
안녕하세요, 이번에는 BOP 챌린지의 코어 데이터셋 중 하나인 ITODD 데이터셋에 대해 리뷰해보았습니다.
원래는 다른 논문을 읽었는데 이해가 잘 안가는 부분이 많이 이번 논문으로 읽게 되었네요.. ?
아무튼, 해당 데이터셋으로 평가를 진행하면서도 다른 데이터셋과 다른 grayscale로 구성된 형태로 제공하여 해당 데이터셋의 구축 내용이 궁금하긴 했었는데, 이번 데이터셋 논문은 생각보다 그렇게 자세하게 풀지는 않네요. 특정 알고리즘은 MVTec에서 판매하고 있는HALCON 소프트웨어(MVTec의 머신비전 라이브러리)를 구매해야 돌릴 수 있는 걸로 알고 있습니다. 가격과 경쟁사 비교는 해당 블로그에서 잘 정리를 해두었네요. 이런 머신비전 툴도 있구나 싶었습니다.
바로 리뷰 시작하겠습니다.
Introduction
공개 데이터셋은 컴퓨터 비전 연구 커뮤니티에 매우 중요한 도구입니다. 데이터셋이 확보되면 연구자들은 데이터셋을 직접 확보하거나 모든 선행 기술들로 직접 데이터셋을 평가할 필요 없이 바로 pose estimation 과 같은 방법론을 데이터셋에 적용하여 성능을 확인할 수 있겠네요. 유저 입장에서는 데이터셋을 통해 특정 분야의 최신 기술의 성능을 파악하는 것에 저자는 초점을 맞추었다고 합니다.
대규모 데이터셋이 많이 제안됨에 따라 새로운 데이터셋을 제안하려면 데이터셋에 대한 평가와 합리적인 결과를 얻는 것이 점점 중요해지고 있습니다. 따라서, 데이터셋을 제안함으로써 평가 기준이 오히려 연구방향을 제시할 수 있으며 새로운 방법에 대한 재요구 사항을 형성할 수 있다는 점인데요. 따라서, 전반적인 성능 뿐만 아니라 파라미터 선택 및 평가 기준과 함께 현실적인 시나리오를 나타내느 데이터셋을 보유하는 것이 더욱 중요하다는 판단을 하였다고 합니다.
가정 환경, 사무실, 창고 등과 같은 로봇 어플리케이션 측면에서 3D 물체 검출 모델 환경을 위한 기존 데이터셋의 물체와 설정은 대부분 실내(가정, 사무실)에 적용이 되는데요. 이러한 시나리오는 연구 및 어플리케이션 측면에서는 모두 중요하지만, bin-picking 이나 표면 및 결함을 검출하는 그런 산업 어플리케이션에서는 기존 데이터셋으론 모델링이 되지 않는 상당히 다른 특성을 가진다는 것입니다. 여기에는 다양한 3D 형태나 센서, 물체에 대한 배치가 포함이 됩니다. 따라서 기존 데이터셋에서 잘 동작하는 방법론들도 산업 시나리오에 적용하면 전혀 다른 결과를 보이는 경우가 있습니다.
이러한 단점 때문에 저자는 산업 시나리오에 중점을 둔 3D 물체 검출 및 pose 추정을 위한 새로운 데이터셋인 ITODD를 제안합니다. 해당 데이터셋에는 다양한 형태와 표면에 대한 특성을 가진 28개의 물체들로 구성되어있으며 800장 이상의 장면에 물체들이 다양한 형태로 배치되어 GT pose가 라벨링 되어 있습니다. 특이한 점은 grayscale의 형태로 depth와 함께 제공한다는 점인데요. 이러한 grayscale 센서가 오히려 산업 환경에서는 훨씬 눈에 잘 띄기 때문에 채택되었다고 하네요.
이제 구체적으로 ITODD 데이터셋을 알아보겠습니다.
The MVTec ITODD Dataset
저자는 가능한 많은 어플리케이션 측면에서 적용할 수 있는 시나리오들을 구성하기 위해 이번 데이터셋을 제안합니다. 다양한 센서와 물체들을 선정하여 단일/다중 인스턴스에 따른 시나리오를 커버할 수 있도록 다양한 배치도 적용을 하였다고 하네요.
