안녕하세요 박성준 연구원입니다. 제가 오늘 리뷰할 논문은 Moment Retrieval을 weak supervision으로 다룬 방법론입니다. weakly supervised moment retrieval은 영상과 자연어 쿼리만 주어지고 쿼리에 해당하는 구간이 annotation이 되어 잊지 않은 데이터로 학습을 수행하는 task입니다.
Abstract
temporal sentence grounding(moment retrieval)은 비디오에서 자연어 설명에 해당하는 구간을 찾는 것을 목표로 하는 task입니다. 대부분의 기존의 weakly supervised temporal sentence grounding 연구들은 일치하지 않는 비디오와 언어 쌍을 negative 샘플로 선정하고 negative proposal과 구별되는 positive proposal을 생성하는 방식을 사용하고 있습니다. 하지만 비디오의 복잡한 temporal 구조 때문에 negative proposal로부터 positive proposal을 더 잘 구분하는 방식은 때로 정확하지 않은 ground truth(GT)를 생성할 수 있습니다. 저자는 위와 같은 문제를 해결하기 위해 uncertainty기반의 self-training 기술을 도입하여 weakly-supervised 학습에 추가적인 supervision을 제공합니다. self-training 프로세스는 teacher-student mutual learning 방식을 기반으로 weak-strong augmentation을 포함하고 있습니다. 저자는 추가로 여기에 베이지안 teacher network를 도입하고 temporal data augmentation을 인한 cycle 일관성을 활용하여 teacher network와 student network의 상호 학습의 효율을 올렸습니다. 기존의 weakly-supervised 방법론에 저자가 제안하는 방법을 추가하는 것으로 성능을 올릴 수 있다고 주장합니다.
Introduction
temporal sentence grounding(moment retrieval)은 자연어 쿼리의 설명에 해당하는 구간을 반환하는 task로 구체적으로는 해당하는 구간의 시작점과 끝점을 반환하는 task입니다. 따라서 fully-supervised 학습을 위해서는 자연어 쿼리에 해당하는 구간의 시작점과 끝점이 annotation되어 있어야합니다. 저자는 방대한 인터넷 속에 존재하는 많은 데이터를 활용하여 학습을 하기 위하여 영상에 annotation을 사용하는 것은 사실상 불가능하다고 언급하며 weakly-supervised temporal sentence grounding(이후로는 moment retireval (MR)로 서술하겠습니다)의 필요성을 강조합니다. 또한, 연구의 확장성 그리고 실생활에서의 실현가능성의 관점에서도 weakly-supervised MR 연구의 필요성을 강조하고 있습니다. MR에서의 weakly-supervised 학습은 쿼리와 영상은 주어지지만, 쿼리에 해당하는 구간의 시작점과 끝점을 알려주지 않습니다. 즉, 영상과 영상내 한 event에 대해 쿼리로 설명이 주어지면 모델이 알아서 자연어 쿼리에 해당하는 구간을 학습해야하는 challenging한 task입니다. 기존의 방법론들이 이 challenging한 task를 해결하기 위하여 채택한 방법은 Multiple Instance Learning(MIL) 방법입니다. 이 방법은 일치하지 않는 비디오와 자연어 쿼리 쌍을 생성하고 negative sample로 칭합니다. 그리고 모델로 하여금 negative sample과 positive sample을 구분할 수 있도록 학습합니다. 여기서의 negative sample들은 대개 쿼리와 쿼리가 존재하지 않는 다른 영상을 쌍으로 설정하는 경우가 많습니다. 하지만, 위의 방법에서 사용하는 negative sample은 때때로 구별하기가 쉬워 strong supervision을 제공할 수 없다는 문제가 존재합니다. 이러한 문제를 해결하기 위해 negative sample을 쿼리가 존재하는 같은 영상에서 쿼리에 해당하지 않는 구간을 사용하여 negative sample을 선정하여 모델이 더 헷갈려하게끔 유도하는 방법도 존재합니다. 하지만, 저자는 이러한 방법들은 negative sample에 지나치게 의존하여 학습하는 근본적인 문제를 해결하지 못한다고 지적합니다. 또한 negative sample과 positive sample을 구별하기 위해 일반적으로는 거리를 계산하는 방식을 사용합니다. 하지만, 종종 여러 event를 포함하고 있는 복잡한 영상의 경우에는 복잡한 시간적 구조로 인해 negative sample과 구별된다고해서 positive sample이 올바르게 선정되었다고 말할 수 없습니다.
