제가 이번에 리뷰할 논문은 투명 객체에 대한 Pose Estimation을 수행한 논문입니다. 저는 투명 객체에 대한 pose 추정을 위해 열화상을 사용하는 것의 효과를 확인하기 위한 실험을 하고 있고, 투명 객체에 대한 기존의 pose 추정 방법론은 어떻게 진행되고있는지 확인하고자 읽게 되었습니다.
Abstract
투명한 물체는 시각적 특징이 뚜렷하지 않기 때문에 물체 감지와 위치 파악이 어렵습니다. 또한 일반적으로 사용되는 depth 센서는 반사되는 특성으로 인해 투명한 객체의 표면에 대한 정확한 깊이 정보를 측정하기 어렵습니다. 이러한 문제로 인해 컵과 같은 투명 객체는 동일 카테고리의 불투명한 객체보다 구분력이 떨어진다고 합니다. 이러한 관찰을 기반으로 저자들은 instance-level의 pose 추정이 아닌 category-level의 pose 추정의 가능성을 확인하고자 하였다고 합니다. 저자들은 localized depth completion과 surface normal estimation를 이용하여 category-level의 pose를 추정하는 2-stage pipline인 TransNet을 제안합니다. TransNet은 대량의 투명 물체 데이터셋에 대하여 category-level의 SOTA알고리즘들과 비교를 수행하며, 비교 결과를 통해 TransNet이 투명 물체에서 개선된 pose 추정 정확도를 달성한다는 것을 보입니다. 또한 로봇 pick-and-place 및 pouring 작업을 위한 조작 시스템 구축에 TransNet을 사용하였다고 합니다.
Introduction
유리문, 창문, 각종 용기 등 투명 객체는 일상 생활 속에서 널리 사용되고있으며, 이러한 투명 물체의 pose를 인식하는 것은 환경과의 상호작용하려는 자율 인식 시스템에서 중요한 문제입니다. 그러나 투명한 객체는 RGB와 Depth 영역 모두 인식에 어려움이 있습니다. 먼저 RGB 색상의 경우 투명 물체의 반사 및 굴절 효과로 인해 배경, 시야각, 재질 및 조명에 따라 크게 달라진다는 문제가 있으며, 일반적으로 사용되는 depth 센서의 경우 투명한 영역 내에서 유효하지 않거나 부정확한 측정값을 제공합니다. 이러한 문제로 인해 투명 객체를 인식하는 것이 어려우며 이는 자율 물체 조작 및 장애물 회피와 같은 작업에서 심각한 문제를 야기하게 됩니다. 본 논문에서는 end-to-end 학습 방식을 이용하여 category-level의 투명 객체 pose 추정 방식을 연구함으로써 해당 문제를 해결하고자 합니다.
최근 연구들은 손실된 depth 값을 채운 뒤 기하학적 정보를 기반으로 하는 방식, RGB 기반의 transfer learning, Domain Randomized depth noise simulation등의 방식을 통해 성능 개선을 이루어왔습니다. instance-level의 투명 객체 pose 추정은 stereo 나 RGB-D 이미지의 keypoint를 추정하거나 평면을 추정하는 등의 방식으로 추정할 수 있으며, 최근 투명 객체에 대한 대규모 데이터 셋의 등장으로 딥러닝을 활용한 연구가 가능해졌다고 합니다.
본 논문에서는 TransNet을 제안하여 category-level pose 추정의 정확도를 개선하고, 입력 모달라티, feature embedding 방식, depth-normal consistency의 효과를 검증하며, TransNet을 이용한 자율 물체 조작 시스템을 구축하여 pick-and-place와 pouring 작업에서 효과를 입증합니다.
Method
투명 객체를 포함하는 장면에 대한 RGB-D 쌍(\mathcal{I,D})이 주어졌을 때, 물체의 6D pose [\mathbf{R|t}]와 3D scale \mathbf{s}, 사전에 정의된 범 주 중 객체가 포함되는 class를 추정하는 것을 목표로 합니다. 이때 투명 객체의 이미지 영역에 부정확하거나 유효하지 않은 depth값이 존재하며, category-level의 pose 추정을 위해 2단계의 pose 추정 파이프라인인 TransNet을 제안합니다.
