제가 이번에 리뷰할 논문은 아직 아카이브에 있는 논문으로 기하학적 representation을 encoding 한다고 하여 궁금증이 생겨 읽어보게 되었습니다.
Abstract
object의 정확한 자세를 추정하는 것은 중요하며, 이를 위해 딥러닝 기반의 방법론은 크게 2가지로 구분됩니다: 1) 기하학적 representation을 regression하는 방식과 2) 반복적으로 refinement하는 방식이 있습니다. 그러나 이러한 방법은 효율이 떨어진다는 한계가 있으며, 본 논문에서는 이러한 기존 방식의 한계를 분석하고 새로운 방식을 제안합니다. 기하학적 representation이 흐려지는 문제를 해결하기 위해 객체의 3D 좌표의 고주파 성분을 사용하여 positional encoding합니다. 또한 refinement 과정에서 local minimum가 발생하는 문제를 해결하기 위해 intrinsic 파라미터와 독립적인 normalized image plane기반의 multi-reference refienement 전략을 제안합니다. 마지막으로 adaptive instance normalization(style transfer에서 제안된 기술로, content와 style이 입력으로 주어졌을 때 두 입력의 평균과 분산을 style 입력과 동일하도록 조절하여 새로운 스타일에 대해서도 style transfer를 빠르게 수행할 수 있도록 하는 방식이라 합니다. 처음 AdaIN을 제안한 논문은 정민님의 x-review로 확인하실 수 있습니다.)과 간단한 occlusion augmentation방식을 통해 모델이 대상 객체에 집중할 수 있도록 합니다. 다양한 데이터 셋(LM, LM-O, YCB-V)에 대하여 기존 방법론과 비교했을 때 높은 성능을 달성하였습니다.(아직 코드는 공개 전이라 합니다..)
Introduction
단일 RGB이미지를 이용하여 6D Pose를 추정하는 것은 물체와의 상호작용을 위해 중요한 task이며 AR, 자율주행, grasping 등의 다양한 분야에서 활용 가능한 기술입니다. 단일 RGB기반의 방식은 크게 2가지로, 먼저 2D-3D 대응관계를 구한 뒤, RANSAC기반의 PnP나 추가적인 네트워크를 통해 pose를 추정하는 방식은 둥글고 texture가 부족한 객체에 대하여 기하학적 표현이 어려워 정밀한 추정이 어려워지며, 네트워크가 불연속적인 좌표를 구분하기 어려워 RANSAC기반의 PnP과정에서 부정확한 pose를 예측하게 됩니다.(아래의 Figure 2) 두 번째 방식은 직접적으로 pose를 regression하는 방식도 동일하게 texture가 부족한 경우에 대한 문제가 존재하며, 이를 해결하기 위해 외관의 texture를 이용하는 연구가 수행되었으나 이는 객체의 전체 형태를 나타내는 것이 아니라 segmentation 된 영역만을 나타낸다는 한계가 있습니다.

최근 반복적으로 예측값으로 렌더링한 뒤 이미지와 비교하는 방식을 이용하여 reference와 query 이미지 사이의 상대 pose를 추정하는 연구가 있으며, 이러한 방식은 점진적으로 정밀도가 증가합니다. 그러나, 이러한 방식은 초기 pose로부터 점진적으로 개선이 진행되면서 한정된 공간에서 pose가 개선되므로 local minimum에 갇히는 문제가 발생할 수 있습니다. 이를 위해 앙상블 방식을 이용하여 신뢰할 수 있는 refinement를 이용하는 방식이 있으나, 아래의 Figure 3과 같이 refinement에 사용하는 reference마다 성능이 크게 달라지게 됩니다. 따라서 이러한 방식으로는 local minimum 문제를 효과적으로 해소하기 어렵습니다. 게다가 refinement 기반의 방식은 상대 pose를 매개변수화하며, 이는 query와 reference의 intrinsic 행렬이 동일할 경우에만 가능하다는 제약이 있습니다. 따라서 online-rendering을 통해 reference를 동일한 instrinsic 파라미터로 렌더링해야하며 reference가 증가할 경우 연산량이 급증하게 됩니다.

