안녕하세요, 서른 한번째 x-review 입니다. 이번 논문은 2023년도 arXiv에 올라온 Point-GCC: Universal Self-supervised 3D Scene Pre-training via Geometry-Color Contrast입니다. 일년 동안 SUN RGB-D 데이터셋에서 SOTA를 유지하고 있는 방법론인데, 학회에 publication 될 때까지 기다리다가 결국 읽게 되었습니다 . . 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
3D 데이터셋은 2D에 비해 포인트 클라우드 라벨링에 시간과 노동력이 많이 소비됩니다. 그래서 3D Self-supervised learning (SSL)에서는 라벨링되지 않은 데이터를 통해 representation을 학습하여 라벨링된 데이터에서의 downstream task 성능을 향상시키는 것을 목표로 하고 있습니다. 기존 연구에서는 contrastive learning, maked auto encoder (MAE)와 같이 2D 분야의 연구 방향을 따르고 있는데, 2D 분야와 비교하였을 때 3D에서의 특징을 몇가지 살펴볼 수 있습니다.
(1) 데이터의 정보 형태
포인트 클라우드는 기하학적인 정보 뿐만 아니라 컬러와 같은 다양한 추가적인 정보가 포함되어 있습니다. 기존 방법론들은 이러한 정보들을 각 포인트에 대한 통합된 하나의 정보로 취급하였습니다. 그러나 저자는 모든 정보를 한번에 통합해버리면 포인트 클라우드가 제공하는 다양한 측면에서의 정보를 차별적으로 학습할 수 없다고 주장합니다.
(2) pretraining과 downstream task 사이의 mismatch
이전의 사전학습 연구에서는 포인트 사이의 constrastive와 reconstruct와 같은 self supervsied 포인트 레벨의 task를 설계하였으나, 대부분의 3D scene에서의 downstream task들은 (object detection, instance segmentation) 물체 레벨의 representation에 집중합니다. 그래서 사전학습 모델과 downstream task 간의 차이가 self supervised 학습의 성능 개선에 방해가 될 수 있다고 합니다.
(3) 구조의 다양성
3D 분야에서 널리 사용되는 구조들은 downstream task에 따라 변경이 가능한데, 이렇게 많은 갈래의 task에 맞게 구현되어 있고 쉽게 적용할 수 있는 일반적인 pretrained 프레임워크 설계가 중요하게 여겨지고 있습니다.
이러한 3가지 측면을 고려하여 저자는 포인트 클라우드가 가지고 있는 정보 사이의 관계를 더 잘 활용하고자 하였습니다. 포인트 클라우드는 크게 기하학/컬러 정보 이렇게 두 가지를 제공하고 있는데 기하학적인 정보는 물체의 표면, 윤곽 정보를 제공하여 쉽게 구분할 수 있게 하고, 컬러 정보는 물체의 내부적인 특성을 구별할 수 있도록 해줍니다. 저자는 이런 서로 다른 정보 사이에 연관성이 있다고 이야기하는데요, 예를 들어 물체의 연속적인 컬러 정보를 이어서 대략적인 윤곽 정보를 얻을 수 있는 것처럼 말입니다. 본 논문에서는 포인트 클라우드가 제공하는 이런 정보 사이에서 발견할 수 있는 차이와 연관성을 기반으로 Siamese 네트워크를 사용하여 representation을 추출하고, 계층적인 supervision을 통해 self supervised 3D scene 사전학습 프레임워크인 Point-GCC를 제안합니다. downstream task와의 갭을 줄이기 위한 계층적 supervision에는 포인트 별 feature을 얼라인 맞추는 것을 목표로 하는 포인트 레벨의 supervision과 새로운 deep clustering 모듈을 기반으로 하는 물체 레벨의 supervision을 포함하였습니다. 