Introduction
Speech emotion recognition이란 음성 신호로부터 대상의 감정을 인식하는 task입니다. 인간의 의사 소통에서 감정은 행동이나 욕구에 반영되는 중요한 정보로 작용하기 때문에 human-computer interaction에서 Speech Emotion Recognition (SER)은 사용자의 감정, 태도, 그리고 욕구를 인지하는 도구로써 활용됩니다. SER은 우리가 일상에서 흔히 사용하는 스마트폰, 홈 어시스턴트, 로봇 등과 같은 엣지 디바이스에 널리 적용할 수 있는데요, 이에 따라 다양한 사용 환경에서도 감정을 정확히 인식할 수 있도록 robust 하고 adaptable한 알고리즘을 설계하는 것이 중요합니다.
그러나 SER은 음성의 녹음 환경, label 체계, data의 bias 등 여러 요소들로 인해 일반화 성능 저하가 발생하게 되는데요, 이러한 요소들로 인해 감정 데이터셋 뿐 아니라 real-world에서도 SER이 잘 동작하지 않게 될 수 있습니다. 이러한 문제를 해결하기 위해 다양한 환경에서 음성 데이터를 수집하고, 이렇게 수집된 대량의 데이터를 한 번에 모델에 학습하려고 하였으나, 음성 데이터는 개인적이고 민감한 정보를 포함하고 있기 때문에 중앙 서버로부터 이전에 모델 학습에 사용했던 데이터와 새로운 데이터를 동시에 사용하여 모델을 재학습하는 것에 문제가 있었다고 합니다.
이에 이 논문의 저자들은 SER 모델이 마지막 사용자의 환경에 adaptation하는 방법이 필요하다고 주장하였습니다. 보다 구체적인 예시를 통해 설명 드리자면, 어떤 사용자가 다양한 음향 환경에서 스마트폰을 사용한다고 할 때, 즉, 사용자가 주로 집에서 스마트폰을 사용하다가 직장에서 더 많은 시간을 보내게 될 경우, 스마트폰의 SER 시스템은 직장의 음향 환경에 적응하여 그 환경에서 더욱 향상된 성능을 보여야 합니다. 그러나 이때, 시스템이 회사의 음향 환경에 최적화되면서 기존의 집에서 동작하던 SER 성능을 유지해야 할 것입니다.
논문에서는 이러한 문제를 continual learning을 통해 해결하고자 하였습니다. 또한 모델이 다양한 음향 환경에 순서대로 노출된다고 가정하여 어떤 정보를 우선적으로 학습할 지에 대해 알아보고자 하였습니다. 이를 통해 SER 모델이 새로운 도메인에 적응하면서도 이전 도메인의 성능을 유지하고, 이전에 모델 학습에 사용한 데이터에 접근하지 않고도 효과적인 학습이 가능해졌다고 합니다.
일반적으로 어떤 도메인에서 학습된 모델을 다른 도메인의 데이터에서 사용하려고 할 때는 fine-tuning을 진행합니다. 그러나 단순히 새로운 데이터셋으로 기존 모델을 학습하게 되면 새로운 학습을 진행할 때 이전에 학습한 데이터를 잊어버리는 현상이 발생하게 됩니다. 이를 catastrophic forgetting 현상이라 하며, 이를 해결하기 위해 memory-based learning method를 사용합니다. memory-based learning method란 이전에 학습에 사용했던 데이터의 일부를 fine-tuning 시 함께 사용하는 것을 의미합니다. 이런 식으로 기존의 지식을 유지한 채 지속적으로 들어오는 새로운 데이터로 학습하는 것을 continual learning이라 합니다. 논문에서는 memory-based learning method가 다양한 음향 환경에서 진행되는 SER에서는 어떻게 동작할 지는 아직 알려지지 않았다고 언급하였습니다.
논문에서는 새로운 도메인의 데이터에 대해 memory-based learning method를 사용하는 SER 모델 학습 기법을 제안하였으며, 이를 위해 다음과 같은 두 가지 질문을 제시하였습니다.
- Can memory-based methods encapsulate varying acoustic environments while preserving properties of emotion?
- Does memory sampling improve these memory-based methods’ ability to overcome forgetting?
