안녕하세요, 서른두 번째 X-Review입니다. 이번 논문은 2023년도 IET에 올라온 Multilevel receptive field expansion network for small object detection입니다. 바로 시작하도록 하겠습니다. 👺
1. Introduction
딥러닝 기반의 object detection은 1단계 detector와 2단계 detector로 나뉩니다. 대표적인 2단계 object detection 알고리즘 같은 경우 RCNN, fast RCNN, faster RNN이 있죠. 이 2 stage detection 알고리즘은 이름 그대로 두 단계로 나눠져 있는데 첫 단계에서는 RPN(Region proposal network)를 통해 객체가 존재할 법한 후보 proposal을 얻은 다음 두 번째 단계에서 roi에 대한 classification과 regression을 수행합니다. 일반적으로 2-stage detector가 1-stage에 비해 정확도가 더 높죠.
물체 감지는 컴퓨터 비전 커뮤니티에서 중요한 연구 분야입니다. 결함 감지[1], 자율 주행[2], 원격 감지[3]에 널리 사용됩니다. 위의 모든 분야는 작은 물체의 감지 정확도와 관련이 있습니다. 딥러닝, 특히 컨볼루션 신경망(CNN)의 발달로 물체 감지는 감지 정확도와 속도가 비약적으로 발전했습니다. 딥러닝 기반 객체 감지 알고리즘은 1단계 감지 알고리즘과 2단계 감지 알고리즘으로 나뉩니다. 대표적인 2단계 객체 감지 알고리즘은 지역 컨볼루션 신경망(RCNN)[4], 고속 RCNN[5], 고속 RCNN[6] 등이 있습니다. 2단계는 감지 알고리즘이 두 단계로 이루어져 있다는 것을 의미합니다. 첫 번째 단계에서는 지역 제안 네트워크(RPN)를 사용하여 거친 후보 제안을 얻고, 두 번째 단계에서는 정확한 분류와 경계 상자 회귀를 완료합니다. 일반적으로 2단계 감지기는 1단계 감지기에 비해 정확도가 더 높습니다. 하지만 region-based 방법론들은 시간이 많이 걸리고 복잡하다는 단점이 있습니다.
1-stage detection 알고리즘은 한 단계로 결과를 직접 예측하기 때문에 2-stage보다 빠릅니다. 1-stage detector의 예로는 SSD, YOLO 시리즈, 일부 anchor free 방법론들이 있는데, RetinaNet은 FPN(Feature pyramid network)를 사용해 다중 scale object를 검출하고 positive negative sample 불균형 문제를 해결하고자 Focal loss를 설계하였습니다. 이 RetinaNet은 모델 성능 측면에서 2-stage 방법론의 성능을 능가하는 최초의 1-stage 방법론이었으며, 이런 1-stage detector들은 빠르며 간단하고 성능도 2-stage detector를 능가할 수 있는 잠재력을 갖고 있기에 많은 주목을 받고 있습니다.
지금까지 일반적인 object detector는 성능이 크게 향상되어 왔지만, pixel 수가 적은 small object를 검출할 때는 여전히 성능이 떨어집니다. Image super-resolution은 이미지를 확대하고 이미지의 디테일을 보완하지만, small object에 대해 image super resolution을 하는 task는 극히 일부에 불과합니다. 또, small object는 흔히 볼 수 있는데, MS COCO 데이터셋을 예로 들어보자면, 이 데이터셋에서 32×32 픽셀 미만의 instance는 small object로 간주되며 전체 데이터셋의 41%를 차지한다고 합니다. 하지만 small object에 대한 성능은 일반적으로 COCO 데이터셋에서 large object보다 떨어지고 있죠. 이는 크게 보면 아래의 4가지 이유 때문입니다.
- visual 정보가 부족해서 해상도가 낮은 small object에서 구별력 있는 feature 정보를 추출하기 어렵다.
