Introduction
Scene Graph Generation (이하 SGG)은 이미지에 존재하는 객체와 객체들간의 관계를 예측하는 작업으로 High-level Scene Understanding 능력을 요구로 합니다. Scene Graph의 구성 요소는 크게 세 가지로 구분이 됩니다. 1) Subject, 2) Predicate, 3) Object 로 세 가지가 존재하게 됩니다.

<subject, predicate, object>
즉, 이미지를 설명할 수 있는, 주어, 서술어, 목적어로 구성된, triplet을 잘 찾는 것이 최종 목적이라 보시면 됩니다.
최근 SGG 연구 동향의 경우 학습 때 배운 category만 대응할 수 있는 Closed-Set 시나리오가 아닌, 추론 과정에서 발생할 수 있는 새로운 category에도 대응할 수 있는 Open-Vocabulary 상황에서 연구가 활발하게 진행되고 있습니다.
Ov-SGG의 경우 제가 지난 리뷰에서 22년도, 23년도 방법론을 하나씩 리뷰를 했습니다.
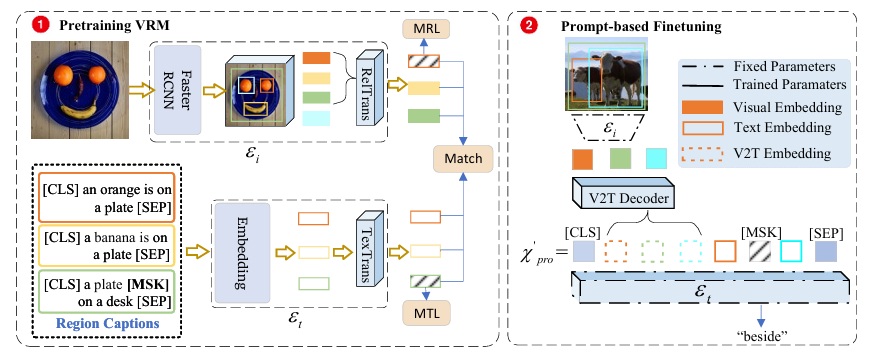
우선 [ECCV 2022] Towards Open-Vocabulary Scene Graph Generation with Prompt-based Finetuning 에서는 처음으로 Ov-SGG를 제안하면서 이를 해결할 수 있는 사전 학습 전략을 제안했습니다. 핵심은 Object-level의 Vision-Language Representation을 학습 하기 위해 Dense하게 annotation 되어 있는 Visual Genome caption을 활용하여 regional-level matching을 수행하였고 사전 학습을 마친 후에는 그 표현력을 유지하면서 down-stream task에 최적화 시킬 수 있는 prompt-based finetuning을 제안하였습니다.
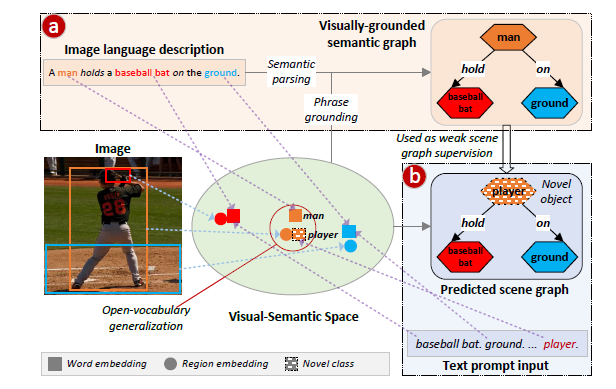
다음으로 [CVPR 2023] Learning to Generate Language-supervised and Open-vocabulary Scene Graph using Pre-trained Visual-Semantic Space 의 경우는 Ov-SGG와 Weakly Supervision 문제를 동시에 해결할 수 있는 방법을 제안하였습니다. 전적으로 GLIP이라는 object-level Vision-Language Pretraining 모델의 사전 학습 공간을 활용하여 이를 Ov-SGG + Weak Supervision에 맞춰 최적화 시켰다고 볼 수 있습니다.
