안녕하세요. 박성준입니다.
제가 오늘 리뷰할 논문은 바로 CVPR 2024에 등재된 UVCOM입니다. UVCOM은 Unified Video COMprehension의 약자로 Moment Retrieval과 Highlight Detection task를 다룰 수 있는 Unified 모델입니다.
Abstract
비디오의 관심이 증가하며, Moment Retrieval(이하 MR)과 Highlight Detection(이하 HD)에 대한 관심이 증가하고 있습니다. 최신 연구들은 MR과 HD를 비슷한 video grounding task로 여기며 트랜스포머 기반의 architecture로 통합하여 다루는 경향이 있습니다. 하지만, 저자는 MR이 local relation에 집중하는 반면 HD는 global context에 집중한다는 것을 강조하며, 기존의 MR과 HD를 같은 task로 여기는 것은 잘못된 접근방식이라고 지적합니다. 따라서, 저자가 제안하는 UVCOM은 MR과 HD를 동시에 다루기는 하지만, multi-granularity(coarse-grained와 fine-grained를 모두 읽컫는 용어)를 다루기 위해 inter, intra-modality를 모두 다뤄 local과 global 정보에 모두 집중하여 MR, HD 모두에서 좋은 성능을 가지는 모델입니다. 또한 UVCOM은 multi-aspect contrastive learning을 도입하여 local relation과 global knowledge를 통합할 수 있었다고 강조합니다.
Introduction
인터넷의 발전으로 비디오는 다양한 플랫폼에서 활용되고 최근에 많이 연구되는 연구주제 중에 하나입니다. 온라인에서 비디오 매체는 사용자로 하여금 사용자가 원하는 영상을 제공하는 것을 목표로 할 때가 많습니다. 그러한 관점에서 모든 영상에 시간을 쏟는 것 보다는 자연어 설명에 맞는 특정 구간의 클립을 제공하는 것은 중요한 연구입니다. 이러한 관점에서 MR과 HD는 현재 연구되고 있습니다. MR은 자연어 쿼리가 주어졌을 때에 비디오에서 자연어 쿼리에 해당하는 구간을 반환하는 task이고, HD는 자연어 쿼리가 있을 때에 영상에서 쿼리와 관련이 있는 구간를 relavancy score를 통해 표현하여 구간(하이라이트)를 반환하는 task입니다.
두 task는 굉장히 비슷한 점이 많습니다. 두 task 모두 쿼리와 비디오가 인풋으로 주어지고, 비디오의 구간을 반환한다는 공통점이 있지만, 두 task가 같은 task는 아닙니다.

Figure 1. 은 저자가 영상과 쿼리가 주어졌을 때에 MR과 HD가 각각 영상의 어떠한 구간에 집중하는 지를 attention map을 통해서 시각화한 figure입니다. Figure 1. 에서 확인할 수 있듯이 MR은 특정 구간에 attetion map이 활성화되는 반면에 HD의 경우 영상 전체적인 구간에 attetion map이 활성화되는 것을 확인할 수 있습니다. 저자는 위의 figure를 강조하며 MR과 HD가 같은 model로 다루기 위하여 하나의 task에 집중하다보면 다른 task에서는 온전한 성능을 낼 수 없다고 강조합니다.
기존에 MR과 HD를 같이 다루던 방법론들은 이와같은 문제를 다룬 적이 없습니다. Moment-DETR은 트랜스포머 기반 객체 검출기인 DETR에서 영감을 받아 MR과 HD에 대해 동시에 annotation이 된 QVHighlight 데이터셋을 공개하며 두 task를 동시에 다룬 첫 연구입니다. 이후에 UMT는 비디오 텍스트 뿐만 아니라 오디오까지 통합하는 multi-modal architecture로 성능을 개선했고, QD-DETR은 text-query dependent video representation을 활용하며 MR과 HD에서 SOTA를 달성하며 CVPR 2023에 등재된 논문입니다. 하지만, 저자는 위의 3연구 모두 local relation에 집중하는 MR, global context에 집중하는 HD의 각 task별 특징에 집중하지 못하였다는 것을 문제점으로 지적하며 저자는 두 task에서 각각의 task의 특징을 잘 다룰 수 있는 통합 모델인 UVCOM을 제안합니다.
