안녕하세요. 지난 주의 MSDA (Multi-Source Domain Adaptation) for Object Detection 리뷰에 이은 MSDA-OD 논문을 리뷰하고자합니다. 지난 주 리뷰한 논문은 MSDA-OD의 시초 논문이였으나, 코드가 공개되어 있지 않았고 저자에게 문의를 했으나 역시나 답변을 받지 못하였는데 이번 논문은 코드가 일부 공개되어있습니다. 이 또한 제가 얼마전 리뷰한 Detectron2로 짜여져있으나 전체 중 일부 코드만 공개되어 있는 상황이여서 많이 아쉽습니다. 그래도 논문을 한 번 읽어보았습니다. 그럼 시작하겠습니다.
Introduction
Object Detection은 주로 Pascal-VOC -> Pascal-VOC, MS-COCO -> MS-COCO에서만 진행되고 있으므로, Pascal-VOC -> MS-COCO, 또는 MS-COCO -> Pascal-VOC의 Cross-Dataset Evaluation에서는 좋은 성능을 보이지 못합니다. 이는 Pascal-VOC (Source)와 MS-COCO (Target)의 데이터 분포 차이에서 기인하였으며 이 분포 이동 현상 (Distribution Shift)은 영상 촬영 환경, 시점, 지지리상 위치, 크기, 객체의 형상 등에 따라 다양하며 이러한 문제를 극복하고자 한 연구가 UDA (Unsupervised Domain Adpatation)입니다. 주로 Classification 태스크에서 연구되는 UDA는 Object Detection으로 오면서 Source<->Target 간의 Feature alignment, Target 데이터에 대한 Pseudo-labeling이 가장 흔한 방법입니다. 최근 앞선 두 방법을 섞은 Mean-Teacher 프레임워크는 Target에 대한 Pseudo-labeling과 지난번 리뷰에 소개한 Gradient Reversal Layer (GRL)을 통해 도메인을 식별하는 Domain Discriminator를 통합하여 Feature alignment를 진행합니다.
이 때 주류의 UDA-OD는 Single Source -> Target의 상황을 가정하는데, 이는 여러 Source 데이터가 존재하는 실용적인 상황에서는 아쉽다고 합니다. 다양한 센서, 환경에서 취득한 Source 데이터를 다량 사용할 수 있는데 그에 대한 연구가 주목받고 있진 못하는 상황이기 때문입니다. 이를 위해 아주 단순한 방법은 아래의 Fig.1-(a)에 보이는 바처럼 다양한 Source 도메인의 데이터를 단순히 섞어 하나의 데이터로 만든 이후 DA 방법론을 적용해보면 됩니다. 하지만 이전 연구들은 단순히 데이터를 합치는 방법에 비해 각각을 Source로 두는 방법이 도메인 불일치를 명시적으로 해결하는 방법으로, Adaptation 시 Source를 정렬하면 더 좋은 성능을 보임을 발견하였습니다.
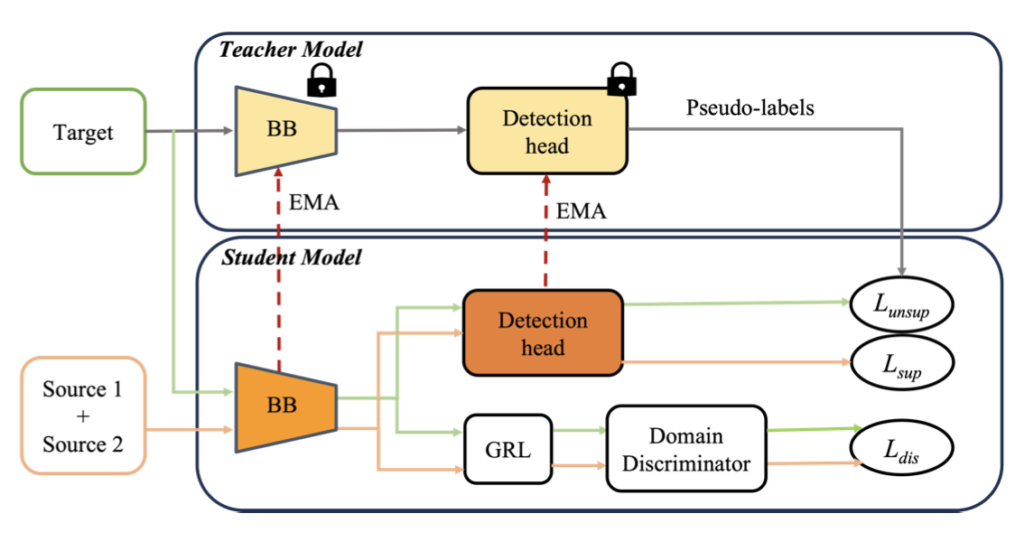
MSDA-OD의 이전 두 연구인 Divide-and-Merge Spindle Network (DMSN), Target-Relevant Knowledge Preservation (TPKP)는 각각 아래 그림의 Fig.1-(b),(c)에 해당합니다. 위 Source 1 + Source 2와는 달리 다양한 Source를 각각의 Source로 두면서 두 방법은 동시에 Domain-general, Domain-specific Feature를 추출함을 목적으로 합니다. 이전 리뷰에서 언급한 바와 같이 이 때 GRL이 사용되는데, GAN의 학습 방식과 유사하게 Domain Discriminator는 RoI의 Feature가 어느 Domain에서 온지를 판별하고, 학습 시 이를 속이고자 Gradient Reversal Layer에선 Loss를 높이는 방식을 사용합니다. 이를 통해 Domain-general (invariant) Feature를 추출함을 목표하며 (결국 Multi-Source에서도 Source 간의 Domain Shift를 줄이고자 합니다) 뒤의 Teacher-Student 모델 구성에서는 Pseudo-labeling을 통해 Domain-specific Feature를 추출함을 목표합니다.