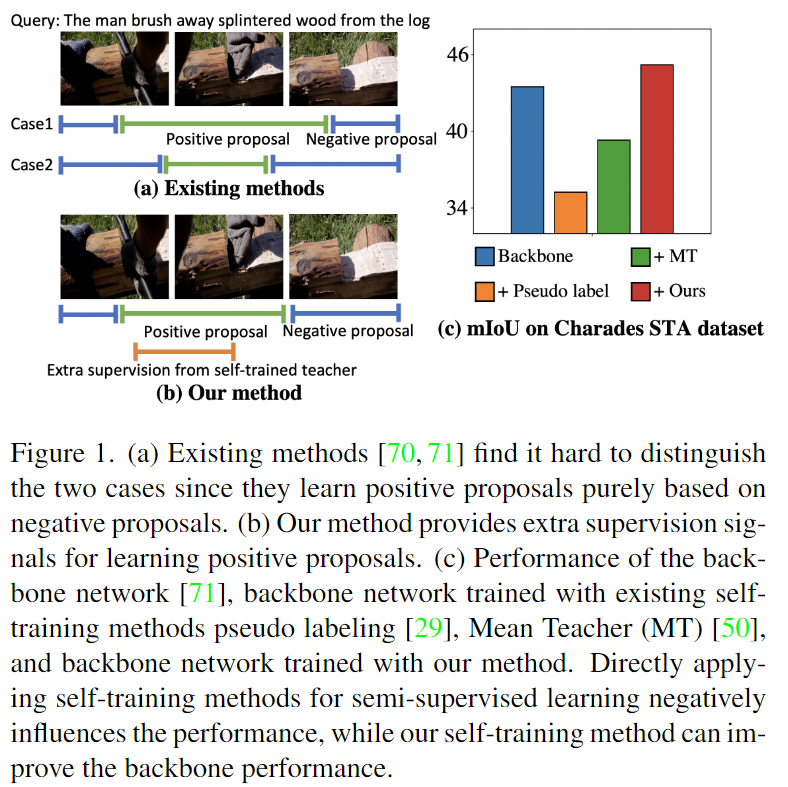
Figure1.에서 (a)는 기존의 negative sample로부터 거리를 계산하여 positive sample을 구하는 기존의 방법으로 positive proposal이 온전히 negative에 의존하기에 정확하지 않을 수 있기에 positive proposal의 정확도를 확신할 수 없습니다.
저자는 이러한 문제점을 해결하기 위하여 self-supervised 학습의 기법을 통해 모델에 추가적인 supervision을 제공하는 것으로 해결하고자 합니다. negative sample에만 의존하여 positive sample을 생성하는 것이 아닌 다른 supervision을 제공하여 positive proposal가 negative sample외에 고려할게 생겨 positive proposal의 신뢰를 높일 수 있다는 것이 저자의 견해입니다. Figure1.의 (b)는 저자가 기존의 방법론에 추가적인(extra) supervision을 더해줘 positive proposal이 더 정확해지는 것을 보여줍니다. 하지만, 저자는 추가적인 supervison을 제공하는 것은 신중해야한다고 언급하며 Figure 1.의 (c)를 설명합니다. backbone에 저자의 방법론을 추가하여 추가적인 supervision을 제공하는 것은 성능에 개선이 있었지만, 다른 self-supervised 기반의 방법론을 backbone에 추가하는 것은 성능을 올리는 것이 아니라 오히려 성능을 해치는 결과를 보여줍니다. 그 이유로 teacher의 supervision이 noisy하기에 오류들이 축적하게 된다면 성능을 해칠 가능성이 높기 때문이라고 합니다.
