안녕하세요. 이번 주 X-Review에서는 23년도 CVPR에 게재된 <Query-Dependent Video Representation for Moment Retrieval and Highlight Detection>이라는 논문을 소개해드리겠습다. 성균관대 허재필 교수님 연구실에서 나온 논문이며, 해당 한국인 저자분이 본 task에 대해 아주 선도적인 연구를 진행하고있어 주목받고 있는 상황입니다. 깃허브를 보니 최근까지도 활발하게 코드를 관리해주고 있던데, 책임감 있는 모습이 존경스럽네요.
비디오 분야의 Grounding 또는 Moment Retrieval이라 불리는 task에도 DETR이 핵심 방법론으로 자리잡았습니다. 21년도 NeurIPS에 QVHighlights라는 데이터셋이 공개되었는데, 해당 데이터셋은 Moment Retrieval과 Highlight Detection을 함께 수행할 수 있도록 라벨링되어있습니다. 이러한 데이터셋을 공개하며 Moment-DETR이라는 나이브하지만 강력한 베이스라인도 함께 제안하였는데, 그 이후 이번에 리뷰하고자 하는 논문인 QD-DETR 외에도 EaTR, MH-DETR, CG-DETR, BAM-DETR, TR-DETR 등이 쏟아져 나오며 DETR 기반 방법론들이 연구의 주축이 되어버린 상황입니다.
아무튼 저도 Grounding이라는 task에 관심이 많고, 관련 논문도 한 편 쓰고자 마음먹었으니 이러한 흐름을 놓칠 수 없는 상황이 되었네요. 빠르게 follow-up하며 이를 X-Review로 잘 기록해두어 보겠습니다. DETR을 이번에 처음 접하게되어 그런 것인지 아직까지는 방법론들이 낯설고 코드가 복잡하게 느껴지네요.

리뷰 시작하겠습니다.
1. Introduction
우선 방법론과 저자의 이야기를 들어보기 전 task에 대해 간단히 소개하겠습니다. 제목에서도 알 수 있듯 최근들어 Temporal Sentence Grounding in Videos (TSGV) 또는 Moment Retrieval (MR)이라 불리는 task는, Moment-DETR 방법론과 QVHighlights 데이터셋 등장 이후 Highlight Detection (HD)과 함께 연구되고 있습니다. 편의를 위해 각각 MR, HD라고 칭하겠습니다. 두 task는 텍스트 쿼리와 비디오를 활용한다는 공통점이 있습니다.
첫 번째로, MR은 비디오 내에서 텍스트 쿼리가 설명하고 있는 구간 (시작 지점, 끝 지점) 또는 (중간 지점, 구간 너비)를 출력으로 내뱉습니다. 두 번째로 HD은 원래 아무런 쿼리도 없이 비디오에서 하이라이트가 될 법한 구간(실제 사람이 highlight라고 생각되는 프레임에 대해 annotation을 수행하지만 highlight에 대한 명확한 정의가 어려운 것이 사실입니다.)을 찾아내는 task이지만, 여기서 이야기하는 HD는 텍스트 쿼리가 함께 주어진 상황에서의 HD를 의미합니다. 텍스트 쿼리가 함께 주어지고 해당 쿼리에 관련된 하이라이트를 뽑아내는 것이니 찾아야 하는 목표가 조금 더 명확해지겠죠. 모델은 비디오를 작게 자른 단위인 clip 별 saliency score를 계산하는데, 해당 score에 기반하여 비디오 내 텍스트 기준 하이라이트를 산정하여 하이라이트 라벨과 비교하여 평가를 진행합니다.
MR과 HD 모두를 동시에 평가할 수 있도록 라벨링된 최초의 데이터셋이 QVHighlights이고, 이 데이터셋을 제안한 연구진이 Moment-DETR이라는 DETR 기반 모델을 함께 제안하며 이후로 관련 연구가 진행되고 있는 상황인 것입니다. Moment-DETR은 Object Detection을 Transformer로 수행하는 DETR 방법론에 영감을 받아 텍스트 토큰과 비디오 토큰을 concat하여 한 번에 DETR에 입력하는 방식으로 동작하고, 그 이후 제안된 UMT라는 또 다른 방법론은 비디오, 오디오 토큰은 encoder의 입력, 텍스트는 decoder의 입력으로 함께 활용해 두 task를 수행하고 있었습니다. 이러한 연구 흐름 속에서 저자는, 기존 방법론들이 텍스트 쿼리의 역할을 중요하게 생각하고 있지 않다고 이야기합니다.
