안녕하세요 이재찬 연구원입니다. 연구실 합류 후 미숙하지만 첫 리뷰를 쓰게 되었습니다. 현재는 신입교육과정으로 신정민, 권석준 연구원님의 지도 하에서 Self-supervised monocular depth estimation 분야에 대해 학습 중이라, 그 일환으로 ECCV 2020의 FeatDepth 논문을 읽었습니다. 논문 제목만 봤을 때는 일단 feature-metric한 loss를 핵심으로 적용하여 성능 향상을 가져온 것으로 보였는데요. 본 논문의 자세한 내용은 baseline 격으로 공부했던 monodepth1, monodepth2 방법론에 대한 설명을 먼저 진행한 다음 살펴보도록 하겠습니다. 리뷰 시작하겠습니다.
Introduction
[Depth Estimation]
Depth Estimation은 이미지의 깊이, 즉, 이미지 내 물체들이 얼마나 멀리 있는지를 추정하는 태스크입니다. 이 태스크를 수행하기 위해서는 보통 multiple observation을 이용합니다. 예를 들면 저희가 urp때 배웠듯이 calibration 된 2개의 view, 즉 stereo camera를 사용하여 깊이를 추정하는 방법이 있겠습니다.
[Monocular Depth Estimation]
본 리뷰에서 다루고자 하는 monocular depth estimation는 단일 이미지만을 가지고 depth를 추정하는 방법론입니다. 기존에는 supervised learning 방식으로 단일 이미지와 GT depth를 이용해 학습하고 depth estimation을 진행했습니다. 다만, 해당 방식은 꽤 좋은 성능을 보여왔으나 문제점이 하나 있었죠. 바로 depth estimation을 regression 문제로 취급하게 되기 때문에, 방대한 양의 GT depth data가 필요하단 것이고 이는 상당한 cost가 든다는 점입니다.
[Monodepth1]
위의 GT cost 문제에 먼저 해결방안을 제시한 논문이 바로 monodepth1 이었습니다. monodepth1은 depth estimation 문제를 training 시의 image reconstruction 문제 관점으로 접근하여, self-supervised learning이 가능한 network 구조를 제안했습니다. 학습 때 GT depth가 없어도, stereo pair 이미지를 이용한 image reconstruction이 supervisory signal로 적용되는 것입니다. 이 과정을 조금만 자세히 살펴보면 다음과 같습니다.
- L 이미지가 encoder network를 타고 나와 disparity maps(L,R)를 생성합니다.
- 해당 disparity maps(L,R)를 이용하여 L,R 이미지 각각에 대한 bilinear sampling과정을 거쳐 reconstruction 이미지(L’, R’)를 만듭니다.
- 원본 이미지(L,R)와 recon 이미지(L’,R’)간의 reconstruction error를 줄이도록 학습합니다.
- (추가로) 학습과정에서 bilinear sampling을 활용하다보니, gradient locality(변환된 영역 내에서만 gradient가 집중적으로 발생하고, 변환되지 않은 영역에서는 거의 발생하지 않는 성질) 영향으로 인해 local minima의 빠지는 경향을 방지하고자, disparity map 추론과정과 reconstruction 과정을 다중 scale에서 진행하여 이들에 대한 loss를 계산하고 학습했습니다.
그런데 이상하죠. monodepth라면서 stereo 이미지쌍을 이용하다니 말입니다. 정확히 말하자면 monodepth1은 학습 때만 aligned된 stereo pair 이미지를 활용하고, network input으로는 single L image만을 넣고 output으로 depth 이미지를 얻을 수 있기 때문에 monodepth라고 불리는 것이 가능하다고 볼 수 있겠습니다. monodepth1 저자들은 위 과정인 image reconstruction loss 외에도 추가적인 loss 2개를 제안하여 성능을 더욱 높였습니다. 바로 disparity smoothness loss와 L-R disparity consistency loss 입니다. 그렇게 monodepth1은 monocular depth estimation 태스크에서 supervision 방법론들과 견줄정도로 좋은 성능을 냈었습니다.
[Monodepth2]
monodepth2는 monodepth1을 잇는 후속 논문입니다. 앞선 monodepth1이 Self-supervised monocular depth estimation이라는 패러다임을 제안했었습니다. 하지만 이 과정에서 여전히 아쉬운 부분들이 몇 존재하게 되었고, 이는 다음과 같습니다.

- 기본적으로 stereo pair를 이용해 Depth를 추정할 시 camera pose 추정에 대해서는 offline에서 한 번의 calibration만 하면 된다는 장점은 있지만, Depth가 RGB의 representation 특성을 따라가는 ‘texture-copy artifacts’ 문제가 발생합니다.
- Self-supervised 방식으로 학습을 진행할 시, stereo pair 이미지 둘 중 하나에서라도 occlusion이 발생하면 reconstruction 과정에서 photometric error 신뢰성이 떨어집니다.
- 학습 과정에서 depth map과 reconstruction 이미지가 multi-scale로 추출되어, 저해상도 scale의 low-texture 영역 표현에 관해서는 “texture-copy artifacts” 뿐만 아니라, “depth hole(depth 측정불가픽셀, 까맣게(무한대로) 표현됨)” 또한 생성하는 경향이 있음. 이 둘로 인해 photometric error가 또 신뢰성이 떨어집니다.