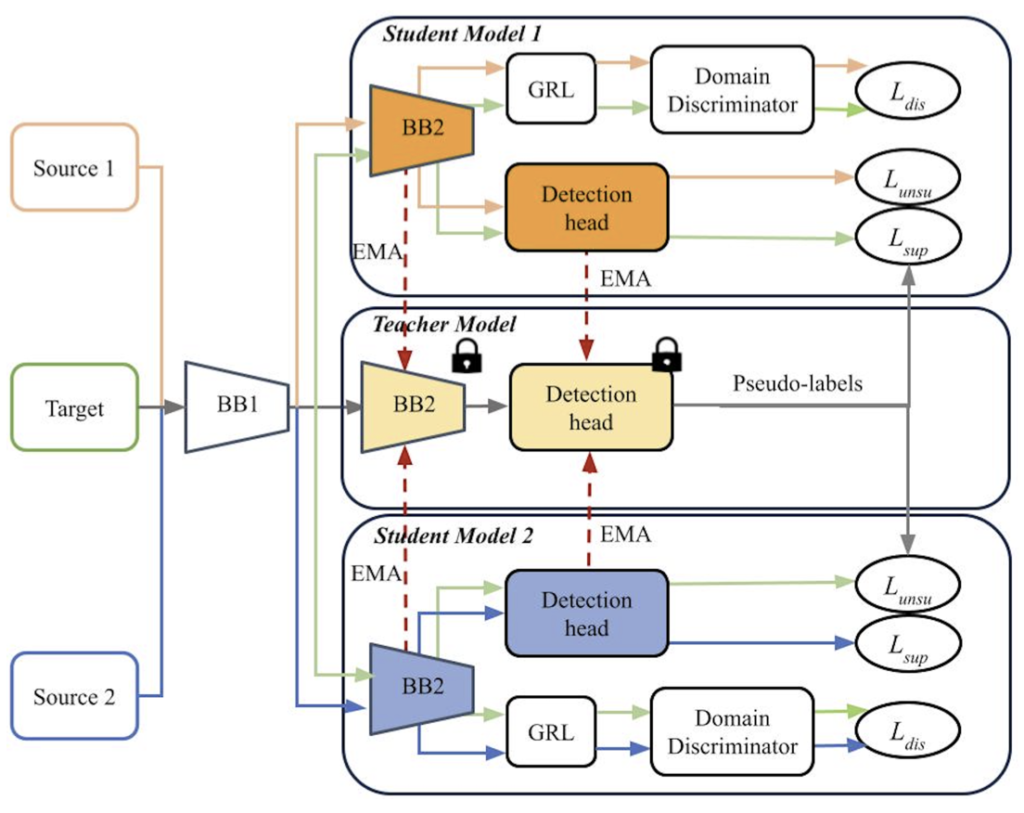
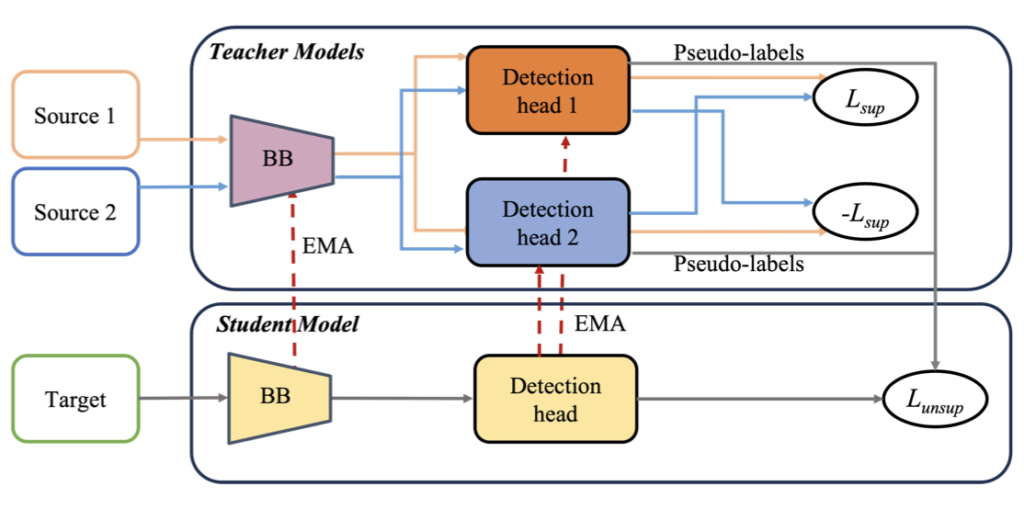
두 방법을 짚어 보면 Fig.1-(b)의 DMSN은 Mean-Teacher 학습 프레임워크를 따르며 Domain-specific student subnet이 각각의 Source domain에 존재합니다. 반면, Fig.1-(c)의 TPKP는 adversarial disentanglement 방법과 서로 다른 Source 도메인에 대해 각각의 detection head를 두어 Domain-specific knowledge를 보존하고자 합니다. Teacher detection model에서 나온 검출 결과를 Pseudo-label로 활용하여 Target 도메인의 student 모델에서 학습을 진행합니다. MSDN은 저의 이전 리뷰 논문으로 이해되었으나, TPKP는 읽어보진 않았지만 “서로 다른 Source에 대해 각각의 detection head를 둔다”는 점을 이해의 중점에 두었습니다. 두 방법은 다르긴 하지만, 공통점으로는 Multiple Source의 이점을 활용하고자 각 Source 도메인으로부터 결합한 Domain-specific weight을 학습하는 방법을 사용합니다.
위의 방법은 MSDA-OD 연구의 중점이 되었지만 두 Source 데이터만을 사용하며, 이는 Source 데이터가 많아질수록 파라미터의 수가 비례해서 늘어나기 때문입니다. 둘 이상의 Source 데이터를 사용하면, 예를 들어 위의 TPKP의 경우 언급한 바와 같이 각 Source에 대해 각각의 detection head를 두므로 Source 도메인이 많아질수록 파라미터 수도 늘어남은 당연합니다. 또한, Source 도메인의 Weighted combination이 도메인의 유사성을 통해 휴리스틱한 방식으로 설계되어 최적의 방법이 아니라고 합니다. 또한, DMSN과 TPKP는 GRL 등을 통해 도메인 간 공통된 Feature Representation Space를 찾고자 하나 카테고리의 class-wise alignment를 고려하지 않습니다. 현 방법에선 만약 Source와 Target 도메인의 외형이 많이 다르다면, Target 도메인에서의 alignment에 문제가 있는데, 이 때 class-wise alignment를 고려해야한다는 의미이며 Source 도메인의 수가 이를 극복할 수 있으나 파라미터 등을 고려할 때는 역부족입니다.
