이번 리뷰는 Grounding-DINO와 SAM을 결합한 Grounded SAM이란 기법에 대한 기술 보고서에 대한 내용입니다. 해당 내용에서는 다양한 태스크들을 어떻게 수행했는지에 대한 내용들이 작성되어져 있습니다.
해당 리뷰를 읽으시는 분들은 갑자기 기술보고서를 리뷰해서 당황하시는 분들도 계실거라고 생각합니다. 해당 리뷰를 진행하게된 이유는 해당 기법이 이번에 선정된 산자부-그래스핑 과제에서 미학습 물체 탐지를 위해 설계한 방향 중 bbox와 semgmentation을 연결시킨 파이프라인과 동일한 구조를 가지고 있어 가져왔으며, 해당 기법이 이외에도 다른 방향으로 활용이 가능함을 알고 알리고자 들고 왔습니다.
Intro

Open-world에서의 visual perception 및 understanding은 자율 주행, 매니퓰레이터, 로봇 내비게이션과 같은 여러 어플링케이션들이 진정한 자율성을 갖추기 위해서는 필수적입니다. 이러한 애플리케이션들이 자율성을 갖추기 위해서는 open-world를 해석하고 상호 작용할 수 있는 정하고 다양성에 강인한 시각적 인식 모델이 필요합니다.
저자가 정리해주길 현 시점에서 open-world visual perception을 해결하기 위한 3가지 방법이 있다고 정리합니다.
1. Unified Model. 해당 기법들은 여러 태스크를 수행하는 데이터 셋으로 학습을 진행한 UNINEXT와 같은 모델을 예시를 들 수 있습니다. 이외에도 LLaVa, Qwen-VL과 같이 VQA에서 특화된 기법들이 존재합니다. 그러나 이러한 접근 방식들은 학습 데이터 셋에 따른 태스크에 제한적이라는 한계를 가집니다. 또한, task-specific models 대비 성능이 떨어지는 경우가 많이 발생한다고 합니다.
+ 구체적으로, encoder와 decoder 그리고 각 태스크에 따른 head들이 분리하여 적용이 불가능하다는 이야기입니다.
2. LLM as Controller. 대표적인 예시로 Visual ChatGPT, HuggingGPT들이 있으며, LLM을 활용해 다양한 태스크를 수행하기 위한 AI 모델들을 컨트롤하는 방법을 사용합니다. 즉, LLM의 언어적 이해 기능을 이용하여 필요한 시각적 태스크를 판단하고 이를 수행하기 위한 파이프라인을 구축해서 인지를 수행하는 방법에 해당합니다. 저자는 제안하는 기법이 속하는 3. ensemble foundation models 대비 LLM에 지나치게 종속적이고 개별적으로 단계별 시각적 추론을 보여주기 때문에 보다 효율적인 결합이 가능하다고 주장합니다.
3. Ensemble Foundation Models. 저자가 제안한 기법이 속하는 방법으로 특정 상황에 맞게 설계된 expert model을 공동으로 통합 적용하는 기법에 해당합니다. 다양한 모델들을 조립식으로 결합하기 때문에 유연성을 갖추고 있다는 점을 갖춘다고 합니다.
저자는 위와 같은 방법으로 opwn-world를 해결하기 위한 발전이 있었지만, 어플리케이션 관점에서 open-world를 지원 가능한 강력한 파이프라인이라고 하기에는 아직 부족하다고 합니다. 이러한 관점에서 저자는 Grounded SAM을 제안하였고 Ensemble Foundation Models 접근 방식으로 Grounding DINO와 같은 open-set detector model과 SAM과 같은 Promtable segmentation model을 통합하는 방법을 개척?했다고 합니다.
즉, open-set segmentation 문제를 open-set detection과 promptable segmentation라는 2가지 주용 구성 요소로 나눠 해결하는 방식을 제안하며 이러한 접근 방식은 다양한 expert model과 효율적으로 융합되어 포괄적이고 복잡한 open-world task를 처리하는 방법을 제시합니다.
Grounded SAM을 기반으로 다른 expert mode이자, open-set model을 쉽게 통합할 수 있습니다. 예를 들어, Recognize Anything(RAM)과 결합한 RAM-Grounded-SAM 모델은 텍스트 입력 없이도 이미지 내의 사물이나 객체를 자동으로 식별하고 분할할 수 있으므로 자동 어노테이션 작업에 활용 가능합니다. 유사한 자동 어노테이션 기능으로 BLIP과의 통합을 통해서도 가능합니다. 또한 아래에서 다룰 Grounded-SAM-SD 모델의 예처럼 Stable Diffusion의 Inpainting 기능과 Grounded SAM을 결합하면 매우 정확한 이미지 편집 작업을 실행할 수 있습니다.