또한 일반적인 Siamese 네트워크를 설계하여 다양한 downstream task 모델에서 plug-and-play 방식으로 쉽게 적용할 수 있도록 하였습니다. 이러한 사전학습 모델 자체의 성능을 확인하기 위해 어떠한 fine tuning 없이 fully unsupervised semantic segmentation을 수행하였고, 추가적으로 여러 downstream task에 대한 실험을 진행하였다고 합니다. 여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- Siamese 네트워크를 통해 기하학/컬러 정보의 얼라인을 맞춘 self-supervised 3D Scene 사전학습 프레임워크인 Point-GCC 제안
- 풍부한 물체 represenation을 학습하기 위해 물체의 수도 라벨을 생성하는 deep clustering 모듈 설계
- 다양한 데이터셋과 downstream task에서 SOTA 달성
2. Related Work
2.1. Deep Clustering for Self-supervised Learning
self-supervised learning에서 deep clustering은 더 나은 representation을 학습하고 라벨을 할당하는 것을 목표로 하며, 이는 self-supervised 뿐만 아니라 semi-supervised learning에서까지 널리 사용되고 있습니다. 이는 K-means 알고리즘 수도 라벨을 supervision으로 사용하여 self-supervised learning을 위한 representation을 학습합니다. SeLa[1]는 동일한 분포를 가진 수도 라벨을 생성하기 위해 클러스터링과 representation을 동시에 수행하는 Sinkhorn-Knopp 알고리즘을 제안합니다. SwAV[2]는 contrastive learning과 deep clustering을 합쳐서 다른 뷰의 동일한 이미지에서 할당하는 클러스터링의 일관성을 강화하였습니다. 본 연구에서는 contrastive learning과 deep clustering을 합쳐서 포인트 클라우드의 기하학/컬러 정보의 feature 일관성을 기반으로 수도 라벨을 생성하는 deep clustering을 제안합니다.
3. Point-GCC: Pre-training via Geometry-Color Contrast
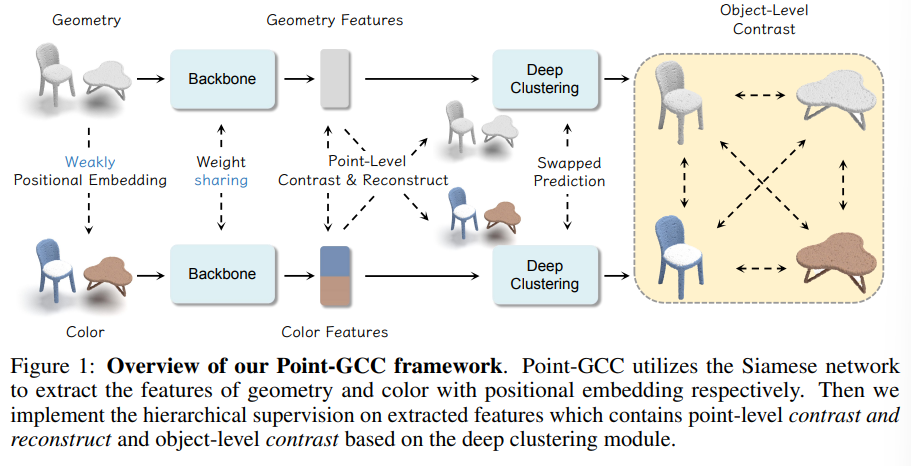
3.1. Siamese Architecture
하나의 포인트 클라우드 p는 일반적으로 기하학적인 정보로 간주되는 포인트 좌표 p_{geo}와 컬러 정보인 p_{color{로 구성되어 있습니다. 이런 두 정보가 모두 포함된 하나의 포인트를 가장 작은 입력 단위로 간주하는 이전의 사전학습 방식들과는 다르게, 포인트 클라우드를 기하학/컬러 이렇게 두 파트로 나누게 됩니다. 그 다음 식(1)과 같이 공용 임베딩 공간인 e에 projection하고, 유사한 컬러이지만 서로 다른 좌표의 포인트를 나타내는 컬러 정보들을 구별하기 위해서 논문에서의 표현으로 약하게 위치 임베딩 e_{pos}를 추가하였습니다. 프레임워크의 설계 목적에 plug-and-play가 포함된 만큼, fine tuning 단계에서 모든 임베딩 모듈을 제거함으로써 더 많은 기존의 방법들이 해당 프레임워크를 활용할 수 있도록 하였습니다.