따라서, MSDA-OD는 Domain-specific Class Prototype을 학습함을 목표로하여 Domain-specific Information을 도메인 간 alignment를 목표로 합니다. Prototype이라함은 아시다싶이 어려운 방법이 아니며 새로운 방법이 아님에도, 이를 적용시킨 이유만으로 논문이 붙었다는 점이 (물론 WACV일지언정) 놀랍네요. 뒤에 보면 Method는 더욱 쉽고, 사실 쓸 내용이 많이 없는데 이전 연구의 Prototype을 도입한 Contribution 만으로도 저자는 MSDA-OD에서 더 많은 Source를 사용해도 파라미터 수가 늘어나지 않아 장점임을 강조합니다. 다만, 그렇다면 적어도 더 많은 Source를 사용해야하지 않았을까요? 이전의 연구들과 동일한 실험 세팅을 가져감은 굉장히 많이 아쉽습니다. 그럼, 얼마나 간단한 내용인지 Method를 확인해보겠습니다.
Proposed Method
MSDA 실험은 N개의 Source domain S_1, S_,2, ..., S_N 과 하나의 Target Domain T가 존재함을 가정합니다. 각 Source는 이미지와 {category, bounding box offset}을 포함한 annotation으로 구성되어 있고, Target은 이미지만 존재합니다. 보통의 UDA-OD와 MSDA-OD는 Faster R-CNN을 Base Detector로 사용하는데, 이 때의 Classification, Regression Loss도 동일하게 Cross-Entropy와 Smooth L1Loss를 차용하여 사용합니다. 이전 리뷰에서도 말했지만 아쉬운 점으로 MSDA 세팅에서 Source와 Domain이 동일한 카테고리 풀을 가지고 있음을 가정하여 사용하므로, 예를 들어 A, B의 Source와 C의 Target에서 교집합의 클래스만을 사용합니다. Source 도메인에서는 어어노테이션이 존재하기 때문에 Supervised 방식으로 학습하는데, 이를 Burn-in 스테이지로 명명합니다. Burn-in 스테이지를 통해 Target 도메인에 대해 신뢰할만한 Pseudo-labeling을 생성함은 이전 연구와 동일합니다.
