이번 리뷰도 저번에 이어서 Depth completion 논문에 해당합ㄴ디ㅏ. 이전 논문과 유사하게 gated convolution을 이용하고 raw depth를 보완하기 위한 방법을 제시합니다.

INTRO

이전 리뷰에서 다룬 바와 같이 RGBD 센서들은 fig 1과 같이 반사되는 물체나 센싱 대비 너무 먼거리나 너무 밝은 빛 등 다양한 이유로 invalid areas가 발생하게 됩니다. 그렇기에 depth completion과 같은 기법들이 요구되는 거죠. 물론 RGBD를 활용하는 다양한 기법들이 raw depth를 활용한 기법들이 제안되어 왔지만, fig 1과 같은 상황에서는 성능 저하가 필연적으로 발생할 수 밖에 없습니다. 이전 연구에서는 이러한 문제를 해결하기 위한 전통적인 기법에서는 bilateral filters, Markov random field와 같이 주어진 규칙에 따라 주변의 유효한 이웃들의 정보들을 활용해서 빈 공간을 채우는 방법을 활용합니다. 하지만 이러한 전통적인 기법들 실시간성을 보장할 만큼 빠르지도 않고 비교적 정확한 성능을 갖추고 있지도 않습니다. 또 다른 기법은 auto-encoder 구조를 가진 모델로 invalid aread를 예측하는 딥러닝 기법으로 놀라운 성과를 보여줬고, 대부분의 방법론들은 해당 기법을 적용하여 구현됩니다.
그러나 기초적인 딥러닝 기법에서는 해결해야하는 2가지 요소가 있다고 저자는 주장합니다. 첫째, 기존 vanilla convolution은 모든 입력을 유효한 값이라고 가정하고 정보를 처리합니다. 무슨 말이냐면, fig 1과 같이 depth map에는 invalid map이 발생하게 됩니다. 하지만 vanilla convolution은 invalid map을 구분하는 능력이 없어 구분 없이 정보를 추출하고 추출된 latent feature을 모순시키고 주어진 정보로부터 의도되지 않는 노이즈 정보를 생성할 가능성이 있습니다. 이러한 한계를 개선하기 위해서 자동으로 유효한 픽셀만을 구분하는 partial convolution이 제안되어지만, 이는 receptive filed 내에 유효한 픽셀이하나 이상만 포함해도 해당 영역은 유효하다고 판단해 연산을 수행하기 때문에 비교적 노이즈에 대한 강인성을 향상되었지만 본 문제에 대한 해결하지 못했다는 문제점이 있습니다. 더 나아가 gating mask를 학습하여 유효하지 않은 특징을 억제하고 신뢰 가능한 특징을 강화하는 gated convolution (GConv) 및 De-convolution (De-GConv)가 제안 되었습니다. 해당 기법은 유효하지 않은 픽셀이 있는 raw depth map에서 특징을 추출하기 위해 원활한 작동하지만 누락된 영역이 클 경우에는 여전히 제대로 처리하지 못하기 때문에 여전히 신뢰하기 힘듭니다. 저자가 주장하길 이러한 문제점을 제대로 해결하기 위해서는 색상(RGB)도 동시에 고려하여 접근하는 방법이 해결안이라고 주장합니다
두번째로 depth completion에서 color 정보를 활용하는 것은 긍정적인 영향과 부정적인 영향 모두 가져온다는 것입니다. 기존 기법들은 대부분 encoder로부터 추출된 depth와 color의 latent feature를 융합하여 사용합니다. 이는 깊이와 무관한 색상 특징 정보들이 포함되거나 오히려 도움이 될 텍스쳐 정보들이 유효하지 않는 깊이 정보에 대한 예측을 수행하면서 왜곡되는 형태로 융합된 결과가 나올 수 있습니다. 따라서 깊이와 색상 특징 정보 간의 융합은 서로 간의 간섭을 차단하는 메커니즘이 필요하다고 해석할 수 있습니다. 그러나 저자가 주장하길 이러한 연구들이 다뤄지지 않았다고 합니다.