UVCOM은 MR과 HD를 모두 다루기 위해서는 두가지가 필요하다고 언급합니다. 첫번째는 Local Relation Activation입니다. 앞에서 설명드렸던 것처럼 MR은 local relation에 집중하는 task이기에 통합 모델 역시 local relation activation이 필요합니다. 두번째는 Global Knowledge Accumulation입니다. HD는 영상의 global context에 집중하기에 통합 모델 또한 global knowledge에 집중해야합니다. 문제는 어떻게 위 두가지를 모두 다룰 것인가 하는 것인데 UVCOM은 Comprehensive Integration Module(CIM)를 제안하며 위 모듈을 통해 두가지를 모두 다룰 수 있었음을 강조합니다. CIM은 local relationship perception을 실현시키기 위해 텍스트에서 집계된 semantic phrase를 시각적 특징으로 전파합니다. 그 다음에는 moment-awareness 특징을 활용하여 비디오에서 global information을 축적합니다.
UVCOM의 contribution은 다음과 같습니다.
- MR과 HD task에서 집중하는 부분이 서로 다릅니다.
- UVCOM은 CIM 모듈을 제안하여 temporal, multi-modal의 관점에서 local perception과 global knowledge를 다뤄 multi-granulartity에서 모두 잘 기능합니다.
- 멋으로 붙이는 부가기능 없이 UVCOM은 MR, HD에서 모두 눈에 띄는 성능 개선을 이뤄냈습니다.
Method
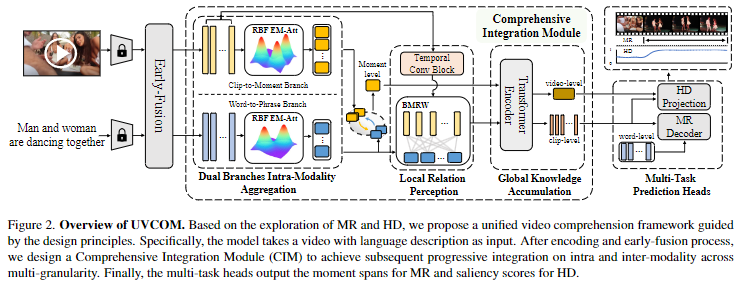
위 Figure 2.는 UVCOM의 전체 architecture를 한눈에 보여주는 figure입니다.
비디오에서 $L$개의 클립 $\{v_1, v_2, \dots , v_l\}$와 텍스트 특징 $\{e_1, e_2, \dots , e_n\}$이 주어지면, MR의 목표는 텍스트에 가장 일치하는 구간을 중앙좌표와 영상의 길이를 통해 표현하고 HD의 목표는 전체 영상에서 클립별 saliency score를 생성하여 saliency score 분포를 생성하는 것입니다.
Visual-Text Encoding
먼저 CLIP, SlowFast, I3D와 같은 비디오 인코더를 통해 영상의 특징을 추출합니다.
$F_v \in R^{N \times D}$로 표현할 수 있고, 여기서 D는 차원을 의미합니다.
그 다음은 CLIP의 텍스트 인코더를 통해 텍스트 임베딩에 대한 linguistic expression을 확보합니다.
$ F_t \in R^{N \times D}$로 표현할 수 있고, 마찬가지로 D는 차원을 의미합니다.
그 후 두 feature를 bidirectional 트랜스포머 기반의 encoder를 활용하여 early fusion을 진행합니다. 이는 coarse하게 다른 두 모달리티의 특징을 인코딩하고 예비적으로 정렬된 시각적 및 텍스트 표현을 출력합니다.
Comprehensive Integration Module(CIM)
CIM은 figure 2. 에서 시각화된 것처럼 Dual Branches Intra-Modality Aggregation, Local Relation Perception과 Global Knowledge Accumulation으로 구성되어있습니다. CIM은 multi-granularity 전반에 걸쳐 점진적으로 intra, inte-modality 통합을 수행합니다. 특히 저자는 EM attention을 통해 moment-wise 시각적, 텍스트 feature를 생성하여 inner-modality content를 연관시킵니다. 그 후 Local Relation Perception(LRP)를 제안하여 temporal relationship modeling과 inter-modality fusion을 통합합니다. 이는 temporal 그리고 modality의 inter connection을 reformulate하여 locality perception을 강조합니다. 해당 파트가 CIM에서 local relation을 다루는 파트입니다. 마지막으로 일반적인 인코더를 사용하여 video-wise feature를 다룹니다. 마지막 파트에서 global context를 다룹니다.
