안녕하세요. 최근 권석준 연구원과 센서과제 실적 논문 작성을 위한 UDA-OD에 대해 살펴보는데, UDA에서 Multi-Source를 사용하는 방법은 없을까? 하던 도중 Multi-Source를 사용하는 OD 논문을 발견하여 읽어보게 되었습니다. UDA 논문을 처음 읽어보아 이해에 어려웠지만, 실험 세팅 등을 위주로 보았습니다. 바로 리뷰 시작해보겠습니다.
Introduction
computer vision의 fundamental task인 object detection에서, cnn-based detector의 대표 주자로 불리는 Faster R-CNN은 대용량의 레이블링된 학습 이미지 덕분에 좋은 성능을 보이지만, 실 세계에서 학습 이미지와 평가 이미지 간 외형 변화, 배경, 조명, 촬영 시간 등의 다양한 이유로 인해 도메인 불일치 현상이 발생하고, 이는 성능 저하로 이어집니다. 해당 환경에 대한 레이블링을 통한 학습은 이를 극복할 수 있지만 비용, 시간이 문제가 됩니다. (몇몇 논문을 읽어보고 석준님께 말해보니, 이는 UDA 연구의 필요성을 언급하기 위해 항상 언급되는 문장이라고 하네요) 물론 foundation model, zero-shot model이 이를 극복할 수 있는 해결책이지 않냐고 묻는다면, 할 말은 없습니다. 그들의 모델을 가져다 사용하는, 예를 들어 segment anything, detect anything, – anything 등이 이들에 대해 일반화된 성능을 보일 수 있음에는 동의하나 domain specific한 태스크에 대해 예를 들어 “사람, 자동차”의 두 물체만 검출하는 상황에서 해당 모델을 사용 시에 상용성에 대해서는 역으로 의문입니다. 적어도 연구 측면에서는 UDA 연구가 foundation, zero-shot이 만능의 대체자로 보진 않습니다. 어찌되었든, 해당 domain gap을 해결하고자 주로 classification에서의 UDA (Unsupervised Domain Adaptation) 연구가 성행하게 되었으며 object detection으로 확장된 UDA 연구 (UDA-OD)들도 존재하였습니다. 해당 연구들은 주로 Faster R-CNN을 기반으로 domain distribution 간의 차이를 극복하고자 feature alignment 방법론을 적용시켰으며, 대표적으로 adversarial 방법을 통해 backbone에서 추출된 feature가 어느 domain의 이미지에 대해 온 지에 무관한 학습을 하는 시도가 있었습니다.
하지만 저자는 UDA-OD 방법들의 source가 single source, 즉 하나의 데이터만을 가정하여 연구하고 있으므로 모델의 일반화에 한정적임을 언급합니다. 더 현실적인 시나리오인 다중 domain에서 얻어진 다중 source에 대해 target 도메인에서 잘 작동해야 한다는 주장은 아래의 figure 1에서 보입니다.

S_j, S_k 는 source domain으로, (domain shift를 고려하지 않는다면) 일반적으로 data-drvien 특성 상 두 source domain을 합쳐 학습함이 좋을 것으로 예상되지만 일반적인 UDA-OD 모델에선 그렇지 않음을 보입니다. 오히려 성능이 하락하며 이는 source domain 내에서 domain 불일치 현상때문입니다. 음, 제 생각엔 multi-source를 사용하는 이유를 모델의 generalization 측면보단 다음의 측면이 더 좋아보이는데, “target 도메인에 대한 label을 만족하는 source 도메인이 부족한 경우, multi-source를 합치면 이를 극복할 수 있다”. 이것이 저자가 암묵적으로 의미할지는 몰라도 명시적으로 쓰여져 있지 않다보니, 제게는 위와 같은 이유가 multi-source를 설득시키는데 더 좋아보입니다. 결국 저자는 multi-source를 사용하며, 이 때 source-domain 간의 domain shift를 방지하고자 이전 연구들의 adversarial 학습 기법을 차용하여, 학습하는 영상이 어느 도메인에서 온지를 모르게끔 하고자합니다. 해당 시도는 classification 태스크에선 이미 존재하였으나, object detection에선 최초임을 밝히며, 음, adversarial 학습 기법, EMA 등 웬만한 기법등이 이전에 존재하였으나 localization 측면을 고려하였다는 점에서 좋은 평을 받을 수 있지 않았나 싶습니다. 문제는, 코드를 공개하지 않습니다. 이 이후의 연구들도 총 세 개의 multi-source UDA-OD 논문 중 단 한 논문 (하필 WACV)을 제외한 ICCV와 CVPR의 논문 모두, 코드를 공개하지 않고 중국인 저자에게 메일을 보내보았지만, 역시나 묵묵부답입니다. 이럴 때가 정말 답답하네요. 최소한의 학습 세팅 정도는 알았으면 하는데요..
