안녕하세요.
오늘 리뷰할 논문도 마찬가지로 Test-Time Adaptation 관련 논문입니다.
TTA 관련 논문을 찾아보던 도중 Open-Set 키워드가 함께 들어있어서 읽어보게 되었습니다.
시작 전에 말씀드리자면, 본 논문은 Open-Set class 에 대해 직접적으로 class prediction 을 하는 것은 아니며, open-set class의 경우 noisy한 결과를 유발할 수 있기 때문에 적절하게 filtering 을 하여 adaptation을 수행하는 논문입니다.
그럼 리뷰 시작하도록 하겠습니다.
1. Introduction
real world로의 application을 고려하는 TTA 기법들은 보통 continual domain shift, 즉 test 단계에 하나가 아닌 여러 domain shift를 마주하는 상황에 대해서도 고려하게 됩니다. 그리고 특성 상 짧지 않은, long-term adaptation을 수행하죠.
일반적으로 TTA 에서는 test 시에 마주하는 target sample 에 대한 gt 없이, model의 예측값에 의존하여 adaptation을 수행해 나갑니다. 예를 들면 model prediction 의 entropy를 최소화해 나가는 방향으로 말이죠. 하지만 이 경우 특정 noisy sample로 부터 발생하는 noisy signal 때문에 안정적인 adaptation에 방해가 된다고 합니다. 그리고 이러한 noisy signal은 i) incorrect prediction, ii) open set prediction 이렇게 2가지로 부터 비롯된다고 합니다.
저자는 이런 noisy signal 때문에 long-term TTA 수행 시 error accumulation 현상이 발생하고 불안정한 adaptation이 수행된다고 합니다. 저자는 이러한 noisy signal이 왜 문제가 되는지 introduction 단계에서 여러가지 실험을 수행하며 독자들을 납득시키게 됩니다. 아래에서 천천히 설명드리겠습니다.
본 논문에서는 i) incorrect, ii) open-set prediction 으로 부터 비롯된 noisy signal에 대한 이해를 위한 figure를 제공하고 있습니다. 두 요소를 함께 보여주기 위해 source train set을 CityScapes dataset으로, target test set을 BDD-100K dataset으로 사용한 open-set 상황에서 진행하였습니다.
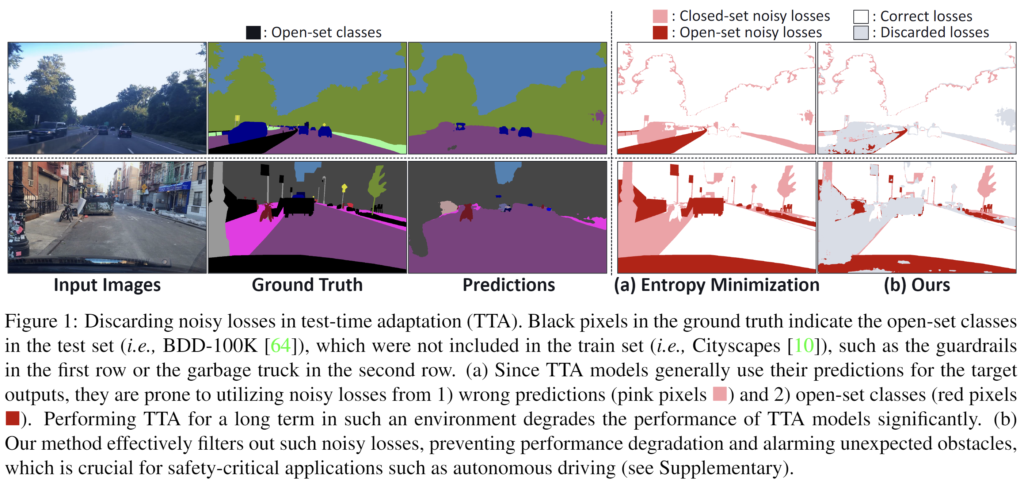
위 결과는 BDD-100K dataset 중 2개의 test sample에 대한 결과입니다. GT 와 Prediction을 살펴보시면 결과 성능 차이가 꽤나 많이 나는것을 볼 수 있습니다. 저자는 이렇게 잘못 예측된 영역에 대해 우측 (a)를 언급하며, 2가지 이유 때문이라고 합니다. 바로 위에서 말씀드렸던 i) incorrect, ii) open-set prediction 이녀석들이죠. incorrect prediction에 대응되는 부분이 분홍색 (closed set noisy losses) 이고, open-set prediction에 대응되는 것이 빨간색 (open-set noisy losses) 입니다. 그리고 이러한 noisy signal을 불러 일으키는 영역들에 대해서는 (b) 속 회색(discarded losses) 에 보시는 것 처럼 loss 계산 시 고려하지 않는 식의 기법을 설계하게 됩니다. 컨셉적으로는 이렇구요, 자세한 식은 method 부분에서 다루겠습니다.