- downsampling으로 인해 small object의 feature가 한 점으로 모이거나, 사라질 수 있다.
- 큰 Receptive field는 큰 객체를 검출하는데 적합하고, small receptive field는 작은 객체를 검출하는데 적합하지만 detector의 receptive field는 object와 매치되지 않는다.
- bbox는 small object detection에 큰 영향을 미치기 때문에 작은 객체를 정확하게 찾기가 어렵고 놓치는 경우가 발생할 수 있다.

CNN 기반의 방법론 같은 경우 shallow feature는 location 및 디테일한 정보를 담고 있지만 semantic information은 부족합니다. Deep layer는 저해상도이며 디테일한 정보는 없지만 receptive field가 크고 semantic한 정보를 담고 있습니다. RCNN 시리즈와 YOLO v1, v2는 fig1-(a)와 같이 객체를 검출할 때 single feature layer를 사용합니다. Feature에 있는 image의 detail들이 convolution과 pooling을 거치면서 손실되기 때문에 이런 모델들은 small object에 대한 성능이 가장 좋지 못합니다. Image pyramid는 FIg1-(b)와 같이 원본 이미지가 확되대고 scale이 다른 image의 feature가 각각 추출됩니다. 하지만 작은 object의 pixel이 확대되더라도 여전히 몇개의 feature만 사용됩니다. 또 이 구조는 계산 복잡도가 증가된다는 단점도 존재하죠. SSD는 feature pyramid구조를 사용해서 Fig1-(c)와 같이 다양한 scale의 object를 검출하며, 고해상도 feature에서는 small object를 검출해낼 수 있습니다. 하지만 backbone network의 shallow feature는 classification을 위한 충분한 semantic 정보가 부족하며, 이를 위해서는 deep layer가 필요하게 됩니다. 마지막으로 FPN은 top down path와 옆으로 연결되는 구조를 갖고 있는데 이 구조는 FIg1-(d)에서 확인할 수 있는 것처럼 풍부한 semantic 정보를 가진 deep layer feature와 풍부한 detail 정보를 갖는 shallow layer의 feature를 fusion합니다. 이 결과 shallow layer에서는 small object에 대한 검출 성능이 향상되지만 down sampling 과정에서 feature map의 spatial resolution이 감소되고 이에 따라 target이 background와 fusion됨에 따라 small object의 정보가 점차 감소됩니다. 따라서 deep downsampling은 small object와 context information이 손실되며 이 경우 small object의 정보를 복구해낼 수 없습니다.
이런 문제를 해결하기 위해 본 논문에서는 MRFENet이라고 하는 multilevel receptive field expansion network를 제안하였습니다. DNN에서 receptive field는 context 정보에 해당하는데, 이 MRFENet은 receptive field를 확장하여 풍부한 context 정보를 얻는 것을 목표로 합니다. 이 모델은 deep layer의 context cue와 shallow layer의 detail한 정보를 사용해 small object를 검출하고자 한 것인데요 , , Fig1-(e)가 제안된 구조입니다. 보시면, 백본 네트워크의 각 stage마다 RFEB를 통과시키는 것을 확인할 수 있는데 이는 Receptive field expansion block입니다. 모델 구조에 대한 상세한 부분은 아래 method에서 다루도록 하겠습니다.
추가로 본 모델은 transformer를 백본으로 사용하여 small object에 대한 feature 추출 능력을 향상하였다고 합니다. 또 기존 bbox를 학습할 떄 사용하던 loss가 object의 location을 제대로 파악해서 학습하는데 한계가 있다며, bbox의 overlap 영역, 중심 거리, aspect ratio를 고려하는 union loss 함수를 설계하였습니다.
본 논문의 contribution은 아래와 같습니다.
