이번에 소개드릴 논문은 AAAI 2024에 게재된 SQLDepth라고 하는 논문입니다. Self-supervised monocular depth estimation (SDE)에서 상당히 좋은 성능을 보여준 논문이지만 코드 공개도 안되어있고, 논문도 상당히 모호하게 작성되어 있어서 작년에 읽다가 포기했던 논문인데, 이번에 AAAI게재되면서 코드 공개 및 글이 많이 개선이 되었더군요. (여전히 불친절한 부분들이 많이 존재하지만요^^..)
본 논문의 깃허브 이슈에서 실험 결과가 fair comparision이 아니라는 이의가 제기되었으며 이에 대해 저자들은 명확한 대답을 내놓지 않고 있습니다. 따라서 본 논문의 방법론 및 실험 결과를 신뢰하기는 매우 어려운 상황이므로 해당 논문과 리뷰를 읽지 않는 것을 권장합니다.
그럼 리뷰 시작하겠습니다.
Intro
intro는 Self-supervised monocular depth estimation(SDE) 분야에서 자주 등장하는 진부?한 이야기들이라서 해당 부분들은 넘기고 핵심이 되는 부분만 설명드리겠습니다. (대충 monocular depth estimation의 중요성, Lidar와 같은 label 없이 영상만으로 학습을 하면 좋은 점 등등..)
기존의 SDE 연구들은 계속된 연구 덕에 비약적인 발전을 이루었지만, 여전히 supervised learning과의 성능 차이는 존재합니다. 그리고 dense prediction task들이면 다 그렇겠지만.. 해당 분야에서도 역시 추정된 깊이 결과는 세부적인 디테일에서 아쉬운 측면이 많다고 합니다. (작거나 가는 객체들에 대한 깊이 성능이 낮음.)
저자들은 이런 문제를 극복하고, 깊이 추정의 성능을 개선시키기 위해서 영상 내 어떤 한 픽셀의 깊이와 그 주변 이웃 픽셀 또는 객체들의 픽셀들이 강한 관련이 있다는 것에 집중합니다. 다른 말로 하면, 픽셀의 거리를 상대적인 거리 정보를 제공하는 연관 문맥으로 추론할 수 있는 것이 아닌가라는 점이죠.
저자들은 상대적인 거리 정보가 효과적인 inductive bias 역할을 수행할 수 있으며, 결과적으로 단안 깊이 추정 SSL의 성능 향상을 크게 기여할 수 있을 것으로 보았습니다. 결과적으로, 저자들은 하나의 영상 내 한 지점과 다른 지점 간에 상대적인 관계성을 표현하기 위하여, Self-Query Layer라는 방식을 설계해 새로운 self-cost volume 생성 방법을 제안합니다.
구체적인 내용은 바로 아래에서 다뤄보도록 하죠.
Method
논문에서 제안하는 framework은 아래와 같습니다.

논문에서 제안하는 부분은 Depth를 추론하는 과정이며, 그 외에 reference frame과 posenet을 이용해 loss를 계산하는 과정은 기존의 monodepth2 학습 방식을 그대로 활용합니다. Self-supervised monocular depth estimation이 학습하는 방식에 대해서는 제가 예전에 작성했던 관련 논문들의 리뷰를 살펴보시면 좋을 것 같습니다. 해당 분야는 2019년 ICCV에 게재된 Monodepth2가 제안하는 학습 방식을 온전히 활용하는 경우가 많기 때문에, 하나의 논문에서 학습 방식을 제대로 이해하면 다른 논문의 학습 방식도 거의 동일하다고 보시면 됩니다.
그럼 Depth Estimation을 수행하는 DepthNet과 Self-cost Volume에 대해서 집중적으로 알아보도록 하죠.
DepthNet with Self-Query Layer
그림1에서 저자들이 제안하는 DepthNet에 대한 그림을 더 자세히 나타낸 것이 그림 2입니다.
