
안녕하세요, 허재연입니다. 어쩌다 보니 2주 연속 페이스북, 그것도 얀 르쿤 교수팀의 논문을 읽게 되었네요. 오늘 다룰 논문은 얀 르쿤 교수를 포함하여 NYU 및 Facebook 연구진들이 함께 작성해ICML2021에서 spotlight를 받은 논문으로, Barlow Twins라는 Self-Supervised Learning(SSL)기법을 제안합니다. SSL 논문을 읽다 보면 자주 비교군으로 등장하는 이름이기도 하고 인용수도 높아서(24년 5월 10일 기준 2023회) 언제 한번 읽어보려고 했던 논문인데, 이번 기회에 읽어보게 되었습니다. 기존의 방법론들과 비교해 압도적인 성능 개선을 보여주지는 못했지만 새로운 목적함수를 제안하여 기존 SSL 방법들의 단점들을 극복한 것이 contribution이라고 볼 수 있습니다. 리뷰 시작하겠습니다.
Introduction
Self-Supervised Learning(SSL)은 human annotation이 필요한 정답 라벨 값 없이 입력 데이터에서 유용한 representation을 얻어내는것을 목표로 합니다. 일반적으로 학습용 데이터셋 구성 과정에서 라벨링에 많은 비용과 시간이 들기에, 라벨 없이 대량의 데이터로 SSL 사전학습을 진행한 다음 downstream task로 fine-tuning하고자 합니다. 해당 방법이 잘 동작하기 위해서는 SSL 과정에서 데이터의 유용한 특징을 잘 학습하여 좋은 representation vector를 얻어야겠죠. 2020년 즈음에는 MoCo, SimCLR, SimSiam, BYOL, SwAV, PIRL 등 강력한 SSL 방법론들이 많이 제안되어 downstream task로의 transfer learning에서 기존에 자주 사용되던 ImageNet supervised pretraning 방법의 성능에 근접하거나, 일부 태스크/데이터셋에서는 능가하기도 했습니다. 많은 방법론들은 서로 다르게 distortion(data augmentation)을 가한 동일 데이터에 일관성을 유지하는 방법을 이용합니다. 이 방법은 기본적으로 동일한 데이터에 서로 다른 augmentation을 가한 뒤, 이 둘의 representation vector 유사도를 높이는 방향으로 수행할 수 있습니다. 하지만 여기에는 trivial solution이 있기에 일정 이상 수렴하면 모델이 constant representation만을 출력하는 collpase 문제가 발생할 수 있습니다.. 따라서 유사도를 높이는 방법만으로는 좋은 representation을 얻는 데 한계가 있습니다.
이에 다른 방법론들은 자신들만의 프레임워크 설계를 이용하여 collapse 문제를 완화하였습니다.
- MoCo, SimCLR와 같은 Contrastive Learning 방법은 유사도를 높이는 동일한 이미지의 positive pair 뿐만 아니라 negative pair를 이용하여 loss function 부분에서 다르게 학습하도록 유도합니다. 임베딩 공간 상에서 positive pair의 거리는 가까워지지만(유사도는 높아지지만), negative pair 간 거리는 멀어지도록 패널티를 가함으로서(유사도를 낮추어서) constant representation만을 출력하는 문제를 해결하였습니다(contrastive learning에 단점이 없는 것은 아닙니다. 일정 이상 학습하게 되면 임베딩 공간의 모든 차원을 활용하지 못하고 특정 low-rank 저차원 공간으로 벡터들이 축초되는 dimensional collapse 문제가 있습니다. 이는 representation vector의 차원에 비해 표현력을 제한하는 한계로 이어집니다).
- BYOL 및 SimSiam은 ‘predictor’ 네트워크를 도입해 비대칭적인 구조를 가지게 하고, 파라미터 업데이트 또한 비대칭적으로 이루어집니다. SimSiam 논문에서는 stop-gradient가 trivial solution을 막는 데 중요한 역할을 한다는 것을 밝혀냈다고 논문에서 언급합니다.
- 저자는 위 방법들 이외에도 clustering을 이용한 방법도 언급하는데, DeepCluster라는 방법론은 K-Means clustering을 활용했다고 합니다.