A. Architecture Overview
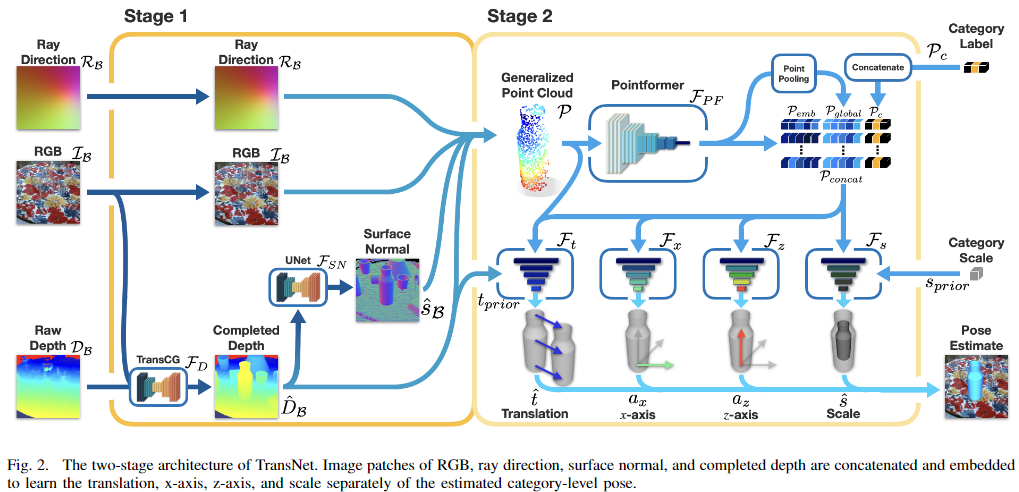
TransNet은 미세조정된 instance segmentation 모듈을 통해 전체 이미지에서 객체 영역에 대한 패치를 먼저 추출합니다. 위의 Fig. 2는 TrasnNet의 구조로, 객체 영역에 대한 패치를 입력으로 받아 투명 객체에 해당하는 multi-modal feature를 추출합니다. RGB-D 패치에 대하여 depth completion과 surface normal 추정을 적용하여 두 작업간의 consistency를 통해 depth-normal 쌍을 얻고, 이를 RGB와 ray direction 패치와 함께 concat한 다음 instance 마스크 내에서 무작위 샘플링 방식을 사용하여 Generalized point cloud라고 하는 특징을 생성합니다. Stage 2에서는 Generalized point cloud를 PointFormer를 통과시켜 embedded feature vector를 생성한 뒤, 4개의 개별 decoder 모듈을 통해 Translation과 x축과 z축, Scale 정보를 추정합니다.
B. Object Instance Detection and Segmentation
다른 Category-level pose 추정과 유사하게 Mask R-CNN을 finetuning하여 object의 bounding box \mathcal{B}, mask \mathcal{M}, 카테고리 라벨 \mathcal{P}_c을 얻습니다. \mathcal{B}에 따라 패치 (ray direction \mathcal{R_B}, RGB 패치 \mathcal{I_B}, depth \mathcal{D_B})를 추출하여 TransNet의 Stage 1에 입력합니다. UV mapping은 이미지 내에서 해당 패치의 상대적 위치와 크기 정보를 제공하기 때문에 중요한 단서로 작동하며, 본 논문에서는 UV mapping 대신 카메라의 intrinsic 정보를 포함하는 ray direction을 이용합니다. 여기서 ray direction \mathcal{R}은 카메라 원점에서 카메라 프레임의 각 픽셀까지의 방향을 나타내며 각 픽셀 (u,v)에 대하여 아래의 식(1)을 적용합니다.
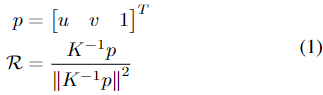
- p: 이미지 평면에서의 homogeneous UV 좌표
- K: 카메라의 intrinsic matrix
C. Cross-task Consistency for Depth-Normal Pairs
Depth completion의 SOTA 방법론인 TransCG^{[1]} (\mathcal{F}_D)와 surface noraml 추정을 위해 U-Net^{[2]} (\mathcal{F}_{SN})을 적용합니다.