저자는 위에서 설명한 기존의 연구들이 VLM 모델을 새롭게 사전 학습 시키거나 너무 간단한 학습 파이프 라인을 채택하여 문제를 해결하고 있다고 주장합니다. 또한 그 과정에서 image-to-text 간의 discriminative한 matching을 많이 활용하는 데 이는 풍부한 representation을 capture하기 어려운 점을 지적합니다.
저자는 조금 더 일반화된 문제해결을 위해 generative한 solution을 제안합니다.
저자는 SGG 문제를 sequence generation 문제로 정의합니다. 정확히는 Image로 부터 caption을 생성하는 Vision Language Model (VLM)을 활용합니다. 정확히는 저자가 정의하는 Scene Graph Prompt를 활용하여 이미지 내에서 존재하는 relation들을 설명하는 Scene Graph Caption을 생성합니다.
사전 학습된 VLM의 knowledge를 discriminative한 방식으로 활용하는 것이 아니라 generative한 방식으로 활용하여 훨씬 더 풍부한 표현력을 가지도록 유도하는 것이죠.
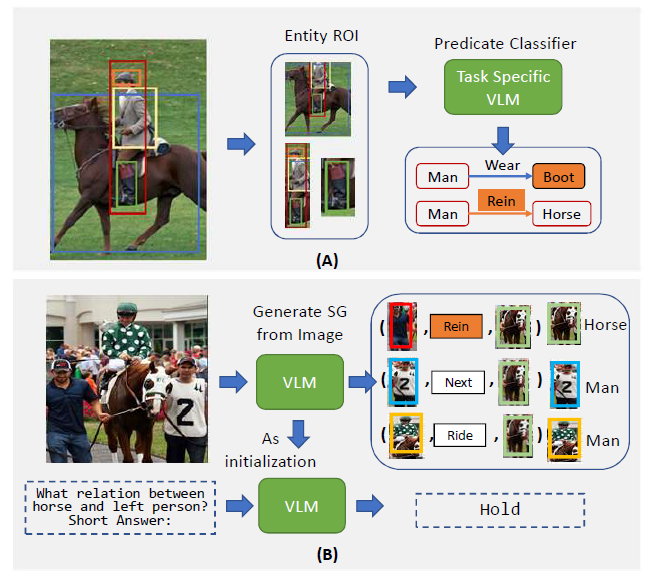
위의 그림에서 (A)의 경우 이전의 Ov-SGG 방식을 나타냅니다. VLM을 활용하여 Open-Vocabulary 상황을 해결하려고 하지만 결국 base 혹은 novel category가 무엇일지 discriminative 한 방식으로 예측하는 pipeline을 많이 활용하게 됩니다.
반대로 (B)의 경우는 저자가 제안하는 방식으로 VLM을 통해 Image에서 바로 SGG를 생성하는 모습을 보여줍니다.
즉, 기존의 방식은 Discriminative하게 어떤 object 혹은 어떤 predicate 인지 classification 하는 반면 제안하는 방식은 Graph를 바로 생성하여 조금 더 일반적인 표현에 용이하도록 설계하였습니다.
또한 저자가 제안하는 방식으로 VLM을 활용하여 다른 Vision-Language Task (Captioning, Question Answering) 에서도 놀라운 성능을 보여주며 제안하는 방식의 높은 transferability 를 보여줍니다.
정리하면 기존의 Discriminative 방식의 VLM을 활용한 Ov-SGG 방식과는 다르게 Generatrive 방식으로 VLM을 활용하여, 높은 Ov-SGG 성능과 다른 VL task 에서도 높은 성능을 보여주어 보다 더 일반적인 framework를 제안한 것에 contribution이 있습니다.
