
안녕하세요.
오늘 리뷰할 논문은 Object Detection 분야에서의 TTA 논문입니다.
최근 몇달동안의 제안서 작업에서, 관련 분야를 서베이하다가 발견한 논문입니다.
서울대 곽노준 교수님 연구실에서 작성된 논문이며, arXiv 인 줄 알았더니 CVPR 2024 에 억셉된 논문이더군요.
Detection 관점에서의 TTA 기법 설계, TTA에서의 adaptor 활용, contribution의 간결&명확함, 그리고 매끄러운 서술 등 여러가지 측면에서 만족도(?)가 높은 논문이였습니다.
그럼 리뷰 시작하도록 하겠습니다.
1. Introduction
1.1. Previous TTA works for Classification
Semantic Segmentation, Object Detection 등의 분야에서도 TTA 연구가 수행이 되고 있긴 합니다만, 많은 TTA 연구들은 classification task를 수행하는 데에 설계 포인트가 맞춰져 있습니다. 또한 해당 연구들은 TTA 수행 시 Batch Norm layer 또는 뒷단의 classification head만을 최적화 하는 방식을 사용하게 되죠.
그렇기 때문에 이런 기존 연구들에서 설계한 TTA 기법들을 그대로 Object Detection 분야에 적용하는 데에는 여러 제약사항이 존재합니다.
Batch Norm layer를 최적화하는 방식은 아무래도 CNN 계열이 아닌 Transformer 계열의 Detector에는 적용이 불가능하고, classfication head만을 최적화하는 방식은 Detector의 task적인 고려가 부족하기 때문에 일반화된 성능을 기대하기 어렵죠.
1.2. Previous TTA works for Object Detection
본 논문 말고도 Object Detection을 타겟으로 한 앞선 TTA 연구들이 존재합니다. Introduction에서는 3가지 방법론들에 대해 간단한 설명을 진행합니다.
<ActMAD>
[CVPR 2023] Actmad: Activation matching to align distributions for test-time training.
CNN 계열의 모델이라면 백본 혹은 detection module 내에 BN layer가 있을텐데, ActMAD는 test 단계에서 BN layer를 통과한 후의 각 feature map의 분포를 train domain과 유사하게 정렬하는 방식으로 동작하게 됩니다.|
다시 말해, train 단계에서 모델의 각 단계 별 feature map에 대한 통계값(평균, 분산)을 미리 offline 단계로 save해 놓은 이후, test 단계에서 동일 단계의 feature map에 대해 미리 계산해둔 통계값(평균, 분산) 과의 loss 계산을 수행하는 것이죠. 아래 그림을 참고하시면 됩니다.
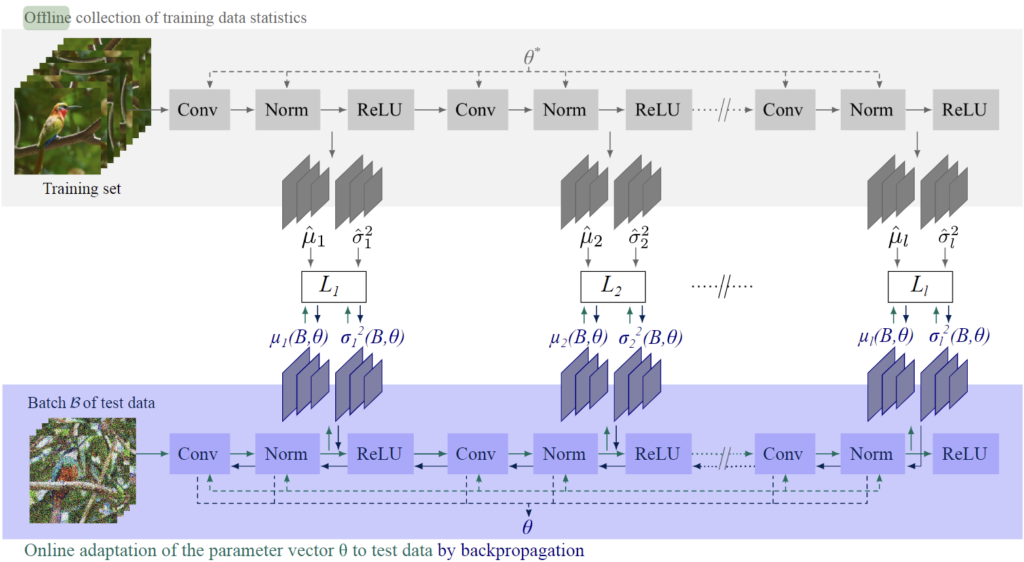
하지만 위 ActMAD 방식은 adaptation 수행 시 모든 단계에서 feature map alignment를 수행하기 때문에 메모리 및 시간이 상당히 소요됩니다. 만약 목표하는 task가 실시간성이 중요하다면 더욱 치명적이겠죠.
