
안녕하세요, 허재연입니다. 중간고사를 마무리하고 오랜만에 논문을 읽어보았는데, 논문 읽기를 쉰 지 얼마나 되었다고 눈에 잘 안 들어오네요. 기말고사 기간이 다가오기 전에 이번 학기 목표를 달성하기 위해 부지런히 움직여야 할 것 같습니다. 오늘 리뷰할 논문은 마이크로소프트 등의 연구원들이 CVPR2021에 게재한 논문으로, 제목에서 짐작 할 수 있듯 Self-Supervised Learning(SSL)을 다룹니다. 기존의 contrastive learning 등의 대표적인 Self-Supervised Learning 방법론들은 대부분 Image classification을 염두해두고 설계되었는데, 사실 instance discrimination에 집중해 사전학습된 visual feature representations는 detection이나 segmentation 등 다른 downstream task에 곧바로 가져다 쓰기에는 충분하지 않을 수 있습니다. 해당 논문도 서두에서 classification과 detection task가 요구하는 feature representation의 차이를 지적하고 detection에 맞게 개량한 self-supervised learning 방법론을 제안합니다. 기존보다는 local feature를 추출할 수 있게 pretraining task를 설계했는데, 결과적으로 detection에서는 개선된 결과를 보여주었지만 classification task에서는 기존보다 떨어지는 성능을 보여주어 아쉬웠습니다(기존 방법론을 수정해서 classification, detection, segmentation 모두에서 SOTA를 찍었다면 더욱 주목받았겠죠). 그럼 한번 살펴보겠습니다.
Abstract
기존 Self-Supervised learning 관련 연구는 image classification에서 상당한 진보를 이루었지만, object detection으로 전이 학습을 했을때는 종종 좋지 못한 성능을 보여주었습니다. 본 논문의 목적은 object detection을 위해 self-supervised pretrained model을 개선하는 것이라고 합니다. classification과 detection task에 내제된 본질적인 차이에 기반해서 저자들은 instance localization이라는 새로운 self-supervised pretext task를 제안합니다. 제안하는 방법론에서는 background image위에 image instance를 붙여넣고, foreground bounding box와 합성된 이미지의 instance category를 예측하도록 합니다(사전학습에 bounding box를 고려하게 하는 것이 task alignment를 개선할 수 있다고 합니다). 추가적으로 feature alignment를 위해 bounding box에 augmentation을 가하는 방법을 제안한다고 합니다.
결과적으로 모델이 Imagenet semantic classification에는 약해졌지만 image patch localization에는 강점을 보여 object detection을 위한 사전학습에는 좋은 결과를 보여준다고 합니다. PASCAL VOC와 MS COCO 데이터셋에서 object detection 실험을 수행한 결과 SOTA를 달성함을 보입니다.
Introduction

일반적으로 컴퓨터 비전에서 신경망을 사용할 때 pretraining 후 fine-tuning을 거치게 되는데, 이 때 사전학습 단계에서는 어떤 generic representation을 얻기 위해 최적화되어 이후 다양한 downstream application에 이용됩니다. 대표적으로는 ImageNet 등 대규모 데이터셋으로 classification 사전학습을 시키거나 contrastive learning을 이용해 self-supervised learning을 수행한 이후 object detection, semantic segmentation, human pose estimation, image classification 등의 task에 적용하였으며, 이 방법은 상당히 잘 수행되었다고 합니다.
이 방법이 보편적으로 자리잡긴 했지만 기존 연구들에서 image classification에서 사전학습된 representation이 object detection에서도 잘 적용되지 않을 수 있다는 점이 드러난 것을 지적하며, 저자들은 이렇게 확보한 representation이 정말 최선인지 의문을 제기합니다. 현존하는 self-supervised model들이 classification task에 overfit되어 다른 task에는 충분히 효과적이지 않도록 학습됐다는 것이죠. 사실 단순 분류 문제는 객체 탐지나 segmentation같은 task에 비해 지나치게 단순합니다. 간단히 생각해보아도 분류기를 설계할때는 translation invariance하여도 상관이 없지만, detection 등의 task에서는 translation equivalent해야 합니다(객체의 위치가 바뀌면 bounding box의 좌표도 달라져야 하니까요). classification을 주로 염두해두고 사전학습된 representation은 충분하지 않을 수 있습니다.
