안녕하세요, 이번 X-Review에선 23년도 MM 학회에 게재된 MH-DETR이라는 논문을 소개해드리고자 합니다. 기본적으로 저번 리뷰에서도 설명드렸던 Moment Retrieval (MR)과 Highlight Detection (HD)를 동시에 수행하는 방법론 중 하나입니다.

바로 리뷰 시작하겠습니다.
1. Introduction
본 논문에서는 MR과 HD를 동시에 수행하기 때문에 편의상 두 task를 MHD라고 줄여 부릅니다. 각 task는 아래 그림 1을 통해 이해할 수 있습니다. MR은 주어진 텍스트 쿼리에 상응하는 비디오 구간(그림 1에서 파란색)을 찾아내는 것이고, HD는 모든 segment(비디오를 세분화한 단위, 본 방법론에서는 2초 단위의 구간)에 대한 saliency score(분홍색 그래프)를 추출하여 실제 highlight라고 annotation되어있는 GT와 비교하게 됩니다.

21년도 NeurIPS에서 QVHighlights라는 데이터셋과 MHD를 동시에 수행하는 Moment-DETR이라는 방법론이 공개되었습니다. 이때부터 MR과 HD는 대부분 동시에 연구되기 시작되었으며 굉장히 단순하지만 높은 성능을 보여주는 Moment-DETR을 기반으로 다양한 DETR-like 방법론들이 쏟아져나오고 있는 상황입니다.
이러한 연구 흐름에 대해 더욱 깊은 정보가 궁금하신 분들은 질문 주시거나 아래 리뷰들을 참고해주시면 감사드리겠습니다.
본 논문에서 제안하는 MH-DETR 또한 그런 방법론 중 하나이며, 단순하기 때문에 발생하는 Moment-DETR의 단점을 이것저것을 건드리며 큰 성능향상을 이룬 방법론입니다. 일반적으로 논문의 그림 1은 기존 방법론과 자신들 방법론의 정성적 비교 그림이거나, 정의한 문제에 대한 실험 결과를 담는데, 아직 MHD를 동시에 수행하는 task가 많지 않아서인지, 아니면 정의한 문제가 어느정도 주관적이라 그런지 단순히 task에 대한 단순한 설명만을 하고 넘어가고 있습니다.
아무튼 Introduction 초반에는 task에 대한 설명이 주를 이루고, 계속 읽다보면 저자가 지적하는 Moment-DETR의 단점이 등장합니다. 핵심은 Moment-DETR의 두 모달리티 feature fusion 방식이 너무나 단순하다는 것입니다. MR과 HD 모두 비디오에 대한 visual feature와 텍스트 쿼리에 대한 text feature 간 상관관계 파악 및 interaction modeling이 성능에 큰 영향을 미치는데, Moment-DETR에서는 단순히 각 모달의 token을 concat해 Transformer Encoder로 넣어주게 됩니다. 앞서 리뷰했던 QD-DETR에서는 이 문제를 해결하고자 모달 간의 cross-attention을 바로 수행하기도 했었죠.
본 논문에서 제안하는 MH-DETR은, 두 모달 간 좀 더 유의미한 feature fusion을 위한 DETR 기반 모델 구조를 제안합니다. 우선 각 모달 내부적으로 global한 맥락 정보를 잘 파악하기 위한 효율적 pooling operator를 적용하고, 그 후 두 모달 간 interaction을 잘 수행하기 위해 plug-and-play 방식의 cross-modal interaction module을 제안합니다.
바로 방법론으로 넘어가겠습니다.
2. Method
2.1 Overview
우선 notation을 정리하겠습니다. 비디오 V \in{} \mathbb{R}^{L_{v} \times{} H \times{} W \times{} 3}가 주어지는데, 여기서 L_{v}는 비디오에 존재하는 clip의 개수를 의미합니다. 다음으로 텍스트 쿼리 T \in{} \mathbb{R}^{L_{t}}는 L_{v}개의 단어로 구성된 하나의 문장입니다. MR task의 목적은 주어진 두 feature를 잘 fusion하여 시작 지점, 끝 지점으로 구성되는 비디오 내 모든 상응 구간 M = \{{m_{i} \in{} \mathbb{R}^{2}}\}_{i=1}^{L_{m}}을 찾는 것입니다. 또한 HD는 클립 별 Saliency score S \in{} \mathbb{R}^{L_{v}}를 뽑음으로써 수행됩니다. DETR 구조를 조금 변형하여 encoder의 output으로부터 S를, encoder의 output과 Moment query를 decoder의 입력으로 주어 M을 얻는 것입니다.
