안녕하세요. 이번 X-Review에서 소개해드릴 논문은 제가 이전에 작성했던 리뷰 QD-DETR의 후속 연구 논문 CG-DETR입니다. QD-DETR과 동일한 성균관대 한국인 박사님의 연구이며, ECCV에 제출한 뒤 이제 리비전을 거치고 있는 상황으로 보입니다. QD-DETR의 후속연구답게 QD-DETR의 문제점을 바탕으로 새로운 모듈들을 제안하게 됩니다. 자세한 내용은 이제 차차 알아보겠습니다.

1. Introduction
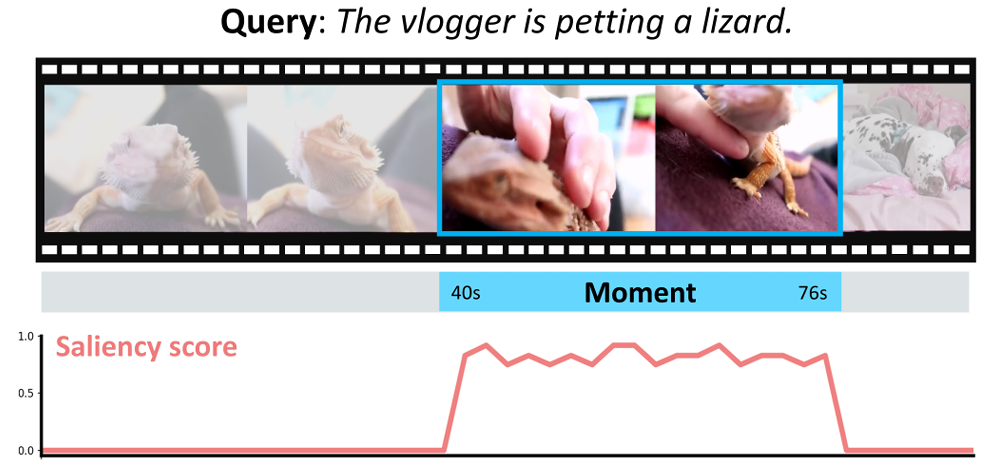
CG-DETR은 제가 최근 리뷰에서 계속 다루었고 세미나 때도 소개해드렸던 MR (Moment Retrieval) & HD (Highlight Detection) task를 동시에 수행합니다. 위 그림과 같이 비디오와 텍스트 쿼리를 입력받아 파란색으로 표시된 상응 구간과 붉은색 그래프로 표시된 비디오 클립 별 saliency score를 얻는 것이 목표입니다. Task에 대한 자세한 설명은 이전에 여러번 하였으므로 생략하도록 하겠습니다.
21년도 제안된 베이스라인 논문 Moment-DETR의 나이브한 방법론에 상대적으로 단순한 contribution들을 추가해 큰 성능 향상을 이룬 논문이 Query-Dependent DETR (QD-DETR)인데요, 이에 대한 관련 리뷰는 아래 링크에서 확인하실 수 있습니다.
베이스라인 방법론인 Moment-DETR은 비디오와 텍스트 토큰을 추출한 뒤 단순 concat하여 DETR encoder-decoder 구조의 입력으로 주었습니다. 이러한 방식은 두 모달 간 상관관계 모델링이 굉장히 중요한 MR&HD task를 수행하기에 너무 단순하다는 지적이 많았고 실제 이 포인트를 문제삼아 개선된 방법론들이 여럿 등장하였습니다.
