안녕하세요. 오늘 다룰 논문은 ICCV 2023의 Unified Coarse-to-Fine Alignment for Video-Text Retrieval(UCoFIA)입니다. CLIP 기반의 text-video task에서 SOTA를 달성했었던 모델입니다.
Abstract
Moment Retrieval에서 흔히 사용되는 방법 중 하나는 CLIP과 같은 거대 사전학습 모델로 시각 정보와 텍스트 정보를 활용하는 방법입니다. 하지만 텍스트 쿼리에 해당하는 올바른 영상을 반환하는 것은 high-level, low-level의 시각 정보를 추론하고 어떻게 텍스트 쿼리에 관련되는 지를 추론할 수 있는 능력을 필요로 하기에 어려움이 존재합니다. 따라서 저자는 다양한 다양한 granularity(coarse, fine)에서 유사성을 계산하는 Unified Coarse-to-fine Alignment model 즉, UCoFIA를 제안합니다. UCoFIA는 관련없는 시각 단서들을 제거하기 위하여 Interactivesimility Aggretion(ISA) 모듈을 여러 granularity에서 유사성을 계산합니다. 계산한 유사성 점수는 Sinkhorn-Knopp 알고리즘을 적용하여 정규화시킴으로 과대적합, 과소적합을 피할 수 있다고합니다. 결국 UCoFIA는 기존의 CLIP을 활용하여 텍스트와 이미지의 특성을 활용하여 fusion하는 기존 모델이 하나의 granularity에만 집중하는 것을 ISA모듈과 Sinkhorn-Knopp 알고리즘을 통해 여러 granularity에 잘 적용할 수 있게하여 기존 CLIP 기반 방법론들보다 좋은 성능을 내는 것을 강조하고 있습니다.
Introduction
서로 다른 두 도메인의 정보를 cross-modal alignment를 활용하는 방법 특히 CLIP과 같은 거대 image-text 사전학습 모델을 활용하는 방법은 좋은 성능을 보이며 CLIP을 비디오 task에서 잘 활용할 수 있는 방법들데 대한 연구들이 많이 진행되고 있습니다. 하지만, CLIP은 이미지와 텍스트에 대한 사전학습 모델로 비디오의 temporal 정보를 담고 있지 못합니다. 따라서 기존의 연구들은 CLIP에서 temporal fusion을 추가하는 것으로 temporal 정보를 담아 CLIP을 비디오에서 활용합니다. 저자는 이러한 연구들로 인상적인 결과를 얻긴 했지만, 이러한 coarse-grained alignmnet는 high-level 시각 정보만을 활용한다는 한계를 지적합니다.

위의 Figure 1. 은 저자가 coarse-grained와 fine-grained alignment의 문제점을 지적하며 UCoFIA가 coarse-grained와 fine-grained를 같이 활용하는 것으로 각 alignment의 단점을 극복했음을 보여주는 figure입니다. 구체적으로 fine-grained의 경우 쿼리의 ‘microphone’과 같은 디테일한 정보는 잘 잡지만, ‘stage with huge audience’와 같은 high-level clues를 파악하지 못하기에 마이크가 포함된 부분을 반환하고, coarse-grained는 반대로 ‘microphone’의 디테일한 정보를 놓치는 모습을 보여줍니다. 따라서 저자는 이러한 coarse-grained와 fine-grained의 장점을 잘 활용할 수 있는 방법을 연구했고 그 결과로 UCoFIA를 제안한다고 강조합니다.
UCoFIA의 approach는 간단하게 정리하면 먼저 (1) coarse-grained alignment를 위해 전체 비디오와 쿼리를 align한 후에 (2) 비디오의 프레임별로 쿼리와 align하는 것으로 frame-sentence align하고 (3)이를 바탕으로 fine-grained alignment를 진행합니다. 하지만, 이러한 다차원적인 정보는 쿼리에 해당하는 구간에 필요하지 않은 정보도 제공하는 문제가 있다고 밝히며, 저자는 이러한 문제를 해결하기 위해서 ISA 모듈을 활용합니다. ISA모듈은 모달 간 유사성을 통해 각 granularity의 유사성 점수를 구하기에 위의 문제를 해결하는 데에 도움을 줍니다. 추가로 기존의 연구들이 CLIP을 활용하며 temporal 정보를 제대로 활용하지 못했는데, 저자는 자신의 UCoFIA가 비디오의 temporal 정보 또한 잘 잡아낸다고 강조합니다.