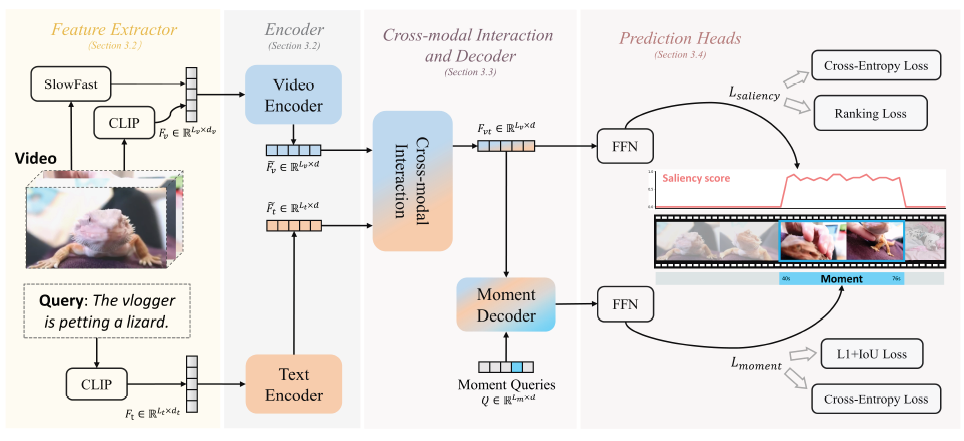
그림 2에서 MH-DETR의 전체 구조를 볼 수 있습니다. 그림 2에서 확인 가능한 방법론의 전체 구조는 우선 4가지 모듈로 나눠지고 있습니다. Feature Extractor와 Encoder에서는 각 모달리티의 feature를 추출하는 부분이고, 실질적으로 task를 수행하기 위한 모달리티 간 interaction은 Cross-modal Interaction and Decoder에서 이루어집니다. 마지막으로 FFN으로 구성된 Prediction Heads에서는 앞 단계에서 뽑은 encoder, decoder의 representation을 활용해 각각 HD, MR을 수행하는 것입니다.
앞서 Introduction에서 말씀드렸던 MH-DETR의 contribution은 Encoder와 Cross-modal Interaction and Decoder 각각에 존재합니다. 이제 각 모듈을 하나씩 알아보겠습니다.
2.2 Feature Extractor and Encoder
Feature Extractor.
기본적인 세팅은 MHD의 베이스라인 방법론인 Moment-DETR을 따릅니다. 우선 video feature의 경우 사전학습된 SlowFast 백본과 CLIP image encoder로 2초당 하나의 feature F_{v} \in{} \mathbb{R}^{L_{v} \times{} d_{v}}를 만들어줍니다. 또한 텍스트 쿼리는 CLIP text encoder를 활용해 feature F_{t} \in{} \mathbb{R}^{L_{t} \times{} d_{t}}를 추출합니다.
Encoder.
최근 Transformer에서 token mixer도 중요하게 연구되고 있습니다. Token mixer의 가장 기본적인 구조는 attention 연산일 것이고, 22년도 쯤에는 Attention 대신 spatial MLP를 적용해도 유사한 성능을 낼 수 있다는 연구 결과도 많이 나온 것으로 보입니다. Token mixer의 의미는 아래 그림의 MetaFormer 구조를 보면 알 수 있습니다.
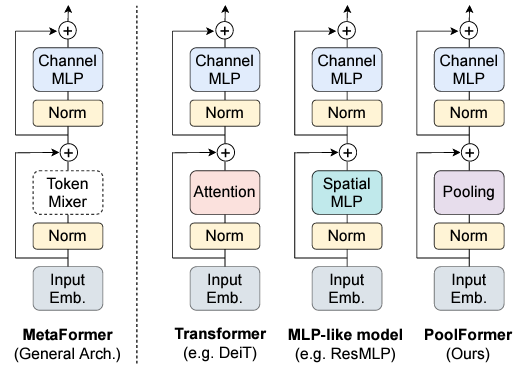
위 PoolFormer의 그림에서, Token Mixer를 Attention도 MLP도 아닌 Average Pooling으로 대체한 PoolFormer의 구조를 볼 수 있습니다. PoolFormer 논문의 abstract를 보면 “embarrassingly simple spatial pooling operator”라고 작성했는데, 이를 보니 다른 token mixer들과 비교했을 때 Pooling operator가 parameter도 없이 굉장히 효율적, 효과적으로 잘 동작한다는 것을 알 수 있습니다.
