안녕하세요, 서른 세번째 x-review 입니다. 이번 논문은 2024년도 CVPR에 게재된 Probing the 3D Awareness of Visual Foundation Models로, 널리 사용되는 Fondation model의 3차원 인지 능력에 대한 분석을 진행한 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !
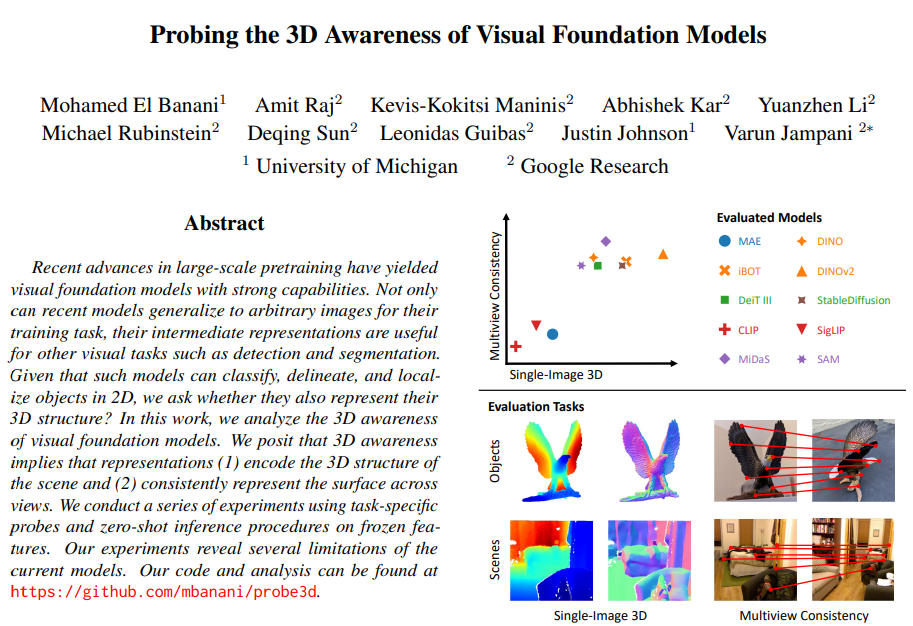
1. Introduction
large scale의 이미지 데이터셋에서 사전학습한 visual foundation model (VFM)은 높은 일반화 성능을 갖추고 있죠. 그래서 이러한 모델들을 통해 이미지를 분류하고, segmentation을 수행하거나 혹은 가상의 이미지를 생성할 수도 있습니다. 더 나아가서 학습한 task 이외에도 zero-shot 기반의 down stream task를 수행할 수 있게 되었습니다. 이러한 흐름은 결국 VFM이 이미지에 대한 높은 표현력을 가진다는 것을 증명하게 되는데, 그럼 이미지가 표현하는 3차원 공간은 잘 표현할 수 있을지 궁금증을 가지게 됩니다. 최근 연구에서는 VFM이 이미지 데이터로 학습되었지만 그럼에도 불구하고 일부 3차원 task에서의 사용 가능성을 확인할 수 있는데, 예를 들어 VFM은 scene이나 얼굴에 대한 이미지를 생성할 때 depth와 surface normal을 내재적으로 표현하게 된다고 합니다. 그러나 3차원 객체를 재구성할 때 이러한 모델들을 사용하게 되면 여러 뷰의 이미지들로부터 얻어야 하는 일관성이 부족해지며 그에 대한 결과로 온전한 얼굴 형태를 갖추지 못한 동물을 생성하게 되죠. 따라서 VFM을 통해 3차원 공간을 어떻게 표현하고 모델이 이해하는지는 확실하게 밝혀지지 않았기 때문에 본 논문에서는 VFM의 3차원 인지에 대한 연구를 진행하였다고 합니다. 이전까지는 semantic task에서 VFM을 평가하곤 했지만, 3D understanding에 대해서는 연구되지 않고 있었습니다. 그래서 본 논문에서는 3차원 인지를 하나의 이미지에서의 surface 재구성과 멀티 이미지에서의 consistency로 나누어서 평가할 수 있다고 가정합니다. 모델이 3차원 인지가 가능하다면, 이미지에서 보이는 물체 표면의 기하학적인 구조, 예를 들면 공간에서 각 부분이 얼마나 멀리 떨어져있는지 또는 각 표면에서의 방향이 어떻게 되는지를 알아낼 수 있을 거라고 예상할 수 있겠죠. 또한 scene이 다양한 뷰의 이미지로 주어졌을 때 각 이미지가 scene에 대해서 일관적인 표현이 가능하며 정확한 대응 관계를 이룰 수 있어야 합니다. 이런 기준으로 3차원 인지에 대한 분석을 진행하며, 분석 대상은 학습 목적에 관계없이 강력한 일반화 성능을 가지는 다양한 VFM 모델을 고려하고 있습니다. 