이 연구에서는 이전에 본 샘플들의 episodic memory를 저장하기 위해 ExpeR과 Gradient Episodic Memory (GEM)를 기반으로 한 framework를 살펴보았다고 합니다. memory experience replay(ExpeR)과 GEM은 일반적인 fine-tunig 에 비해 일반적인 fine-tuning 접근법과 비교되며, 이전 데이터와 unseen 데이터에 대해 현저히 향상된 성능을 보인다고 합니다.
Related Works
Continual learning은 모델이 시간이 지남에 따라 새로운 데이터로 학습을 계속하면서 과거에 학습한 task도 잘 수행할 수 있도록 학습하는 것을 목적으로 합니다. 따라서 나중에 들어온 데이터로 인한 catastrophic forgetting을 피하는 것이 중요합니다. Catastrophic forgetting이 문제를 해결하기 위한 방법 중 하나는 Experience Replay이며 이는 이전 task의 subset을 활용하는 방법입니다. 이러한 방법은 음성 인식 분야에서는 사용되었으나 아직 감정 인식이나 다양한 음향 환경에서는 사용된 적이 없다고 합니다.
GEM(Gradient Episodic Memory)은 continual learning을 위해 설계된 또 다른 프레임워크로, GEM은 이전에 본 샘플들을 재활용하는 대신, 각 training step에서 memory sample애 대한 loss와 weignt gradient를 계산합니다. 그리고 이전 task에서 계산된 gradient와 현재 batch의 gradient를 비교합니다. gradient가 충돌할 경우, GEM은 업데이트를 방지하고 이전 task의 gradient와 충돌하지 않는 한 최대한 현재 batch의 gradient에 가까운 값을 탐색하여 업데이트를 수행합니다. GEM은 새로운 데이터가 도입될 때 전체 데이터셋에 대한 재학습 피하고 전체 훈련 시간을 개선하기 위해 ASR 문야에서 사용된다고 합니다.
Experiments
Data setup
먼저 논문에서 사용할 데이터셋과 실험 세팅에 관해 설명드리겠습니다.

논문에서는 SER의 continual learning을 다양한 음향 환경에서 진행하고자 하였고, 이를 위해 [표 1]과 같은 서로 다른 세 가지의 데이터셋을 사용하였습니다. 각 데이터셋을 모델이 이전에 본 환경, 현재 처해 있는 환경, 아직 보지 못 한 환경으로 구분하여 성능을 확인하였습니다.
- IEMOCAP
- 총 다섯 개의 session으로 구성된 multimodal emotion 데이터셋으로, 각 세션은 두 명의 배우의 대본 연기 혹은 즉흥 대화로 구성됨. 1~3session을 train, 4session을 valid, 5 session을 test로 사용
- MSP-Improv
- 특정 감정이 주어졌을 때 즉흥 시나리오 음성으로 구성됨.1~4를 train, 5를 valid, 6을 test로 사용.
- MSP-Podcast
- 팟캐스트 음성으로 구성. 사전에 train/test/val로 분리되어 있음 데이터셋에 script가 포함되어 있지 않기 때문에, Microsoft Azure 의 ASR로 script 생성.
각 데이터셋을 동일한 방식으로 전처리하여, 음성이 3초 미만이거나 30초를 초과하는 경우 제거하였고, 각 데이터셋에 대해 min-max scaling을 적용하였습니다.
