안녕하세요, 서른 번째 x-review 입니다. 이번 논문은 2024년도 IJCAI에 게재된 RoboFusion: Towards Robust Multi-Modal 3D Object Detection via SAM 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
이미지와 포인트 클라우드를 함께 활용하는 멀티 모달리티 기반의 3차원 물체 검출은 자율 주행에서 중요한 역할을 하고 있습니다. 이미지에서는 semantic한 정보를 얻을 수 있는 반면 depth 정보가 부족하고, 포인트 클라우드는 기하학적인 데이터이지만 sparse한 데이터 형태로 semantic한 정보가 부족하여 상호보완할 수 있습니다. 현재 방법론들은 현재 자율 주행 데이터셋 (KITTI, nuScenes)에서 SOTA를 달성하고 있지만, 이러한 방법론들은 out of districution (OOD) 환경에서는 일반적인 데이터셋에 비해 일반화 성능이 떨어지는 경향을 보입니다. 데이터셋에서도 마찬가지로 일반적인 환경에 비해 흔히 악천후라고 불리는 눈이나 안개 상황이 거의 포함되지 않습니다. 이를 해결하기 위해 현재까지는 domain adaptation 기법을 활용하고 있었는데, 이는 데이터의 어노테이션 필요성을 줄일 수 있지만 도메인 shift, 라벨 shift 또는 과적합 문제와 같은 한계점이 발생하였다고 합니다. 이런 상황에서 최근에 NLP와 CV 분야에서 foundation 모델이 등장을 하게 되면서 domain adaptation에 의존하지 않으면서 학습한 상황이 아니라 새로운 환경을 모델이 보았을 때 (OOD 시나리오) 일반화를 달성할 수 있게 되었습니다. 본 논문에서는 이러한 흐름을 따라 OOD 시나리오에서 visual foundation model(VFM)을 활용한 멀티모달리티 기반 3차원 물체 검출기를 제안합니다. SAM을 활용하여 정상 시나리오에서 OOD 시나리오로 adaptive하게 넘어갈 수 있는 프레임워크인 RoboFusion을 제안합니다. 좀 더 제안한 구조를 크게 살펴보면,
(1) SAM에서 inference segmentation 결과 보다는 SAM에서 추출한 feature 활용 (2) 자율 주행 시나리오를 위해 미리 학습된 SAM인 SAM-AD 제안
(3) 멀티 모달리티의 3차원 물체 검출기와 VFM의 align을 맞추기 위해 feature 업샘플링 문제를 해결할 수 있는 AD-FPN 도입
(4) 노이즈 간섭을 줄이면서 필요한 신호 feature을 유지하기 위해서 노이즈를 효과적으로 감쇠할 수 있는 Depth-Guided Wavelet Attention (DGWA) 모듈 설계
(5) 포인트 클라우드, 이미지 feature을 융합하고, 융합된 feature에 adaptive하게 가중치를 재조정하는 adaptive fusion 제안
(6) KITTI-C, nuScenes-C 데이터셋에서 OOD 시나리오에 대한 강인성 검증
2. RoboFusion
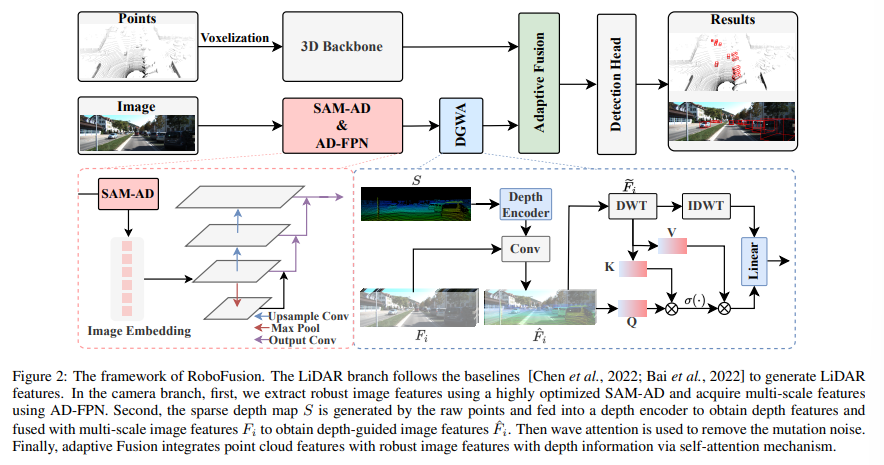
전체적인 구조를 먼저 살펴보면 (1) 멀티스케일의 이미지 featuere를 추출하는 SAM-AD 및 AD-FPN 모듈 (2) depth를 이용한 이미지 feature에서 노이즈를 제거하기 위한 Depth Guided Wavelet Attention (DGWA) 모듈 (3) 포인트 클라우드, 이미지 feature을 융합하기 위한 adaptive fusion 모듈, 이렇게 크게 3가지 모듈로 구성되어 있습니다.