Dual Branches Intra-Modality Aggregation
비디오은 기본적으로 적어도 한개 이상의 event가 존재합니다. 따라서 쿼리에 일치하지 않는 background scene이 많이 존재합니다. 중요하지 않은 단어들과 unconstrained(거리낌 없는)한 표현들은 모호함을 초래할 수 있습니다. 이러한 문제를 해결하기 위하여 저자는 RBF-kernel을 기반으로하는 EM Attention을 사용합니다. Figure 2.에서 볼 수 있듯이 해당 모듈은 dual branch로 위의 경로는 clip-to-moment branch로 배경 노이즈를 지우는 동시에 event 표현력을 증가시킵니다. 밑의 경로는 word-to-phrase branch로 contextual 정보를 축적시키는 것으로 moment description을 강조합니다.
구체적으로 $F_v$와 $F_t$를 따로 Gaussian Mixture Model에 fit하는 것으로 콤팩트한 moment, phrase-level 표현력으로 생성합니다. clip-to-moment branch를 예시로 들어 설명하면,
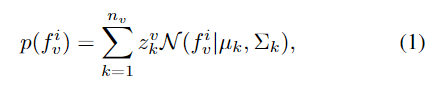
1번 수식은 가우시안 분포를 나타내는 수식으로 $f^i_v$는 $F_v$의 i번째 snippet(영상 구간의 단위)입니다. clip-to-moment branch의 k번째 가우시안에서 $z^v_k$는 가중치, $\mu_k$는 평균, $\sum_k$는 분산을 나타냅니다.
저자는 여기서 단순화를 위하여 분산을 identity matrix $I$로 교체하고 rank basis function (RBF kernel) $K(f^i_v, \mu_k)$를 적용하여 사전학습 $N(f^i_v|\mu_k,I)$를 계산했다고 합니다.
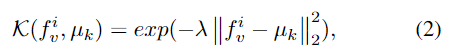
여기서 $\lambda$는 하이퍼파라미터로 분포를 조절하는 역할을 합니다.
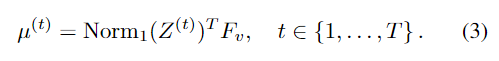
t번째 interation 이후 E 단계에서 가중치 $Z^{(t)} \in R^{L \times n_v}$를 부여하고 M 단계에서 $\mu^{(t)} \in R^{n_v \times D}$를 다시 추정하면 (3) 수식과 같이 공식화 됩니다.
여기서 초기화된 평균 $\mu^{(0)}$는 학습가능한 파라미터로 위의 과정에서 데이터셋의 feature 분포를 역전파를 통해 효과적으로 학습할 수 있습니다.
t번의 iteration 이후 저자는 contextual 정보를 완전히 집계하는 $\mu^{(t)}$로부터 fine-grained moment-wise 표현력 $F_m$을 얻을 수 있다고 강조합니다. 위의 과정은 word-to-phrase brach에서도 동일하게 진행되며 phrase수준의 언어 특징을 얻을 수 있다고합니다.
수식이 굉장히 많이 나오는데 솔직히 아직 정확하게 이해하지 못했습니다. 추후에 EM Attention에 대해 더 공부한 후에 다시 정리하여 수정해두겠습니다. 일단은 두가지 branch가 존재하며 video feature와 text feature 각각 가우시안 정규분포를 통해 중요한 정보를 더 강조하고 불필요한 노이즈를 제거했다고 이해하고 넘어가면 될 것같습니다.