또한 Object Detection을 위한 명시적인 고려가 없습니다. 이 말은 즉슨, 이미지 내 object에 대한 명시적인 loss 설계가 없고, 단순 전체 feature map에 대해 alignment를 수행한다는 것이죠.
<TeST, STFAR>
[WACV 2023] Test: Test-time self-training under distribution shift
[arXiv 2023] Stfar: Improving object detection robustness at test-time by selftraining with feature alignment regularization
이 2가지 방법론들은 Teacher-Student 구조를 가지는 논문입니다.
이중 STRAR는 EMA update 기반의 teacher이며, TeST는 미리 stage1에서 pre-train을 시키는 방식으로 teacher를 구성합니다.
하지만 이런 Teacher-Student 구조를 기반으로 TTA를 수행하게 되면 adaptation 수행 시 forward를 2번(student, teacher) 수행해야 합니다. 즉 그만큼 연산량이 많다는 것이죠.
그리고 두 방법론 모두 모델 내 모든 parameter를 update하는 방식을 채택하고 있는데, 이는 online 상황에서의 update 속도 저하가 발생합니다.
또한 test 환경이 continual하게 여러 domain 변화가 일어나거나 급작스럽게 변화하는 경우 task-specific knowledge를 잃어버리는 현상이 발생하게 됩니다. 미리 source dataset에 대한 풍부한 표현력을 가지는 모델을 조금씩 조금씩 test domain으로 update 해야 하는데, 급작스럽게 update를 많이(?), 급격하게 수행하게 되므로 knowledge를 잃어버리게 된다~ 뭐 이런 뜻입니다.
1.3. TTA for Object Detection on this paper
따라서 저자들은 위 문제점들을 모두 커버하는,
object detection을 위한 efficient continual test-time adaptation (CTA) 기법을 설계하게 됩니다.
그리고 크게 3가지 측면에서 전체 논문을 서술합니다.
i) What to update
As is
바로 윗 단락의 TeST, STFAR 설명에서 말씀드렸다시피,
TTA 수행 속 모델을 update 할때 모든 parameter를 update하는 full fine-tuning을 진행하게 되면 매우 비효율적일 뿐 아니라, task-specific knowledge를 잃어버리게 됩니다.
(저자는 Object Detection task가 classification 대비 복잡하기 때문에, task-specific knowledge를 잃어버리기 쉽다고 합니다)
또한 일반적으로 classification 에서 많이 사용하는 Batch Norm update 방식은 보통 test 단계에 입력으로 들어오는 batch 에 대해 평균, 분산값을 구해서 parameter update를 진행하게 됩니다. 즉 해당 과정은 batch size가 클 수록 더 다양한 정보가 반영된다는 것인데, classification대비 Object Detection은 상대적으로 더 작은 batch size를 사용하기 때문에 해당 방식을 그대로 사용하는 것은 부적합하다고 합니다.
또한 Batch Norm layer는 CNN에서만 사용되기 때문에, Transformer 등의 타 architecture로의 일반화된 적용이 불가능하죠.
To be
이를 해결하고자 저자는 매우 가벼운 adaptor를 전체 architecture에 부착합니다.
그리고 adaptor 외의 타 parameter는 모두 freeze를 하고, TTA 수행 시 adaptor의 parameter만 update하게 됩니다.
이러한 방식을 통해 속도 및 메모리적 강점을 가지게 됩니다.
또한 full fine-tuning이 아니라 adaptor만을 udpate하기 때문에 continual domain shift 상황 속에서 catastrophic forgetting 문제를 방지할 수 있다고 합니다.
ii) How to update
As is
앞선 TTA for OD 연구 중 TeST, STFAR 에서 사용한 teacher-student 기반의 기존 연구들은 forward 과정을 2배로 수행해야 하기 때문에 TTA의 실시간성이 매우 떨어집니다.
또한 ActMAD는 train 과 test의 feature map alingnment를 수행하는데, 이는 object level로의 고려 없이 단순히 image level로의 alignment만 수행하기 때문에 Object Detection적 관점에서는 그리 효과적이지 못합니다.
(앞 단락에서 설명드린 내용입니다)
To be
그리하여 본 논문에서는 image-level 뿐만 아니라 object level도 함께 고려하여 feature map alignment를 수행하게 됩니다. 구체적으로는, train과 test 각 feature의 mean & variance를 맞춰나가는 방식이죠.
구체적인 사항은 Method에서 살펴보도록 하겠습니다.
핵심은 Object Level에 대한 고려도 했다는 것입니다.
iii) When to update
As is
대부분의 TTA 그리고 Continual TTA 에서는 입력으로 들어오는 모든 test sample에 대해 지속적으로 update를 수행합니다. 물론 계속해서 새로운 domain input이 입력으로 들어오게 된다면 계속해서 update를 하는 것이 맞기는 합니다.