저자들은 전이 학습에서의 task misalignment를 유발하는 두 가지 이슈를 지적합니다. 첫 번째로 사전학습된 모델이 downstream task에 활용되기 위해 구조를 수정해야 하며(feature pyramid 삽입 등), 두 번째로는 일반적인 사전학습 pretext task 및 contrastive learning이 지역적/공간적 모델링에 대한 명시적 고려 없이 전반적으로 instance discrimination을 수행한다는 것입니다. 이런 사전학습 방법들은 classification에 대해서는 이식성이 좋지만 공간적 추론을 요구하는 object detection과 같은 task에는 충분히 경쟁력을 갖지 못합니다.
저자들은 본 논문에서 instance localization이라는, object detection에 특화된 새로운 SSL 방법론을 제안합니다. 이 방법은 기존의 instance discrimination 뿐만 아니라 추가적으로 bounding box의 정보를 고려하려 representation learning을 수행합니다. foreground 이미지를 crop하여 이를 다양한 aspect ratio/scale로 서로 다른 background image의 위치에 합성하여 training set을 구축하였습니다. self-supervised learning은 bounding boxes를 이용하여 RoI feature를 추출하고 instance labels를 활용해 contrastive learning을 수행하여 진행됩니다. 사전학습 단계에서 bounding box를 사용하게 하여 image domain 내부에서의 translation에 더욱 민감해질 수 있다고 합니다. 기본적으로 방법론은 MoCo를 기반으로 하였으며, 모델은 합성 이미지 및 bounding box를 input으로 받아 contrastive learning을 위해 region embedding을 추출합니다. 해당 방법으로 baseline보다 image classification은 낮은 성능을 보였지만, bounding box location에 대한 regression에서는 개선된 결과를 얻을 수 있었다고 합니다. 결과적으로 ResNet50-C4, ResNet50-FPN로 수행한 object detection task에 대한 실험에서 PASCAL VOC, MS COCO 데이터셋에서 SOTA를 달성했다고 합니다.