Model architecture
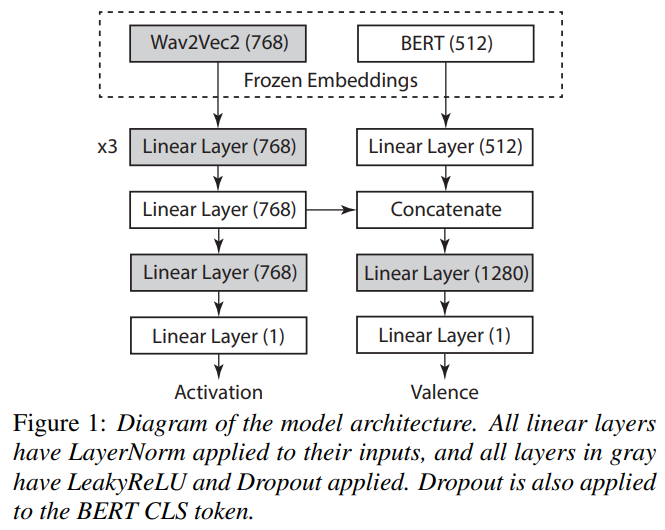
음성과 텍스트 모두를 인코딩하기 위해 사전 학습된 대규모 transformer 모델을 사용합니다. 특히, Wav2Vec2을 사용하여 음향 특성을 인코딩하고, 도메인 간 성능에서 Melspectrogram 특성보다 더 나은 일반화 성능을 보여줍니다. 텍스트 인코딩에는 BERT를 사용하며, 이는 CLS 토큰에 해당하는 hidden state에서 추출됩니다. CLS 토큰에는 0.2의 드롭아웃이 적용되며 결과는 linear 계층을 통해 전달됩니다.
GEM의 계산 복잡성을 고려하여 Wav2Vec2와 BERT 모델을 동결시켜 훈련 가능한 파라미터 수를 줄이고 훈련 시간을 개선합니다. Wav2Vec2를 동결하는 것이 전체 모델을 훈련시키는 것보다는 덜 효과적이지만, 동결된 임베딩은 여전히 유용한 정보를 제공합니다.
이 모델은 activation와 valence에 대해 각각 두 개의 linear 계층을 가진 두 개의 prediction head를 사용하며, 이를 multi task learning을 통해 공동으로 최적화합니다. Wav2Vec2 feature 다음의 첫 세 계층과 각 prediction head의 첫 계층은 각각 0.2와 0.1의 확률로 LeakyReLU와 드롭아웃을 적용합니다. 모든 linear계층은 입력에 LayerNorm을 적용합니다. 또한, BERT 특성이 Wav2Vec2 특성을 사용할 때 활성화 성능을 저하시키기 때문에, BERT feature를 음향 표현에만 정서 예측을 위해 연결합니다. 이러한 접근 방식은 활성화 성능을 저하시키지 않으면서도 정서를 학습함으로써 음향 표현을 정규화할 수 있도록 합니다.
Experiment setup
논문에서는 새로운 도메인의 데이터가 사용 가능해짐에 따라 연속적 학습의 효과를 알아내고자 하였습니다. 특히, 더 제한적인 환경에서 훈련되면서 특정 음향 환경에 맞춰 적응하는 방식으로 일반 모델이 어떻게 변화하는지 조사합니다. 이를 위해 가장 크고 자연스러운 데이터셋인 MSP-Podcast에서 baseline 모델을 학습하는 것으로 시작합니다.
기본 실험은 사전 훈련과 미세 조정으로 구성되며, memory-based method는 baseline의 fine-tuning 단계를 확장합니다. 각 실험의 모델 구조는 동일하며, 모든 결과는 서로 다른 5개의 random seed로 실험한 결과값의 평균과 표준 편차를 나타냅니다.
- 사전 훈련 및 미세 조정:
- 일반 모델을 MSP-Podcast 데이터셋에 대해 사전 훈련합니다. 이 데이터셋은 넓은 범위의 자연스러운 음성 데이터를 제공하여 일반화 성능을 최적화할 수 있는 기회를 제공합니다.
- 사전 훈련된 모델을 더 작은 또는 특정 음향 환경이 강조된 다른 데이터셋(예: MSP-Improv)으로 미세 조정합니다. 이 단계에서 모델은 새로운 음향 조건에 적응하면서도 이전 데이터셋에서의 성능을 유지해야 합니다.
- 메모리 기반 방법의 적용:
- 메모리 기반 방법을 사용하여 미세 조정 단계를 강화합니다. 이는 기존의 훈련 데이터와 함께 새로운 도메인의 데이터를 메모리에 저장하고 이를 반복적으로 재사용함으로써, 모델이 새로운 데이터에 대해 빠르게 적응하면서도 이전 데이터에 대한 지식을 유지하도록 합니다.
본 연구에서 사용된 모델은 사전 훈련 후 각 데이터셋에 대해 순차적으로 미세 조정됩니다. 이 접근 방식은 모델이 다양한 음향 환경에 적응하면서도 이전 환경에 대한 정보를 유지할 수 있는지를 평가하는 데 중요한 역할을 한다고 합니다.