앞에서도 이야기 하였듯 depth, surface noraml, 3차원 대응관계 등을 추정하는 능력에 대해 평가합니다. Fig.1.이 본 논문에서 사용한 모델과 task를 정리하여 보여주고 있네요. 가장 관심있는 부분은 VFM이 무엇을 표현하고 있는지이기 때문에 미리 학습된 가중치에 대한 transferability보다는 모델의 표현력을 평가하겠다고 이야기 합니다. 실험 결과를 잠깐 언급하는데, 우선 모델별로 3차원 인지에 대해 차이가 꽤 있는 것으로 나타났다고 하네요. Fig.1.에서 상단의 그래프는 단일 이미지 및 멀티 뷰 task에서 모델들의 종합적인 등급을 나타내는데 DINOv2와 같이 self-supervised 모델은 depth와 surface normal을 인코딩하는 표현력을 학습하면서 안정적인 등급을 보이지만 그에 반해 CLIP과 같이 NLP 기반 학습 모델은 해당 task에서는 눈에 띄는 일반화 성능을 보임에도 불구하고 3차원 인지에서는 낮은 성능을 보이고 있습니다. 또한 실험 결과 대부분 모델은 멀티 뷰에서 작은 시점이 변화할 때는 물체와 장면을 정확하게 일치시킬 수 있지만, 시점 변화가 크다면 이미지끼리의 일관성을 잃고 성능이 매우 떨어지는 경향을 보입니다. 이러한 결과는 모델은 semantic한 부분은 찾아서 일치시킬 순 있겠지만 전체적인 뷰의 변화에 따른 물체의 pose를 찾는데 어려움을 겪고 있다고 분석할 수 있습니다. 저자는 본 논문의 분석을 통해 VFM에서의 3차원 인지가 더 활발히 연구되길 바란다고 말하며 intro를 마치고 있습니다.
2. Experimental Setup
본 논문의 실험 목표는 다양한 downstream task나 어플리케이션 관점에서 일반화된 백본으로 제안되는 VFM의 3차원 인지 능력을 평가하고자 합니다. 실험을 통해 답을 얻고자 하는 질문은 크게 3가지로 나눌 수 있습니다. (1) 모델이 물체의 표면을 표현하는 방법을 학습할 수 있는지? (2) 표현이 멀티 뷰에서 일관되게 나타나고 있는지? (3) 기존의 모델일 사전학습한 task가 3차원 인지에 어떤 영향을 미치는지? 이런 3가지에 초점을 맞추어서 읽어주시면 좋을 것 같습니다.
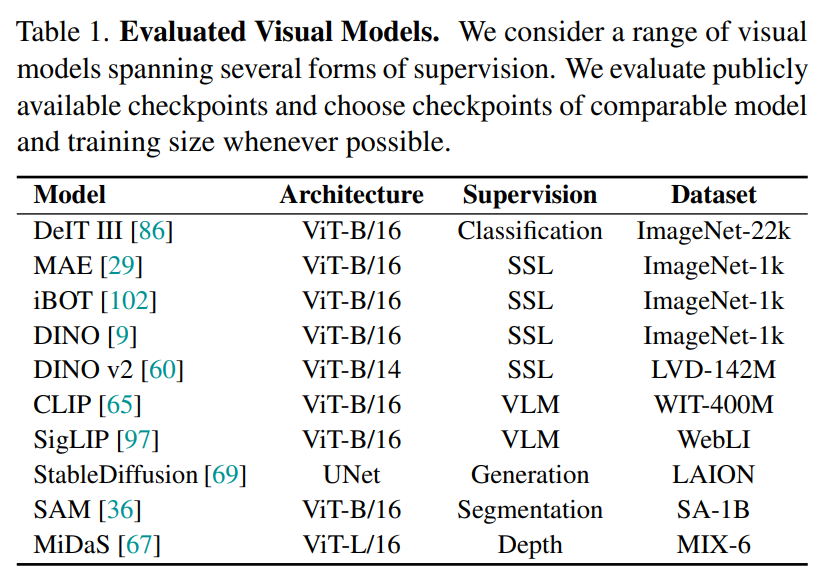
먼저 각기 다른 데이터셋과 계산 비용을 요구하는 모델들을 공정하게 비교하는 것부터 시작됩니다. Tabl.1와 같이 모델이 학습하는 데이터셋 중 다수는 비공개 데이터셋이며, 데이터 규모와 클래스 라벨링, 캡션, 그리고 마스크와 같이 데이터가 요구하는 사항들이 각기 다릅니다. 그 결과 어떤 데이터셋을 사용하는 것이 공정한 비교가 될지는 불분명하기에 저자는 최대한 공정한 비교를 위해 공개적으로 사용가능한 체크포인트가 존재하고, 비슷한 아키텍처와 학습 규모의 체크포인트를 선택하였다고 합니다.