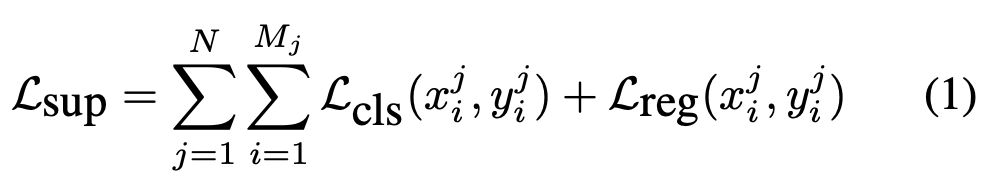
위에서 언급한 바와 같이 Target 도메인에서는 이미지만 존재하므로 Pseudo-labeling을 생성해야하는데, DMSN의 Mean-Teacher 방식을 따르며, 두 Augmentation을 통해 수행합니다. 첫 번째는 Source 도메인에 대한 Weak Augmentation으로 Rescaling, Horizontal Flip만을 사용하며, 두 번째는 Target 도메인에 대한 Strong Augmentation으로 Color jittering, Grayscale, Gaussian blur, Cutout과 같은 Pixel-level의 Transformation을 활용합니다. 이제 아래 Fig.2에 보이는 구조와 같이, Weak Augmentation 이미지 (Source)는 Teacher, String Augmentation 이미지 (Taget)는 Student 모델의 입력이 됩니다. Weak Augmentation 이미지를 입력으로하는 Teacher 모델은 Student 모델 학습을 위한 Pseudo-label을 생성하여 Student 모델을 학습시킵니다. 다만 Teacher 모델에서 생성하는 Pseudo-label은 Nosiy함이 있을 수 있으므로 Threshold를 통해 Teacher 모델의 예측을 걸러내는 작업을 진행합니다. 이때는 위의 Burn-in 스테이지 학습 Loss와 동일하게, 그러나 Pseudo-label을 활용하여 Unsupervised로써 아래 수식 (2)로 학습됩니다.
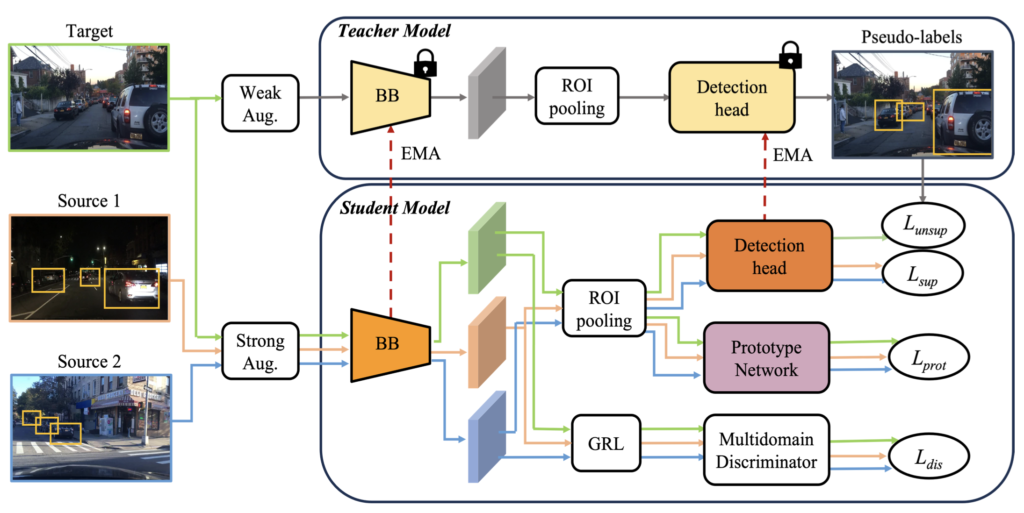
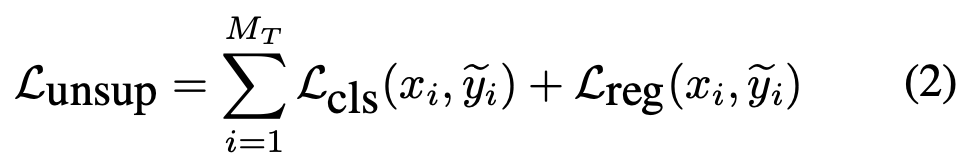
음, 저자가 처음 Contribution으로 삼은 점이 위 Framework이며, 두 번째로 내세운 점은 위 TPKP가 “각 Source 도메인마다 detection head를 따로 둔다”는 점에 착안하여, 그렇다면 각 Source마다 Domain Discriminator가 달린 점을 볼 수 있습니다 (fig.1-(b)). 그에 비해 저자는 각각의 Domain Discriminator가 아닌, Source 데이터들을 하나의 Faster R-CNN에 넣으니 Multi-class Discriminator를 제안합니다. 하하, 여러 Binary Discriminator를 하나의 Multi-Discriminator를 사용한 부분이 Contribution입니다. 너무 팬시하지 않은데, 그래서 WACV인가 싶기도하고, 코드 상 역시나 0/1, 0/1의 Multiple-Binary Discriminator를 하나로 통합시킨 것에 불과합니다. 이후에는 GRL에 대한 일반적인 설명을 이어갑니다.