Related Work
Method
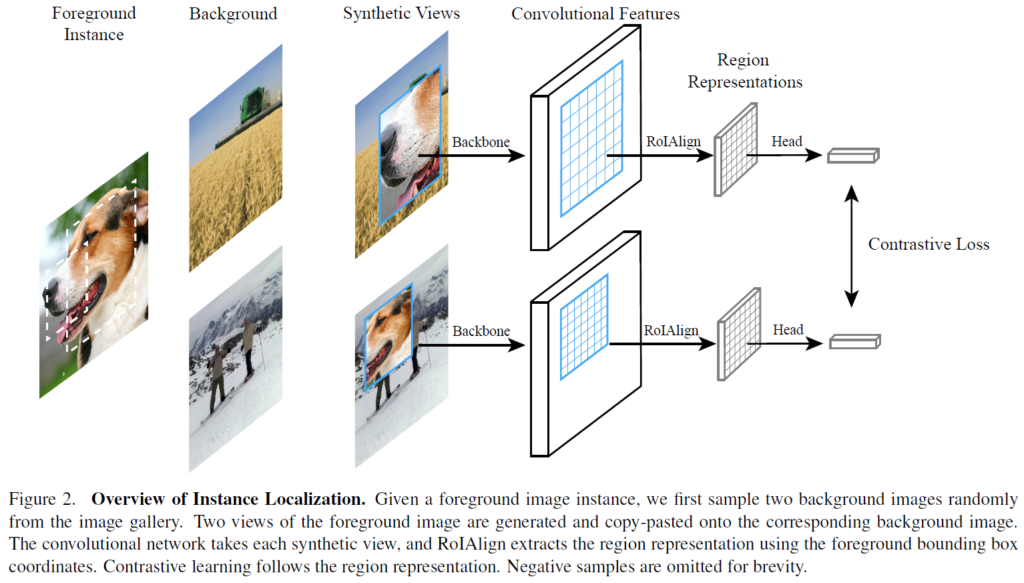
Pretext task – Instance Localization
이미지 분류에서는, 다양한 크기 및 위치에서의 object가 하나의 이산 object category로 축소되기에 traslation/scale invariance한 경향을 띄게 됩니다. 반대로 object detection은 translation/scale equivariance해야 합니다(object detection을 위한 feature representation은 이미지 내 객체의 크기 및 위치에 대한 정보를 보존해야 합니다). 저자들은 classification과 detection에 내제된 이런 본질적인 차이로 인해 각각 task만을 위한 모델링을 해야 한다고 주장합니다. 최근 contrastive learning을 이용한 pretraining 연구의 흐름은 image classification에 초점이 맞춰져 있기 때문에(SimCLR, MoCo 등 방법론들은 결국 postiive/negative pair에 대한 data instance 단위의 분류라고 볼 수 있죠) translation/scale invariance 성질이 강제된다고 하네요. 결국 이러한 pretext task들을 사용하게 되면 전반적인 instance discrimination에 overfitting되어 되어 공간적 추론 능력을 추구하는데 실패할 수 있다고 합니다.
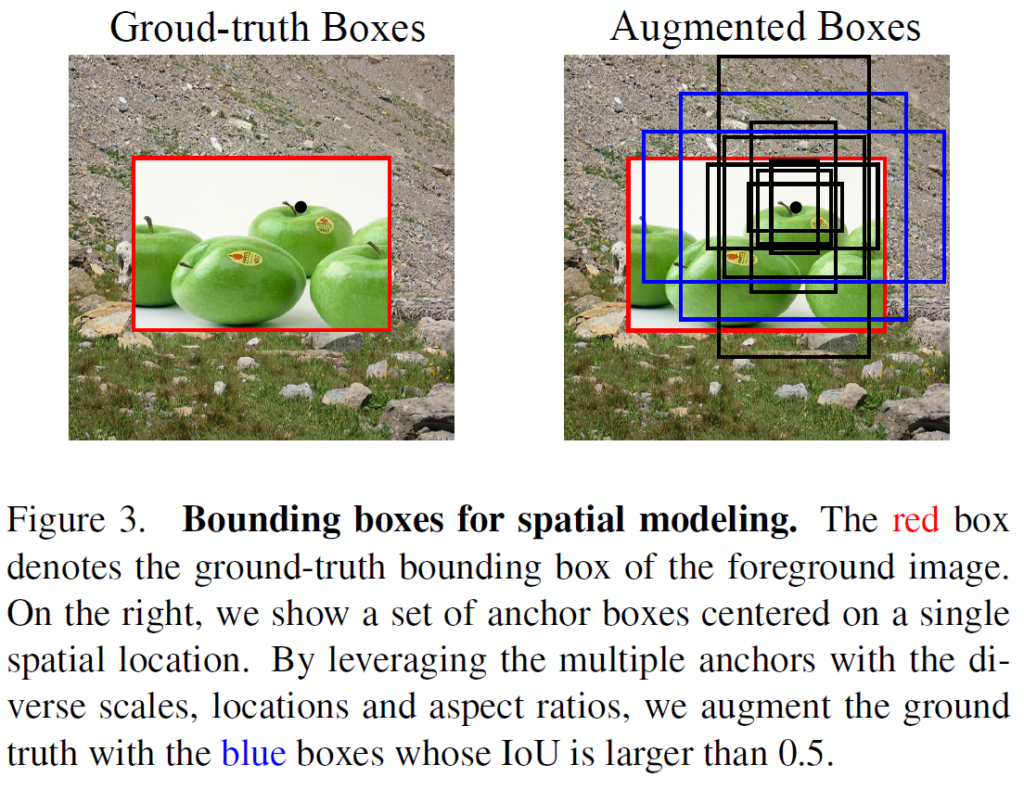
Figure 3을 보면 전경 사진을 배경 사진 위에 합성한 것을 확인할 수 있습니다(Figure 2,3은 프레임워크를 전반적으로 설명하는 그림이니 잘 보는 것이 좋습니다). 목표는 bounding box 정보를 활용해 전경을 배경과 구별하는 것입니다. 해당 태스크를 해결하기 위해서는 foreground instance를 먼저 localize하고 이후에 foreground feature를 추출해야 합니다. bounding box b로 전경 이미지 I가 합성된 합성 이미지를 I’, 하고 하면, task T는 I에 대한 instance label y를 예측하는 것입니다.