- 사전학습:
- 모델은 가장 크고 자연스러운 데이터셋인 MSP-Podcast에서 처음 훈련됩니다. 이 단계에서 모델은 다양한 자연 음향 데이터를 통해 광범위한 감정과 상황을 인식하는 법을 배웁니다.
- 첫 번째 fine-tuning – MSP-Improv:
- 사전 훈련된 모델은 이후 MSP-Improv 데이터셋으로 미세 조정됩니다. 이 데이터셋은 즉흥적인 시나리오를 포함하고 있어 모델이 예측하지 못한 새로운 음향 환경에 적응할 수 있는 기회를 제공합니다.
- 두 번째 fine-tuning – IEMOCAP:
- 마지막으로, 모델은 IEMOCAP 데이터셋에 대해 추가적으로 미세 조정됩니다. 이 데이터셋은 각본에 따른 및 즉흥적인 대화를 포함하여 인간 간의 감정적 상호작용을 더욱 깊이 있게 포착합니다.
Results
Memory-based approaches
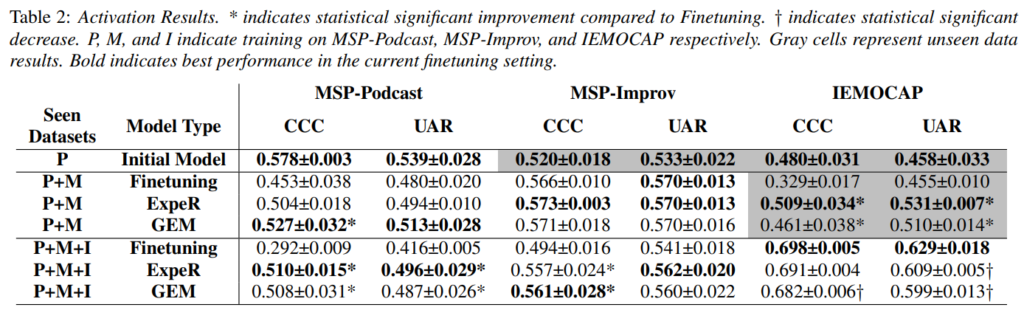
본 논문에서는 다양한 음향 환경에서 메모리 기반 방법이 감정 지식을 어떻게 유지하는지에 대한 연구 결과를 제시합니다. 연구 결과는 통계적 유의성을 검증하기 위해 양측 대응 표본 t-검정을 사용하며, 신뢰도는 95%로 설정합니다.
4.1.1 Baseline
기본 미세 조정 방법을 사용할 때, 모델이 새로운 도메인을 학습함에 따라 기존의 지식을 상당히 잊어버리는 것으로 나타났습니다. 구체적으로, MSP-Podcast에서의 CCC(Concordance Correlation Coefficient)가 0.578에서 MSP-Improv를 거쳐 IEMOCAP으로 미세 조정될 때 각각 0.453과 0.292로 감소했습니다. 또한, MSP-Podcast에서 훈련된 모델이 IEMOCAP에서 더 나은 성능을 보였습니다. 이는 새로운 음성에 대한 단순한 적응이 모델의 성능을 저하시킬 수 있음을 보여줍니다.
4.1.2 GEM (Gradient Episodic Memory)
GEM은 기본 실험보다 이전에 본 데이터셋에서 모든 훈련 단계에 걸쳐 UAR(Unweighted Average Recall)과 CCC에서 더 우수한 성능을 보였습니다. 특히 P+M 설정에서 MSP-Podcast의 CCC가 기본 미세 조정보다 통계적으로 유의미하게 개선되었습니다. 또한, 보지 못한 IEMOCAP의 성능도 기본보다 크게 향상되었습니다. GEM은 MSP-Improv의 학습 제한에도 불구하고 성능을 유지했습니다.