또한 저자는 weak-strong augmentation 방법을 추가적으로 사용합니다. student 방법에는 strong augmentation을 진행하고 teacher에는 weak augmentation을 진행하는 방식으로 teacher network는 student network에 비해 strong augmentation의 영향을 덜 받는 출력을 생성하여 student network에 supervision guidance를 제공할 수 있습니다. 추가적으로 저자는 두개의 방법을 더 사용하였는데 첫번째 방법은 베이지안 teacher network를 사용하는 것으로 teacher network 자체는 처음에는 weak supervision만으로 학습되고 잘못된 supervision guidance를 제공할 수 있으므로 베이지안 teacher network를 사용하여 uncertainty를 추정할 수 있게 합니다. 추정된 uncertatinty는 teacher network의 supervision signal을 측정하여 오류가 축적되는 것을 방지하는 데에 사용됩니다. 두번째 방법은 cyclic mutual learning을 사용하는 겁니다. teacher와 student를 모두 효율적으로 업데이트하기 위하여 forward 사이클에서는 student network가 teacher와 함께 temporally consistent representation을 출력하도록 합니다. backward 사이클에서는 teacher의 출력이 여러가지 augmentation을 거친 student의 출력들에 일관적일 수 있도록 합니다.
정리하면, 저자는 weakly-supervised MR 연구가 확장성과 실생활 적용가능성의 관점에서 필수적이라 주장하며 연구의 필요성을 설명한 뒤 기존의 negative sample을 생성하고 negative sample과 구별되는 positive sample을 생성하는 방법론들이 가지고 있었던 학습에서의 negative sample에 지나치게 의존하는 문제를 제기합니다. 문제 해결을 위해 저자는 self-supervised 연구에서 활용되는 teacher-student를 활용하는 MIL 방법을 추가하여 추가적인 supervision을 제공함으로 negative sample에 과하게 의존하지 않게하고 베이지안 teacher, cyclic mutual learning을 추가하여 모델의 성능을 올렸습니다.
Method
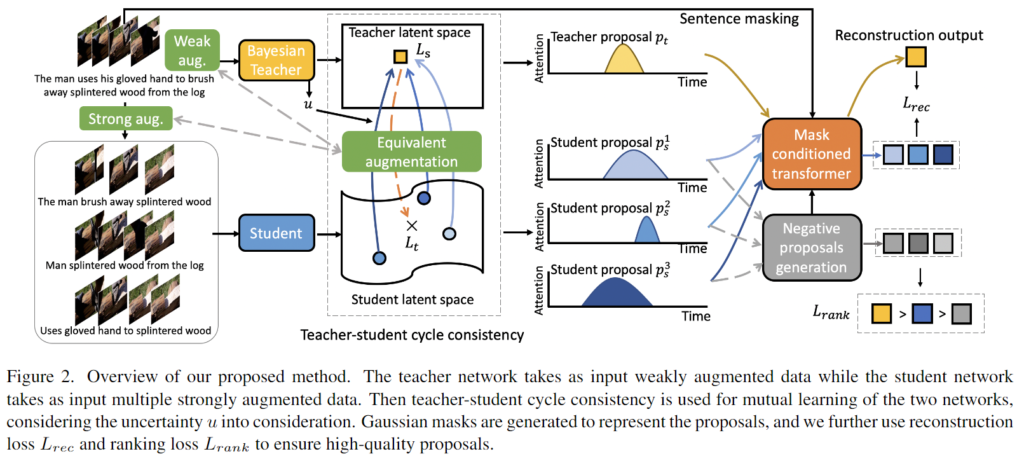
Figure 2.는 제안하는 모델의 전체적인 구조를 보여주는 figure입니다. 제안하는 모델의 self-training 방법은 베이지안 network로 teacher network를 구성하고 identical network로 student network를 구성합니다. teacher/student 모델로는 많이 사용되는 weakly-supervised 모델을 사용할 수 있습니다. 저자는 당시 SOTA 모델이었던 CPL 모델을 backbone으로 사용하여 저자가 제안하는 방법의 효과를 보여줍니다. CPL 모델에 대한 자세한 설명은 백지오 (전)연구원의 리뷰 ([CVPR 2022] Weakly Supervised Temporal Sentence Grounding with Gaussian-based Contrastive Proposal Learning)를 통해 확인할 수 있습니다. 저자는 showcase로 CPL을 사용하지만, CPL이 아닌 다른 모델을 활용해도 된다고 언급합니다. 먼저 weak-strong augmentation을 진행하고 student에는 strong augmentation을 거친 결과를, teacher에는 weak augmentation을 거친 결과를 받게 되는데 teacher는 추가적으로 베이지안 teacher를 거친 결과를 활용하게 됩니다. 이때 각 teacher, student에 비디오-쿼리 쌍으로 들어가게 됩니다. backbone 모델은 backbone 모델의 학습 방식 대로 초기화됩니다. 이후 학습에서는 self-training을 수행하고 teacher가 추정한 uncertainty와 temporal augmentation cycle-consistency를 통해 network를 업데이트합니다.