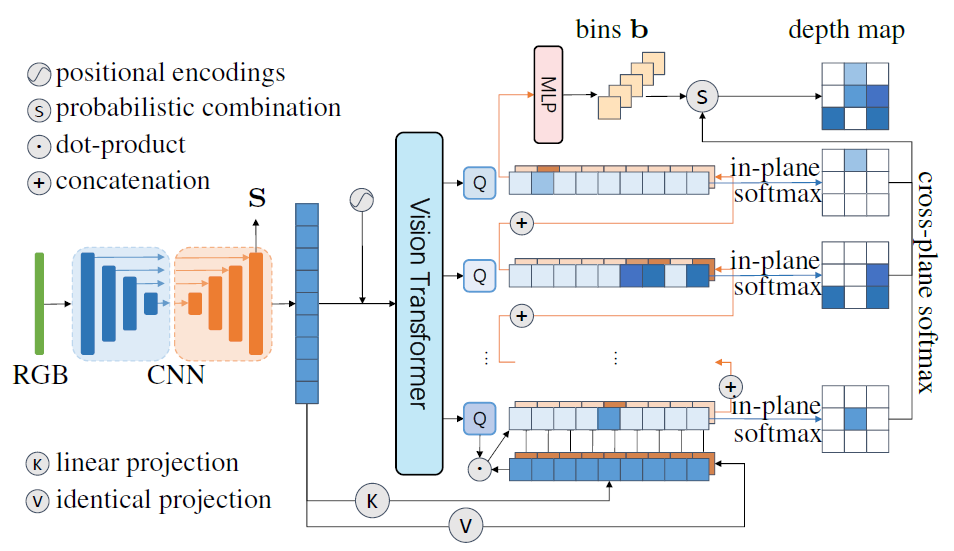
우선 첫번째로는 RGB Image가 입력으로 들어왔을 때, U-net 구조의 네트워크를 통과시켜 원본 영상의 1/2 해상도 크기의 feature map S \in \mathcal{R}^{H\times W\times C} 를 추출합니다. (편의성 입력 영상의 1/2 해상도를 H, W라고 표기하겠습니다.)
보통 일반적인 DepthNet은 Encoder를 통해 encoding한 뒤 Decoder를 태워서 나온 결과값이 결과적으로 Depthmap이 되는 경우가 많은데, 이 논문에서는 Decoder를 통해 Depth를 추출하는 것이 아니라, 뒤이어 소개드릴 SQL Layer를 통과시키기 위한 feature map을 추출하는 것을 목표로 합니다. 이러한 feature map은 해상도가 입력 영상과 차이가 크게 나지 않기에 섬세한 디테일 정보들이 많이 포함되고 있다고 생각하시면 좋겠습니다.
Building a self-cost volume
intro에서도 간략하게 소개드렸다시피, 저자들은 정확한 깊이 추정을 위해서 영상 내 영역들 간에 상대적인 거리 정보를 잘 포착할 수 있는 모듈을 만들고자 하였습니다. 즉, relative distance cue와 같은 정보들이 깊이 추정 성능에 상당한 영향력을 행사할 것 같은데, 문제는 이를 어떻게 모델링할지는 불분명하다는 것이죠.
이러한 문제에 대하여 저자들은 두개의 서로 다른 영상을 기반으로 기하학적 정보를 포착하던 stereo depth estimation, optical flow 연구들이 자주 사용하던 cost volume에 관심을 가졌다고 합니다. 물론 현재 논문에서 수행하는 것은 monocular depth estimation이기에 단안 영상으로 만든 cost volume이라는 이름 아래에 self-cost volume이라는 것을 모델링하기 시작합니다.
근데 기존의 cost volume을 만드는 방식을 그대로 활용하다보니, 계산 복잡도가 해상도의 제곱배가 들어가는 바람에 이를 곧바로 사용하기에는 무리였다고 합니다. 아까 U-Net을 통해 생성한 feature map S는 입력 영상의 1/2 해상도밖에 되지 않으니, 기존 cost volume 생성 방식으로는 해상도의 제곱배만큼의 메모리 공간을 차지해야해서 OOM이 발생하기 때문이죠.
이러한 문제를 해결하고자, 저자들은 point-point 간에 상대적인 거리를 계산하려는 것 대신에, point와 object 간에 상대적 거리를 묘사하려고 하였습니다. 이는 feature map S를 large patch로 쪼갠 후 트랜스포머에 입력으로 태워서 영상 내 객체를 표현하는 방식으로 구현이 가능합니다. 저자들은 ViT를 타고 나온 object query들에 대하여 내적 연산을 통해 per-pixel 별 상대적인 거리를 계산하였다고 하네요.
정리하면 저자들은 pxp 커널과 스트라이드 p 값을 가진s 컨볼루션 연산을 통해 패치로 쪼개고, 그 후 ViT의 입력으로 태우기 위한 일련의 과정(Patch embedding(flatten), positional encoding)을 수행합니다. 이후 4번의 트랜스포머 연산을 통하여 CxQ 사이즈의 object query를 계산하게 되는데 이때 Q가 object(라고 저자들은 이야기하지만 느낌이 region에 더 적합한?) 개수가 됩니다. 저자들은 Q를 N과 같거나 작은 값으로 설정하였으며, 이때 N은 영상을 패치 단위로 쪼갰기에 h*w/p^2의 길이를 가지게 됩니다.
결과적으로 self-cost volume V는 C x Q의 shape을 가지는 Query와 H x W x C의 크기를 가지는 S 간에 내적을 통해서 H x W x Q 꼴의 형태를 지니게 됩니다.
