Before Review
이번 논문은 요즘 제가 관심을 가지고 있는 Open-Vocabulary Scene Graph Generation을 처음으로 제안하는 논문 입니다.
방법론이 새롭거나 복잡한 부분은 딱히 없지만, 처음으로 문제 정의를 시도한 것이 인정 받아 게재가 된 것 같습니다.
리뷰 시작하겠습니다.
Introduction
Introduction 부분의 글은 중복되는 부분이 많아 지난 리뷰를 발췌하여 작성하였습니다.
Scene Graph Generation은 이미지에 존재하는 객체와 객체들간의 관계를 예측하는 작업으로 High-level Scene Understanding 능력을 요구로 합니다. Scene Graph의 구성 요소는 크게 세 가지로 구분이 됩니다. 1) Subject, 2) Predicate, 3) Object 로 세 가지가 존재하게 됩니다.

<subject, predicate, object>
즉, 이미지를 설명할 수 있는, 주어, 서술어, 목적어로 구성된, triplet을 잘 찾는 것이 최종 목적이라 보시면 됩니다. 하지만 이 Scene Graph Generation이라고 하는 task는 상당히 어려운 task라 볼 수 있습니다. 객체를 잘 찾는 것도 어려운데, 이 객체 간의 semantic relationship 까지 예측해야 하기 때문이죠.
그 높은 난이도 때문에 기존 연구들은 closed set 환경에서 연구를 진행하였습니다. 추론 과정에서 처음 보는 object나 관계에 대해서는 고려할 수 없는 문제 상황인 것이죠. 저자는 기존 연구들이 closed-set 환경에서만 문제를 푸는 것에 대해서 한계를 지적합니다. 실제 application level에서 학습 단계에서 보지 못한 객체들이 존재할 수 있지만 기존 연구들은 이런 open 시나리오에 대한 대응을 할 수 없었기 때문이죠.
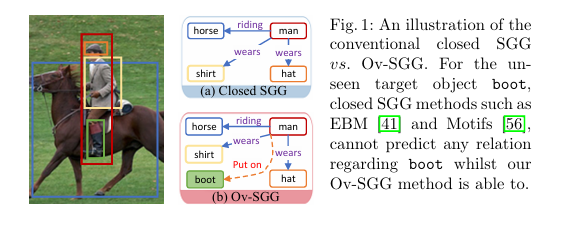
Motivation 자체는 굉장히 간단합니다. 기존 연구들이 풀지 못하는 문제들을 해결하기 위함이죠.
문제 상황에 따라 저자는 두 가지 세팅을 제안합니다.
Scene Graph Generation을 수행할 때 처음 보는 object만 고려한다면 Open Vocabulary SGG (Ov-SGG) 이고 처음 보는 관계 (predicate) 까지 고려한다면 generalized Open Vocabulary SGG (gOv-SGG)로 정의하고 있습니다.
어떤 문제를 해결하고 싶은지는 굉장히 직관적이니 저자가 제안하는 framework에 대해서 간단하게 소개하고 method에 대해서 자세히 알아보도록 하겠습니다.
저자는 Ov-SGG 혹은 gOv-SGG를 해결하기 위해 two-step method를 제안합니다.
첫 번째는 1) visual-relation pre-training 이고 다음으로 2) prompt-based finetuning을 진행합니다.
Visual-relation pre-training에서는 CLIP이나 GLIP과 같은 VLM 방법을 바로 활용하는 것이 아니라고 합니다. 저자가 직접 제안하는 방식으로 pre-training을 진행합니다. GLIP 같은 경우는 object detection 용으로 제안이 되었기 때문에 SGG에 적절할 수 있지만 저자가 고려를 하지 않은 것 같고 CLIP 같은 경우는 image-text pair로 사전 학습이 되었기 때문에 fine-grained level의 representation이 부족하여 저자는 Visual Genome의 자세한 regional text를 활용하여 CLIP을 사용하는 것이 아니라 직접 사전 학습을 진행했다고 합니다.