Proposed Approach
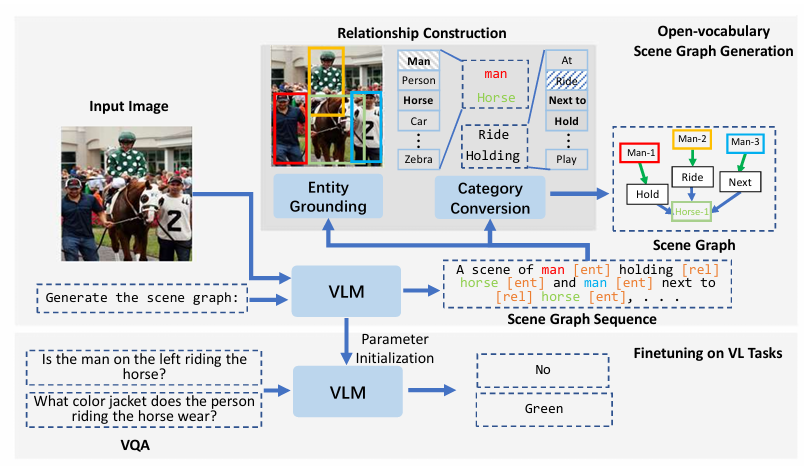
Method가 복잡하지는 않아서 간단하게 설명할 수 있을 거 같습니다.
크게 보면
(1) Scene Graph Sequence를 생성하는 부분
(2) 생성된 Scene Graph Sequence 부터 Relation을 추출하는 부분
(3) 학습한 VLM을 다른 VL task로 adaptation 하는 부분
이렇게 세가지로 구성 되어 있는데 사실 (1), (3) 같은 경우는 내용이 정말 없어서 간단하게만 설명하고 (2)에 조금 집중해서 설명해보도록 하겠습니다.
Scene Graph Sequence Generation
위에 나와 있는 그림을 보면 “Generate the Scene Graph”라는 프롬프트가 들어가서

Scene Graph로 표현할 수 있는 Sequence가 출력으로 나오고 있습니다.
이는 전적으로 BLIP이라고 하는 VLM 모델에 의존하고 있습니다.
BLIP은 이미지와 text description을 같이 넣어줬을 때 그에 해당하는 내용을 text로 생성해주는 VLM 입니다.
저기서 [ENT]는 entity의 약자이며, [REL]은 relation의 약자 입니다.
사실 여기서는 이게 전부 입니다. BLIP이라는 모델을 적~극 활용하여 “Generate the Scene Graph”라는 프롬프트를 활용해 이미지에서 나타날 수 있는 Scene Graph Sequence를 생성해주고 있습니다.
다만, 여기서 기존 VLM (CLIP이나 GLIP) 과 다른점은 discriminative한 matching이 아니라 자연어 수준의 문장을 생성하는 것을 강제하기 때문에 훨씬 더 풍부한 텍스트 표현을 도출할 수 있고 이를 통해 더 다양한 open-vocabulary 상황에 대응할 수 있다고 합니다.
Relationship Construction
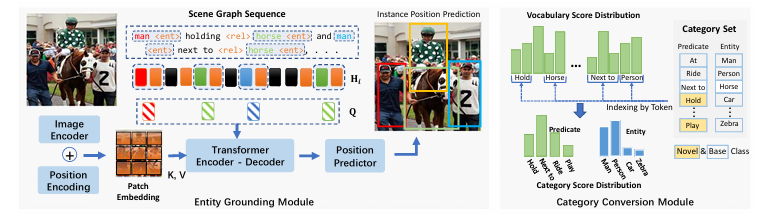
다음으로 이제 Scene Graph를 정말로 생성해야 합니다. 위에서 정의한 것은 Scene Graph Sequence이고 Scene Graph는 객체의 좌표, 카테고리 그리고 그들간의 관계를 모두 정의할 수 있어야 합니다.
그래서 여기 Relationship Construction 에서는 Scene Graph Sequence를 통해 bounding box 좌표와 우리가 target으로 하는 데이터의 카테고리 단어로 변경하는 작업을 수행합니다.
Entity Grounding Module
먼저 객체의 공간적 좌표를 나타내는 bounding box를 예측하는 부분에 대해서 설명 드리도록 하겠습니다.
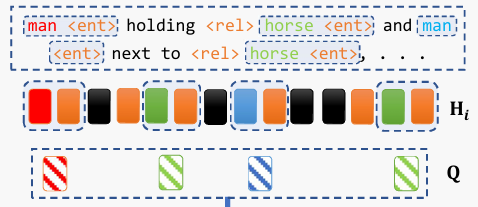
위에서 정의한 Scene Graph Sequence는 아래와 같이 text 형태로 정의되면서 동시에 hidden state 형태로도 표현이 됩니다. 정확히는 hidden state 형태가 아래와 같이 text 형태로 변환되는 것이죠.