Uncertainty estimation via Bayesian teacher
techer network 자체는 strong supervision없이 학습하기 때문에 weak augmentation이 주어지더라고 낮은 퀄리티의 supervision signal을 생성할 수 있습니다. Introduction의 figure 1.의 (c)에서도 보여준 것처럼 teacher network의 signal을 그대로 사용하면 오히려 성능을 해쳐서 원래의 성능도 나오지 않는 결과를 초래할 수 있습니다. 따라서, 낮은 퀄리티의 supervision signal의 영향을 억제하는 것은 굉장히 중요합니다. 저자는 베이지안 딥러닝에서 영향을 받아 uncertainty estimation을 얻기 위해 베이지안을 사용합니다.
베이지안 네트워크에서 모든 파라미터들이 확률변수로 여겨지기 때문에 사후 분포를 얻는 것은 어려울 때가 많습니다. 최근 연구에서는 근사값을 활용하여 추론을 합니다. 입력I가 주어지면 출력 O의 예측분포는 근사된 분포 q(w)에서 샘플링된 네트워크 매개변수를 활용하여 D번 반복되어 얻습니다.
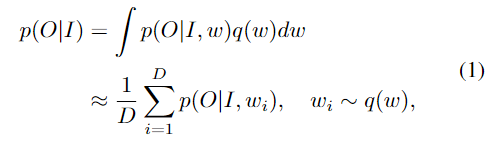
여기서 p(O|I,w_i)는 모델 매개변수 w_i를 한번 forward하는 것을 의미합니다. 하나의 비디오v와 쿼리q 쌍이 주어졌을 때에 시간 세그먼트 제안p를 출력하는 가중치w의 MR모델을 사용하여 얻는 uncertaintyu는 다음과 같이 계산됩니다.
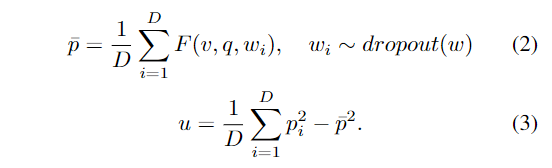
이러한 uncertainty 추정은 teacher network의 낮은 퀄리티의 supervision siganl을 억제하기 위해 사용됩니다.
Mutual learning with temporal augmentation cycle consistency
student가 teacher로부터 signal을 잘 받아 encourage되고 학습한 정보를 teacher에게 전달하기 위해서 저자는 teacher-student mutual learning witch temporal augmentation cycle consistency를 제안합니다. student 모델에 temporally augment된 영상을 feed합니다. 이때 사용하는 augmentation은 temporal scaling, shifting, masking 등을 포함합니다. temporal scaling의 경우에는 1%의 확률로 temporal length를 조절하고, s%의 확률로 영상을 crop, m%로 masking을 진행합니다. masking은 timestamp를 선정하고 timestamp에 해당하는 영상의 구간을 zero 벡터로 바꾼다고합니다.
또한, sentence query에도 augmentation을 진행한다고 합니다. 이때 사용하는 augmentation은 semantic role labeling(SRL)입니다. 50%의 확률로 랜덤한 단어를 drop하는 augmentation입니다. 하지만, 적어도 하나의 문장은 온전한 상태로 보존할 수 있게 유지한다고합니다. 이러한 augmentation을 k번 반복하여 k개의 비디오, 쿼리쌍을 생성합니다. \{(v^1_s,q^1_s),\cdots(v^k_s,q^k_s)\}
Teacher-student cycle consistency
먼저, student에 적용한 augmentation을 똑같이 teacher에도 적용합니다. teacher의 출력을 p_t라고하면 p_t는 temporal segment(시작점과 끝점)를 의미합니다. augmentation 과정에서 temporal augmentation도 진행하기에 p_t또한 같은 방식의 augmentation이 선행되어야합니다. k개의 student 출력 결과를 p^k_s라고 할때 위의 과정을 거쳐 나온 p_t와 p^k_s는 가까이에 위치하는 것이 이상적입니다. student의 출력은 teacher의 출력과 가까워질 수 있게 학습합니다.