이러한 상황 속 QD-DETR은 기존 MR&HD 방법론들이 텍스트 쿼리에 대한 고려가 너무 부족하였다는 점을 지적합니다. 두 모달리티의 관계를 잘 모델링하는 것도 중요하지만 이 과정에서 기본적으로 비디오에 비해 상대적으로 텍스트 쿼리에 대한 모델링이 부족했다는 것이었죠. 그래서 QD-DETR의 저자는 MR&HD 수행 과정에서 텍스트 쿼리의 영향력을 높이고자 여러 모듈을 제안하였고 실제로 큰 성능 향상을 이루었습니다. 하지만 비디오를 구성하는 클립 간에도 텍스트 쿼리와의 상관관계 정도가 상이할 것이고, 반대로 텍스트 쿼리를 구성하는 단어 간에도 비디오 내 moment와의 상관관계 정도의 차이가 존재할 것입니다. 쉽게 말하면 비디오와 텍스트 쿼리 간 상호작용 시 각각의 세부 단위인 클립과 문장 내 단어들이 “얼마나” 상호작용할지는 고려된 적이 없기에 이를 모델링해보겠다는 것입니다. QD-DETR에서는 이렇게 한 층 더 fine-grained한 level에서의 모델링은 이루어지지 않고 단순히 비디오-텍스트 단위의 학습만 고려하였었습니다.
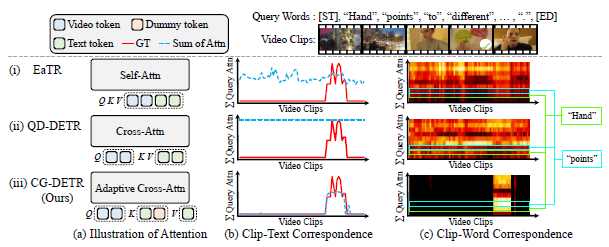
기존 방법론인 EaTR, QD-DETR과 저자가 본 논문을 통해 제안하는 CG-DETR에 대한 차이점이 그림 1에 나타나있습니다. 세부적으로 설명을 드리면, 먼저 (b)는 clip-text 간 상관관계를 나타내고 있습니다. 붉은 선이 Highlight Detection과 관련된 GT annotation을 의미하고, 푸른 점선이 각 방법론의 attention layer에서 추출한 비디오 클립-문장 간 attention score입니다. EaTR 방법론 내 self-attention과 QD-DETR 방법론 내 cross-attention 모두 두 모달리티 간의 상관관계를 제대로 파악하고 있지 못합니다. 하지만 CG-DETR은 비디오 단위의 모델링 뿐만 아니라 클립 단위의 모델링 또한 수행하기에 클립과 문장간 attention score가 실제 GT 구간과 유사한 분포를 가지는 모습입니다.
그림 1의 (c)는 비디오 클립과 문장 단위 모델링에서 하나 더 들어가 클립과 문장 내 단어 단위의 모델링 또한 수행하는 CG-DETR의 장점을 보여줍니다. (c) 또한 attention weight에 해당하는데, GT 구간 내 높은 weight를 갖는 단어들(밝은 색)을 볼 수 있습니다. 이는 문장 내에서도 중요한 의미를 갖는, 중요한 역할을 하는 단어들이 강조되고 있는 것으로 해석해볼 수 있습니다. 결국 위 그림 1을 통해 알 수 있는 것은, CG-DETR에서 이전보다 더 fine-grained한 비디오의 “클립”, 텍스트 쿼리 문장 내 “단어” level로 모델링이 이루어졌다는 것입니다.
Contribution을 정리한 뒤 방법론으로 넘어가겠습니다.
Contribution
- We propose adaptive cross-attention with dummy tokens to enable the manipulation in the degree of video-text interaction with respect to their correlation
- To further calibrate the interaction degree, we discover and distill the clip-word correlation from the aligned space at video-sentence level
- We introduce a moment-adaptive saliency detector to exploit the calibrated degree of cross-modal interaction
- Extensive experiments demonstrate the effectiveness of CG-DETR
2. Method
2.1 Overview
L_{v}개의 클립으로 구성된 비디오 V = [v_{1}, \cdots{}, v_{L_{v}}]와 L_{q}개의 토큰으로 구성된 텍스트 쿼리 Q = [q_{1}, \cdots{}, q_{L_{q}}]가 입력으로 주어집니다. 이를 활용해 HD에 대한 예측값 clip-wise saliency score \{s_{1}, \cdots{}, s_{L_{v}}\}와 MR에 대한 예측 구간을 (m_{c}, m_{\sigma{}}) 형태로 얻어내는 것이 목적입니다. m_{c}는 중간 지점, m_{\sigma{}}는 너비를 의미합니다.