즉, man <ent> , horse <ent> 들은 모두 BLIP의 중간 변환 과정에서 hiddent state로 변환이 됩니다.
여기서 man <ent>만 예시를 들어봤을 때
그렇다면 저 text에 집중하는 것이 아니라 feature 형태인 hidden state가 아래와 같이 정의되어 있다고 하겠습니다.
- \mathbf{H}_{i}=[\mathbf{h}_{1},\cdots,\mathbf{h}_{T_{v}}] \in \mathbb{R}^{T_{v} \times d}
여기서 T_{v}는 어떤 임의의 객체를 토큰화 했을 때 길이라고 보시면 됩니다. 뭐 예를 들면 man이라고 했을 때는 1이겠지만, super man이라고 하면 2개의 토큰이 나오겠네요.
이 때 box 좌표는 정말 간단하게도 self-attention 연산을 통해서 진행됩니다.
Query는 아래와 같이 Linear Project layer와 hidden state 들간의 average pooling을 통해서 정의가 됩니다.
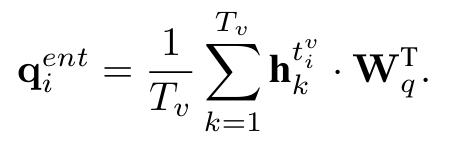
여기서 t_{i}^{v}는 임의의 Entity를 나타내는 notation이라 생각하시면 편할 거 같습니다.
Key, Value는 BLIP을 통해서 나온 Visual Feature 입니다.
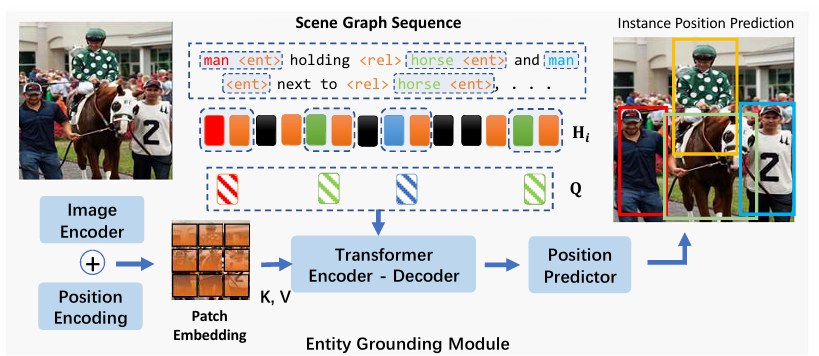
그래서 hidden state와 Visual feature 간의 attention을 거치고 postion predictor를 뒤에 붙여준다음 box 좌표를 예측하는 것이죠.
크게 복잡한 부분은 없는 거 같습니다.
Category Conversion Module
다음으로는 Category Conversion Module 입니다. 앞서 우리가 BLIP을 통해 Scene Graph Sequence를 생성했을 때 이를 나타내는 단어들은 굉장히 일반적이라고 볼 수 있습니다. 하지만 평가를 하기 위해서는 우리가 원하는 데이터에 대한 표현으로 다시 바꿔주는 작업이 필요 합니다.
즉, 일반적인 vocabulary space에서 category space로 변환하기 위해 Category Conversion Module을 제안하였다고 합니다.
별다른 parameter가 필요한 것은 아니고 제안 하는 연산 과정을 통해서 변환을 진행합니다. 근데 사실 이해를 잘 못했습니다.
우선 우리가 target으로 하는 데이터의 object category와 predicate를 tokenize 시켜 sequence로 만들어줍니다.
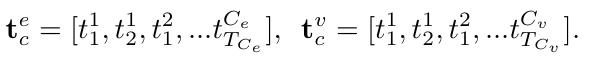
mathbf{t}_{c}^{e}는 predicate 를 의미하고 mathbf{t}_{c}^{v}는 object (entity) 를 의미합니다.
