이번에 소개드릴 논문은 ICCV2023에 게재된 논문으로 Adapter를 활용하여 Multitask learning을 수행하는 논문입니다. 본 논문이 요즘 핫한 키워드인 adapter부터해서 zero-shot task transfer, domain generalization 등등 온갖 키워드를 다 가져다 붙이는 바람에 상당히 매력적으로 보였으나 막상 논문을 읽어보니 아쉬움이 많이 남네요.
우선 글을 너무 휘갈겨?쓰는 바람에 저자들의 의도를 이해하는 것이 상당히 어려웠으며 더욱이 중요한 컨트리뷰션 부분에 대해서도 설명이 모호하고 간단하게 작성된 후 그냥 넘어가버리는 바람에 구체적인 동작 과정 자체도 이해하기 힘드네요. 다른 논문으로 x 리뷰를 작성할까 하다가 이 논문을 이해하려고 아둥바둥한 시간이 너무 아까워서 그냥 작성해보도록 하겠습니다^^..
Intro
우선 저자들이 인트로에서 다루는 문제점들을 정리해보면 아래와 같습니다.
- Transformer 백본을 기반으로 하나의 획일화된 프레임워크에서 다양한 테스크들을 수행하는 것이 이상적이지만, 이러한 연구들이 많지도 않을 뿐더러 현존하는 연구들은 특정 테스크에 맞추어 트랜스포머의 구조를 커스터마이징 시켜야만 한다는 단점이 존재합니다.
- 멀티모달 입력에 대한 트랜스포머 기반 방법론들이 CNN 기반 방법론들보다 더 좋긴 했는데, 이 두 방법론들 중 어느 하나도 새로운 테스크와 도메인에 대하여 적응적으로 동작하는 것까지는 고려하지 않았습니다.
이러한 문제점을 바탕으로, 저자들은 멀티 테스크에 대한 관련성(affinity)을 전이 가능하고 일반화 가능하도록 만들어서 새로운 테스크나 도메인에 대하여 현존하는 모델을 재사용할 수는 없을까? 라는 의문을 가지게 됩니다.
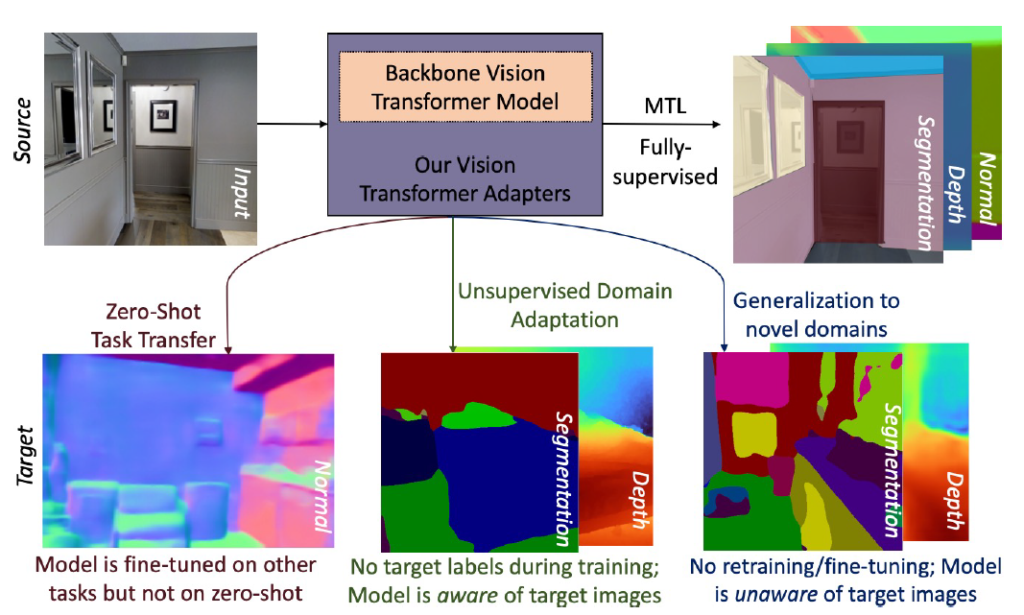
그림1을 살펴보시면 저자들이 논문에서 수행하고자 하는 목표를 확인할 수 있는데, 하나의 획일화된 Transformer Model에 대하여 Segmentation, Depth estimation, Normal, Edge detection 등 다양한 multitask learning을 수행 후 Zero-shot task transfer, Unsupervised Domain Adaptation, Domain Generalization 등을 최종적으로 수행하는 모델을 만들고자 합니다.
따라서, 저자들은 ViT에 추가할 수 있는 adapter와 자동화된 프레임워크를 함께 제안하여 테스크 관계성에 대해 일반화 가능성을 학습시키도록 하였습니다. 이는 새로운 테스크나 도메인에 대하여 파라미터 효율적인 방식으로 적응할 수 있도고 합니다.