그래서 monodepth2는 위 문제 중 특히 1,2번의 문제를 해결해보고자 했습니다. 학습 시 사용되는 데이터의 형태를 stereo pair 이미지에서 sequence한 monocular video 이미지로 바꾸기로 합니다. 이로 인해 연속적인 이미지 pair간에 카메라 egomotion 추정문제가 추가로 필요하게 되지만, 이는 depth 자체를 추정하는 ‘DepthNet’ 이외에 ‘PoseNet’이라는 카메라 포즈 추정 network를 추가 설계하여 해결했습니다. monodepth2 저자들은 위 과정 이외에도, 또 새로운 loss를 3가지 제안하여 추가적인 성능 향상을 이루었습니다.
- occlusion 문제 해결을 위한, minimum reprojection loss
- photometric error 개선과 depth hole 문제 해결을 위한, auto-masking loss
- photometric error 개선과 depth hole 문제 해결을 위한, low-scale depth map에 대해 upsampling을 거쳐 reconstruction 하게하는 loss
결론적으로 mono1, mono2간의 큼직한 차이들을 비교 정리하면 다음과 같습니다.
- monodepth1는 stereo pair(left & right) 를 사용해서 ‘DepthNet’만을 학습
- monodepth2는 monocular video(t-1, t ,t+1)를 사용해서 ‘DepthNet’과 ‘PoseNet’을 학습
- mono1 DepthNet input은 L만. mono2 DepthNet input은 0만, PoseNet input은 (-1,0), (0,1)쌍으로.
- 새로운 loss 3개.
이렇게 monodepth2는 monodepth1 보다 더 좋은 성능을 가질 수 있게 됐습니다.
[FeatDepth]
이제 본 리뷰에서 다루고자 하는 FeatDepth를 설명할 수 있게 됐습니다. mono1, mono2와 같은 self-supervised 접근법은 그래도 여전히 large margin에 의한 supervised learning 방식보다는 성능이 낮았습니다. 주요 원인은, photometric loss로 학습하는 과정에서의 생각보다 약한 supervision 때문이라고 합니다. 작은 photometric loss는 특히 이미지의 textureless한 영역에서 depth와 pose추정에 아쉬움이 있었지만, smoothness loss를 depth map에 추가해주면 어느정도 해결이 되었었습니다. 해당 loss가 texture-less한 영역으로 depth propagation을 가해줄 수 있었기 때문입니다. 그러나 해당 propagation가 제한된 range를 가지고 있다는 점은, 오히려 over-smooth한 결과를 만들어버릴 수도 있었습니다. 위의 주요 한계들은 이미지의 representation 관점에서 왔음을 생각해봤을 때, 저자들은 각 픽셀에 대한 feature representation을 학습하기 위해 “feature-metric loss”를 제안합니다. 아까와 같은 texture-less한 영역에 대해서도 판별되게 만들 수 있다고 합니다. feature representation을 학습하는 데 있어서, 단안 reconstruction pathway가 AutoEncoder network에 더해집니다. 학습된 feature representation에 대해 정의된 loss landscape를 원하는 shape으로 만들기 위해, 저자들은 2가지 regularizing loss를 AutoEncoder loss에 추가했습니다. 바로 discriminative loss와 convergent loss입니다.
discriminative loss는 1차 그래디언트로 모델링된 픽셀들 간의 feature difference를 더욱 가져오는 loss이고, convergent loss는 픽셀 간의 feature 그래디언트의 분산들에 페널티를 줘서 landscape가 넓은 수렴 분지 형태를 취하게끔 하는 loss입니다. 여기에 더해 종합적으로 저자들은 아래 3가지 sub network를 가집니다.
- DepthNet, PoseNet -> for cross-view reconstruction
- FeatureNet -> for single-view reconstruction
이 때 FeatureNet에서 만들어진 feature들은 DepthNet과 PoseNet에서의 feature-metric loss를 정의하는 데 사용됩니다. 결론적으로는 feature-metric loss가 기존의 smoothness loss의 성능을 능가했다고 합니다.
Method
기본적인 geometry model은 다음과 같습니다.
[Camera model and Depth]
projection에 대한 camera operator는 다음과 같이 정의될 수 있습니다. 3D -> 2D 변환입니다.
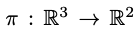
그리고 3D 포인트와 2D 픽셀은 다음과 같이 표현될 수 있습니다.
3D point P = (X, Y, Z) -> 2D pixel p = (x, y)
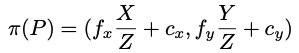
여기서 camera intrinsic params은 다음과 같습니다. f는 focal length이고, c는 principal point입니다.
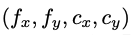
반대로 backprojection에 대한 정의는 다음과 같습니다. 2D -> 3D 변환입니다.
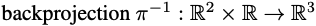
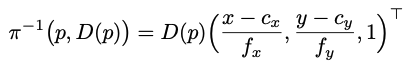
여기서 D(p) 는 depth 입니다.
[Ego-motion]
ego motion은 π and π−1 을 쓰면서 G 라는 SE(3) 변환으로 모델링됩니다.
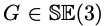
여기서 SE(3)은 special euclidean transformation이라고 하며, Rigid-body motion에 의한 transformation이라고 합니다. 쉽게 말하면 3D(월드좌표계) -> 3D(카메라좌표계) 인 extrinsic parameter와 관련된, 즉 카메라 포즈와 관련된 설명 같습니다.
