안녕하세요, 서른 두번째 x-review 입니다. 이번 논문은 2023년도 ICCV workshop에 게재된 SAM3D: Segment Anything in 3D Scenes 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction and Background
3D segmentation은 2D와 유사하지만 segment하는 대상이 3D 포인트 클라우드로, 포인트 레벨의 semantic한 라벨을 예측하는 task 입니다. 해당 task는 포인트 클라우드에서 바로 semantic segmentation을 수행하거나 멀티 모달 fusion을 통해서 2D RGB 이미지로부터 추출된 feature을 이용하여 수행되고 있습니다. 3D detection에서도 그렇고 3D task에서 RGB를 fusion하는 이유에 대해 늘 이야기하는 것처럼, 본 논문에서도 포인트 클라우드는 이미지로부터 얻을 수 없는 기하학적인 정보를 제공하지만, 포인트 클라우드만으로는 RGB 이미지가 제공하는 semantic 정보를 얻기 위해 fusion을 진행하게 되죠. 또한 최근에는 SAM의 등장으로 RGB 이미지에서 더 나은 feature을 얻을 수 있게 되면서 복잡한 scene에서도 background/object에 대한 fine-grained segmentation을 수행하고 있습니다. 이러한 SAM을 이어서 SAD[1]는 depth map에서의 segmentation을 위해 SAM을 이용하며, 또 다른 Anything-3D[2]는 단일 이미지 내의 물체에 대한 3D reconstruction을 위해 SAM과 Stable Diffusion을 결합하는 연구를 진행하였습니다.
이러한 SAM을 활용한 3차원 인지 task의 흐름을 따라 본 논문에서는 3차원 scene에서 3차원 마스크를 생성하기 위해 SAM의 결과를 활용하는 SAM3D를 제안합니다. SAM3D에서는 RGB 프레임에서 생성한 SAM의 segmentation 마스크를 3차원 scene으로 projection하고 전체 scene에 대한 마스크를 얻기 위해 반복적으로 여러 프레임에 대한 마스크를 합치게 됩니다. 좀 더 살펴보면, 이미지에 해당하는 3D scene에 대한 포인트 클라우드가 주어지고 이미지에 SAM을 적용하여 2D segmentation 마스크를 예측합니다. 그 다음, 마스크를 3차원으로 projection하면 장면에 대한 부분적인 마스크를 얻을 수 있고 이러한 마스크를 반복적으로 합쳐서 전체 scene에 대한 마스크를 생성합니다. 합치는 기준은 한번의 병합 단계에서 인접한 프레임의 두 마스크이며, 양방향 병합 방식을 제안하고 있습니다. 마지막으로 이렇게 병합 방식을 통해 얻은 3D 마스크와 scene의 전체 over segmentation 마스크를 합친다고 합니다. 이러한 SAM3D 방식을 통한 SacnNet 데이터셋에서의 정석적 결과만을 리포팅하고 있네요.
2. Method

2.1. Single-frame 3D masks from SAM

먼저 특정 단일 프레임 이미지에 SAM의 자동 마스크 생성 방식을 적용하여 이미지 픽셀 레벨의 마스크를 얻습니다. 이렇게 얻은 마스크는 이미지의 전체, 부분, 하위 부분과 같이 서로 다른 특성을 가지고 한 픽셀에 대해 여러 마스크가 겹쳐져 있는 상태 입니다. 한 픽셀에 대해 겹치지 않는 단일 마스크를 얻기 위해서 한 픽셀이 만약 여러 개의 마스크가 예측되어 있는 경우, 가장 높은 예측 IoU를 가지고 있는 마스크 ID를 해당 픽셀에 할당합니다. 그런 다음 RGB-D 이미지에서 각 픽셀에 매칭되는 depth에 따라 2D 마스크를 3차원 공간으로 매핑하게 되는데, 매핑 공식은 식(1)과 같이 정의합니다. [u_i, v_i, 1]과 [x_i, y_i, z_i]은 2차원 homogeneous 좌표와 projection된 3차원 homogenous 공간의 좌표를 의미합니다. \mathcal{M}은 카메라 내부, \mathcal{R}, \mathcal{T}은 외부 카메라 포즈를 통해 알 수 있는 rotation, translation 파라미터 입니다. s는 포인트의 스케일을 나타내며 포인트 클라우드 마스크를 다운 샘플링하기 위해서 grid pooling을 사용하는데요 .. grid pooling은 본 논문에서 처음 제안한건 아니고 Point Transformer v2[3]에서 처음 제안한 pooling 방식으로 식(8)과 같이 동작합니다.