CG-DETR에서는 두 모달리티 간 interaction 정도를 조절해줄 수 있는 3가지 모듈을 제안합니다.
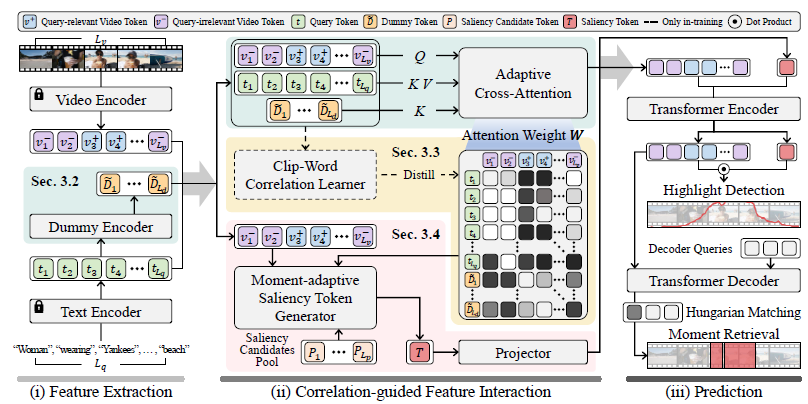
2.2 Adaptive Cross-Attention: Reflecting the Video-Text Correlation
기본적으로 Adaptive Cross-Attention (ACA) 모듈은, 비디오를 구성하는 모든 클립이 텍스트 쿼리의 의미론적인 정보를 담고 있는 것은 아니라는 점을 파고들기 위해 설계되었습니다. 결국 비디오를 구성하는 클립들이 텍스트 쿼리에 각각 얼마나 상응하는지를 고려해주면 되는 것입니다.
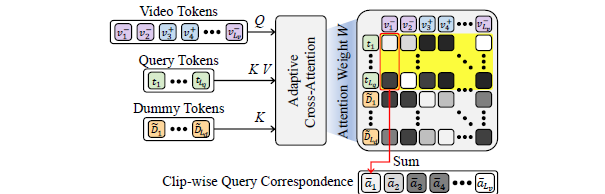
우선 그림 2를 보면, DETR 구조에 해당하는 Transformer encoder-decoder 구조에 무언가를 입력해주기 전 Adaptive Cross-Attention을 수행해주는 것을 볼 수 있습니다.(초록색 부분) 비디오 토큰을 query, 텍스트 쿼리 토큰을 key, value로 넣어주는 것이 일반적인 cross-attention이라고 볼 수 있을 것입니다. 이 때 dummy token D = [D_{1}, \cdots{}, D_{L_{d}}]를 encoding한 \tilde{D}를 key에 concat하여 cross-attention을 진행합니다. 기본적으로 dummy token \tilde{D}는 텍스트 쿼리와 반대되는 의미를 갖도록 추후에 학습됩니다.
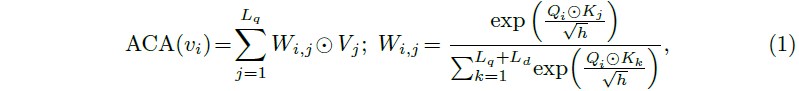
각 클립이 텍스트 쿼리와 얼마나 상응하는지를 고려할 가중치를 위 수식 1과 같이 얻을 수 있습니다. 처음에는 key와 value의 shape이 안맞아 뭔가 이상하다고 생각했는데, value에 곱해주는 weight W_{i, j}의 j 인덱스가 더미를 제외한 쿼리 개수만큼까지 사용되고 있었습니다. 그림 3을 통해서도 이 과정을 확인하실 수 있습니다. 그렇다면 dummy token D가 쿼리를 제외한 의미를 가지는 토큰으로 만들어주기 위해서는 학습이 별도로 필요할 것입니다.