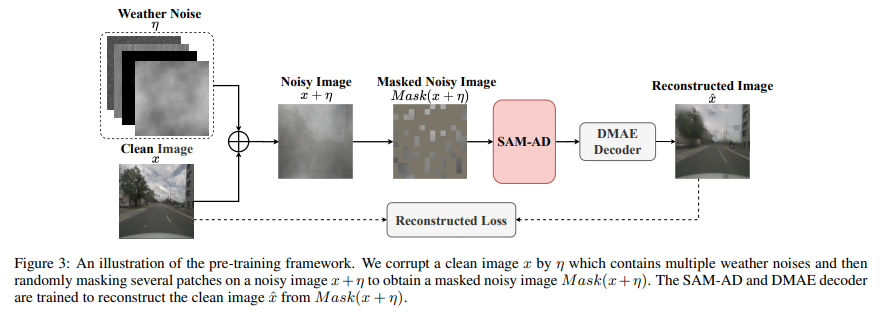
SAM-AD
자율 주행 시나리오에서 SAM을 적용하기 위해 SAM에서 사전 학습을 수행하여 SAM-AD를 설계합니. 기존의 KITTI와 nuScenes 데이터셋에서 이미지를 샘플링하여 기본적인 자율주행 데이터셋을 구성합니다. Fig.3.과 같이 DMAE라는 방법을 따라서 SAM-AD를 구성하기 위해 SAM을 사전학습 합니다. Fig.3.에서 x는 기존 데이터셋으로, 즉 clean 이미지이며 \eta는 x를 기반으로 생성한 노이즈 이미즈 집합을 의미합니다. 노이즈의 유형은 4가지 날씨(비, 눈, 안개, 강한 햇빛)이며 강도는 1-5까지로 구분되어 랜덤으로 선택됩니다. 인코더는 SAM의 이미지 인코더를 사용하며, 디코더와 reconstruction loss는 DMAE와 동일하다고 합니다.
AD-FPN
SAM은 이미지 인코더, 프롬프트 인코더, 그리고 마스크 디코더 세 가지 모듈로 구성되어 있습니다. 일반적으로 이미지 인코더는 다운스트림 task를 위해 high 퀄리티의 이미지 임베딩을 제공할 수 있으며, 마스크 디코더는 semantic segmentation에 피팅해서 설계되어 있습니다. 구성 모듈 중 필요한 것은 프롬프트 인코더의 정보 처리보다는 강인한 이미지 feature 이기 때문에 이를 추출하기 위해 SAM의 이미지 인코더를 사용하는 것 입니다. 다만 SAM은 이미지 인코더로 멀티 스케일의 feature을 고려하지 않고 ViT 기반이기 때문에 물체 검출에 필요한 멀티 스케일 feature을 생성하기 위해서 ViT 기반의 다중 스케일 feature을 제공할 수 있는 AD-FPN을 설계하였습니다. SAM에서 제공하는 stride 16의 height 차원 이미지 임베딩을 사용하여 {32, 16, 68, 4}의 stride를 가진 멀티 스케일 feature F_{ms}을 생성합니다. 기존 FPN과 유사한 bottom-up 방식으로 F_{ms}을 합쳐서 최종 멀티 스케일 feature F_i \in \mathbb{R}^{\frac{4}{H} \times \frac{4}{W} \times C_i}을 생성하게 됩니다.