MH-DETR도 이러한 PoolFormer의 방식을 따라 각 모달리티 feature의 global 정보를 담고자 합니다. 파라미터 없이 각 모달리티 feature를 even하게 인접한 토큰 간 관계를 모델링할 수 있게 되는 것입니다. Notation 상으로는 \tilde{F}_{x}를 얻는 것이 목표입니다.
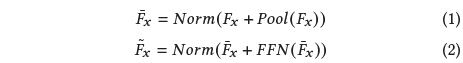
위 수식에서 F{x} \in{} \{F_{v}, F_{t}\}를, Pool은 PoolFormer의 Average Pooling으로 window 크기 3, stride 1로 설정되어 있습니다. Norm은 LayerNormalization을 의미합니다. 수식 1, 2를 통해 PoolFormer로 설계된 encoder의 forward 연산을 알아볼 수 있었습니다. 사실 이 MH-DETR의 온전한 contribution이라 보기엔 좀 어려울 것 같네요.
2.3 Cross-modal Interaction and Decoder
Cross-modal Interaction Module.
저자가 Introduction에서 지적한 베이스라인의 단점을 보완해주는 부분입니다. MR, HD task 특성 상 두 모달리티 간 상호작용 quality에 따라 성능이 많이 달라지는데, 특히 HD에서는 애초에 텍스트 쿼리를 기반으로 하이라이트를 찾는 연구가 적었기에 더더욱 중요하게 고려해줘야 할 것입니다. QD-DETR을 포함한 다른 방법론에서도 강조하는 이야기이지만, 두 task 모두 모달리티 정보의 interaction을 위해 단순 concat보다 더욱 고도화된 방법론이 필요하다고 말하고 있는 추세입니다.
결론적으로 MH-DETR에서 제안하는 cross-modal interaction module은 아래 그림 3과 같습니다.
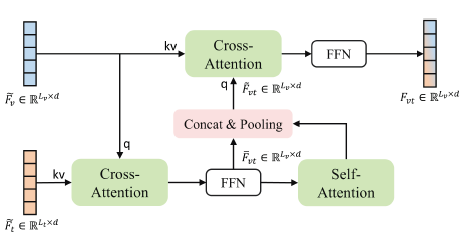
입력값부터 차례차례 살펴보면, 우선 Encoder에서 얻은 video feature \tilde{F}_{v}, text feature \tilde{F}_{t}를 받아 \tilde{F}_{v}를 query, \tilde{F}_{t}를 key, value로 받아 cross-attention을 먼저 수행합니다. 이 연산을 통해 비디오의 각 clip이 문장 내 각 단어와 어떠한 관계를 가지는지 파악할 수 있게 됩니다.
이후 FFN을 거치고 다시 한 번 self-attention 연산을 거치게 됩니다. 분홍색 박스에 해당하는 과정에선, CA-FFN의 결과물과 CA-FFN-SA의 결과물을 차원 축으로 concat한 뒤 pooling하여 이를 query로, 원본 video feature \tilde{F}_{v}를 key, value로 삼아 다시 한 번 cross-attention을 수행해줍니다. 이는 아래 수식과 같습니다.
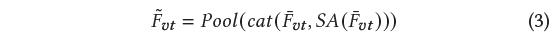
본 모듈에서 얻고자하는 fusion된 최종 feature F_{vt} \in{} \mathbb{R}^{L_{v} \times{} d}는 \tilde{F}_{vt}에 FFN까지 거쳐 얻게 됩니다.
Moment Decoder.