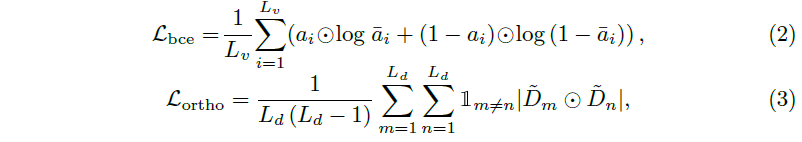
수식 2에서 \bar{a}_{i}=\Sigma{}_{j=1}^{L_{q}}W_{i, j}는 i번째 클립에 대한 문장 전체의 attention weight를 의미하며, a_{i}는 HD를 위한 GT 라벨을 의미합니다. 구간이 Highlight에 해당하면 \bar{a}_{i}는 1로, 아니면 0으로 향하도록 학습하는 \mathcal{L}_{bce}입니다. 이렇게 GT 구간의 weight 값을 크게 만들어줌으로써 Dummy token들이 정확히는 규정할 수 없지만 텍스트 쿼리와 반대되는, 또는 배제하는 의미를 갖도록 학습될 것입니다. 수식 3번의 \mathcal{L}_{ortho}는 벡터의 내적이 0이면 서로 orthogonal 하다는 성질을 이용해 Dummy token 각각이 서로 다른 의미를 갖도록 학습하게 해주는 역할을 수행합니다.
2.3 Clip-Word Correlation Learner: Align, Discover, and Distill the Fine-grained Correlation
앞선 절에서 설명드린 Adaptive Cross-Attention (ACA)를 거치며 각 클립들이 텍스트 쿼리에 얼마나 상응하는지에 대한 attention 연산을 수행해줬습니다. 반대로 텍스트 쿼리를 구성하는 모든 단어들이 동등하게 중요하다라고 보긴 어렵겠죠. 그래서 본 절에서는 clip-word level에서의 cross-attention 시의 가중치를 적절히 얻어보고자 하는 것입니다.
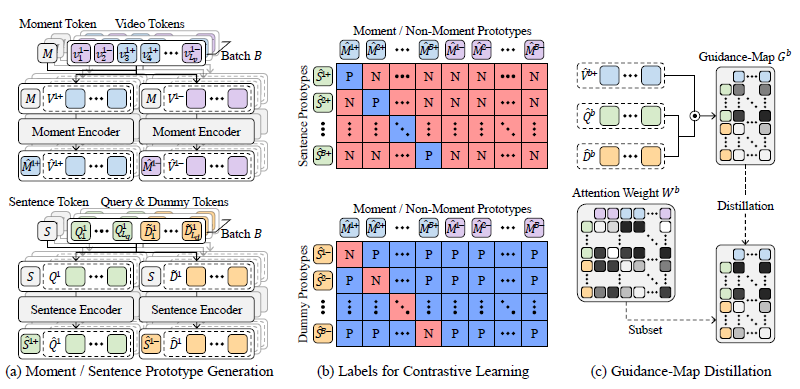
사실 앞선 절에서 클립-텍스트 쿼리 간의 관계는 GT 라벨이 있기 떄문에 학습이 가능했습니다. 하지만 문장 내 존재하는 단어들이 얼마나 중요도를 갖는지에 대한 라벨은 없습니다. 이러한 상황에도 최적의 중요도를 모델링하기 위해 두 단계의 파이프라인을 구성합니다. 첫 번째는 supervision이 가능한 moment-sentence level의 embedding space를 구축하는 것입니다. 두 번째는 이러한 embedding space를 기반으로 clip-word level의 상관관계를 추정하는 것입니다. 명시적인 라벨은 없지만 라벨을 가지고 있는 한 단계 위 레벨에서의 embedding space를 잘 구축해두고 이를 다시 아래 레벨로 내린다면 weak supervision에 가깝다는 저자의 고민이 담겨있는 방식인 것입니다.
Supervision이 가능한 moment-sentence level의 embedding space를 구축하기 위해서, 라벨을 활용해 각 모달리티의 moment prototype과 non-moment prototype을 생성해줍니다. 즉, Moment, sentence token을 구축한 뒤 contrastive learning을 수행하는 것입니다. 그림 4-(a)를 보면 비디오는 saliency label이 있으므로 보라색의 negative와 파란색의 positive로 나눠진 것을 볼 수 있습니다. 이후 Moment token M을 concat하여 self-attention을 거쳐줍니다. 이 과정은 아래 수식 4, 5와 같습니다. 수식 4, 5의 출력이 비디오의 moment prototype, non-moment prototype에 해당하는 것입니다.