이와 같은 문제점을 해결하기 위해 저자는 깊이와 색상 특징을 두 개의 병령 인코딩으로 추출한 다음 디코딩 단계에서 skip-connections을 통해 하나의 분기를 융합하는 UNet과 유사한 아키텍쳐 기반의 새로운 프레임워크를 제안합니다. 구체적으로 다루자면 두 모달리티에 대한 융합은 색상과 깊이 값 모두에서 joint contextual attention을 학습하여 유효하지 않은 깊이 영역에 대한 적절한 예측이 가능하도록 안내하는 Attention Guided Gated Convolution (AG-GConv)를 제안합니다. 또한 Attention Guided Skip-Connection (AG-SC) module을 통해 깊이 예측에 있어 관련 없는 색상 특징을 필터링하도록 설계했습니다. 본 논문에 대한 저자가 작성한 기여를 옮겨두자면 다음과 같습니다.
- We propose a dual-branch multi-scale encoder- decoder network that combines depth and color fea- tures to achieve high-quality completion of the depth image.
- An Attention Guided Gated Convolution (AG-GConv) module is proposed to alleviate the adverse impacts of invalid depth values on feature learning.
- A new Attention Guided Skip Connection (AG-SC) module is presented to reduce the interference from depth-irrelevant color features to the decoder.
- Experimental results indicate that our model outper- forms state-of-the-art on three popular benchmarks, including NYU-Depth V2, DIML and SUN RGB-D datasets
METHOD
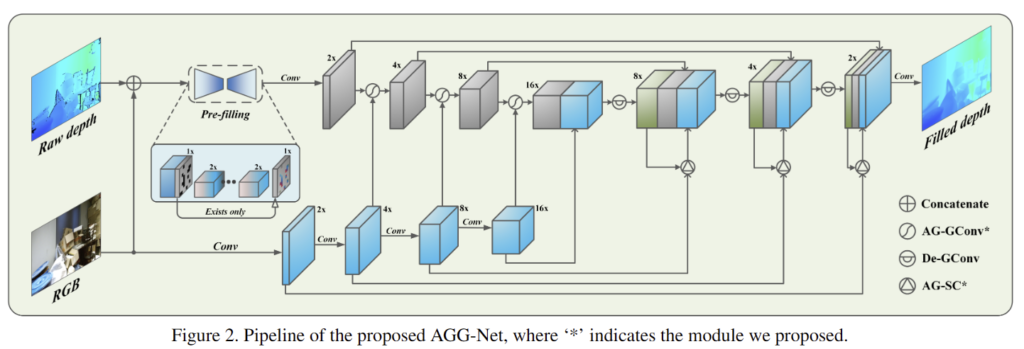
Architecture
Overview. 제안된 기법에 대한 전반적인 구조는 fig 2에서 확인 가능합니다. 해당 기법을 크게 구분하면 pre-filling network와 fine-tuning network로 구성됩니다.
+ 나머지를 fine-tunning network로 호칭을 하는데…. 적절한 표현은 아닌 것 같습니다.
pre-filling network는 raw depth와 이에 대응되는 영상을 입력으로 tiny auto-encoder를 통해 대략적인 depth completion을 수행합니다. fin-tunning netwrok에서는 dual-branch encoder를 통해 깊이와 컬러 모두에서 특징을 추출합니다. 그런 다음 multi-scale skip-connected decoder를 통해 보완된 깊이 정보를 생성합니다. 또한, AG-GConv는 encoder, AG-SC는 Decoder 레이어에 내장되어 두 모달리티의 융합을 보다 상호보완적으로 동작시켜 깊이 보완 영상을 향상시키도록 합니다.
Pre-filling. 앞서 설명한 바와 같이 해당 파트는 tiny한 convolution과 deconvolution인 auto-encoder로 구성된 depth completion 모델로 깊이 영상과 컬러 영상을 결합한 4채널 정보가 입력으로 들어가게 됩니다. 해당 모델은 유효하지 않은 깊이 값들을 대략적으로 채우는 용도로 사용됩니다. 해당 모델에서는 누락이 큰 영역에 대해 충분히 커버 가능하도록 넓은 커널을 활용합니다. 이를 통해 0 값이 픽셀 없이 유효하지 않은 영역이 채워진 대략적인 (coarse) 깊이 정보를 생성합니다.