이처럼 기존 연구들의 장점과 환계를 고려하여 pose를 추정하기 위해 Multi-Reference Refinement method with Positional Encoding(MRPE)라는 방식을 제안합니다. structure light scanning 방시과 NeRF에서 영감을 받아 mask 및 예측 오차와 함께 정규화 된 object 좌표계의 positional encoding을 추정하는 방법을 설계하였으며, positional encoding은 등고선과 유사하게 전체적인 형태 정보를 제공하여 모델이 고주파 성분을 통해 형태의 디테일에 집중할 수 있도록 하여 챌린지한 물체의 blur한 representation을 줄일 수 있었다고 합니다.
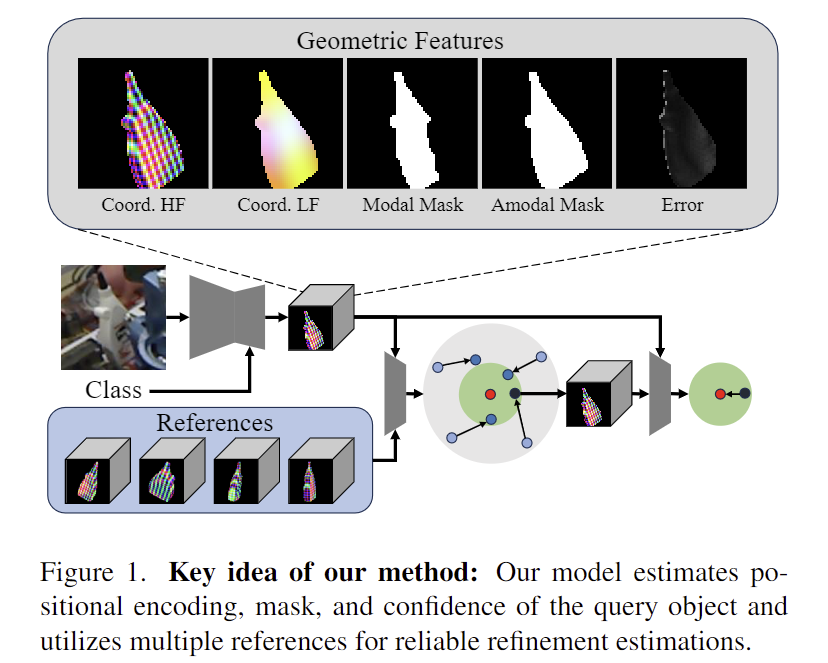
그 다음, 기하학적 도메인에서 물체를 렌더링하고 비교하는 방식을 적용합니다. 상대 pose를 추정하기 위해 추정된 positional encoding을 offline multi-references와 비교하는 방식으로 수행되며, 이를 위해 intrinsic 행렬을 활용하여 pose를 업데이트하는 방식을 제안합니다. 이때 여러 referenece를 렌더링하는 과정에 연산량이 급증하지 않도록 앙상블을 사용하여 성능을 개선하였다고 합니다. 또한, occlusion에 강인하도록 Adaptive Instance Normalization(AdaIN) 기술을 활용하여 주어진 객체 클래스에 따라 대상 객체에 집중하도록 네트워크를 조정하며, 다양한 벤치마크(LM,LM-O,YCB-V)에서 SOTA를 달성하였다고 합니다.
Contribution을 정리하면
- 대상객체에 대한 object 좌표계에서의 positional encoding을 활용하여 부정확한 추정 문제 해결.
- intrinsic 행렬에 의존하지 않는 pose update 모듈을 제안하였으며, 해당 모듈은 rendering-and-compare과정(반복적으로 렌더링 하고 원본과 비교하여 업데이트하는 방식)에서 multi-reference를 활용하여 rendering으로 인한 연산량 증가를 막고 local minimum 문제를 해결.