- distortion을 가한 이미지의 유사도를 활용하는 방법은 아니지만, rotation, jigsaw puzzle, context prediction, colorization 등 사람이 직섭 설계한 휴리스틱한 자체 supervised learning을 이용하여 visual representation을 학습하기도 합니다. 이렇게 사람이 설계한 task로 사전학습을 진행하는 것을 pretext task라고 합니다. 이 방법 역시 사전학습한 representation을 downstream task에 fine-tuning하여 사용합니다.
본 논문에서 저자는 Barlow Twins라는, 신경과학에서 처음 제안된 ‘redundancy-reduction’이라는 개념을 SSL에 처음 적용한 방법론을 제안합니다. Barlow는 해당 이론을 제시한 예전의 신경과학자 이름이고, 프레임워크가 2-way 형식이니 이에 착안에 Barlow Twins라는 이름을 붙인 것 같습니다. 논문에서는 이 신경과학 관련 사설이 좀 있는데, 요약하자면 Barlow라는 사람이 제안한 ‘신경과학에서 신호처리의 목표는 중복된 정보를 독립된 코드로 인코딩하는 것이다’라는 개념입니다. 우리 뇌 속에서 정보를 처리하는 메커니즘 중 하나가 중복된 정보를 줄이고 독립적인 정보만 남겨서 그 효율을 높인다.. 라고 이해하면 될 것 같습니다. 이를 약간 선형대수적인 개념으로 끌고 오면, 서로 중복되는 정보를 가진 벡터들 말고 고차원 공간을 span할 수 있는 벡터들로 정보를 표현하면 효율적이다 정도로 생각할 수 있겠네요.
아무튼 저자는 이 이론을 기반으로, 저자들은 twin embedding에서 계산된 상관 계수 행렬(cross-correlation) 최대한 항등행렬(identity matrix)가 되도록 유도하는 objective function을 고안했습니다. 저자는 해당 프레임워크가 개념적으로 간단하고, 구현하기 쉽고, trivial solution이 아닌 유용한 representation을 배울 수 있다는 장점을 강조하며, 기존 SSL 방법론들과는 달리 큰 배치 사이즈를 필요로 하지 않고(SimCLR), prediction network(BYOL), momentum encoder(MoCo), non-differentiable operators(contrasting cluster assignment), stop-gradient(SimSiam)와 같은 비대칭적인 메커니즘을 필요로 하지 않아 응용에 제약이 적으며, pretext task와 달리 특정 task에 치우지지 않은 일반적인 표현을 학습할 수 있으면서도 기존 SOTA 방법론들에 견주는 성능을 보이는 것을 내세웁니다(기존 방법론들을 모두 이기지는 못했습니다).
Method