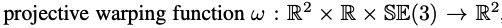
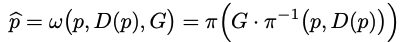
w는 한 프레임에서 G로 변환된 다른 프레임으로 픽셀 p를 매핑합니다.
[Cross-view reconstruction]
input video frame 중 target frame It(0)는 source frame Is(-1 or 1)를 통해 reconstruct 될 수 있습니다.
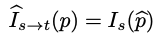
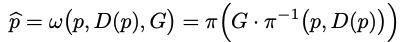
It(p) 와 Is(p^) 은 둘의 depth와 ego-motion이 정확하다는 걸 포함한 일련의 가정을 감안할 때 유사해야 합니다. 대응하는 3D point는 Lambertian refelctance 과 함께 고정되어 있고, 두 view 에서 다 occluded 되어있지 않은 것도 일련의 가정입니다. 그렇게 됐을 때, multi-view reconstruction loss는 learning depth 와 motion에 대해 다음과 같이 정의될 수 있습니다.
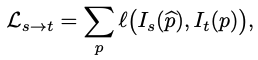
여기서 l( , ) 은 픽셀당 loss입니다. photometric difference를 측정하기 위한 loss인 것입니다. 그런데 이 loss는 효과가 있지만, 근복적으로 문제가 있습니다. depth와 pose 정확도가 photometric error에는 크게 주요하지 않기 때문입니다. 예를 들면 심지어 depth와 pose가 틀리게 추정되어도, 같은 photometric 값을 가진 textureless 속의 픽셀이면 작은 photometric loss를 가질 수도 있습니다.
이 때 이 문제는 depth D(p)와 egomotion G 둘 다에 대해 그래디언트로부터 파생되기 때문에, 최적화 관점으로 분석해 볼 수 있습니다.
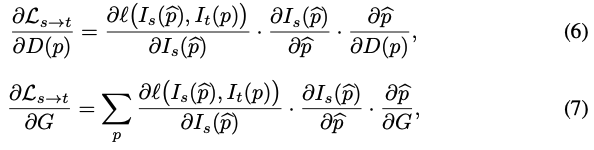
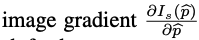
depth D(p)와 egomotion G에 대한 두 그래디언트는 위의 image gradient 텀에 의존합니다. 식 (6), (7)을 자세히 보면 가운데 텀으로 들어갑니다. 그런데 texture-less 영역에 대해 image gradient는 사실 0에 가깝습니다. 이는 식 (6), (7)에 영향을 끼치게 됩니다. 게다가, local한 부분에서 non-smooth한 그래디언트 방향들은 일관적이지 않은 방향 업데이트 때문에 local minima로 빠지는 수렴문제를 가지고 있습니다. 그렇기 때문에, 저자들은 image gradient를 대신할 feature representation인 φs(p) 를 학습하고자 합니다.
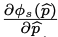
이 그래디언트는 위의 문제들을 극복하고, feature metric loss에 따른 photometric loss로서 일반화된 성능을 가질 수 있습니다.
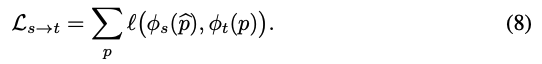
[Single-view reconstruction]
feature representation φ(p) 는 또한 AutoEncoder를 통한 single view reconstruction 과 함께 self-supervised manner로도 학습됩니다. AutoEncoder 중 인코더는 input 이미지로부터 deep feature를 추출하고, 디코더는 인코더에서 만든 deep feature 에 기반하여 input 이미지를 reconstruct합니다. deep feature는 redundancies(중복성)와 noise가 제거된 이미지속의 큼직한 패턴들을 압축하기 위해 학습됩니다. 식(8) 최적화와 관련해 좋은 특성을 가진 학습된 표현력을 확실히 하기 위해, 저자들은 2가지 추가적인 regularizer를 제시했습니다.바로 Lrec에다가 Ldis 와 Lcut를 regularizer로 더해주는 것입니다.
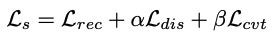
α and β 는 cross validation을 통해 1e-3으로 정해졌다고 합니다. 추가로 앞으로 나올 식의 간결성을 위해 이미지 좌표계에서의 1,2차 미분이 ∇1, ∇2 로 표현되었으며, 이는 각각 ∂x +∂y, ∂xx +2∂xy +∂yy 가 되겠습니다.
- Image reconstruction loss
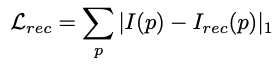
Lrec는 AutoEncoder에서의 학습을 위한 기준 loss function이 됩니다. Network는 인코더의 인풋에 대해 reconstruction을 진행하는 encoding된 feature들을 요구합니다. I(p)는 인풋 이미지, Irec(p)는 Network로부터 reconstruct된 이미지입니다. Lrec는 단순히 그것들의 pixel wise한 L1 loss인 것입니다.
- Discriminative loss
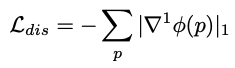
Ldis는 학습된 feature가 명백히 큰 gradient를 갖도록하여, 아래의 feature gradients 텀을 위해 정의됩니다.