[1] H. Fang, H.-S. Fang, S. Xu, and C. Lu, “Transcg: A large-scale real- world dataset for transparent object depth completion and grasping,” arXiv preprint arXiv:2202.08471, 2022
[2] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Con- ference on Medical Image Computing and Computer-assisted Inter- vention. Springer, 2015, pp. 234–241.
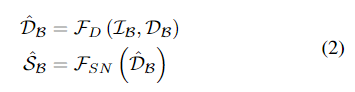
- \mathcal{\hat{D}_B}: 추정된 Depth 값으로 surface normal 추정의 입력으로 사용
두 모델은 처음에는 별도의 depth loss \mathcal{L}_d 와 surface noamal loss \mathcal{L}_s로 학습되며, 이후 함께 cross-task consistency를 이용하여 학습됩니다. consistency loss \mathcal{L}_{con}은 두 네트워크를 함께 학습하기 위해 설계되었으며, \mathcal{L}_d와 \mathcal{L}_s는 투명 객체에 대한 마스크 \mathcal{M} 내에서 depth completion과 surface normal estimation을 위한 L2 loss로 정의되며 아래의 식으로 정의됩니다.
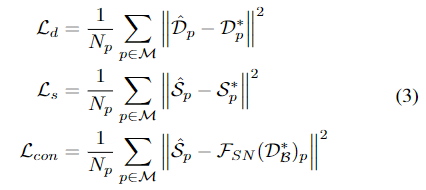
- \mathcal{D^*, S^*}: GT depth와 GT surface normal 이미지
- N_p: 마스킹 영역의 픽셀
consistency loss를 보면 예측된 depth값으로 구한 surface noraml 추정치와, GT depth값으로 구한 surface noraml의 추정치가 동일하도록 설계되어있습니다. cross-task consistency 학습을 통해 두 네트워크를 학습한 뒤, 해당 모듈은 이후 frozen 되어 Stage 2에 입력을 생성합니다.
D. Generalized Point Cloud
Generalized Point Cloud는 멀티모달 입력의 feature(\mathcal{I_B,R_B,\hat{D}_B, \hat{S}_B} )를 통해 구현됩니다. 마스크\mathcal{M} 내에서 N개의 픽셀을 무작위로 샘플링하여 Generalized Point Cloud \mathcal{P}∈ \mathbb{R}^{N ⨉ 10} 을 구합니다.
E. Transformer Feature embedding
Generalized Point Cloud \mathcal{P}가 주어졌을 때 대상 객체를 인식하기 위해 TransNet은 multi-stage Transformer를 기반으로 point cloud를 임베딩하는 Pointformer를 이용하여 객체의 feature \mathcal{P}_{emb} \in \mathbb{R}^{N⨉d_{emb}}를 구합니다.
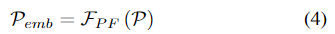
그다음, global feature \mathcal{P}_{global}를 추출하기 위해 1개의 MLP와 maxpooling으로 이루어진 Point Pooling layer를 적용하며 global feature는 local feature \mathcal{P}_{emb}와 instance segmentation으로 구한 one-hot 카테고리 \mathcal{P}_C와 연결되어 decoder의 입력으로 사용할 feature vector를 생성합니다.
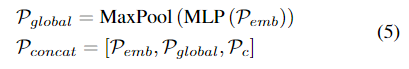
F. Pose and Scale Estimation
그 다음 4개의 별도의 decoder를 이용하여 객체의 translation과 x축/z축/scale을 추정하게 됩니다.
Translation Residual Estimation
translation decoder\mathcal{F}_t는 샘플링된 point cloud \mathcal{P}의 평균 3D translation으로 구한 translation prior t_{prior}로부터 residual값을 학습합니다.
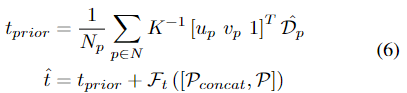
- u_p, v_p : 2D 픽셀좌표
GT와 추정치에 대한 L1 loss를 이용하여 loss를 구합니다.