또한 기존 Multitask learning 연구들은 테스크 별로 짝을 매칭시켜서 테스크의 관계성을 학습한 반면, 저자들은 adapter를 통해 task 관계성을 자동적으로 학습시켜서 모든 테스크에 대해 잘 작동한다고 주장합니다. 결과적으로 저자들이 제안하는 컨트리뷰션은 다음과 같습니다.
- 그레디언트 기반의 테스크 유사도 추정 방식 제안.
- 테스크 적응적인 어텐션 방식 제안(이는 어텐션 결고와 그레디언트 기반의 테스크 유사도를 융합시켜 일반화 가능한 테스크 관계성을 학습시키도록 함.)
- 테스크 스케일 정규화를 통해 서로 다른 테스크에 따른 스케일 변화성을 고려함.
Method
우선 저자들이 제안하는 모델의 프레임워크는 아래 그림과 같습니다.

크게 인코더, Adapter, TROA, Decoder, Task head 로 크게 나타날 수 있으며 여기서 저자들이 제안하는 부분이 TROA와 Adapter 모듈 입니다. 인코더부터 차례대로 알아보도록 하겠습니다.
Encoder Module
저자들이 실험에 사용한 모델은 Swin-B V2로 해당 모델은 ImageNet-22K에 사전학습된 가중치를 사용합니다. Adpater 기반 방법론들은 사전학습된 백본 모델을 모두 freeze하기 때문에 본 논문에서도 동일하게 freeze가 되어 있는데 재밌는 점은 저자들이 Adapter라고 설정한 부분이 기존 Swin-B v2의 stage3 일부와 stage4 레이어입니다. 제가 그 동안에 봐왔던 논문들은 추가적인 layer나 모듈을 사용하는 방식이었는데 기존의 백본에서 일부 레이어 및 블록을 adapter로 갈아끼우는 방식도 있었네요.
아무튼 Swinv2의 경우 Stage 1,2,4의 경우 각각 2개의 swin block으로 구성되어 있는 반면에 Stage3에서는 총 18개의 블록으로 구성이 되어 있습니다. 그래서 저자들은 stage3 내 15번째 블록부터 18번째 블록까지를 adapter로 대체하였으며, 그 이후에 stage4 내 2개의 블록 역시 adpater로 대체가 됩니다.
Vision Transformer Adapter Module
저자들이 제안하는 트랜스포머 adapter 모듈은 아래 그림3과 같습니다.
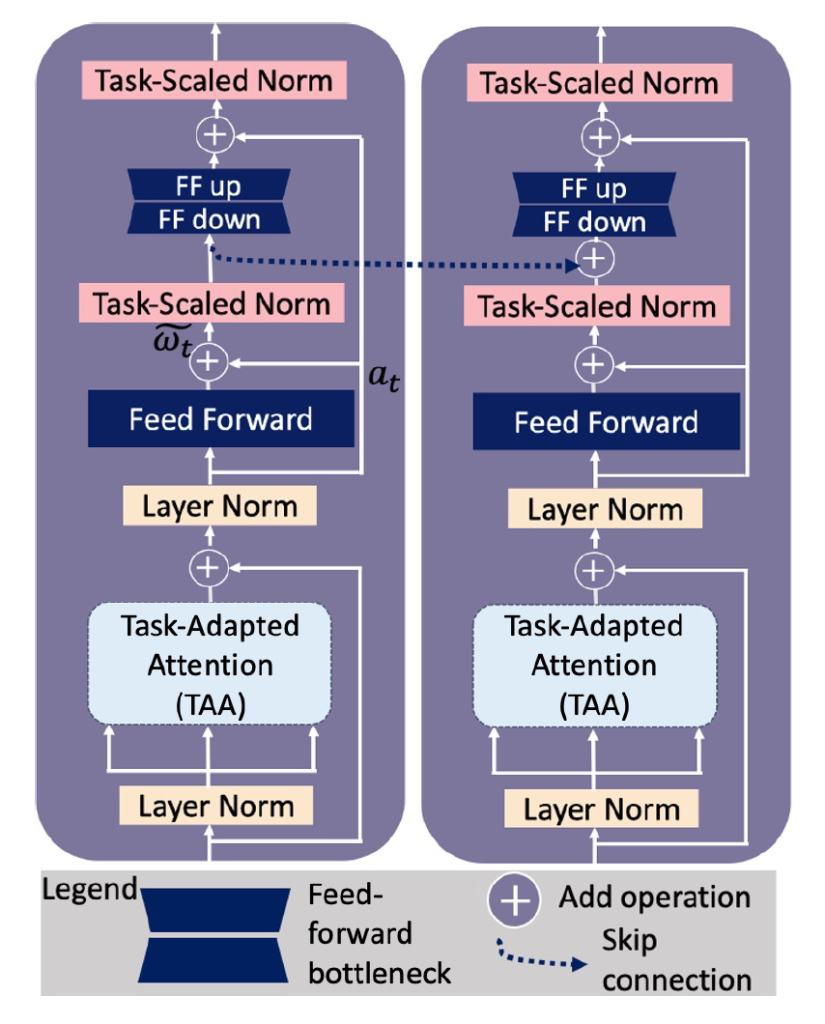
일반적인 Transformer 블록이랑 거의 동일한데, 다른점이 있다면 Task-Adapted Attention (TAA) 모듈과, Task-scaled Norm(TSN)이라는 노멀라이제이션이 존재한다는 것입니다. 그리고 한가지 더 눈에 띄는 점이 있다면 이전 adapter의 feature가 다음 adapter의 Feed-Forward down sampling을 수행하기 전 skip-connection 형태로 연결이 된다는 것입니다. 사실 논문에서 ablation을 따로 진행하지 않아 이러한 skip connection이 효과가 좋은지는 잘 모르겠네요.