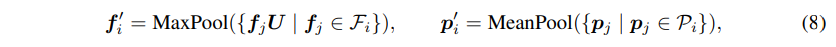
- (p’_i, f’_i) : 하위 집합 \mathcal{M}_i의 3차원 좌표와 feature
- U \in \mathbb{R}^{c \times c’} : linear projection
기존에 사용하는 포인트 샘플링에 사용하는 FPS, KNN은 주변 포인트의 정보를 제대로 모으기 어려운데, 한 개의 포인트에 대한 주변 정보에 따라 density가 다르며 샘플링할 때 겹치는 면적이 발생할 수 있습니다. 그래서 [3]에서 Partition-based Pooling, 즉 Grid Pooling이라는 방식을 제안했다고 하네요. 만약 포인트 집합 /mathcal{M} = (\mathcal{P), \mathcal{F})이 주어지면 \mathcal{M}을 겹치지 않게 나누어서 하위 집합 /mathcal{M} = (\mathcal{P), \mathcal{F})으로 만들게 됩니다. 각 하위 집합 \mathcal{M}_i = (\mathcal{P}_i, \mathcal{F}_i)을 식(8) 과정을 거친 다음 다시 하나의 집합으로 합치게 됩니다. n’개의 하위 집합에서 식(8)과 같은 pooling 연산을 하여 포인트를 다운샘플링하면 다음 인코딩 단계에서 사용할 포인트는 \mathcal{M}’ = \{p’_i, f’_i\}^{n’}_{i=1}이 됩니다. 이러한 과정에서 균일한 그리드를 사용하여 포인트 클라우드 공간을 나누기 때문에 grid pooling이라고 정의하였다고 합니다. 잠깐 다른 논문의 방법론을 보았는데 SAM3D에서는 어쨌든 이러한 grid pooling을 사용하여 포인트 클라우드 마스크를 다운샘플링 한다고 합니다.
2.2. Bidirectional Merging between Two Point Clouds

섹션 2.1.에서 3차원 마스크가 만들어지면 이제 Fig.4.과 같이 서로 다른 프레임에서 예측한 마스크를 양방향으로 병합하는 방식을 제안합니다. 인접한 두 프레임의 포인트 클라우드 X’ = \{x^1_1, x^1_2, . . ., x^1_m\}과 X^2 = \{x^2_1, x^2_2, . . ., x^2_n\}가 주어지는데, 여기서 m, n은 각각 X^1, X^2의 포인트 수를 나타냅니다. 이렇게 정의한 두 프레임의 포인트 클라우드 X^1, X^2 사이의 대응하는 매핑 M을 계산하게 됩니다. (i, j) \in M라고 정의한다면 포인트 x^i_i, x^2_j는 X^1, X^2 사이에서 일치하는 한 쌍의 포인트 입니다. 이러한 한 쌍을 어떻게 찾는지를 살펴보도록 하겠습니다. 먼저 앞서 할당한 마스크 ID가 있으니 X_1의 각 마스크 ID m에 대해 동일한 3차원 마스크 내에서 Q^1으로 표시되는 X^1의 포인트를 찾고, 찾은 ID가 m인 포인트의 수를 \sigma^1_m로 정의합니다. Q^1과 대응하는 X^2에서의 Q^2를 찾기 위해서 매핑 M을 활용합니다. Q^2에서 마스크 ID가 n인 포인트의 수를 \sigma^{1-2}_{mn}라고 정의하고, 전체 포인트 X^2에서 마스크 ID가 n인 포인트의 수를 \sigma^2_n이라고 정의해보겠습니다. 만약에 여기서 \sigma^{1-2}_{mn} > \delta \times min(\sigma^1_m, \sigma^2_n)이라면, X^1의 마스크 ID가 m인 마스크와 X^2의 마스크 ID가 n인 마스크가 매우 겹치는, 유사한 마스크임을 의미합니다. 따라서 이전 프레임에서 마스크 ID가 m인 X^2의 포인트에 대해 새로운 마스크 ID로 n을 할당하여 마스크를 병합하게 됩니다. 이러한 과정은 X^2의 마스크 ID를 기준으로도 반복하고 X^1의 포인트와 마스크 ID를 쿼리로 사용하는, 양방향 과정으로 반복하는 것 입니다.