Rotation Estimation
3D rotation R을 두개의 직교하는 x축(a_x)과 z축(a_z)을 추정합니다. 네트워크는 추정된 두 축이 orthogonal하지 않는 문제를 해결하기 위해 confidence값을 학습합니다.
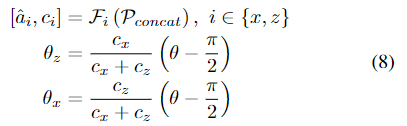
- c_x,c_z : 각 축에 대한 confidence
- θ: a_x와 a_z 사이의 각
- θ_x, θ_z : 최적화로 구한 공통 평면 위에서 두 축을 회전하는 데 사용
loss는 각 개별 축에 대한 L1와 cosine similarity loss \mathcal{L}_{r_x}, \mathcal{L}_{r_z}를 더한 값을 이용하며, 각도에 대한 loss \mathcal{L}_a는 두 축 사이의 수직 관계 제약에 사용되며 축 신뢰도를 학습하기 위해 \mathcal{L}_{{con}_x}, \mathcal{L}_{{con}_z}를 이용하며 각 loss는 아래의 식으로 정의됩니다.
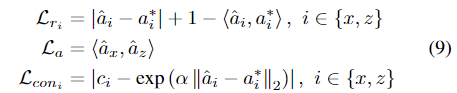
- | | : L1 loss
- <>: cosine similarity
- \alpha: 거리를 조정하는 상수
이렇게 두번째 Stage에서의 loss 는 아래의 식 (10)으로 정리되며, 각 \lambda는 각 loss의 가중치를 의미하며 실험적으로 \{λ_{r_x} , λ_{r_z} , λ_{r_a} , λ_t, λ_s, λ{con_x} , λ_{con_z} \} = \{8, 8, 4, 8, 8, 1, 1\} e^{−4}로 설정하였다고 합니다.
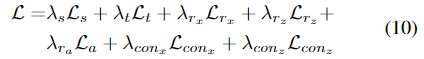
Scale Residual Estimation
translation decoder와 유사하게 각 카테고리의 3D CAD 모델들의 평균 scale을 이용하여 scale에 대한 prior s_{prior}를 정의한 뒤, 추정하고자 하는 객체의 scale은 아래의 식 (11)로 구합니다.
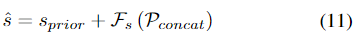
loss는 L1 loss를 이용하여 GT와 추정 치를 비교합니다.

Experiments
Dataset

Clearpose Dataset에 대하여 평가를 수행하였으며, Clearpose Dataset은 3개의 카테고리(bowl, water_cup, wine_cup)에서 33개의 투명 인스턴스를 선택하였으며, 위의 Fig. 3에서 투명 객체의 예시를 확인할 수 있습니다. 33개 중 25개의 object를 학습에 사용하였으며, 학습하지 않은 8개의 객체에 대한 평가를 수행합니다. 190K 이미지로 학습을 하며, 60K개의 평가 이미지를 균등하게 샘플링하여 각 객체별로 5K개의 이미지로 test set을 구성하였다고 합니다.
또한, 로봇의 manipulation 실험을 위해 1개의 bowl과 1wine_cup과 함께 로봇의 그리퍼에 맞는 새로운 wine_cup 1개와 시중에서 구매한 2개의 water_cup을 이용하였다고 합니다.
Evaluation metrics
category-level의 pose 추정을 위해 25%, 50%, 75%의 IoU를 임계치로 평가를 수행합니다. 추가로 5°5cm, 10°5cm,10°10cm를 평가지표로 사용하며, 이는 각 기준의 회전 및 이동 변환의 오차가 임계값보다 작을 경우 정답으로 간주합니다.
depth completion의 평가를 위해 RMSE와 REL(absolute relative error), MAE를이용하여 \delta_{1.05}, \delta_{1.10},\delta_{1.25} 를 구하며, \delta_n은 아래의 식을 통해 구합니다.