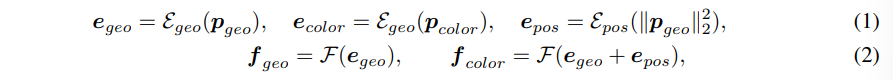
- \varepsilon : 각 임베딩에 대응하는 linear layer
- F(\dot) : Siamese 네트워크
계속해서 본 논문이 Siamese 네트워크를 사용하였다고 언급하였는데요, 대칭적인 네트워크를 F(\dot)을 통해 기하학적인 feature f_{geo}와 컬러 feature f_{color}를 각각 인코딩하였습니다. 단 기존 구조에서 기하학/컬러 정보를 함께 사용하여 더 나은 representation을 학습할 수 있도록 하기 위해 백본 구조는 수정하지 않았다고 합니다. 이를 통해 모든 백본 구조에서 segmentation을 위한 주요 모듈을 직접적으로 재사용할 수 있습니다. 다시 말해서 백본은 입력 x \in \mathbb{R}^{N \times C_1}를 인코딩하고 feature y \in \mathbb{R}^{N \times C_2}를 추출하는 것 입니다. 여기서 두 정보의 align을 맞추기 위해 백본은 기하학 임베딩 e_{geo}와 컬러 임베딩 e_{color} (약한 위치 임베딩 e_{pos}가 포함된)을 각각 f_{geo}와 f_{color}로 인코딩 하게 됩니다.
3.2. Point-level Supervision
contrastive learning과 reconstructive learning을 함께 사용하는 당시 연구의 흐름을 따라 Siamese 구조를 위해 설계된 포인트 레벨의 supervision을 제안합니다.
Contrastive learning
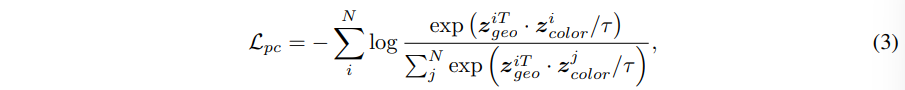
- tau : temperature 하이퍼 파라미터 → 0.4로 설정
- z^i_{geo}, z^i_{color} : 한 쌍의 positive sample을 나타내는, 하나의 포인트 p^i에 대한 feature f^i_{geo}, f^i_{color}를 의미
f_{geo}와 f_{color}는 분리하긴 했지만 어쨌든 처음에는 동일한 하나의 포인트 클라우드 p에서 나누어진 것이기 때문에 백본 네트워크에서 feature가 추출된 이후에 포인트 단위로 정렬됩니다. 그래서 기하학적인 feature와 컬러 feature에서 positive pair를 가까워지게 하고 negative pair는 멀어지도록 InfoNCE loss를 계산합니다.
Reconstructive learning
reconstructive learning에서는 일반적인 마스킹 방식 대신에 swapped 재구성 방식을 사용하였는데, 그 이유는 포인트 클라우드에서 MAE를 적용했으 때 발생할 수 있는 학습/테스트 데이터 분포 간의 불일치 문제를 해결하고자 하였습니다. c컬러 \hat{p}_{geo}와 기하학 \hat{p}_{color}를 재구성하기 위해서 f_{geo}, f_{color}를 projection 하기만 하면 됩니다. reconstruction loss는 각 포인트의 재구성된 정보(\hat{p})와 기존 정보(f) 사이의 MSE Loss를 사용합니다.