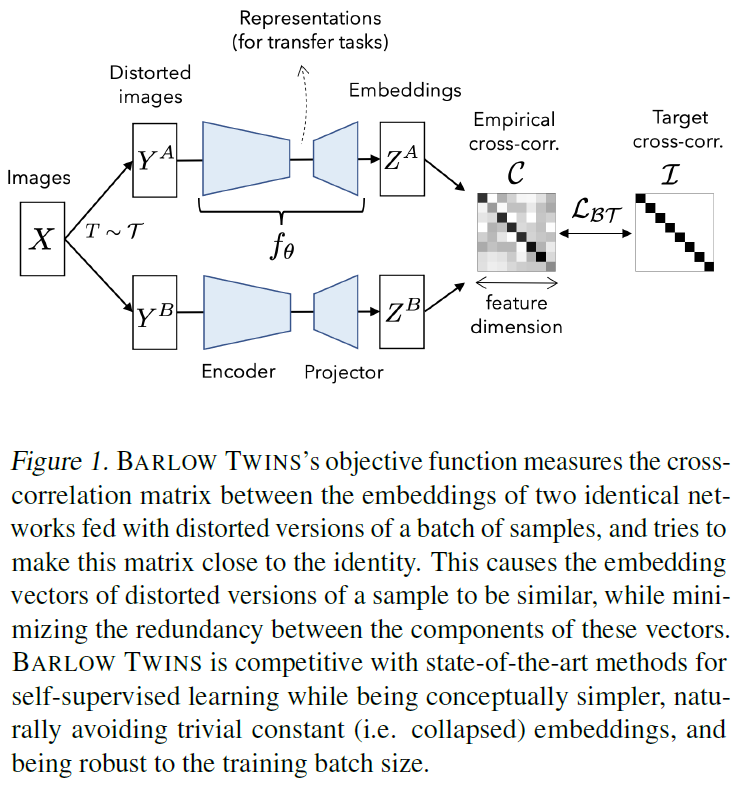
기존 주류 SSL 방법론들과 마찬가지로 Barlow Twins는 증강된 이미지 쌍에 대한 joint embedding을 활용합니다. 데이터셋으로부터 배치 X를 샘플링하고, 이에 다른 random augmentation을 적용해 Y^A와 Y^B를 만듭니다. 이후 이렇게 증강된 이미지를 Encoder(ResNet과 같은 Visual feature extractor)에 입력해 representation vector를 얻고, representation을 다시 projector(3계층 MLP)에 입력해 embedding vectors Z^A, Z^B를 얻습니다. Z^A와 Z^B는 각각 입력 입력 이미지에 대한 임베딩 벡터가 미니배치 사이즈로 모인, 일종의 행렬 형태로 생각하시면 됩니다. minibatch size=N이라고 하면 representation vector z_i에 대해 Z^A = [z1, z2, … , zN]으로 표현할 수 있겠네요. 이후에는 Z^A와 Z^B 내부 값들을 이용해 상관 계수를 계산해, 이를 다시 행렬 형식으로 표현한 Cross-Correlation Matrix를 만듭니다. 관련 자료를 검색하다 나온 사진을 첨부해 드릴테니 Figure1과 비교하면서 보시면 좋을 것 같습니다.
결국 저자의 목표는 redundancy-reduction, 즉 정보의 중복되는 부분을 줄여 효율적인 표현력을 얻고자 합니다. 그렇다면 두 view간 일치하는 요소들의 상관관계는 1에 가깝게, 다른 요소들과의 상관관계는 0에 가깝게 만들어야 합니다. 이는 다음과 같은 방법으로 구현합니다.
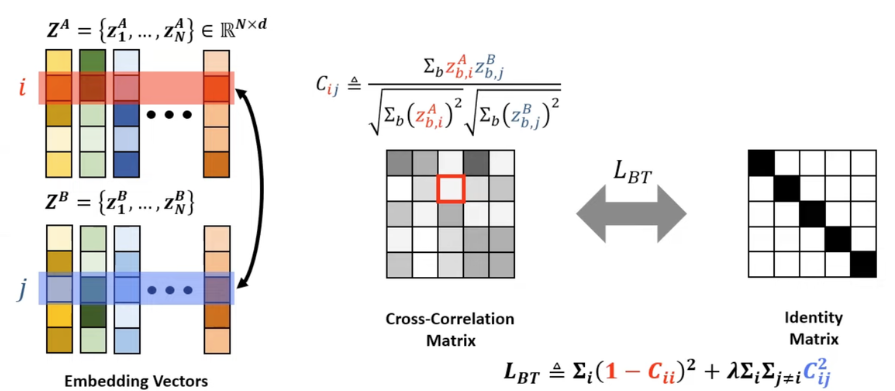
위 그림에서 embedding vector는 크기가 5, 배치 사이즈는 N이라고 가정해보겠습니다. Cross-Correlation Matrix의 (2,3)번 원소값을 계산하기 위해서는 5xN matrix Z^A의 2번째 행(i=2)과 Z^B 의 3번째 행(j=3) 간 상관계수를 구합니다. 이때, 행 i와 행 j 는 하나의 이미지에서 나온 임베딩 벡터를 취하는 것이 아니라, 배치 내부 모든 임베딩 벡터의 i or j 번째 값을 취하게 됩니다. 그럼 Cross-Correlation Matrix의 주대각선 요소들은 임베딩 벡터 내부의 동일한 부분의, 그 이외 요소들은 임베딩 벡터 내부의 다른 부분들의 상관 계수가 채워질 것입니다. 이후 이 cross-correlation matrix를 항등행렬(identity matrix)이 되도록 학습을 진행합니다. 그럼 임베딩 벡터의 동일한 부분들은 상관도가 높아지도록, 다른 부분들은 상관도가 낮아지도록 학습될 것입니다. 다음 의 Loss function을 보면서 다시 정리해보겠습니다.