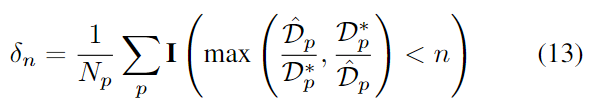
- \mathbf{I}( ): indicator 함수(특정 조건 만족하면 1, 아니면 0)
- \mathcal{\hat{D}}_p, \mathcal{D^*}_p: 각 픽셀 p에 대하여 예측된 depth와 GT depth
surface normal estimation을 평가하기 위해 11.25°,22.5°, 30°를 임계값으로 정규화된 벡터의 RMSE와 MAE 오차를 측정합니다. 11.25°에 대한 지표는 오차각이 11.25° 이내의 백분율을 나타내며 평균 각도의 오차(MEAN)도 리포팅합니다.
Comparison with Baseline
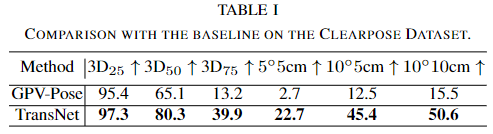
- SOTA pose 추정 알고리즘인 GPV-Pose[3]를 베이스라인으로 선정하였으며, 공정한 비교를 위해 TransCG 네트워크로 보완된 depth값을 이용하였다고 합니다.
- Table 1에서 TransNet은 Clearpose 데이터셋의 대부분의 평가지표에서 우수한 성능을 보였으며 정성적 결과는 아래의 Fig. 4에서 확인하실 수 있습니다.

[3]Y. Di, R. Zhang, Z. Lou, F. Manhardt, X. Ji, N. Navab, and F. Tombari, “Gpv-pose: Category-level object pose estimation via geometry-guided point-wise voting,” arXiv preprint arXiv:2203.07918, 2022
Ablation Study
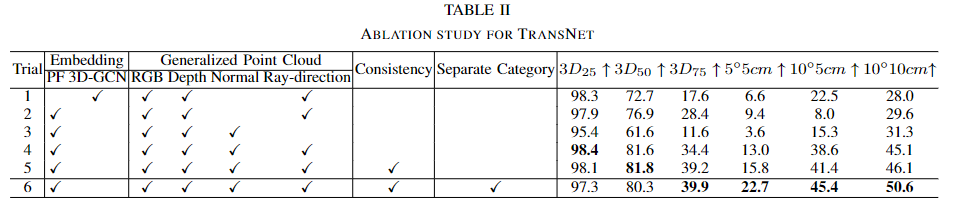
- 위의 Table 2는 TransNet의 성능과 네트워크 구조를 실험한 것으로, embedding 방식에 3D-GCN과 Pointformer에 대한 비교를 통해 Pointformer가 더 효과적임을 확인하였으며, Generalized Point Cloud를 생성할 때 어떤 feature를 융합하여 사용하는 것이 효과적인지에 대한 실험도 진행하였습니다.
1. Embedding 방식에 대한 비교
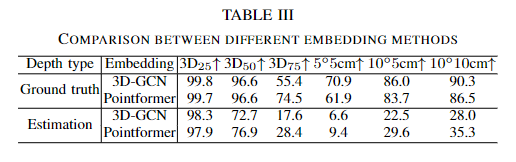
Pointformer와 3D-GCN을 비교한 결과 추정된 depth값에서 대부분 Pointformer가 더 높은 정확도를 유지함을 아래의 Table 3을 통해 확인할 수 있습니다. 이는 3D-GCN이 가장 가까운 이웃값의 정보를 전파하는 방식이므로, local한 정보를 전달하는 것에는 효과적이지만, 노이즈가 발생할 경우 문제가 발생하게 되며, Poinformer의 경우 전체 point cloud에서 정보를 공유하기 때문에 depth에 노이즈가 발생하더라도 더 견고하게 작동할 수 있다고 분석하였습니다. 따라서 투명 객체에서 노이즈가 포함될 가능성을 고려하여 Pointformer를 선택하였습니다.
2. Generalized Point Cloud의 모달리티에 대한 비교
위의 Table 2에서 실험 2~4는 최적의 입력 조합을 찾기 위한 실험으로 2와 4 실험을 통해 surface normal을 이용할 경우의 효과를 확인할 수 있습니다. 이에 대해 저자들은 투명 객체와 같이 depth 값이 정확하지 않을 경우 surface normal 이 정보를 보완하는 데 도움이 된다는 것을 의미한다고 분석하였습니다. 또한 실험 3과 4의 비교를 통해 ray-direction정보를 포함할 경우 성능 개선이 이루어짐을 보였으며, 모든 지표에서 surface normal과 ray-direction을 모두 이용할 경우 pose 정확도가 개선된다는 것을 실험적으로 확인하였습니다.