게다가 image gradients들은 low-texture regions을 강조하기 위해 쓰입니다.
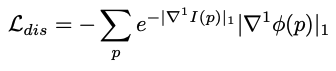
여기서 low-texture 영역은 큰 가중치를 받게 됩니다.
- Convergent loss
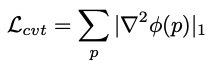
Lcvt은 feature gradients의 smoothness를 위해 정의됩니다. 이는 최적화와 큰 수렴 반경 동안 일관된 gradient를 보장합니다. 그리고 해당 loss는 2차 gradient를 페널티를 주기 위해 정의됩니다.
Overall Pipeline
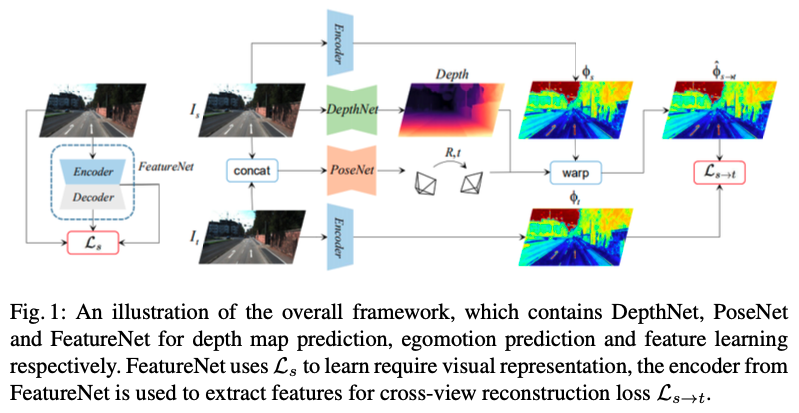
single-view reconstruction과 cross-view reconstruction에 대한 최종 프레임워크는 위와 같습니다. DepthNet은 monodepth estimator로써 target frame을 input으로 depth map을 output으로 갖습니다. PoseNet은 egomotion estimator로써 source 와 target 두 프레임을 가지고, 그들 사이의 상대 pose를 output으로 내놓습니다. DepthNet 과 PoseNet은 geometry 정보가 cross-view reconstruction에서 pixel이 1대1 대응에 성립하게끔 정보를 제공합니다. FeatureNet은 feature representation learning을 위한 것입니다. 이는 single-view reconstruction loss에 의해 학습됩니다. FeatureNet 인코더의 feature는 추후 cross-view reconstruction loss를 정의하는 데 사용됩니다.
더 자세한 디테일은 다음과 같습니다. FeatureNet의 인코더는 FC layer 가 제거된 ResNet-50입니다. 여기서 가장 깊은 층의 feature map은 5개의 downsampling stage를 거치고, 인풋이미지의 1/32 해상도로 줄어듭니다. 디코더는 반대로 5개의 3*3 conv layer & bilinear upsampling layer 를 가집니다. 디코더의 conv layer 로부터 나온 multi-scale feature map들은 multi-scale reconstruction 이미지들을 만들어 냅니다. 이를 통해 feature map의 feature값은 Ldis와 Lcvt에 의해 regularized되는 Ls 연산을 수행하고, feature representation learning 후 인코더 부분은 cross-view reconstruction feature-metric loss로 추후 사용되게 됩니다.
DepthNet도 역시 인코더 디코더 구조를 따랐습니다. FeatureNet과 동일하게 인코더는 FC layer 제거된 ResNet-50이고, 여기서 multi-scale feature map들이 output으로 나오게 됩니다. depth를 위한 디코더는 top-down pathway를 따라 depth map을 생성합니다. 특히, 인코더로 나온 multi-scale feature들은 3*3 conv와 sigmoid를 통해 0~1값으로 mapping되어 예측되고, 그 map들은 scale factor를 통해 final depth map으로 정제됩니다. FeatureNet과 DepthNet은 input 해상도는 320*1024 입니다.
FeatureNet & DepthNet 과 비교해보면 PoseNet은 더 작은 이미지 해상도와 더 가벼운 백본을 사용합니다. PoseNet은 ResNet-18 구조를 따 구성됩니다. concat된 이미지쌍을 input으로 받고 해당 이미지쌍 간의 상대 포즈 예측을 output으로 뱉습니다. output 중 axis angle은 3D rotation을 표현합니다. PoseNet의 input 해상도는 192*640입니다. 이는 포즈 정확도에 큰 영향은 없으면서도 메모리와 컴퓨팅 연산을 어느정도 save할 수 있다고 합니다.
자 이제 다시 전체적인 그림으로 돌아가면, 아까 언급했듯이 visual representation을 학습하기 위해 Ls를 사용했던 FeatureNet에서 인코더를 때와서 cross-view reconstruction loss Ls->t 를 위한 feature를 추출하는 데 사용합니다. 그러므로, 두 파트를 포함한 전체 아키텍쳐에 대한 총 loss는 다음과 같습니다. 여기서 Ls는 single-view reconstruction을 통해 학습된 feature의 퀄리티를 규제합니다. 반면에 Ls->t는 cross-view reconstruction으로부터의 불일치에 페널티를 줍니다.
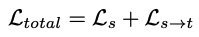
더 좋은 성능을 위해 feature-metric loss Lfm는 새로운 photometric loss Lph와 결합됩니다.