- spatial resolution을 유지하고 receptive field를 확장해 small object의 over downsampling으로 인한 정보 손실 문제를 해결하기 위한 MRFENet 제안
- Swin transformer의 각 feature layer에 따른 dilated convolution 구조를 설계하여 저해상도 feature map에서 작은 객체와 receptive field간의 mismatch 문제 해결
- 물체의 localization 가능성을 높이고 작은 객체의 검출 성능을 향상시키기 위한 union loss 함수 설계
- MS COCO 데이터셋에서 small object에 대한 성능 크게 향상
2. The Proposed method
몇 deep network는 down sampling을 통해서 spatial resolution을 점진적으로 감소시킨 다음에 top-down 구조나, 측면으로의 connection을 통해 원래 resolution을 재구성하게 됩니다. 하지만, small object에 대해서는 downsampling 중에 손실된 정보는 재구성하기 어렵다는 문제가 존재하죠. 이런 문제를 해결하기 위해 제안된 것이 MRFENet인데, MRFENet은 deep layer에서 small object의 context를 유지한 다음 이 context 정보를 고해상도 feature와 fusion하여 feature를 얻게 됩니다. 각 layer마다 다른 RFEB(Receptive Field expand block)을 갖는 MRFENet을 구성하여 spatial resolution을 유지하고 각 feature layer에 필요한 receptive field를 matching합니다. 아래에서 전반적인 프레임워크를 설명하도록 하겠습니다.
2.1. Overview of our framework
CNN은 local한 정보에 집중하고 global한 정보를 포착하는데 취약합니다. global 정보를 파악하기 위해서는 deep한 network가 필요하지만 small object는 deep layer에서 사라지는 경향이 있죠. 반면 transformer는 self attention 방식을 통해 global feature를 추출합니다. 저자는 swin transformer를 백본으로 사용하였는데, swin transformer는 vit를 개선한 것으로 멀리 떨어진 영역에 과한 attention을 하지 않고 세부적인 정보에 집중하는 특징을 갖고 있습니다. 따라서 swin transformer는 small object에서 feature를 추출하는데 더 효과적이겠죠.
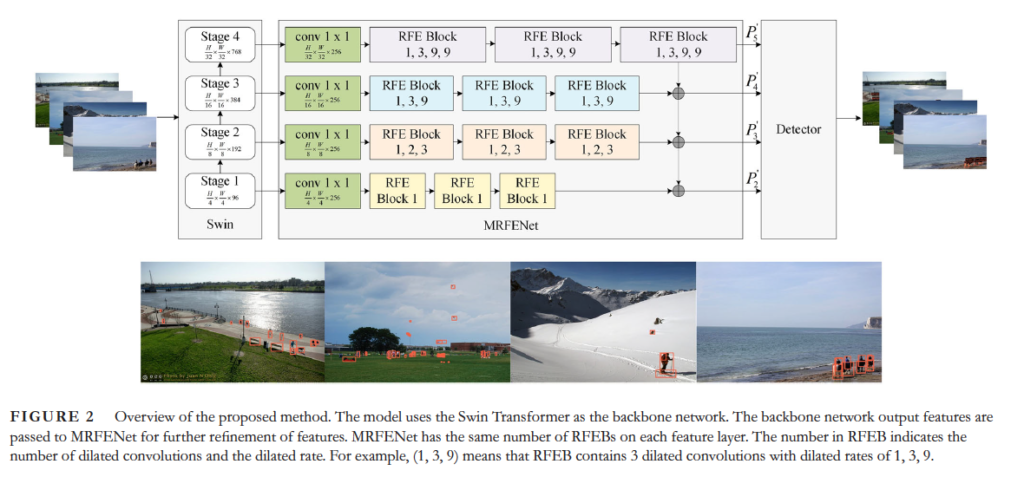
위 Fig2와 같이 4 stage의 output feature scale은 각각 1/32, 1/16, 1/8, 1/4입니다. 그 다음 이 4 scale을 갖는 feature는 MRFENet에 입력으로 들어갑니다.