Fine-tunning. fig 2와 같이 dual-branch UNet-like 구조를 가진 모델로 대략적인 깊이 정보와 이에 대응되는 컬러 정보를 입력으로 받아 최종적으로 보완된 깊이 정보를 출력합니다. 각 encoding layer는 vanillar convolution 또는 gated covolution과 다르게 저자가 제안하는 AG-GConv 모듈은 깊이 및 색상 특징을 기반으로 학습한 contextual attention (CA)의 안내에 따라 elenment-wise mask를 생성해 깊이 특징을 게이트 하도록 합니다. decoding layer에서는 De-GConv 모듈과 제안한 AG-SC 모듈을 적용해 color encoding layer로부터 해당 depth decoding layer로 skip-connection을 수행하며, 깊이 정보와 무관한 색상 깊이 정보들이 전달되지 않도록 제안된 attention 기법이 적용됩니다.
Ecoding with AG-GConv

대부분의 기존 encoder들은 fig 3-(a)와 같이 multilayer vanilla convolution (VConv)을 통해 특징을 추출합니다. 해당 모델에서는 pre-fiiling으로 채워진 값들이 전송되지만, 그럼에도 불구하고 거칠게 채워진 깊이 값들은 신뢰할 수 없으며, 그대로 입력이 될 경우에는 잘못된 예측값을 생성할 수 있습니다. fig 3-(b)와 같이 gating signal을 사용하여 신뢰할 수 없는 값들을 걸러내는 gated convolution을 사용해 어느정도 해결이 가능하긴 합니다. 그러나 해당 기법도 여전히 문제점을 가지고 있습니다. 깊이 특징만 고려해서 컬러 특징에 숨겨진 유의미한 정보들을 무시하고, 작은 receptive field를 기반으로 gating signal을 생성해 큰 누락을 채우는 능력이 부족하다는 문제점이 있습니다. 이러한 한계를 극복하기 위해 깊이와 색상 분기 모두에서 학습한 CA의 안내에 따라 깊이 특징을 조절하는 AG-GConv를 제안했습니다. AG-GConv에서 깊이와 색상 특징을 F_d, F_c 로 표현됩니다. 먼저, fig 3-(c)와 같이 깊이 특징은 stride=1, stride=2의 두 개의 연속적인 VConv를 통해 F^{'}_d \in R^{H\divideontimes 2 \times W\divideontimes 2 \times C} 로 변경하고, 두 특징 정보를 결합하여 F_{all} = [ F^'_d, F_c] 를 만듭니다. 그 다음, stride = 1인 VConv에 전달하여 2C -> C의 특징을 생성합니다.
해당 특징은 gating signal을 생성하기 위한 CA 모듈에 입력합니다. 먼저, F_all을 채널에 따라 flatten한 S를 생성합니다. S의 각 요소들은 f_i로 표현합니다. CA는 fig 3-(d)와 같이 global context atteion을 학습 하기 위해 두 개의 FClayer로 입력됩니다. 해당 레이어는 ReLU (M=4L)와 L개의 sigmoid로 통해 ouput vector g_i 를 생성합니다, 이는 다음과 같습니다.
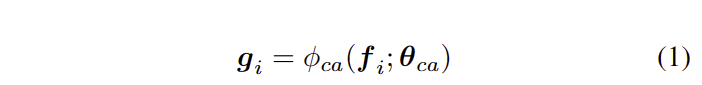
여기서 \phi_{ca} 는 CA network의 mapping function으로 일반적으로 ReLU를 이용합니다. 해당 네트워크를 통해 모든 공간적 위치를 고려하여 특정 특징의 슬라이스 영역에 대한 관심도를 평가합니다. 이렇게 나온 텐서는 gating tensor G_d 로 패킹되며, AG-GConv 모듈의 출력으로 깊이 특징 F_d에 gating tensor G_d를 가해 다음과 같이 얻습니다.