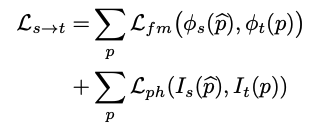
특히, feature-metric loss Lfm는 아래와 같이 정의되고,
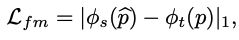
photometric loss Lph는 L1 loss와 SSIM loss의 결합으로 정의됩니다.
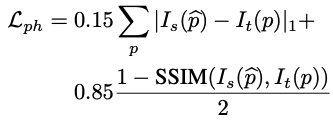
여기에 저자들은 occlusion 문제를 해결하고자 하여 monodepth2에서 쓰이던 minimum loss 형태를 추가 적용하여 L‘s->t loss를 최종적으로 만들었습니다. 이 중 V는 source frame들의 집합이고, 여기서 두 source view(-1, 1)는 cross-view reconstruction loss를 정의하는데 쓰였습니다. monocular videos에서 학습된 상황에서, V는 현재 타겟 프레임(t)에 대해 이전(t-1)과 이후(t+1) source 프레임을 가집니다.
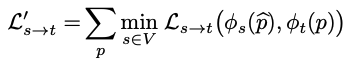
[정성적 결과]

2번째 행은 mono2이고, FeatDepth는 3번째 행입니다. 벽이나 표지판 같은 low-texture 영역에서 더 좋은 성능을 보입니다. 그리고 사람이나 pole의 실루엣 같은 더 세세한 디테일들이 나타납니다.
[Experiments]
KITTI 2015 데이터셋에 대해 평가가 들어갔습니다. ablation study들은 feature-metric loss의 효과성을 보여주기 위해 시행됐습니다. KITTI 2015 데이터셋은 RGB 카메라로 찍힌 200개의 스트릿 씬 비디오를 포함하고, sparse하게 velodyne 레이저 스캐너로 잡힌 depth를 GT로 가집니다. 전처리단계에서는 고정적인 프레임은 버립니다. Eigen split을 사용하여 KITTI raw data를 나눴습니다. 그래서 데이터는 39810개의 monocular 세 프레임을 training용으로 갖고, 4424개를 validation으로 갖고 697개는 testing으로 가집니다.
평가 기준 metric은 아래와 같습니다.

d, d* 는 각각 predicted depth와 gt depth입니다. D는 한 이미지에서의 예측된 모든 depth값의 집합을 의미하고, |.| 은 인풋 셋의 요소 갯수를 반환합니다. eval 과정에서 depth는 80m까지 제한되어 있었습니다. monocular 비디오로 학습된 방법론에서, depth는 아래와 같은 scale factor까지 정의됩니다.
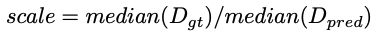
pred의 스케일을 GT에 맞게 맞추는 과정인 것인 것 같았습니다. 이 때 median을 활용하여 계산하기에 이 과정을 median scaling이라 부릅니다.
다음은 monocular depth estimation에서의 성능비교입니다.
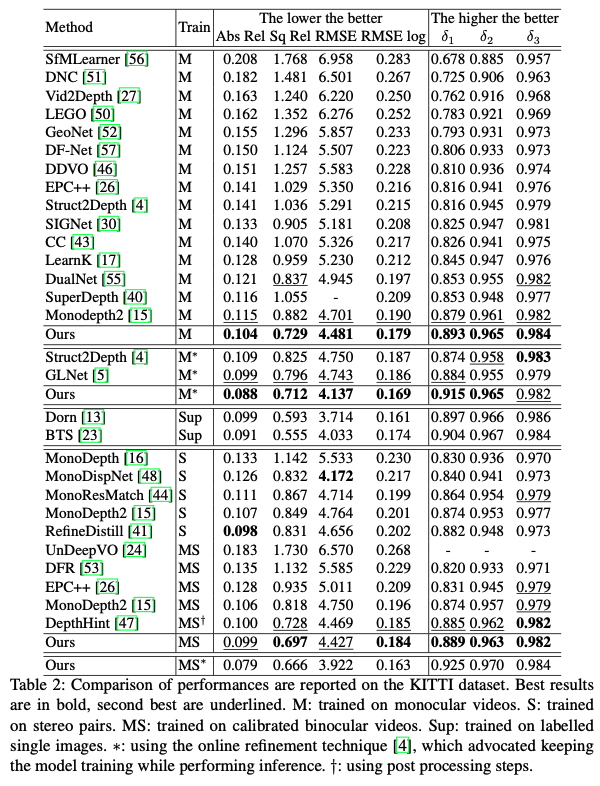
이들은 모두 다른 데이터로 학습되었고, 테스트 시엔 single image input으로 테스팅됩니다.
- M : monocular video
- S : streo pair
- MS : calibrated binocular video
- Sup : labelled single images
- * : using the online refinement technique, (인퍼런스 수행 중에도 모델이 training 을 계속하게끔 하는 것 같습니다.)