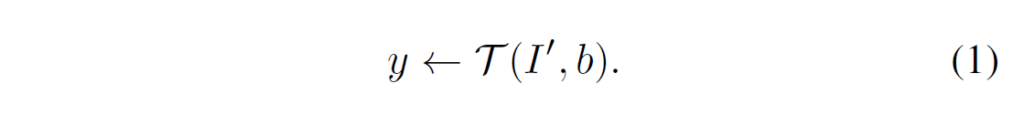
Learning Approach
1. Instance Discrimination with Bounding Boxes
Instance Discrimination.
해당 방법론은 contrastive learning(MoCo)를 이용한 instance discrimination을 진행하기에, 해당 부분에서는 contrastive learning을 설명합니다. 기본적으로 SSL 에서의 contrastive learning은 동일한 이미지를 2개의 다른 random augmentation을 가한 뒤 이들을 positive pair로 묶어 encoder(ResNet등 feature extractor)를 태워 feature representation을 얻은 뒤, 이들 벡터를 unit sphere로 projection하여 positive pair의 유사도를 높이고, 서로 다른 이미지에서 추출한 representation에 대해서는(negative pair) 유사도를 낮추는 방향으로 학습을 합니다. 여기서는 InfoNCE라는 contrastive loss를 사용했으며, 식은 다음과 같습니다.
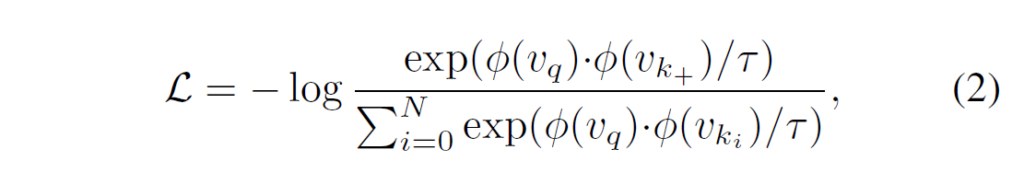
ϕ는 신경망이고, vq, vk+는 positive pair라고 생각하시면 됩니다. 해당 loss로 학습하게 되면 positive pair끼리는 유사도가 높아지고, engative pair끼리는 유사도가 낮아지는 방향으로 학습이 됩니다.
Spatial Modeling with Bounding Boxes
Figure 2를 보시면 이해가 쉬울 것 같습니다. 해당 부분에서는 contrastive learning을 수행함과 동시에 input region과 convolutional feature 사이 spatial alignment를 유지할 수 있게 설계하였다고 합니다. 말이 어려운데.. 결국 주어진 이미지 I에 대해서 무작위로 배경 이미지 B를 선택하여 I를 random crop한 뒤 위치와 크기를 무작위로 B 위에 합성하게 됩니다. 해당 과정을 거치면 합성된 이미지 I’와 bounding box 파라미터 b를 얻을 수 있습니다.