- occlusion에도 대상 객체에 집중할 수 있도록 AdaIN 기반의 모델 제안
Method
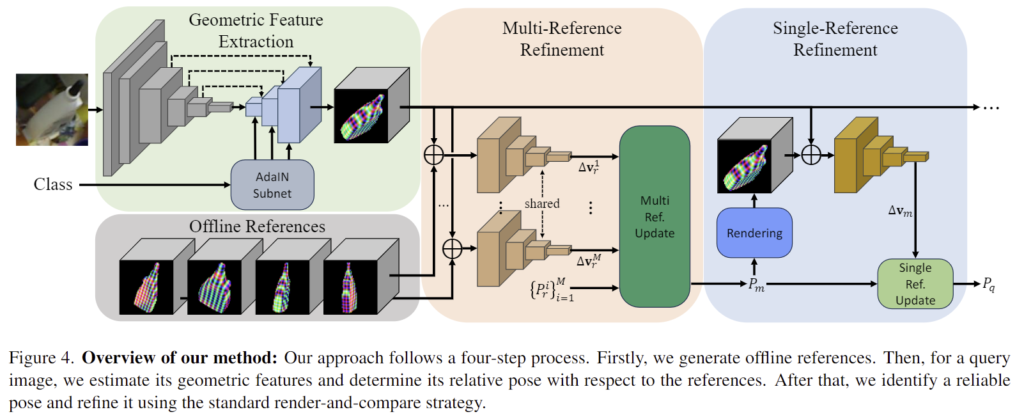
주어진 query 이미지에서 3D 모델 \mathcal{M}의 pose P_q를 추정하는 것을 목표로 하며, 기존 연구와 유사하게 기존 detection 연구의 검출기를 사용하여 대상 객체에 대하여 zoom-in된 이미지 I_q를 구하고 intrinsic matrix K_q를 이용합니다. 전체적인 과정은 위의 Figure 4에 나타나 있습니다. 이제 각 파트에 대해 설명하겠습니다.
1. Offline References Generation
학습을 시작하기 전에 학습set에서 각 object에 대해 M개의 대표 샘플을 선택하여 reference로 사용합니다. 각 reference에 대해 학습 및 inference단계에서 사용되는 기하학적 특징 \{ F^i_r\}^M_{i=1}을 생성하는 단계입니다.
다양한 reference view를 얻기 위해 farthest point sampling 알고리즘을 이용하여 학습 set을 샘플링합니다.(기존 연구의 방식을 따랐으며, 기존 연구는 mask영역이 가장 큰 view에서의 이미지를 첫번째 reference로 삼은 뒤, rotation matrix의 오차를 기준으로 가장 먼 점의 viewpoint를 선택하는 방식으로 샘플링을 수행하였다고 합니다.) 샘플링된 reference들의 pose \{ P^i_r\}^M_i=1는 positional encoding 함수를 이용하여 기하학적 feature의 2D-3D 대응 map을 생성하는 데 사용하며, 아래의 식(1)로 표현됩니다.
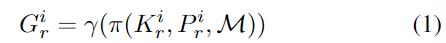
- G^i_r∈\mathbb{R}^{h⨉w⨉6N}: encoding feature
- \gamma (.): N 주파수를 갖는 positional encoding 함수
- \pi (.): intrinsic matrix K^i_r과 pose P^i_r, 3D 모델 \mathcal{M}을 이용한 projection 함수
이후 G^i_r는 reference 이미지 I^i_r와 마스크 M^i_{r-}, amodal 마스크(가려진 영역에 대한 정보를 포함하는 마스크) M^i_{r+}와 concate되어 전체 reference feature F^i_r∈\mathbb{R}^{h⨉w⨉(6N+5)} (+5는 rgb+mask+amodalmask)를 생성한 뒤 학습 및 평가시 multi-reference refinement 모듈에 사용합니다.
2. Geometric Feature Extraction
해당 묘듈은 디테일한 query의 feature F_q를 추출하는 과정입니다. CNN 기반의 encoder-decoder 구조를 통해 dense한 feature를 추정하도록 하며, 모델은 식(1)과 유사하게 기하학적 feature G_q∈\mathbb{R}^{h⨉w⨉6N}를 추정하며, 기하학적 feature의 추정치에 대한 오차 E_q∈\mathbb{R}^{h⨉w⨉6N}를 예측합니다. 또한, 마스크M^i_{r-}와 amodal 마스크 M^i_{r+}를 예측한 뒤 이를 query I_q와 연결하여 query feature F_q∈\mathbb{R}^{h⨉w⨉12N+5}를 생성합니다. (Introduction의 Figure 1에서 Geometric Feature에서 예측하는 값들을 확인하실 수 있습니다.)
E_q는 대칭 객체의 기하학적 모호성(180도 대칭일 경우 앞뒤의 기하학적 차이가 없음과 같은 모호성을 의미)을 해결하기 위해 설계되었으며, positional encoding \gamma (.)에는 대칭인 sine과 비대칭인 cosine 인코딩을 모두 포함하므로 E_q는 모델에게 대칭인 객체는 cosine 인코딩에만 집중하고 비대칭인 객체는 sine과 cosine 인코딩에 집중하도록 알리는데 활용합니다.