MR과 HD는 앞서 추출한 encoder의 최종 feature F_{vt}로부터 수행됩니다. HD는 decoder의 관여없이 encoder의 출력 F_{vt}만으로 수행되고, MR은 learnable moment query Q \in{} \mathbb{L_{v} \times{} d}와 encoder의 output F_{vt}를 입력받아 출력 moment feature \tilde{Q} \in{} \mathbb{R}^{L_{m} \times{} d}를 얻음으로써 수행됩니다. 이에 대한 자세한 내용은 다음 절에서 다루겠습니다.
2.4 Prediction Heads and Training Loss
Prediction Heads.
HD의 목적은 clip 별 saliency score S를 얻는 것입니다. 이는 앞서 얻은 encoder의 output F_{vt}에 하나의 FC layer를 태워 얻어줍니다. MR은 decoder의 output \tilde{Q}를 FC layer에 태우고, Sigmoid를 거쳐 0~1 사이의 값을 만들어냅니다. 0~1 사이 값은 normalized start, end point라고 생각하시면 됩니다. 이와 더불어 별도의 FC layer에 태운 뒤 Softmax를 거쳐 해당 구간이 foreground인지 background인지 예측을 수행하고, 구간 label을 가지고 있으니 학습을 추후에 진행해줍니다. DETR의 class 학습을 따라가되 텍스트 쿼리는 몇 가지로 정의할 수 있는 “클래스”가 아니다보니 fgd, bgd로 치환한 분류 loss를 적용해주는 것입니다. Action Localization에서도 마찬가지였지만, foreground, background 각각을 하나의 클래스로 엮고 있는 것도 짚어볼 만한 개선점이 될 수 있겠네요.
Loss에 적용해줄만한 모델의 출력값을 정리해보겠습니다. 우선 HD를 위한 saliency score S, MR을 위해 예측한 moment M, 그리고 동시에 얻은 foreground-background 예측값이 있습니다.
Saliency Loss.
HD 학습을 위한 loss \mathcal{L}_{saliency}입니다.
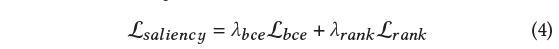
이 중 \mathcal{L}_{bce}는 아래 수식과 같습니다.
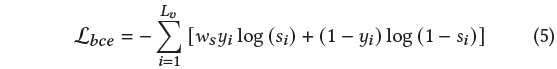
클립 별 saliency score에 대해 실제 label과의 BCE loss이며, 가중치 w_{s}는 BCE loss 계산 시 실제 saliency score에 따라 가중치를 다르게 주기 위해 곱해져 있는 값입니다. Score가 높을 수록 loss 가중치를 높게 주는 것이죠.
또 다른 term \mathcal{L}_{rank}는 아래 수식과 같습니다. Margin ranking loss의 형태를 가지고 있으며 그 대상은 GT 구간 내 score가 높은 clip, 낮은 clip 간 margin loss와 GT 구간 내 clip과 구간 외 clip의 margin loss의 합으로 구성됩니다.
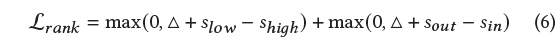
Moment Loss.
다음은 MR을 위한 loss \mathcal{L}_{span}입니다.
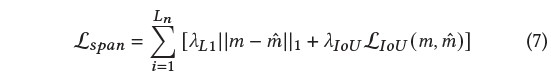
예측한 구간과 실제 GT 구간 간의 L1 loss와 구간의 generalized IoU loss로 구성되어있습니다.
3. Experiments
3.1 Datasets
벤치마크를 위한 데이터셋은 아래와 같습니다.
- MR&HD: QVHighlights
- MR: Charades-STA, ActivityNet Captions
- HD: TVSum
기본적으로 데이터셋마다 feature를 추출하는 백본의 세팅은 조금씩 상이합니다. 이는 벤치마크 표에서 확인하실 수 있습니다.
3.2 Evaluation Metrics
QVHighlights 데이터셋의 MR은 IoU threshold 0.5, 0.7에서의 Recall@1 값과, IoU threshold 0.5, 0.75에서의 mAP 그리고 [0.5:0.05:0.95] 구간에서의 평균 mAP를 리포팅합니다. HD는 mAP와 HIT@1 값을 리포팅합니다. HIT@1은 모델이 예측한 saliency score 중 가장 높은 score를 기록한 clip이 GT annotation 중 ‘Very Good’으로 라벨링되어 있는 클립인지의 정확도를 의미합니다.