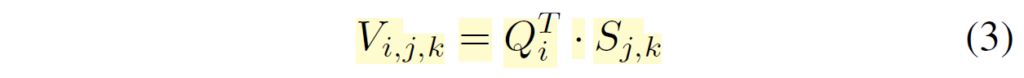
Depth bins estimation with the self-cost volume
Depth를 추정하는 방식으로는 단순히 pixel-level regression을 통해 곧바로 추론하는 방식이 있습니다만, 최근에 Supervised learning에서는 depth-interval이라는 개념을 두어 어떤 bin(거리)에 해당될지에 대한 확률을 계산하여 이를 가중합하는 classification 방식의 추론 방식이 좋은 성능을 보여주고 있습니다. (관련 리뷰 참조)
저자들도 이러한 bin 형식의 classification 기반 깊이 추정을 수행하고자 하였으며, 기존에 자주 사용되는 Adabin 방식을 사용하였다고 합니다. 하지만 이전의 depth bin을 학습하는 방식은 self-sup에서는 학습이 잘 되지 않는 모습을 관측했다고 합니다.
따라서, 저자들은 depth bin이라는 개념의 근본적인 정의를 다시 생각하였으며, depth bin은 곧 서로 다른 depth value의 개수를 의미하는 것이라고 생각하였음. (약간 히스토그램 개념.) 그래서 저자들은 self-cost volume 내 latent depth를 카운팅하는 방식을 통해 깊이를 추정했다고 합니다. 저자들은 latent depth space에서의 depth 카운팅 과정을 정보의 aggregation 과정으로 보고, 이를 softmax를 이용한 가중합 연산으로 대체하였다고 합니다.
위에 일련의 설명들이 직관적으로 이해되기는 어려울 것으로 예상이 됩니다. 사실 저자들이 코에 걸면 코걸이, 귀에 걸면 귀걸이 느낌처럼 설명을 끼워맞추는..? 듯한 화법을 많이 사용해서 그렇지 실제 수식을 통한 구현 과정은 어렵지 않습니다.
우선 feature map S와 obejct query Q를 통해 계산한 Volume V는 H x W x Q의 형태를 지닌다고 하였습니다. 여기서 저자들은 채널 축(즉 Q)에 대해 쪼개서 HxW feature map이 Q개 있는 것으로 나누고, 각각의 HxW 꼴 feature map에 대해 공간축에 대한 softmax를 취하여 픽셀 레벨의 확률 맵을 생성합니다.
이렇게 생성된 확률 맵은 Unet의 output인 feature map S에 pixel-wise product을 수행한 뒤, 모든 픽셀을 다 더해버립니다. 즉 1x1xC 꼴의 벡터를 생성하는 것이죠. Q개의 feature map이 존재하기 때문에 이러한 연산이 총 Q번 반복되어 결과적으로 QxC 꼴의 feature가 생성이 되고 이를 MLP layer를 태워서 최종적인 depth bin을 생성하였다고 합니다.
수식으로 나타내면 아래와 같습니다.
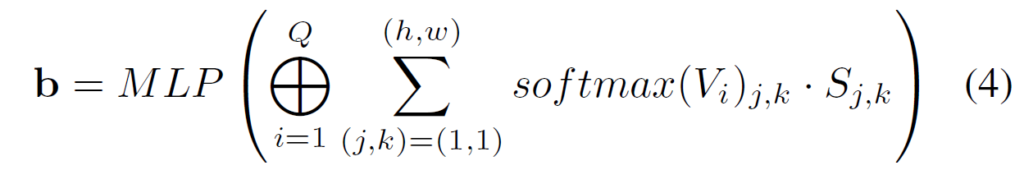
Probabilistic combination
수식 4를 통해 생성한 bin 값을 통해서 깊이를 추정하는 방법에 대해 알아보겠습니다.
Depth bin b의 shape이 DxC이기 때문에 저자들은 1×1 convolution을 통해 self-cost volume V도 D차원을 가질 수 있도록 하였습니다. 그 후 V의 D차원 축으로 softmax 연산을 적용하여 Depth bin에 대한 확률 분포 값을 생성하도록 합니다.

수식 5에서는 i가 1~Q라고 되어있는데 제가 봤을 땐 오타인 것 같고, Q가 아닌 D로 생각하시면 좋을 것 같습니다.
결과적으로 center bin과 확률분포 p 간의 가중합 방식을 통해서 최종적인 depth 값을 생성할 수 있게 됩니다.
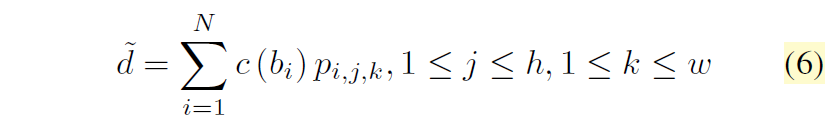

참고로 center bin을 생성하는 수식 7은 Adabin의 방식을 그대로 활용한 것입니다.