2.2. Depth-Guided Wavelet Attention
SAM-AD를 통해 이미지 feature을 추출할 수 있지만 2D와 3D 사이의 갭이 여전히 존재하고 악천후 환경에서는 특히 기하학적인 정보가 부족한 카메라 이미지로부터 노이즈가 증폭되는 문제가 발생합니다. 이를 완화하기 위해서 본 논문에서는 두 단계의 DGWA 모듈을 제안합니다. 먼저 포인트 클라우드로부터의 depth feature와 이미지 feature을 합침으로써 이미지 ㄹeature에 기하학적 정보를 추가하는 depth guided 네트워크를 설계합니다. 다음에 이미지 feature을 Haar wavelet 하위 대역으로 나눈 다음, 어텐션 연산을 통해 하위 대역의 feature 노이즈를 제거합니다. 다시 자세하게 설명해보면, 이미지 feature F_i \in \mathbb{R}^{\frac{4}{H} \times \frac{4}{W} \times C_i}와 raw한 포인트 클라우드 P \in \mathbb{R}^{N, C_p}가 입력으로 주어집니다. P를 먼저 이미지 평면에 projection해서 sparse한 depth map S \in \mathbb{R}^{H \times W \times 2}를 생성합니다. 그 다음에 여러 개의 컨볼루션 레이어와 max pooling 레이어로 구성된 depth 인코더 (DE)에 S를 입력으로 넣어서 depth feature F_d \in \mathbb{R}^{\frac{4}{H} \times \frac{4}{W} \times C_i}를 출력합니다. 마지막으로 컨볼루션 인코더 (F_i, F_d)를 활용해서 식(1)과 같이 depth guided 이미지 feature인 \hat{F}_i \in \mathbb{R}^{\frac{4}{H} \times \frac{4}{W} \times 16}을 최종적으로 얻을 수 있습니다.
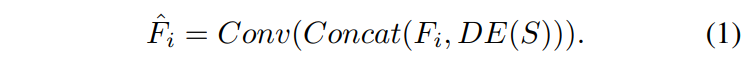
이러한 depth guided 이미지 feature을 얻고 나서, 이산 wavelet transform (DWT)를 사용해서 \hat{F}_i를 4개의 하위 대역으로 분할 합니다. 이를 분할한다는게 무슨 말이냐고 하면, 입력 feature의 행, 열을 하나의 저주파 밴드 \tilde{f}^{LL}_i \in \mathbb{R}^{\frac{8}{H} \times \frac{8}{W} \times 4}와 3개의 고주파 대역 (\tilde{f}^{LH}_i, \tilde{f}^{HL}_i, \tilde{f}^{HH}_i \in \mathbb{R}^{\frac{8}{H} \times \frac{8}{W} \times 4}로 각각 인코딩하여 low 필터 f_L = (\frac{1}{\sqrt{2}}, \frac{1}{\sqrt{2}} 와 high 필터 f_H = (\frac{1}{\sqrt{2}}, -\frac{1}{\sqrt{2}} 로 인코딩 합니다. 이 상태에서 저주파 대역은 coarse 정보를, 고주파 대역은 fine-grained 정보를 가지고 있게 되는데, 즉 노이즈 정보를 필터링 하기 위해서 변하는 신호를 더 쉽게 찾아낼 수 있습니다. 채널 축을 따라서 4개의 하위 대역 feature을 연결하여 wavelet feature \tilde{F}_i = [\hat{f}^{LL}_i, \hat{f}^{LH}_i, \hat{f}^{HL}_i, \hat{f}^{HH}_i] \in \mathbb{R}^{\frac{8}{H} \times \frac{8}{W} \times 16}을 생성하게 됩니다. 그 다음에 wave-attention Att_{\omega} 연산을 수행하는데, 식(2)와 같이 \hat{F}_i를 쿼리, \tilde{F}_i를 key, value로 사용합니다.
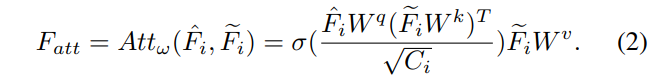
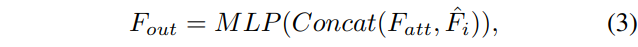
마지막으로 IDWT(inverse DWT)를 사용하여\tilde{F}_i를 다시 \hat{F}i로 변환하고, 이 변환한 \hat{F}i를 attention 결과인 F{att}와 합쳐서 식(3)과 같이 노이즈가 제거된 feature F{out} \in \mathbb{R}^{\frac{16}{H}, \frac{16}{W} \times 16}을 얻을 수 있습니다. 이렇게 얻은F_{out}은 필요한 feature을 가지고 있으면서 주파수 도메인에서 발생하는 노이즈를 억제된 형태를 가지게 됩니다.