Local Relation Perception
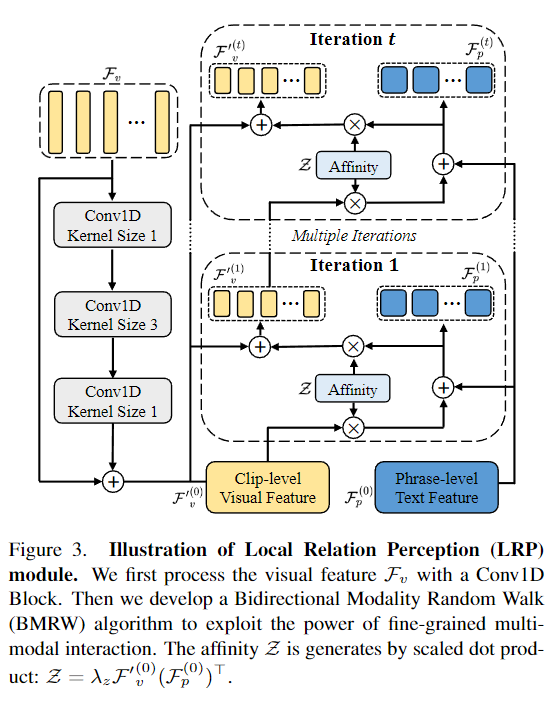
만약 이웃 클립(바로 다음 혹은 전 시간대의 클립)의 정보 없이 단순히 coarse한 clip-word fusion은 모델로 하여금 관련있는 클립의 boundary를 파악하는 것을 힘들게 만들 수 있습니다. 이 문제를 해결하기 위해 LRP는 temporal과 inter-modality relationship을 모두 파악합니다. figure 3.은 LRP의 구조를 보여주고 있고, 우선 temporal convolution을 통해 clip-level feature의 local perception을 향상시킵니다.
$F’_v=Conv(F_v) + F_v$
단순히 clip-level relation을 활용하는 것은 local redundancy(중복성)을 토래할 수 있습니다. untrimmed video(정제되지 않은 긴 영상)의 복잡한 시나리오는 attention이 필요치 않은 부분에도 집중할 수 있다는 문제가 있습니다. 또한 phrase-wise 언어 특징은 word-wise 언어 특징보다 노이즈가 많은 가능성이 높기 때문에 이를 해결할 방법으로 저자는 LRP 내에 bidirectional modality random walk(BMRW) 알고리즘을 사용합니다. 이는 일치하는 local context를 강조하고 일치하지 않는 것을 suppressing(억압)합니다.
Figure 3. 에서 오른쪽 부분에 해당하는 BMRW 알고리즘에서 affinity는 $Z = \lambda F’^{(0)}_v (F^{(0)}_p)^T)$이고 이는 Dual Branches Intra-Modality Aggregation의 output인 clip-level feature를 temporal convolution을 진행한 feature와 phrase-level feature scaled dot-product 연산을 수행한 값입니다. %\lambda$는 scaling해주는 값입니다.
t번째 iteration의 output인 $F_p^{(t)}$와 $F_v^{(t)}$는 다음과 같은 수식으로 표현됩니다.
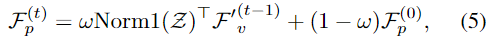

여기서 $\omega \in (0,1)$는 modalities fusion을 위한 값입니다.
Neumann Series에 의하여 저자는 inference 함수를 통해 근사시킨다고합니다.
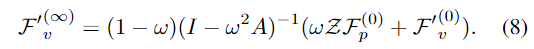
Global Knowledge Accumulation
figure 1. 에서 언급한 것처럼 저자는 HD에서 global 정보를 다루는 것을 중요하게 생각하고 있습니다. QD-DETR에서는 saliency token을 사용하여 general 정보를 다룹니다. 하지만, input-agnostic한 design은 텍스트 관련 간격에 대한 perception이 저하될 수 있습니다. 따라서 저자는 moment-aware feature를 비디오에 대한 global knowledge를 축적하는 방법을 제안합니다.
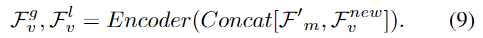
결과적으로 의미론적인 snippet은 참조된 순간에 초점을 맞춰 non-target response를 억제하고 비디오의 특징에 집중합니다.
Multi-Aspect Contrastive Learning
CIM은 앞에서 설명드린 것처럼 temporal과 inter-modality의 local relation을 강화시킵니다. 따라서 저자는 마지막으로 행렬곱을 활용한 contrastive loss를 활용하여 relavant clip을 구합니다.
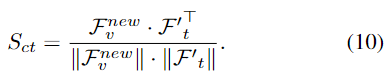

Video-Linguistic Discrimination
비디오 수준의 시각적 특징이 관련 문장 수준의 텍스트 표현은 닫고 거리가 관련되지 않은 헤분화된 다중 모드 관련 공간을 구축하는 것을 목표로 합니다.