3.3 Experimental Results
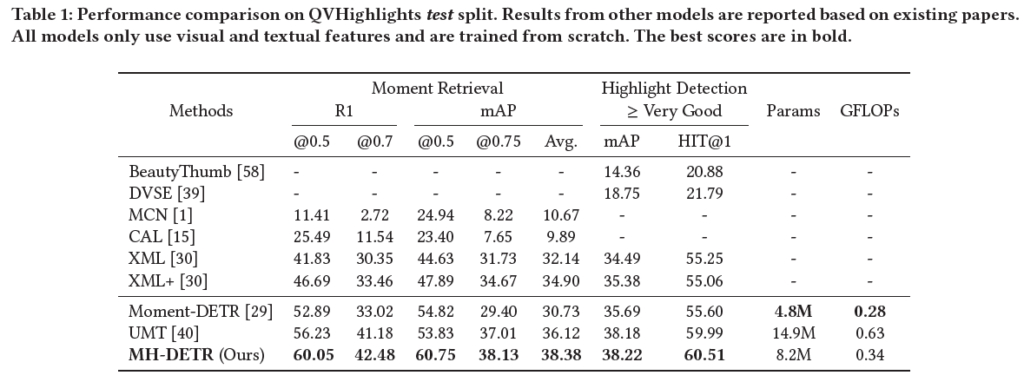
표 1은 QVHighlights test split에서의 MHD 성능입니다. 베이스라인인 Moment-DETR의 성능보다 월등히 향상된 것을 확인할 수 있습니다. 23년도 논문들까진 주요 loss만 일부 붙여줘도 성능 향상 폭이 굉장히 크게 느껴지네요.
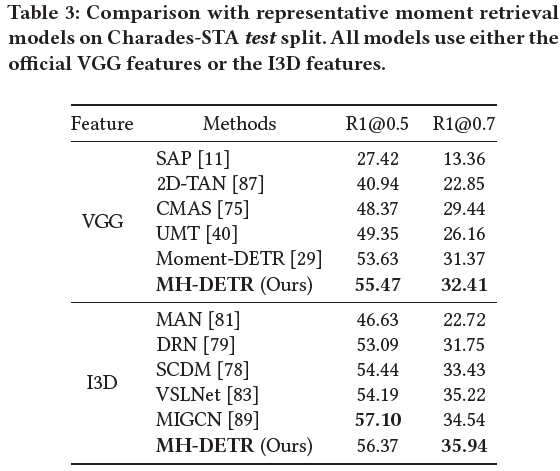
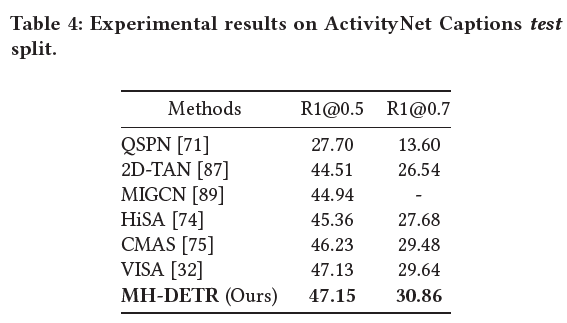
표 3, 4는 각각 Charades-STA, ActivityNet Captions 데이터셋에 대한 MR 성능입니다. 사실 QVHighlights의 MR 측면에서는 굉장히 큰 폭의 성능 향상이 있었지만, 다른 데이터셋에서도 향상은 있지만 폭은 그리 크진 않네요. 우선 저자는 별다른 분석 없이 SOTA를 달성하고 있다고만 이야기하고 있습니다.
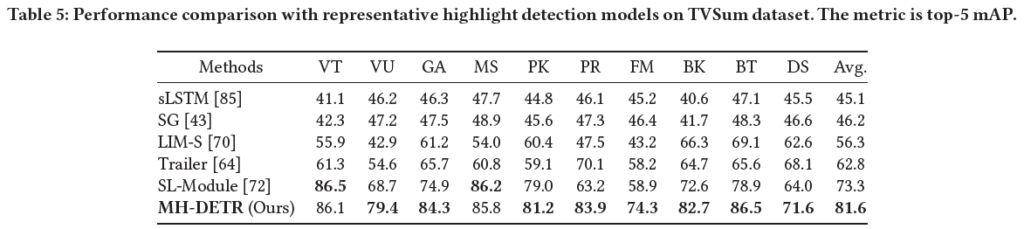
표 5는 TVSum 데이터셋에서의 HD 벤치마크 성능입니다. 10개의 카테고리 중 몇몇을 제외하고는 SOTA를 달성하고 있습니다.