2.3. Adaptive Fusion
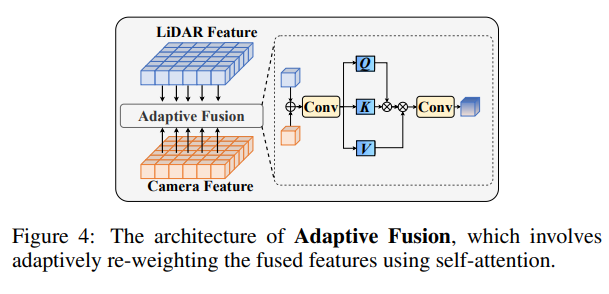
DGWA 모듈 내에서 image와 depth feature를 합친 후에 포인트 클라우드에 이러한 depth 정보가 풍부해진 이미지 feature와 합치기 위한 adaptive fusion 방식을 제안합니다. 다양한 형태의 노이즈는 포인트 클라우드와 이미지에 서로 다른 정도에 영향을 미치기 때문에 데이터가 손상되는 정도가 다른, 불균형 문제가 발생하게 됩니다. 따라서 다양한 노이즈가 두 모달리티에 미치는 영향을 고려해서 Fig.3와 같이 합쳐진 feature에 adaptive하게 가중치를 재조정할 수 있는 self attention 연산을 진행합니다. 모달리티가 노이즈에 따라 데이터가 손상되는 정도가 다양하기 때문에 self attention가 adaptive하게 가중치를 재할당 하였다고 합니다.
3. Experiments
3.1. Dataset
기본적으로 outdoor 환경의 자율주행 데이터셋인 KITTI와 nuScenes에서 실험을 진행하였으며, 추가적으로 LiDAR와 카메라 센서에 대해서 노이즈가 추가된 KITTI-C, nuScenes-C를 사용하였습니다.
3.2. Comparing with state-of-the-art
먼저 clean 데이터셋인 KITTI, nuScenes에 대해 실험을 진행하고, 노이즈가 존재하는 데이터셋인 KITT-C, nuScenes-C에 대한 실험을 차례대로 진행하였습니다. 실험 결과에 대해서 무조건적인 SOTA를 달성했는지 여부 보다는 얼마나 강인성과 일반화 성능이 높은지에 중점을 두었다고 합니다. 이러한 평가 요소는 자율 주행 시나리오에서 3차원 물체 검출을 실제로 진행하는데 중요하기 때문에 노이즈가 존재하는 데이터셋에서 강인한 성능을 보이는 것이 더 중요하다고 판단하였기 때문이라고 합니다.
Results on the clean benchmark
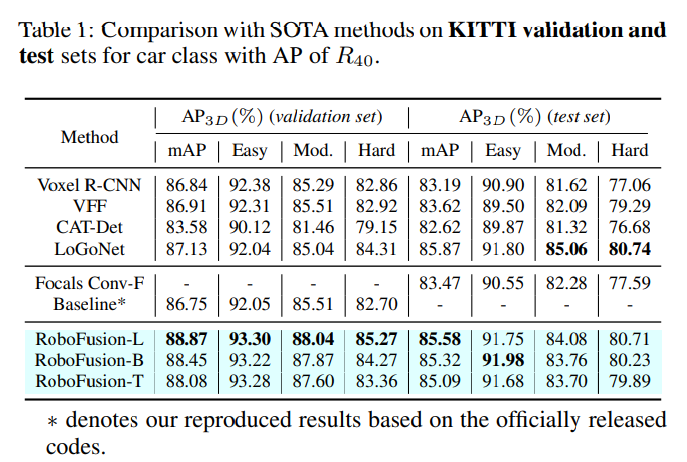
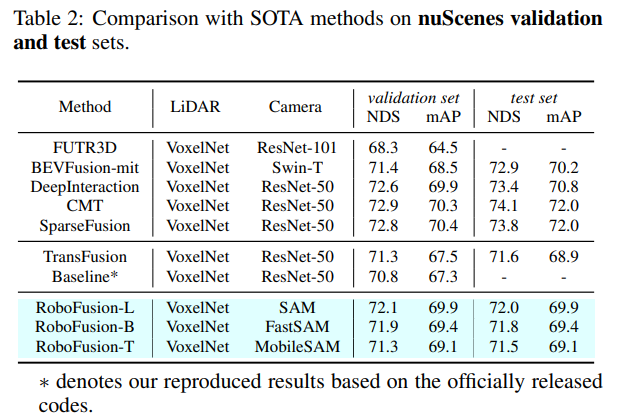
Table1을 통해 보통의 3차원 물체 검출 성능 리포팅과 동일하게 KITTI 데이터셋에서의 실험 결과를, Table2는 nuScene에서의 결과를 보여주고 있습니다. clean 데이터셋에서도 기본적으로 SOTA, 혹은 SOTA에 준하는 성능을 달성한 것을 확인할 수 있습니다.