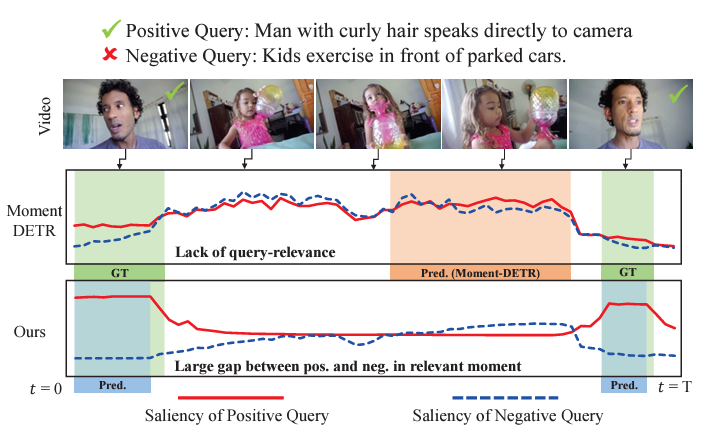
그림 1을 통해 저자가 무엇을 이야기하는 것인지 볼 수 있습니다. 우선 비디오와 positive query, negative query가 보이고 positive query에 상응하는 비디오 구간에 초록색 체크 표시가 되어있는 것을 볼 수 있습니다. 의미를 따져보았을 때 초록색 체크 표시 된 구간에서 실제로 positive query의 내용에 해당하는 곱슬 머리의 남성이 카메라를 보며 이야기하고 있는 모습이 보이네요. 그리고 아래는 모델이 예측한 쿼리에 대한 비디오 구간 별 saliency score 그래프입니다. 저희가 기대하는 것은, 모델이 positive query에 대한 상응 구간에서는 높은 score를 내뱉고 negative query에 대해서는 비디오의 어느 구간도 높은 score를 내뱉지 않는 것입니다.
이를 바탕으로 saliency score 추세를 살펴보겠습니다. 계속 언급했던 기존 방법론 Moment-DETR은 엉뚱한 구간에서 높은 saliency score를 내뱉고 있습니다. 이 자체로도 문제가 되지만 저자가 이야기하는 더 큰 문제는, 아예 상응 구간이 존재하지 않는 negative query에 대해서도 positive query와 비슷한 경향의 score를 뽑아내고 있다는 점입니다. 본 모델이 수행하는 MR과 HD 모두 텍스트 쿼리를 기준으로 score가 생성되고 구간을 만들어내야 하기 때문에 텍스트 쿼리의 의미를 잘 파악하는 것이 중요한데, 어떤 텍스트 쿼리이든 상관없이 유사한 경향의 score를 내뱉고 있는 기존 방법론은 각 모달 정보에 대한 이해와 이들의 상호작용에 대한 이해를 바탕으로 예측을 수행하고 있다고 보기 어렵겠죠.
결과적으로 저자의 방법론을 보면 실제 상응 구간에서만 굉장히 높은 saliency score를 만들어내고 있고, 앞서 정의한 문제점인 negative query에 대한 score를 보면 쿼리에 따라 negative는 실제 0에 가까운, negative다운 saliency score를 만들어내고 있음을 볼 수 있습니다. 기존 방법론과 다르게 텍스트 쿼리에 대한 모델링을 중요시하는 저자의 방법론을 Query-Dependent DETR (QD-DETR)이라 부르겠습니다.
텍스트 쿼리의 모델링을 중요시한다는 것이 어떤 것을 의미하는지 알아보아야겠죠. 결론적으로 QD-DETR의 목적은 query-dependent한 video representation을 만들어내는 것입니다. 높은 유사도를 갖는 쿼리에 대해서는 비디오의 saliency score가 확실히 높고, 낮은 유사도를 갖는 쿼리에 대해서는 반대가 되도록 만드는 것이 가장 핵심적인 목표입니다. 이를 달성하려면 쿼리를 지금보다 좀 더 명시적으로 모델링해주어야 할 것입니다.