- † : post processing step
FeatDepth는 모든 self-supervised 방법론에 비해 어느 training 셋에서든 가장 높은 성능을 보여줬습니다. 특히 Sq Rel에서 더 의미있는 향상이 이루어졌습니다. Sq Rel 메트릭은 짧은 구간 내에 큰 에러가 있을 때 더 많이 패널티를 준다는 점에서 의의가 있습니다. FeatDepth에 가장 close한 결과는 DepthHint였습니다. 해당 모델은 사실 추가적인 post processing 과정이 있었습니다. 추가적인 supervisory signal을 훈련 중에 보내기 위해서, local minima에 덜 빠지는 경향이 있는 전통적인 스테레오 매칭 기법이라 불리는 SGM을 활용했다고 합니다. 하지만, 그 세팅에서, SGM의 object function이 여전히 photometric loss형태였고, photometric loss 의 단점은 여전히 불가피했습니다. sota supervised 방법론과 비교해보았을 때는, 그것들은 KITTI depth prediction competition에서 최고 성능을 보였었는데, online refinement 테크닉을 겸비한 저자들의 모델은 많은 metric에서 이들의 성능을 넘어섰습니다. supervised 방법론을 능가한 저자들의 방법론적 이점은 다음과 같았습니다. 바로, training과 testing 데이터 간의 갭이 존재하고, 저자들은 online refinement 테크닉을 풀로 사용할 수 있었던 것입니다. 여기에 더해 feature-metric loss의 제안은 online refinement 테크닉으로 더욱 퍼포먼스 이득을 얻을 수 있었습니다. 위에서 한번 언급됐었던 정성적 결과 figure에서, 이전에 sota였던 Monodepth2 방법론에 비교해봤을 때, 저자들은 low-texture 영역과 세밀한 디테일에서 더 좋은 성능을 보였습니다. 예를 들면, 벽, 표지판, 사람의 실루엣이나 폴대 등. 하지만, monodepth2는 photometric loss로 구성되었고, 그것은 벽이나 표지판같은 low-texture 영역에서 특히 local minima에 쉽게 빠집니다. 대조적으로, feature-metric loss의 등장은 네트워크를 local minima로부터 빠져나오게 만들었고, 이것은 저자들이 제안한 feature들이 편안한 최적화를 위해 바람직한 loss 형태를 가지고 있기 때문인 것으로 볼 수 있었습니다.
[ablation study]
저자들은 제안된 loss들인 feature-metric loss, discriminative loss, convergent loss 에 대해 ablation study를 진행했습니다.
- The losses for cross-view reconstruction
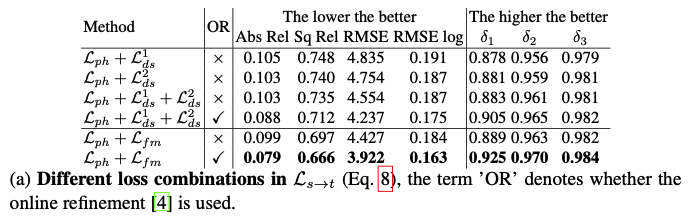
위 테이블 (a)를 보면, Ls->t 에 서로 다른 loss 조합으로 ablation을 진행했습니다. 아래의 i값에 따른 1,2차 미분 smoothness loss들은 feature-metric loss의 효과성을 입증하기 위해 base line들로 쓰였습니다.
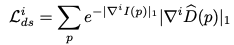
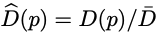
이 때 위 식은 평균 normalization 테크닉이라고 합니다.
역시 smoothness loss들과 비교해서 feature-metric loss는 더 좋은 효과를 냈습니다. 저자들이 일전에 언급한 것 처럼, smoothness loss들의 propagation 범위는 제한되어 있고, 그에 반해 feature-metric loss는 넓은 수렴 반경을 갖고 있었기 때문에, 넓은 범위의 propagation이 가능했습니다. 또한 feature-metric loss는 다른 loss 조합보다 online refinement가 적용되었을 때의 이점을 더 얻을 수 있었습니다. online refinement 구간 동안 feature-metric loss가 적용된 더 좋은 supervised signal이 그 이유라고 합니다. 여기서 부정확한 depth 값은 더 discriminative한 feature들에 의한 더 큰 loss에 의해 적절히 페널티가 먹여집니다.
- The losses for single-view reconstruction
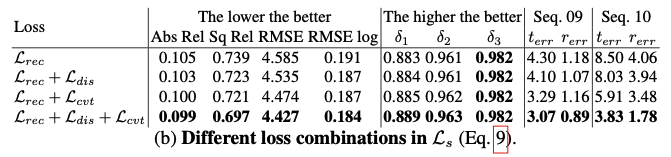
위 테이블(b)은 Ls 조합에 따른 ablation 입니다.
단순 Lrec 사용 —> a 테이블에서의 photometric loss를 사용한 것과 유사한 성능을 가집니다. 왜냐면 texture less 영역에서는 photometric loss와 유사한 역할을 하기 때문입니다.
Ldis를 추가 —> low-texture 영역에서 discrimination(차이)가 개선되기 때문에 성능이 더 좋아집니다.
Lcvt를 추가 —> 최고성능입니다. 이는 discrimination이 충분하지 않다는 것을 의미, 올바른 최적화 방향도 중요하다고 합니다.
추가적으로 위 테이블의 오른쪽 부분을 보면, 비록 작은 편차가 depth eval의 몇몇 지표에서는 덜 명확할지라도, 작은 error들은 궤적 예측 중에 accumulation과 propagation을 통해 확대될 것이라고 합니다. seq.09 와 seq.10은 depth task와 별개로 해당 모델에 대한 odometry task의 eval이라고 합니다.