하지만 test domain의 변화가 이전 batch와 비교했을 때 크지 않은 경우에는 이미 현재 버전의 모델로도 충분히 현재 test sample에 대한 예측이 가능할테고, 이런 상황에서 굳이 지속적으로 update를 하는 것은 비효율적이라고 문제를 삼습니다.
To be
본 논문에서는 추가적인 cost 없이, 단순히 2개의 새로운 criterion을 도입해서 모델 입장에서 adapation이 필요한 시점을 결정하도록 하였습니다.
이에 대해서는 아래 그림을 통해 설명드리겠습니다.

x축을 나타내는 Time Step t가 지날수록 점차적으로 새로이 domain이 continual하게 변화는 상황이며, y축은 이에 따른 detection mAP 성능을 나타냅니다.
4가지 그래프 중 회색 점선(Direct-Test)는 아무런 TTA 기법이 적용되지 않은 성능이며, source에 대해 학습된 모델로 예측만 수행한 결과입니다. lower bound에 해당하겠죠.
또한 Full-Finetuning은 이전 연구들에서 사용한, 모델 전체를 update 하는 방식입니다.
초반 2종류의 도메인 변화에 대해서는 ours와 유사한 성능을 보여주는데, time이 점차적으로 지날수록 성능향상이 매우 낮은 것을 볼 수 있습니다. 위 intro에서 설명드린, continual domain shift 상황 속에서 catastrophic forgetting 현상이 나타난 것이죠.
그리고 핑크색 Ours는 본 논문에서 설계한 방식이며, 노란색 Ours-Skip이 2개의 새로운 criterion을 도입해서 모델 입장에서 adapation이 필요한 시점을 결정하는 방식입니다.
성능적으로는 핑크색 Ours가 아주 조금 더 높아 보이지만, 다른 효율성 측면으로는 Ours-Skip이 더 좋다고 합니다. 그래서 본 논문에서는 Ours-Skip을 efficient TTA 라고 표현하네요.
2. Method
위 intro 설명에서 As is -To be 형식으로 3가지 측면에 대해 자세하게 다뤄 보았습니다.
그렇기에 본 Method 단락에서는 핵심 요소들만을 짚어 설명드리도록 하겠습니다.
2.1. What to update: Adaptation via an adaptor
본 논문에서는 CNN 뿐만 아니라 Transformer 기반의 모델에서도 TTA 기법이 잘 동작할 수 있도록 하기 위해 BN layer update 기반이 아닌, Adaptor 개념을 적용하였습니다.
(사실 Adaptor란 개념을 새로 도입한 건 아닙니다)
아래 그림은 CNN과 Transformer 각 architecture별 adaptor의 구조입니다. 매우 간단한 구조를 가집니다.
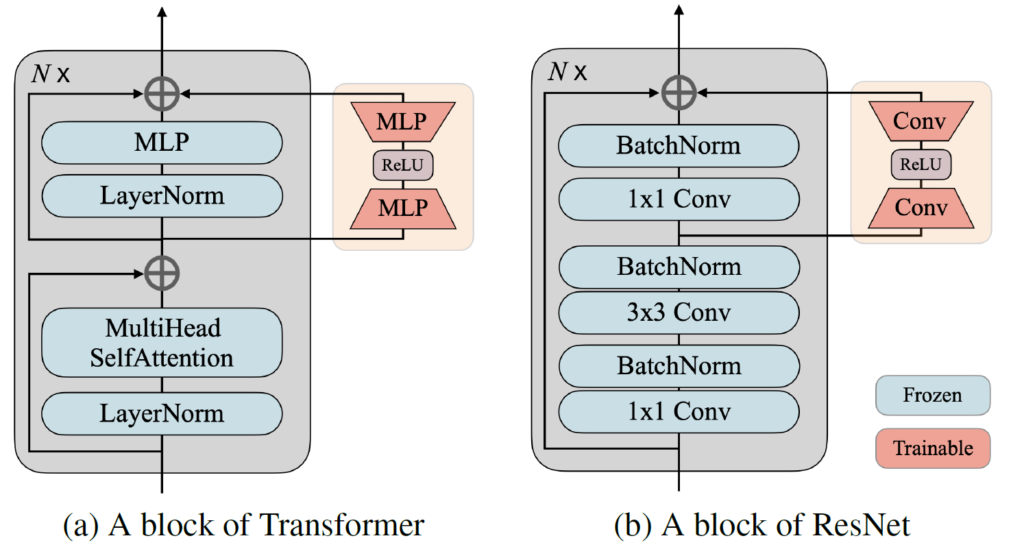
좌측 Transformer 구조 내 Adaptor는 MLP->ReLU->MLP 구조를 사용하며,
우측 CNN(ResNet) 구조 내 Adaptor는 1×1 Conv->ReLU->1×1 Conv 구조를 사용합니다.