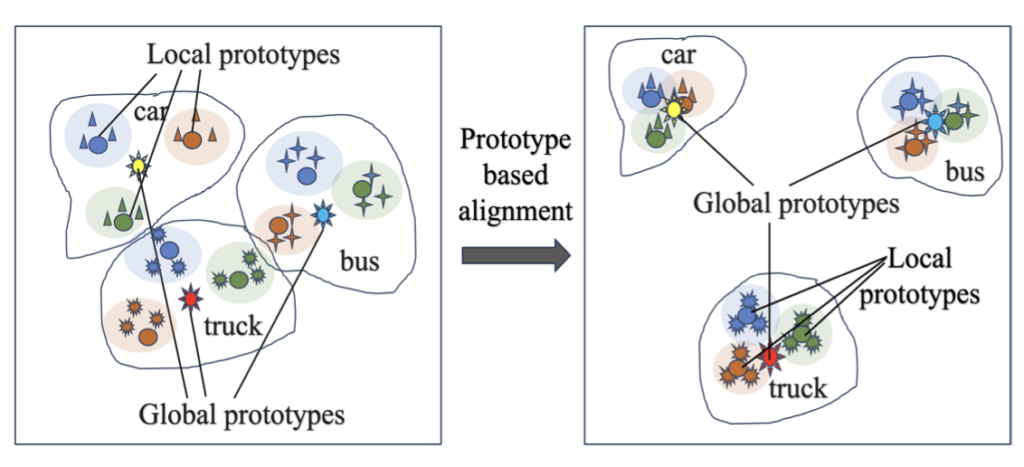
세 번째로 주장하는 Contribution이 Prototype을 활용한 점인데, 저자는 이 Prototype이 Domain-specific information을 보존할 수 있다고 합니다. 결국 Domain-specific information이 Pseudo-labeling의 신뢰성을 높이다보니, 이를 위해 Prototype을 제안합니다. 음, 이전 OWOD의 시초 논문인 ORE에서도 동일하게 Faster R-CNN을 활용하였는데, 그와 동일하게게 RoI에서 나온 2048차원을 동일 클래스끼리 묶어 평균낸 벡터를 클래스 Prototype으로 활용하며, 이 후 Contrastive loss를 통해 학습합니다. 이 때 지켜볼만한 점은 아래 fig.3에 보이는 바와 같이, 하나의 Source 도메인이 아니다보니 여러 Source 도메인을 고려한 Contrastive learning이 필요합니다. 이를 위해 저자는 각 Source 도메인에서의 클래스 당 Prototype을 Local prototype, 이후 각 Local prototype을 평균낸 Prototype을 Global prototype으로 두고, Local prototype끼리는 클래스끼리 가까워지게, 다른 클래스끼리는 멀어지게끔 학습하며 반대로 Global prototype끼리는 (어짜피 모두가 다른 클래스들이다보니) 서로 멀어지게끔 학습합니다. 이렇게하면 Domain-specific information을 보존하며 위 방식대로라면 Source 도메인이 달라도 Prototype에 묶여 유사한 Feature를 내도록 학습하겠네요. 음, 이를 수식으로 표현하지만 결국 원래 우리가 아는 Prototype 기반의 Contrastive learning과 다를 빠가 없습니다. 특이한 점으로 Memory bank의 최대 수를 따로 두지 않는데, 그렇다면 역시 Source 도메인의 수가 3,4, … 늘어나면 문제가 되지 않나, 이는 고치는게 낫지 않았나하는 아쉬움은 있습니다. 이제 실험을 한 번 보겠습니다.