Feature pyramid 구조는 shallow layer에서 small object를 예측해내지만 shallow layer의 semantic한 정보를 object의 class를 식별하기에 충분하지 않다고 하였죠. 이 FPN은 top-down lateral(측면) 연결 구조로, 이 문제를 더 약화시킵니다. 하지만 FPN은 더 큰 receptive field를 얻기 위해 down sampling되고 deep layer에서 small object의 정보가 손실되면 context 정보도 손실되죠. 이런 문제를 해결하기 위해 설계한 것이 각 feature layer에 대한 RFEB입니다. 즉, 작은 객체에 대한 정보를 보존하는 새로운 네트워크 구조를 제안한 것입니다.
MRFENet은 다양한 dilated rate와 multiple dilated convolution을 사용해 고해상도 feature를 갖도록 하고, receptive field를 확장하는 RFEB들로 구성됩니다. Deep layer의 feature는 큰 receptive field를 가져 semantic 정보가 풍부하며, shallow feature는 디테일한 정보가 풍부하죠. 따라서 swin transformer의 네 단계 output feature를 adaptive하게 학습하기 위해 서로 다른 RFEB를 통과하도록 하여 multilevel의 receptive field를 형성합니다. swin transformer의 output feature는 먼저 channel수를 조절하기 위해 convolution layer를 통과해 feature C^’_i(i=2,3,4,5)를 얻어냅니다. 그 다음 이 multilevel feature를 RFEB로 들어간 다음 각 layer의 feature P^’_i(i=2,3,4,5)가 top-down 방식으로 fusion됩니다. Semantic, contextual 정보가 shallow layer로 전달되면서 small object 검출을 돕는 것이죠. 수식으로 살펴보자면 아래와 같습니다.

여기서 ↑_{2×}는 double nearest-neighbour interpolation을 나타내며, n은 RFEB의 수를 나타냅니다. 또 [latex]RFEB_i(i=2,3,4,5)는 i번째 layer의 receptive field expansion block을 의미합니다. FPN과 비교해서 보자면 MRFENet은 feature resolution을 변경하지 않고 receptive field를 확장해 small object 및 contextual cue에 대한 정보를 동시에 보존합니다. 또 feature가 top-down 방식으로 전파되면서 모델의 shallow layer가 유용한 semantic, contextual 정보를 얻게 됩니다.
2.2. Receptive field expansion block
이제 RFEB(Receptive field expansion block)을 어떻게 설계했는지 살펴보도록 하겠습니다. 이 RFEB는 feature resolution을 유지하면서 receptive field를 확장해 중간 feature를 얻기 위해 제안되었다고 했습니다.

구체적으로 RFEB는 dilated residual 구조를 base block으로 사용하였는데, 즉 base block은 1x1 convolution과 dilated convolution으로 구성됩니다. 추가로 효율성을 보장하기 위해 multi-residual 구조를 사용하였는데, 위 그림 3에 나와 있는 것처럼, local residual 구조는 single base block마다 구현되어 있습니다. 회색 block이 residual block입니다. 이 여러 base block을 통해 global residual 구조를 갖는 것입니다. 즉, 이 여러 base block을 결합함으로써 receptive field를 확장한 것입니다.
Receptive field가 너무 커지면 많은 배경 정보가 도입되면서 small object의 검출에 영향을 미칩니다. 따라서 큰 객체를 검출하는 deep layer에서는 큰 dilated rate를 사용하여 shallow layer에서 작은 객체를 검출하기 위해 small dilated rate를 사용하였습니다. FIg3에서 이를 확인할 수 있는데 맨 위의 layer5는 receptive field를 확장하기 위해 dilated conv에 대한 큰 dilated rate(9)를 사용하였습니다. layer4부터 2까지는 상대적으로 작은 receptive field를 얻기 위해 dilate rate를 점차 줄였는데, 이는 각 layer에서 요구되는 receptive field를 얻기 위한 것이겠죠. Deep laeyr의 RFEB에는 4개의 dilated conv가 있으며 중간에는 3개, shallow layer에서는 1개가 포함되어 있습니다. 전반적으로 각 layer는 block 수를 점차 줄여 계산 복잡도를 줄이고자 한 것입니다. 예를 들어 3개의 base block을 사용하는 RFEB는 수식으로 아래와 같이 설명할 수 있습니다.