다음으로는 모델을 평가하는 방법인데, 일반적으로는 전이학습으로, task별 supervision을 통해 사전학습된 모델을 finetuning하는 것이 되겠죠. 그러나 이는 좋은 finetuning 성능이 두 가지의 의미로 나타날 수 있기 때문에 적합하지 않다고 이야기하는데, 첫번째는 모델의 3차원 인지 성능이 우수하거나 두번째로는 모델 가중치가 다른 task에 적합하게 초기화 되었다는 것 입니다. 그래서 대신 모델 가중치를 변경하거나 모델 크기를 크게 변경하지 않고 학습 가능한 probe와 zero-shot inference 방식을 사용하여 어떤 frozen feature을 평가하였습니다. 이를 통해 동일한 모델을 다양한 task에 활용 가능하다는 가정을 하고 사전학습된 모델의 representation을 평가할 수 있게 됩니다.
2.1. Single Image Surface Reconstruction
두 가지로 나눈 representation 중에서 먼저 섹션 2.1.에서는 이미지에서 보이는 표면을 분석합니다. 단일 뷰에서의 3D understanding을 위해 monocular depth estimation과 surface normal estimation이라는 두 가지 task를 수행하였습니다. 두 task에 대해 간단하게 먼저 얘기를 해보면, 먼저 monocular depth estimation은 단일 이미지의 각 픽셀에 대한 depth를 예측하는 task 입니다. 이에 대해 RMSE와 다양한 임계값에서의 recall를 리포팅 한다고 하네요. 물체 중심의 데이터셋에서 depth를 추정하는 것은 스케일 모호성으로 인해 특히 어려움이 존재하는데, 스케일 모호성이란 물체와 scene 관점에서 모두 영향을 미치지만 물체의 depth를 추정하도록 학습된 모델은 결국 전체 scene의 디테일한 부분들을 놓치게 되고 물체의 평균적인 depth를 예측하는데 집중한다는 사실을 발견하였다고 합니다. 따라서 본 논문은 물체의 depth를 0-1 사이의 값으로 정규화하여 스케일 불변한 공식을 사용하였다고 합니다. 두번째로 surface normal estimation은 모든 픽셀 표면의 방향을 예측하는 task 입니다. 여기서는 각기 다른 각도 임계값에서 RMSE와 recall을 리포팅 합니다.
두 task에서 scene과 물체 중심 데이터셋에서 모두 성능을 평가하는데, indoor scene understanding을 위한 벤치마크 데이터셋인 NYUv2 데이터셋을 사용하여 scene 레벨의 성능을 평가합니다. 그 다음은 다양한 물체 중심의 데이터를 포함하는 NAVE 데이터셋을 사용하여 물체 수준의 성능을 평가합니다. 아래에서 성능에 대한 여러 개의 질문을 던지면서 대답하는 형태로 실험에 대해 분석하고 있습니다.