아무튼 위에서 소개드린 TAA와 TSN 과정을 제외하고는 Layer normalization, Feed Forward Network, 그리고 추가적인? linear downsampling과 upsampling 과정이 존재하고 있어 adapter 자체가 기존 transformer block과 비교하였을 때 엄청 특별하지는 않는 모습입니다.
Task Representation Optimization Algorithm(TROA)
그럼 task-adapted attention(TAA) 연산 내부에 사용되는 TROA에 대해서 살펴보겠습니다. 사실 이 부분이 가장 중요한 것 같은데 저자들이 얼렁 뚱땅하고 넘어가버려서.. 최대한 이해한 내용을 설명해보도록 하겠습니다.
TROA는 각각 테스크 표현력 \hat{\theta} 과 테스크 관계성 행렬 \hat{\mathcal{w}} 로 나타내며, 이 때 행렬 \hat{\mathcal{w}} 은 각 테스크들이 어떠한 관계를 가지는지를 표현하는 척도라고 합니다. 저자들이 TROA라고 명칭을 지은 이유는 각 테스크 별로 목적 함수를 통해 계산된 gradient 값을 기반으로 task representation \hat{\theta} 를 최적화시키기 때문입니다.
구체적으로는, target task와 inductive task의 그레디언트 사이에 코사인 유사도를 계산하여 이를 테스크 관계성으로 취급하게 됩니다. 만약 i번째 iteration에서 TROA는 특징 표현력과 대응되는 N개의 task-specific한 디코더를 다음과 같이 나타낼 수 있습니다.
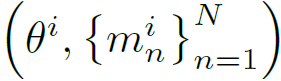
여기서 m은 decoder라고 생각하시면 될 것 같습니다. 포워드 단계에서, 전체 멀티테스크 러닝에 대한 손실 값을 줄여나가는 방향으로 학습을 수행하게 되는데 이때 task representation \theta 도 함께 최적화가 되는 것으로 판단됩니다.

여기서 \mathcal{w} 는 task weight를 의미하며 저자들은 task weight 값을 approximate mirror descent 방식으로 업데이트 한다고 합니다. 저자들이 사용한 mirror descent 기반 최적화 알고리즘이 뭔가 하고 찾아보니 20년도에 게재된 강화학습을 위한 최적화 함수인 것 같더군요. 갑자기 웬 강화학습?
일단 저자들은 mirror descent 방식으로 task weight를 새로 업데이트 하였다고 하는데 정확히 어떤식으로 동작하는지 구체적인 설명은 없습니다. 결과적으로 i번째 이터레이션의 마지막에서, 저자들은 최종적으로 t번째 테스크에 대한 새로운 task weight vector \hat{\mathcal{w}_{t}}를 구하게 되며 이는 모든 테스크에 대한 관계성을 나타내고 있다고 합니다. 아래는 저자들이 소개하는 TROA 과정을 코드로 나타낸 것입니다.

대략적으로 살펴보면, task representation \theta 와 decoder m에 대하여 각 테스크 별 loss를 계산해 adam optimizer로 최적화하는 과정이 나타납니다. 그 후, target task에 대한 decoder와 \theta 에 대하여 그 외에 task에 대하여 손실 함수를 통해 계산한 gradient 간에 코사인 유사도를 계산한 뒤 이들 정보를 mirror descent 과정을 통해서 weight를 업데이트한다는 것으로 보여집니다. 근데 제가 공개된 코드를 살펴보니 cos 유사도를 계산하는 부분도, mirror descent가 동작하는 부분을 찾아보려고 했으나 보이지 않았는데.. 코드를 일부만 공개해서 그런 것인지 깊은 이해를 할 수 없어 아쉽습니다.
결과적으로 저자들이 학습을 통해서 만든 기울기 기반 task affinities matrix는 아래 그림과 같이 나타낼 수 있습니다.