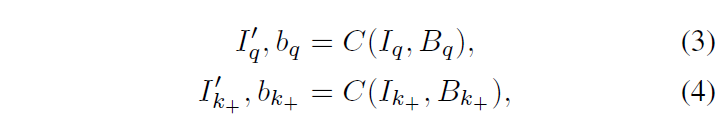
I_q와 I_k+는 동일한 이미지에서 crop되었고, B_q와 B_k+는 각각 이에 선택된 배경 이미지입니다. 전경 이미지는 랜eja한 aspect ratio와 128~256 픽셀 사이 랜덤한 크기로 resize됩니다.
이후 bounding box parameter b를 이용해 convolutional feature map으로 foreground feature를 추출하기 위해 RoIAlign이 적용됩니다.
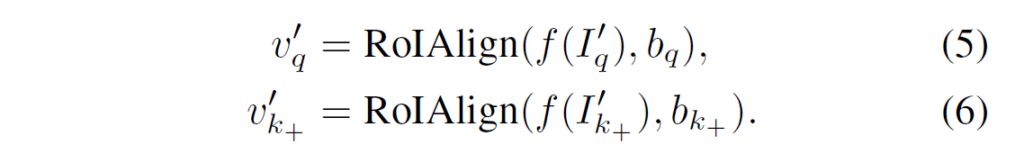
이렇게 추출한 query와 key feature에 대해 2번 수식과 Figure 3번의 framework를 통해 contrastive learning이 진행됩니다.
2. Bounding Box Augmentation
contrastive learning에 있어 image augmentation은 핵심적인 역할을 하기에 저자들은 bounding box에 대해서도 증강이 효과가 있을 것이라는 가정을 세웠습니다. GT location 주변의 jittered bounding box들은 boundground 영역을 포함할 수 있기에 여기서 얻는 representation은 배경을 무시하고 localization 능력을 가질 수 있을 것이라고 합니다.
Augmentations as predefined anchors
augmentation 할 때는 bounding box를 직접 이동시키지 않고 region proposal network(RPN)의 anchor를 이용합니다. 주어진 GT box에 대해 모든 anchors에 대한 IoU를 계산하고 0.5 이상 겹치는 것들만 남긴 후 무작위적으로 하나를 선택해 augmented box로 사용합니다. anchor 기반으로 box를 생성했기에 저자들은 다양한 IoU의 box를 얻을 수 있었다고 합니다. 이렇게 얻은 bounding-box augmentation은 RoIAlign module에 함께 넘겨줍니다.
3. Architectural Alignment
앞서 전이학습에 있어 task misalignment를 유발하는 결정적인 이슈 중 하나가 모델 구조 수정이라고 언급했습니다. pretrained network는 detection을 수행하기 위해 추가적인 연산 구조를 추가해야 했습니다. 저자들은 bounding box representation을 도입함으로 사전학습과 파인튜닝 간 모델 구조 불일치를 최소화 할 수 있다고 주장합니다. 좀 더 구체적으로, 사전학습 과정에서 RoIAlign 작업이 지역적 representation을 도입하여 fine-tuning에서의 detection 작업을 모방한다고 합니다. 이를 위해 사전학습에서 ResNet50-C4와 ResNet50-FPN을 사용하였습니다.
R50-C4 : 기본적인 ResNet50 모델 구조에서 4번째 residual block의 출력에 RoI 연산을 추가했다고 합니다. bounding box 좌표는 region feature를 추출하는데 사용되었습니다(Figure2 참고) .
R50-FPN : 4단계 feature hierarchy를 형성하기 위해 lateral connection을 하용합니다. 각 feature level은 해당 scale의 객체를 모델링하게 됩니다. 저자들은 모든 FPN hierarchy의 level에 RoI 연산을 적용해 instance localization task가 4개의 feature level에서 동시에 수행될 수 있게 하였습니다.