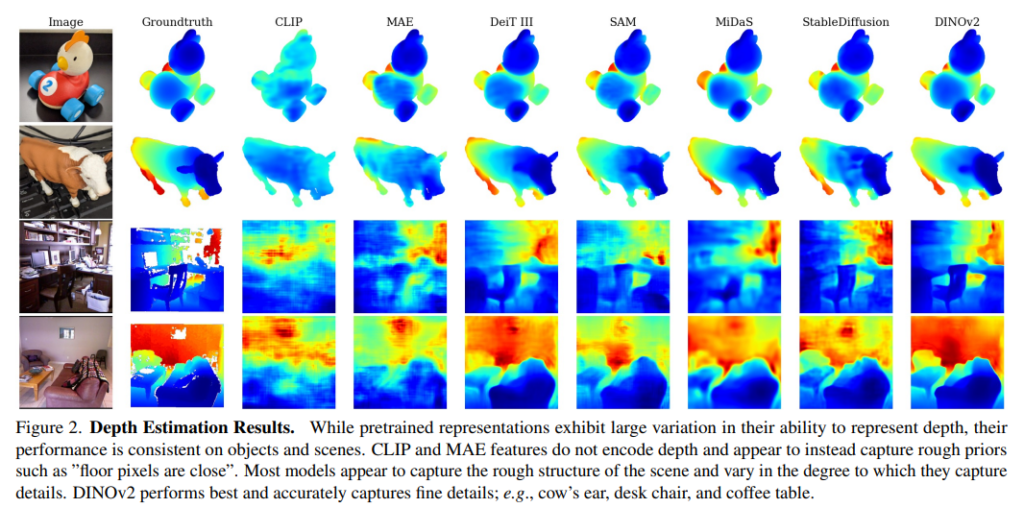
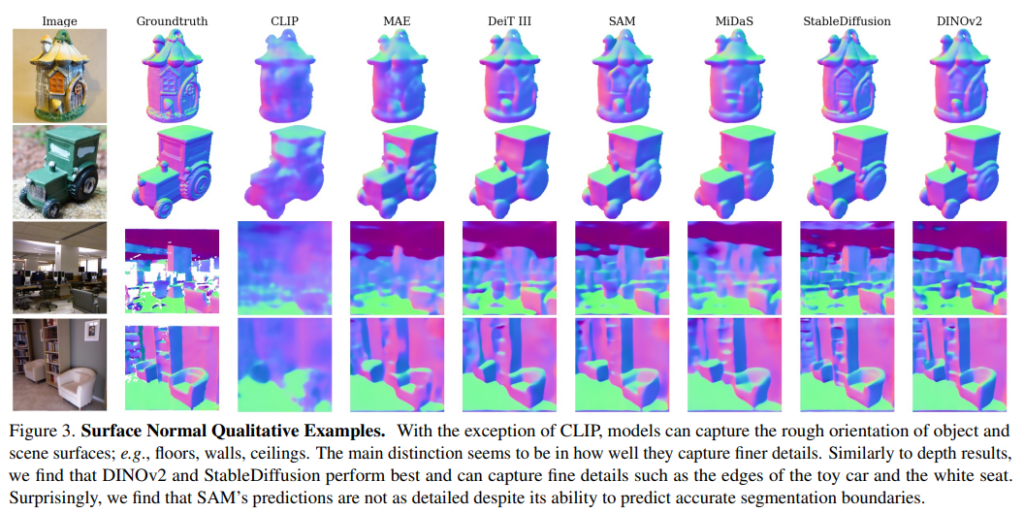
(1) 모델이 depth를 표현하는 방법을 학습하는가 ?
우선 모델이 depth를 인코딩하는 능력은 일정하진 않고, 매우 변동이 심한 것을 확인할 수 있었습니다. 이는 Fig.2에서 확인할 수 있는데, DINOv2와 StableDiffusion은 소의 귀와 의자 다리를 명확한 depth map으로 예측하는 반면 CLIP과 MAE는 비교적 흐릿한 추정으로 depth map을 생성하고 있습니다. 비교한 모든 모델을이 모두 downstream task에서 백본으로 자주 사용되는 높은 성능의 FM이라는 점을 생각해보았을 때, 이러한 성능 차이는 모델들을 벤치마킹할 때 더 넓은 범위의 task를 고려하는 것이 중요하며 그런 task 중 하나로서 3차원 인지의 유용성을 강조하고 있습니다.
(2) 모델이 surface normal을 표현하는 방법을 학습하는가 ?
여기서도 depth estimation과 비슷한 경향을 보이는데, 일부 모델은 매우 높은 성능을 달성하는 반면 또 어떤 모델은 바닥 픽셀이 향하는 윗 방향과 같은 정보를 잘 찾지 못하고 있습니다. 물체는 scene에 비해 prior가 더 적기 때문에 물체와 scene에 대한 예측을 비교해봤을 때 prior의 의존도를 확인할 수 있습니다. 그 예로 Fig.3에서 CLIP은 scene에서는 그나마 블러하지만 대략적인 depth를 예측할 수 있는 반면 물체에 대해서는 전혀 depth를 추정하지 못하는 모습을 볼 수 있네요. 그에 비해 최고 성능을 달성하는 DINOv2는 GT와 비교해도 매우 정확한 depth를 예측할 수 있는 것을 확인할 수 있습니다.
(3) 학습 objective의 영향은 무엇인가 ?
self supervised 모델이 두 가지 task에서 가장 우수한 성능을 보이고 있습니다. 특히 dense supervision, 심지어 depth supervision으로 학습된 모델 역시도 self supervised 및 텍스트를 조건으로 하는 이미지 생성보다 낮고 분류로 학습된 모델과 유사한 성능을 보입니다. 마지막으로 language-supervised 모델은 다양한 task에서 중심적인 역할을 하는 일반화된 경향성에도 불구하고 매우 성능이 좋지 못한 것을 확인하였습니다. 이러한 결과는 vision language 모델이 공간적인 관계와 구성을 하는데 있어서 어려움을 겪고 있다고 분석할 수 있습니다. 하지만 어쨌든 VFM은 이미지 데이터로만 학습했음에도 불구하고 전반적으로 표면적인 속성을 인코딩하여 표현하는 방법을 학습하고 있다는 것이 놀라운 결과라는 생각이 듭니다.