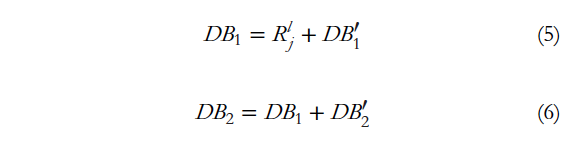

여기서 DB^’_i는 base block을 나타내며, i는 base block의 순서입니다. R^l_j는 l번째 layer의 j번째 RFEB의 입력을 나타냅니다.

저자가 세팅한 RFEB의 receptive field는 위 table 1과 같습니다. 보시면 layer2에서는 dilated rate가 1인 conv하나만 포함되어 있는데 이는 그냥 보통의 3x3 conv와 동일합니다. 이렇게 설계한 이유는 small receptive field가 small object의 location을 파악하는데 도움이 되기 때문입니다.

Fig4에 4개의 feature layer의 RFEB의 receptive field가 시각화되어 있습니다. (a), (b), (c), (d)는 각각 layer 5, 4, 3, 2에 해당하는 receptive field입니다.
2.3. Union loss
Detection에서 IoU는 자주 사용되는 metric이며, GIoU는 IoU의 개선된 metric입니다. 저자가 제안하는 Union loss는 IoU와 GIoU의 개선된 방식입니다. 저자는 IoU는 object 에 scale에 민감하지 않고, GIoU는 수렴속도가 느리고 부정확하게 box를 예측한다는 문제점이 았다고 하여 GIoU loss와 BIoU loss를 결합하여 loss를 구성하였습니다. 이를 통해 bbox의 offset, center 거리, aspect ratio를 고려하여 localization을 할 수 있게 하였습니다. classification loss로는 Cross Entropy loss를 사용하였습니다. 전체 loss는 아래와 같습니다.