Grounded SAM Playground
해당 섹션에서는 Grounded SAM을 기반으로 활용하여 보다 포괄적인 시각적 작업을 쉽게 수행할 수 있도록 다양한 영역의 expert model을 통합하는 방법을 보여줍니다.
Preliminary
먼저 Grounded SAM의 기본 구성 요소와 다른 도메인에서의 expert model에 대해서 설명합니다.
Segment Anything Model (SAM). SAM은 점, 상자 또는 텍스트와 같은 적절한 프롬프트가 있는 이미지의 모든 개체를 “잘라낼” 수 있는 개방형 분할 모델입니다. 1,100만 개 이상의 이미지와 11억 개 이상의 마스크를 학습했습니다. 강력한 제로샷 성능에도 불구하고 모델은 임의의 텍스트 입력을 기반으로 마스크된 개체를 식별할 수 없으며 일반적으로 실행하려면 점 또는 상자 프롬프트가 필요합니다.
Grounding DINO. Grounding DINO는 임의의 자유 형식 텍스트 프롬프트와 관련하여 모든 객체를 감지할 수 있는 open-set object detector입니다. 이 모델은 감지 데이터, 시각적 접지 데이터, 이미지-텍스트 쌍을 포함하여 천만 개가 넘는 이미지에 대해 훈련되었습니다. 이는 강력한 제로 샷 감지 성능을 가지고 있습니다. 그러나 입력으로 텍스트가 필요하며 해당 문구가 있는 상자만 감지할 수 있습니다.
OSX. OSX는 단안 이미지로부터 3D 인체 포즈, 손 제스처 및 얼굴 표정을 공동으로 추정하는 것을 목표로 하는 표현 전신 메쉬 복구를 위한 SOTA 모델입니다. 먼저 인간 상자를 감지하고 인간 상자를 자르고 크기를 조정한 다음 단일 사용자 메시 복구를 수행해야 합니다.
BLIP. BLIP은 비전 언어 이해와 생성 작업을 통합하는 vision-language model입니다. 캡션 모델은 어떤 이미지에서든 설명을 생성할 수 있습니다. 그러나 모델은 객체 감지 또는 분할과 같은 객체 수준 작업을 수행할 수 없습니다.
Recognize Anything Model (RAM). RAM은 입력 이미지에 대해 높은 정확도의 일반적인 범주를 인식할 수 있는 강력한 이미지 태깅 모델입니다. 그러나 RAM은 태그를 생성할 수만 있고 인식된 범주에 대한 정확한 상자와 마스크를 생성할 수는 없습니다.
Stable Diffusion. Stable Diffusion은 훈련 데이터의 학습된 분포에서 이미지를 샘플링하는 이미지 생성 모델입니다. 가장 널리 사용되는 응용 프로그램은 텍스트 프롬프트로 이미지를 생성하는 것입니다. 우리는 실험에서 인페인팅 변형을 사용합니다. 놀라운 생성 결과에도 불구하고 모델은 인식 또는 이해 작업을 수행할 수 없습니다.
ChatGPT & GPT-4. ChatGPT & GPT-4는 대화형 AI 에이전트 구축에 사용되는 GPT(Generative Pre-trained Transformer) 아키텍처를 사용하여 개발된 대규모 언어 모델입니다. 엄청난 양의 텍스트 데이터에 대해 훈련되었으며 사용자 입력에 대해 인간과 유사한 응답을 생성할 수 있습니다. 모델은 대화의 맥락을 이해하고 종종 인간의 응답과 구별할 수 없는 적절한 응답을 생성할 수 있습니다.
Grounded SAM: Open-Vocabulary Detection and Segmentation

사용자가 제공한 텍스트에 언급된 영역에 해당하는 이미지의 마스크를 결정하여 open-set segmentation과 같은 픽셀 수준의 시각 인지를 수행하는 것은 쉬운 영역이 아닙니다. 이는 주로 실제 세계를 표현하기 위한 학습 데이터를 수집하기 위해서는 한계가 존재하기 때문에 데이터 부족으로 이어지게 됩니다. 이와 대조적으로, open-set detection task은 주로 다음 두 가지 이유 때문에 더 다루기 쉽습니다.
첫째, 탐지 데이터의 어노테이션 비용이 segmenation에 비해 상대적으로 낮기 때문에 보다 고품질의 주석 데이터 수집이 가능합니다. 둘째, open-set detection에서는 정확한 픽셀 수준 개체 마스크 없이 주어진 텍스트를 기반으로 이미지에서 해당 개체 좌표를 식별하기만 하면 됩니다. 더 나아가 bbox를 프로픔트로 하고 bbox 위치에 대한 사전 지식을 활용하여 해당 객체의 mask를 예측하는 것이 텍스트를 기반으로 mask를 직접 예측하는 것보다 더 효율적이겠죠.