손실함수는 invariance term과 redundancy reduction term으로 구성됩니다. C는 두 output 임베딩 벡터로부터 계산된 cross-correlation matrix입니다(network 출력 차원의 크기를 갖는 정방행렬입니다). 상관계수로 이루어진 행렬이므로 값은 -1 ~ 1 사이 값들로 채워지게 됩니다. invariance term은 행렬의 대각선 요소들로, 두 view 간 임베딩 벡터에서 일치하는 요소들의 상관계수가 1에 가까워지도록 하고, redundancy reduction term은 정보의 중복을 방지하기 위해 두 view 간 임베딩 벡터에서 일치하지 않는 요소들의 상관계수가 0에 가까워지도록 합니다. 람다값은 두 term의 trade-off를 조절하는 하이퍼파라미터입니다.
사실, 위 손실함수는 어떻게보면 contrastive loss와 닮은 면도 있습니다. contrastive loss는 positive pair의 유사도가 높아지게 하고 negative pair의 유사도가 낮아지도록 유도하고, Barlow Twins의 loss는 임베딩 벡터의 동일 차원 부분의 상관관계는 높이고, 다른 차원 요소의 상관관계를 없애는(상관계수 0) 방향으로 학습을 하게 됩니다. 대표적인 contrastive loss인 InfoNCE에서는 임베딩 벡터가 일반적으로 feature dimension으로 normalize되어 임베딩 샘플 간(입력 데이터 간) 코사인 유사도를 계산하지만, 저자들의 방법에서는 임베딩 벡터를 feature dimension 방향이 아닌 batch dimension 방향으로 normalize하여 이용합니다.
구현의 세부사항을 살펴보면, input image에는 random cropping, resizing, horizontal flipping, color jittering, converting to grayscale, Gaussian blurring, solarization의 random augmentation을 적용합니다. 인코더로는 ResNet50이 사용되었으며(마지막 classification layer는 제거하고 feature representation을 출력합니다) 프로젝터는 8192 output unit을 가지는 3계층 linear layer로 구성됩니다. 보통 feature extractor를 타고 나온 출력값을 ‘representation’, 이후 projector를 태워 나온 출력값을 ’embedding’이라고 부릅니다. 메인 실험에서 학습은 1000epoch, 2048 배치 사이즈로 수행되었습니다. 배치사이즈가 큰데? 라고 생각하실 수도 있지만, SimCLR같은 알고리즘이 8192~16000대의 배치 사이즈를 사용하는 것과 비교하면 작다고 할 수 있으며, Ablation에서 보면 256의 작은 배치 사이즈로도 학습이 잘 됩니다(반면 contrastive learning 계열 방법론들은 negative sample이 많아야 하므로 배치 사이즈가 커야 학습이 잘 됩니다)
Experiments

먼저 linear evaluation 먼저 보겠습니다. Table 1은 ImageNet으로 사전학습한 ResNet50 인코더에 대해 파라미터를 freeze시키고 단순히 선형 layer만 얹어서 전이학습하여 top1/top5 accuracy를 비교한 결과입니다(이 방법을 linear evaluation이라고 부릅니다). SwAV와 BYOL에 비해 성능은 약간 낮지만 프레임워크의 구조적 제약이 덜하며 더 낮은 메모리와 배치 사이즈를 요구하기에 타 방법론들보다 효율적이라고 합니다.
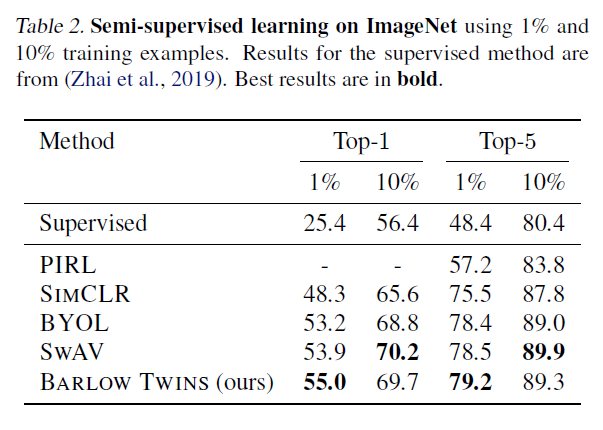
Table2는 freeze없이 1% or 10% 레이블만 사용하여 전이학습한 결과입니다. 사전학습한 barlow twins는 이미 일반화된 특징을 잘 추출할 수 있기 때문에 레이블이 적어도 좋은 성능을 가질 수 있다는 것을 확인할 수 있습니다.