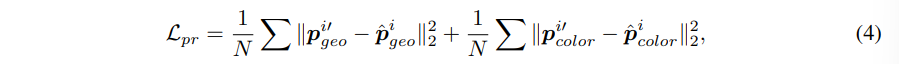
- N : 포인트 수
- \hat{p}^i_{geo}, \hat{p}^i_{color} : reconstruct 예측값
- p^{i’}_{geo}, p^{i’}{color} : 0-1 사이로 스케일링 되는 reconstruct 타겟
3.3. Object-level Supervision
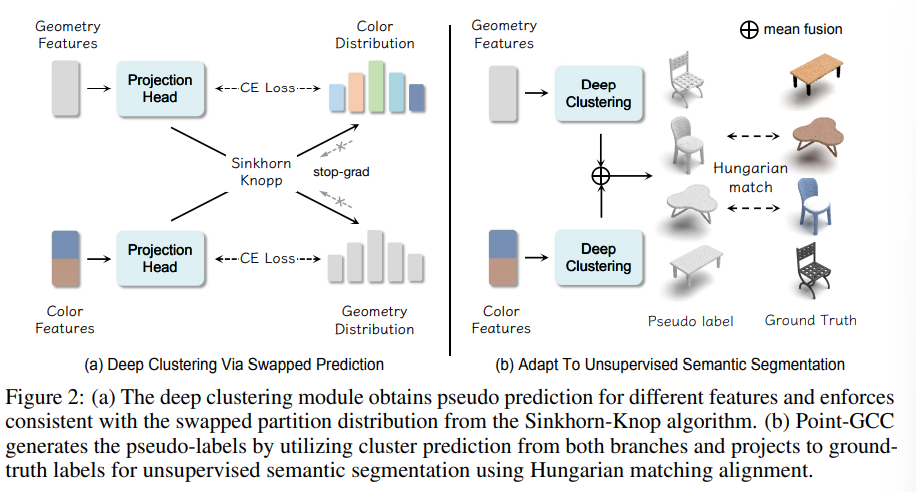
앞선 섹션 3.2.의 포인트 레벨 supervision은 기존 3D self-supervised 학습에 널리 적용되고 있지만 3D downstream task들에서 중요한 물체 레벨의 representation은 크게 활용되고 있지 않았다고 합니다. 그래서 본 논문에서 새로운 unsupervised deep clustering 모듈로 동작하는 물체 레벨의 supervision을 제안하게 된 것 입니다. 해당 클러스터링 모듈은 f_{geo}, f_{color}에 대해 각각 수도 라벨 \mathcal{P}_{geo},\mathcal{P}_{color}를 생성하고, 동일한 하나의 포인트 p의 \mathcal{P}_{geo}, \mathcal{P}_{color}사이에서 일관된 예측을 수행합니다. 저자는 수도 라벨을 통해 고정된 물체 클래스 사이에서 사람이 수행하는 어노테이션에 제한되지 않고 더 다양한 물체의 feature을 나타낼 수 있다고 주장합니다. 이러한 물체 레벨의 수도 라벨 중에서 confidence score가 높은 물체 feature을 샘플링하고, 수도 라벨에 대한 물체 레벨의 contrastive learning을 진행하는 것 입니다.