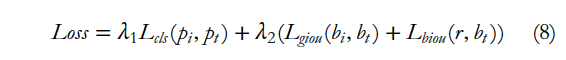
3. Experiments
본 논문에서 제안된 MRFENet은 MS COCO 데이터셋에서 평가하였으며 평가지표로는 AP, AP50, AP75, AP_s를 사용하였습니다. AP_s는 IoU = 0.5:0.95이며, object가 32x32보다 작은 small object에 대한 성능입니다.
3.1. MS COCO dataset experiment
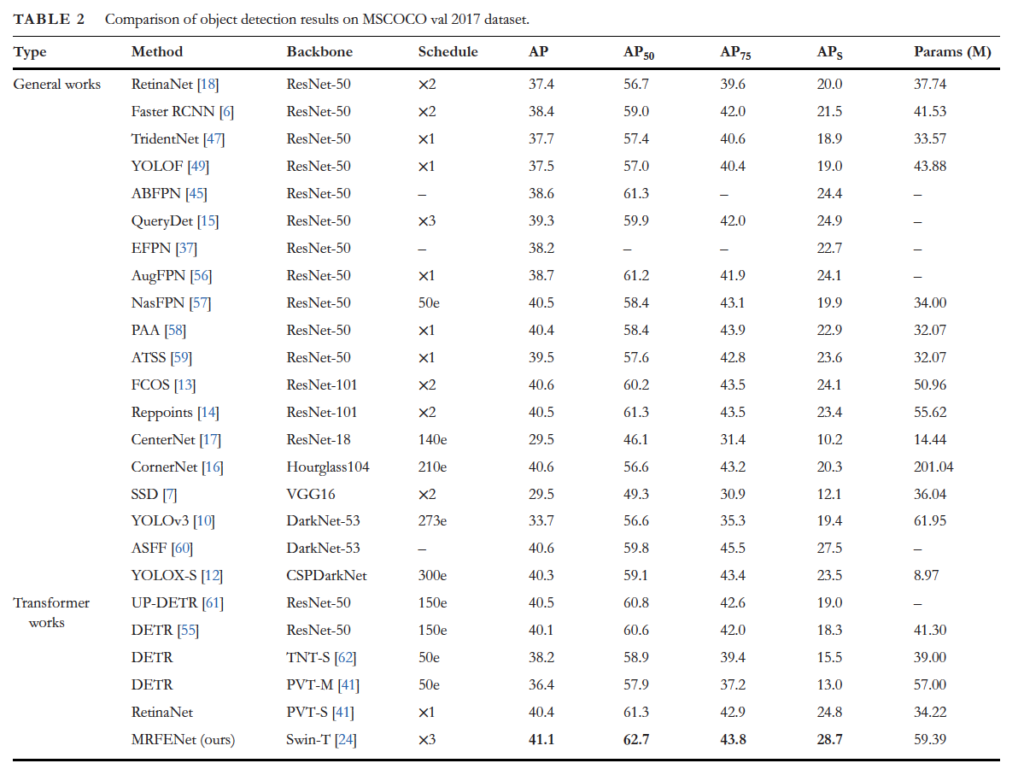
MRFENet은 RetinaNet의 detection head를 사용하였습니다. original RetinaNet은 모든 크기의 객체에 대해 37.4 AP와 small object에 대해 20.0의 AP_s 성능을 보이는 반면, MRFENet의 AP와 AP_s는 각각 3.7과 8.7 향상된 성능을 보입니다. FPS가 표에 없어서 속도 측면에서의 비교를 못한다는 점이 아쉽네요 ..무튼 전체적으로 transformer를 사용하는 방법론도마 높은 성능을 보이며, small object에 대한 성능도 다른 방법론에 비해 가장 높습니다.
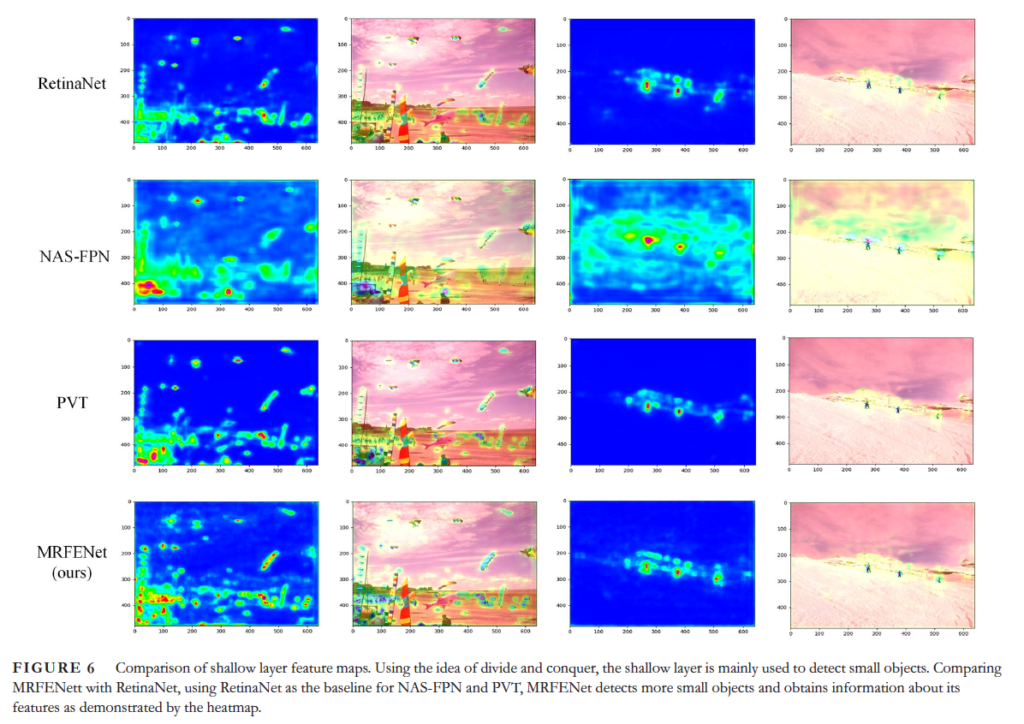
위 fig 6은 RetinaNet, NAS-FPN, PVT와 본 논문에서 제안된 MRFENet 각각의 shallow layer에 대한 heatmap을 보여줍니다. 맨 아래 행에 있는 MRFENet은 다른 method보다 더 많은 small object를 검출하고 있는 것을 볼 수 있네요.