Sensors

먼저 센서는 어떻게 설정하였는지 살펴보겠습니다.
2개의 industrial 스테레오 3D 센서(depth)와 3개의 grayscale 카메라를 사용합니다. 모든 센서에 대한 FOV는 거의 동일하도록 배치를 하였으며, intrinsic parameter와 상대적인 카메라 pose를 얻기 위해 캘리브레이션을 진행합니다. 카메라 같은 경우 grayscale로 제공이 되는데요. 위 그림(1)과 같이 촬영된 이미지에 대한 예시를 확인할 수 있습니다. 다양한 센서들에 대한 조합으로 인해 멀티 모달리티 데이터를 이용하는 방법론들도 모두 평가를 진행할 수 있게 됩니다.
Calibration
앞서 언급한 5개의 센서들에 대한 캘리브레이션을 진행하여 0.2픽셀 미만의 캘리브레이션 오차를 만족하였다고 합니다.
Objects
물체 같은 경우, 비슷비슷하게 생겼지만 28개로 생각보다 다양하네요. diameter는 2.4cm~27cm까지 다양하게 존재합니다. 물체에 대한 표면 같은 경우에는 반사율이 높은 물체들도 있고, 대칭성을 가지는 것도 있고, 복잡한 구조를 띄거나, 평평하거나, 크기가 작다거나 되게 다양합니다. 위 그림(3)에는 ITODD에서 사용되는 물체들에 대한 이름과 형태들을 나타내고 있네요.
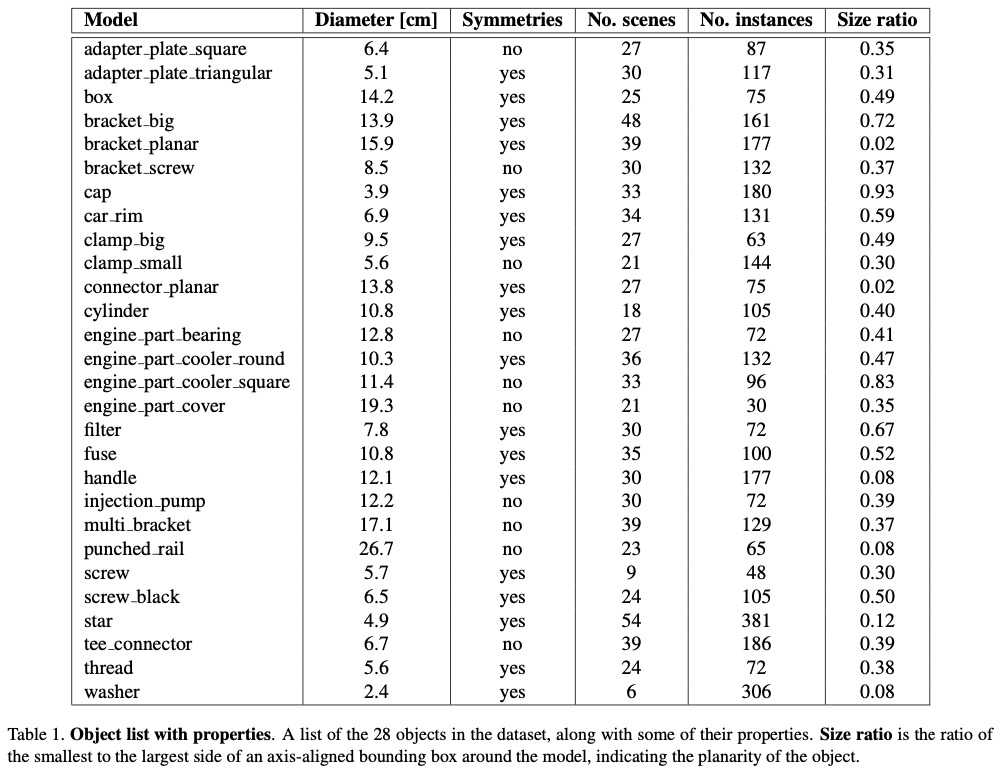
표(1)에는 다양한 물체들에 대한 속성들을 나타내고 있는데요. 물체 이름들을 자세히 보시면 같은 물체들에 대한 다양한 인스턴스가 있는 물체들도 존재하는 것을 확인할 수 있습니다. 이로써 각 물체에 대한 하나의 인스턴스만 있는 장면 뿐만 아니라 여러 인스턴스가 있는 장면에도 방법론들을 적용할 수 있겠네요.