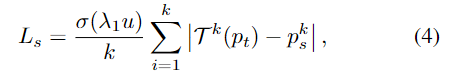
T^k는 equivalent augmentation을 의미합니다. \sigma는 sigmoid함수를 의미합니다. u는 teacher의 uncertainty입니다. \lambda_1은 scale을 조정하는 하이퍼 파라미터입니다.
teacher는 다음과 같이 학습합니다.
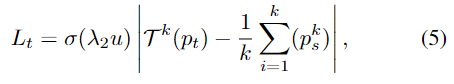
Enhancing self-training with reconstruction
더 효율적인 학습을 위하여 저자는 teacher의 proposals, student의 proposals 그리고 negative proposals를 masking한 후에 마지막에 reconstuction합니다. 해당 방법론은 CNM에서 제안된 방법으로 논문에서도 설명이 없이 넘어가네요. CNM의 내용은 김현우 연구원님의 리뷰[AAAI 2022] Weakly Supervised Video Moment Localization with Contrastive Negative Sample Mining를 참고해주시기 바랍니다. 암튼 마지막에 reconstruction을 통해 self-training을 강화합니다. reconstruction을 학습하기 위해서 저자는 cross-entropy loss를 student와 teacher의 proposals에 적용합니다.
Experiment
저자는 MR에서 자주 사용되는 데이터셋인 Charades-STA 데이터셋에서 실험결과를 리포팅합니다. backbone으로 사용한 모델이 CPL이므로 다른 모델과의 비교보다는 CPL 단일 모델의 성능을 어느정도 개선시켰나에 집중하면 될 것 같습니다.
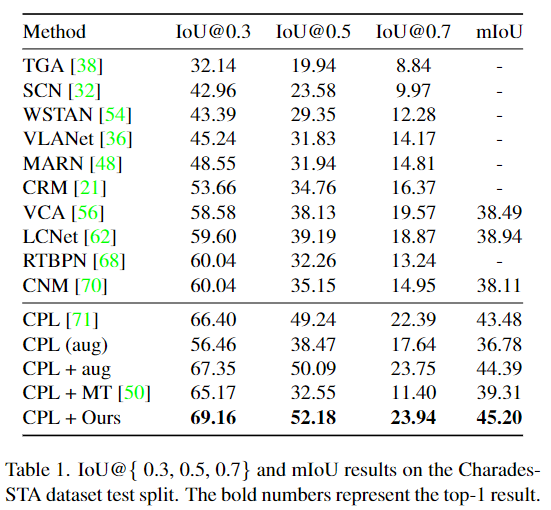
CPL (aug)는 학습된 모델에 inference시에만 augmentation을 진행했을 때의 성능으로 확실히 평가할때만 augmentation을 진행하게되면 성능이 낮게 나오는 것을 확인할 수 있습니다. CPL + aug는 학습과 평가 모두 augmentation을 적용했을 때의 성능입니다. 저자가 제안하는 방법론들이 각각이 따로 쓰였을 때에는 거의 효과가 없다가 같이 모아 사용하는 것으로 성능을 더 높일 수 있는 것이 인상적이네요.
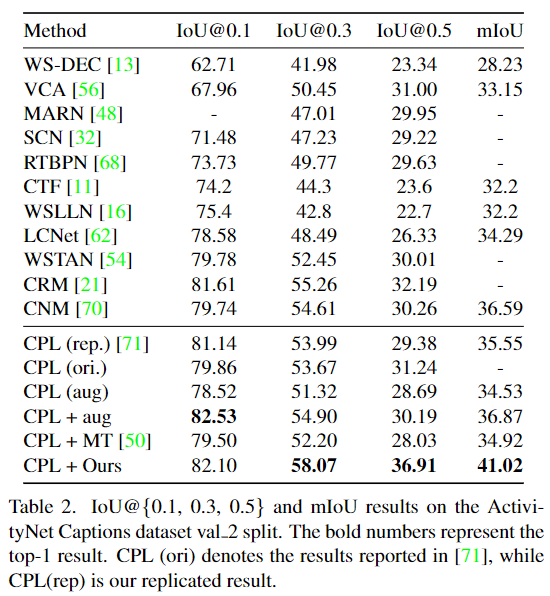
Table 2는 역시 MR에서 자주 사용되는 ActivityNet Captions 데이터셋에서의 결과입니다. 마찬가지고 각자 적용한 것은성능이 오히려 하락했지만, 저자가 제안하는 방법은 성능이 개선된것을 확인할 수 있습니다.