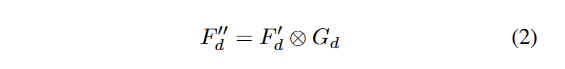
여기서 ⊗는 element-wise multiplication입니다. 출력값은 다음 encoding layer의 입력으로 전송됩니다.
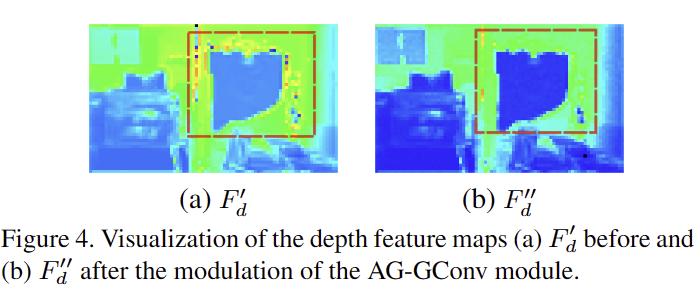
Motivation analysis. 큰 누락이 발생한 raw depth인 경우, 주변 픽셀 또한 유효하지 않기 때문에 low-level feature에서도 유사한 경향을 보일 겁니다. 대표적으로 VConv가 동일한 경향을 보이며, 이런 패턴을 보이는 경우를 구분 할 수 없습니다. 결과적으로 layer가 거듭됨에 따라 같이 확산되어 최종 결과값에도 큰 영향을 줍니다. GConv는 선택적으로 전달이 가능하지만 depth 정보에만 취중되는 한계를 가지고 있다는 한계를 가지고 있죠. 이에 반해 AG-GConv는 깊이와 색상 특징을 모두 고려하고 공간과 채널 모두에 걸쳐 joint contextual attention을 생성하여 gating signal을 이용하기에 더 나아진 결과를 보인다고 주장하며, fig 4와 같이 큰 누락(빨간색 상자)을 둘러싼 흩어진 불필요한 정보들(fig 4-(a)이 대부분 제거된 것(fig 4-(b))을 확인 할 수 있습니다. 이를 통해 저자는 해당 인코더가 유효하지 않은 특징이 아닌 신뢰 할수 있는 특징들로 특징 정보들을 생성한다는 것을 보인다고 합니다.
Decofing with AG-SC
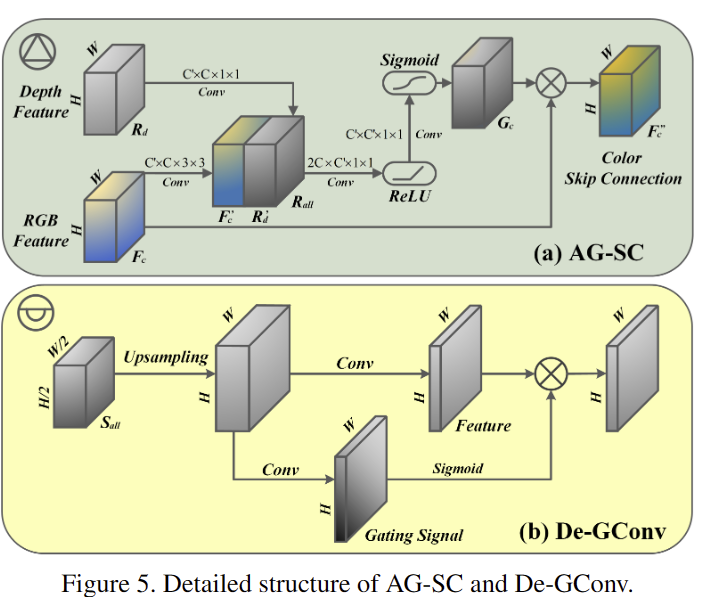
대부분의 기존 모델들은 decoder의 구성으로 upsampling과 deconvolution을 활용하여 설계를 합니다. 하지만 이를 단순하게 설계를 하면 fine-scale faeatures에 손상이 가기 때문에 muliscale skip-connection으로 구성하는 방식을 이용합니다. 그리고 color feature가 누락된 깊이 값을 예측하는 데에 도움이 된다는 것은 단안 깊이 연구에서 입증이 된 상태죠. 이를 근거로 fig 5와 같은 새로운 디코딩 구조를 제안합니다. 각 디코딩 레이어는 3 가지 입력 -> ‘depth branch의 전 단계 레이어의 특징 정보, depth encoder의 skip-connection, 대응되는 color encoder의 특징’을 전달 받아 특징을 생성합니다. 먼저, color skip connection의 특징은 F_c, 이전 층의 깊이 특징은 R_d로 구성되며, VConv (kernel size 1×1 and 3×3)을 탄 뒤, fig 5-(a)와 같이 R^{'}_{all} = [ R^{'}_d; F^{'}_c] 로 사이즈는 H x W x 2C로 구성됩니다. 그런 다음 ReLU와 sigmoid로 구성된 VConv를 통해 gating signal G_c를 학습합니다. 마지막으로 AS-SC의 출력은 요소별 element-wise production을 통해 다음과 같은 방식으로 생성됩니다.