결국 3가지 contribution이 존재하는데, 첫 번째로 기존에는 인코더 단에서 텍스트-비디오 토큰을 concat한 후 self-attention을 수행했다면 QD-DETR에서는 명시적인 두 모달의 상호작용을 모델링하기 위해 바로 cross-attention을 수행해줍니다. 첫 번째는 feature-level에서 비디오 feature에 텍스트의 정보를 주입해주는 느낌이었습니다. 두 번째 contribution은 이보다 좀 더 명시적으로 텍스트 쿼리를 활용하는데, negative pair에 대한 saliency score는 0으로 가도록 만들어주는 loss를 설계합니다. 마지막 세 번째로, 달라지는 비디오와 텍스트 쿼리에 따라 dynamic한, 또는 adaptive한 saliency score를 만들어낼 수 있도록 saliency token을 도입합니다.
각 component들이 MR과 HD에서 큰 성능 향상을 일으켰는데, 이제 자세한 방법론 내용을 하나씩 알아보겠습니다
2. Query-Dependent DETR
2.0 Notation
먼저 notation을 정리하겠습니다. 사전학습된 비디오와 텍스트 인코더로부터 각각의 feature \{v_{1}, \cdots{}, v_{L}\}, \{t_{1}, \cdots{}, t_{N}\}을 추출합니다. 비디오를 나눈 단위인 clip의 개수와 문장 내 존재하는 단어의 개수는 각각 L, N이라 볼 수 있습니다. MR의 목적은 두 모달의 feature를 입력받아 상응 구간의 중심점 m_{c}와 너비 m_{\sigma{}}를 얻는 것이고, HD를 위해서는 동일한 입력을 받아 saliency score \{s_{1}, \cdots{}, s_{L}\}을 얻는 것이 목적입니다.
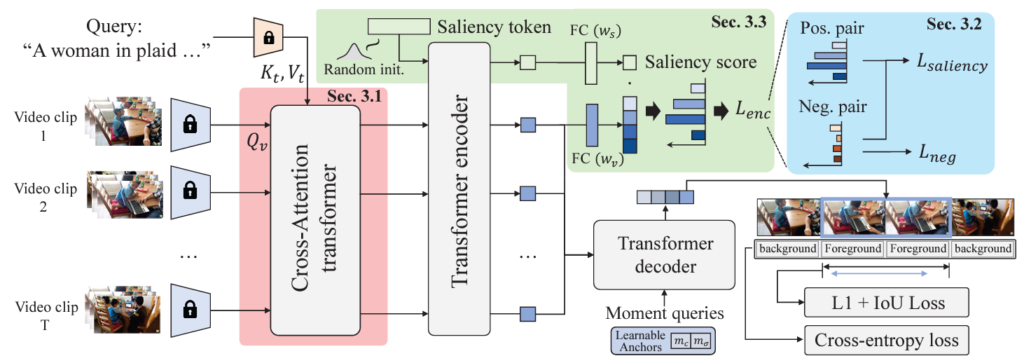
위 그림 2를 통해 QD-DETR의 전반적 구조를 살펴볼 수 있습니다. 이제부터 각 모듈에 대해 하나씩 알아보겠습니다.
2.1 Cross-Attentive Transformer Encoder
본 절에서 저자는 텍스트 쿼리와의 혼동을 방지하고자 cross-attention layer에 들어가는 Query를 query와 같이 표현하였는데, 저도 이를 따르겠습니다. 기존 방법론의 인코딩은 Moment-DETR의 경우 단순 두 모달의 token concat 후 self-attention이거나 UMT의 경우 decoder에서 text token을 보게되는 방식이었습니다. 비디오의 feature가 text query의 영향을 받는다고 보긴 어려운 것입니다. QD-DETR에서는 feature가 기술되는 과정 중 텍스트 쿼리의 영향력을 기존보다 더 높여주기 위해 Cross-attention을 수행합니다. 그림 2의 분홍색 부분에서도 비디오를 query로 두고 텍스트 feature를 key, value로 사용하고 있음을 볼 수 있습니다. 비디오의 모든 clip feature에 텍스트 쿼리의 맥락 정보를 심어주는 느낌이라고 생각하시면 이해하기 편하실 것 같습니다.
Query Q_{v}를 만들어주기 위해 비디오 feature를 projection하고, 나머지 K_{t}, V_{t}는 텍스트 feature로부터 projection하여 얻습니다. 이에 대한 cross-attention 연산은 아래 수식 1과 같습니다.