Method

Overview
MSDA (Multi-Source Domain Adaptation)에서의 시나리오는 라벨링된 M개의 source 도메인 S_1. S_2, S_3, ..., S_M 과 하나의 라벨링되지 않은 target 도메인에 대해, i번째 source 도메인은 S-i = \left\{\left(x_i^j, B_i^j \right) \right\}_{j=1}^{N_i} , j-번째 이미지를 나타내는 x_i^j 와 bounding box B_i^j 로 이루어져있으며, target 도메인은 T = \left\{x_T^j \right\}_{j=1}^{N_T} 로 bounding box annotation이 존재하지 않습니다. Adaptation 과정에선 target 데이터에 대해 접근한다는 점 (target 도메인에 학습 데이터가 존재)은 DG (domain generalization) 연구와의 차이점이며 이 때 저자는 두 가정을 언급합니다. 1) homogeneity: 모든 도메인의 feature가 동일한 manifold (feature space) 내 존재할 수 있습니다 (아마 Faster R-CNN의 RoI 덕분). 하지만 도메인 간의 데이터 분포는 상이합니다. 2) closed set: 모든 도메인은 동일한 카테고리를 공유합니다 (제가 위에서 언급했었는데, 이 점이 아쉽네요. Multi-Source라 함은 source 도메인의 레이블링을 합쳐 target 도메인에 대해서도 대처할 수 있었을텐데요.)
Hierarchical Feature Aligment
hierarchical feature alignment의 핵심은 backbone에서 추출되는 low-level feature와 high-level feature는 detection 시 담당하는 부분이 상이하며 이 둘 간의 큰 연관성이 없다는 점입니다. 본 목적은 domain-invariant feature, 즉 도메인과 상관없이 일반적인 feature를 추출하도록 학습함에 있습니다. 위 architecture의 figure에서 M개의 source 도메인 (S; 본 논문에선 2개의 source 도메인을 사용하며, 이는 아래의 실험에서 자세히 다루겠습니다)과 1개의 target 도메인 (T)을 사용하며, 위에서 언급한 바와 같이 adversarial 학습을 통해 domain-invariant feature를 만들고자 1×1 convolution layer로 구성된 discriminator D_l 을 GRL (Gradient Adversal Layer; 우리가 아는 Gradient Descent의 정반대로 Gradient를 연산하는, 쉽게는 GAN의 방식)로 학습시킵니다. 정리하면 figure에서 G_1 으로 추출한 feature를 D_l 에 넣어 채널의 차원을 M+1 (source (M), target (1))로 줄여 domain을 구분하도록 하는데, GRL을 통해 domain을 구분하지 못하도록 속이는 방향으로 학습시켜 결국 domain에 무관한 feature를 추출하게끔 만듭니다 (GAN과 유사하다고 언급했지만 자세히 보면 결국 discriminator가 generator가 판별하지 못하는 fake를 만드는 과정과는 달리 discriminator가 어느 도메인인지를 구분하지 못하도록 만듦이 최종 목적입니다). 이를 통해 domain-invariant feature를 추출할 수 있으며 아래의 수식으로 정의됩니다.
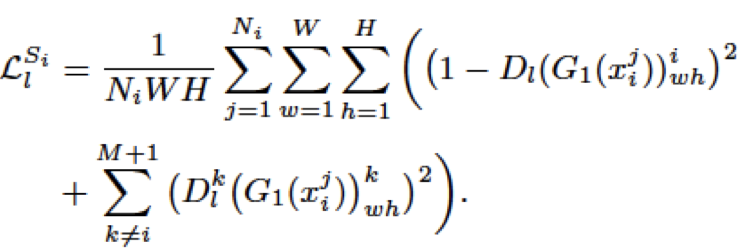
위 식의 Loss를 통해 source 도메인의 feature를 alignment하며 각 도메인 간의 불일치를 줄일 수 있다고 합니다. target 도메인에 대해서는 아래의 수식 (least-square loss: bounding box offset에 대한 regression)을 통해 연산되며 이 둘을 합쳐 low-level feature에 대한 loss를 정의합니다. 수식에 대해 완벽히 이해하기 어려워 아쉽지만, 최종 목적을 생각하면 discriminator에 대해 일반적인 loss를 역방향으로 학습하여 원래의 domain을 구분하지 못하도록 만듦이 핵심이지 않을까 생각합니다.