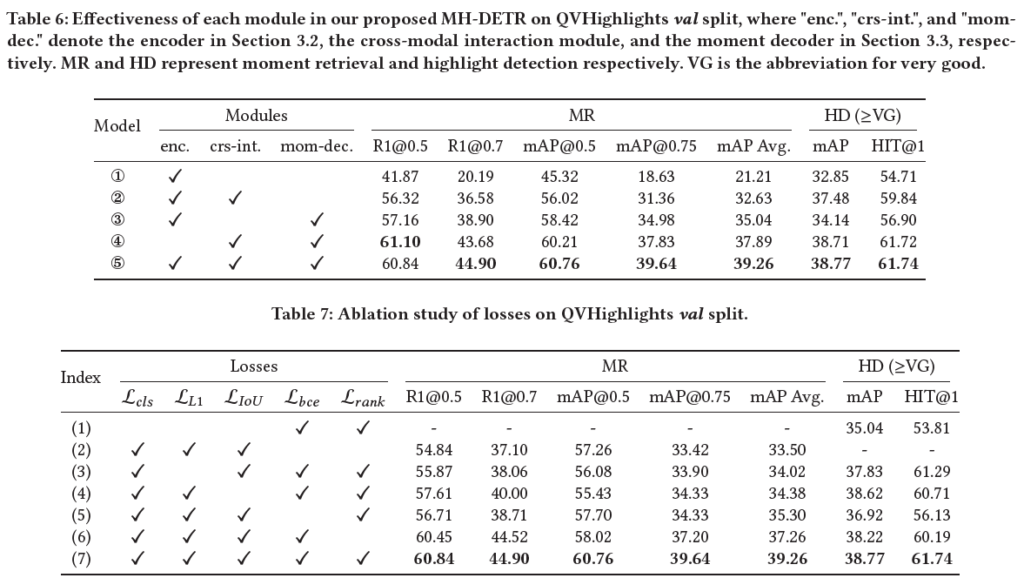
표 6은 module 별 ablation study 성능입니다. 3번 모델이 베이스라인 성능에 해당하고, PoolFormer를 사용했는지, cross-modal interaction module을 사용했는지 여부에 따라서 4, 5번 모델에 해당합니다. 저자의 분석은 그냥 모듈을 추가할수록 각각이 제역할을 하면서 성능을 올려준다고 이야기하고 있습니다. 볼만한 것은 아무래도 저자가 방법론 실험을 MR 기준으로 진행했는지 MR에서는 높은 성능 향상을 보여주지만 HD에서는 MR에서의 향상에 비례한 향상 폭을 보여주고 있지 못한 모습입니다. 다른 논문들을 봐도 MR task를 기준으로 실험을 진행해서 그런지 HD 성능은 MR 성능 순위와 비례하지 않는.. 경향을 보여줍니다. MR에서 SOTA를 달성한 방법론이 HD에서는 베이스라인과 얼마 차이나지 않는, 낮은 성능을 보는 경우가 있다는 의미입니다.
정성적 결과는 생략하겠습니다.
4. Conclusion
실험 결과는 아무래도 방법론 초창기이다보니 명확하지 못한 부분이 종종 보이지만, 우선은 방법론적 측면에서 follow-up 하는 것에 초점을 더 맞춰야 할 것 같습니다. MR과 HD를 동시에 수행하다보니 벤치마크해야하는 데이터셋도 많고, 데이터셋 별로 이전 방법론과의 fair comparison을 위해 feature 추출 backbone도 달라 성능 측정 세팅이 꽤 복잡해보이네요.
예전에도 논문 작업을 할 때 하나의 데이터셋에서 열심히 성능을 올린 뒤 다른 벤치마크 데이터셋에 적용해보았을 때 성능이 잘 오르지 않아 당황스러웠던 기억이 있었는데, 본 task에서의 실험도 동일한 상황이 발생할 것 같은 느낌이 듭니다.