둘 모두 downsample->upsample 형식으로 진행되는데, 이때의 ratio는 32입니다.
그리고 구현 레벨에서 조금 특이한 점이, upsample 을 수행하는 layer의 weight는 초기에 0으로 세팅한다고 합니다. 초기 0으로 부터 출발해서, 입력으로 들어오는 test domain에 대해 맞춰서 update를 진행해 나가는 방식입니다.
그리고 앞선 intro에서도 설명드렸다시피, Adaptor를 제외한 타 parameter는 모두 freeze합니다.
2.2. How to update: EMA feature alignment
본 논문에서는 image level의 alignment 뿐만 아니라, object level의 alignment도 고려합니다.
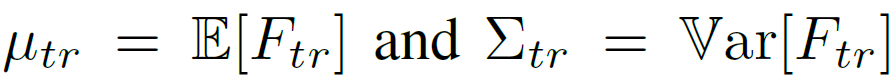

위 식은 train data의 평균 및 분산을 구하는 식입니다.
위 식 속 g는 백본을 뜻하며, x_{tr} 은 학습 이미지, 그리고 식 1의 output은 각각 계산된 평균, 분산을 의미합니다.
본 논문에서는 학습 데이터로부터 추출된 feature F_{tr} 을 계산하는 데에 2,000장의 training samples를 사용했다고 합니다. 그리고 test 단계에서 feature의 평균, 분산을 구할 때에 아래 식을 통해 EMA update 기반으로 계산을 수행한다고 합니다.
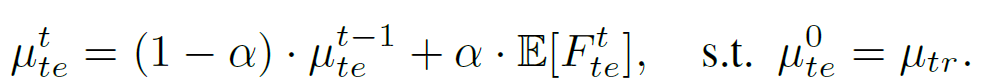
time t=0 일 때의 test feature 평균은 train에서 계산한 값과 동일한 값을 사용하며, time1,2,,, 로 지날수록 점차적으로 alpha=0.01 의 가중치와 함께 update 됩니다.
표준편차 값은 object detection의 작은 batch size에 따른 불안정성 때문에 train에서 계산한 값을 근사화하여 그대로 사용하였다고 합니다.
<Image-level feature alignment>
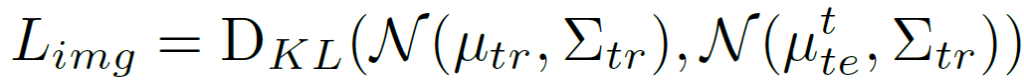
Image-level의 feature alignment는 위 식을 통해 KL Divergence로 계산됩니다.
이전 연구들과 동일합니다.
<Region-level class-wise feature alignment>
저자는 object detection에서의 domain shift 현상은 background를 잘못된 proposal로 예측하는 경향이 있다는 것을 이전 연구를 통해 밝힙니다. 그리고 이를 해결하고자 background에 해당하는 예측 확률값이 특정 threshold 미만인 feature를 골라서 이를 새로운 foreground class로 할당합니다.
예를들어, 새로운 domain 에서의 사람에 대해 모델이 실수로 background로 예측했을 지라도, 만약 그 background 예측 확률이 0.5보다 낮다면 이는 background가 아니라 모델이 잘못 예측한 foreground class로 간주하고, background를 제외하고 가장 높은 확률을 가지는 class로 할당하는 것입니다. 아래 수식으로 말이죠.

그리고 class imbalance 문제를 해결하기 위해 아래 수식을 사용해서 class별 weight를 계산하여 loss에 반영합니다.
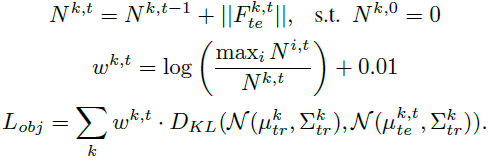
object level로의 feature alignment를 계산할 때 단순히 계산하는 것이 아니라, class의 비율을 고려하여 loss를 계산하게 됩니다.
2.3. When to update: Adaptation on demand
저자들은 조금 더 효율적인 TTA를 위해 모델이 현재 입력으로 들어오는 test sample에 대해 update를 수행할 지 말지를 결정하고자 합니다. 이를 위해 2가지 관점으로의 criterion을 설계하였습니다.
i) When the distribution gap exceeds the in-domain distribution gap
앞선 2.2절 속 L_{img}는 train 과 test feature 사이의 distribution을 의미하는 loss 입니다.|
그리고 아래 식을 통해 train dataset의 in-domain distribution을 계산합니다.
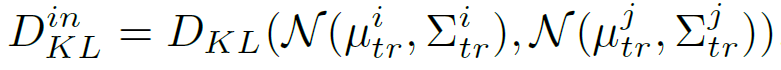
D^{in}_{KL}은 임의의 두 학습 이미지 x_{i}, x_{j}로 부터 계산된 KL divergence를 의미합니다.