저자는 서로 다른 비디오 간의 유사성 점수가 불균형하다는 것을 실험적으로 발견하고 이를 수정함으로 성능을 개선시키면서 일반화 성능을 올렸다고 밝힙니다. 구체적으로 설명하면, 가끔 특정 비디오와 모든 텍스트 간의 유사성의 합이 다른 비디오와의 유사성의 합보다 훨씬 클 때가 있다고 합니다. 이러한 경향은 비디오가 과도하게 표현(over-represented)되고 있다는 것을 의미하고 다른 비디오가 반환 될 확률을 낮춘다고 합니다. 이를 해결하기 위해 Sinkhorn-Knopp 알고리즘을 도입하여 정규화시켰습니다.
Methodology
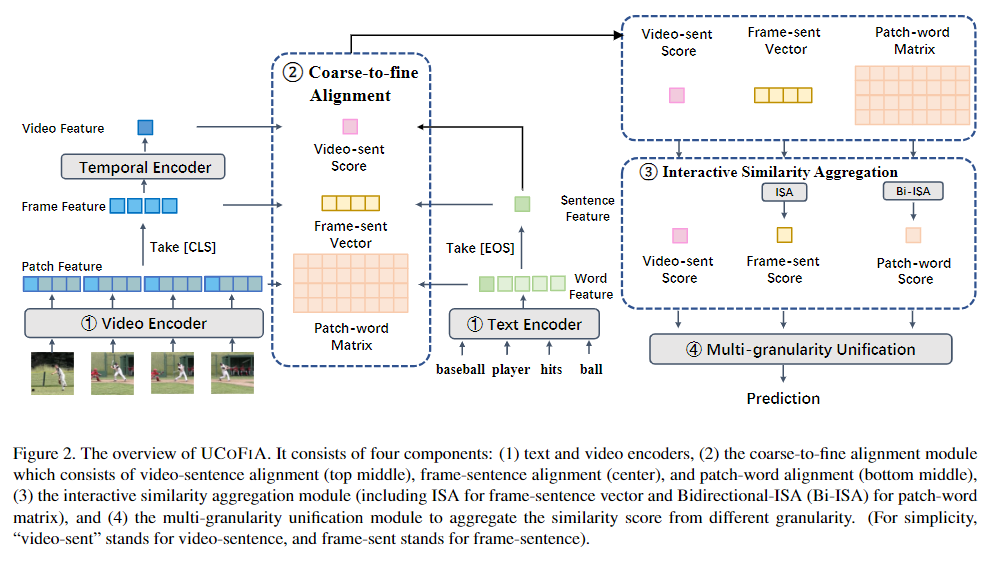
UCoFIA의 구조는 Figure 2. 를 통해 확인할 수 있습니다. (1) 텍스트 인코더와 비디오 인코더 (2) coarse-to-fine alignment 모듈 (3) Interactive Similarity Aggregation(ISA) 모듈 (4) multi-granularity unification 모듈 (w/ Sinkhorn-Knopp 알고리즘) 총 4개의 구성요소가 존재합니다.
Feature Extraction
텍스트 쿼리 T가 주어졌을 때, [EOS] 토큰을 추가합니다. CLIP의 텍스트 인코더를 활용하여 텍스트 특징을 추출하고, 추가한 [EOS] 토큰은 문장의 representation으로 활용합니다. 비디오 특징은 ViT를 활용한 CLIP의 이미지 인코더를 사용합니다. 이미지의 패치들 앞에 [CLS] 토큰을 추가하여 이미지의 representation을 나타낼 수 있게 하고 각 이미지들의 [CLS] 토큰들을 모아 frame feature로 사용합니다. 여기서 CLIP의 이미지 인코터는 temporal 정보를 담고 있지 못하기에 temporal encoder를 추가하여 각 프레임사이의 temporal 정보를 담은 video feature를 얻습니다.
정리하면 영상으로부터는 각 프레임의 이미지 패치 특징, 프레임의 특징, 비디오의 특징을 추출하고, 텍스트로부터는 각 토큰의 특징, 문장의 특징을 추출합니다.