Results on the noisy benchmark
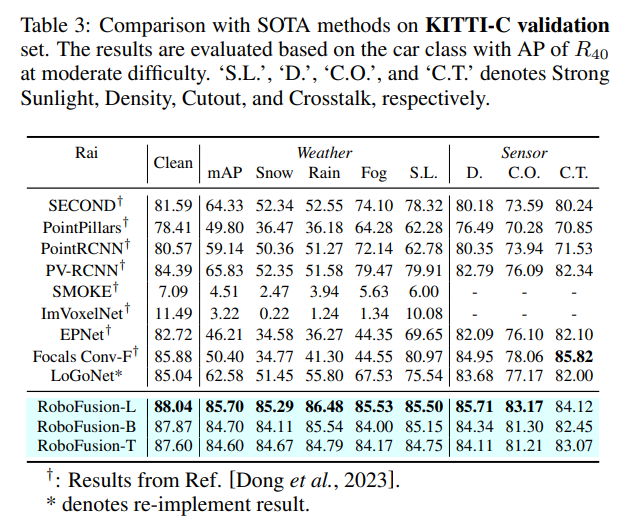
실제 자율 주행 시나리오의 상황은 Fig.1(a)와 같이 학습이나 테스트 데이터에서의 분포와 다를 가능성이 많습니다. 그래서 비, 눈, 안개나 강한 햇빛과 같은 날씨와 센서의 노이즈를 평가하기 위해서 KITT-C와 nuScenes-C를 포함하는 새로운 노이즈가 포함된 벤치마킹 데이터셋이 제공되고 있습니다. 기존의 SOTA 방법론들은 이러한 노이즈가 많은 상황, 특히 눈이나 비와 같은 기상 환경에서 성능이 크게 감소하게 됩니다. 이는 clean KITTI 데이터셋에서 눈이나 비가 오는 날씨가 포함되어 있지 않기 때문일 수 있는데, 반면에 SAM-AD와 같은 VFM은 다양한 데이터에 대해 학습되어 있어 OOD 시나리오에서 훨씬 강인한 성능을 보여줄 수 있어 RoboFusion이 더 높은 성능을 달성할 수 있습니다.
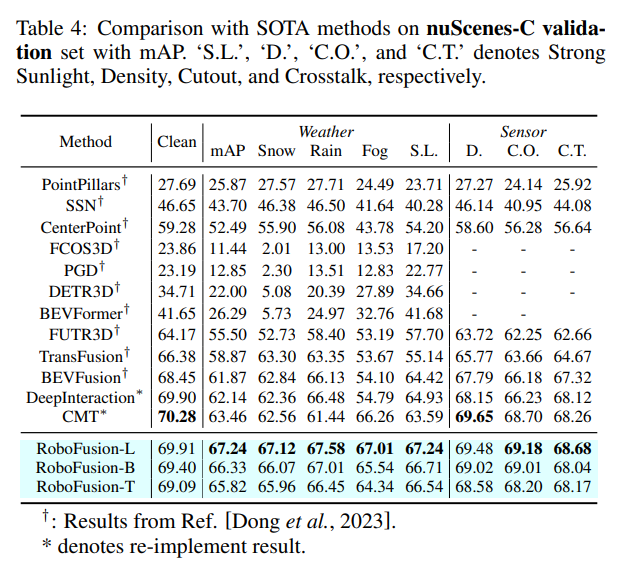
Table 4는 nuScenes-C에서의 실험 결과로, BEVFusion은 다른 기상 환경에서는 유사한 성능으로 작동하지만 안개가 낀 환경에서는 유독 성능이 크게 떨어지고 있습니다. 그러나 본 논문의 방법론은 어떤 기상 환경이 포함되어 있는지와 크게 상관없이 모두 안정적인 성능을 보이며 저자가 강조했던 노이즈 데이터에 대한 강인성과 모델의 일반화 성능을 증명하고 있습니다.