Deep clustering via swapped prediction
여기서는 swapped 예측을 적용하는데, 이는 다른 뷰의 클러스터링 결과로부터 이미지의 수도 라벨을 예측하는 2D contrastive learning 방식을 따랐다고 합니다. 본 논문에서는 Fig.2(a)와 같이 서로 다른 정보 feature의 클러스터링 하는 대상을 바꾸고, 두 정보의 특성을 기반으로 서로 다른 정보 feature로부터 수도 라벨을 예측하게 됩니다. 수도 라벨 클래스가 K일 때, learnable 행렬 C = [c_i, . . ., c_K]를 사용해서 클러스터링의 중심을 표현합니다. 그 다음 feature f와 C 사이의 유사도 S를 계산합니다. 모든 feature가 동일한 예측으로 가는 것을 막기 위해서 Sinkhorn-Knopp 알고리즘을 사용해서 유사도 S로부터 클러스터링 분포 \mathcal{Q}를 생성한하여 수도 라벨 생성을 최적의 운송 문제로 변환한다고 합니다. 여기서 Sinkhorn-Knopp 알고리즘은 수도 라벨과 최적의 운송 문제를 연결짓는 방식이라고 합니다. 그리고 learnable 예측 \mathcal{P}은 유사도 S에 대한 softmax(S/\tau)로 계산되며 여기서 \tau는 하이퍼파라미터 입니다. swapped 예측에서 모든 하이퍼파라미터는 2D에서와 동일하게 설정되며, 아래의 식(5)는 learnable 예측 \mathcal{P}와 swapped 분포 \mathcal{Q} 사이의 cross entropy loss로 이루어진 swapped 예측 loss를 정의한 것 입니다.
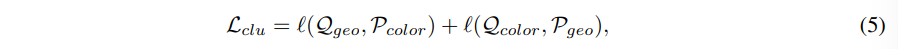
- \ell : 예측과 타겟 사이의 cross entropy loss
Object-level constrastive learning
deep clustering에서 대응하는 수도 라벨 \mathcal{P}과 confidence sore을 가진 feature f들 중에 unsupervised 클러스터링에서 발생하는 노이즈를 줄이기 위해 임계값보다 높은 confidence score를 가진 feature들로 필터링하게 됩니다. 그 다음 기하학/컬러 브랜치에서 각각 confidence score가 높은 샘플들의 평균 feature를 계산합니다. 동일한 수도 라벨을 가진 두 유형의 평균 feature을 positive pair로, 반대로 다른 수도 라벨을 가진 두 유형의 평균 feature는 negative pair로 하여 물체 레벨의 InfoNCE loss를 계산합니다.
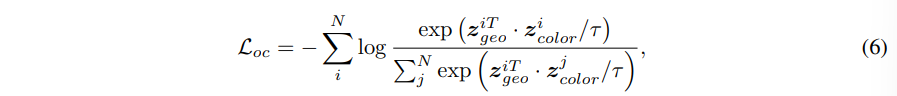
- tau : temperature 하이퍼 파라미터 → 0.4로 설정
- z^i : L2 normalize한 수도 라벨 i에 대한 mean feature
- z^i_{geo}, z^i_{color} : 한 쌍의 positive sample을 나타내는, 동일한 수도 라벨 i를 가진 샘플
3.4. Adapt to unsupervised semantic segmentation
이전의 사전학습 모델이 전이 학습을 통해 downstream task에서의 성능을 평가하는 반면, 본 논문의 방법론은 물체 레벨의 supervision의 수도 라벨을 통해 fintuning 없이 unsupervised downstream task에 적용할 수 있게 됩니다. 기존에는 fintuning 설정에 따라 결과가 크게 영향을 받았습니다. 하지만 본 논문에서는 Fig.2(b)와 같이 기하학/컬러 브랜치에서 클러스터링 예측을 활용해서 최종적인 수도 라벨을 생성하는데, inference에서는 사전 학습에서 GT와 연관이 없었기 때문에 헝가리안 매칭을 통해 수도 라벨을 GT 라벨에 적용하게 됩니다.
4. Experiments
indoor 3D scene 데이터셋인 ScanNetV2, SUN RGB-D, 그리고 S3DIS에서 실험을 진행하였습니다.