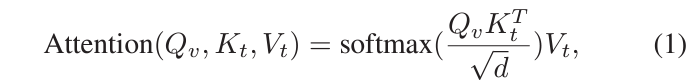
위 수식으로 얻은 값을 다시 MLP에 태워, text feature와의 유사도가 고려된 비디오의 clip 별 attention score를 뽑아줄 수 있고, 이를 비디오 feature에 곱해 앞으로 텍스트 쿼리가 고려된 비디오 feature X = \{x_{v}^{1}, \cdots{}, x_{v}^{L}\}로 표현하고 사용합니다.
2.2 Learning from Negative Relationship
앞선 2.1절에서 cross-attention을 통해 텍스트 쿼리를 고려한 비디오 feature X를 추출했습니다. 본 절에서는 모델 관점의 cross-attention보다 좀 더 명시적으로 텍스트 쿼리와의 관계를 모델링해줍니다. DETR 기반의 방법론 baseline인 Moment-DETR이 높은 성능을 기록하긴 하지만, 방법론 자체는 굉장히 naive하기 때문에 기존 연구되던 DETR 기반이 아닌 방법론들에서 열심히 구축해왔던 기본적인 contrastive learning 등의 loss들이 배제된 상태였습니다. 본 절에서 소개할 loss가 다시 이러한 컨셉을 DETR 기반 방법론에 가져온 것이라고 볼 수 있겠습니다.
아이디어 자체는 어렵지 않고, 단순히 배치 내 다른 텍스트 쿼리를 가져와 negative로 두고, 비디오와 negative 쌍 간 saliency score를 0으로 보내주는 것입니다.
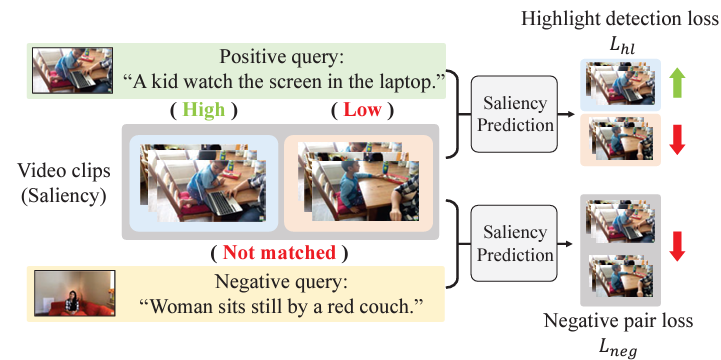
위 그림 3이 해당 과정을 나타내고 있습니다. 비디오 내에도 positive query와 높게 상응하는, 즉 진짜 highlight인 ‘High’ 구간이 존재하고, 시각적으로는 유사하지만 의미론적으로 해당 텍스트 쿼리에 잘 들어맞는 하이라이트라고 보기엔 어려운 ‘Low’ 구간이 존재합니다. 기존 방법론은 High를 높게, Low는 낮게 saliency score를 조정하는 loss가 존재했는데, QD-DETR에서는 negative, 그림 상에서는 Not matched라고 붉게 표시된 비디오-텍스트 관계에 대해서는 볼 것도 없이 어떠한 clip이든 highlight에 해당할 확률이 없으므로 이를 명시적으로 낮추는 Negative pair loss를 적용해주는 것입니다.
물론, 한 단계 더 들어가 배치 내에서 어떠한 negative query를 가져왔을 때 쿼리의 일부는 상응할 수도 있어 이 부분까지 더욱 정교하게 고려해준다면 일반화 성능이 더 높아지겠지만, 우선 DETR 기반 방법론에서는 고려되지 않던 큰 줄기를 잡고 간다는 것에 contribution이 있는 것으로 보입니다. 뒤 실험 부분에서도 보겠지만, 실제 성능 향상에도 큰 도움이 되는 loss였습니다.