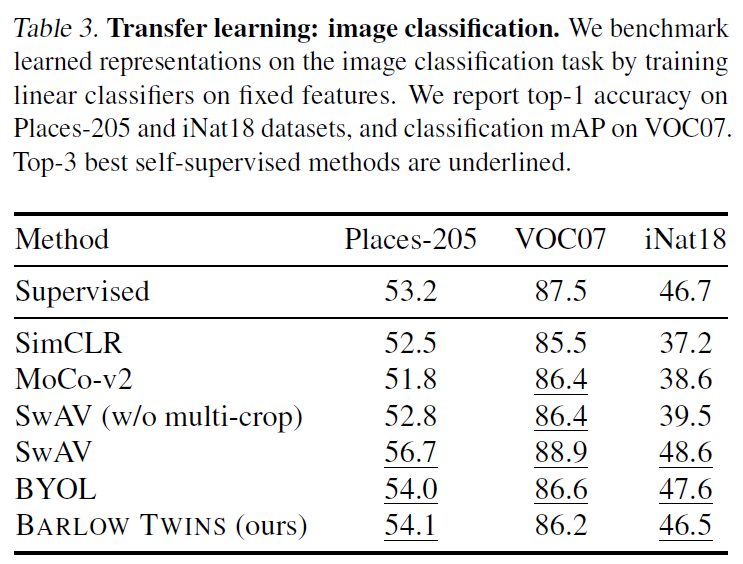
Table 3은 다른 데이터셋에 대한 image classification 전이학습 실험입니다. Place-205와 iNat18에서는 top1 accuracy를, VOC07에서는 classication mAP를 나타내었다고 합니다.
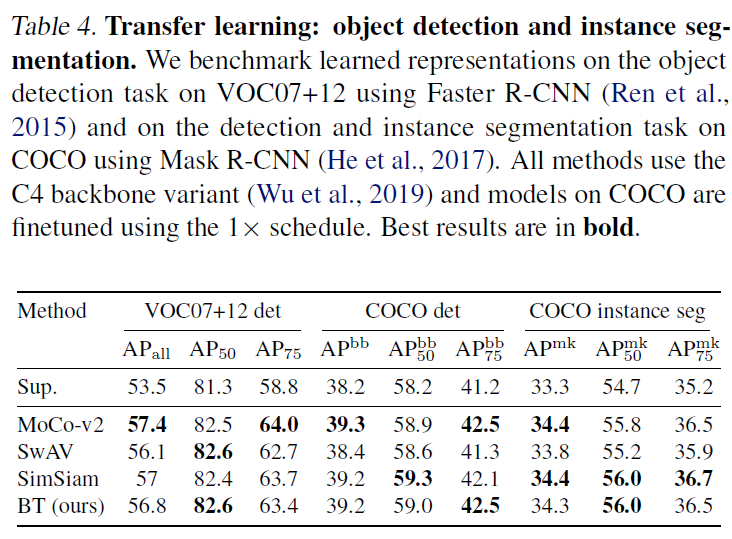
다음은 단골 downstream task인 Object detection과 instance segmentation에 대한 실험 결과입니다. VOC과 COCO 데이터셋을 이용해 finetuning을 진행하여 기존 SOTA 방법론들에 견주는 성능을 보였습니다.
Ablation study도 많은데, 몇가지 주요한 것을 살펴보겠습니다. 먼저 배치 사이즈에 대한 그래프입니다.