모든 물체들에 대해 CAD 모델을 사용하여 detection task 또한 학습을 할 수 있습니다.
Acquisition Protocol
이제 제안된 데이터셋은 어떤 취득 과정을 거쳤는지 알아보겠습니다.
장면의 구성은 다음과 같은 3가지 유형으로 물체들을 구성하여 캡처를 진행하였다고 합니다.
- clutter 없이 물체의 단일 인스턴스만 포함
- clutter 없이 물체의 여러 인스턴스 포함
- clutter 있으며, 여러 인스턴스 포함
각 장면들은 3D 센서로 한 번 grayscale 센서로 두 번 촬영하는식으로 진행하였다고 합니다. 해당 3D 센서로부터 생성되는 random projection된 패턴들이 있는 경우와 없는 경우에 대해서 촬영하기 위해 나누어 촬영을 진행하였다고 합니다. 해당 패턴들이 있으면 stereo reconstruction으로도 사용할 수 있다고 합니다. 물체는 사전에 움직임이 정의된 턴테이블 위에 배치하여 회전되면서 여러 장면들을 구성하게 되는데요. 이를 통해 rotation에 따른 GT pose를 구성할 수 있게 됩니다.
Ground Truth

3D 센서로부터 얻은 3D 정보를 기반으로하여 semi-manual 하게 GT 라벨링을 진행합니다. 좀 더 구체적으로는, 각 물체에 대한 인스턴스들은 사람이 직접 수작업으로 segmentation을 진행하고, ICP(3D-3D 매칭) 알고리즘을 시각적으로 올바른 결과를 얻을 때까지 계속 적용하고 파라미터를 조정하고, pose를 다듬는 작업들을 여러번 반복하였다고 합니다. 턴테이블의 위치를 사용하여 턴테이블이 회전 됐을 때, 해당 장면에 대해 rotation이 얼마나 변했는지에 따라 GT를 적용하였다고 하네요.
그림(2)를 보시면 3D 센서가 각각 다른 센서인데요. 두 개 중 하나는 저품질의 센서로, 비용적인 문제에도 직면했을 때에 대한 시나리오도 고려하기 위해 값싼 센서를 사용하였다고는 하네요. 이번 논문에서는 모든 센서들에 대해 무엇을 사용했는지에 대한 정보가 없어 각 센서들이 어떻게 사용되고 있는지 유추를 할 수가 없네요…
Evaluation Criteria
Pose
실제 산업에서 조작을 한다거나, 검출을 한다거나 이러한 작업을 수행하기 위해선 일반적으로 장면과 모델 간의 정혹한 3D 변환(rotation, translation)이 필요하게 될텐데요. 결과에 대한 실질적인 유용함이 있음을 평가하기 위해서 bbox 또는 surface overlap으로 정확도를 평가하지 않고, pose 기반의 평가를 사용하였다고 합니다.
예측된 pose를 GT pose와 비교할 때는 모델 표면의 한 지점이 GT 위치에서 떨어진 최대 거리를 모델의 크기로 정규화한 값을 사용합니다.
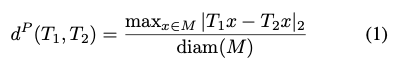
이를 식으로 나타내면 식(1)과 같이 나타낼 수 있는데요. 점 집합 M과 그에 대한 diamter가 주어진 특정 모델이 주어지면 두 변환 T_{1}, T_{2}의 거리는 식(1)을 통해 구해집니다. 이때 x는 점 집합 M에 있는 특정 점이 되겠네요.
ADD와 비슷해보이긴 하나, 다양한 샘플링과 특정 모델의 내부적인 복잡성에 대해서도 invariant한 특성이 있다고 합니다. 또한, 정규화로 인해 스케일링과 모델 크기에 따라 크게 변하지 않아 서로 다른 물체들 간의 매칭 퀄리티를 비교할 수 있다고 하네요.