저자는 위 결과를 보여주며, 앞선 TTA 연구들의 open-set 관련 문제에 대해 지적합니다.
real-world의 application적인 관점에서 봤을 때 TTA 는 분명히 open-set classes 상황을 다루어야만 하는데, 이전 연구들은 그러지 못했다는 것이죠.
이에 대해 이전 연구들은 오직 covariate shifts (i.e., domain shifts) 만을 다루었고, semantic shifts (i.e., including open set classes) 는 다루지 않았다고 표현합니다. 아래 figure는 이전 연구들과의 차별성을 보여줍니다.
사실 뭐 대단한 의미가 담긴 figure는 아닙니다.
둘 중 좌측 classification 에 대한 그림을 보시면 기존 연구들은 y축 방향인 covariate shift만을 고려하여 CIFAR-10 -> CIFAR-10-C , SVHN -> SVHN-C 로의 TTA를 수행하였다면, 본 논문에서는 x축 방향인 semantic shift를 고려하여 CIFAR-10-C -> SVHN-C 이런 식의 open-set class 상황도 반영하였다는것입니다.
또한 저자들은 특정 실험을 통해 중요한 실험적 분석을 진행합니다. 우선 figure 먼저 첨부하고 설명 이어가겠습니다.
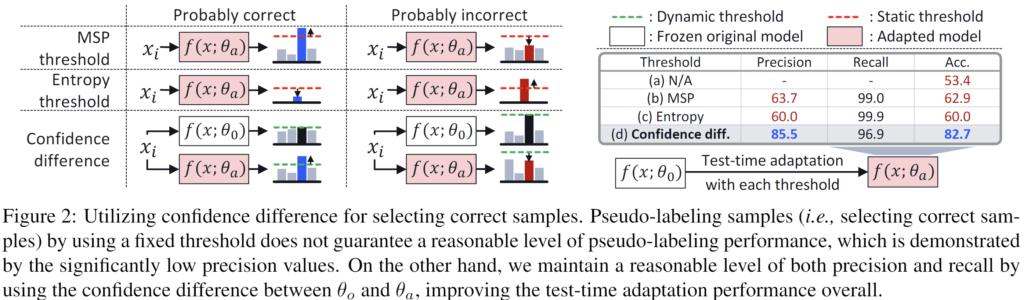
일반적으로 TTA 논문들에서 가장 많이 활용하는 최적화 방식은 entropy 최소화 방식입니다. 이 entropy 최소화는 결국 모델 예측의 불확실성을 최소화하는 것이기 때문에 예측의 confidence를 높이는 방향으로 진행되고자 하겠죠.
하지만 실험적으로 특정 wrong samples들에 대해서는 confidence 값을 높이는 데에 실패하는 경우가 많다고 합니다. 이전 연구들에서도 이러한 문제들을 발견하였고 이런 wrong samples들로 부터 비롯된 error accumulation을 방지하기 위해 적절한 threshold 값을 설정하여 confidence 혹은 loss를 기준으로 filtering 하는 방식들이 제안되었지만, 이러한 정적인 threshold 방식을 사용하게 되면 성능이 제한적이라고 합니다. 뭐 직관적으로 납득이 되는 부분입니다.