결과적으로 Grounded Pre-training및 SAM과 같은 성공적인 성과를 이룬 기법들에 영감을 받아 open-set foundation model을 결합하여 실제 세계의 복잡한 분할을 해결하는 것을 목표로 합니다.
입력 이미지와 텍스트 프롬프트가 주어지면 먼저 Grounding DINO를 사용하여 텍스트 정보를 조건으로 활용하여 이미지 내의 개체나 영역에 대한 정확한 bbox를 생성합니다. 이후 Grounding DINO를 통해 얻은 주석 상자 는 SAM이 정확한 마스크 주석을 생성하도록 하는 상자 프롬프트 역할을 합니다. 이 두 가지 강력한 전문가 모델의 기능을 활용하면 개방형 탐지 및 분할 작업을 더욱 쉽게 수행할 수 있습니다. fig 2와 같이 Grounded SAM은 기존 시나리오와 이외 시나리오 모두에서 사용자 입력을 기반으로 텍스트를 정확하게 감지하고 분할하는 결과를 보여줍니다.
RAM-Grounded-SAM: Automatic Dense Image Annotation

automatic image annotation system은 데이터 수동 어노테이션의 효율성을 높이고, 수작업으로 인한 비용을 절감하며, 자율 주행 시 실시간 장면 어노테이션 및 시각적 이해를 위한 정보를 제공하여 운전 안전성을 높이는 등 다양한 어플리케이션에서 활용이 가느앟빈다.. Grounded SAM에서는 Grounding DINO의 기능을 활용합니다. 임의의 카테고리 또는 캡션을 생성한 후 이미지 내의 항목과 자동으로 일치 시킵니다. 이러한 기반을 바탕으로 출력 결과(캡션 또는 태그)를 입력으로 사용하여 image-caption model(BLIP 등) 또는 image tagging(RAM 등)을 사용할 수 있습니다. Grounded SAM에 연결하고 각 인스턴스에 대해 정확한 상자와 마스크를 생성합니다. 이를 통해 전체 이미지에 대한 자동 라벨링이 가능해 자동화된 라벨링 시스템을 구현할 수 있습니다. fig 3과 같이, RAM-Grounded-SAM은 카테고리 예측을 자동으로 수행하고 다양한 시나리오에서 입력 이미지에 대한 세그멘테이션 결과를 보여줍니다.
Grounded-SAM-SD: Highly Accurate and Controllable Image Editin

이미지 생성 모델의 강력한 text-to-image 변환 기능을 Grounded SAM과 통합함으로써 prat-level, instance-level , semantic-level에서 세분화된 이미지 합성 기능을 지원합니다. fig 4에서 볼 수 있듯이 사용자는 이 파이프라인 내에서 bbox를 클릭하거나 그리는 등의 대화형 방법을 통해 정확한 마스크를 얻을 수 있습니다. 또한 사용자는 텍스트 프롬프트와 결합된 grounding 기능을 활용하여 해당 관심 영역을 자동으로 찾을 수 있습니다. 이러한 기반을 바탕으로 이미지 생성 모델의 추가 기능을 사용하면 이미지 표현 수정, 객체 교체, 해당 영역 제거 등을 포함하여 매우 정확하고 제어된 이미지 조작을 달성할 수 있습니다. 데이터 부족이 발생하는 다운스트림 시나리오에서 해당 기능은 새로운 데이터를 생성하여 모델 교육을 위한 데이터 요구 사항을 해결 가능 할 것으로 보입니다.
Grounded-SAM-OSX: Promptable Human Motion Analysis

이전의 expressive whole-body mesh recovery는 먼저 모든(instance-agnostic) human bbox 감지한 다음 한 사람의 메쉬 복구를 수행합니다. 즉, 이전 기법에서는 먼저 대상 인물을 탐지하고 분석할 대상 사람을 지정해야 합니다. 그러나 기존의 human detector는 서로 다른 인스턴스(예: “분홍색 옷을 입은 사람”을 분석하도록 지정)를 구별할 수 없으므로 세밀한 인간 동작 분석이 어렵습니다. fig 5에서 볼 수 있듯이 Grounded SAM과 OSX 모델을 통합하여 promptable (instance-specific) whole-body human detection and mesh recovery를 달성함으로써 신속한 인간 모션 분석 시스템을 실현할 수 있습니다. 구체적인 방법으로 이미지 내 특정 인물을 표현하는 텍스트가 주어지면 먼저 Grounded SAM을 사용하여 정확한 특정 인간 상자를 생성합니다. 그런 다음 OSX를 사용하여 nstance-specific human mesh를 추정하여 프로세스를 완료합니다.