[Visualization anlysis]

학습된 visual representation이 특징을 잘 잡는지 시각화한 것 입니다. PCA 분해를 통해 하나의 principle한 채널을 선택하고(어떤 채널인지는 언급없음), feature map을 히트맵으로 표현했습니다. 더 뜨거워보이는 색상은 더 높은 feature 값을 가집니다. 첫번째 행은 벽과 그림자 같이 texture-less한 영역으로 가득 찬 기존 이미지를 나타냅니다. 이것에 대한 feature map 시각화가 행마다 아래 3개 순서로 보입니다.
- L_rec
- L_rec + L_dis
- L_rec + L_dis + L_cvt
전체로 봤을 땐, a,b,c 영역이 크게 차이가 없어보여서, L의 영향을 잘 못 알아먹겠지만, 논문에서 친절히 texture-less 영역인 a,b,c 세부분 각각을 crop하고, 잘린 feature map에 대해 상대적인 range로 다시 시각화 해서 비교해줍니다. 먼저 단순 1. Lrec를 사용하는 것은 texture-less한 영역에서 작은 변화를 얻는다는 것을 알 수 있습니다. 원본 이미지의 클로즈업은 Lrec로만 학습된 feature map과 유사합니다. 이 현상은 feature 표현을 개선하는 데 있어서의 제안된 loss들을 입증합니다. 2. Lrec + Ldis로 학습된 feature map은 smooth 하지 않고, 무질서합니다. 왜냐하면 Ldis는 인접 feature들 사이의 불일치를 지나치게 강조해서, 네트워크도 지그재그 형태의 배경을 만드려고 퇴화하는 경향이 있기 때문입니다. 이 현상은 단순 1. Lrec를 사용하는 것보다 성능이 약간만 높은, ablation 테이블 (b)에서의 두번째 행 결과로 이어졌습니다. 이런 식으로 feature map이 최종적으로 원하는 형태는 smooth한 경사면 형태이고, feature-metric loss는 분지형태의 feature map형태를 만들어 낼 수 있었을 것이라고 합니다. 3. 의 제안된 모든 loss들로 학습된 feature map은 이 이상적인 분지 형태와 유사하고, crop된 표현을 보면 이런 smooth한 변화를 볼 수 있습니다. 이 분지 형태의 feature map에서의 그래디언트 디센트 방식은 최적화 해를 향해 smooth하게 갈 것이라고 합니다.
Conclusion
feature-metric loss(특징 측정 loss)는 depth와 egomotion에 대한 self-supervised learning을 위해 제안되었고, 여기서 feature representation은 정확한 depth와 pose로 확실히 수렴되도록 추가적인 regularizer 2개로 학습이 되었습니다. 더구나 전체 프레임워크는 self-supervised 환경에서 end-to-end로 학습될 수 있었으며, 기존 supervised learning 방법론과 비교할 만한 그 때 당시의 SoTA depth estimation이었다고 합니다.
monodepth2 와 비교했을 때 크게 달라진 건 단순하게 보면 기존의 image 레벨 관점의 loss연산에서, feature representation을 고려하다보니 feature level에서의 loss연산까지 추가로 고려해주는 것이라고 볼 수 있는 것 같습니다. feature 단에서 loss 연산을 수행해보겠다는 관점이 참신했던 것 같습니다.
첫 리뷰이다보니 요약보다는 장황하게 글을 작성한 것 같고, 분량조절도 실패한 것 같고, 리뷰에 제 생각을 넣는 것도 여간 쉽지 않았습니다. 앞으로 점차 발전하는 모습 보이도록 노력하겠습니다. 리뷰 마치겠습니다.
안녕하세요 재찬님!
좋은 리뷰 감사합니다!
글을 읽던 도중 질문사항이 있어 댓글 남깁니다.
1. SSL방법론이 large margin을 제공하는 SL방법론에 비해서 supervision이 약했다고 말씀해주셨는데요. 여기서 large margin이 의미하는 바가 무엇인가요? 단순히 목적함수의 loss값이 큰 것을 의미하는 것인가요?
2. 해당 논문에서 저자들이 depth featur map을 사용하여 타겟이미지를 합성하는 것으로 또 다른 loss를 제안했다고 이해하였습니다.
그런데 feature map단에서 타겟이미지가 합성되는 과정이 상상이 안갑니다..! 혹시 해당 논문에 그 과정에 대한 언급이 있었나요?
감사합니다!
안녕하세요 현석님, 리뷰 읽어주셔서 감사합니다.
1. 저도 논문에 large margin에 대한 설명은 없었어서 처음에 혼자 추측하기로는 ‘대량의 데이터로 학습되는 경향성 때문에 supervision이 더 세다’라고만 생각하고 스르륵 넘어갔었는데 현석님의 질문 덕분에 한번 더 되짚어 보게 되어 좋네요. 제가 찾아본 바로는 Large margin은 머신러닝과 같은 분류문제에서 쓰이는 개념이라고 합니다. 두 클래스 사이의 결정경계가 가능한 멀리 떨어지게끔 만드는 것을 의미하는데요. 모델이 새로운 데이터를 더 잘 일반화하게끔 돕는 특징이라고 볼 수 있겠습니다. 이런 관점에서 SSL의 경우 gt가 없는 데이터이기 때문에 당연히 SL에 비해 결정경계가 명확하지 않을 테고, 이는 즉 다른 말로 supervision이 약하다고 표현될 수 있는 것 같습니다. 결론은 large margin이 있다 = supervision이 강하다 정도가 되는 것 같습니다.
