안녕하세요, 오늘의 X-Review는 22년도 ECCV에 게재된 Open-Vocabulary Object Detection (OVOD) 관련 논문입니다. 구글에서 진행된 연구네요. CLIP과 유사한 방식으로 영상과 텍스트 간 거대 사전학습을 수행한 후 이를 OD로 확장 모델을 구축한 방법론입니다. 와이즈넛 과제에서 결국 전장 도메인과 관련된 OVOD를 수행해야하는데 제가 그쪽 분야에 대한 지식이 전무하여 코드 공개가 잘 되어있고 관리가 잘되고 있는 본 논문의 방법론을 베이스라인 모델로 삼고자 세세하게 읽고 리뷰로 남기려고 합니다. 지금까지 follow-up 하던 task가 아니라 잘 이해할 수 있을지 두려움이 있지만, 천천히 하나씩 알아보도록 하겠습니다.

1. Introduction
우선 OVOD라는 task는 Object Detection과 목적 동일합니다. 영상 내 존재하는 물체의 위치와 클래스를 찾아내는 것이죠. 이 때 Open-Vocabulary라는 단어가 붙어있는데, 이는 학습 과정 중 많이 보지 못했거나 아예 보지 못한 클래스들을 의미합니다. 이들에 대해서도 강인한 추론을 해내는 것이 목적이고, 일반적으로는 거대 사전학습의 표현력을 빌려와 이를 달성하는 것으로 보입니다.
OVOD task가 21년도에 제안되었다고 알고 있는데, 이를 감안하면 22년도에 게재된 본 논문도 꽤나 초창기 연구라고 볼 수 있을 것입니다. 이전까지 비전 분야의 근본과도 같은 task인 OD는, 특정 데이터셋 내 존재하는 클래스에 대해서만 한정적으로 inference할 수 있었습니다. OD를 산업적으로 적용하려면 그 도메인에 맞게 데이터셋을 또 구축하고 학습시키는 정교한 과정이 반드시 필요했던 것이죠.
하지만 CLIP과 같은 거대 image-text 사전학습 모델을 통해, 웹 데이터로부터 학습한 지식을 바탕으로 학습하지 않은 클래스에 대한 분류도 가능케하는 Zero-shot 기반 분류가 가능하게 되었습니다. CLIP에 대해서는 제 이전 리뷰에도 많이 담겨있으니 모르시는 분들은 참고하시면 좋을 것 같습니다. 아무튼 그 당시에도 벌써 많은 연구들이 image classification을 넘어 OD에도 CLIP의 표현력을 빌려오고 있었습니다. 저자도 이러한 흐름에 맞춰 ViT를 활용한 간단한 architecture로 당시 높은 성능을 보이는 OVOD 모델을 제안하였습니다.
물론 OD를 수행해야하니 ViT를 그대로 쓸 순 없을 것이고, 일부를 수정하여 사용하였습니다. 기존 아키텍쳐의 마지막 pooling layer를 떼어내고 그 자리에 각 토큰에 대한 가벼운 detector(classification and box head)를 붙여줍니다. Open-Vocabulary classification을 수행하기 위해 기존 분류 레이어 output을 CLIP의 text encoder의 class-name embedding으로 대체하였고, 이에 대한 localization을 위해 학계 OD 데이터셋으로 사전학습된 DETR 프레임워크 일부 수정해 사용했다고 합니다.
좀 특이하다고 생각이 든 점이 하나 있는데, 기존의 CLIP을 활용하는 대부분의 zero-shot 또는 few-shot 방법론들은 text-conditioned task였습니다. 제가 연구하던 분야인 비디오의 Temporal Action Localization을 예로 들어도, 모든 action 클래스 이름을 CLIP의 text encoder를 통해 feature로 만들어주고 비디오와 text feature의 유사도를 구하는 방식이었습니다. 즉 text feature들을 기준으로, 비디오에서 “창 던지기”를 찾거나 “멀리뛰기”를 찾는 상황이었는데 저자의 방법론으로 image-conditioned one-shot OD가 별다른 모델 변형 없이 가능하다고 합니다. 이는 쿼리로 text를 던지는게 아니고 영상 내 물체를 crop한 패치를 condition으로 주고 다른 영상 내 그 물체를 찾아내는 것이죠. 이러한 방식을 통해 text로 설명하기 모호한 물체에 대해서도 one-shot 기반의 OD가 가능해진 것입니다. 물론 저자가 이 기법 자체를 처음 제안한 것은 아니지만, 뭔가 간단한 생각의 전환이자 기존에 있던 task를 거대 사전학습 모델에 접목시킨 것 뿐인데 꽤나 새롭게 느껴지네요.
본 방법론은 Vision Transformer for Open-World Localization, OWL-ViT라고 합니다. 구현 방식이 굉장히 단순하며 성능이 좋아 후속 연구의 베이스라인이 될 수 있을 것이라고 기대하고 있고, 실제로 코드 공개나 관리도 잘 되고 있어 개발 관점에서도 활용하기 좋은 방법론인 것 같습니다. Contribution을 정리한 뒤 Related Work로 넘어가겠습니다.