또한, 여러 대상 객체에 대한 단일 모델을 학습시키는 과정에서 모호성이 추가로 발생하며, 기존 연구는 여러 객체가 겹쳐있을 경우 모델이 대상 객체를 구별하기 어려웠습니다. 이를 해결하고자 feature extractor가 대상 객체에 집중할 수 있도록 AdaIN 방식을 구현하였다고 합니다. 모델이 대상 객체에 집중하도록 검출된 calss는 FC layer로 이루어진 네트워크를 통해 embedding 된 후 feature extractor에 통합됩니다. 이후 AdaIN 방식이 적용됩니다.
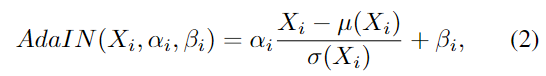
- X_i: feature extractor 헤드의 i번째 layer의 feature
- \alpha _i, \beta _i: 서브 네트워크에서 추정된 파라미터
- μ(.), \sigma (.): 객체별 평균과 표준편차를 구하는 함
3. Pose Refinement
Multi-Reference Refinement
F_q와 각각의 F^i_r를 연결하여 CNN기반의 pose 추정 헤드에 입력하여 query와 i번째 reference 사이의 rotational/positioinal 차이를 포함하는 refinement 파라미터 \Delta \mathbf{v}^i_r를 계산합니다. i번째 reference의 pose P^i_r는 \Delta \mathbf{v}^i_r와 업데이트되어 query에 대한 후보 pose P_c^i를 생성합니다. 아래의 Algorithm 1은 해당 과정에 대한 pseudo code입니다.

translation에 대한 refinement
먼저, focal length로 인한 크기 차이를 고려하기 위해 먼저 translation z 파라미터를 t_{cz}^i로 업데이트합니다. 이후 intrinsic matrix K^i_r의 크기와 offset 문제를 분리하기 위해 객체의 중심을 정규화된 이미지평면으로 투영합니다. 그 다음 추정된 v^i_x와 v_y^i 를 이용하여 각 reference의 투영된 객체 중심 \mathbf{o}_r 을 업데이트하고, 업데이터 된 중심 \mathbf{o}_c 는 query의 intrinsic 행렬 K_q을 이용하여 3차원으로 재투영되고, t^i_{cz}로 스케일링되어 translation vector \mathbf{t}_{cxy}^i를 찾습니다.
rotation에 대한 refinement
rotation에 대한 refinement를 위해 allocentric rotation 표현을 이용하였다고 합니다. 먼저 allocentric과 egocentric이 어떤 차이가 있는 지 간단하게 설명 드리겠습니다. 아래의 그림은 이해를 돕기 위한 것으로, 카메라와 대상 객체가 있을 때 egoentric은 object의 중심을 기준으로 rotation되고, allocentric은 외부의 객체를 중심으로rotation됩니다. allocentric을 이용하게 될 경우 객체의 외관이 크게 변하지 않는다는 장점이 있어 객체 중심의 작업에서 유리하고, 저자들도 viewpoint-invariant하다는 특징 때문에 allocentric 표현을 이용하였다고 합니다.

이처럼 rotation을 allocentric한 rotation 표현 R_{r,a}로 변경한 뒤, 예측된 \mathbf{v}_{rot}^i상대 rotation matrix R^i_{rot}으로 refine된 allocentric 도메인의 R_{c,a}^i를 구합니다. 마지막으로 R_{c,a}^i를 예측된 \mathbf{t}^i_c를 이용하여 egocentric domain으로 변환하여 rotation 예측값을 구합니다.
위의 과정을 통해 추정된 \Delta \mathbf{v}^i_r는 이미지 평면에서 translation을 업데이트하므로 intrinsic matrix로부터 자유로우며 이는 모델이 파라미터를 효율적으로 학습할 수 있도록 도움이 될 뿐만 아니라 query 이미지와 다른 intrinsic matrix를 가진 reference를 사용할 수 있도록 하므로 offline에서 생성된 referecne를 이용할 수 있으며, 각 query에 대한 reference를 생성하는 데 필요한 연산량을 크게 줄일 수 있습니다.(즉, queyr 이미지와 동일한 intrinsic matrix를 가진 렌더링 이미지를 만들어야하는 과정을 피할 수 있어 연산량을 줄일 수 있다는 것 입니다.)