Coarse-to-fine Alignment
추출된 특징들을 활용하여 먼저 비디오 특징과 문장 특징을 align시킵니다. 이때는 cosine similarity를 사용하여 비디오-문장 유사성 점수를 계산합니다.
다음은 프레임 특징과 문장 특징을 align시키는데, 프레임 특징의 각 행과 문장 사이의 cosine similarity를 사용하여 프레임-문장 유사성 점수를 계산합니다.
마지막으로 패치-단어 alignment입니다. 디테일한 정보를 잘 포착하기 위한 fine-grained alignment를 위하여 저자는 low-level 특징도 포착해야한다고 주장하며 이미지 패치와 문장의 단어들을 align합니다. 하지만, 모든 패치를 단어에 맞춰 정렬하는 것은 중복이 많이 되기 때문에 비효율적입니다. 따라서 MLP 기반의 패치 선택 모듈을 사용하여 프레임, 비디오의 특징에 따라 top-K 개의 핵심 패치를 선택하고 선택한 패치들로 단어들 사이의 유사성을 계산합니다.
Interactive Similarity Aggregation
정렬을 시키는 과정에서 모든 조합을 확인하게 되면 높은 중복성으로 인해 유사성 벡터 내 관련없는 정보들로 방해를 받기 때문에 정확히 대응되는 정렬이 어려울 수 있습니다. 기존 방법에서는 관련 없는 정보들의 영향을 줄이기 위해 소프트맥스 기반의 방법을 사용합니다. 하지만 소프트맥스 함수는 입력 특성 간의 정보를 확인하지 못합니다. 무슨 뜻이냐면 소프트맥스는 지수곱 연산으로 연관성이 적은 정보들에 대한 가중치를 줄이는 작업을 수행할 수 있지만, 프레임-문장의 정렬을 진행하는 동안에는 비디오-문장의 정보를 무시하기에 결과적으로 서로 다른 프레임과의 상호작용을 무시하고 관련성이 있는 정보를 관련성이 없다고 판단할 수 있습니다. 따라서, 저자는 ISA 모듈을 활용하여 이 문제를 해결했고, ISA의 모듈의 구조는 밑의 Figure 3. 와 같습니다.
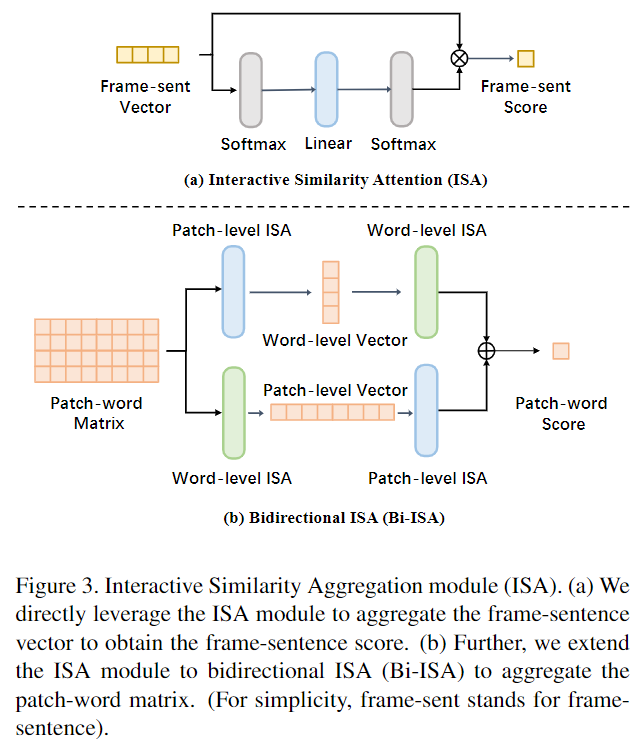
ISA 모듈의 아이디어는 서로 다른 유사성의 가중치를 계산하는 동시에 서로 다른 모드 간의 관련성도 고려하는 것입니다. 먼저 유사성 벡터에 소프트맥스를 적용하여 cross-modal relevance를 계산하고 서로 다른 기능 간의 상호작용을 위해 linear layer를 추가합니다. 마지막으로 유사성 벡터의 최종 가중치를 얻기 위해 소프트맥스를 한번 더 적용시킵니다. ISA 모듈은 유사성 벡터를 집합시키면서 동시에 관련있는 특징에 집중합니다. 특징의 차원과 상관없이 ISA 모듈은 서로 다른 graunlarity를 다룰 수 있습니다. 따라서 저자는 패치-단어 사이의 유사성 점수 집합을 구하기 위해서도 ISA 모듈을 활용하기 위해 Bidirectiounal ISA(이하 Bi-ISA)를 제안합니다. Bi-ISA는 패치 단어 행렬을 하나의 벡터로 flatten 시킨 후에 ISA 모듈을 적용하는 것입니다. 