2.2. Multiview Consistency
이전 섹션 2.1에서는 모델의 가시적인 표면의 표현 성능을 확인하였는데, 이는 3D understanding에 있어서 중요하지만 평가를 단일 이미지로 제한하고 있습니다. 3차원 인지에서는 멀티 뷰에 거쳐서 scene에 대한 모델의 표현 일관성으로 정의할 수도 있다고 introduction에서 언급하였죠. 섹션 2.2에서는 대응 관계 추정을 통해 이러한 관점에서의 3차원 인지를 평가하였으며, 동일한 3차원 포인트를 나타내는 멀티 뷰에서 이미지 패치를 식별하는 것을 목표로 하고 있습니다.
기하학적으로 대응 관계를 추정한다는 것은 동일한 물체나 scene에 대핸 두 개의 뷰로 촬영한 이미지가 주어졌을 때, 3차원 공간에서 동일한 지점을 나타내는 픽셀을 식별하는 것 입니다. 각 이미지에서 추출한 dense한 feature map 간의 대응 관계를 직접 계산하여 표현의 일관성을 평가할 수 있다고 합니다. 데이터셋은 섹션 2.1과 같이 scene과 물체를 모두 고려하였는데, scene의 경우 ScanNet에서 평가하였고 물체의 경우, 서로 다른 배경(혹은 환경)에서 동일한 instance 객체를 구성한 NAVI wild 셋에서 이미지 쌍을 샘플링하였습니다. 또한 추가적으로 키포인트 라벨을 제공하는 이미지로 구성된 SPair 데이터셋에서 성능을 평가하였습니다. 평가는 correspondence recall, 즉 정의한 거리 내에 매칭된 대응 관계의 비율로 리포팅하였습니다. 대응 관계 에러는 흔히 depth의 변화가 큰 것을 고려하기 위해 픽셀 단위로 계산된다고 합니다. 예를 들어서 1 픽셀의 오차는 가까운 표면에서는 몇 mm일 수도 있고, outdoor에서 촬영된 장면에서는 몇 미터가 될 수 있겠죠. 그런데 이러한 기준은 물체 수준에서는 물체에 대한 depth 변화가 크지 않기 때문에 적합하지 않고, 물체는 occlusion 및 물체 내에서 depth가 반복되는 영역이 많기 때문에 픽셀 단위의 임계값을 적용하는 것은 오류를 발생시킬 가능성이 높습니다. 그렇기 때문에 물체에 대해서는 앞서 언급한 기준이 아니라 metric 임계값을 사용하였다고 합니다. layer selection은 결과에 큰 영향을 미칠 수 있기 때문에 네 개의 다른 intermediate 지점에서 모델의 성능을 평가하였습니다. 이렇게 지정한 데이터셋과 평가 방식으로 실험한 결과, 모델 성능이 두 뷰로 이루어진 한 쌍 간의 시점 차이에 따라서 크게 달라지는 것을 확인할 수 있었기에 쌍 사이의 시점 변화 정도에 따라서 구간을 나누어서 평가를 진행하였습니다. 이제 아래에서 실험 분석에 대해 살펴보도록 하겠습니다.


(1) 3차원 표현에 대한 일관성을 가지는가 ?
Fig.6와 같이 시점 변화가 작은 구간에서는 모델이 물체 간의 정확한 대응 관계를 추정할 수 있지만, 시점 변화가 커질수록 성능이 급격하게 떨어지는 것을 확인할 수 있습니다. 리포팅한 시점 구간 보다 더 크게 변화할 경우에 성능이 더 낮을 것으로 예상된다고 하네요. 특히 StableDiffusion과 SAM은 가장 시점 변화가 작은 구간에서 가장 높은 성능을 달성하고 시점 변화가 큰 구간에서 전혀 대응 관계를 찾아내지 못하고 있습니다. 이는 정성적인 자료인 Fig.5에서 두 모델이 모두 시점 변화가 최소인 첫번째 행의 공룡 물체에 대해서 대응 관계를 비교적 정확하게 예측하고 있지만 회전된, 즉 시점 변화가 큰 두번째 행의 독수리에 대해서는 대응 관계를 찾더라도 전혀 잘못된 부분들을 매칭하고 있습니다. 이런 급격한 성능 저하는 DINOv2와 DeiT와 같은 모델과 비교하였을 때 모든 FM의 일반적인 경향성은 아닌 것을 확인할 수 있네요. 물체 뿐만 아니라 indoor scene에서도 비슷한 경향을 확인할 수 있는데, 유사한 시점에서 촬영한 두 scene은 모델이 정확하게 예측하고 있지만 Fig.5의 마지막 두 행을 통해 확인할 수 있듯이 조금만 시점이 변화하더라도 예측하기 어려워하는 것이 보입니다. 여기서도 DINOv2가 다른 모델에 비해 더 나은 성능을 보이긴 하지만, DINOv2를 포함하여 모든 모델의 절대적인 성능이 분포된 정도가 매우 낮다는 것 입니다. 본 논문에서는 분석한 결과 섹션 2.1에서의 결과로 표면적인 특성은 학습할 수 있더라도 현재 FM에서는 3차원 공간에서의 일관성을 추정할 수 없다라는 결론을 도출하고 있습니다.