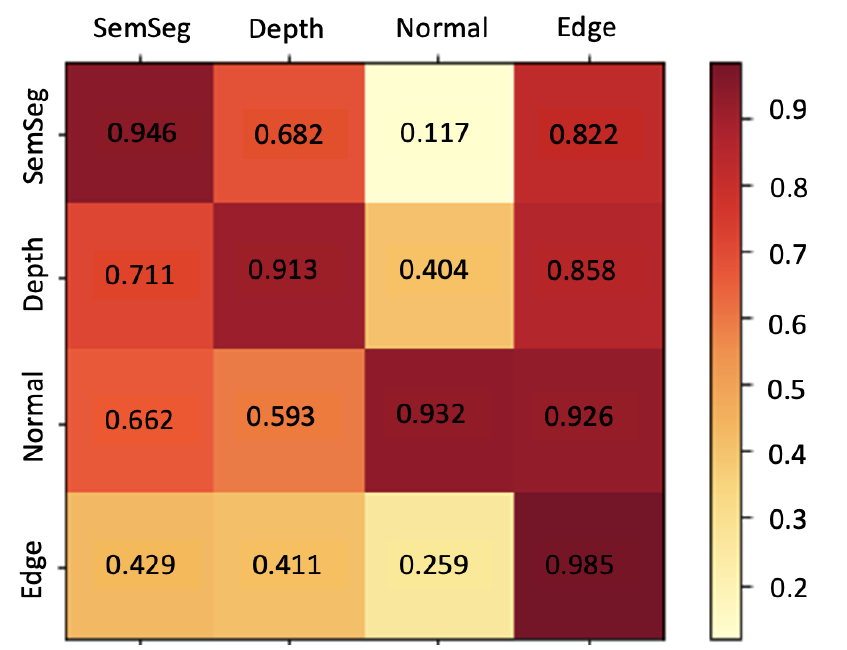
위에 그림에서는 4개의 task에 대해서 나타낸 것이라 task affinity matrix \hat{\mathcal{w}} 가 4×4 행렬 꼴로 나타나는데 task의 개수가 N개면 NxN 꼴로 나타난다고 이해하시면 되겠습니다.
참고로 대각행렬 부분은 자기 자신에 대한 task의 관계성을 나타낸 것으로, TROA는 같은 테스크의 그레디언트 사이에서는 테스크 연관성을 상당히 잘 학습한다고 저자들은 주장합니다. 그리고 task 의존성은 비대칭적인데, 가령 세그멘테이션은 surface normal detection task에는 영향을 주는 정도가 0.117로 미미하지만 그 반대의 경우에는 0.662로 상대적으로 높은 모습을 보여줍니다.
Task-Adapted Attention (TAA)
다음은 저자들이 제안하는 Adapter 모듈 내 Attention 연산을 담당하는 TAA 모듈에 대한 설명입니다. 우선 TAA의 구조는 아래와 같이 구성되어 있습니다.

우선 TAA 모듈의 입력으로는 이전에 다루었던 TROA를 통해 계산된 task affinity matrix \hat{\mathcal{w}} 과 attention 연산을 위한 task representation \hat{\theta} (지금 보니 \hat{\theta} 는 encoder를 통해 타고 나온 feature map인 것 같네요.]) 를 통해 추출된 Query, Key, Value 값이 사용됩니다.
이러한 Query, Key, Value 그리고 task affinity matrix \hat{\mathcal{w}} 는 아래 수식을 통해 서로 attention 연산을 수행하게 됩니다.
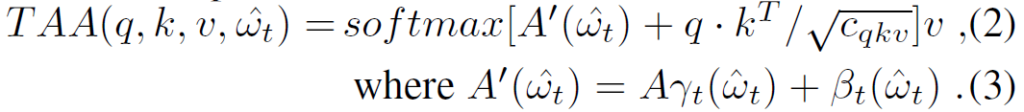
여기서 \hat{\mathcal{w}} 를 특정 task t에 대하여 길이 N의 affinity vector 형식으로 나타낸 것이 \hat{\mathcal{w}_{t}} 입니다. 즉 Nx1 짜리 길이의 affinity vector를 수식3 과정을 거치게 되면 task representation과 동일한 spatial representation을 가질 수 있는 행렬 A’를 계산할 수 있게 됩니다.
이러한 계산 과정을 그림5에서는 Feature Wise Linear Modulataion(FiLM)이라고 표기를 하였는데, 이 FiLM은 이전에 text와 image 사이에 multimodal 특징을 연구하는 분야에서 예전에 제안된 기법으로 한쪽 모달리티 특징으로부터 \gamma 와 \beta 를 추출하고 이를 다른 쪽 모달리티 특징에 feature transformation 하는 방법론입니다.