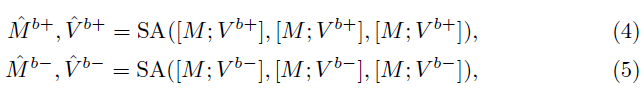
비디오는 라벨이 있었으니 positive, negative를 직접적으로 정의할 수 있었습니다. 텍스트와 비디오의 positive 관계는 명시적으로 정의되어있다고 하더라도 negative, 즉 반대되는 텍스트가 라벨링 되어있는 것은 아닙니다. 하지만 앞선 절에서 활용한 Dummy token이 이러한 역할을 수행하도록 학습되고 있었습니다. 따라서 텍스트 토큰을 positive, dummy token을 negative로 두어 위 수식 4, 5와 동일한 과정을 거칩니다. 여기엔 M 대신 Sentence token S를 사용합니다.
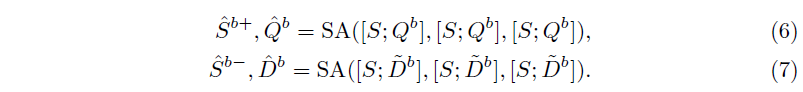
이렇게 positive, negative prototype을 추출했다면 이제 clip-word level의 contrastive learning을 수행합니다.
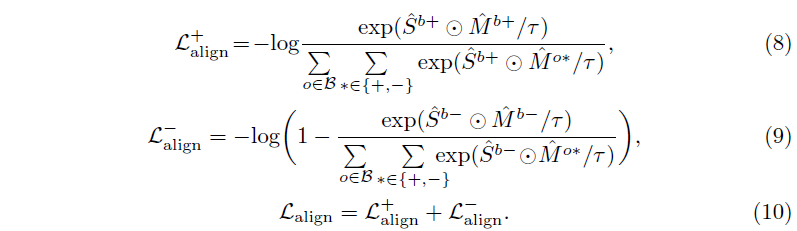
위 수식 8, 9, 10을 거쳐 contrastive learning이 수행되는데, 위 수식과 그림 4-(b)를 통해 알 수 있습니다.
Contrastive learning은 위와 같이 진행되고, 여기서 ACA 모듈의 cross-attention map의 guidance를 만들어줍니다.
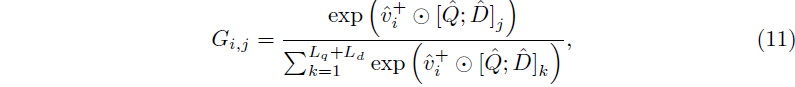
아무리 Dummy token이 positive와 반대쪽으로 학습되고 있다고 해도, 확실한 negative라고 보기엔 부정확한 부분이 있기에 GT 구간에 속하는 클립에 대해서만 guidance를 주게 됩니다. 이러한 guidance G는 아래 수식 12와 같이, 수식 1에서 만든 attention map의 guide가 됩니다. 그림 4-(c)를 참고하시면 쉽게 이해하실 수 있습니다.
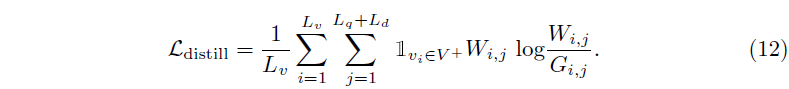
2.4 Moment-adaptive Saliency Detector
앞선 두 절에서 비디오-텍스트 쿼리, 클립-단어 레벨의 상관관계를 모델링했습니다. 여기서 제안하는 모듈은 Saliency score를 만들 때 moment의 특성을 고려해주고자하는 의도가 담겨있습니다. QD-DETR에서는 saliency token을 두고 비디오 토큰들에 concat해 self-attention을 거치고 FFN을 태워 saliency score를 얻었습니다. 이는 random으로 초기화되고 학습을 거치며 비디오와 텍스트 쿼리에 맞춤형인 토큰으로 학습되도록 기대하는 것입니다.