(2) 의미론적 vs 기하학적 대응 관계
현재 모델은 의미론적인 대응 관계는 매우 잘 추정하고 있는데, 의미론적인 대응에서는 동일한 물체에 대한 멀티 뷰에서 동일한 지점을 찾는 것에서부터 같은 클래스인 여러 instance에서 유사한 의미론적인 부분을 찾는 것으로 의미론적인 대응 관계 추정 문제를 정의할 수 있습니다. 후자는 이제 예를 들어 서로 다른 두 개의 개가 존재하는 이미지에서 개의 왼쪽 귀를 찾아내는 것과 같죠. 의미론적인 대응은 3차원 구조와 의미를 모두 분석해서 찾아내는 것처럼 보일 수도 있으나 이는 위의 본 논문의 실험을 통해 3차원 구조를 분석할 수 있지는 않다는 걸 알 수 있습니다. 의미론적인 대응 관계는 보통 keypoint recall을 통해 평가하는데, 모델의 성능은 데이터의 의미론적인 편향성에 영향을 받지 않기 위해 일반적으로 이를 사용한다고 합니다. 키포인트는 보통 동물의 부리나 꼬리처럼 고유한 특성이고 쉽게 찾아낼 수 있는 지점이지만 일부 키포인트, 예를 들어 눈이나 무릎은 여러 물체에서 나타나는 반복적인 특성이지만 데이터 생성에서 편향성이 생겨 일관된 공간으로 나타날 수도 있다는 것 입니다.
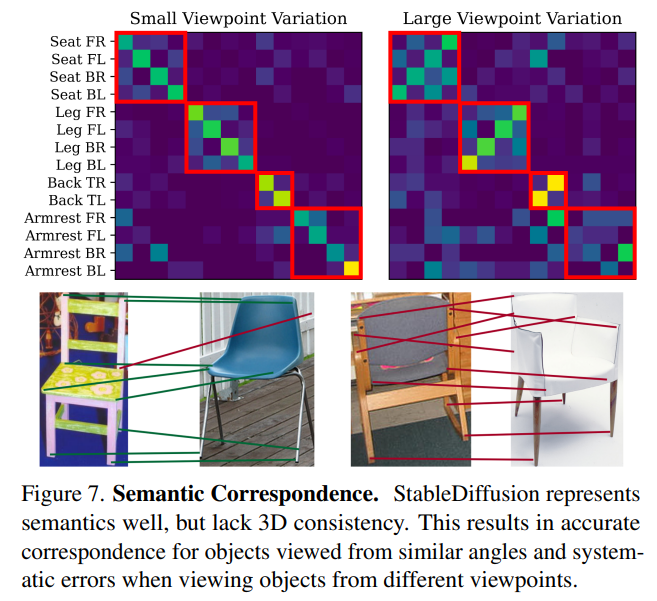
Fig.7은 SPair71k 데이터셋 중 의자에 대해서 StableDiffusion으로 평가하여 의미론적 대응과 기하학적인 대응 사이의 차이를 설명하고 있습니다. 평가는 예측된 대응 위치에서 가장 가까운 키포인트를 찾아내고 혼동 행렬을 계산하는 방식으로 진행하였다고 합니다. StableDiffusion은 작은 시점 변화에서는 정확한 대응 관계를 추정하지만, 시점 변화가 크면 대응 관계 추정에 발생하는 오류를 찾을 수 있습니다. 이는 의자에서 좌석 모서리나 의자 다리와 같이 의미론적인 정보를 통해 시점 변화가 적을 경우에는 대응 관계를 잘 찾아내지만 시점 변화가 커져 기하학적인 정보가 중요해지면 똑같이 의자에 대한 대응 관계를 찾더라도 잘 찾아내지 못한다는 의미 입니다.