4.2. Fully unsupervised semantic segmentation
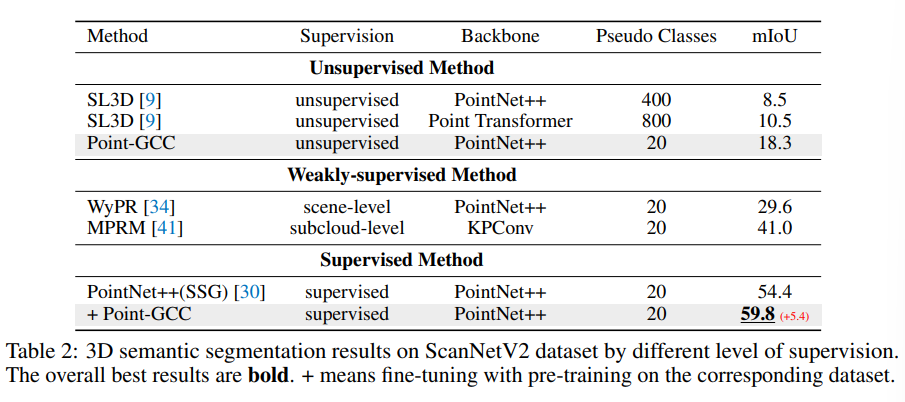
먼저 Tab.2는 pretrain 모델 자체의 성능을 검증하기 위해서 섹션 3.4에 따라 fully unsupervised semantic segmentation task를 수행한 결과 입니다. 이전의 unsupervised 방식보다 좋은 결과를 보이는 것을 확인할 수 있습니다. 이러한 결과를 통해 point-gcc가 보다 풍부한 물체 representation을 학습할 수 있음을 보여주고 있습니다. 또한 추가적으로 semantic segmentation을 위한 supervised fine tuning을 진행함으로써 맨 아래 행의 mIoU 59.8%를 달성하면서 포인트 클라우드의 내부적인 representation을 학습할 수 있음을 강조하고 있습니다.
4.3. Transfer learning on downstream tasks
3D Object Detection
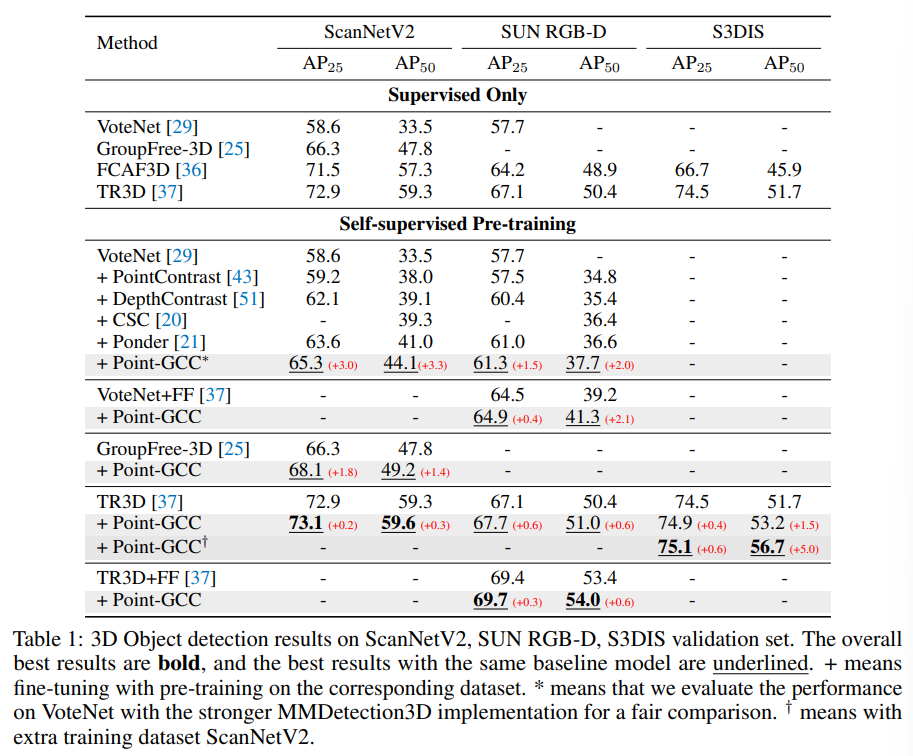
3D detection에서 비교 모델은 PointNet++ 백본을 사용하는 VoteNet, VoteNet+FF, 그리고 GroupFree-3D와 MinrResNet 백본을 사용하는 TR3D, TR3D+FF 입니다. 이전의 self supervised 방식들을 VoteNet 베이스 모델에서 비교하였을 때 ScanNetV2와 SUN RGB-D에서 가장 높은 성능을 보여주고 있습니다. 또한 TR3D+Point-GCC는 모든 데이터셋에서 SOTA를 달성한 것을 확인할 수 있습니다.