Effectiveness of Grounded SAM
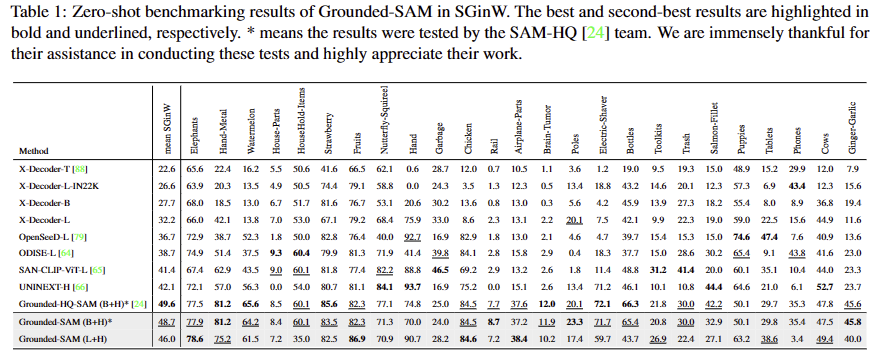
Tab 1은 zero-shot Sgemntation에 대한 2023 CVPR workshop 수행 결과로 데이터 셋 Segmentation in the Wild (SGinW)에서의 평가 결과 입니다. 다른 접근 방법 대비 7% 넘는 성능 향상을 보여주고 있습니다.
Conclusion
다양한 비전 작업을 수행하기 위해 다양한 전문가 모델의 집합을 활용하는 Grounded SAM과 그 확장의 강점은 다음과 같이 요약될 수 있습니다. 첫째, 다양한 expert models을 조합하여 수행 가능한 태스크들을 원활하게 확장할 수 있습니다. 둘째, model assembling pipeline은 작업을 여러 하위 항목으로 분해하여 더 설명하기 쉽습니다. 최종 결과에 대한 추론 과정을 얻기 위해 각 단계의 출력을 관찰할 수 있습니다. 마지막으로, 다양한 expert models을 쉽게 결합 가능 하기 때문에 다른 분야의 태스크들과 쉽게 결합이 가능하기에 잠재적 확장 가능성을 가지고 있습니다.
저자는 이후 연구로, 어노테이션 정보와 모델 학습 사이에 closed loop 형태를 구축하는 것을 목표로 한다고 합니다. 정리하자면, 모델이 자체적으로 오토 라벨링을 수행하고 이를 기반으로 학습을 진행하는 형태를 구축하는 것을 의미합니다. 기존에 있던 파이프라인과는 다르게 여러 단계의 추론 과정 중 관찰된 결과물을 토대로 중간 점검이 가능하며, 이를 기반으로 데이터를 수정하거나 문제가 발생한 모델들을 미세 조정이 가능하다는 점입니다. 이외에도 LLM을 활용하는 것이 목표라고 합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
본래 박스나 텍스트 정보를 프롬프트로 제공해야하는 SAM에 Grounding DINO를 사용하여 생성한 보다 정확한 bbox를 프롬프트 정보로 SAM에게 제공함으로써 SAM의 성능을 더 향상시켜주는 것을 Grounded SAM이라고 이해하였습니다. 그런데 원래 SAM은 detection이 아닌 segmentation가 가능하기 때문에 Grounded SAM으로 detection이 가능하려면 추가적인 detection 모듈이 모델에 존재해야 하는 것이 맞을까요 . . ?
감사합니다.
SAM은 의미론적인 정보를 직접적으로 추론하지 못합니다.
Grounded SAM은 이러한 한계를 극복하면서 예측 성능을 향상 시키기 위해 Grounding DINO의 예측 정보를 프롬프트 + 라벨로 활용합니다.
걍 Grounding DINO의 아웃풋을 SAM에 태운 것이 끝임
안녕하세요 리뷰 잘 봤습니다.
preliminary만 최근 연구 동향에 대해서 간략하게 맥을 짚을 수 있었네요.
헷갈리는 부분이 있는데 제안하는 Grounded SAM은 Grounded DINO와 SAM을 결합하는 과정에서 별다른 학습을 요구하지는 않는 건가요?
사전학습 데이터의 규모와 학습 비용 (GPU) 개수에 대한 내용이 궁금해서 질문 드립니다.
음… 해당 리뷰한 논문은 연구 논문이라기 보단 어떻게 보면 기술 보고서에 적합한 것 같습니다.
추가적인 학습을 진행한 것은 아니고, FM인 grounding DINO와 SAM을 결합한 기법이고 추가적으로 이를 활용해 어떤 태스크까지 확장 가능한지를 보인 논문으로 보면 될 것 같습니다.
즉, 사전 학습 쪽으로 연구 안해도 이 정도로 대단한 것들 연구/개발 할 수 있다! 라는 것을 보이는 논문이라고 생각해요.
사전 학습에 대한 정보는 Grounding DINO와 SAM을 리뷰한 논문들을 참고하시면 좋을 것같아요.