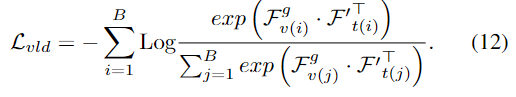
Prediction Heads and Loss Function
Figure 2. 에서 시각화된 구조에서 확인할 수 있듯이 두개의 간단한 Head를 통해 CIM을 거친 feature를 통합합니다. MR Head는 쿼리에 해당하는 일련의 순간을 범위 $P_m$을 생성하기 위한 $F_t$를 활용하는 표준 디코더로 구성됩니다. HD Head는 fully-connected layer로 구성된 두개의 그룹으로 구성되어 있습니다. sliency score는 다음과 같이 구성되었습니다.
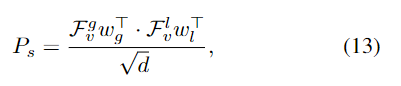
Total Loss
MR의 경우 L1 loss와 GIoU loss를 활용하여 loss를 계산합니다.
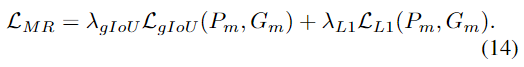
HD는 margin ranking loss와 rank-aware loss를 사용합니다.
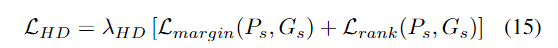
Experiment
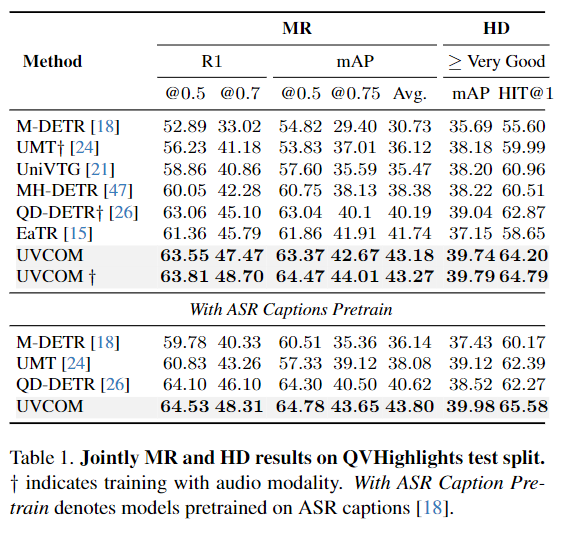
Table 1.은 MR과 HD의 결과를 QVHighlight에 Inference한 결과를 보여주고 있습니다. UVCOM은 coarse-grianed과 fine-grained를 모두 잘 다룰 수 있는 모습을 보여주며 HD와 MR에서 모두 좋은 성능을 보여주며 SOTA의 성능을 달성한 것을 확인할 수 있습니다.

추가로 UVCOM은 MR에서 자주 사용되는 Charades-STA데이터셋과 TACoS에서의 결과도 직접 Inference하며 결과를 보여주고 있습니다. MR에서는 UVCOM의 성능이 다른 모든 방법론들보다 좋은 성능을 보여주며 fine-grained에서의 성능의 월등함을 보여줍니다. CIM을 통해 local relation에 집중하는 UVCOM이 다른 방법론들에 비해 좋은 성능을 보여주는 것이 눈에 띄네요.