3D Instance Segmentation
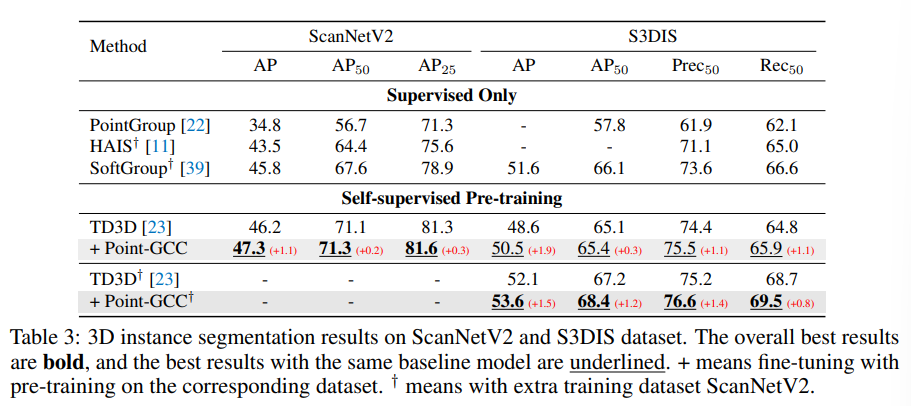
다음은 3D Instance Segmentation에서의 실험 결과로, 여기서 눈여겨볼 점은 PointNet++ 백본을 사용한 모델에서의 성능 개선이 MinkResNet 백본 기반보다 훨씬 크다는 점 입니다. 이러한 결과에 대해 저자는 sparse conv 구조의 MinkResNet은 feature의 컬러와 기하학적인 정보에 대해 내부적으로 align이 맞춰지는 것으로 추측하고 있습니다.
4.3. Ablation study
Hierarchical supervision
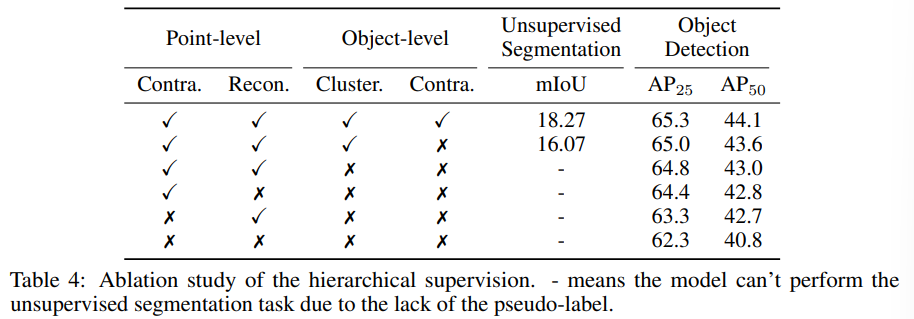
Tab.4는 계층적인 supervision 방식의 효과를 확인하기 위한 ablation sutdy로 unsupervised semantic segmentation과 fine tuning을 거진 object detection 결과를 리포팅하고 있습니다. 먼저 포인트 레벨에서의 contrastive learning과 reconsruction learning은 모두 성능 개선에 긍정적인 영향을 미치며 포인트 레벨에서만 두 학습 방식을 모두 사용하였음에도 이전 SOTA 모델인 Ponder 대비 더 높은 성능을 달성할 수 있었다고 합니다. 물체 레벨에서 역시 성능 향상이 이루어졌는데, AP50에서 더 큰 폭의 향상이 일어나면서 물체 레벨의 supervision이 물체를 더 정확하게 검출할 수 있는 방향으로 설계되었음을 확인할 수 있습니다.