Experiment
실험은 PASCAL VOC 및 MS COCO에서 수행되었습니다. 사전학습에는 ImageNet dataset이 사용되었으며, 전이학습에 PASCAL 및 COCO가 사용되었습니다. 하이퍼파라미터는 MoCo-v2의 세팅을 따랐으며, 8개의 GPU를 사용하여 SGD 방식에 weight decay=0.0001, momentum=0.9, 각 GPU당 batch size 32를 사용했다고 합니다. contrastive learning의 temperature parameter는 0.2로 설정했다고 하네요. MoCo 방식에서 메모리 큐는 65536개의 negative sample로 설정되었다고 하며, 키 인코더 업데이트에 대한 momentum coefficient는 0.999로 설정되었다고 합니다(MoCo는 두 인코더가 동시에 업데이트 되는게 아니라, 한 쪽으로 gradient가 흘러 파라미터 업데이트가 되면 다른 한 쪽은 momentum을 두어 가중합 방식으로 해당 파리미터 업데이트를 따라가는 방식으로 학습됩니다). 이미지 데이터 증강은 random resize cropping, color jittering, grayscaling, gausian blurring, horizontal flipping이 사용되었다고 합니다(위에서 다룬 augmentation은 이미지 증강이 아닌 bounding box 증강이었습니다)
비교 실험은 당시 좋은 성능을 보여주었던 SimCLR, BYOL, MoCo, InfoMin, SwAV와 함께 리포팅되었습니다.

PASCAL에 대해서는 R50-C4 백본을 활용한 Faster R-CNN이 사용되었습니다. 기존의 사전학습 방식을 단순히 적용한 것과 비교하면 확실히 detection 성능이 개선된 것을 확인할 수 있습니다.

COCO에는 R50-C4와 R50-FPN 백본을 활용한 Mask R-CNN이 사용되었습니다. 지표에서 APbb와 APmk는 각각 bounding box detection의 AP와 instance mask segmentation에 대한 AP라고 합니다. detection뿐만 아니라 segmentation에서도 해당 방법이 SSL 방법 및 imagenet supervised pretrain을 이긴 것을 확인할 수 있습니다.
요즘 detection에 contrastive learning을 적용하기 위해 instance 단위가 아닌 local feature를 고려한 논문들을 읽고 있었는데, boundind box를 이용한 방법론은 신선하네요. 이전에 읽었던 DenseCL은 local feature를 잘 이용한 contrastive learning을 이용했었는데, 이번 논문은 아예 이미지를 합성하고 detection task를 겨냥해 bounding box까지 고려한 사전학습을 하였습니다. 한가지 아쉬운 점이라면, classfication task에서 기존 방법론들을 앞서지 못한게 아깝습니다. 앞으로도 관련 논문을 몇 편 더 읽어볼 생각입니다. 추후 또 리뷰로 다룰 수 있도록 노력해 보겠습니다.
감사합니다.
재연님 안녕하세요!
좋은 리뷰 감사합니다.
글을 읽던 중 모르는 부분이 생겨 질문드립니다.
classification을 위한 feature representation과 달리 detection에서 필요로하는 feature representation은 공간 정보에 대한 추론을 통해서 사전학습 간 모델로 하여금 공간에 대한 이해를 시키는 것이 중요해 보입니다.
그렇게 하기 위한 과정에서 Learning Approach -> Spatial Modeling with Bounding Boxes부분에서 언급된 input region과 convolutional feature사이 spatial alignment가 무엇을 의미하는 것인지 궁금합니다.
그리고 (3), (4)번 수식의 결과로 합성된 이미지와 bounding box 파라미터 b가 output으로 얻어지는데, 이 bounding box 파라미터 b가 무엇인가요!? 이를 통해 (5), (6)번 수식의 과정에서 align을 맞추기 위한 중요한 정보를 담고 있는 것 같은데, 어떤 정보를 담고있는 것인지 궁금합니다.