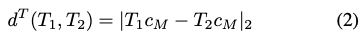
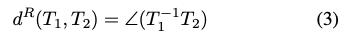
또한 식(2)와 같이 모델의 중심점 c_{M}의 translation 정확도와 식(3)과 같이 rotation에 대한 오차를 측정합니다.
어플리케이션마다 예측된 pose의 정확도에 대한 요구 사항이 다를텐데요. 물론 모든 알고리즘은 이상적으로 높은 게 좋긴 하겠지만, 예를 들어 표면에 대한 결함을 탐지하는 로봇이라면 매우 정확한 pose를 추정하는 것이 초점에 맞춰져 있을 것입니다. 신박한 예시인 vacuum suction actuator(진공 흡입 구동기, 빨아들이면서 손에 착 붙는 그런 도구 같습니다)로 물체를 파지한다고 했을 때는 pose가 다소 어긋나더라도 작동은 할 수 있겠네요. 이를 고려하기 위해 결과에 대한 정확도를 분류하려면 다양한 thershold d^{p} 값을 사용하게 됩니다.
Symmetries
이번에는 대칭성에 대해 평가하는 방법을 살펴보겠습니다.
일부 물체들은 강한 회전 대칭 또는 이산 대칭(ex. 점, 축)을 나타내게 되는데요. 이러한 대칭들들은 평가에서 제외합니다.
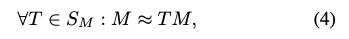
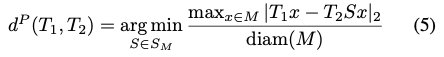
특정 물체에 대한 모델 M이 대칭 구조를 가질 경우 S_{M}으로 표현할 때, 식(4)로 나타낼 수 있습니다. 이를 통해 거리에 대한 측정은 식(5)를 통해 식(1)과 비슷하지만 T_{2} term에서 S가 곱해져 대칭성을 고려하는 것으로 보이네요.
translation, rotation에 대한 오차는 식(5)에 따라 처리되는데요. cylinder나 cap과 같은 물체에 대한 연속적인 회전 대칭과 box나 car_rim와 같은 물체에 대한 불연속적인 대칭 pose를 가지는 물체에 대해 두 가지 종류의 대칭을 모델링합니다.
선행 연구로 제안된 평가 기준에서는 물체에 대한 표면에 대한 중첩 정도를 측정하였으나, 저자는 여기에 대칭성을 추가적으로 명시하는 것을 결정합니다. bin-picking 같은 테스크를 수행하기 위해서는 특정 뷰포인트에 대한 정확한 지점과 거의 구분할 수 없더라도 잘못된 pose를 예측하는 것은 어플리케이션 측면에서 적절하지 않다고 판단하였다고 합니다.
Priors, Parameters, and Evaluation Rules
저자는 가능한 한 현실적이고 공정한 평가를 위해 데이터셋에 대한 평가는 다음과 같은 규칙들을 준수하도록 설계를 하였습니다.
Per-Model Parameters
파라미터는 모델별로 설정할 수 있습니다.
모델 간의 공유되지 않은 모든 매개 변수는 텍스트 형식으로 요약해야 하며 방법론의 유용성을 한눈에 파악할 수 있도록 해야 합니다.
Per-Scene Parameters
파라미터는 장면별로 조정할 수 없습니다.
즉, 특정 물체에 대해서는 detection 파라미터는 일정하게 구성돼야 한다는 것입니다. 장면 단위로 허용되는 유일한 prior 조건은 데이터셋과 함께 제공되는 장면에 포함되는 인스턴스 수입니다.
Provided Parameters
물체의 CAD 모델과 장면 당 인스턴스 수 외에도 거리 범위(장면 내에 존재하는 모델 중심의 z 값 범위)가 제공됩니다. 예를 들어 물체에 대한 합성 렌더링이 필요한 학습 방법을 사용하는 경우 이를 서포트 할 수 있는 역할을 합니다.
Evaluation
데이터셋에 대한 여러 메소드를 적용하여 평가한 결과를 다룹니다. 이를 통해 당시 최신 방법론들을 적용하였을 때 제안하는 데이터셋의 난이도를 파악할 수 있었다고 합니다.