저자들은 task affinity vector를 이용해 task representation을 가중 평균을 수행한 다음, fc layer를 통하여 shift, scale 상수를 계산하고 이를 learnable matrix A에 수식3 연산을 적용시켜 A’을 만들었다고 합니다. 그림5 우측에서 FiLM의 과정을 확인하라고 하는데, 사실 그림만으로는 이해하기에 내용이 상당히 부족하며 텍스트로 작성된 글 조차도 구체적인 설명이 없습니다. 그저 과정을 나열하는 식으로 서술되어 있는데 적어도 구체적인 입출력의 관계와 shape을 나타내주면 좋았을텐데 task affinity weighted embedding이나 weighted averaging 과정을 단순히 text로만 표기하고 과정을 생략해버린 것이 아쉽네요. 공개된 코드를 살펴봐도 이와 관련된 과정 내용이 전혀 없어서 아마 코드를 일부만 공개한 것이 아닌가 싶습니다.
결과적으로, task affinity vector를 통해 성공적?으로 matrix A’을 생성하였다면 해당 matrix는 Query와 Key 사이에 한 결과 값에 내적 연산을 한 뒤 element-wise summation 됩니다. 그리고 해당 결과 값은 softmax 연산 처리 후 value matrix와 행렬 곱을 수행하게 되는데, 그림5에서 matmul과 dot product를 따로 구분지은 것 봐서는 dot product가 element-wise product이고 matmul이 내적을 의미하는 것 같습니다.
그리고 이러한 Task-Adapted Attention 과정은 multi head로 수행되기 때문에 각 헤드에 나온 결과값을 concat하여 최종적인 feature를 생성합니다. 저자들은 3 stage 내에 존재하는 adapter에 대해서는 head의 개수를 24개로 취했으며, 4 stage 내에 존재하는 adapter에 대해서는 48r개의 head를 사용했다고 합니다.
Task-Scaled Normalization (TSN)
다음은 저자들이 제안하는 Adapter 모듈 내 마지막 contribution인 Task-Scaled Normalization 에 대한 내용입니다. 저자들은 이전의 TAA 과정을 통해 계산된 feature들이 특정 task t에 대하여 스케일이 편향되어 있기 때문에 여러 task를 수행하는 관점에서 이들 간의 스케일을 정규화해주는 과정이 필요하다고 합니다.
그래서 저자들은 Conditional Batch Normalization이라고 하는 예전 기법을 기반으로 Task-scaled Normalization 방법론을 제안합니다.
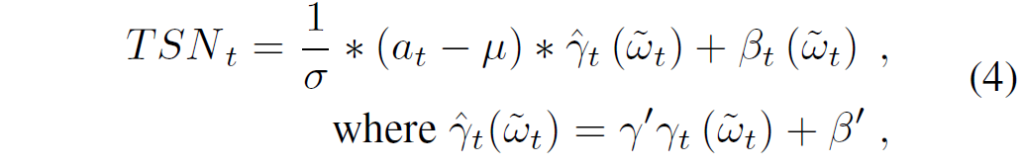
a_{t} 는 그림 3에서 보실 수 있듯이 residual connection으로부터 task-specific한 activation값을 의미하며 \tilde{\mathcal{w}} 는 residual connection이 포함된 feed-forward network의 출력의 합을 의미합니다.
그리고 \mu, \sigma, \gamma', \beta' 는 각각 Layer Normalization에서 계산되는 각 레이어에 대한 모든 입력의 평균과 분산 및 사전학습된 Swin Layer normalization의 weight와 bias를 의미합니다. 저자들은 TSN이 기존 Layer Norm과 비교해서 2가지 차별점이 존재한다고 하는데 첫째는 Layer norm의 경우 가중치와 편향이 고정되는 반면에, 자신들은 일부 weight와 bias가 꾸준히 학습된다는 것이며(아마 Swin Layer norm이 freeze되어 고정됨을 의미하는 것 같네요.) 둘째로는 Layer norm이 특징들을 가로질러 입력으로 받는다면, TSN은 task weight를 기반으로 normalization output을 낸다는 이점이 있다고 주장합니다. 2번째 이점은 무슨 말인지 잘 모르겠네요? 그냥 task weight 기반으로 정규화한다는 것이 저자들이 강조하고 싶은 내용이 아닐까 싶습니다.
Decoder Module
디코더 모듈은 비교적 단순합니다. 디코더는 각 task별로 하나씩 구성되어 있는데, 인코더와 동일하게 4개의 stage로 구분되고 각 스테이지 별 2개의 transformer 디코더 블록이 구성되어 있습니다. 이러한 transformer block은 모두 swin transformer 구조를 그대로 활용하고 있습니다.
저자들은 각 스테이지가 끝날때마다 해상도를 2배씩 키웠으며, 트랜스포머 내 어텐션 연산 시 사용되는 multi-head의 개수도 48, 24, 12, 6으로 스테이지가 끝날때마다 2배씩 줄여나갔습니다. 해상도가 커지다보니 연산량을 고려하여 헤드의 개수를 줄인 것 같네요.