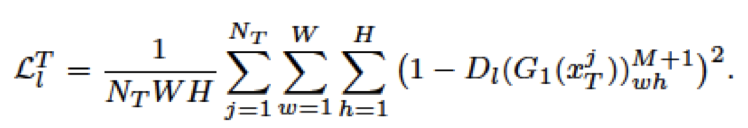
High-level feature alignment
high-level에 대해선 object detection에서 classification과 연관된 부분 (빠트린 점이 저자는 low-level feature map은 feature map의 spatial resolution이 크기 때문에 localization에, high-level feature는 우리가 알듯이 classification에 주로 사용된다고 언급합니다)으로, 이번에는 discriminator인 D_h 를 GRL로 학습합니다. 먼저, 앞선 low-level feature를 추출하는 G_1 으로 추출된 feature는 M개의 본인 source subnet으로 들어가며 반면 target domain으로 추출된 feature는 (아까 채널을 M+1개로 만들었습니다) M개의 source subnet과 pseudo subnet의 입력이 됩니다. 분리된 source subnet들은 각각의 feature extractor인 G_2 와 discriminator ( D_h^{s_j}, D_h^{s_k}, ... )를 가지게 되는데 이 discriminator는 이번에는 source와 target의 domain을 구분하도록 학습시켜, 역시나 GRL 방식이다 보니 해당 feature가 source인지, target인지를 구분하지 못하도록 만듭니다. 위의 low-level feature alignment과정에서 언급하면 좋았을테지만, 이 구분하지 못하도록 만드는 과정이 결국 source와 target 간의 직접적이진 않아도 간접적으로 feature 간의 alignment (데이터의 분포)를 맞추는 작업으로 볼 수 있습니다. 이 discriminator에 대해서도 아래의 수식 (low-level의 경우와 유사, 이번에는 classification에 대해 focal loss를 활용)으로 정의되고, 학습됩니다.

pseudo subnet learning
위 과정을 통해 low-level, high-level 즉 전체 feature extractor 과정에서의 feature alignment를 수행하였으니, 서로 다른 source 분포 간의 조합으로 target 분포를 근사화하는 pseudo subnet learning (psl)을 진행합니다. 아주 쉽게는 multi-source를 활용하였으니 여러 source에 대한 feature extractor 파라미터들에 대해 EMA (Exponential Moving Everage)를 사용하며, 바로 직전의 high-level feature alignment에서 D_h 의 loss가 클 수록 source와 target이 유사하단 점 (GRL 방식임을 상기)을 활용하여, 이 loss를 매 iteration마다 loss memory bank (LMB)에 저장하여 이들을 평균낸 V를 구합니다. 역시나 V가 크면 source와 target이 비슷하다고 볼 수 있으니, 각 iteration 마다의 source와 target의 유사성을 측정할 수 있고, 이 값을 통해 i번째 iteration에서의 source subnet의 파라미터를 업데이트할 수 있습니다.
최종적으로 저자는 Faster R-CNN의 RPN (Region Proposal Network)을 consistency learning하는 방식을 제안하는데, 결국 위의 source subnet은 동일한 target 이미지에서 시작하면, 유사한 region proposal을 내뱉어야한다는 주장입니다. RPN은 Top-N의 (objectness score에 따른) bounding box를 내뱉는데, i 번째 source subnet과 target subnet의 region proposal 집합을 정의할 수 있고, 이들 간의 maximum IoU를 구할 수 있으며 이에 따른 proposal serial number (source, target 간 IoU 매칭에 대한 내림차순에 따라 각 proposal에 번호를 붙이는 방식)을 붙여 아래와 같이 loss를 정의합니다. 어우, 개념적으론 이해가 되는데, 수식 하나하나 뜯어보다 몇 시간이 지나도 완벽히 이해되지 않아, 개념을 위주로 설명드리고자 하였습니다. 수식은 추후 다시 해당 논문을 베이스 삼을 일 (아마 코드가 없어 그럴 순 없겠지만)이 있다면, 그 때 또 뜯어봐야겠죠.. 그래도 본 논문을 읽은 이유는 Experiments의 세팅과 실험을 살펴보고자 함이 가장 큽니다. 실험으로 넘어가겠습니다.