Experiments
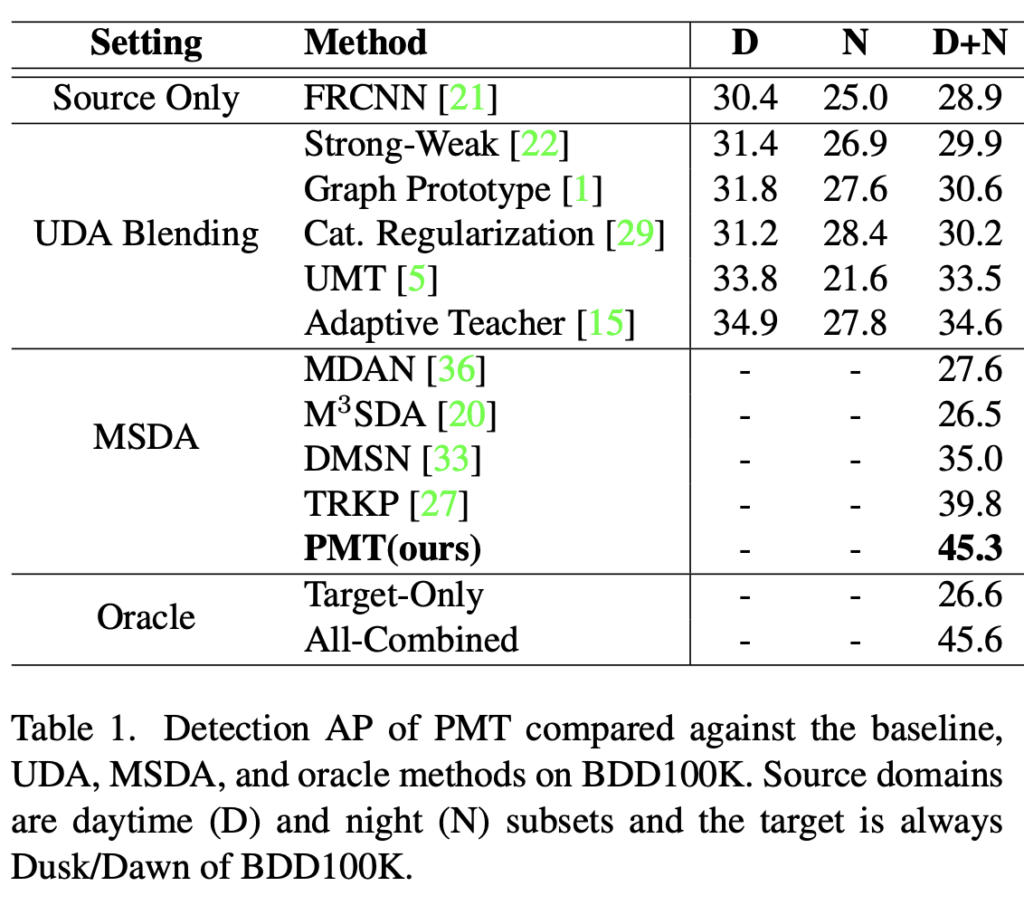
우선 실험 세팅은 이전 리뷰에서 하나 추가되었습니다. 현재 MSDA-OD는 세 가지 세팅을 가져가는데, (1) Cross Time Adaptation: 위 Table 1.은 동일한 BDD-100K 데이터에 대해 Day, Night을 Source 데이터로, Dusk/Dawn을 Target으로 사용합니다. 제가 본 실험을 위해 BDD-100K를 다운받아봤는데, 데이터의 수가 굉장히 적더라구요. 성능 자체가 MSDA에서도 PMT(ours)가 아직 45.3의 낮은 성능을 보이는데, Target-Only와 All-Combined, 타겟 데이터에 대해 학습 및 평가, 모든 데이터 (Target 어노테이션 합쳐)를 합친 성능과 비슷하다는 점을 듭니다. 다만 제 생각으론 Adaptation이 Multi-Source에선 아직 농익지는 않았다는 생각이드네요. UDA Blending, 즉 Source 도메인을 단순히 합쳐 하나의 데이터로 취급하는 방법이 효과적이라면 메모리, 시간 적으로 이득을 볼 수 있을 것으로 생각이 드는데, 그래서 그 부분을 실험해보려 합니다.