2.3. Analysis
본 논문에서 위와 같은 실험을 수행하면서 중요하게 생각했던 점은 서로 다른 task 간의 상관관계였다고 합니다. 즉 모델이 depth를 정확하게 표현할 수 있을 때 대응 관계 추정에서도 유의미한 결과를 보일 가능성이 얼마나 될 것인가와 같은 상관 관계를 말이죠. 이러한 상관 관계를 확인하기 위해 여러 task에서 모델이 도출한 성능에 대해 상관 관계를 계산하였습니다. 특히 학습 objective와 3차원 인지 간의 관계를 이해하는데 초점을 맞추었는데, 분석에서는 DINOv2와 같은 특정 모델의 성능을 강조하긴 했지만, 실제로는 훨씬 더 많은 모델에 대해 평가하고 task 간의 성능에 대한 상관 관계를 계산하였다고 합니다.
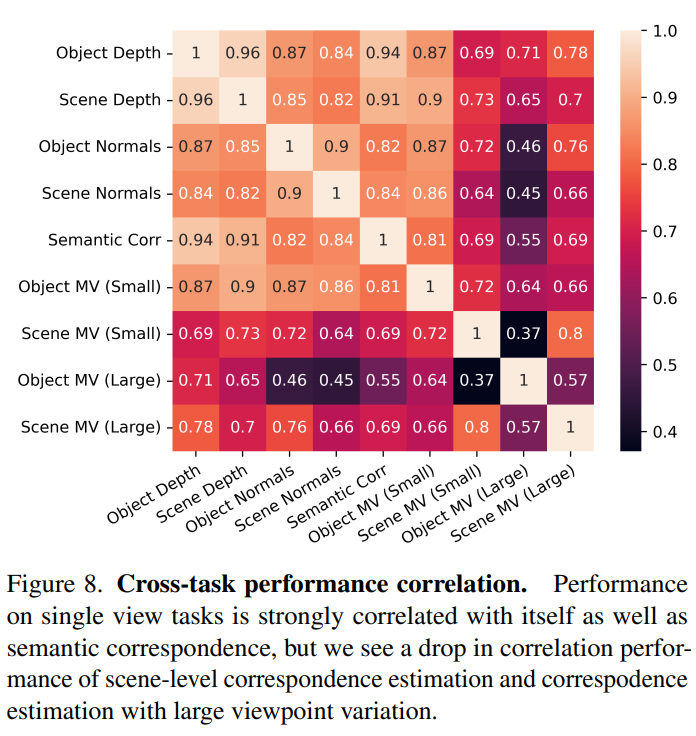
Fig.8이 바로 모든 task 사이의 상관관계를 계산한 결과로 단일 이미지의 경우 물체와 scene의 depth 및 surface normal 추정에 대한 recall을 리포팅 합니다. 또한 대응 관계 추정을 위한 recall을 계산하고 NAVI와 ScanNet 데이터셋의 가장 작은 뷰 포인트의 bin과 가장 큰 뷰 포인트의 bin을 고려하여 뷰 포인트 변화에 따라 또 성능을 나눕니다. 마지막으로 의미론적인 대응 관계 추정에 대한 성능 역시도 리포팅하는데, 결국에는 위에서 분석한 실험 결과에 대해 한번에 나타낸 것이네요.
모든 단일 뷰 task는 0.82보다 큰 상관 관계가 있는 것으로 나타났지만, 오른쪽 하단에 있는 값처럼 멀티 뷰 task 간의 상관관계는 훨씬 낮게 나타납니다. 특히 의미론적인 대응 추정의 성능은 멀티뷰 task와 평가 프로토콜이 비슷함에도 불구하고 멀티뷰 task보다 단일 뷰 task와 더 높은 상관관계를 나타내는데, 이러한 결과가 앞서 말한 것 처럼 의미론적인 대응은 3차원 일관성을 표현하는데 좋은 수단이 아니라는 주장을 뒷받침 할 수 있는 자료가 될 수 있는 것이죠.
좋은리뷰 감사합니다.
몇가지 궁금한 점이 있어서 질문 남깁니다.
먼저 2.1절에서 전체 scene의 디테일을 놓치고 물체의 평균적인 depth를 예측하는 데 집중하는 문제를 해결하고자 물체의 depth를 0~1 사이의 값으로 정규화하셨다고 하셨는데, 그렇다면 NYUv2와 NAVE 중 NYUv2의 물체에 대해서도 해당 과정을 적용하는 것인 지 궁금합니다.
또한, (1) 모델이 depth를 표현하는 방법을 학습하는 가? 에 대한 내용 중 ‘FM 모델들의 성능차이는 모델들을 벤치마킹할 때 더 넓은 범위의 task를 고려하는 것이 중요하며, 그런 task 중 하나로 3차원 인지의 유용성을 강조’한다는 것은, FM 모델을 선택함에 있어 3차원 인지 성능을 기준으로 활용하는 것이 효과적일것이라는 의미인가요?