Prompt-based finetuning은 finetuning 이지만 사전 학습 때 배운 representation을 보존하면서 down-stream task에 적합한 prompt를 생성하는 방식으로 Ov-SGG를 설계 합니다. 기존 finetuning 방식 처럼 target task를 위한 Learnable Layer를 추가하고 모델의 파라미터를 다시 학습하게 되면 사전 학습 때 찾은 파라미터가 변형되어 generality를 잃게 된다고 합니다. 따라서 이를 방지하기 위해 target task에 적합한 prompt만을 찾는 방식으로 finetuning을 진행하여 generality를 보존하고 zero-shot 성능의 고도화를 이끌어 냈다고 합니다.
제안하는 방법론은 이게 전부 입니다. 어렵지 않으니 바로 이어서 설명 들어가도록 하겠습니다.
Proposed Method
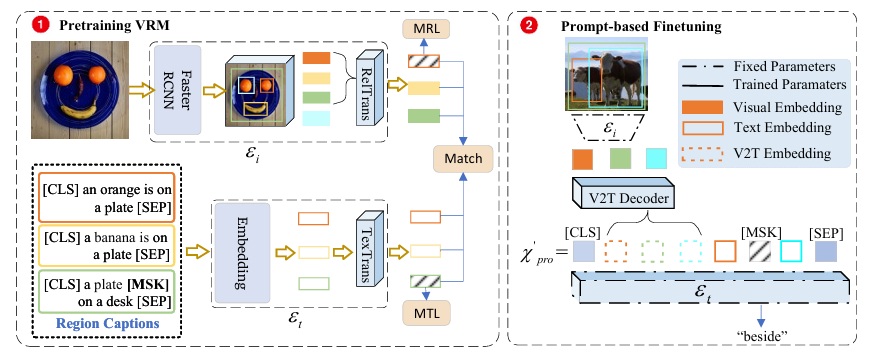
Pretrained context-aware visual-relation model
기본적으로 Open-Vocabulary Learning을 하기 위해서는 CLIP과 같이 대규모 사전 학습이 진행된 Vision-Language Model (VLM)의 역할이 중요합니다. 하지만 저자는 Scene Graph Generation과 같이 Object-level의 representation이 중요한 task에서는 CLIP이 적절하지 않고 이를 대체하기 위해 VG-caption을 활용하여 Transformer 기반의 Image, Text Encoder를 SGG task에 맞춰 새롭게 사전 학습을 하려고 합니다.
VG-caption (Visual Genome Caption) 같은 경우는 이미지 한장 당 50개 정도의 dense한 caption이 존재하여 이미지 전체를 간단하게 설명하는 것이 아니라 regional 하게 구체적으로 설명하기 때문에 Ov-SGG에 적합하다고 판단한 것 같습니다.
Image Encoder
Imaeg Data를 처리 하는 부분은 두 가지로 구분이 됩니다. Faster-RCNN과 같이 region proposal feature extractor 부분 과 Transformer로 구성되어 region feature를 encoding 해주는 부분으로 구분을 하고 있네요.
여기서 region feature를 encoding 해줄 때 독립적으로 각 region을 encoding 하는 것이 아니라 union region을 기준으로 encoding을 하여 좀 더 relation context를 잘 이해할 수 있게 설계하였습니다.
Faster RCNN을 돌려서 region proposal을 하면 여러가지 region이 검출됩니다. 여기서 랜덤하게 두 개의 anchor region을 선택하여 top-left r_{t}와 , bottom right r_{b}를 지정합니다.
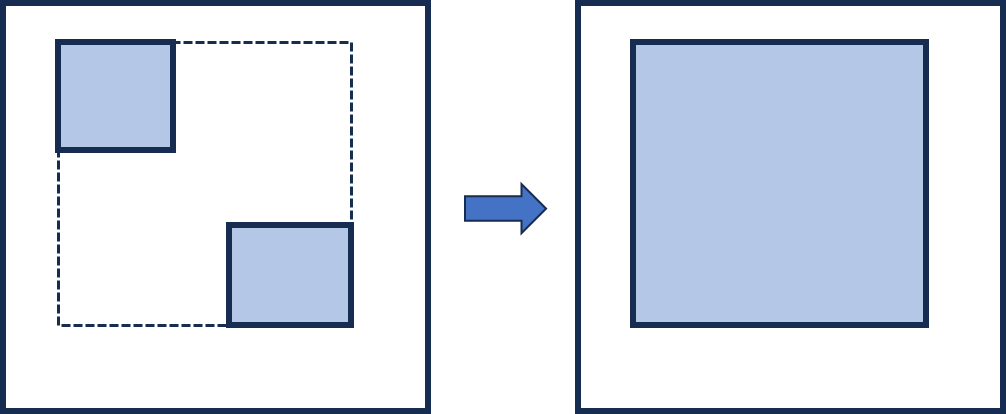
이런식으로 말이죠. 그 다음에 다른 region proposal 과는 IoU를 계산하고 thresholding을 통해서 regional context [r_{1}, \cdots, r_{m}]로 정의합니다. 위에서 정의한 union region과 IoU가 어느 정도 겹치면 context로 활용하여 Transformer 입력으로 넣어주는 것이죠.