또한 task 별로 디코더가 구분되기에 최종적인 추론을 위한 각 task 별 head도 구성이 되어 있습니다. 모델 학습은 각 task에서 계산된 loss를 선형적으로 합쳐서 adapter와 디코더를 학습시켰으며, loss는 당연하게도 모델이 추론한 결과와 각 task에서 제공하는 GT와의 비교를 통해 계산한 supervision 입니다. 조금 더 디테일하게는 Segmentatation은 Cross Entropy loss, Depth는 rotated loss, surface normal과 2d edge detection은 l1 loss를 사용했다고 합니다.
Experiments
그럼 실험 섹션에 대해서 다루고 리뷰 마무리 짓도록 하겠습니다.
논문에서 다루는 task는 크게 4가지로, 위에 loss 함수에서도 소개드렸듯이 Segmentation (S), Depth Estimation (D), surface Normal (N), 2D sobel texture edges (E)로 구성이 됩니다.
또한 저자들이 수행한 실험의 종류는 크게 4가지로 (1) 하나의 데이터셋에서 위 4가지 task들 중 복수 개의 task를 동시에 학습시키는 Multitask Learning (MTL) 방식, (2) A 데이터셋으로 N개의 task를 학습하고 A와 유사한 B 데이터셋에서는 1개의 테스크만 재학습한 뒤 N-1개를 학습 없이 평가하는 Zero-shot task transfer 방식, (3) A로 학습하고 A와 유사하지만 실제 분포는 다른 B 데이터셋을 UDA 방식으로 학습한 Unsupervised domain adaptation 방식, (4) 마지막으로 학습 때 전혀 보지 못한 데이터로 평가하는 Domain Generalization 방식이 존재합니다.
가장 기본적인 MTL 학습 방식의 경우 저자들은 각 task 조합에 대해 완벽하게 지도 학습 방식으로 수행되었다고 하며, 실험 테이블에서 가령 ‘S-D’, ‘S-D-N’, ‘S-D-N-E’ 형식으로 나오면 이는 각각 위에 Segmentation ,Depth, normal, edge의 task들을 조합한 방식이라고 이해하시면 될 것 같습니다.
Zero-shot task transfer의 경우 모든 방법론들은 처음 Virtual KITTIv2 데이터셋으로 학습 후, Cityscape 혹은 Synthia 데이터셋에서 파인튜닝 및 평가를 수행하게 되는데, 만약 ‘S-D’ 조합이라면 GT segmentation label을 통해 segmentation만을 fine-tuning하는 것이고, ‘S-D-N’의 조합이면 GT segmentation, depth로 fine-tuning 후 surface normal은 학습 없이 평가한다고 생각하시면 됩니다.
UDA 세팅의 경우 source와 target 도메인이 서로 다른 데이터 분포를 가지고 있으며, 여기서 source 도메인으로는 supervised learning을, target data에 대해서는 source domain으로 학습 시킨 모델의 pseudo-labeling 과정을 통한 target domain에서의 fine-tuning 과정을 거치는 것으로 파악됩니다. (정확하지 않음.)
Domain Generalization은 zero-shot inference랑 동일하기 때문에 학습 때 보지 못한 데이터로 평가만 하면 되는지라, Taskonomy 데이터셋으로 모델을 학습시키고 NYUDv2로 평가를 진행하였다고 하네요.
Quantitative results
그럼 MTL 실험부터 차근차근 정량적 결과를 비교해보겠습니다.
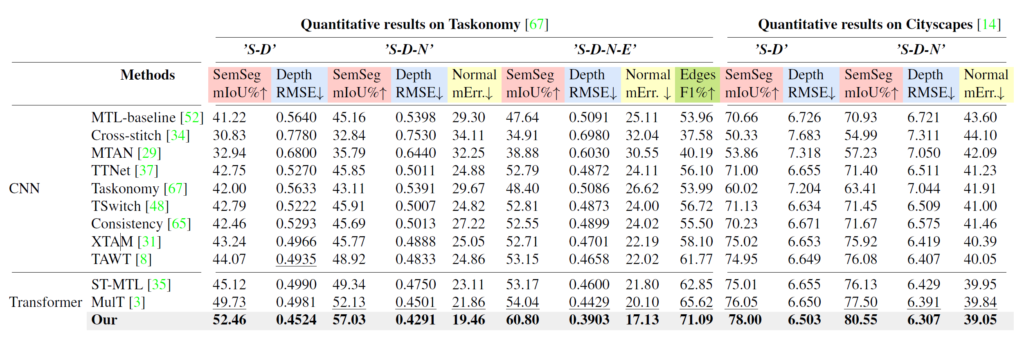
우선 기존의 CNN 기반 방법론들과 저자들이 제안한 방법론을 포함한 Transformer 기반 연구들의 성능을 비교한 것입니다. 가장 좋은 성능은 bold, 2번째로 좋은 성능은 밑줄 처리가 되어 있습니다. 일단 가볍게 살펴보면, transformer 기반의 방법론이 CNN 기반 방법론들보다 대부분 더 좋은 성능을 보여준다는 점입니다.