Experiments
다음은 실험 섹션입니다. 우선 KITTI dataset에서의 정량적 결과는 아래 테이블에서 확인이 가능합니다.
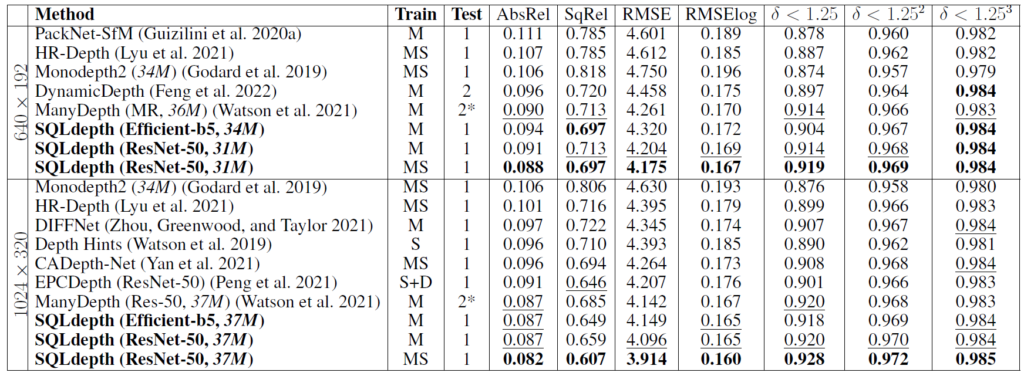
MS는 학습 시 연속된 frame 뿐만 아니라 stereo image까지 같이 사용한 것에 대한 성능으로 보통 MS 환경에 대한 성능은 크게 고려하지는 않습니다.
그럼에도 저자들이 제안하는 방법론이 다른 방법론들과 비교하였을 때 모든 metric에서 더 우수한 ㅓㅅㅇ능을 보여주는 것을 확인하실 수 있습니다.
Ablation study
다음은 ablation study 관련 결과입니다.
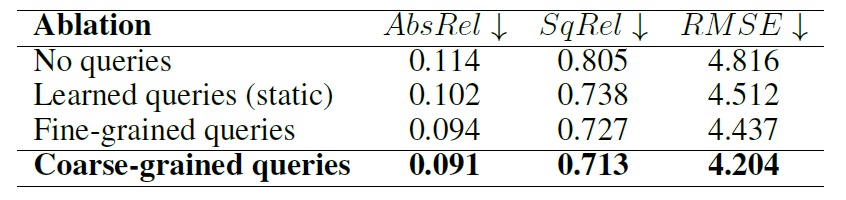
저자들이 제안하는 SQL layer가 없을 때의 성능(No queries)와 있는 경우의 성능 차이는 약 17.5% 수준으로 SQL layer의 필요성이 상당히 부각되는 모습입니다. 그리고 Learned Queries의 경우 DETR의 object query 생성 방식을 사용한 것인데, 제가 DETR의 방법론을 제대로 알지 못해서 설명드리기는 어려우나 자신들이 제안하는 query 생성 방식이 깊이 추정에는 더 좋았다는 것을 주장합니다.
게다가 또 의외인 점은 트랜스포머를 입력으로 패치를 나눌 때 4×4를 한 것보다(fine-grained), 16×16으로 진행하는 경우(coarse-grained)가 성능이 훨씬 더 좋게 나타나는 것을 확인하실 수 있습니다. 저자들은 이게 곧 receptive field가 넓어서 그렇다고 주장합니다만.. 사실 global attention을 수행하는 것 자체로 receptive field는 차이가 없다고 생각하기 때문에 무언가 다른 이유가 있을 것 같다는 생각이 드네요.

위에 실험은 bin 기반으로 깊이를 추정할 때 기존의 fixed bin 방식, Adabin의 bin 추정 방식 그리고 저자들이 제안하는 bin 추정 방식에 대한 성능 차이인데, 여기서도 재밌는 점은 저자들이 제안하는 bin 추정 방식이 가장 좋은 성능을 보였으며 그 외에 다른 bin 기반 깊이 추정 방식은 모델 성능에 큰 이점이 없었다고 합니다.
결론
다른 논문들과 비교하였을 때 상당히 큰 성능 향상폭을 보여주어 제법 많은 사람들이 관심을 가지는 논문인 것 같습니다. 다만 너무나 큰 성능 향상과 달리 논문에서 다루는 내용들 중 일부는 논리적인 부분이 조금 결여되어 있어 아쉽게 느껴집니다. 다행히 코드를 공개하였으니 논문에서 이해가 안되는 부분들을 검증 해볼 수는 있겠네요.