3.4. Ablation Study
Performance of Different VFMs on RoboFusion
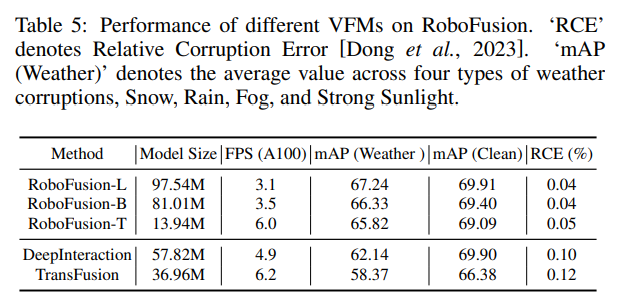
Table 5는 본 논문에서 기본으로 사용한 SAM 이외의 다양한 사이즈의 SAM (FastSAM, Mobile-SAM)을 사용하였을 때 노이즈에 대한 강인성과 FPS 성능을 분석한 ablation study 입니다. 우선적으로 타 방법론들에 비해 기상 환경에 대한 mAP가 높은 성능에서 안정적으로 작동하고 있음과 동시에 RoboFusion-T는 기존의 방법론인 TransFusion과 유사한 FPS를 갖추고 있습니다. 이를 통해 3차원 물체 검출 task에서 SAM의 실용적인 적용 가능성을 보여주고 있습니다.
Roles of Different Modules in RoboFusion
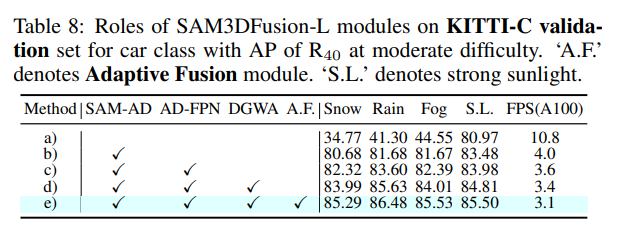
마지막으로 Table 8은 논문에서 제안한 각각의 모듈의 영향을 비교한 실험 입니다. 우선 자율 주행 시나리오에 맞춘 SAM-AD를 적용한 것이 가장 큰 성능 향상을 이루어낸 것을 확인할 수 있습니다. 다른 모듈 역시 추가함으로써 모두 성능이 개선되는 것을 통해 자율 주행의 실제적인 OOD 노이즈 시나리오에서 강인한 성능을 위해 본 논문이 제안하는 방법이 효과가 있음을 강조하고 있습니다.
FM을 이용한 3D Detection 논문이라… 흥미로운 논문이네요!
몇 가지 질문 던지고 갈게요.
1. DMAE라는 기법이 생소하여 어떤 것인지 부연 설명이 필요해 보입니다.
2. SAM-AD의 목적이 clean image를 생성하는 것일까요?
3. 영상 특징을 Haar wavelet 하위 대역으로 나눈 다음 노이즈를 제거하는 이유가 무엇인가요?
안녕하세요. 좋은 리뷰 감사합니다.
3D object detection에서 multimodal이라니…@.@ 바로 리뷰 읽어봤습니다.
adaptive fusion부분에서 흥미로운 부분이 있었는데요. LiDAR feature와 Camera Feature를 합친뒤 conv를 통과시키고 이후 키, 쿼리, 값을 통해서 self-attention 연산을 수행하는 것으로 보입니다. 여기서 궁금한 점은 보통 멀티모달끼리 attention 연산을 한다면 쿼리는 Liader feature, 쿼리, 값은 Camera feature로 가져가는 식으로 Cross-modal attention을 수행하는 경우가 많은데 여기서는 굳이 self-attention을 수행한 이유가 있을까요? 아니면 이 논문 task에서는 주로 저런식으로 fusion하는 것이 더 보편적인건가요?
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
1) DMAE를 따라 SAM을 사전학습한다고 하는데, SAM-AD는 마스킹된 이미지가 들어가는것인가요? SAM이란 것이 대용량의 데이터로 사전학습하는데, 이 SAM-AD가 마스킹된 이미지를 대용량으로 학습한 모델인가요? 그렇지 않다면 그냥 마스킹된 이미지를 SAM에 태워도 문제가 없나요?
2) Depth-Guided Wavelet Attention에서 Harr wavelet이 무엇이고, 이런 Wavelet이 무엇인지 어떻게 Depth 정보를 추가하는지에 도움되는지 등등에 대한 설명을 부탁드립니다. 지금의 설명에서 제가 사전지식이 많지 않다보니 이해하는데 어렵네요.. Wavelet Attention이란 과정부터 설명해주시면 감사합니다.