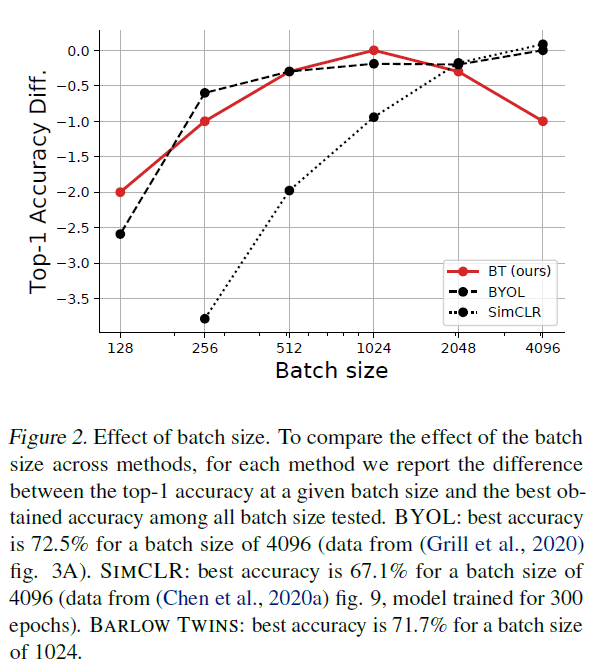
저자들은 Barlow Twins가 SimCLR같은 contrastive learning에 비해 적은 배치 사이즈를 사용할 수 있는 것을 강점으로 내세웠습니다. contrastive learning 방법들은 성능이 준수하지만 배치 사이즈를 늘려야 온전히 그 힘을 발휘할 수 있어 메모리 제약이 많은 편입니다. 하지만 Barlow Twin는 이와 달리 1024나, 이보다 작은 배치 사이즈를 이용하더라도 성능 드랍이 크지 않습니다(contrastive learning은 아니지만 BYOL도 최고 성능을 내려면 배치 사이즈가 4096은 되어야 합니다)
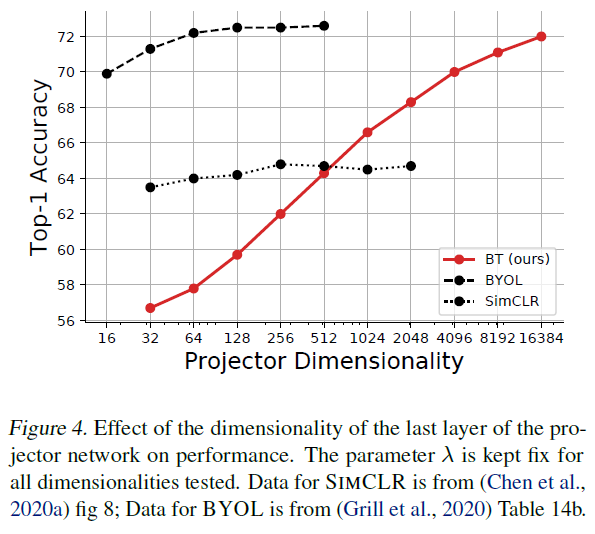
다음은 projector 차원에 따른 실험입니다. Barlow Twins는 배치 사이즈에 대한 제약이 적어 프로젝터의 크기를 키우거나 임베딩 벡터의 차원을 늘리는 데 비교적 자유롭습니다. 그리고 projector의 차원이 커짐에 따라 성능이 향상되므로 다른 SSL 방법론들과 달리 projector의 입력 차원보다 출력 임베딩 차원의 크기가 더 큽니다. 위 Figure4를 확인해보면 projection의 차원이 커질수록 전이학습의 성능이 개선되는것을 확인할 수 있습니다. 해당 실험에서 인코더를 타고 나온 representation vector의 차원은 모든 실험에 대해 고정되었습니다. 사전학습 이후 fine-tuning 단계에서는 보통 projector를 제거하고 해당 task에 맞는 요소를 추가하므로, 사전학습 할 때의 팁이라고 할 수 있겠네요.
Conclusion
기존 SSL 방법론들의 구조적 한계를 어느정도 개선하면서 동시에 뒤지지 않는 성능을 보여준 방법론이었습니다. 정보에서 중복되는 부분을 줄이는 방향으로 학습해 최대한 정보 효율성을 높인 부분이 꽤 재밌었네요. 지금 준비중인 논문에 적용했을 때 잘 동작할지 궁금합니다. 나중에 한번 돌려봐야겠습니다.
감사합니다.