Reliable Pose Voting
예측 신뢰도를 향상시키기 위해 medoid values \{R_c^i, \mathbf{t}_c^i \}^N_{i=1}를 이용합니다. 해당 과정은 각 \mathbf{t}_c^i와 다른 후보값들 사이의 거리의 합을 translation의 지표로 이용하고 각 R_c^i과 후보의 geodesic distances의 합을 rotation의 지표로 이용하여 오차가 최소가 되는 rotation과 translation을 찾습니다. 즉, 아래의 색을 통해 구한 d_t^i와 d_R^i가 최소가 되는 값을 구하는 것 입니다.
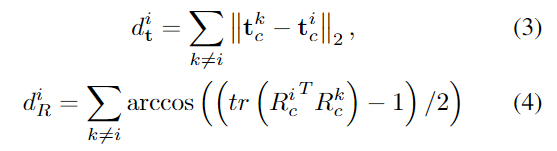
Single-Reference Refinement
앞선 과정을 통해 선택된 pose P_m=[R_m|\mathbf{t}_m]와 query의 intrinsic matrix K_q를 이용하여 medoid reference의 feature F_m∈\mathbb{R}^{h⨉w⨉(6N+2)}(+2는 mask와 amodal mask인 것으로 보입니다)를 생성합니다. F_m과 F_q를 합산하고 이를 이용하여 pose 추정 헤드로 refinement 매개변수 \Delta \mathbf{v}_m을 추정합니다. 해당 과정에서는 기하학적 특성을 렌더링하는 과정에서 연산량 증가를 막기 위해 단일 reference만을 이용하며, pose를 업데이트하여 최종 pose P_q를 구합니다. 해당 과정은 반복적으로 수행하며, 실험적으로는 2번 반복하면 충분한 결과를 얻을 수 있었다고 합니다.
4. Objective Function
해당 방법론의 모델은 2가지 목적함수가 존재합니다.: query에서 feature를 추출하기 위한 것과 pose P^i_c와 P_q를 추정하는 것. 먼저, feature 추출을 위해 masked L1 loss를 이용하며 아래의 식으로 정의됩니다.
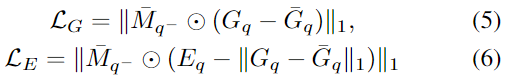
- \bar{M}_{q-}: query에 대한 GT 마스크
- \bar{G}_{q}: query에 대한 GT 기하학적 feature
- ⊙: element-wise 곱
- E_q는 기하학적 feature의 오차를 추정하는 것이므로 ||G_q - \bar{M} ||_1이 GT가 됩니다.
또한 마스크와 amodal 마스크를 학습하기 위해 L1 loss를 적용하였으며 아래의 식(7)로 정의됩니다.
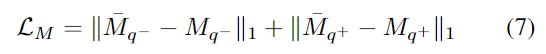
pose 예측을 위한 목적함수는 아래의 식 (8)로 정의되며, 이는 기존 연구에서 제안된 공간상에 grid를 만들어 유클리드 거리를 구하는 방식입니다.

- \bar{\mathcal{G}}_q: query의 GT pose로 생성된 grid
- \bar{\mathbf{t}}_q: GT translation 벡터
- \mathcal{G}^i_c: P^i_c로 생성된 grid
P_q와 \mathbf{t}_q, \mathcal{G}_q도 위의 식 (8)을 적용하여 \mathcal{L}_{P_q}를 구하며, 이때 4x4x2 grid points를 이용하였다고 합니다.
최종 loss는 아래의 식으로 정의되며 \lambda는 실험적으로 20으로 설정하였다고 합니다.

Experiment
LM, LM-O, YCB-V데이터로 평가를 수행하였으며, ADD(-S)를 평가지표로 이용합니다. LM과 LM-O는 객체 지름의 10% 이내의 오차일 경우 정답으로 보며, YCB-V는 최대 10cm까지 정답의 임계값을 변화하여 그래프를 그린 뒤, AUC(Area Under Curve)를 구합니다. 추가로, BOP 챌린지에서 사용하는 지표로도 평가를 수행합니다.