2.3. Bottom-up Merging of the Point Clouds in the Whole Scene
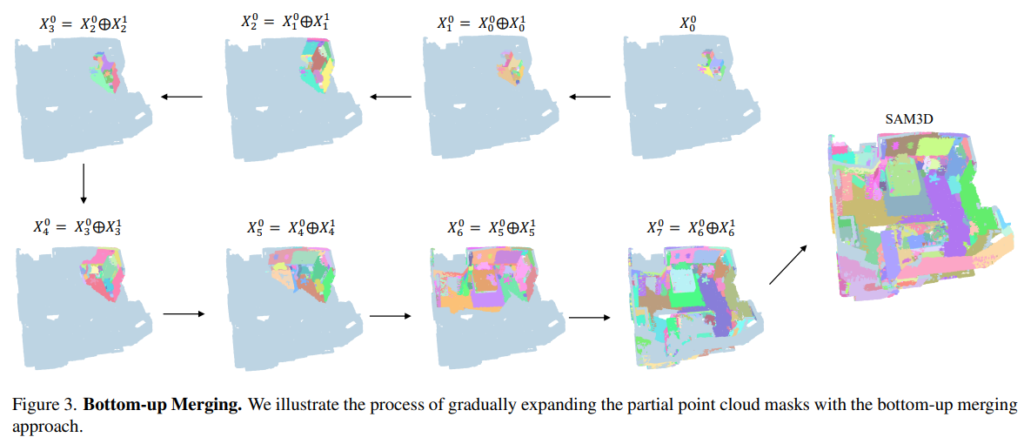
본 논문에서 실험을 진행한 ScanNet은 복잡한 scene의 경우 수백, 수천 개의 프레임으로 구성되며 각 프레임을 로컬한 포인트 클라우드에 해당합니다. Fig.3.과 같이 각 프레임의 로컬 포인트 클라우드의 마스크를 반복적인 양방향 병합 방식을 통해 전체 scene 하나의 마스크로 병합하는 bottom-up 방식을 제안하고 있습니다. 한 프레임의 로컬 포인트 클라우드를 X^1_0, X^2_0, . . ., X^K_0이라고 가정하고 여기서 K는 scene의 총 프레임 수를 의미합니다.
먼저 인접한 프레임 X^{2i}_0과 X^{2i+1}_0의 포인트 클라우드를 앞선 양방향 병합 방식을 통해 새로운 포인트 X^i_1로 병합합니다. 그런 다음 병합한 새로운 포인트들 X^1_1, X^2_1, . . ., X^{K/2}_1를 기반으로 식(2)와 같이 다시 X^{2i}_1, X^{2i+1}_1을 X^i_2로 합치게 되는 것이죠. 이 과정을 로컬한 포인트 클라우드들이 전체 scene의 단일 포인트 클라우드로 병합될 때까지 반복하면 됩니다. 결국 앞선 양방향 병합 방식을 인접한 두 포인트 클라우드 간의 병합의 각 단계에 활용을 하고, 각 병합 단계를 거친 후에 grid pooling을 적용하여 다시 포인트 클라우드를 다운 샘플링 합니다.
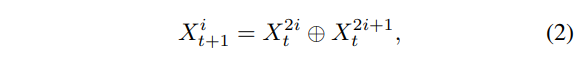
- \oplus : 양방향 병합 연산
bottom-up 방식의 병합 방식을 식(2)와 같이 정의할 수 있는데, 결국 여기서 t 단계에서 인접한 두 프레임 X^{2i}, X^{2i+1}_t는 t+1 단계에서 하나의 프레임 X^i_{t+1}로 병합됩니다.