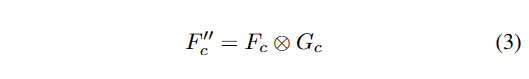
그런 다음 feature stensor S_{all} = [ R_d; F_d; F^{''}_c] 로 결합되어져 fig 5-(b)인 De-GConv에 태워져 다음 계층으로 전달됩니다.
Loss Functions
손실 함수는 2개의 텀으로 구성됩니다. 이는 다음과 같습니다.

첫번째 텀은 reconstruction error를 측정하기 위한 Huber loss로 구체적인 정의는 다음과 같습니다.

\hat{d}_{i,j} 는 location (i, j)에서의 depth value이며, d_{i,j} 는 GT에 해당합니다. M, N은 reconstructed image의 높이와 넓이입니다. huber loss는 픽셀 단위로 재구성된 오류에 대해 흔히 쓰이는 손실 함수로 이상값에 강인함을 가졌다는 것이 특징입니다.
두번째 텀은 edge pesistence loss로 다음과 같이 정의됩니다.
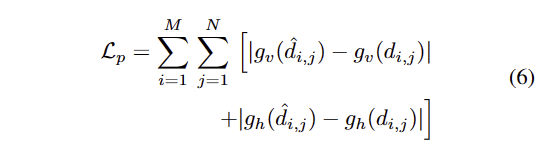
g_v와 ㅎ_h는 영상의 수직 및 수평 기울기에 대한 정보로 재구성된 깊이 영상과 GT 사이의 경계 일관성 여부를 유지하는 것이 목적입니다.
EXPERIMENT
해당 방법론에서는 NYU-Depth v2, DIML, SUN RGBD를 사용합니다.
Ablation Studies
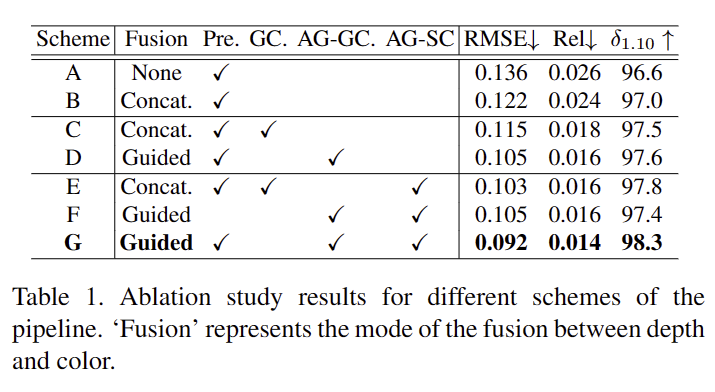
On pipeline. tab 1에서 확인 가능하며, 기본 프레임워크는 vConv와 skip-connection으로 구성된 UNet-like archecture입니다. Scheme B에서 Fusion->Concat은 깊이와 컬러 특징의 융합을 각 인코더 레이어에서 수행한 방식을 의미합니다. Scheme C와 D는 각각 GConv를 적용, GConv와 De-GConv를 적용한 아키텍쳐를 의미합니다. Schcme E,F,G는 각각 제안한 기법을 적용한 예시입니다. 결과적으로 제안한 모듈을 적용할 경우에 모든 결과에서 개선된 성능을 보입니다.