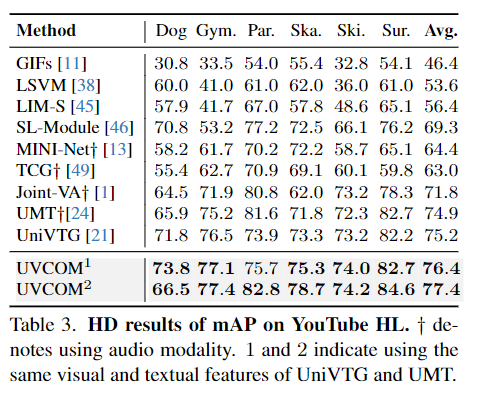
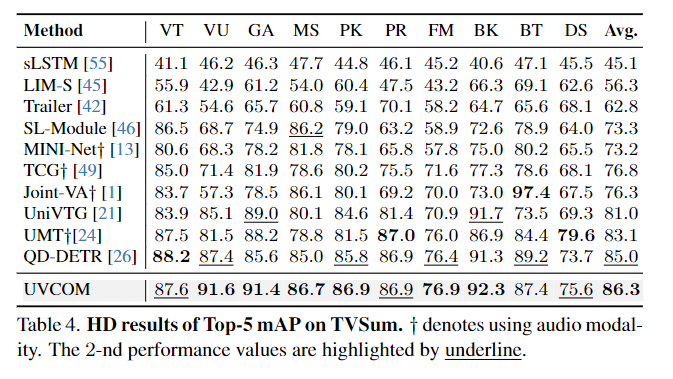
HD에서도 UVCOM은 좋은 성능을 가져간다는 것을 Table 3.와 Table 4. 에서 보여주고 있습니다. 실제로 QVHighlight에서뿐만 아니라 다른 HD 데이터셋인 YouTube HL와 TVSum에서도 좋은 성능을 보여주며 MR과 HD 모두에서 좋은 성능을 보여주는 것은 저자는 Experiment에서 보여주고 있습니다.
Ablation Study
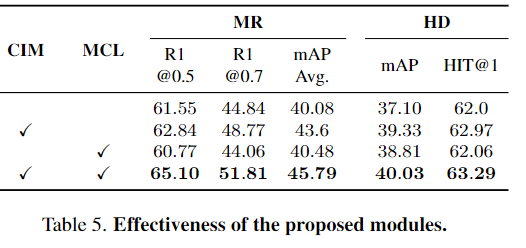
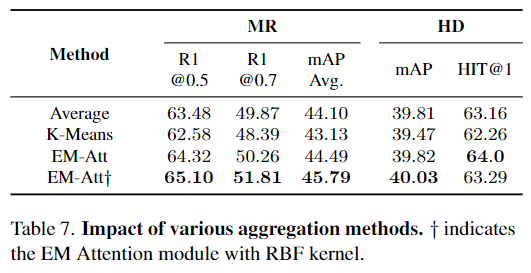
Table 5.은 저자가 제안하는 CIM과 MCL의 성능을 적용하지 않았을 때와 비교하며 저자의 방법론이 얼마나 효과적 인지를 강조하고 있습니다. 또한 Table 7. 은 저자가 도입한 EM Attention을 적용하는 것이 다른 방법론을 적용했을 때와 차이를 보여주며 저자가 제안하는 방법론이 저자가 파악한 문제점을 잘 해결한다는 것을 반증하는 결과를 보여줍니다.

Table 6. 은 특히 CIM 모듈에서도 CIM 에 포함되어 있는 다른 모듈들이 포함되어 있을 때와 포함되어 있지 않을 때를 비교하며 자신들이 제안하는 CIM에 포함된 모듈들의 필요성을 강조하고 있습니다. 실제로 중간에 포함되어 있는 다른 DBIA와 LRP, GKA 가 모두 포함되어 있을 때가 가장 좋은 성능을 보여주며, 자신들이 제안하는 모듈들이 모두 coarse-grianed, fine-grained 에서 즉, multi-granularity 에서 좋은 성능을 보여주고 특히 MR과 HD에서 모두 좋은 성능을 보인다는 것을 보여줍니다.


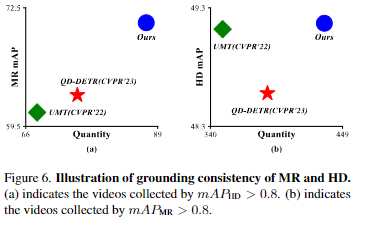
Figure 4.는 UVCOM은 기존 SOTA모델인 QD-DETR과 비교하며, UVCOM이 QD-DETR과 비교하여 MR과 HD모두에서 효과적인 성능을 낸다는 것을 정성적으로 보여주는 figure입니다.
Figure 5. 는 리뷰의 처음에 소개했던 Figure 1. 에서와 마찬가지로 저자는 attention map에서 MR과 HD에서의 차이점을 강조하며 자신의 방법론이 얼마나 효과적으로 이 차이점을 잘 대응하고 있는 지를 강조합니다.
Figure 6.은 기존의 방법론들에 비해 얼마나 자신들이 제안하는 방법론인 UVCOM이 얼마나 효과적인지를 강조합니다.