Comparison with SOTA

- 위의 Table1은 LM에 대한 정량적 결과로, 기존 방법론 대비 좋은 가장 좋거나 유사한 성능을 달성하였습니다. (Convnet-T는 tiny모)
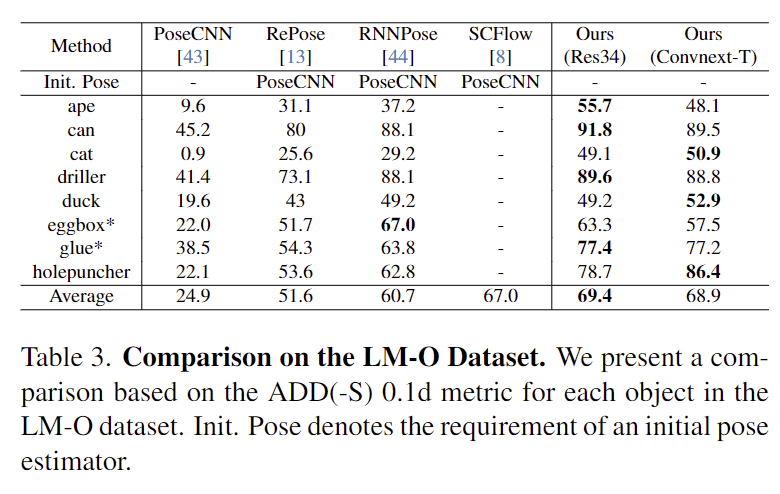
- 위의 Table 3은 LM-O에 대한 평가지표로, ResNet34에서 SOTA를 달성하였으며, 모두 기존 방법론 보다 좋은 성능을 보였습니다.


- 위의 Table2는 YCB-V에 대한 성능으로, 본 논문의 방법론이 두 백본에서 모두 기존 방법론보다 좋은 성능을 달성하였습니다.
- occlusion이나 texture가 적은 경우에도 더 정확하게 poes를 추정하였다고 합니다.
- 위의 Figure 5는 정성적 결과를 시각화한 것으로 local minimum문제를 해결할 수 있음을 보여준다고 합니다.

- 위의 Figure 6은 각 모듈에서 정성적 결과를 시각화 한 것으로, 제안된 모델은 feature extraction 모듈에서 query 객체의 기하학적 특징을 고려한 인코딩을 수행하였으며, refinement 모듈은 mask와 amodal mask를 활용하여 occlusion이 심하게 발생하여도 representation이 잘 된 것을 확인할 수 있습니다.

- 위의 Table 4는 BOP 챌린지에서 사용하는 지표를 이용하여 벤치마킹을 한 것으로, 기존 방법론과 비교했을 때 대부분 더 좋은 성능을 달성하였습니다.
- 또한, ConvNext-Tiny를 백본으로 사용할 경우 빠른 inference가 가능하면서도 평균 AR이 가장 좋은 성능을 달성할 수 있음을 보였습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
positional encoding에서 등고선과 유사한 형태를 제공한다는 것은 챌린지한 물체가 나타나더라도 semantic한 정보까진 아니더라도 형태를 알아내면서 pose를 추정할 수 있다는 의미가 맞을까요 ?? 또 여기서 사용하는 intrinsic 행렬에 자유롭게 다른 카메라로 촬영한 query가 들어오더라도 pose를 추정할 수 있는데, 기존에 intrinsic 파라미터는 refinement 파라미터를 구할 때만 사용되던 것인가요 ? 또한 여러 reference를 렌더링하는 과정에서 연산량이 급증하지 않기 위해 앙상블을 사용하여 성능을 개션하였다고 말씀해주셨는데 기존에 앙상블로 진행할 때 refinement에 사용하는 reference마다 성능이 크게 달라지는 문제는 어떻게 방지할 수 있나요 ?
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
간단한 질문을 남기자면,
제안한 AdaIN이 occlusion에 강인하게 동작하는 것으로 보이는데 식으로 보았을 때는 feature에 대한 분포 형태를 보고 파악하는 것으로 이해하였습니다. 하지만 이러한 행위가 occlusion에 강인한 것은 무엇의 영향 때문인지 정확하게 이해가 되지 않네요. 부가적인 설명이 가능할까요?
감사합니다.