실험적 비교를 위해 2021년 제안된 TENT 방법론을 baseline 삼아서 각 threshold 기법 별 실험적 비교를 수행합니다. 그 결과는 위 figure 2에 해당합니다.
우선 MSP threshold 방식은 confidence value 가 0.9 이상인 sample을 고르는 것이며, 우측 table의 (b) MSP 에 해당합니다.
Entropy threshold 방식은 entropy value가 특정 threshold 보다 낮은 sample 을 고르는 것이며, 우측 table의 (c) Entropy에 해당합니다.
마지막으로 Confidence difference 방식은 본 논문에서 제안하는 방식입니다. source 에 대해 학습된 기존 모델 \theta_o에 비해 adaptation이 수행중인 모델 \theta_a 에서의 confidence value가 더 높은 sample만을 골라서 수행하는 방식이며, 우측 table의 (d) Confidence diff. 방식에 해당합니다.
우측 table 의 (a) N/A 는 아무런 threshold 적용 없이 TTA를 수행 한 것입니다.
우측의 성능 측면(Precision, ACC)에서 보시면 고정적인 threshold 를 사용하는 b,c 에 비해 본 논문의 d가 더 성능적인 측면에서 우수한 것을 볼 수 있습니다.
다만 b,c 에서는 recall은 높지만 precision이 낮은 것으로 보아 noisy sample을 걸러내지 못하고 단순히 대부분의 샘플을 선택하는 것을 의미한다고 합니다.
저자들은 confidence difference 를 사용하는 직관적인 이유에 대해 설명합니다.
entropy 최소화 전략은 불확실성을 줄이는 방향으로 모델이 update를 수행하기 때문에 결국 모델 예측의 confidence를 높이는 방향으로 update가 진행되도록 강제(enforce) 합니다. 하지만 모델의 다른 수많은 예측에서 비롯된 ‘wisdom of crowds – 군중의 지혜‘ 와 일치하지 않는 noisy signal에 대해서는 entropy를 최소화하면서 confidence값을 높이려고 해도 실제로는 confidence 값이 오르지 않는다는 것을 실험으로 보여줍니다.
이러한 실험을 기반으로 source 에 대해 학습된 기존 모델 \theta_o에 비해 adaptation이 수행중인 모델 \theta_a 에서의 confidence value가 더 높은 sample 만을 고르게 됩니다. 각 sample 별로 model의 knowledge를 반영하여 confidecne 값이 계산되기 때문에, 암묵적으로 동적인 confidence thresholding 기법이라고 볼 수 있습니다. 또한 설계한 기법은 classication 뿐만 아니라 semantic segmentation 에서도 높은 성능을 달성하였다고 합니다.
2. Wisdom of Crowds in Entropy Minimization
2.1. Problem Setup
notation에 대한 간략한 설명입니다.
source 에 대해 학습된 기존 모델을 \theta_o, adaptation이 수행중인 모델을 \theta_a 라고 합니다.
test sample x 에 대해 각 모델의 softmax output을 \tilde{y}=f(x;\theta_o), \hat{y}=f(x;\theta_a) 라고 정의하게 됩니다. 각각 class 수 C 만큼의 차원을 가집니다.
또한 sample x 에 대해 각 모델이 예측한 confidence 값을 \tilde{y}^{c_o}, \hat{y}^{c_o} 라고 표현합니다.
2.2. Motivation
Decreased confidence values
앞서도 설명드렸다시피, 이상적으로라면 entropy 최소화 전략을 통해 모든 test sample 의 confidence 값이 올라야 정상입니다. 하지만 특정 noisy (wrong) sample 에 대해서는 오히려 confindence 가 하락하는, 즉 \hat{y}^{c_o} < \tilde{y}^{c_o} 의 경우가 발생한다고 합니다. adaptation을 했더니 오히려 confidence가 감소해버렸단거죠. 이와 관련된 실험을 아래 figure로 포현합니다.