즉 source domain 사이의 distance를 의미하는 in-domain distributiion이라고 생각할 수 있고, 만약 test time에 입력으로 들어온 test sample로부터 계산된 L_{img}가 D^{in}_{KL}보다 크다면 domain이 상이한 상황이므로 모델은 업데이트를 해야 한다고 설명합니다.
저자는 이를 기반으로 아래 수식이 만족하는 경우 모델이 아직 새로운 test domain을 만났다고 가정하며, 모델의 update를 진행하게 됩니다. 이때 우변의 값은 실험적으로 1.1을 사용하였다고 합니다.
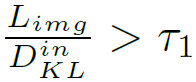
ii) When the distribution gap suddenly increases
두번째 criterion도 i과 유사한 목적성을 가집니다.
바로 수식부터 살펴보겠습니다.
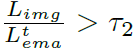
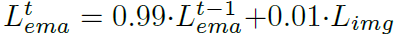
위 criterion은 결국 train과 현 test feature 사이의 distribution을 의미하는 L_{img}를 기반으로 계산됩니다.
만약 현 test sample이 기존과는 많이 상이한 domain image라면, L_{img} 값은 매우 커지게 되고, 결과적으로 L_{img} / L^t_{ema} 값도 커지게 됩니다.
물론 분모인 L^t_{ema}도 함께 커지긴 하겠다만, EMA 방식으로 update가 진행되다 보니 향상폭은 더 작습니다. 위 부등식 속 우변의 값은 실험적으로 1.05를 사용하였다고 합니다.
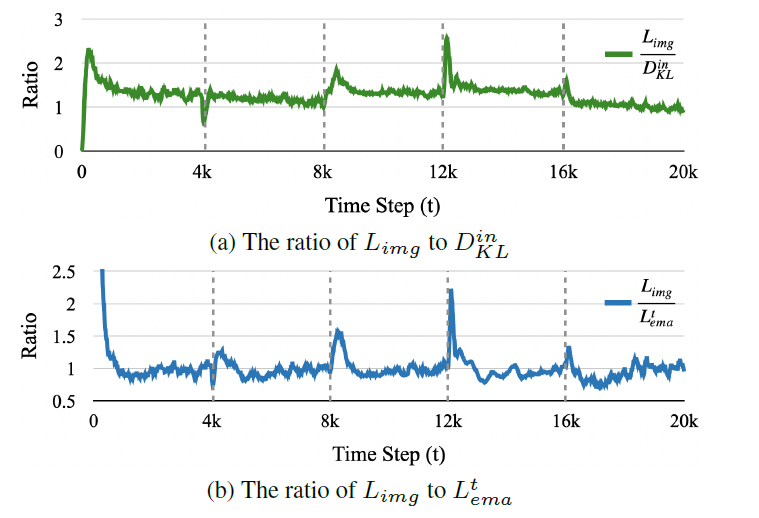
위 그래프를 통해 각 criterion에 대해 알 수 있습니다.
x 축인 time step에서 4k 기준으로 새로운 test domain을 만난다고 생각하시면 됩니다.
두 그래프 모두에서 4k 배수 근방 부근에서 갑자기 y축 ratio값이 크게 튀는것을 볼 수 있고, adaptation이 진행되니 점차적으로 ratio 값이 낮아지는것을 볼 수 있습니다.
3. Experiment
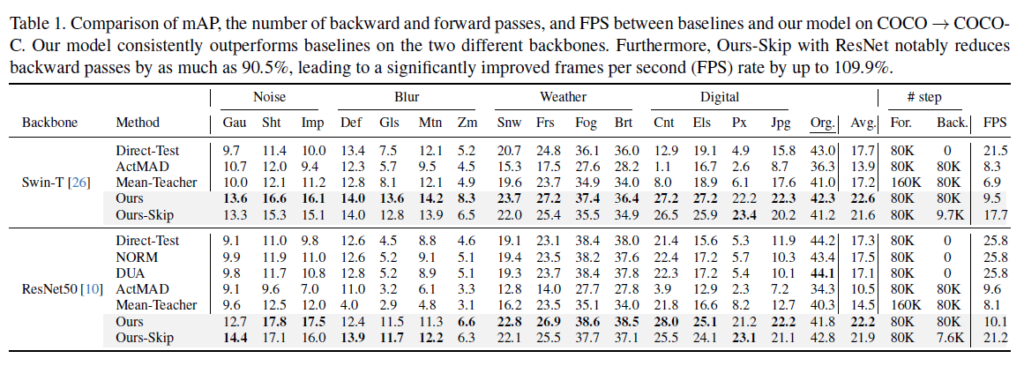
위 table은 COCO=>COCO-C 로의 실험 결과입니다.
COCO-C 데이터셋은 기존 COCO에 15가지 corruption을 부여하여 생성한 dataset입니다.
