로 인해 고유한 class label을 식별하기 어렵다는 상황에 처했을 때, soft label을 사용하면 보다 세밀한 representation이 가능하다는 가설을 세우고 실험을 진행을 하였다고 하네요. 이러한 효과를 검증하기 위해 soft label와 hard label을 적용하였을 때에 대한 비교를 하였으며 hard label의 경우 soft label 값이 가장 높은 고유 class의 index를 선택하도록 설계하였다고 합니다.
Classification and regression in parallel vs sequential
표1(b)는 MRC-Net의 classifer와 regressor를 연속적인 수행하는 것과 병렬적으로 수행하는 것에 대한 비교를 표에서는 Type(P, S)에 따라 나타내고 있습니다. method를 살펴보면 ClfOnly는 calssification만 수행하는 모델, Multitask는 1행을 기반으로 regression head 추가, FeatConcat은 Feature concat, SSCorr은 Signle-sclae Correlation을 각각 의미합니다. 연속적인 형태로 수행함으로써 성능이 급격하게 상승하는 양상이 보이며 성능에서 흥미로운 점은 병렬적으로 수행했을 때, 추가적인 task를 적용하여도 성능은 오히려 떨어지는 점이네요. 병렬적으로 수행하면 regression head는 classfication에 대한 정보가 없으므로 classification error를 개선할 수 있는 방법이 없기 때문이라고 볼 수 있습니다.
Perspective correction
표1(c)는 Perpective correction과 TTA의 영향에 대한 결과를 리포팅하고 있습니다.
TTA(Test Time Augmentation)는 domain gap을 줄이기 위한 domain randomization 과정으로, 예측을 수행할 때 적용합니다. 입력으로 들어가는 crop된 이미지에 대해 4가지(90, 180, 270, 360)으로 rotation시켜 독립적으로 inference를 수행하고, classification 점수가 가장 높은 것을 최종 pose 예측으로 선택하도록 했다고 합니다. 이번 논문의 메인 부분은 아니지만 TTA를 적용하여 어느정도 성능이 개선되었네요.
Comparison with State-of-the Art
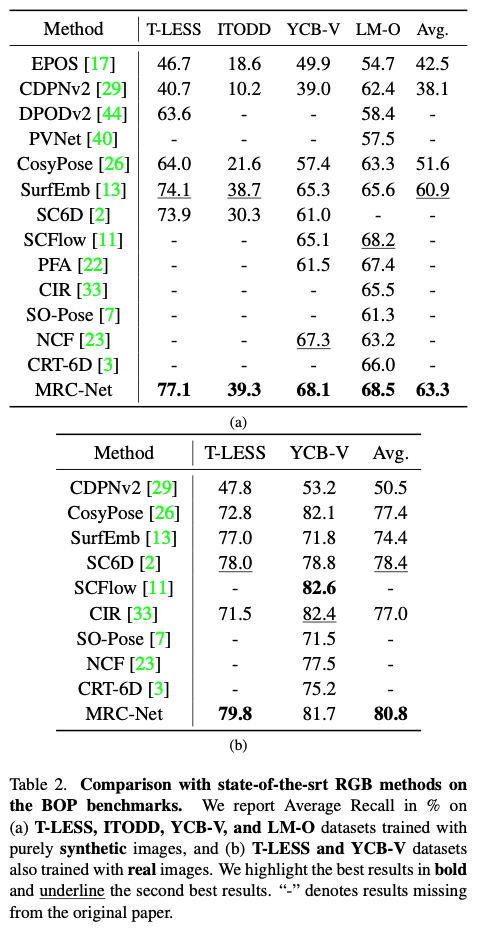
표(2)(a)는 합성 이미지를 통한 학습을 진행한 결과를 나타내고, (b)는 실제 이미지를 학습한 결과를 나타낸 결과입니다. 기존 방법론들보다 우세한 결과를 보여주고 있네요.
Conclusion & Limitation
이번에는 단일 RGB 기반의 방법론인 MRC-Net에 대해 살펴보았습니다. 2-stage로 진행되며 제안된 아키텍처로부터 MRC(Multi-scale Residual Correlation)을 volume으로부터 얻은 정보를 regression에 활용합니다. 또한, soft-labeling을 통해 coarse한 pose를 얻어 최종 refinement하는 residual로 수행하여 최종적인 6D pose에 대한 추정을 수행하게 됩니다.
저자가 말하는 한계점은 아키텍처를 보시면 렌더링에 대해 의존적인 구조라고 볼 수 있습니다. 따라서 CAD 모델이 부정확한 경우 성능이 저하가 되는 문제가 있다고 하네요.
이번 논문은 RGB만을 입력으로 사용하여 문제를 해결하였지만, 이왕 사용하는 렌더링과 함께 depth까지 고려할 수 있다면 좀 더 개선할 수 있지 않을까하는 생각이 드네요.
이상으로 논문 리뷰 마치도록 하겠습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
pose 예측을 classification 문제로 구성할 수 있다는 것은 처음 알게되었는데, 이럴 경우 발생할 수 있는 문제로 classification과 regression을 병렬적으로 수행하기 때문에 발생하고, regression이 classification 과정에서 관련된 어떤 정보도 볼 수 없기 때문이라고 말씀해주셨습니다. 제가 이런 앞선 연구의 동작 과정을 잘 몰라서일 수도 있는데 결국 본 논문의 방법론도 classification 결과로부터의 residual pose를 regression하는 흐름 자체는 동일한 것이 아닌지 .. 가장 메인으로 제시한 문제 관점에서 어떤 부분을 변경하여 문제를 해결하고자 한 것인지 잘 파악이 되지 않아 질문 드립니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
결론부터 말씀을 드리면, classification(coarse pose, 앞단)을 이용하여 regression(fine pose, 뒷단)을 수행하기 위해 앞단의 정보를 활용하는 것이 이번 논문의 핵심으로 볼 수 있습니다. 주로 regression만 direct로 수행하는 연구들은 많이 봤어도 classification을 수행하는 것은 저도 이번 논문에서 처음 봤는데요. 저자가 말하고 싶은 건 disentangle 하게 각 테스크를 수행하는 것이 아니라, 테스크를 같이 사용해야 함을 보여주는 것을 시사하는 것으로 이해하였습니다.
감사합니다.