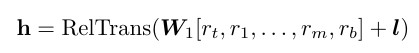
여기서 \mathbf{W}_{1}는 Faster RCNN의 regional feature를 새로운 공간으로 투영 시켜주는 학습 가능한 proejction matrix 이고 mathbf{l}는 positional encoding 입니다.
Text Encoder
Text Encoder도 동일하게 Transformer 구조로 되어 있습니다. 복잡한 구조는 없고 Visual Genome에 존재하는 dense text caption을 embedding 시켜줍니다.
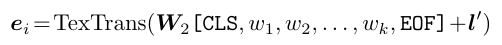
한가지 궁금한 부분은 이미지 데이터를 처리할 때 Faster RCNN을 통해서 여러가지의 region을 검출한다고 했습니다. 여기서 검출된 region r_{i} 마다 대응 되는 caption을 활용 했다고 하는데 이게 정확히 annotation된 caption이랑 검출된 region이랑 매치가 되는지는 잘 모르겠네요.
이런 부분에 대한 자세한 내용은 나와 있지 않아 일단 그렇다고 가정하고 설명하겠습니다.
w_{1}, \cdots, w_{k}로 부터 나온 e_{i}는 region r_{i}와 매칭 되는 text embedding이라고 합니다. 마찬가지로 \mathbf{W}와 \mathbf{l}'는 학습 가능한 layer와 positional embedding 입니다.
Pre-trained Loss Function
Loss는 간단하게 cosine sim 기반의 matching loss와 masking loss로 구성되어 있습니다.
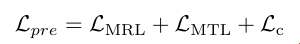
- \mathcal{L}_{\text{c}} : Transformer를 타고 나온 visual embedding과 대응 되는 text caption 과의 유사도를 조절하는 contrastive loss 입니다. 다만, formulation에 대한 디테일은 서술하지 않네요.
- \mathcal{L}_{\text{MRL}} : Maksed Region Loss의 약자로, \mathbf{h}=\text{RelTrans}(\mathbf{W}_{1}[r_{t},r_{1},\cdots,r_{m},r_{b}]+\mathbf{l})의 일정 부분을 masking 하고 (특정 region feature를 지운 다는 의미) 대응되는 ground-truth caption embedding과 유사해지는 contrastive loss라고 합니다. 이를 통해 relation predictiopn 에서의 표현력을 강화시킨다고 하네요.
- \mathcal{L}_{\text{MTL}} : Text의 일정 부분 masking 하고 reconstruction 하는 loss 입니다. BERT에서 사용하는 구조와 동일합니다.
네 이렇게 Pre-train 방식에 대해서 알아보았습니다. 이미지의 region과 대응되는 text caption만 존재한다면 간단하게 설계할 수 있는 module로 구성한 것 같습니다.
다음으로는 finetune 과정에 대해서 알아보도록 하겠습니다.
Prompt-based Finetuning for Ov-SGG
일반적인 finetuning 방식은 사전 학습된 encoder 뒤에 새로운 classifier (보통은 linear layer)를 추가하여 전체 파라미터를 다시 재조정 하는 과정으로 진행됩니다.