4.1.3 ExpeR (Experience Replay)
ExpeR은 GEM과 비슷한 성능을 보였지만, P+M 설정에서 MSP-Podcast의 성능은 GEM보다 크게 향상되지 않았습니다. 이는 GEM이 더 엄격한 제약을 가지고 있기 때문일 가능성이 있습니다. 기본 방법에서 MSP-Improv에 대한 미세 조정이 MSP-Podcast에 미치는 부정적인 영향이 IEMOCAP에 미치는 영향보다 더 크게 나타났습니다. ExpeR은 새로운 데이터에 적응하는 능력이 GEM보다 약간 개선되었으며, 초기 일반 모델보다 IEMOCAP의 성능을 향상시키는 데 성공했습니다.
Sampling approaches
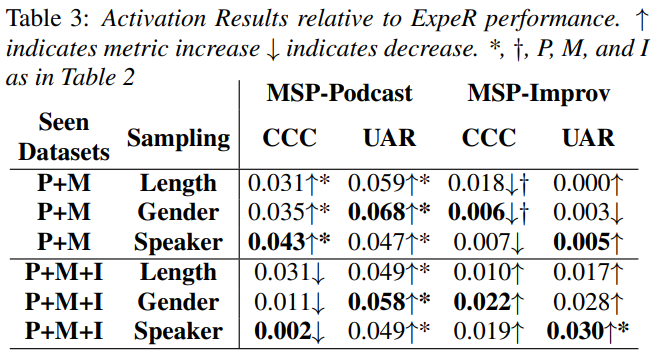
이 연구에서는 메모리에 저장된 샘플들이 모델의 성능과 정보 유지에 미치는 영향을 조사했습니다. ExpeR에 대한 결과만 제시되었으나, GEM에서의 샘플링 결과 추세도 비슷하게 나타났습니다. 표 3은 임의 샘플링에 대한 상대적 성능 향상을 보여줍니다. MSP-Podcast에서는 P+M과 P+M+I 설정 모두에서 UAR(Unweighted Average Recall) 성능이 크게 향상된 것을 관찰할 수 있습니다. 또한, P+M+I 설정에서 MSP-Improv에 대한 성능 유지는 발화자 샘플링에서만 유의미한 향상을 보였습니다.
- 모든 샘플링 방법은 P+M 설정에서 MSP-Podcast의 성능 유지에 유의미한 개선을 보였습니다. 그러나 P+M+I 설정에서는 샘플링이 MSP-Podcast의 CCC(Concordance Correlation Coefficient) 성능을 개선하지 못했으나, MSP-Improv의 CCC 점수는 일부 향상되었습니다.
- 기본 미세 조정 실험에서 P+M 설정에서 MSP-Podcast의 CCC 하락이 가장 컸기 때문에, 샘플링이 서로 충돌하는 도메인이 많을수록 더 유용할 수 있음을 시사합니다.
- UAR이 CCC보다 개선된 것은 메모리 샘플 분포가 활성화 및 정서 구간에서 균등하게 분포되어 있기 때문으로 추정됩니다. CCC의 경우, 이러한 균형이 문제가 될 수 있습니다. 왜냐하면 메모리 샘플 분포가 데이터셋 간에 일치하지 않기 때문입니다.
안녕하세요. 좋은 리뷰 감사합니다.
이전에 연구미팅을 통해서 간략하게 설명을 들었지만 잘 이해가 되지 않아 읽게 되었습니다. 제가 기존의 알던 방법론과는 처음 접한 방법론을 사용하여 흥미가 돋는 방법론인거 같습니다.
1) 궁금한 점이 있는데, 이 논문의 방법론이 multi-task 방법론인거 같은데 왜 굳이 multi-task learning을 하여서 학습을 하는 건가요? 단순히 single-task로만으로도 잘 학습시킬 수 있을 거 같은데 multi-task로 학습하는 이유가 잘 와닿지 않습니다.
2) 또한, 모델 구조를 보면 최종적인 예측 결과물이 activation과 valance인데 이 둘 중에 어떤 것을 이용하여 ccc를 계산하는 것인지, UAR을 계산하는 것인지 잘 이해가 되지 않는데, metric을 계산하기 위해서 사용되는 값은 어떤 것인가요?
3) 본 논문의 모델 구조를 보면 결국에는 text와 speech 모두를 필요로 하는 것 같은데, 만약 speech만 제공되었을 경우 ASR로 통해서 script를 만들었을 때 script의 정확도에 따라 성능이 많이 달라지나요?
감사합니다.