3. Consistent Learning
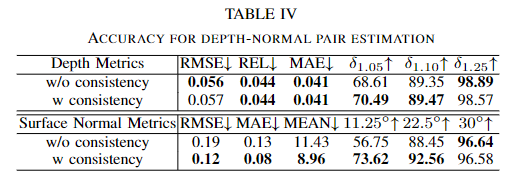
Table 2의 실험 4와 5는 consistency에 대한 고려에 따른 실험 결과로, 실험 4은 depth completion과 surface normal estimation을 각각 학습하였으며, 실험 5는 cross-task consistency를 추가하여 실험을 진행한 것으로, 일관성을 고려할 경우 성능이 개선됨을 실험적으로 확인하였습니다. 또한 아래의 Table 4는 depth completion과 surface normal estimation에서 consistency를 고려할 경우 성능을 비교한 것으로 대체로 성능이 개선된 것을 확인할 수 있습니다.
4. Separate Category
Table 2의 실험 5와 6은 카테고리에 대해 여러 인스턴스를 학습하는 것과 카테고리별로 모델을 하나의 인스턴스로 만들어 학습하는 것의 효과를 비교한 것으로 TransNet은 카테고리별로 단일 인스턴스화하여 학습하는 것이 성능이 개선됨을 실험적으로 확인하였습니다.
Robot Experiment
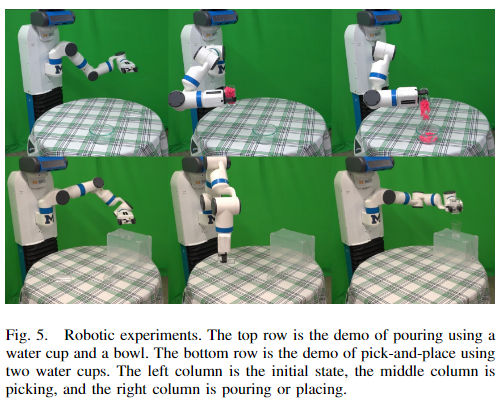
조작을 위해 Fetch 로봇을 이용하였으며 Clearpose 데이터 셋에서 사용된 RGB-D 정보를 촬영하기 위해 Intel Realsense L515 센서를 활용하였다고 합니다. 앞서 dataset 파트에서 설명한 대로 총 5개의 투명 객체에 대하여 평가를 수행하였다고 합니다.
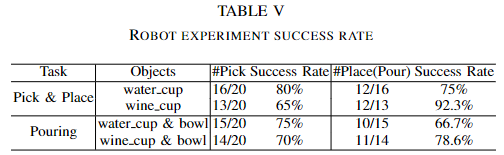
위의 Table 5는 두 작업의 성공률을 나타냅니다. 저자들에 따르면 promising 한 성공률을 달성하였다고 합니다. (그러나 베이스라인 방법론의 성공률은 나와있지 않아서.. 아쉽습니다..)
안녕하세요 이승현 연구원님 리뷰 잘 읽었습니다.
리뷰를 읽다 궁금한 점이 생겨 질문 남깁니다.
F. Pose and Scale Estimation 부분에서… “네트워크는 추정된 두 축이 orthogonal하지 않는 문제를 해결하기 위해 confidence값을 학습합니다.” 라고 하셨는데… confidence로 이를 어떻게 해결한다는 것인지, 추정한 x, z축의 각도 교정과 confidence 사이의 관계가 이해가 가지 않는데 추가적으로 설명해주실 수 있을까요?
안녕하세요 승현님 좋은 리뷰 감사합니다.
본문의 용어 중에 surface normal에 대해 질문이 있습니다. 일단 surface normal이 무엇이고 어떤 정보를 처리하는데 사용되는지가 궁금합니다. 그리고 이러한 surface normal 정보는 이후 cloud point를 생성하는데 사용이 되는건가요??
감사합니다