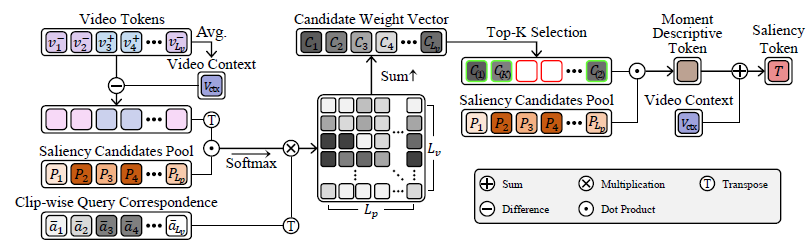
저자는 QD-DETR과 saliency token을 동일하게 활용하되 생성 과정을 좀 더 정교하게 만들어줍니다. 먼저 video context token을 도입해 추후 생성될 saliency token과 비디오 representation 간 discrepancy를 최소화합니다. 또한 moment-descriptive token을 도입해 moment들의 다양성을 담아줍니다. 이 두 토큰을 합쳐 saliency token을 만들어주게 되는 것입니다.
Video context 토큰 V_{ctx}는 단순히 비디오 내 클립들의 토큰을 평균내어 만들어줍니다. 동시에 moment-descriptive 토큰도 만들어줍니다. 이 과정은 우선 각 클립에서 V_{ctx}를 뺌으로써 distinctive characteristic을 모델링해주고, 이들과 saliency candidates pool에 있는 토큰들과의 유사도를 구합니다. 이 saliency candidates pool이 정확히 무엇으로부터 시작하는지 언급이 없는데, 아무래도 learnable vector인 것으로 보입니다. 이에 대해서는 추후 코드를 좀 살펴보아야 확실히 알 수 있을 것 같습니다. 이후에는 앞선 그림 3에서 얻었던 \bar{a}를 가중치로 사용해 클립 별로 곱해줍니다. 이 과정은 수식 13과 동일합니다.
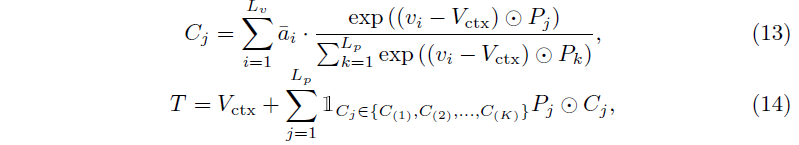
이후 candidate weight vector에서 top-K개만을 뽑아 엮어 Moment descriptive token으로 사용합니다. 최종 saliency token T는 V_{ctx}와 moment descriptive token을 더해 만들어줍니다.
2.5 Training Objectives
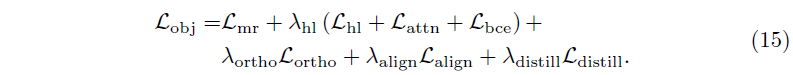
CG-DETR 학습에 사용되는 최종 loss는 위 수식에서의 \mathcal{L}_{obj}와 같습니다. \mathcal{L}_{mr}은 Moment Retrieval을 위한 loss로 예측 구간과 GT 구간 간 L1 loss + GIoU loss를 의미합니다. 나머지 loss들은 모두 본문에서 언급한 바와 같습니다.
3. Evaluation
MR 평가는 QVHighlights, Charades-STA, HD 평가는 QVHighlights, TVSum에서 진행되었습니다.