방법론 측면에서는 phrase-level, 즉, 텍스트 encoder에 들어가는 각각의 token이 담는 의미를 좀 더 세분화에서 다룰 수 있는 방법론을 제안해보는 것이 지금 시점에서는 유의미할 것 같습니다. 이를 위해서는 기존 MR 방법론을 분석해보기보단 Object Detection 쪽에서 image patch를 효과적으로 다루는 DETR의 응용 방법론들을 살펴보는 것이 필요할 것 같습니다. 이에 대해 알고 계신 분들은 논문을 추천해주시면 감사드리겠습니다.
리뷰 마치겠습니다.
안녕하세요. 리뷰를 읽다가 조금 놀랐던 것이 token mixing 방식에 대하여 기존의 attention 방식이 아닌 단순히 pooling 연산만으로 mixing한다는 것이 많이 놀랐습니다.
저자들이 pooling former를 제안한 것은 아니겠지만, 혹시 pooling을 통한 트랜스포머 방식이 기존의 attention 기반 트랜스포머와 비교하였을 때 정확도 측면에서도 더 뛰어나나요? 속도와 메모리 측면에서는 당연히 훨씬 더 좋을 것으로 보여지는데 성능이 잘 나오는지가 궁금하네요.
리뷰 중간에서 확인하신 그림에 나타나있듯, 실제로 attention 연산이나 MLP를 pooling만으로 대체하고 있습니다. 원본 논문에서 pooling에 대한 pseudo code를 보니 정말 nn.AvgPool2d() 함수만을 사용하고 있습니다.
원본 논문을 보니 ImageNet-1K에 대해서는 모델 사이즈가 유사한 ViT와 PoolFormer를 비교했을 때 PoolFormer가 param 개수가 3M 정도 적음에도 5.5% 더 높은 Top-1 accuracy를 보여주고 있습니다. 정리하자면 완전한 1대1 비교는 어렵지만, PoolFormer는 기존 ViT 또는 PVT에 비해 유사하거나 더욱 높은 성능을 보여주고 있습니다.
contribution이 강한거 같지 않다는 느낌은 저만 드나요? ㅋㅋ
Co2 Net이랑 비슷한 느낌이 드네요 같은 학회라 그런지
차기 논문 작업은 MR이랑 HD를 같이 하는 연구를 하실 계획이신가요?
넵 맞습니다. Moment-DETR이라는 베이스라인 방법론이 잡힌 후 나온 후속 연구 중 방법론이 가장 간단하기도 하고, task에 대한 특별한 모듈이나 loss를 두기보단 CO2-Net처럼 두 모달의 feature를 interaction하는 것 위주로 방법론이 설계되어 있습니다.
MR만을 수행하는 방법론도 물론 최근까지 연구되고 있지만, 대부분 위와 같이 DETR 기반 MR&HD task가더욱 활발히 연구되고 있어 저도 이를 따라가고자 합니다.
안녕하세요. 좋을 리뷰 감사합니다.
Transformer의 token mixer에 대해서 그리 크게 관심을 가지고 있지 않았는데 이 논문을 보니 이 부분을 어떻게 가져가는지가 중요하다는 생각이 드네요. 본 논문에서는 PoolFormer의 encoder 부분을 가져가서 사용했는데 사실 attention부분을 Pooling 연산으로 대체했을 때 어떻게해서 성능이 좋게 나오는지 잘 와닿지 않네요. attention을 사용해도 global한 정보를 얻을 수 있을거 같은데 이 논문의 모델에서 기본 transformer의 encoder를 사용했을 때와 PoolFormer의 encoder를 사용했을 때의 성능 차이가 많이 발생하나요?
감사합니다.
우선 베이스라인 성능부터 PoolFormer를 적용했기 때문에 정확히 MH-DETR 방법론에서 Poolformer만을 attention과 교체했을 때의 성능을 알기는 어렵습니다.
다만 표 6의 3번 실험은 기존 베이스라인 방법론 Moment-DETR의 encoder만 PoolFormer로 교체한 경우의 성능인데 대략 모든 지표에서 2~3%정도 올라갔다고 보시면 됩니다. 하지만 해당 성능은 하이퍼파라미터나 일부 구조 관점에서 정말 동일한지 확인되지 않은 성능이라 간접적으로 참고정도만 하시면 좋을 것 같습니다.