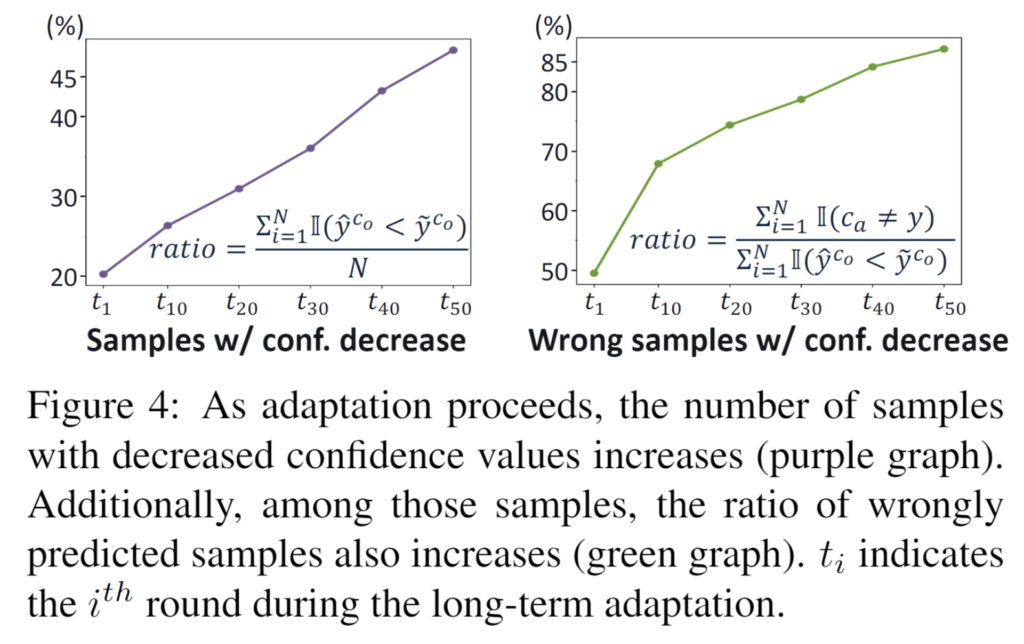
두 그래프에서 x축 t는 test time adapation이 점차적으로 수행되는 시간의 흐름, 즉 round 수를 나타냅니다. 각 라운드에서 15가지 corruption type을 모두 마주하게 되고, 동일한 변화가 총 50 라운드 동안 반복되게 됩니다.
좌측 그래프는 전체 test sample 대비 confidence 가 감소한 sample의 비율을 나타냅니다. 이상적으로라면 round가 점차적으로 진행됨에 따라 ratio 가 하락하는, 우하향 그래프로 그려져야겠죠. 하지만 너무나도 우상향입니다. entropy minimization을 수행함에도 불구하고 confidence 가 기존 대비 하락하는 sample 이 점차적으로 많아진다는 뜻이죠.
또한 우측 그래프는 confidence 가 기존 대비 하락하는 sample 중 class 예측 마저 틀린 sample의 비율을 의미합니다. 이 또한 round 가 진행됨에 따라 우상향 하는 것을 보여줍니다. confidence 가 하락하는 sample 중 상당 비율이 잘못된 예측을 수행하고 있으며 이 비율 또한 급격한 속도로 향상하는 것입니다.
저자는 이러한 결과의 이유는 많은 다른 test samples들로부터 학습된 signal인 ‘wisdom of crowds‘ 가 개별 sample의 confidence에 영향을 미치기 때문이라고 합니다. 솔직히 논문에 영어로 작성된 표현이 명쾌하게 와닿지 않아서,,,, 제 주관을 조금 섞어서 이해해보자면,
대부분의 많은 test samples가 생성해내는 공통된 ‘wisdom of crowds‘ 정보가 있는데, 예를들어 2개의 noisy sample 에 대해 예측해낸 signal이 ‘wisdom of crowds‘ 와 상이하다면, entropy minimization을 통해 confidence 값을 올려야 합니다. 이 때 2개의 noisy sample이 서로 반대되는 패턴을 보이게 된다면 전체적인 측면으로 상쇄되어 버리기 때문에 개별 요소적으로 고려가 되지 않습니다. 따라서 이러한 noisy sample들의 경우 confidence 가 높아지지 못하는 것입니다.