Ablation Study
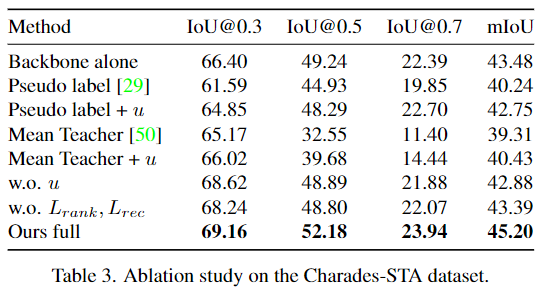
Ablation 결과로 역시 모든 방법을 적용했을 때의 결과가 제일 좋게 나오는 것을 확인할 수 있습니다. 한두가지만 적용했을때에는 오히려 낮아지는 것이 신기하네요. w.o. u는 베이지안의 uncertainty를 적용하지 않았을때, 그리고 w.o. L_{rank}, L_{rec}은 마지막에 reconstruction을 하지 않았을 때의 성능입니다.
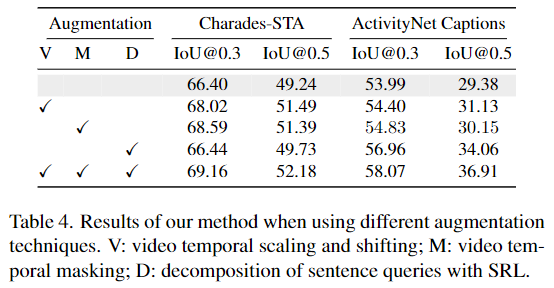
Augmentation에 대해서도 ablation study를 진행한 결과입니다. V는 비디오에 대한 augmentation, M은 마스킹, D는 쿼리에 대한 augmentation입니다.
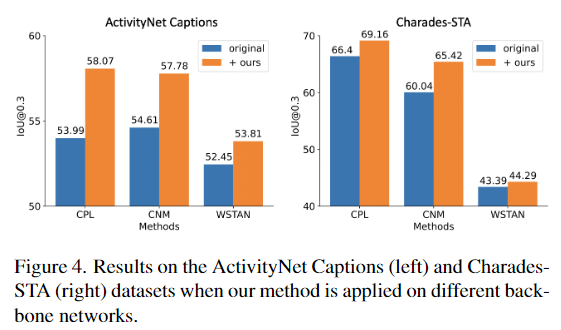
backbone을 CPL이 아닌 모델에 적용했을 때의 결과를 나타내는 figure로 CPL, CNM, WSTAN 모두에서 꽤나 인상적인 성능 개선이 있는 것을 확인할 수 있습니다.

마지막으로 정성적 결과를 확인하면 아무래도 backbone 모델에서 추가적인 학습 기법을 통해 성능을 개선시키는 방법론으로 backbone에 많이 의존하는 것을 확인할 수 있습니다. 해당 논문에서 제안하는 방법론의 가장 큰 문제점이 backbone에 의존한다는 점인 것 같습니다. backbone의 원래 성능에 비하면 확실히 self-training을 통해 supervision을 더하는 것으로 성능을 개선시키는 것도 확인할 수 있습니다. 단점에서 언급한 backbone에 의존한다는 것은 반대로 backbone이 좋다면 성능을 더 좋게 만들 수 있다는 것이기도 하고 general하게 모든 방법론을 backbone으로 활용할 수 있다는 것도 장점이겠네요.
오늘 리뷰는 여기서 마치도록 하겠습니다. 읽어주셔서 감사합니다.
안녕하세요.
베이지안 네트워크를 활용해 uncertainty를 측정해 학습에 사용하는 방법론으로 이해를 하였습니다. 베이지안 네트워크에 대한 기본적인 이해가 없다보니 uncertainty가 어떤 방식으로 뽑혀나오는 것인지 이해가 잘 안되는데, 우선 베이지안 네트워크가 어떻게 구성되는지 알려주실 수 있나요?
Uncertainty 추정 부분이 너무 간단하게 설명이 되어 있는 거 같습니다.
사전 확률, 사후 확률은 베이즈 정리에서 많이 사용하는 용어인 것으로 알고 있는데
딥러닝 학습 관점에서 사전 확률과 사후 확률은 어떻게 정의되는 것인지 알 수 있을가요?