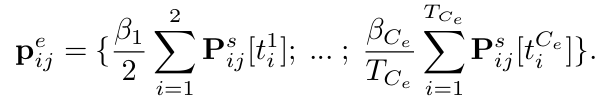
그리고 위의 수식과 같이 category space로의 prediction score로 변환해주는 데 사실 이해가 잘 안가긴 합니다. 핵심은 parameter 없이 생성된 단어들은 우리가 원하는 category space로 변환해주는 것이 가능하다고 하네요.
무튼 Close-set, Open-Vocabulary 상황일 때 우리가 원하는 category 들을 tokenize 시켜주고 해당 수식을 통해 변환만 시켜주면 전부 대응이 가능하다고 하네요.
이 정도로만 정리하고 넘어가겠습니다.
Learning and Inference
학습은 크게 두 가지 task로 진행이 됩니다.
\mathcal{L}_{lm}은 VLM backbone과 동일하게 다음 단어를 예측하는 task를 진행한다고 합니다.
저는 VLM backbone이 freeze 되는 줄 알았는데 해당 논문은 같이 finetuning을 시켜주고 있는 모습입니다.
근데 여기서 조금 의아했던 것은 Ground Truth를 어떻게 정의 하는지가 제대로 설명이 안나와있어서 그 부분이 조금 헷갈리긴 합니다.
다음 task는 bounding box를 예측하는 task로 \mathcal{L}_{pos}가 있습니다.
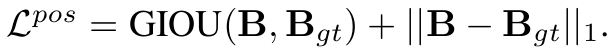
이는 일반적으로 많이 활용하는 세팅을 통해서 학습을 진행 시켜주고 있네요.
Adaptation to Downstream VL Task
여기서는 별다른 장치가 있는게 아니고 위에서 finetuning 한 VLM의 parameter를 가지고 down stream task를 한다고 하네요.
사실 novel한 부분이 없어서 조금 아쉽긴 했는데 뭐 실험 부분에서 나름 본인들의 finetuning 방식의 generality를 잘 주장했으니 accept이 된 거 같습니다.
실험 부분 살펴보고 리뷰 마치겠습니다.
Experiments
여기 PCIs, SGCls, SGDet이라고 하는 평가 지표가 있습니다.
- Predicate Classification (PredCls) : ground truth box와 label을 입력으로 넣어서 predicate를 예측합니다.
- Scene Graph Classification (SGCls) : ground truth box만 입력으로 넣어서 predicate를 예측합니다.
- Scene Graph Deteciton (SGDet) : predicate를 scratch level로 예측합니다. 즉, box와 label을 직접 예측하고 그 다음 predicate를 예측하는 것이죠
이를 참고해서 벤치마킹을 좀 살펴보면
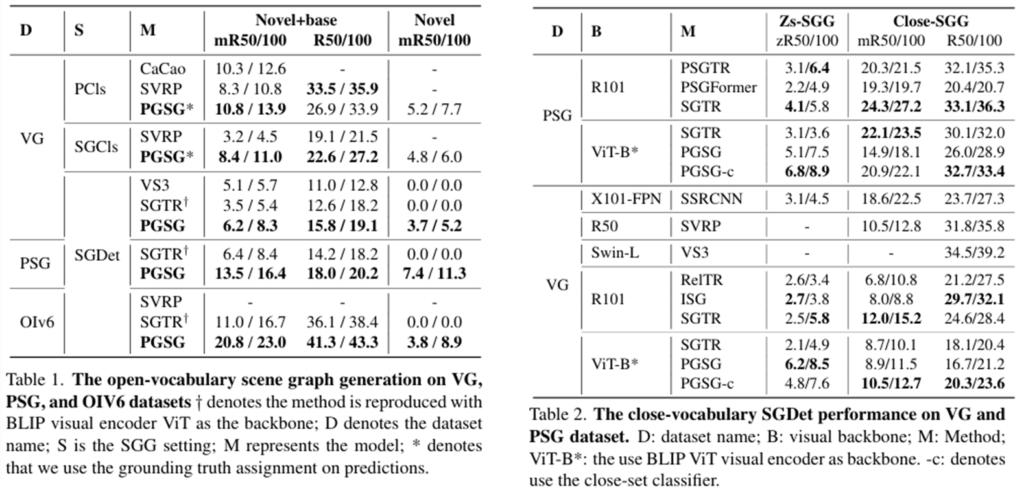
Open-vocabulary 혹은 Close-vocabulary 상황에서 모두 가장 좋은 성능을 보여주고 있습니다.