하지만 모달리티의 차이로 인해 비디오와 텍스트의 상호작용을 모델링하는 것은 쉬운일이 아닙니다. 따라서 유사성 행렬의 각 행 혹은 열로 분리한 후에 ISA 모듈을 적용하는 대안이 있습니다. 그런 다음 각 벡터의 유사성 점수를 다른 유사성 벡터로 집계하고 다른 ISA 모듈을 적용하는 것으로 패치-단어 점수를 얻습니다. 이러한 방식으로 모델링하는 것이 더 나은 유사성 집합을 제공합니다. 저자는 패치 와 단어의 모델링 순서를 어떻게 하는 것이 더 좋은지를 실험했고 경험적으로 결국 두가지 순서를 모두 고려하는 Bi-ISA 모듈이 제일 좋다고 설명합니다. 해당 실험은 밑의 Ablation Study를 통해 확인할 수 있습니다.
Unifying Coarse and Fine-grained Alignments
설명을 위해 하나의 비디오, 쿼리 쌍을 사용했지만, G 비디오와 H 쿼리에 대해 retrieval을 수행할때, 모든 가능한 조합에 대해 유사성을 계산하고 이를 정렬할 수 있어야합니다. 일반적인 방법은 서로 다른 유사성에 대한 평균을 계산하는 것이지만, 저자는 서로 다른 비디오의 점수가 매우 불균형하다는 것을 발견했다고 밝히며 유사성을 합산하여 집계하기 전에 이를 정규화시켜주는 것으로 더 나은 결과를 얻을 수 있다는 것을 경험적으로 발견했습니다. 때로는 특정 비디오, 쿼리의 조합의 유사성이 과도하게 높아 다른 영상이 선택될 가능성이 낮아지는 문제가 생깁니다. 이 문제를 해결하기 위하여 유사성 행렬의 크기를 조정하는 것으로 모든 비디오의 유사성을 정규화합니다. 한가지 접근 방식은 유사성 행렬에 소프트맥스를 적용하는 것이지만, 모든 쿼리와 비디오를 즉시에 확보해야하기에 테스트 단계에서는 적합하지 않습니다.
따라서 저자는 소프트맥스가 아닌 Sinkhorn-Knopp 알고리즘을 활용하여 불균형을 수정하는 방법을 채택합니다.

Sinkhorn-Knopp 알고리즘은 각 granularity에 대한 유사성 점수를 정규화하고 서로 다른 비디오에 대한 marginal 유사성(하나의 특정 비디오와 모든 텍스트 간의 검색 유사도의 합)이 거의 동일한지 확인합니다. marginal 유사성은 모든 텍스트와의 유사성의 합이기에 모든 비디오의 marginal 유사성이 비슷하게 정규화 해 맞춰주는 것으로 특정 비디오에 과대적합 혹은 과소적합되는 것을 방지하는 알고리즘입니다.
Sinkhorn-Knopp 알고리즘에서 S는 유사성 점수를 의미하고 a는 비디오의 편향을 의미합니다. n_itter는 반복회수를 의미하고 UCoFIA에서는 4번의 반복을 한다고 밝힙니다. 위 알고리즘을 통해 a를 구하고 a를 통해 유사성 행렬을 재스케일링하여 모든 비디오의 marginal 유사성을 정규화합니다.