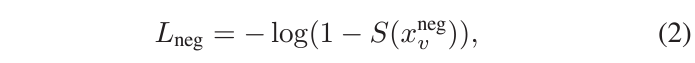
위 수식 2에 negative pair loss L_{neg}가 나타나있습니다. S(\cdot{})는 saliency score predictor를 의미하고, x_{v}^{neg}은 negative pair 간 cross-attention을 거친 feature를 의미합니다. 수식에 따라 negative pair 간 saliency score S(x_{v}^{neg}은 0으로 가도록 학습될 것입니다. 이 loss를 통해 그림 1에서 봤던 기존 방법론의 문제점인, 텍스트 쿼리를 고려하지 않고, 비디오 모달만 단독적으로 예측에 고려되는 상황을 방지할 수 있게 됩니다. 이제 어떤 쿼리가 들어오는지에 따라 모델이 각 상황에 맞는 saliency score를 내뱉을 것으로 기대할 수 있습니다.
2.3 Input-Adaptive Saliency Predictor
본 절은 앞서 수식 2에 있던 saliency score predictor S(\cdot{})에 대해 이야기합니다. S(\cdot{})는 단순히 FC layer나 MLP로 구성해도 동작하는 데에는 문제가 없겠죠. 하지만 이는 Query-Dependent한 모델을 구축하려는 저자의 눈에는 좀 부족해보였을 것입니다. 입력 비디오가 달라지고 텍스트 쿼리가 달라지면 그에 맞게 달라진 기준으로, adaptive하게 saliency score를 뽑아줄 수 있는 모듈이 필요하다는 이야기입니다.
이를 위해 저자는 saliency token x_{s}를 사용합니다. x_{s}는 처음에 random으로 초기화되었다가 학습을 통해 input-adaptive predictor로 변화되는 방식입니다. 이해를 위해 그림 2를 다시 가져와봤습니다. 초록색 부분에서 Random Init.된 x_{s}가 앞서 cross-attention을 통해 추출된 feature X에 concat되어 encoder로 들어가게 됩니다. 이렇게 self-attention을 거치면서, x_{s}는 입력 feature에 존재하는 비디오와 텍스트의 맥락 속에서 함께 학습될 수 있을 것입니다. Encoder를 타고 나온 이후의 비디오 토큰 x_{v}^{i}와 saliency token x_{s}는 각각의 projection 과정을 거쳐주고 내적하여 saliency score S(x_{v}^{i})를 얻게 됩니다. 이 과정은 아래 수식 3과 같습니다.
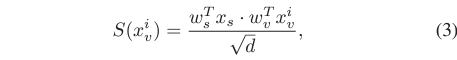
2.2절에서 본 negative loss는, 비디오와 negative query 간 동일 과정을 거쳐 얻은 score를 0으로 보내주는 상황이라고 이해하시면 됩니다.
우선 여기까지만 정리하자면, 실제 DETR 관점에서의 encoder를 태울 입력은 cross-attention을 먼저 한 번 태워 얻어주었고, negative query와의 관계를 명시적으로 모델링해줄 loss와 saliency score를 추출하는 과정에서 input-adaptive한 성질을 부여해줄 saliency token까지 소개된 상태입니다. Saliency score를 뽑는 과정까지 모두 봤는데, 결국 forward 관점에서는 encoder까지만 태워도 HD는 가능한 것으로 보입니다.
그림 상으로 MR은 decoder에서 최종적으로 수행되는 것 같으니, 이제 decoder 부분에 대해 살펴보겠습니다.
2.4 Decoder and Objectives
Transformer Decoder.
DETR을 타 task에 적용할 땐 쿼리를 어떻게 다룰지가 굉장히 중요하게 여겨진다고 합니다. 저도 DETR 기반 방법론들을 많이 살펴본 것도 아니고 다른 task에서 어떻게 활용되는지는 아직 더더욱 모르지만, 쿼리를 설계할 때 positional information을 잘 주입해주면 성능을 향상시키면서 DETR의 문제점인 수렴 속도를 어느 정도 빠르게 가져온다는 연구 결과가 있고 합니다. 저자도 위치 정보를 잘 고려하여 쿼리를 설계해주려고 하는데, 아무래도 multi-modal task이다보니 조금은 신중하게 설계되어야 하겠죠. 비디오에서의 position은 시간 축, text의 position은 문장 내 단어의 위치라고 볼 수 있을 것입니다.