Open-Vocabulary 상황에서 기존 방법들은 평가 지표 상황에 따라 novel category를 예측 못하는 경우가 있었는데 제안하는 방법은 그런 것 상관 없이 모든 평가 지표에서 가장 우수한 성능을 보여주고 있습니다.
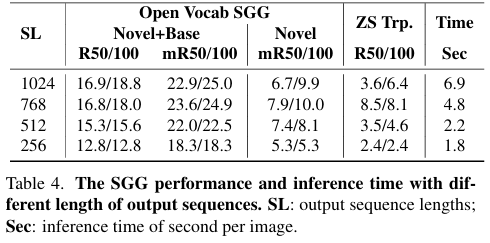
BLIP이 생성할 수 있는 최대 Sequence Length에 따른 Inference 속도를 비교하고 있습니다. 당연히 많은 output을 만들어내는 것이 더 높은 성능을 얻지만, 속도 측면에서는 trade-off 관계에 있다고 볼 수 있습니다.
제안하는 방법은 50%로 길이를 줄여도 비교적 비슷한 성능을 보여주면서 좋은 trade-off를 만족 시킨다고 주장합니다.
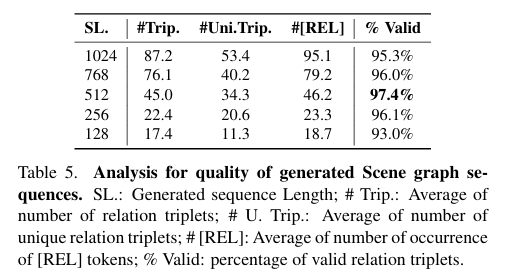
다음으로는 생성되는 relation의 퀄리티를 sequence length에 따라서 비교하고 있습니다. 당연히 sequence length가 길어지면 생성되는 triplet 그리고 relation이 많아집니다.
흥미로운 것은 sequence length가 짧아져도 생성된 relation 내에서는 valid 한 것의 비율이 굉장히 높다는 것 입니다.
이를 통해서 저자가 제안하는 방식으로 Scene Graph Sequence를 생성하는 방식의 generality를 주장하고 있습니다.
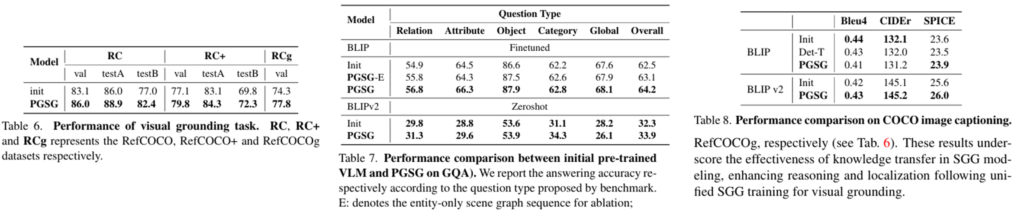
마지막으로는 다른 VL task로의 downstream 성능인데 사실 이 부분에서는 detail에 대해서는 따로 언급이 없고 기존 베이스라인 대비 다 우수한 성능을 보여준다고 합니다.
저기 아래에 Init이라고 하는 건 BLIP의 weight를 사전 학습된 weight를 그대로 활용 했을 때의 성능이라고 합니다.
Conclusion
전반적으로는 너무 BLIP에 의존하는 듯한 모습을 보여주고 있습니다. 저자도 limitation에 밝히고 있구요.
그리고 introduction 앞에서 기존 방법들은 pre-training 방식이라 학습 cost가 크다고 주장하면서 본 연구도 VLM을 다시 finetuning 하는 방식을 채택하고 있었습니다. 그러면서 freeze한 방법과 비교하고 있고…
컨셉만 novel 했던 거 같고 method 측면에서는 조금 아쉬운 부분이 있었던 거 같습니다.
리뷰 마치도록 하겠습니다.