Conclusion
저자는 MR과 HD에서 모두 효과적으로 잘 적용될 수 있는 방법을 찾고자했고, UVCOM을 제안하며 fine-grained에 집중하는 MR과 coarse-grained에 집중하는 HD에 모두 적용할 수 있는 UVCOM을 제안하여 MR과 HD 모두에서 좋은 성능을 보입니다. 추가로 저자는 아직 오디오 modality를 UVCOM에서는 다루지 못하는 것을 언급하면서 UVCOM의 한계점을 언급하며 논문을 마칩니다.
UVCOM은 기존의 방법론들이 MR과 HD를 동시에 다루는 것을 당연시하며 트랜스포머 기반의 방법론들은 coarse-grained와 fine-grained를 모두 다루지 못하며 MR과 HD를 효과적으로 다루지 못했다는 것을 지적하며 UVCOM은 두 task의 특징을 잘 반영하며 좋은 성능을 내는 것을 강조합니다. 저도 다른 논문들을 읽으며 MR과 HD가 비슷한 task라서 그냥 단순히 방법론들을 적용하는 것으로 성능에 개선을 일으킬 수 있을 것이라 생각하는 기존의 방법론에 의문을 제기하는 해당 논문이 굉장히 인상적이네요.
감사합니다.
리뷰 잘 읽었습니다.
수식에 대한 설명이 많이 빠지는 부분은 추후 논문을 많이 읽어보면서 보완하시면 좋을거 같네요.
1. RBF Kernel이 무엇인지 설명 가능할까요?
2. Neumann Series는 무엇인지 설명 가능할까요?
GMM을 찾는 과정에서 평균만 다룬 거 같은데 공분산은 어떻게 구하는지 간단하게 설명 부탁드립니다.
안녕하세요. 좋은 리뷰 감사합니다.
세미나를 통해 논문에 대해서 설명을 들었지만 추가적으로 이해가 되지 않는 부분이 있어 질문 드립니다.
1) Table1에 HD method 아래에 ‘>= Very Good’이라고 적혀 있는데 이거는 어떤거를 의미하는 걸까요? 어떠한 값의 정도를 넘으면 굉장히 좋다라고 평가하는 듯한데 very good이라고 평가하는 기준이 뭔지가 안나와있어서 제가 맞게 이해한 건지 잘 모르겠습니다
2) 본 논문의 방법론은 text와 video를 input으로 받는 것 같은데 Table 1에 ‘with ASR captions pretrain’ 위에 리포팅된 성능은 video와 video에 대해서 사람이 직접 annotate한 text가 주어졌을 때, ‘with ASR captions pretrain’ 아래에 리포팅된 성능은 video만 주어지고 ASR을 통해서 text caption을 생성한 것을 text 데이터로 가져갔을 때라고 생각했는데, 오히려 성능이 더 높더라구요? 제가 맞게 이해한 건지 모르겠지만 제가 이해한대로 실험을 했다면 ASR은 사람이 직접 annotate한 text보다 덜 정확하기 때문에 성능이 낮게 나와야할 것 같은데 왜 높게 나온걸까요?
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
Multi-Aspect Contrastive Learning 부분에서 질문이 있는데 이를 사용하는 목적과 효과로는 MR (Moment Retrieval)과 HD (Highlight Detection) 두 가지 태스크의 요구 사항을 모두 충족하기 위해 설계되었고 MR은 비디오의 특정 구간에 대한 로컬 관계를 중요시하고, HD는 전체 비디오에 대한 글로벌 문맥을 중요시하는 것으로 이해하면 될까요?
그리고 temporal convolution에 대한 언급이 있었는데 이의 역할과 동작 방식이 어떻게 되는지 궁금합니다.
감사합니다.
안녕하세요.
1. 그림 1에서 저자가 보여주는 attention map은 어떤 값을 시각화한 것인가요? task에 따라 보는 영역이 다르다고 하는데, 어떤 값을 시각화했다는 것인지 궁금합니다.
2. 비디오에서 중요한 클립을 모델링하고, 문장에서 중요한 단어를 모델링하기 위해 가우시안 분포를 도입한다는 것은 이해가 되었는데 갑작스럽게 RBF 커널을 활용하는 이유가 무엇인가요? 논문에 어떠한 문제를 해결하고자 RBF 커널을 도입하였는지에 대한 이야기가 없나요?