Experiments
먼저, 중요한 부분은 데이터 셋입니다. multi-source object detection은 본인들이 처음이라 하였으니, mAP의 평가 척도를 사용함은 알겠지만 데이터를 어떻게 구성했고, 왜 그 데이터를 사용했느냐가 제게는 납득이 되어야했습니다. 저자는 데이터 셋으로 KITTI, Cityscapes, BDD100k를 사용합니다. (추후 다른 논문에서 사용한 실험은 target 도메인에 대해 coco 등의 데이터 셋을 사용함을 살펴보았습니다. 해당 실험을 coco와 더불어 두 가지 real 도메인의 데이터를 토대로 synthetic 도메인에서의 성능 평가를 진행하였습니다). 비교군으로는 1) Source-only: source 도메인만 학습한 채 바로 target 도메인에서 평가하는, DA의 lower boundary에 해당합니다. 2) Single-source DA: single-source를 사용하는 일반적인 DA 모델입니다. 3) Multi-source DA: 저자가 제안하는 Multi-source를 사용하는 DA 방법입니다. Multi-source를 classficiation에서 사용하는 이전 방법론들에 일반적인 detection head를 붙여 비교군으로 사용합니다. 4) Oracle: Faster R-CNN을 target 도메인에 대해 직접 학습한 방법입니다.
저자의 실험 세팅에서 KITTI와 Cityscape를 묶어 BDD100k에 대해 평가하는데, 이를 “Cross-Camera Adaptation”으로 칭합니다. 물론, 권석준 연구원님께 전해들은 바로 위와 같이 평가하는 DG 연구도 존재한다고 들었는데, 저자는 source domain shift 중 camera가 달라 영상 품질이 차이나는, 그 상황을 묘사하기 위해 두 도메인의 데이터를 결합하여 multi-source로 사용했다고 합니다.

위 실험 표를 보면 Source-only에 대해 “car” 카테고리에 대해 보면 KITTI, Cityscape 단일에 비해 두 데이터를 묶은 City-scapes+KITTI가 오히려 더 안좋은 성능을 보임을 알 수 있습니다. 또한, KITTI-only DA와 Cityscapes-only DA에 비해 물론 두 데이터를 단순히 합친 Source-combined DA가 조금 더 나은 성능을 보이거나 (KITTI-only에 비해) 혹은 Cityscapes-only에 비해선 더 안좋은 성능을 보이지만, 이에 비해 Ours에 해당하는 DMSN의 경우 꽤나 발전된 성능을 보입니다. 하지만 적어도 제 생각에는 물론 Source 도메인 내의 shift 현상이 발생한다곤 하나, 단일 클래스 AP여서 그런지 성능 향상이 조금 아쉽습니다. 학습 데이터가 늘어난 개수는 훨씬 많고, 그렇기 때문에 학습 resource는 훨씬 더 들었을텐데 말이죠.

두번째는 Cross Time Adaptation입니다. 학습 및 평가 데이터는 BDD100k이나, 촬영 시점에 따라 daytime과 nighttime에 대해 multi-source로 두고, dawn/dusk를 target 도메인으로 뒀을 때의 성능 향상을 보입니다. 음, 우선 train은 뭔지 모르겠네요. 아마 학습 때는 있었는데 평가 데이터에선 없었는 것 같은데, 이 때의 성능 향상도 잘 보면 Source-combined DA의 30.9에 비해 35.0, 꽤나 괜찮은 성능 향상을 보입니다. 또한 저자가 추가적으로 하고자 하는 말은 물론 단순히 detection을 위한 head를 Multi-source DA의 classification 태스크의 모델들에 붙였음에도 불구하고, detection적인 측면 (localization이 추가된)을 고려하지 않으면 Source-combined DA 혹은 Single-source DA (Daytime 비교)에 비해서도 낮은 성능을 보임을 알 수 있습니다. 결론적으로 초기 논문이었음에도, 그리고 adversarial, GRL과 같이 multi-source DA나 다른 방법론의 방법을 적용했음에도 불구하고 괜찮은 성능을 보임을 알 수 있습니다. 처음 읽어보는 UDA 논문이여서 그런지 굉장히 어렵긴 하네요.. 이상으로 리뷰 마치겠습니다.
안녕하세요. 좋은 리뷰 감사합니다 !
수식의 노테이션에 대해 질문이 있는데,,,, high-level feature alignment loss의 수식에서 F와 r이 무엇인지 궁금합니다. 전체 loss는 위 세 loss를 단순히 더하는 것인가오?
감사합니다 !!
리뷰 잘 읽었습니다.
overview에서 말씀하시는 ‘ 1) homogeneity: 모든 도메인의 feature가 동일한 manifold (feature space) 내 존재할 수 있습니다’ 의 부분이, 결국 이상적인 Multi-Source DA를 거친 후에 동일한 manifold 로 보내게 된다는 건가요? 아니면 동일한 manifold 위에 있다는 가정을 한 뒤, adversarial 기반의 DA를 수행하니 최종적으로는 data 분포까지 유사해지더라~ 인건가요? 뭔가 적고 나니 후자일 거 같긴 하네요.
그리고 추측성으로 말씀해주신 (아마 Faster R-CNN의 RoI 덕분) 이 부분에 대한 추가 의견이 궁금합니다~.!
감사합니다.