하지만 이런 방식은 사전 학습 때 배운 일반성을 해치기 때문에 Open-Vocabulary 상황에 적합하지 않습니다. Finetune 과정에서 target dataset에 fitting 될 위험이 있기 때문이죠.
따라서 저자는 원래의 파라미터를 바꾸지 않으면서도 (사전 학습 때 얻은 지식을 유지) 좋은 성능을 유지할 수 있는 prompt-based finetuning을 제안합니다.
Hard prompt based finetuning
Scene Graph Generation은 결국 Subject-Predicate-Object (SPO) triplet으로 구성이 됩니다.

이를 고려하여 relation prompt를 다음과 같이 정의할 수 있습니다. x_{s}, x_{o}는 subject, object의 category text label 입니다. 그리고 [MASK]가 predicate를 위한 slot이라 볼 수 있죠. 그 다음에는 아래와 같이 relation label을 예측 합니다.
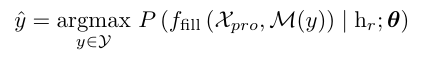
어려워 보이지만 핵심은 h_{r} = \text{LN}(h_{s},h_{so},h_{o}) 입니다. h_{r}가 relation feature를 위한 임베딩 모듈이고 이 h_{r}와 위에서 정의한 relation prompt 간의 유사도를 최대화 시키도록 학습이 진행되는 것이죠.
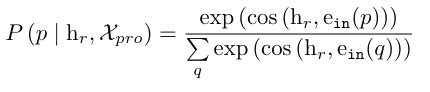
즉, mask token에 여러가지 predicat를 넣어보고 그 중 가장 실제 SPO에 해당하는 predicate token과의 코사인 유사도가 최대가 되는 방식으로 학습이 된다고 보시면 됩니다.
Soft visual-relation prompt (SVRP) based finetuning
위에서 정의한 Hard prompt 방식은 아래와 같이 prompt를 고정해서 사용했습니다. Hand-crafted 방식이라 볼 수 있죠.
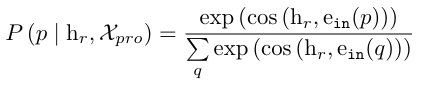
여기에 더불어 soft prompt 방식은 subject, object 뿐 아니라 아까 위에서 정의한 context를 추가하여 prompt를 정의합니다.

사실 바뀌는 부분은 저기 prompt를 정의할 때 IoU가 일정 threshold를 넘기는 context region들을 추가해주는 부분 말고는 크게 달라지는 부분이 없습니다.
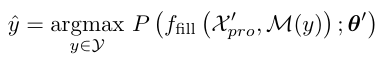
여기서는 context까지 활용하는 임베딩을 활용하기 때문에 위에서 정의한 임베딩 레이어와는 다른 파라미터로 초기화를 진행합니다.
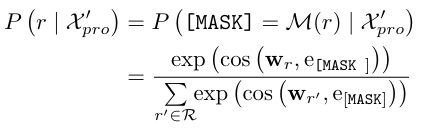
Experiments
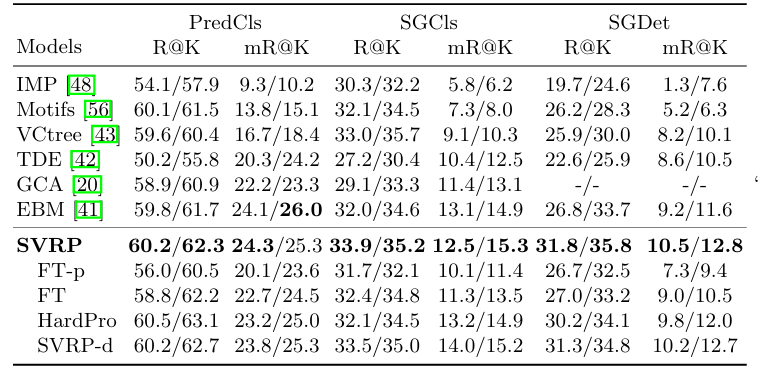
가장 먼저 벤치마킹 실험 입니다. 두 개의 데이터 셋 (VG, GQA)에 대해서 성능을 리포팅하고 있습니다.

타 방법론 대비 모든 세팅 (Cs, Ov, ZsO)에서 모두 좋은 성능을 보여주고 있습니다. 궁금한 건 다른 베이스라인 방법론들 중에서 Ov나 ZeroShot이 안되는 방법들이 있을텐데 실험을 어떻게 했는지는 설명해주고 있지 않네요.

Opem Image라는 데이터 셋 에서도 비교를 하고 있는데 역시나 가장 좋은 성능을 보여주고 있습니다. 딱히 분석적인 내용은 없네요.
마지막으로 Fully Supervised 상황에서의 비교 입니다. 벤치 마킹 실험에서는 딱히 할 얘기가 없네요.
개인적으로는 벤치 마킹 실험 때 사용한 데이터 셋 종류를 비교 했으면 좋았을 텐데 그 부분이 없어서 조금 아쉬웠습니다.

정성적 결과 입니다. 기존 Closed setting인 EBM (파란색 그림) 대비 Ov-SGG 상황에서의 제안한 방법이 더 많은 object와 관계를 검출하면서 더욱 풍부한 scene graph를 생성해내고 있는 모습을 보여주고 있습니다.
본 task의 확장 가능성 정도만 보고 넘어가면 될 거 같네요.
Conclusion
Motivation 자체는 새롭지만 method 관련해서는 novelty가 강한 거 같지는 않습니다. 보통 이렇게 task를 처음 제안하는 논문의 경우 코드도 같이 공개하던데 본 논문은 그러지 않고 있네요.
후속 연구들이 베이스라인을 어떻게 잡았을지 고생이 좀 많았을 거 같네요.
다음 리뷰에서는 좀 더 최신 연구 동향을 나타낼 수 있게 24년도 논문을 리뷰 해보도록 하겠습니다.