Wisdom of crowds from correct samples
또한 실험을 통해 모델이 ‘wisdom of crowds‘ 정보를 일반적으로 correct samples로 부터 학습한다는 점을 밝혔습니다.
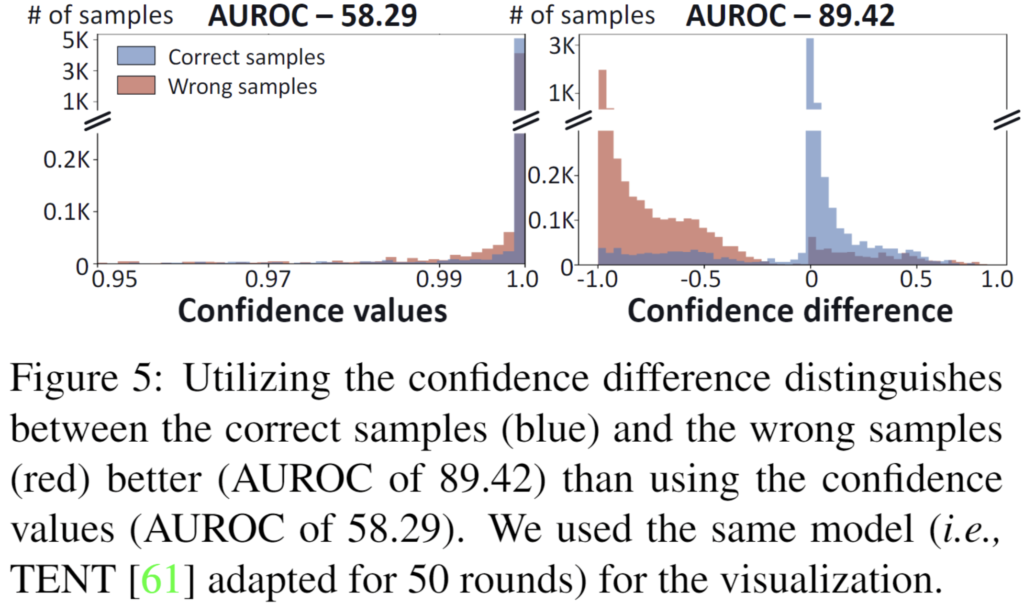
위 그래프는 confidence와 모델 예측 성공의 상관성을 보여주고 있습니다.
우측 그래프의 x축은 \hat{y}^{c_o} – \tilde{y}^{c_o} 를 의미합니다. 해당 값이 0보다 크다면 adaptation 이후 모델 예측의 confidence가 더 높다는 것을 의미합니다.
0 이상 영역에는 대부분 파랑색, 즉 올바른 예측을 수행한 correct samples가 분포해 있네요.
반대로 0 이하의 영역에는 대부분 빨강색, 즉 잘못된 예측을 수행한 wrong samples 가 분포해 있네요.
위 결과를 통해 얻을 수 있는 정보는 2가지입니다.
우선 \hat{y}^{c_o} > \tilde{y}^{c_o} 를 달성하는 샘플은 대부분 올바른 샘플이므로 confidence 값을 높이는 데 필요한 지배적인 신호(즉, ‘wisdom of crowds‘)는 올바른 샘플에서 비롯됩니다.
또한 \hat{y}^{c_o} – \tilde{y}^{c_o} 를 기반으로 correct sample과 wrong sample 을 구별하는 것이 적절하다는 것입니다.