기존 방법론들은 지금 살펴보고 있는 decoder 단계에서 텍스트 쿼리가 처음 등장하기에 이 둘의 정보를 어떻게 섞으면 좋을지 고민해야했지만 QD-DETR은 이미 맨 처음 두 모달의 정보를 합쳐 활용해왔기 때문에 조금은 다른 고민을 하게 됩니다. 영상 분야에서의 2D Dynamic Anchor Boxes (DAB-DETR) 개념을 빌려와 중심 좌표 m_{c}와 너비 m_{\sigma{}}로 표현되는 시간 축에 대한 1d moment query를 만들어주게 됩니다. DAB 방법론을 빌려왔다는 것은, 쿼리가 position 좌표로 구성되며 학습이 layer별로 이루어진다는 것을 의미합니다.
Loss Functions.
우선 최종 학습에 사용되는 loss는 아래 수식 8과 같습니다.
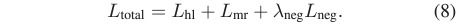
Highlight Detection을 위한 L_{hl}, Moment Retrieval을 위한 L_{mr}, 앞서 2.2절에서 본 negative pair를 위한 loss L_{neg}로 구성되어 있네요. 하나씩 살펴보겠습니다.
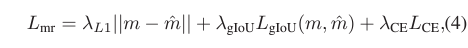
먼저 L_{mr}은 위 수식 (4)와 같습니다. m은 구간의 중심점과 너비 좌표로, 모델의 예측값과 GT 간 L1 loss를 적용해 가지고 있는 라벨과 학습합니다. L_{gIoU}는 generalized IoU loss입니다. L1 loss만 적용한다면 오차의 정도가 다름에도 같은 loss를 내뱉을 수 있기에 조금 더 일반적인 상황, 또는 교집합이 없는 상황에도 loss 값을 내뱉어 학습이 가능한 gIoU loss를 사용합니다. DETR에서 사용한 loss를 temporal 축으로 가져와 사용한다고 생각하시면 됩니다.
다음으로 L_{hl}는 아래 수식 7과 같습니다. 두 가지 loss로 구성되어 있습니다.
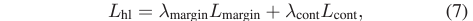
L_{margin}은 margin ranking loss로 높은 점수의 clip과 낮은 점수의 clip 간 margin을 조절해줍니다.
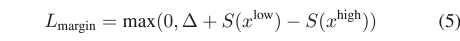
L_{cont}는 rank-aware contrastive loss로, 배치 내 최대 rank 값을 R이라 두고 R보다 낮은 saliency score를 갖는 샘플들만큼 배치 내에서 반복(R번)하며, 반복할 때마다 현재 보고있는 anchor보다 salienct score가 높은 clip들은 positive로, 반대는 negative로 두어 contrastive learning을 진행해주게 됩니다.
이제 학습 과정을 모두 알아보았으니 실험으로 넘어가겠습니다.
3. Evaluation
3.1 Experimental Settings
Dataset and Evalation Metrics.
평가는 앞서 계속 언급되었던 QVHighlights와 TVSum, Charades-STA 데이터셋을 통해 진행됩니다. QVHighlights는 MR, HD 모두에 대한 평가를 진행할 수 있고, Charades-STA와 TVSum은 각각 MR과 HD를 위한 데이터셋입니다.
평가지표는 Recall@1, IoU=0.5, 0.7과 mAP를 측정합니다. HD에 대해서는 HIT@1과 mAP를 측정합니다. HIT@1은 가장 비디오 내에서 가장 saliency score가 높은 하나의 clip이 QVHighlights HD annotation 중 ‘Very Good’에 속하는지 여부를 나타낸 일종의 accuracy라고 생각하시면 됩니다.
Moment-DETR과 동일한 조건에서의 성능 비교를 위해 비디오 feature는 SlowFast + CLIP, 텍스트 feature는 CLIP을 활용합니다.
3.2 Experimental Results
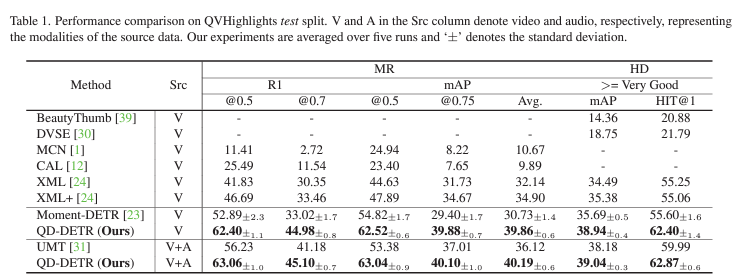
표 1은 QVHighlights 데이터셋에서의 MR과 HD 벤치마크 성능입니다. Src는 source domain을 의미하며, 기본적으로 제가 작성한 리뷰는 Video만을 다루는 상황을 설명드렸습니다. V+A는 Audio 모달을 추가로 사용했을 때의 성능이며, 추가 처리 없이 단순히 기존 베이스라인 방법과 동일하게 video feature에 audio feature를 concat하여 입력해준 것이 차이점입니다. Moment-DETR이 베이스라인 방법론으로서 처음 이 표의 틀을 잡을 때, 5회 평가하고 결과를 평균과 표준편차로 표현했기에 저자도 이 방식을 따랐다고 합니다.