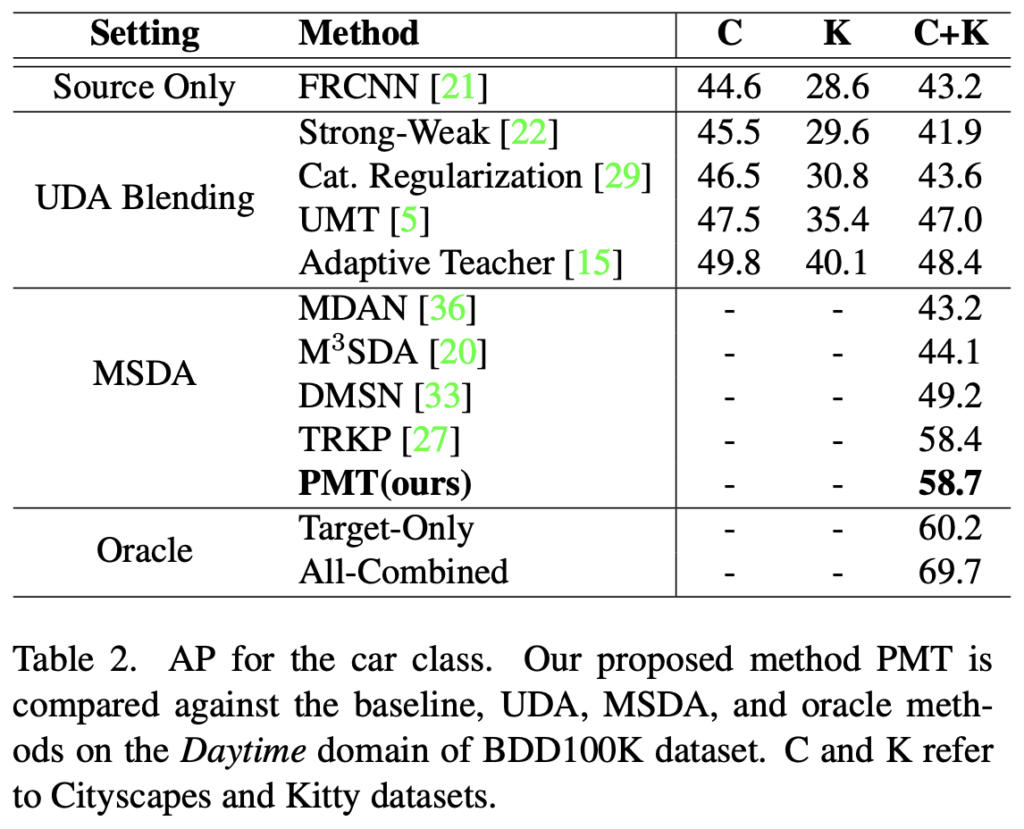
두 번째는 2) Cross Camera Adaptation: 유사한 Scene에서 다른 카메라로 촬영한 데이터에 대한 Adaptation 성능으로, C는 Cityscapes, K는 Kitty, BDD-100K의 Daytime (다른 시간대에 비해 Daytime이 더 많은 데이터를 보유중입니다)의 데이터를 사용하여 평가하였습니다. 개인적으로 Oracle이 Upper인지는 아직 의문입니다. Multi-Source가 더 많은 데이터를 사용하니 Data-driven 특성 상 현재 Oracle 기준보다 더 높은 성능을 보일 수 있지 않을까 생각합니다.
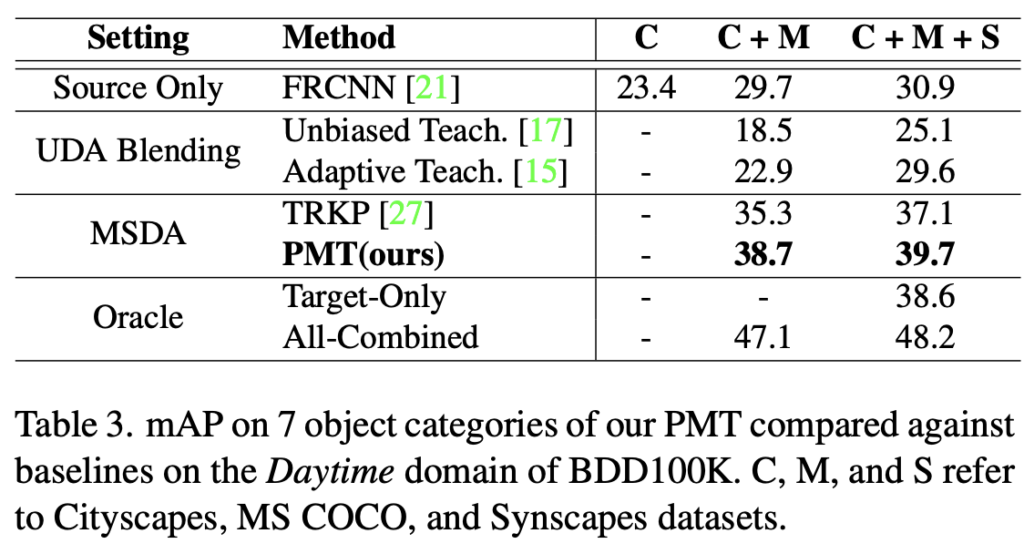
마지막으로는 3) Mixed Domain Adaptation: BDD-100K Daytime의 Target에 대해, Cityscapes, MS-COCO, Synscapes 데이터를 합쳐 평가한 성능입니다. Target이 주로 BDD-100K로 사용되며 이 때 Car 정도의 클래스만 사용되는데, 이 점도 실험 세팅에선 아쉬운 점입니다. 성능은 당연히 PMT(ours)가 모두 높지만 조금 더 관심가는 점은 아래의 Ablation study를 살펴보면 Prototype의 활용이 성능면에서 결국 41.9 -> 44.6의 2.7%정도의 성능 향상을 보이며, Source domain의 수에 따라 (음.. 5개의 Source 도메인을 사용한 성능은 리포팅되어 있지 않은데, 단순히 실험 차원에서만 진행해본 모양입니다) 그 때의 model parameter 수를 보여줍니다. 저자가 결국 하고 싶은 말은 이전의 방법론이 Domain Discriminator에 대해 각 Source 마다 가지고 있어야하다보니, 모델의 파라미터가 늘어났는데 그에 비해 파라미터의 수가 늘어나지 않은 모습이 보입니다. 코드는 공개되어 있지만, 방법론이 팬시하진 않아 아쉬웠습니다. 이상으로 리뷰는 여기서 마치도록 하겠습니다.