그리고 둘째로 저자들이 제안하는 방식이 어떠한 task 조합이라고 할지라도 항상 더 좋은 모습을 보여준다는 점이겠네요. 재밌는 점은 단순히 Segmentation과 Depth estimation 조합으로 학습한 것보다, Surface Normal과 Edge를 추가로 학습할 경우 Segmentation과 Depth의 성능이 더 크게 개선이 되었다는 점입니다. 이것이 바로 Multitask learning의 바람직한 이점을 그대로 간직한 것이 아닐까 라는 생각이 드네요.

다음은 zero-shot task transfer에 대한 실험입니다. 위에서도 소개드렸다시피 해당 실험의 경우는 VKitti 데이터셋으로 S-D, 또는 S-D-N 각 테스크를 먼저 사전에 다 학습한 후, Cityscape 데이터 셋에서는 Segmentation 또는 S & D task에 대해서만 fine-tuning하고 그 나머지 task에 대해서는 평가만 한 결과를 의미합니다.
저자들은 MulT 방법론을 자신들의 baseline 방법론이라고 소개하며, 이들 방법론의 성능과 비교하였을 때 depth와 Surface normal에서 각각 0.196, 1.59 point 더 좋은 성능을 보여주었다고 합니다. 결과적으로 fine-tuning하였을 때의 성능 뿐만 아니라, fine-tuning을 하지 않은 task에 대해서도 다른 방법론들과 비교해서 더 우수한 성능을 보여준다는 것이 저자들이 주장하고자 하는 바입니다.

다음은 UDA 관련 실험입니다. 학습 세팅은 VKitti dataset으로 사전학습 후 Cityscape에 대하여 target domain에 대해 UDA 방식으로 재학습 후 평가하였다고 하고, task는 ‘S-D’ 조합입니다.
또한 아래 1-task Swin target (Oracle)은 target data에서 labeled set으로 학습한 결과값이라고 하는데, 무엇을 의미하는지는 잘 모르겠지만 아무래도 UDA의 upper 결과값을 나타낸 것이 아닌가 싶네요?
아무튼 저자들이 제안하는 방법이 다른 방법론들과 비교해도 성능이 더 좋은 모습을 보여줍니다. 생각보다 segmentation과 Depth에서 꽤 큰 폭의 성능 차이를 보여주는데, 확실히 backbone을 freeze하고 adapter 기반으로 일부 레이어들을 fine-tuning하는 것이 UDA 측면에서 큰 성능 향상을 보여주는 것이 맞는 것 같습니다.
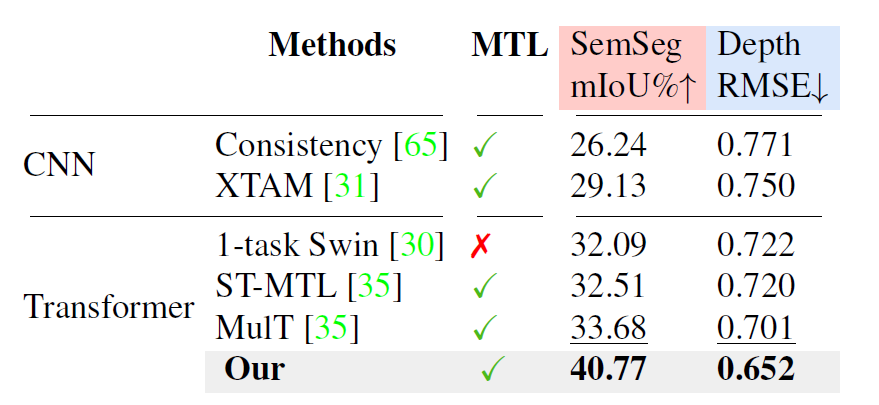
마지막으로 Domain Generalization에 대한 결과입니다. 여기도 마찬가지로 저자들이 제안하는 방법론이 다른 방법론들과 비교해서 가장 좋은 성능을 보여주네요. 참고로 모든 모델이 학습할 때 taskonomy 데이터 셋을 사용했으며, NYUDv2 데이터셋에 대하여 학습 없이 평가만 진행한 것인데, 이는 도메인들 넘어서 task 관계성이 유사한지를 찾기 위함이라고 합니다. 예를 들어, 저자들이 제안하는 TROA는 Segmentation과 Depth 사이에 task 유사도를 잘 측정하였으며, TAA를 통해 이러한 관계성을 뭐 더 돈독히하였기에 비록 학습 때 보지 못한 완전히 다른 도메인 데이터 셋일지라도 더 좋은 일반화 성능을 보여주었다~라며 이야기를 하는 모습입니다. 그냥 저자들 방법론이 잘 동작한다를 어렵게 설명한 것 같네요.
Parameter Comparison
마지막으로, 저자들은 학습에 사용되는 파라미터의 수와 학습 때 소요되는 시간을 비교한 결과를 보여줍니다.