Misalinged wrong signals
추가적으로 본 논문에서는 wrong samples 로 부터 발생하는 signal이 모델의 confidence를 높이는 데에 실패하는 이유를 실증적으로 분석합니다. 이에 가장 큰 이유는 wrong samples로 부터 발생하는 signal이 correct samples로 부터 생성된 ‘wisdom of crowds’ 와 일치하지 않기 때문이라고 합니다.
이에 대한 분석을 위해 동일한 predicted label을 가지는 두 test samples 사이의 ‘cosine similarity of gradients’ 를 계산합니다. 아래 식으로 말이죠,
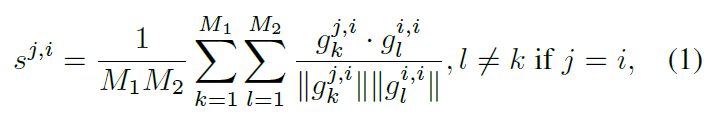
<notation>
g_k^{j,i}: gt label이 j인 M1개의 sample 중 k번째의 sample과, 이에 대한 predicted label i 사이의 gradient vector
g_l^{i,i}: gt label이 i인 M2개의 sample 중 l번째의 sample과, 이에 대한 predicted label i 사이의 gradient vector (즉 correct samples를 의미)
위 식 계산을 통해 아래 figure의 좌측 similarity map 을 생성할 수 있습니다.
계산 과정에 대해 조금 풀어서 설명해보자면, 임의의 predicted label i에 대해 1) gt label도 i인 correct samples로 부터 생성된 gradient g_l^{i,i}와, 2) gt label이 j인 wrong or correct(j=i) samples로 부터 생성된 gradient g_k^{j,i} 사이의 similarity 를 구하는 것입니다.
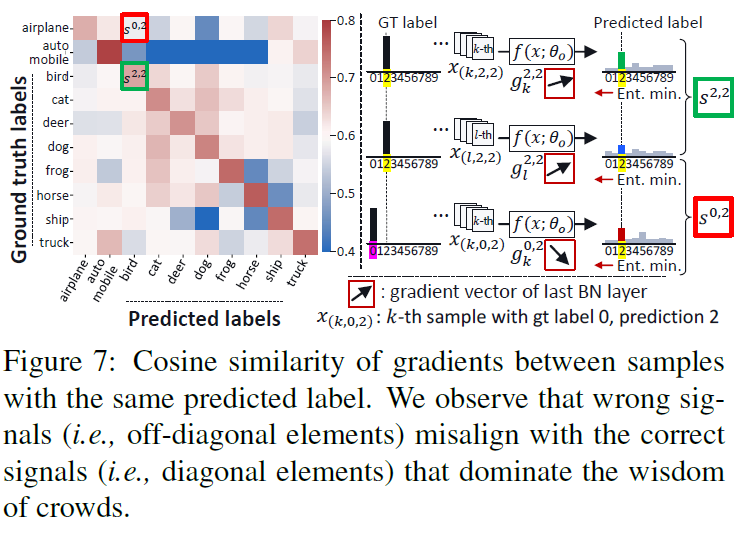
위 similarity matrix의 diagonal elements는 s^{j,i} 에서의 j와 i가 같은, 즉 predicted label과 gt label이 일치하는 경우에서의 gradient similarity를 나타냅니다. 그리고 diagonal 이외의 elements는 특정 predicted label i에 대해 1) gt label도 i인 경우(correct)와, 2) gt label이 j인 경우(wrong)를 비교하여 구한 similarity 입니다. correct와 wrong 사이의 gradient 차이가 크다면 similarity 값이 그만큼 작게 나오겠죠.
위 좌측 그림에서 correct sample (s^{2,2}) 는 wrong sample (s^{0,2})에 비해 더 높은 기울기에 대한 cosine similarity 값을 보여줍니다. 이 중 ‘wisdom of crowds’를 지배하는 것은 correct samples 이므로, 이에 대응하는 noisy samples는 걸러주어야 합니다. 거르지 않는다면 long-term continual TTA 상황 속에서 성능을 크게 저하시킨다고 합니다.