실험에 사용된 모델은 Faster-RCNN 모델이며 각각 백본을 Swin-Tiny, ResNet50으로 구성하였습니다.
타 방법론 대비 대부분의 corruption에서 더 높은 성능을 달성하는 것을 확인할 수 있습니다.
그리고 Ours와 Ours-Skip 사이의 비교도 인상적입니다.
Ours-Skip은 기존 Ours에 2가지 criterion을 사용해서 좀 더 효율성있는 TTA를 수행하고자 저자들이 설계한 것입니다. 결과론적으로 FPS도 기존 대비 약 2배정도 향상하였고, backward(Back.)에 적용되는 parameter 수도 약 10배정도 차이가 나는것을 볼 수 있습니다.
효율성이 중요한 TTA의 분야적 특성 상, 해당 결과는 매우 인상깊습니다.
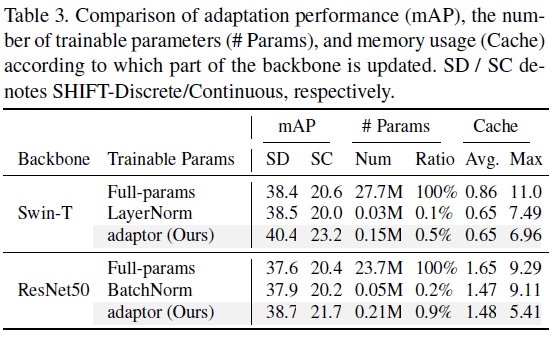
위 실험은 adaptor의 효과에 대해 보여주는 실험입니다.
마찬가지로 두 종류의 백본에 대해 실험을 진행하였고, 비교군은 Full-parameter를 update하는 방식과, normalization layer를 update 하는 방식입니다.
full-parameter와 비교했을 때 paramter수와 메모리 소모에서 본 논문이 훨씬 더 효율적임에도 불구하고, 성능은 더 높은것을 볼 수 있습니다.
그리고 normalization layer 대비 parameter 수는 더 많지만 오히려 메모리는 적게 소모하고 성능적으로도 더 좋은것을 확인할 수 있네요.
adaptor가 Domain Adaptation 분야에서도 잘 워킹하나봅니다.
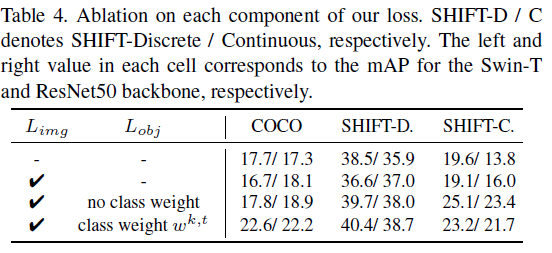
다음은 각 요소별 ablation study 입니다.
우측 성능은 /를 기준으로 좌측은 Swin-T 백본의 성능을, 우측은resnet 백본 성능입니다.
L_{img} 만을 사용해서 image-level에서의 alignment만 수행한 경우 swin-T에서는 세가지 데이터셋에 대해 모두 성능이 하락됩니다.
반면 이에 L_{obj}를 class imbalance weight 적용 없이 그냥 써도 성능향상이 크게 일어나는 것을 볼 수 있습니다.
그리고 class imbalance weight의 경우 SHIFT-C dataset에서는 조금의 하락을 보이긴 하지만, class imbalance 문제가 심한 COCO 데이터셋에서는 두 백본에 대해 대폭 향상을 보입니다.
네, 오늘은 Object Detection 분야에서의 TTA 논문에 대해 읽어보았습니다.
classification 및 Segmentation TTA에 비해 살짝 연구속도가 느려서 뭔가 이것저것 실험해 볼 껀덕지가 조금은 있을 거 같다는 생각도 드네요.. 예를들면 <Region-level class-wise feature alignment> 에서 foreground 와 background 구분을 단순 threshold 가 아니라, 마치 owod에서 적용되는 unknown prototype? background prototype? 을 도입해서 distance 기반으로 썸띵을 한다던지,, 뭐 등등이요.
문제정의 및 해결책 제시가 매우 직관적이였고, 논문 서술 방식 또한 매우 깔끔하다는 생각이 들었습니다.
아직 Supple쪽의 실험은 제대로 살펴보지 못했기에 조금 더 살펴봐야 할 듯 합니다.
감사합니다.
안녕하세요. 논문에서 작성된 내용을 그대로 활용한 것인지는 모르겠지만 as-is to-be 형식으로 리뷰 깔끔하게 잘 작성해서 보기 편했네요.
질문이 몇 가지 있는데,
1) 먼저 adapter는 그럼 offline에서는 어떠한 학습도 하지 않은 채, 실시간 inference를 수행할 때 처음으로 학습을 하는 것으로 이해하면 되나요?