두 task를 수행한다고해서, 여타 unified model과 같이 구조만 동일하고 각각의 task를 별도의 데이터셋으로, 별도의 방법론으로 학습하는 것은 아니고, joint하게 학습됩니다. 우선 V와 V+A 모두에서 베이스라인 방법론인 Moment-DETR보다 월등히 높은 성능을 보여주고 있습니다.
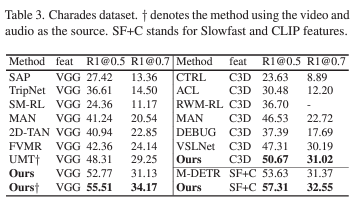
이어서 표 3은 Charades-STA 데이터셋에서의 MR 성능입니다. 공정한 성능 비교를 위해 여러 backbone에서의 feature로 평가를 진행하고 있고, 십자가로 표시되어있는 성능은 V+A를 의미합니다. 모든 feature에 대해 SOTA를 달성하고 있습니다.
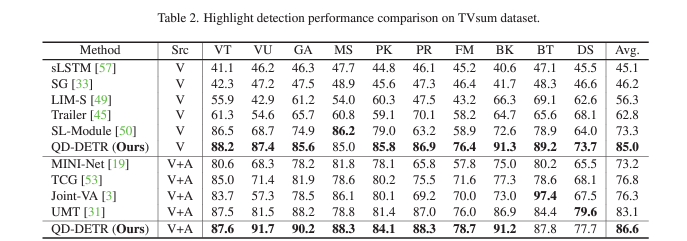
표 2는 TVSum 데이터셋으로 평가한 HD 성능입니다. 칼럼은 데이터셋에 존재하는 10개의 카테고리들을 의미하고, 평균 관점에서는 기존 방법론보다 훨씬 높은 성능을 보여주고 있습니다. 저자도 그렇지만 기존 베이스라인 방법론이 워낙 naive하였어서 높은 성능 향상이 발생하고 있는.. 새로운 연구 갈래의 초창기 상황이라고 생각하고 있습니다. 뭔가 벤치마크 표를 봤을 때 단순히 벤치마킹만을 위해서 뽑아야 할 feature와 비교할 데이터셋이 굉장히 많아보이네요.
3.3 Ablation Study
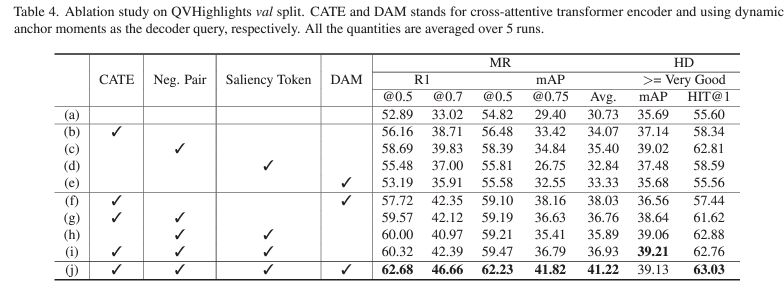
표 4는 QVHighlights val split에 대한 QD-DETR의 module-wise ablation 성능입니다. CATE는 맨 처음 feature 추출에 적용되는 cross-attention 사용 여부, Neg. Pair는 negative query와의 saliency score를 0으로 만들어주는 loss 사용 여부, saliency token은 saliency score 추출에 사용되는 별도의 token 사용 여부, DAM은 Dynamic Anchor Box 기법을 시간 축으로 가져와 활용했는지 여부를 의미합니다.