3.2. Ablation studies
3.2.1. The number of receptive field expansion block

Ablation study입니다. 모델의 RFEB 수를 달리하여 실험해봤는데요, table3에서 볼 수 있는 것과 같이, RFEB 수가 증가함에 따라 모델의 성능이 향상되었으며, small object에 대한 검출 성능도 향상하였습니다. 하지만 RFEB 수를 증가시킬수록 computation cost가 커지기 때문에 3으로 설정하였다고 합니다.
3.2.2. Effectiveness of the backbone and receptive field expansion block
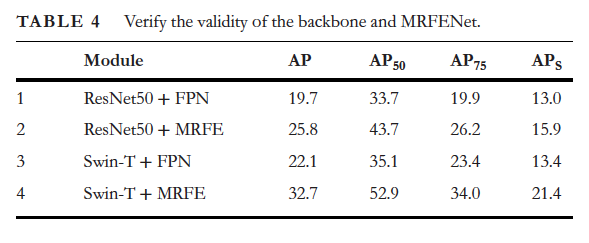
추가적으로 swinTransformer를 백본으로 사용한 것에 대한 성능 향상을 확인하기 위해서 table4에서 보이는 실험을 수행했는데요, 인상적인 부분은 ResNet + FPN에서 MRFE로 변경한 경우 AP_s가 약 3정도 증가하는 반면, SwinT+FPN에서 MRFE로 변경한 경우는 13.4에서 21.4로 10 AP_s 성능 향상이 되었다는 부분이었습니다. 결과적으로 MRFE가 FPN보다 backbone의 feature를 더 잘 처리하며 swintransformer가 small object를 검출하기 더 좋은 feature를 추출한다고 볼 수 있겠습니다.
리뷰 잘 읽었습니다.
본 논문은 아무래도 산자부 과제와 관련해서 읽어보신 거 같은데요, 어떤 부분에 적용할 법 해서 읽어보시게 된건가요??
그리고 저희 과제는 아무래도 fps가 중요할 수 밖에 없는데 본 논문은 fps 관련 실험이 없어서 좀 찝찝하긴 하네요. 본 논문의 구조로 미루어보아 제 생각엔 속도가 그다지 빨라보이진 않는데, 윤서님 생각은 어떠신가요
윤서님 안녕하세요!
좋은 리뷰 감사합니다.
글을 읽던 중 궁금한 부분이 생겨 질문드립니다.
layer마다 다른 receptive field를 제공하는 RFEB을 사용하였습니다. 이때 receptive field의 크기를 적절하게 선정하는 것이 성능과 직결된다고 생각이 됩니다.
논문에서 각 레이어마다 해당 크기의 receptive field를 사용하게 된 이유가 언급된 것이 있는 지, 또는 관련 ablation study가 있는지 궁금합니다.
감사합니다.
좋은 리뷰 감사합니다.
small object detection을 위한 multi-scale feature를 이용하는 아키텍처가 최근까지도 많이 연구가 되고 있네요.
1. union loss 자체는 되게 좋은 손실 함수를 설계한 것 같은데, 해등 논문에서 처음 제안된 것인가요?