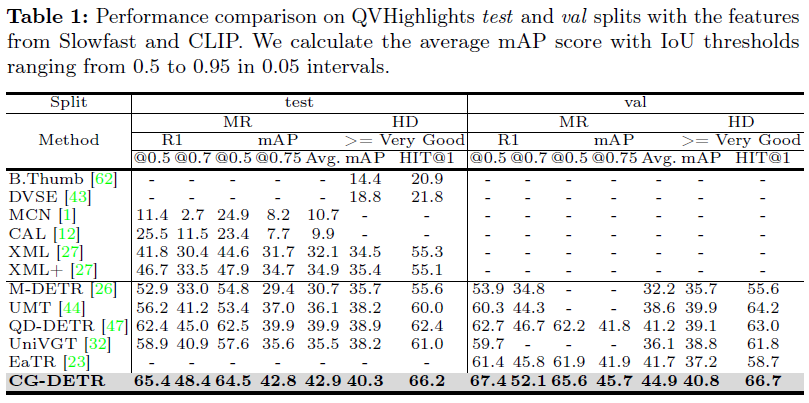
위 표 1은 QVHighlights 데이터셋의 test, val split에서의 성능입니다. CG-DETR이 2024 ECCV에 게재되었음을 감안하면 꽤나 인상적인 성능 향상 폭입니다. test split에서 MR의 평균 mAP는 3%, HD mAP는1% 이상 향상되었습니다. 이번에 읽은 CG-DETR이 제가 기존에 생각하던 조금 더 fine-grained한 수준의 모델링을 제안하였지만 이렇게까지 복합적인 후속연구가 바로 다음 해에 등장할 줄은 몰랐습니다. 정량적 성능이야 많이 올랐지만 코드가 공개되어있으니 잘 분석해보아야겠습니다.
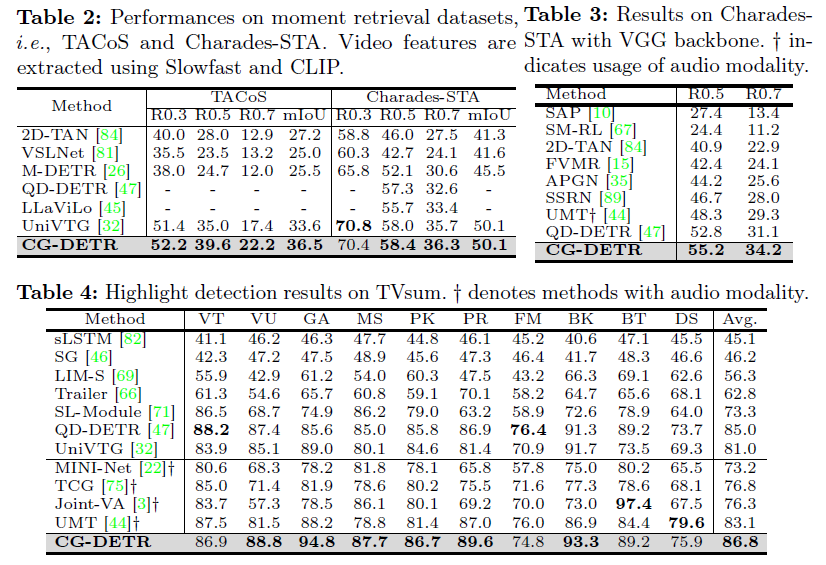
표 2, 3, 4는 각 데이터셋에서의 MR&HD 벤치마크 표입니다. 성능이 이전 연구인 QD-DETR보다 굉장히 많이 올라갔네요. 저자는 QD-DETR을 바탕으로 붙인 CG-DETR의 Clip-Word Correlation Learner 모듈이 추론 때는 관여하지 않기 때문에 inference time의 차이는 그리 크지 않다고 주장합니다.
3.2 Ablation Studies
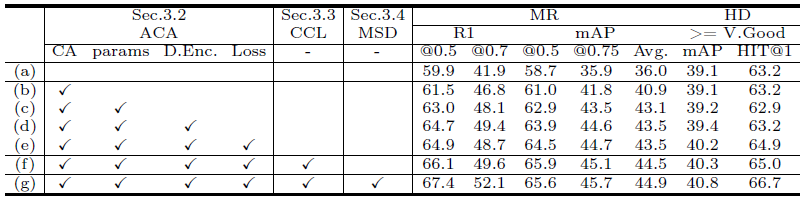
CG-DETR이 제안한 모듈에 대한 ablation study 결과입니다. (b)는 cross-attention 적용, (c)는 cross-attention 내 dummy token 활용, (d)는 dummy token 활용 시 encoding까지 수행을 의미합니다. 세부적인 구현상 디테일까지 ablation에 담고있고 각각이 유의미한 성능 향상을 보여주고 있음을 알 수 있습니다.