마지막으로 (5), (6)번 수식에서 합성된 이미지를 backbone에 태운 후 얻은 feature map과 함께 사용되어 위에서 언급된 spatial alignment을 맞추기 위해서 RoIAlign과정을 수행하는 것처럼 보이는데요. 이 과정을 거치고 나온 feature map은 기존의 feature map과 어떤 부분이 달라지는 지 궁금합니다.
감사합니다.
1. 해당 부분은 결국 전경 사진을 crop해서 배경 사진에 합성한 것을 의미합니다. 표현이 약간 직관적이지 못하게 작성되어있네요..
2. SSL에서는 bounding box GT값이 없기 때문에 합성한 이미지의 영역을 bounding box 정보로 사용하게 됩니다. 해당 bbox는 합성한 전경 사진의 영역을 의미하며, 이를 이용해 사전학습을 진행합니다.
3. feature map은 모델의 layer를 계속 거치게 됩니다. featuremap의 차이는 CNN의 앞단 featuremap과 뒷단 featuremap의 차이라고 생각하시면 됩니다(RoIAlign으로는 bbox 정보를 처리합니다)
안녕하세요. 좋은 리뷰 감사합니다.
중간에 궁금한 점이 생기는데, Augmented Images에서 배경 사진 위 전경 사진을 합성할 때, 즉 Detection에선 이미지를 합성하고 나면 생기는 문제점으로 그 합성되는 Boundary 쪽의 Gradient가 문제되는 경우가 생기는데, 이에 대해선 어떻게 생각하시는지 궁금합니다.
제가 해당 문제에 대해 아는 바가 많지 않고, 해당 논문에는 관련된 언급이 없어서 해당 이슈가 발생했는지, 발생했다면 어떻게 해결했는지 짐작가는 바가 없습니다. 혹시 해당 이슈를 지칭하는 용어가 있다면 해당 용어를 기반으로 추가적인 검색을 해보도록 하겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
본문의 Method 부분에서 질문이 있는데 Fig2에서 이미지를 crop 시킨 부분을 background에 합성하고 이에 대한 피처맵을 뽑은 다음에 RoIAlign을 수행해 Region Representation을 뽑는 것으로 이해했습니다. 그런데 그림을 보았을때는 Crop된 이미지가 Convolution Features 부분에서 파란색 영역으로 도출되고 이를 RoIAlign 시키는 것으로 보이는데 이렇게 하면 각기 다른 background에 대한 정보가 포함될 수 있나요? Crop된 이미지의 정보에 대해서만 정보를 담는 것 같아 질문남깁니다.
bounding box 부분만 뒤쪽으로 넘기는것이 아니고, 합성된 전체 이미지의 feature가 학습되게 합니다. 합성된 부분에서는 bounding box 정보를 이용합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
보통 이미지 augmentation에서 바운딩 박스는 이미지의 augmentation에 따라 조정되는 정도로만 생각하고 있었는데 bounding box augmentation이 따로 contribution이 될 수 있네요. 그런데 저자들이 boundinx의 augmentation이 효과가 있을 것이라고 가정한 만큼 이에 대한 ablation study는 혹시 없었는지 궁금합니다. 그리고 Spatial Modeling with Bounding Boxes 부분에서 주어진 이미지에 대해 무작위로 배경 이미지를 선택하여 random crop한 뒤에 합성하는 과정을 거치게 되면 합성된 이미지와 바운딩 박스 파라미터 b를 얻을 수 있다고 하였는데, 여기서 b는 그럼 rancom crop되어 합성된 전경 이미지의 크기를 의미하는 것인가요 ??
감사합니다.
bounding box 전략에 대한 ablation study는 따로 없습니다. 이해하신대로 bounding box b는 배경에 합성한 cropped foreground image를 의미합니다.