리뷰 잘 읽었습니다.
제가 그때 얼핏 듣기론, Multi-Source DA for OD 연구가 3개밖에 없다고 했는데 그게 Fig.1 – (a),(b),(c) 인건가요?? (그게 아니라, 서베이한 논문이 3개였다는 건가요?)
3개밖에 없다는 가정 하에,,, 이 3개 녀석들의 한계점은 명확히 보이네요. 상인님이 리뷰에서 언급하시긴 했찌만, (b)의 경우 source dataset의 갯수 만큼의 student model을 가져가는 점이 명확한 한계점이네요. n개의 source일 경우 n개의 model이라니 허허,,
그리고 (c)는 적혀진 내용이 적어서 명확히 파악은 못했다만, class-wise alignment 고려가 없다는 식으로 적혀있는 걸 보아 object level이 아닌 image level 에서의 alignment만 수행했다는 거 같네요. (맞나요?? ㅋㅋ) 만약 맞다면, 이 부분을 object level alignment 까지 가져가도 괜찮을 거 같네요. 실제로 제가 최근에 읽은 CVPR 최근 TTA-OD 논문에서도 기존 연구들은 image-level alignment만을 고려했다는 점을 찝어서 object level alignment를 위한 썸띵을 추가하거든요.
—–
본 논문의 method 설명 부분에서 memory bank의 최대 수? 와 관련된 언급이 있는데, memory bank 개념이 어디에 적용이 되는걸까요??
—-
그리고 그냥 이건 의견 공유차 끄적이는 겁니다.
저번 리뷰때 다룬 논문과, 이번에 리뷰해주신 논문 모두 discriminator 기반의 feature alignment 과정이 포함되네요. UDA-SS(Segmentation) 분야에서는 약 2021년 이후 discriminator 기반의 feature alingment 를 통해 분포를 맞추는 것이 능사가 아니다! 라는 주장들이 등장하면서 최근 3년의 논문을 까보면 대부분 discriminator 없이 self-training 기반으로 학습을 진행합니다. source 모델 target 모델을 구성한 뒤 i) parameter 공유 ii) mean-teacher 기반 update, 이렇게 둘 중 하나로 진행하고, source 모델의 예측을 target model의 pseudo label로 사용하게 되는데 이 과정 속에서 thresholding 기반으로 확실한 confident pixel에 대해서만 loss 계산을 진행하게 되죠. 요 개념을 조금 섞어도 괜찮을 듯 합니다.
또한 제가 오늘 리뷰한 논문에서는, source와 target의 class가 서로 상이한 open-set 세팅에서의 tta를 다루게 되는데, target 에 새로 등장하는 open class로 부터 비롯된 잘못된 예측이 noisy 로 동작해서 점차적으로 error 누적이 된다고 합니다. 실제로 성능 하락도 크게 발생하구요. 그 점도 좀 녹여서, 물론 평가는 교집합 class에 대해 수행한다 한들 학습 시에 noise 가 될 만한 그런 class 정보는 특정 기준을 통해 filtering 하고 학습을 진행하는 기법을 추가해도 괜찮을 거 같습니다.
아직 이쪽 multi source 분야를 제대로 읽어보지 않아서 잘 모르겠지만, 연구들이 많이 없는 거 같다 보니 기법적으로 개선할만한 contribution은 시도해볼만한 것이 여러가지 존재할 듯 합니다.
다만 걱정은 dataset 및 실험 세팅… 이 되겠ㅈ네요 ㅎㅎㅎ
암튼 리뷰 잘 읽었습니다
안녕하세요 이상인 연구원님. 좋은 리뷰 감사합니다.
리뷰를 읽고 궁금한 점이 있는데요, TPKP에서는 각 source 마다 detection head를 따로 두었으나 [Fig.2]에서는 하나의 detection head를 사용한 것으로 이해하였습니다. 그렇다면 학습을 진행할 때 source1, source2에 대해서는 2개의 L_sup, target은 L_unsup으로 학습을 진행하게 될 텐데 detection head의 loss는 단순히 3개의 loss를 더한 것으로 구해지나요?