2) 그리고 저자들이 기존 training set에서 계산한 분포 값(평균, 표준편차)을 활용해 모델 update를 할지 말지도 결정하는 등 다양한 용도로 활용하는데 이때 저자들이 분포 계산을 위해 training sample들을 약 2천개 정도 활용한다고 봤던 것 같습니다. sample의 개수를 더 늘렸을 때는 어떻게 성능이 변화하는지는 따로 실험에 없었나요? 이러한 분포를 토대로 in_distribution 여부를 결정하고 이것이 모델의 weight 조정 여부를 결정하는 상당히 중요한 기준이 되다보니 sample의 개수도 상당히 중요할 것 같아서요.
3) 마지막으로, L_img를 계산할 때 KL Divergence를 사용한다고 했는데 L_img 수식을 나타낸 곳에서 N은 무엇을 의미하나요? i.e., L_img = D_{KL}(N(\mu, \Sigma) ..) << 이 식 내에서 N 감사합니다.
댓글 감사합니다.
1. 이 부분에 대한 명쾌한 detail이 표기되어 있지는 않습니다. 하지만 본 논문의 ‘The up-projection layer is initialized to 0 values so that the adaptor does not modify the output of the block, but as the adaptor is gradually updated, it adjusts the output of the block to adapt to the test domain ‘ 구절로 미루어 보아, adaptor 내의 up-projection layer는 test domain이 변하기 시작할 때 서서히 update되기 시작하며 그 전까지는 0 초기화 상태를 유지하는 것으로 보여집니다.
즉 offline에는 adaptor 적용을 하지 않고, 실시간 TTA 수행 시 adaptor 가 그제서야 부착이 되는 것으로 판단됩니다. (추측이긴 합니다,,) (코드 제공 X)
2. 물론 말씀하신 부분이 다 맞습니다. 하지만 실험은 존재하지 않구요.
제 생각이긴 한데,,, 본 논문에서 수행하는 TTA는 가정 자체가 원래 source data로의 직접적인 접근이 불가능합니다. 오로지 pretrained model과 test시에 들어오는 입력만으로 adaptation을 수행하는 task죠. 그런데 본 논문에서는 어쩔 수 없이 2,000장을 사용하는 상황입니다. 제 생각엔 이 부분이 limitation 이기 때문에,, 굳이 실험적으로 이것저것 밝히진 않은 것 같습니다.
3. 아, 이부분에 대한 설명이 부족했네요. N은 정규분포를 나타내는 N 입니다. 두 정규분포 사이의 KL Divergence 계산입니다.
감사합니다.
+ As is – To be는 제가 재구성 했습니다 ㅇㅅㅇ
안녕하세요 석준님, 좋은 리뷰 감사합니다.
TTA에 대한 이해가 아직 잘 정립되지 않아서 이것저것 궁금증이 많이 생겨 질문드립니다!
1.
첫 질문부터 조금 장황한 점 죄송합니다.
우선 본 논문의 저자는 adaptor만을 update하기 때문에 continual domain shift 상황 속 catastrophic forgetting 문제를 방지할 수 있다고 하셨습니다. 그런 와중 when to update의 그래프 속 time step을 보면 다른 domain shifting 시점에서는 다 준수한 mAP성능을 보여주나 Contrast -> Pixelate 에서만 domain shift가 있는 시점에 갑작스런 성능 하락을 보이고 이후 다시 급격히 성능을 높여가는 모습을 보여주는데, 결국 이전의 domain에 비해 성능이 오르지는 않았던 것으로 확인됩니다.
특히 해당 표는 test domain이 input으로 주어지는 time step에서 예쁘게 4k씩 딱딱 떨어져서 들어오는 것에 대한 실험이었는데, 만약 이 test domain이 정말 계속 급변하는 상황이면 무언가 안정적인 update가 안될 것 같습니다. 현실세계의 test input은 더욱 갑작스레 noise도 낄테고 조도나 밝기변화 등으로 갑작스레 contrast도 달라질 수도 있고, 모종의 이유로 화질도 갑자기 깨질 수 있는데, 이런 상황에 대한 고려는 TTA 태스크에서 문제삼지 않는 내용일까요?
2.
adaptor의 구성에 관한 설명에서
upsample 을 수행하는 layer의 weight는 초기에 0으로 세팅한다고 하셨는데, 그럼 downsampling layer에서는 어떻게 초기화되는 건가요? 그리고 이렇게 upsample, downsample간의 weight 초기화에 차이를 두는 이유가 무엇인지 알고 싶습니다!
3.
EMA feature alignment 설명에서 EMA(Exponential Moving Average)는
오래된 데이터에 대한 가중치는 지수적으로 감소하지만 0이 되지는 않게 끔 계산하는 방법이라고 검색하며 이해했습니다. 결국 여기서 test 단계의 feature의 평균 분산을 구할 때에 EMA update를 기반으로 적응적으로 계산을 수행하는 이유도 continual domain shift 상황 속의 catastrophic forgetting 문제를 방지하는 것과 연관이 있는 것으로 이해해도 될까요?