각 비디오의 marginal 유사성(모든 비디오의 유사성 점수의 합) 값이 들쭉날쭉하지 않고 일정한 값으로 어느정도 유지해 일반화 성능을 갖게하는 방법입니다. Sinkhorn-Knopp 알고리즘이 정확히 어떻게 작동하는지는 잘 모르겠지만, 최적화시켜서 혼자 튀는 값 없이 모두 일정한 값으로 조정하는 정규화 알고리즘이라고 이해하시고 넘어가면 될 것 같습니다.
Experiment
평가지표는 R@1, R@5, MeanRank(MnR)를 사용합니다. R@n은 모델이 쿼리에 해당하는 구간을 예측해서 상위 n개의 후보군 중에 올바른 구간이 포함될 확률입니다. MnR은 올바른 구간이 평균적으로 몇번째 후보군인지를 나타내는 평가지표로 낮을 수록 좋은 성능을 내는 모델이라고 할 수 있습니다.
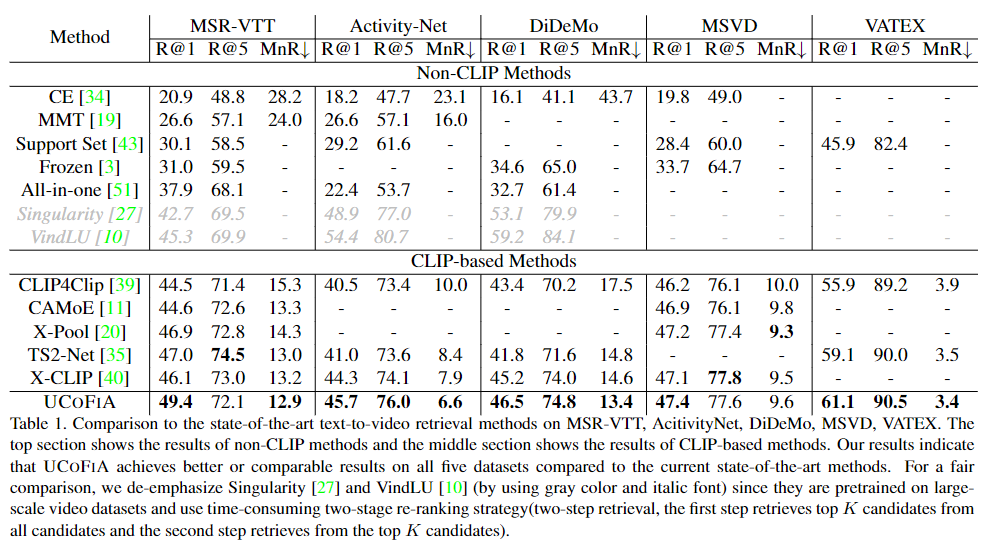
Table 1. 은 text-to-video retrieval 성능을 보여주는 표입니다. UCoFIA는 텍스트와 비디오를 유사성점수로 정렬하고 align시키기 때문에 video-to-text retrieval도 수행할 수 있습니다.
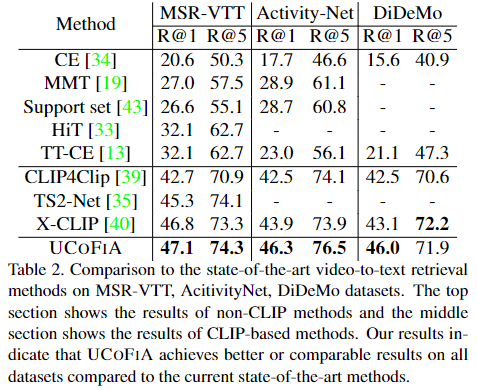
Table 2. 는 video-to-text의 결과를 보여줍니다. 두 가지 task 모두 CLIP-based 모델 중에 가장 좋은 성능을 보여줍니다.
Ablation Study
ablation study에서 저자는 총 4가지를 실험합니다. (1) 여러 alignment schemes (2) fine-grained alignment 방법 (3) 서로 다른 유사성 집계 방법 (4) unification 모듈의 효율성을 실험합니다.
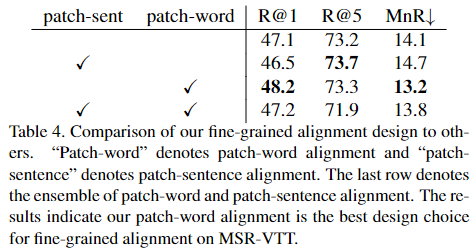
Table 4. 는 fine-grained alignment의 방법을 비교합니다.