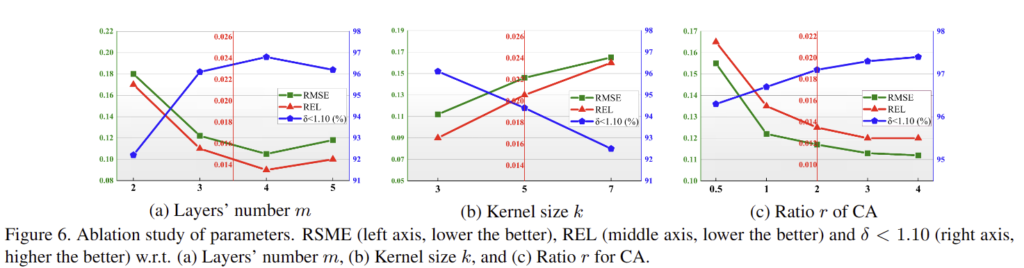
On layers. 레이어의 수 m에 따른 성능 차이로 fig 6-(a)에 해당하며 m=4일 때, 가장 좋은 성능을 보임
On kernel size. 최적의 gating signal 생성을 위한 kernel size. fig 6-(b)와 같이 kernel size k=3에서 가장 좋은 결과를 보임
On hidden layer of CA. CA에 적용된 FC-layer의 hiddeon unit의 input feature 대비 크기의 비율 r에 대한 실험으로 fig 6-(c)와 같 r=4에서 가장 좋은 성능을 보임
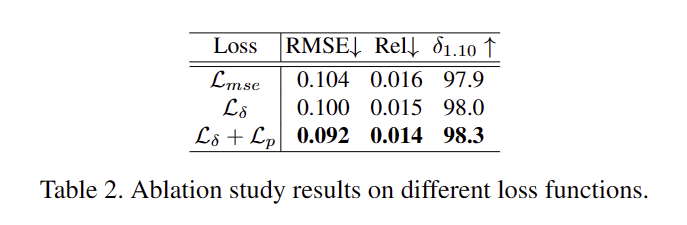
On loss function. tab 2에서 확인 가
Comparison to SOTA
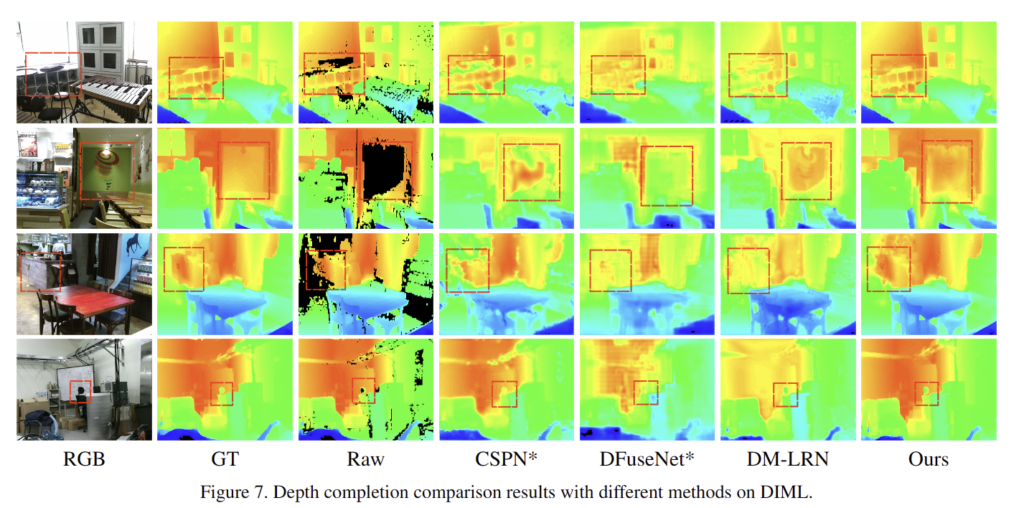

Fig 7과 tab 3와 같이 가장 좋은 성능을 보임