베이스라인 대비 가장 높은 성능 향상을 불러온 것은 Neg. Pair였습니다. 아무래도 task가 텍스트 쿼리를 기반으로 구간 또는 구간에 대한 score를 만들어내는 것인데, 기존 방법론이 이에 대한 모델링을 중시하지 않고있었다는 저자의 통찰이 올바른 방향이었음을 알 수 있습니다. (a)와 (e)를 봤을 때 DAM을 사용하는 경우 오히려 성능이 떨어지는 것도 볼 수 있는데, 이는 DAM 방식 자체가 moment를 잘 찾기 위해 입력 토큰의 위치 정보를 활용하기 때문입니다. Cross-attention을 거치지 않고 넘어온 feature는 단순 concat과도 유사하여 제대로된 multi-modal의 위치 정보를 담고 있다고 보기 어렵기 때문에, DAM은 CATE가 반드시 선행되어야 제역할을 한다고 분석해볼 수 있습니다.
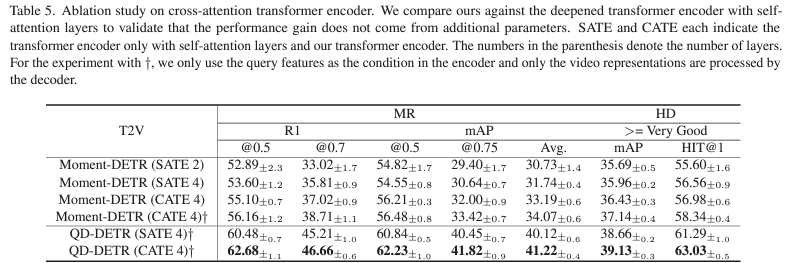
표 5는 단순 ablation보다는 조금 더 의미있는 실험입니다. QD-DETR의 방법론을 보고 누군가는 “그냥 cross-attention layer 하나 추가해서 연산량 많아졌으니 성능이 오른게 아닌가?”라는 의문을 가질 수도 있습니다. 저자는 이에 대응하기 위해 표 5를 제안한 것입니다.
표에서 SATE는 self-attention transformer encoder를 의미합니다. Moment-DETR의 SATE4와 CATE4를 비교했을 때에도 성능 향상이 꽤나 큰 것을 보았을 때 우선 cross-attention 자체가 유의미한 성능 향상을 불러올 수 있는 것을 알 수 있습니다. 이는 QD-DETR에서도 마찬가지이며, 결과적으로 성능 향상은 추가적인 연산으로부터 온 것이 아니라, 텍스트 쿼리를 잘 활용한 것으로부터 온 것임을 논리적으로 증명하고 있다고 생각합니다.
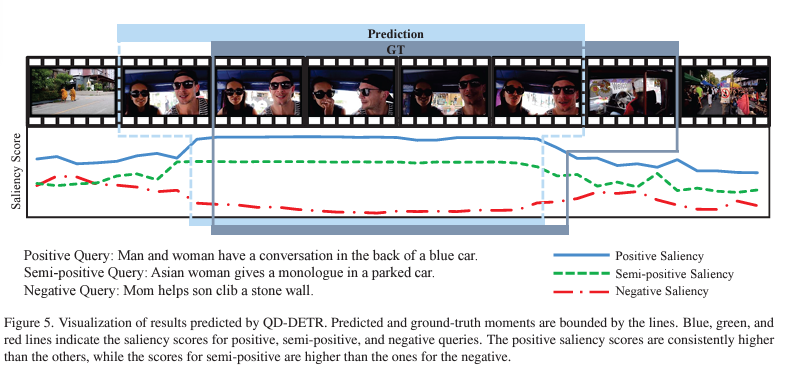
마지막으로 정성적 결과를 보겠습니다. 하나의 비디오에 대해 positive, semi-positive, negative 쿼리에 대한 saliency를 각각 표시하고 있습니다. 모델은 비디오와 쿼리의 연관도에 비례하는 saliency score를 내뱉고 있으며, 저자에 따르면 심지어는 GT보다 더욱 정확한 MR 결과를 내뱉고 있다고 합니다.
4. Conclusion
DETR 기반 MR, HD 방법론을 읽어보았는데, 아직까진 아이디어가 간단해보입니다. 이제부터 읽을 논문들이 방법론 측면에서도 꽤 복잡한 것으로 알고있는데, 본 논문을 코드 레벨까지 잘 이해하고 있는 것이 중요할 것 같네요.
리뷰 마치겠습니다.
테스트