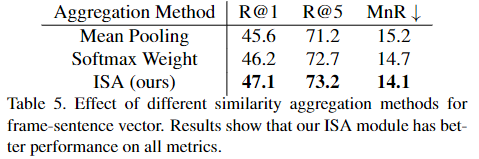
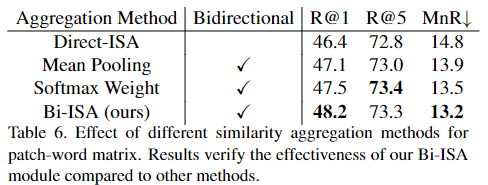
Table 5. 와 6. 은 ISA 모듈의 효과성을 보여주는 표입니다. 기본의 다른 Mean Pooling 혹은 소프트맥스의 방법론 보다 ISA 모듈을 사용하는 것이 더 좋은 성능을 보여주는 것을 확인할 수 있습니다.

Table 7. 은 Sinkhorn-Knopp 알고리즘을 통해 정규화를 하는 것이 정규화를 하지 않는 것보다 더 좋다는 것을 보여주는 표입니다.

Figure 4. 는 정성적 결과로 ISA 모듈이 소프트맥스만을 사용하는 것보다 더 좋다는 것을 보여줍니다.
Conclusion
저자는 여러 granularity를 통합하여 cross-modal 유사성을 구하는 UCoFIA를 제안하여 CLIP 기반의 방법론들 중에 SOTA를 달성했습니다. coarse-grained 보다 fine-grained가 더 디테일한 정보를 담고 있기에 무조건 더 좋을 것이라고 생각했지만, 논문에서는 fine-grained 혹은 coarse-grained 중 하나만을 고려하는 것은 좋은 성능을 낼 수 없다는 것을 지적하며 두 granularity를 모두 통합하는 UCoFIA를 제안합니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
우선 Abstract에서 작성하신 내용 중, Video-Text Retrieval과 Moment Retrieval이 같은 task라는 내용은 논문에 실제로 적혀있던 내용인가요? 아니라는 것은 알고 계실 것 같은데 혼동하신건지 잘못 작성하신 것 같습니다.
저자들이 SK Norm을 적용해준 이유가 특정 비디오들이 과하게 represenation 되는 현상을 발견했기 때문이라고 해주셨는데, 그렇게 과하게 represenation 되는 특정 비디오들의 특성을 밝힌 것이 있나요? 어떤 경우에 그런 과한 represenation이 발생하는 것인지 궁금합니다.
안녕하세요 현우님 좋은 댓글 감사합니다.
우선 Video-Text Retrieval은 Moment Retrieval과 다른 task로 비디오와 텍스트를 다루는 여러 task들이 CLIP과 같은 거대 사전학습 모델을 사용한다는 것을 언급하는 부분에서 오류가 있었습니다. 본문 내용은 수정했습니다.
저자는 서로 다른 영상에서 유사성 점수가 불균형하다는 것을 발견했고, 특히 특정 한 영상과 다른 모든 텍스트와의 유사성 점수가 다른 영상들에 비해 높은 것을 발견했고, 이것을 과도하게 representation되는 비디오라고하며 이를 전처리해주는 것이 성능 개선에 도움이 된다고 언급하고 있습니다. 하지만, 어떠한 영상이 그러한 경향을 보여주는 지에 대해서는 설명하지 않습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
Coarse-to-fine Alignment의 부분에서 추출된 특징들을 활용하여 비디오 특징과 문장 특징을 align시킬때 cosine similarity를 사용하여 비디오-문장 유사성 점수를 계산한다고 하셨는데 그림에서처럼 baseball과 관련된 video가 encoder를 통해 나온 값과 baseball이란 단어가 text encoder를 통해 나온 값이 유사한 값을 띄나요?
안녕하세요 정의철 연구원님 좋은 댓글 감사합니다.
네 맞습니다. 텍스트와 영상에서의 텍스트와 align하는 구간의 유사성 점수가 활성화되어 텍스트와 맞지 않는 구간보다 높은 값을 갖게 됩니다.
감사합니다.