이러한 noisy samples를 거르고자 위에서 설명드린 confidence difference 기법을 기반으로 한 sample 선택 방식을 설계합니다.
2.3. Proposed Method
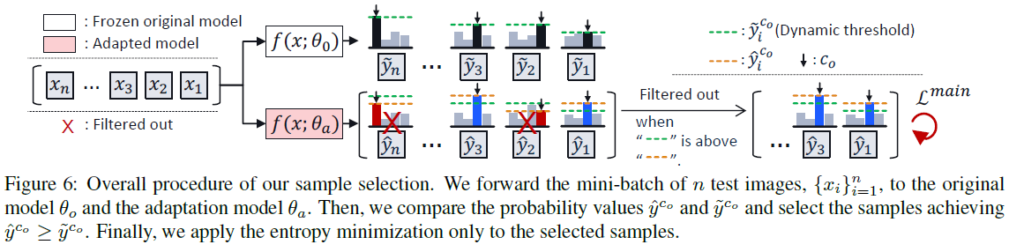
TTA 수행 시 사용할 test sample을 선별하는 criterion을 아래 수식으로 정의합니다.
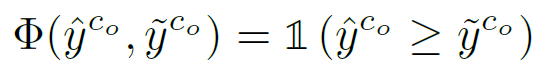
위 수식이 의미하는 바는,
original model 대비 adaptation 수행중인 model의 confidence 값이 더 높은 sample을 선택하겠다 라는 뜻입니다.
그리고 위 criterion을 반영한 전제 목적 함수는 아래와 같습니다.
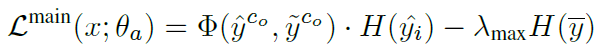
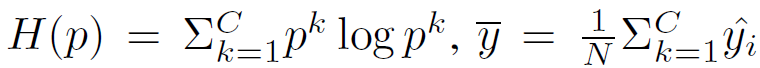
해당 수식의 앞쪽 term을 통해 결국 criterion 을 통해 선별된 test sample에 대해서만 최적화를 진행하겠다는 것이며,
뒤쪽 term은 이전 연구들에서 사용된 class imbalanced 해결을 위해 설계된 것을 가져와서 적용하였다고 합니다.
3. Experiment
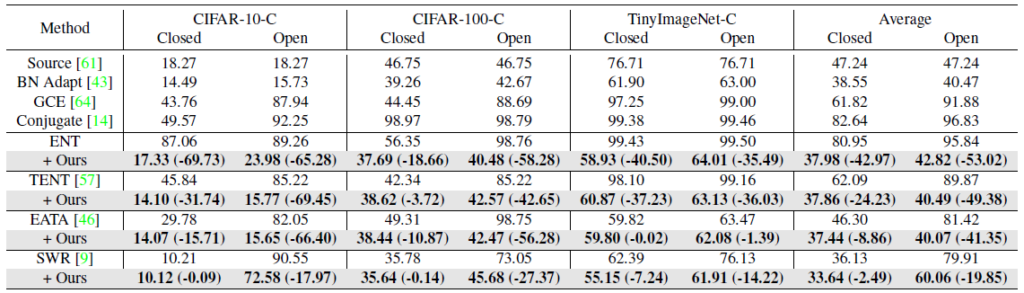
우선 classification에서의 TTA 결과입니다.
50 rounds의 long-term TTA를 수행한 이후의 실험 결과이며, 평가 지표는 error rate 입니다.
각 test dataset 별 Closed, Open에 대한 source target 구성을 말씀드리겠습니다.
CIFAR-10-C 평가의 경우 Closed 에서는 CIFAR-10 을 source로, Open에서는 SVHN Dataset을 사용했다고 합니다.
CIFAR-100-C 평가의 경우 Closed 에서는 CIFAR-100 을 source로, Open에서는 마찬가지로 SVHN Dataset을 사용했다고 합니다.
반면, TinyImagenet-C 평가의 경우 Closed 에서는 TinyImagenet을 source로, Open에서는 ImageNet-O Dataset을 사용했다고 합니다.