2. 위의 권석준 연구원님의 말씀대로, swin으로 백본을 바꾸고 제안한 아키텍처를 붙여 성능은 증명되었지만, 파라미터 개수가 증가함에 따라 속도측면에서는 느려졌을 것이라고 생각이 드네요. OCR과 같은 어플리케이션 측면에서는 어느정도 추론 속도가 받쳐줘야 할 것으로 보이는데 관련된 실험 결과는 없었나요?
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
small object에 대한 논문은 오랜만인거 같아 재미나게 리뷰 읽었습니다. 흥미로운 부분은 표를 보면 small object에 대한 성능 뿐만 아니라 더 큰 사이즈의 object에 대해서도 성능도 향상되었다는 부분인거 같습니다. 또 인상깊은 부분은 MRFENet은 feature resolution을 변경하지 않고 receptive field를 확장해 small object 및 contextual cue에 대한 정보를 동시에 보존한다는 점인데, 간단하게 궁금한 점이 있습니다. 각 layer에 대해서 나온 값을 잘 융합하고 이에 대한 loss를 잘 구하는 것이 중요할 것 같은데, GIoU loss와 BIoU loss의 차이점이 무엇인가요? 이름으로 유츄하면 뭔가 GIoU에서 미세하게 달라 BIoU로 불리는거 같은데 잘 모르겠네요
감사합니다
안녕하세요 윤서님, 좋은 리뷰 감사합니다.
질문이 몇 가지 있습니다!
1. 조현석 연구원님 질문과 유사하게, dilate rate 비율이 layer5에서는 1,3,9,9 로 급격히 커졌었는데(3->9), 이 때 중간 블락 간의 rate가 3에서 9로 급격히 증가하면, 배경정보를 갑자기 확 넓혀진 receptive field를 통해 보게 될 것 같은데 그렇게 확 dilate rate을 늘리는 것에 대한 이유는 없었나요? 그리고 높은 dilate rate을 사용한 conv면 이를 거치고 나온 feature map 사이즈가 굉장히 작아질 것 같은데, 추후 doublenearest−neighbourinterpolation을 통해 2배 업샘플링(?)하는 과정이 fusion과정에서 resolution이 잘 맞아 떨어지나요? 왠지 이 측면에서는 feature resolution을 변경하지 않고 receptive field를 확장한다는 말이 뭔가 단서인 거 같은데 해당 워딩이 잘 이해가 되지 않아 여쭤봅니다!
2. fig4 에서 색깔 차이는 무엇을 의미하는 것인가요? b,d는 각각 layer4,2에 해당하면서 색깔축의 범위가 0.0~1.0인데, layer5,3에 해당하는 a,c는 색깔축의 범위가 0~9이길래 궁금하여 여쭤봅니다!
3. 김주연 연구원님 질문과 유사하게, union loss가 GIoU loss와 BIoU loss를 결합하여 구성되었다고 했는데, BIoU는 무엇인가요?
안녕하세요 좋은 리뷰 감사합니다.
우선 BIoU loss가 무엇인지 궁금합니다. 저자가 직접 contribution 중 하나로 union loss의 제안을 포함해뒀는데, BIoU loss는 박스의 종횡비까지 고려하는 특수한 loss인가요? 수식이라도 함께 알려주시면 좋을 것 같습니다.
그리고 표 2에서 Type과 Backbone 관련되어 궁금한 것이 있습니다. DETR은 영상 feature는 CNN이든 PVT든 추출한 후, Detection이 본격적으로 수행되는 모델이 Transformer 기반이기에 Type이 Transformer works로 들어갔다고 생각했는데, 저자가 제안하는 방법론은 Swin Transformer로 feature만 추출하고 뒤 detection은 모두 Convolution 기반 모델이지 않나요? 왜 본 방법론이 Transformer works로 들어가있는지 궁금합니다.