3.3 Analysis

저자는 그림 6을 통해 두 비디오-텍스트 쿼리 쌍에 대해 모델이 학습한 상관관계에 대한 분석을 진행합니다. 파란색 선 그래프는 GT saliency score, 붉은색 선 그래프는 multimodal interaction 후 attention weight의 단어 축으로의 합 값이라고 보시면 됩니다. 히트맵은 클립에 대한 단어 별 attention weight에 해당합니다.
위 결과를 살펴보면, 실제 salient한 비디오 구간에서 사람이 보았을 때 주요할 것으로 생각되는 단어들만이 높게 activation되는 것은 아닌 것 같습니다. 첫 번째 쌍 히트맵에서 ‘various’라는 단어가 비디오 클립에 표현되려면 어때야할지 제 머릿속으로는 잘 그려지지 않는데, 두 번째로 salient한 구간에서 꽤 많이 activation 되어있는 모습이네요. 저자가 주장하는 각 쿼리에서의 핵심단어 “food”와 “Two”가 잘 activation 되고 있다고 이야기하네요.
3.4 Qualitative Results
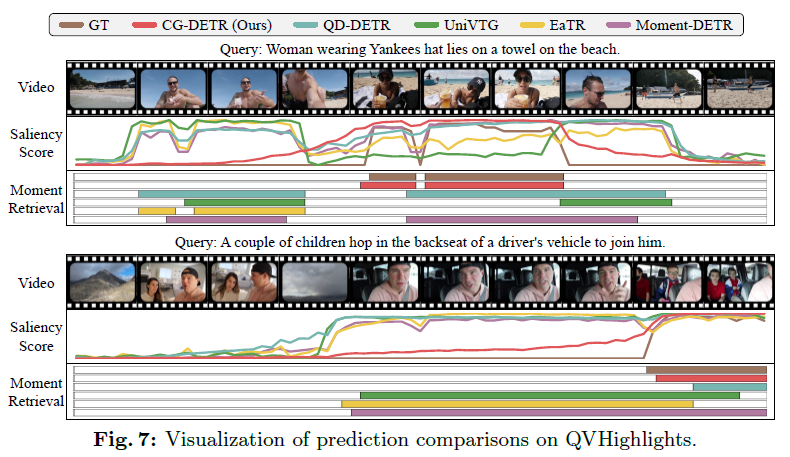
위 그림 7은 정성적 결과입니다. 저자도 별다른 분석을 내놓고 있지는 않고 MR 구간과 HD saliency score가 모두 타 방법론에 비해 GT와 유사하다는 이야기를 하고 있습니다.
이상으로 리뷰 마치겠습니다.
리뷰 잘 보았습니다.
저의 어렴풋한 기억으로는 아마 앞으로 논문 방향 중에서 text query의 fine-grained representation을 집중해서 연구해보고 싶다 이렇게 얘기를 했던 거 같습니다.
그런 관점에서 해당 논문이 비슷한 problem을 해결하고 있는 거 같네요.
방법론적인 측면 말고 컨셉적인 측면에서 해당 논문의 future work가 될 수 있는 부분이 있을까요?
저자도 밝히고 있는 CG-DETR의 장점은 텍스트 쿼리가 복잡할수록 잘 동작한다는 것입니다. 우선 이 task에 대해 텍스트 쿼리에 대한 학계와 실세계의 도메인 차이를 줄이고자 하는 컨셉으로 연구를 하려고 하는데, 저자가 밝히는 장점이 곧 텍스트 쿼리가 실세계 사용자들이 던지는 것과 같이 간단해졌을 때는 잘 동작하기 어렵다는 단점이 될 수 있으니 이 부분을 포인트로 잡아 연구를 하고자 생각중입니다.
아직 확정된 것은 아니고 예상하는 바이기 때문에, 좀 더 분석을 진행해보아야 할 것 같습니다.