저자들이 설계한 test sample 설계 방식을 기존 4개의 방법론에 부착하였을때의 error rate 하락폭을 위주로 살펴보시면 될 듯 합니다.
confidence difference 기반의 noisy sample filtering 방식이 closed set에서도 효과를 톡톡히 보여주며, 특히 open-set 에서의 향상폭이 엄청나게 큰것을 볼 수 있습니다.
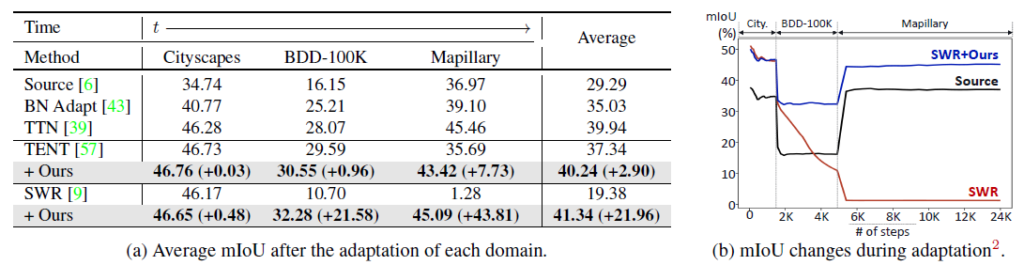
위 실험 결과는 semantic segmentation 에서의 실험 결과입니다.
GTAV 라고 하는 합성 dataset 으로 학습된 모델을 real-domain dataset 3가지에 대해 continual 방식으로 TTA를 수행하였네요.
당연히 Ours를 부착한 모델이 가장 error accumulation을 잘 완화 및 해결한 것을 볼 수 있습니다.
다만 조금 살펴봐야 할 점은 우측 (b)에서 source와 SWR의 차이입니다.
source 는 source pretrained 모델을 아무런 adaptation 과정 없이 단순 inference만 했을때의 성능입니다. 반면 SWR은 ECCV 2022년에 소개된 TTA 기법이죠.
그럼에도 불구하고, SWR은 open-set continual TTA 상황에서 성능이 기하급수적으로 하락하는 것을 볼 수 있습니다. 모델의 error accumulation 이라는 현상이 성능과 엄청나게 연관성이 있는 아주 치명적인 요소인가 보네요..
오늘은 open-set 개념이 조금 섞인 tta 논문을 읽어 보았습니다.
읽으면서 제 역량이 조금 부족한 탓인지, Wisdom of Crowds 라는 개념이 잘 와닿지 않아서 읽고 리뷰를 쓰는데에 조금 어려움이 있었습니다. 그래서 그런지 작성된 리뷰도 뭔가 매끄럽지 못하네요..
그리고 마지막 실험에서 error accumulation 현상이 상상 이상으로 치명적인 문제점이라는 것을 알게 되었습니다. 왜 다들 Continual TTA 연구에서 해당 문제점을 해결하려고 하는지 어느정도 알겠네요.
그리고 또 아무런 adaptation을 수행하지 않은 source pretrained 모델로 그냥 inference 하는 것이 ours 와 비교했을 때에 (dataset 마다 조금 다르겠지만) 엄청나게 성능차이가 크지 않은점도 조금 신기하네요.
오늘 리뷰는 여기서 마치도록 하겠습니다. 감사합니다.
안녕하세요. 석준님!
좋은 리뷰 감사합니다.
글을 읽던 중 한 가지 질문 사항이 생겨 댓글 남깁니다!
(1) 해당 방법론을 Samples로 예측한 signal이 ‘wisdom of crowds’과 다르면 이것들을 noisy한 samples로 판단하여 confidence differece기법을 통해 loss연산 시 해당 샘플을 마스킹해서 배제한다고 이해하였습니다.
그렇다면 실제 application환경에서도 confidence differece를 계산하기 위해서 두 모델을 포팅한 후, 두 번에 inferece를 거쳐야하는 것인지 궁금합니다.
감사합니다.