2.4. Mask Ensemble with Over-segmentation
ScanNet은 데이터셋을 구성할 때 기하학적인 정보를 고려하여 normal 기반의 그래프 컷 방식을 적용하여 3차원 scene의 over-segmentation 마스크를 얻습니다. 이와 다르게 SAM3D에서는 이미지 프레임의 SAM을 기반으로 semantic한 정보를 고려합니다. 그래서 더 개선된 마스크를 얻기 위해서 본 논문에서는 위의 과정을 통해 생성된 포인트 마스크와 또 다시 양방향 병합 방식을 통해 over segmentation 결과를 추가로 병합합니다. 이렇게 병합된 마스크는 3차원 기하학적인 정보와 이미지의 semantic한 정보로 생성되기 때문에 더 높은 segmentation 결과를 보인다고 주장하고 있습니다.
3. Results

Fig.5.는 SAM3D로 ScanNet에서 segmentation한 결과를 정성적으로 나타낸 결과 입니다. 첫번째 행의 벽에 있는 그림이나 사진은 GT 마스크에는 어노테이션 되어 있지 않고 over-segmentation 되어 있지 않음에도 두번째 열의 SAM3D에서는 semgemntation mask를 얻을 수 있었다고 하네요. 이렇게 저자는 SAM3D를 통해 보다 정확한 segmentation 결과를 얻을 수 있다고 이야기하지만 .. GT와의 비교도 비교지만, 다른 방법론과의 비교가 있었다면 더 좋았을 거 같다는 생각이 듭니다.
이미지 브랜치에 SAM을 feature를 추출하는데 사용하는 것이 아니라 3D scene 자체에 SAM을 적용한 논문이라고 생각해서 기대하고 읽었는데 .. 단순 이미지에서의 SAM 결과를 projection한 방식이었네요. 본 논문의 방식과 이미지와의 fusion 과정에서 SAM을 사용하는 것 사이에 어떤 방법론이 더 좋은 결과를 보여주는지도 궁금해집니다. 결과 파트에서도 언급하였지만 정성적인 segmentation 결과가 아닌 기존 방법론들과의 정량적인 지표를 리포팅하였으면 좋았을텐데 아쉬운 부분이 많은 논문인 것 같습니다. 이상으로 리뷰 마치겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
맨 첫 단계에서 sam을 통해 얻은 mask가 이미지의 전체, 부분, 하위 부분과 같이 서로 다른 특성을 가진 마스크가 한 픽셀에 겹쳐있다는게 구체적으로 무슨 말인가요 !?!!? 또, over segmentation이 무엇인가요 ?!
마지막으로 본 논문에서는 정량적인 실험 결과는 따로 리포팅되지 않은 건가요 ?
감사합니다 !
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
먼저 SAM으로 예측한 마스크가 한 픽셀에 대해서 정확히 하나의 마스크만 예측하게 되는 건 아니고, 여러 마스크가 겹쳐져 있다는 것을 표현한 말 입니다.
over segmentation이란 물체로 영역을 분리하는 것 이상으로 세분화해서 물체와 영역을 segment 해놓은 상태를 의미합니다.
마지막으로 본 논문에서는 정량적인 실험 결과에 대해서는 리포팅 하지 않고, 다른 논문들을 추가적으로 읽어보니 본 논문을 베이스라인 삼은 논문들에서 SAM3D를 정량적으로 리포팅하고 있는 것을 확인하였습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
우선, Introduction 설명 부분이 흥미로운데, 3D segmentation에서도 그럼 2D의 Instance, Semantic, Panoptic 등을 모두 수행할 수 있나요? (아마 지난 세미나에서 Panoptic을 언급했으니 가능할 것 같긴한데..) 그럼 이 때의 기준이 궁금합니다. Instance라고 하면 사람으로 따지면 우리가 잘 알 수 있는 2D의 Segmentation mask 전체를 누끼따는게 아닌 사람에게 해당하는 GT pcd에 대해 classification하는 일일까요?