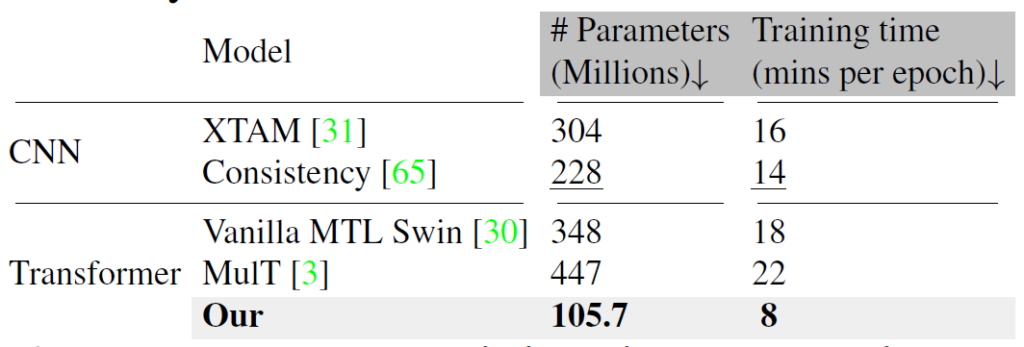
보시면 다른 연구들과 비교해서 학습에 사용되는 파라미터의 수도 적으며 소모되는 시간 역시 제일 작은 모습인 것을 확인할 수 있습니다. adapter 논문들이 하나같이 어필하는 것이 학습에 소요되는 파라미터의 수가 적다는 점을 어필하는데 여기서는 특히 학습 시간도 현저히 줄어든다는 것을 어필했네요.
개인적으로 추론 속도도 얼마나 차이나는지가 궁금했는데 이러한 추론 속도는 함께 보여주지 않은 것이 아쉽게 느껴집니다. 게다가 비록 학습에 소요되는 리소스는 적어보이지만 결국 기본 모델에 adapter를 추가로 적용한 것이기 때문에 추론 관점에서 기존 모델 대비 GPU 메모리나 추론 시간이 더 늘어나게 될 것인데 이런 것들은 아무래도 약점이 되서인지 따로 공개하지는 않는 모습이네요.
결론
성능이 다른 연구들과 비교해 큰 폭으로 좋고, 기존의 Multitask learning 연구들은 다루지 않는 실험들(zero-shot task transfer, Domain Generalization)을 보여주었다는 점 등에서 좋은 점수를 받아 ICCV에 게재된 것이 아닐까 싶습니다. 본 논문에서는 ablation study 조차도 다루지 않으며 supplementary에 다 박아놓은 모습을 보면 실험의 양도 많았기 때문에 더더욱 인정받은 것 같지만, 개인적으로 방법론에 대한 보다 자세한 설명도 없고, 글도 너무 헷갈리게 작성하는 등 아쉬운 점도 분명한 논문인 것 같습니다.
좋은 리뷰 감사합니다.
최근 foundation 모델(SAM, DINOv2)들은 ViT 기반이기도 하고 adapter 를 사용하는 방법이 흥미롭네요.
주중 신정민 연구원님의 세미나를 들으면서 제가 놓친 것일 수도 있으나, ‘foundation 모델을 학습할 때 adapter를 사용하면 더 좋은 효과를 보인다’ 로 저는 이해를 하였습니다. adapter가 대용량 데이터를 통한 모든 학습 방법에는 적용하기 적절한 것으로 보면 될까요? foundation 모델은 아니지만, 예를 들어 ImageNet을 학습시키는 어떤 사전학습 모델을 만든다고 했을 때 적용하여도 적절한 것인지 궁금합니다.
감사합니다.
안녕하세요.
adapter의 역할에 대해서 살짝 혼동이 있으신 것 같아 설명드리면, adapter는 foundation model이 대용량 데이터 셋으로 사전 학습을 할 때 추가되어 학습되는 것이 아니며, 대용량 데이터로 충분히 사전 학습이 되었다면 그 이후에 downstream task 혹은 subset으로 fine-tuning하는 단계에서 추가되어 학습이 되는 것을 의미합니다.
이는 보통 대규모 모델 혹은 대용량 데이터로 모델이 학습하였다면 그 weight는 상당히 좋은 일반화 성능을 보여줄 것이기 때문에 이들 레이어의 가중치를 subset에 대하여 fine-tuning하는 것은 해당 task/dataset에서만큼은 좋은 성능을 보여줄 수 있겠으나 unseen task/dataset에서는 그 성능이 훼손될 수 있습니다.
따라서 adapter를 통해 대신 그 모델이 subset에 fitting되어 잘 동작할 수 있도록 기존의 사전학습된 레이어들은 freeze 시킨 뒤 adapter와 일부 레이어들만을 조금씩 fine-tuning하는 것이 adapter 논문들의 framework이라고 이해하시면 좋을 듯 합니다.
감사합니다.