마지막으로,
위 글에서 언급되는 adaptor가 저번 세미나 때 신정민 연구원님께서 발표하신 adapter와 동일한 개념인 것으로 이해했습니다!
정민님의 저번 세미나를 통해 들었던 adaptor의 존재와 의의는 vision transformer 모델에서의 finetuning을 위한 adapter였는데, domain adaptation 태스크에도 착 맞게 적용되는 점이 신기했습니다! 뭔가 adapter 모듈이 이름 따라 여러 기능을 하는 게 정말 만능처럼 느껴지네요..
감사합니다!
댓글 감사합니다.
1. Contrast -> Pixelate 상황에서도 성능 향상이 일어난다면 물론 이상적이겠으나, domain이 변화할 때 이전 domain 대비 성능이 향상되는 것은 TTA의 직접적인 목적이 아닙니다. TTA는 이전 domain -> 현 domain 상황속 성능 하락을 최소화 하는 것이죠. (이전 대비 조금의 하락이 생길수도 있지만, 그 하락 폭을 최소화 한다는 겁니다). Pixelate 상황의 16k 최종 성능은 이전 contrast의 12k 대비 낮을지 몰라도, 12k->16k로 tta가 수행됨에 따라 점차적으로 Pixelate 상황에서의 성능 향상이 이뤄진것으로 보아, TTA가 어느정도 워킹했다는 것을 알 수 있습니다.
그리고 아래 실험에 대한 궁금증에 대해서는, 아직 제가 Continual TTA관련 논문을 많이 읽지는 않았지만 제가 읽었던 범위 내에서는 대부분 각 domain별로 동일한 time step을 할당해서 평가를 진행하였습니다. 물론 재찬님이 말씀해주신대로, 실제 real world 상황에선 4K단위로 딱딱 떨어지는 것이 아니라 더 짧고 불규칙한 domain shift가 발생하는 상황이 더 적절할 수는 있죠. 하지만 훨씬 더 어려운 문제입니다. 이 부분에 대한 문제 정의 및 실험을 한 paper가 있는지에 대해선 제가 조금 더 살펴봐야 알 거 같습니다.
2. downsampling layer 에 대한 초기화 방식은 따로 언급되어 있지 않습니다. 아마 random하게 수행하거나, xavier등의 초기화를 사용하지 않을까 추측해봅니다. downsample 말고 upsample을 수행하는 layer를 0으로 초기화 하는 이유는 어쨋든 adaptor의 최종 output은 upsample을 수행한 이후 발생하기 때문입니다. adaptor 블럭의 최종 output에 마지막으로 관여하게 되는 layer는 upsample layer인데, 저자는 adaptor가 초기에는 아무런 domain으로 bias 되지 않은 상황을 유지하다가 새로운 test domain을 만나게 되면 그제서야 update가 이루어지길 바랬습니다. 그런 관점에서 ‘ adaptor가 초기에는 아무런 domain으로 bias 되지 않은 상황’ 을 모델링하고자 upsample layer의 초기 weight을 0으로 설정하였습니다.
3. 결론부터 말씀드리자면 연관성이 없는 쪽에 가깝습니다. 보통의 Continual TTA 논문에서 언급하는
catastrophic forgetting 은 ‘기존 source-pretrained 모델의 knowledge를 forgetting’ 하는 것입니다. 우선 이렇게까지만 짚고, 아래로 넘어가보겠습니다.
TTA 수행 속 test 단계에서 현재 입력으로 들어오는 test sample에 대해 단순히 계산을 수행할 수 있지만 본 논문에서는 EMA update 방법론을 통해 각 test sample의 속성을 누적해 나갔습니다. 그 말은 즉슨 이상적으로라면, TTA를 수행하면서 마주하는 모든 test sample 및 test domain에 대한 정보가 점차적으로 반영이 될 것입니다. 즉 EMA update를 통해 test feature를 update해 나가는 방식은 이전에 마주한 test domain들의 지식을 forgetting하지 않는 효과는 톡톡히 볼 수 있을 것입니다. 다만, 일반적으로 catastrophic forgetting 이라는 키워드가 ‘기존 source-pretrained 모델의 knowledge를 forgetting’ 인 점을 미루어 보아, 둘 사이에는 연관성이 없다고 보는 것이 맞아보입니다.
+ 맞습니다, 결국 유사한 구조의 adaptor 입니다. 기존 (large scale) pretrained 모델은 freeze한 채, 매우 적은 규모의 learnable parameter를 가진 adaptor만을 update해서 기존 지식 forgetting을 방지하면서 더 높은 일반화 성능을 가져가고자 하는 것입니다.