2. 조금 정리를 해드리자면, 해당 FeatDepth 논문의 Network 구조는 저희가 배운 monodepth2과 비교했을 때 DepthNet과 PoseNet에서의 output으로 각각 depth map과 egomotion이 나오는 것 까지는 과정이 동일합니다.
단지 다른 점은, 기존의 mono2에서 image reconstruction 관점으로 photometric loss를 계산하던 것이 벽이나 표지판같은 texture-less한 영역에서는 depth와 pose가 부정확하게 예측되더라도 loss가 작게 나오는 현상이 있었기 때문에, 이를 image의 feature representation 관점으로 해석해서 photometric 말고 feature-metric 하게 loss를 계산하는 것으로 바꾸게 된 것입니다.
그로 인해 FeatureNet이라는 Network구조가 추가적으로 붙게 되었고, 해당 Network에서는 feature representation만을 위한 학습을 수행한 후, 학습된 인코더만을 떼어와 sequence video의 타겟과 소스를 인풋으로 태워 각각의 타겟 feature map, 소스 feature map을 서로 만들게 되고, 이 타겟과 소스 feature map들에 대해 DepthNet과 PoseNet에서 output으로 나온 depth map과 egomotion을 이용해 warping 하고 reconstruction loss를 연산하여 self-supervised 학습을 하는 것입니다!
안녕하세요 ! 좋은 리뷰 감사합니다.
Monodepth2에 대한 질문인긴 한데, Depth가 RGB의 representation 특성을 따라간다는게 정확히 어떤 의미인지 좀 더 설명해주실 수 있나요 ? Depth에서의 texture-copy라는 말이 잘 와닿지 않아서 질문 드립니다. 단순히 RGB에서 texture가 적은 부분에 대해서 Depth를 잘 추정하지 못한다고 이해해도 되는걸까요 ?
그리고 monodepth2는 monodepth1의 한 이미지에서라도 occlusion이 존재할 시 발생하는 신뢰성 하락 문제를 해결하고자 한 걸 보니 이미지에 대한 occlusion이 성능에 영향을 많이 미치는 것 같은데 해당 논문에서는 cross-view reconstruction을 할 때 두 뷰 모두에서 occlusion이 없다는 가정을 하고 있네요. 이 부분에 대한 고려가 없었음에도 해당 논문이 monodepth2보다 성능이 대체적으로 좋은 성능을 보이고 있는데, 이에 대해서 어떻게 분석하시는지 재찬님 생각이 궁금합니다.
감사합니다.
건화님 리뷰 읽어주셔서 감사합니다.
질문에 답변을 드리자면,
1. Depth가 RGB의 representation 특성을 따라간다는 것은, 예를 들면 자동차의 유리창 같은 경우 depth 표현으로 일정한 value를 가져야 함이 옳겠지만, RGB representation 특성을 따라가게 되면서 중간에 차체필러(창틀)를 depth로 표현해버릴 수 있는 것과 같습니다. 그래서 건화님께서 말씀하신 ‘RGB에서 texture가 적은 부분에 대해 Depth를 잘 추정하지 못하는 것’ 이 depth에서의 texture-copy가 되는 것이 아니라, RGB의 texture가 말 그대로 copy되어 depth map에 표현되는 것이라고 이해하시면 될 것 같습니다. 이는 저도 이미지를 보며 잘 이해되었던 탓에 리뷰에 이미지를 첨부해서 이해를 도왔어야 하는데 첫 리뷰라 그런지 독자에 대한 배려가 조금 부족함이 있었던 것 같습니다! 본문 [Monodepth2] 부분에 대해 figure를 삽입하여 수정했습니다!
2. 음,, 제가 논문의 서술 순서를 따라가며 너무 번역체로 표현하다보니, 제 글만의 일관성을 부여하지 못해 생긴 오해같네요.. 건화님께서 보신 부분이 아마도 Method의 [Cross-view reconstruction]부분으로 사료되는데요, 사실 해당 부분은 기본적인 geometry적 개념과 함께 monodepth2에서 기본적으로 쓰이던 cross-view reconstruction loss를 설명하기 위한 부분이었습니다. 결론은 해당 논문은 occlusion에 대응하기 위해 monodepth2에서 쓰인 minimum loss 형태를 동일하게 사용했습니다! Overall Pipeline의 마지막 문단을 보시면 나와있습니다. 그래서 둘 다 동일 기준으로 occlusion으로 인한 성능하락 문제를 개선한 것이 맞습니다!
감사합니다.
안녕하세요 재찬님
아직 모르는 내용이 너무 많아서 구체적으로 다 이해하진 못하지만 제가 이해한게 맞는지 궁금해서 여쭤보자면,
이미지가 texture-less한 영역에서 photometric loss만 사용하는건 한계가 있어서 smoothness loss을 통해 depth map을 smoothing한다고 읽었는데 texture less한 부분에서 depth map의 변화가 적을거 같은데 어떻게 smoothing을 하는건가요??