Geometry-Color Contrast
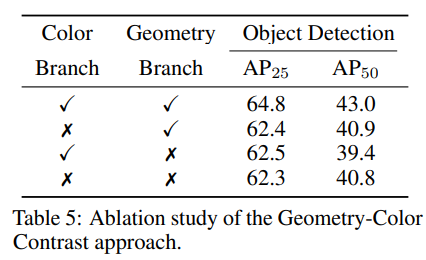
마지막으로 기하학-컬러 contrast 방식의 효과를 증명하기 위해서 각각의 reconstruction 브랜치를 세팅하여 ablation study를 진행하였다고 합니다. 그 결과 기하학 / 컬러 reconstruction 중 하나의 브랜치에만 사용할 경우에는 동시에 사용할 때 대비 확실히 성능 하락이 발생하기 때문에 기하학-컬러 정보의 특성과 연관성을 활용한 본 논문의 방식이 중요한 역할을 하고 있음을 보여주고 있습니다.
안녕하세요 손건화 연구원님 좋은 리뷰 감사합니다.
각 과정에 있어 차근차근 잘 설명해주신 덕분에 이해가 잘 되는 리뷰였던 것 같습니다.
전반적인 컨셉은 익숙한 것 같으면서도, 역시 3D 연구는 그 디테일이 다르네요. 제가 미숙한 탓에 몇 가지 궁금한 점이 있어 댓글 남깁니다!
3.2. Point-level Supervision 파트에서, 혹시 negative pair는 기존 Self-supervised learning 처럼 같은 배치 내에 있는 다른 object 라고 설정하나요?
3.3. Object-level Supervision 파트에서,
clustering을 사용하여 물체 레벨의 supervision을 제안하였다고 하셨는데요, 이 부분의 경우 feature 단에서의 clustering을 진행하는 것이 맞을까요? 그렇다면 어째서 feature 단에서의 clustering을 진행한 것이 물체 레벨의 supervision을 얻게되는 것인지 궁금합니다
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 먼저 negative pair에 대해서는 명시적으로 논문에서 설명하고 있진 않지만, 저도 같은 배치 내에 있는 다른 object라고 이해하였습니다.
2. feature 단에서 클러스팅을 진행하는 것이 맞고, clustering을 통해 하나의 feature 그룹에 대해서 수도 라벨을 할당하여 물체 레벨의 supervision을 얻고자 하였습니다.
감사합니다.
안녕하세요 건화님, 좋은리뷰 감사합니다.
3D self-supervised learning 분야가 상당히 어렵고 복잡해보이는데, 건화님이 잘 설명해주신 덕분에 큰 틀에 대해서는 어느정도는.. 이해가 조금 된 것 같습니다.. 사실 논문의 내용을 코드로 생각해보면 내부에서 구체적으로 어떤 방식으로 굴러가는지는 잘 그려지진 않긴 합니다? 그럼에도 논문 내용만 봤을 때라도 물체레벨 supervision의 수도 라벨을 통해 추가적인 finetuning없이도 unsupervised downstream task에 적용될 수 있었다는 게 매력적인 방법론인 것 같습니다.
모르는 게 너무 많지만 그 중에서 질문할 거 하나만 고르자면, plug-and-play라는 downstream task를 위한 설계목적 때문에 fine tuning 단계에서 모든 임베딩 모듈을 제거하면 더 많은 기존의 방법들이 해당 프레임워크를 활용할 수 있게 된다고 언급되었는데, 이렇게 임베딩 모듈을 제거해 범용성을 높일 수 있다는 게 어떤 방식으로 영향을 주는 것인지 궁금합니다.