Evaluated Methods
Shape-Based 3D Matching(S2D)
2D 이미지에서 3D 물체를 검출하는 방법론이라고 합니다. 이는 template 기반으로 하는 매칭 방식으로 동작하며 여러 뷰포인트에서 물체를 렌더링하여 다양한 방향에 대한 템플릿을 생성합니다.
Point-Pair Voting(PP3D)
표면에 대한 Hough 변환과 포인트 페어를 특징으로 사용하여 3D 포인트 클라우드에서 물체를 검출하는 방법론입니다.
Point-Pair Voting with 3D edges(PP3D-E)
앞서 PP3D과 유사하게 표면에 대한 포인트 페어 뿐만 아니라 표면과 edge 포인트 페어에 대해서도 voting을 진행하도록 추가적으로 구현을 했다고 합니다.
Point-Pair Voting with 3D edges and 2D refinement(PP3D-E-2D)
PP3D-E를 한 번 더 확장하여 장면과 3D모델 사이 즉, 2D 평면과 3D 포인트 간의 거리 뿐만 아니라, re-projection된 3D 모델의 edge와 2D 이미지 edge의 alignment를 맞추기 위한 refinement 단계를 추가적으로 확장하였다고 합니다.
Results
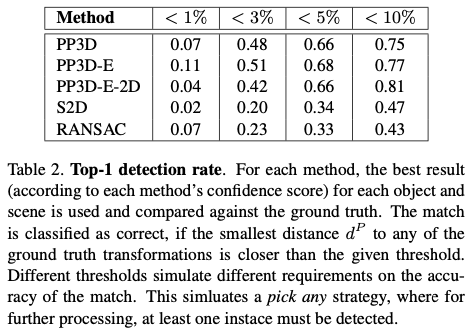
표(2)는 각 방법론에 대한 Top-1 예측 결과를 보여주고 있습니다. GT 변환과의 최소 거리 d^{P}가 주어진 threshold 값보다 가까운 경우 일치하는 것으로 분류합니다.
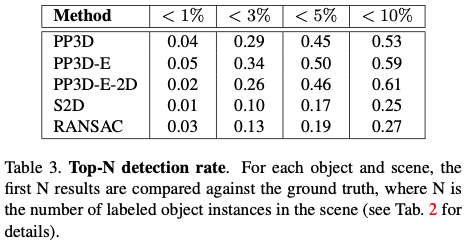
표(3)은 top-N에 대한 예측 결과를 나타내고 있는데요. 여기서 N은 장면 당 라벨이 지정된 인스턴스 수 입니다. 즉 멀티 오브젝트에 대한 결과라고 보시면 되겠습니다. Top-1 보다 성능이 낮은 것을 보아 모든 인스턴스 대신 임의의 인스턴스를 찾는 것이 좀 더 쉽다는 것을 의미하겠네요.
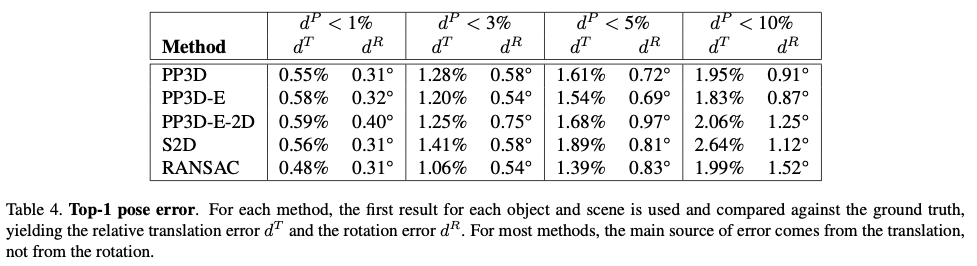
표(4)는 다양한 threshold 값을 사용하여 옳다고 판단된 변환에 대한 translation과 rotation에 대한 평균 오차를 보여주는 결과입니다.