또한 depth estimation과 surface normal에 대한 정량적 결과는 따로 리포팅 되어있지 않은 것인 지 궁금합니다. CLIP에 대한 분석 결과도 scene에 대해서는 블러하지만 대략적인 depth를 추정하지만 object에서는 depth를 추정하지 못한다는 것을 Figure 3을 통해서는 잘 납득이 되지 않고 다른 결과들도 몇가지 예시만으로는 잘 이해가 되지 않아서 질문드립니다.
마지막으로, 해당 논문을 읽으면서 실험중이신 3D detection에 FM모델 적용에 있어 인사이트를 얻으셨는지 궁금합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 넵 저는 모든 데이터셋의 물체 에 대해서 해당 과정을 적용했다고 이해했습니다.
2. 효과적이라기 보다는 FM 모델을 설계하고 여러 downstrem task에서의 성능을 리포팅하고 있는데, 그때 지금 논문처럼 3차원 representation에 대해서도 추가적으로 리포팅하였으면 좋겠다는 저자의 의견이었습니다.
3. CLIP에 대한 분석은 상대적인 분석이었는데, scene에 대해서는 그나마 depth의 정도 차이라도 구분해내고 있지만 물체에 대해서는 전혀 depth의 차이를 인지하지 못하기 때문에 그렇게 표현하였던 것 입니다. 아쉽게도 정량적인 지표로는 평가하고 있지 않네요 ..
4. 현재 적용하고 있는 FM이 2D branch로 들어갈 때 여전히 3차원 정보와 바로 합쳐지기에는 도메인 차이가 존재한다고 생각했는데, 성능 결과를 보니 3차원 representation이 충분히 잘 워킹한다는 생각이 들어 두 정보를 어떻게 합치면 좋을지 좀 더 고민해보아야 할 것 같습니다 ㅎ ㅎ ..
안녕하세요. 건화님!
좋은 리뷰 감사합니다.
글을 읽던 중 두 가지 질문 사항이 생겨 댓글 남깁니다!
(1) 모델의 3차원 기하학적 인지 척도로서 depth, surface normal, 3D 대응관계를 사용하였는데요. 3차원 공간에서 두 물체의 상대적인 depth, 멀티 뷰 이미지로 부터 동일한 scene에 대해서 일관적인 표현이 추출되는 것으로 평가하는 것은 납득이 갑니다만, 왜 surface normal이라는 것을 척도로 사용하였는지 궁금합니다. 각 표면의 방향이 3차원 scene을 이해하는 데 관련이 있는 것인지 궁금합니다.
(2) 해당 리뷰를 읽고 이해한 바로는 VFM이 제공하는 3차원 표현과 3차원 의미론적인 대응은 일관성이 없다는 것이고, 그것을 저자가 실험을 통해서 강조했다고 생각을 했습니다.
그러면, 결국에 저자가 하고자 하는 말이 VFM을 통해서 3차원적인 표현력 분석이 어차피 모델 마다 다르고 일관성이 없으니 무의미하므로 하지 말라는 것인가요? 혹은 기존의 평가지표로 사용되었던 척도들이 무의미하다라는 것을 보이고 싶었던 것인가요? 해당 부분에 대해 무지하여 결론적으로 해당 분석논문을 통해서 저자가 말하고자 하는 바를 알지 못하였습니다 ㅠ
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. surface normal은 depth completion과 같은 depth 정보를 활용하는 task에서 흔하게 쓰이는 정보로, 제가 생각하기에는 이 surface normal 벡터의 방향이 원칙적으로 물체의 바깥쪽을 향하게 되어야 하기 때문에 scene 레벨에서 벡터 정보를 모두 모으면 scene을 이해하는데 도움이 되기 때문에 사용한다고 생각합니다.
2. 음 일단 무의미하기 때문에 하지 말라는 의도는 절대 아니라고 생각이 들고, VFM은 이미지로 학습되었음에도 3차원 표면에 대한 representation은 현재 충분히 잘 하고 있고 의미론적인 대응에 일관성이 없기는 하나, 이는 3차원 understanding을 여러 개로 쪼개어 봤을 때 그 부분이 부족하다는 것을 이야기하고 있는 것이었습니다. 현재 VFM이 3차원 representation에 이 정도로 워킹하고 있고, 앞으로 VFM의 downstream task로 3차원 task를 수행하게 된다면 본 논문의 실험을 바탕으로 연구가 진행되길 바란다는 것이 저자가 본 논문을 통해 하고자 하는 말이라고 저는 이해하였습니다.