또한 SAM을 통해 더 나은 Feature를 얻을 수 있다고 서술되어 있는데, 이 궁금한 점이 SAM이라는 Foundation model을 활용하여 우리가 연구할 때 Output만을 활용하는게 아니라, 모델의 Feature를 중간단에서 끊어 사용할 수도 있는 것일까요? 이 얻을 수 있다는 Feature가 어떤 관점에서 쓰여진지 궁금합니다.
어우, Latex를 굉장히 많이 사용하셔서 덕분에 보기 좋았습니다. 마지막으론 이 SAM-3D를 어떻게 활용하실지가 궁금합니다!
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
넵, 우선 3D segmentation에서도 3가지 segmentation을 모두 수행할 수 있습니다. 3D에서는 2D에서 픽셀을 대상으로 했던 것을 포인트 클라우드로 옮겨가서 하나하나의 mask를 예측하는 task라고 이해해주시면 될 것 같습니다.
저는 중간단의 feature을 끊어서 사용하여 고도화하는 걸 목표로 하고 있는데, 본 논문에서는 그렇게 feature을 끊어 쓰는 것은 아니고 2D branch에서 단순 SAM을 사용한 mask를 가져와서 사용하는것이 주된 contribution이었습니다.
감사합니다.
안녕하세요. 건화님!
좋은 리뷰 감사합니다.
제가 굉장히 관심이 많은 분야인데요. 그럼에도 불구하고 배경지식이 부족하여 아래와 같은 질문이 생겼습니다!
2.1. Single-frame 3D masks from SAM 파트에서 grid pooling이라는 방법을 활용하여 pointcloud 데이터를 다운 샘플링 하는 과정을 거친다고 이해했습니다.
여기서 다운 샘플링을 하는 과정이 왜 필요한 것인지 궁금합니다. SAM을 활용하여 2D이미지로부터 뽑은 mask를 pointcloud로 projection하면 pointcloud데이터가 2D mask projection보다 더 dense해서 매칭이 되지 않는 point들이 나오기 때문인 것인가요?
2.4 Mask Ensemble with over-segmentation파트에서 기하학적인 정보를 고려하여 normal 기반의 그래프 컷 방식으로 얻은 마스크와 2D이미지에서 SAM기반으로 얻은 마스크를 병합을 한다고 이해하였습니다.
그런데 여기서 normal 기반의 그래프 컷 방식이 어떤 것인지 간단히 알려주시면 감사하겠습니다!
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 포인트 클라우드의 다운 샘플링 과정은 segmentation 뿐만 아니라 3D Object Detection에서도 거의 필수적으로 들어가는 과정인데요, raw하게 들어오는 수많은 포인트를 모두 사용하는 것이 아니라 좀 더 전체 scene을 표현할 수 있으면서 계산량이 줄이기 위해 적은 수의 포인트를 사용하는 것을 목적으로 다운 샘플링 과정이 필요하게 됩니다.
2. 네 데이터에서 픽셀이나 포인트 클라우드를 그래프 관점에서 정점으로 정의하고 간선으로 이어서 전체 데이터를 하나의 그래프라고 생각해볼 수 있는데요, 이런 그래프에서 얻고자 하는 목적에 따라 정점을 집합으로 나누는 것을 그래프 컷이라는 알고리즘 입니다. 결국에 이를 통해 얻은 마스크라고 함은 그래프를 어떤 집합으로 나누면 하나의 집합에 모인 노드들이 있을 것이고 그 노드들을 하나의 예측 마스크라고 정의하여 얻게 된 마스크를 의미 합니다.
감사합니다.
안녕하세요 건화님 리뷰 감사합니다!
글을 읽으면서 구조를 파악하는 중에 질문이 생겼는데, 혹시 Bottom-up 방식으로 클라우드를 병합하는 과정에서 grid pooling을 겹치는 부분을 없애주는걸로 이해해도 될까요? 아니면 구조적으로 pooling이 무조건 필요해서 그걸 병합하는 과정을 통해 보완한다고 이해하는게 맞을까요??