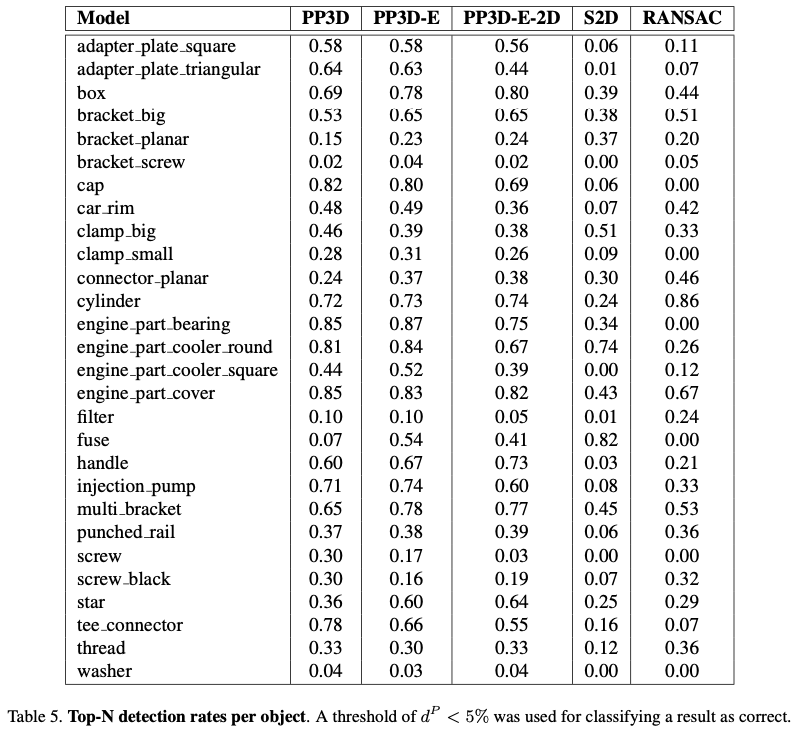
마지막으로 표(5)는 전체 물체에 대한 검출 결과를 보여주고 있습니다.
전체 모델 중에 washer, filter, bracket_screw의 성능이 좋지 않은 것으로 보이네요. washer 같은 경우 연속적인 대칭 뿐만 아니라 평평한 특성까지 가지므로 저자가 말하는 어려운 물체에 속하는 물체라고 볼 수 있겠습니다. bracket_screw 같은 경우 screw와 bracket을 합친 복합적인 물체로 모델 입장에서는 검출하기 어려웠을 것으로 보이네요. 하지만, filter의 경우에는 좀 의외인데요. cap, car_rim의 결과가 생각보다 잘 나와서 반사가 심한 물체인 것말고는 연속적인 대칭 구조로 보이는데 성능 차이가 많이 나네요.
Conclusion
이번에는 BOP 챌린지의 코어 데이터셋 중 하나인 ITODD 데이터셋을 살펴보았습니다.
다양한 어플리케이션 측면에서 문제를 해결하고자 제안된 이번 ITODD 데이터셋의 선정된 물체, 센서 구성, 데이터의 취득 과정, 다양한 방법론을 통한 데이터셋 평가 결과들을 살펴보았습니다. 생각보다 내용들이 구체적이지 않아서 이해하는 것에 어려움이 많았던 논문이었던 것 같습니다.
이상으로 리뷰 마치도록 하겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
해당 데이터셋은 산업환경의 시나리오를 고려하여 데이터 셋을 구성하였다는 것이 가장 핵심인 것 같습니다.
High-Quality depth는 렌더링한 결과처럼 잘 나와있어서 어떤 센서를 쓰는지 궁금한데, 정보가 없다니 아쉽습니다.. 논문이 아니라 사이트에서는 센서 정보를 확인할 수 있지 않을까 합니다.
GT를 구하는 과정은 초기 pose를 구하는 과정은 semi-manual하게 수행하고 이후의 턴테이블을 회전시키며 촬영된 데이터는 그 변화값을 이용하였다는 것이 맞나요?
마지막으로 최신 방법론을 적용하여 해당 데이터 셋의 난이도를 평가하였다고 이해하였는데, 그렇다면 최신 방법론은 기존 데이터 셋에서 성능이 어느정도 나왔는 지 혹시 관련 정보가 있었나요?? 기존 데이터셋과의 난이도 차익아 궁금해서 질문 남깁니다.