Contribution
- A simple and strong recipe for transferring image-level pre-training to open-vocabulary object detection.
- State-of-the-art one-shot (image conditional) detection by a large margin.
- A detailed scaling and ablation study to justify our design.
2. Related Work
OVOD에 대해 처음 읽는 논문이다보니 Related work도 정리해보겠습니다.
2.1 Contrastive Vision-Language Pre-Training
CLIP이나 ALIGN 등의 거대 image-text 사전학습 모델을 통해, 학습 때 보지 못한 클래스 단어에 대해서도 text encoder가 유의미한 feature를 만들어낼 수 있게 되었고 이를 통한 zero-shot 분류가 가능해졌습니다. 지금까지도 마찬가지이지만 CLIP 등장 이후 CLIP의 사전학습 표현력을 향상시킬 수 있는 다양한 방법론들이 연구되며 빠른 속도로 zero-shot classification 성능이 올라가고 있는 상황입니다. 저자는 LiT나 ALIGN이라는 방법론이 OWL-ViT와 가장 직접적으로 비교 가능하다라고 하는데, 아직 해당 방법론들에 대한 자세한 사항들은 몰라 추후에 정리해보도록 하겠습니다.
2.2 Closed-Vocabulary Object Detection
Open-Vocabulary scheme이 등장하면서 기존에 저희가 알고있던 OD는 이제 Closed-Vocabualry OD로 불리게 되었나봅니다. 저희 연구실 분들이라면 모두 잘 알고있을 SSD, Faster-RNN과 같은 고전 detector를 간단히 언급하고 있고, 아직도 활발히 후속 연구가 진행되고 있는 DETR에 대한 설명도 있습니다. DETR은 제가 이제부터 연구하고자 하는 비디오 분야의 Temporal Sentence Grounding in Videos (Video Moment Retrieval) task에서도 EaTR, QD-DETR, MH-DETR, MomentDETR, BAM-DETR, CG-DETR, TR-DETR 등의 이름으로 23년도 이후부터는 엄청나게 많은 DETR 기반 방법론들이 쏟아져 나오고 있고, 추세로 자리매김한 상황입니다. 여기까지 뻗어져온 것을 보면 파급력이 굉장히 큰 연구라고 볼 수 있을 것입니다.
아무튼 DETR에 대한 설명을 함께 살펴보자면, DETR은 OD를 이분 매칭 기반의 set prediction problem 관점에서 바라보며 높은 성능을 달성한 방법론입니다. 제가 주로 살펴보는 task가 아닌지라 본 방법론 자체에 대한 깊은 고찰은 해본 적 없지만, 쿼리를 던져 GT와 매칭시키는 과정을 통해 학습을 진행하고 이에 따라 heuristic한 region proposal이나 NMS 과정을 없앴다는 것이 큰 contribution이었다고 볼 수 있을 것입니다. 저자도 DETR 방식을 따라 OD를 수행하고자 하였는데, DETR도 그대로 가져다 쓰는 것이 아니라 decoder를 삭제하고 하나의 image token을 바로 “detection token”으로 활용하여 OD를 수행하도록 간단화하여 사용했습니다. 자세한 내용은 방법론에서 살펴보겠습니다. DETR에 대한 자세한 설명이 궁금하신 분들은 이상인 연구원의 DETR 논문 리뷰를 참고해주시면 좋을 것 같습니다.
2.3 Long-Tailed and Open-Vocabulary Object Detection
Closed-Vocabulary OD에 반해, OVOD는 분류기 부분을 고정된 classification layer에서 사전학습된 CLIP text encoder와 같은 모델로 갈아 낌으로써 open-vocabulary object detector를 완성하게 됩니다. 이러한 OVOD를 잘 수행하기 위해 거대 image-text 사전학습 모델의 지식을 어떻게 detection으로 가지고 올 것인지가 중요할 것입니다. 이걸 가져오는 과정에서의 가장 큰 문제는 희소 클래스에 대한 localization annotation이 부족하다는 점입니다. 사람이 붙어서 정확한 annotation을 수행하는 것이 가장 효과적이겠지만 이에 수반되는 다양한 cost를 생각해보았을 때 효율적이진 못하겠죠. 그래서 학계에선 몇 없는 annotation을 어떻게 효과적으로 활용할 것인지에 대한 연구가 아래와 같이 진행되고 있었습니다.
ViLD 방법론은, CLIP이나 ALIGN과 같은 모델로부터 RPN을 함께 활용해 영상 내 물체 영역을 crop하여 라벨을 만들어 학습하는 방식입니다. 그러나 RPN을 사용하는 것부터 모델의 upper 성능은 RPN 성능에 의존적일 수 밖에 없고, two-step으로 구성된 학습 과정이 처음보는 물체에 대한 성능의 저하를 일으킬 것입니다. RegionCLIP이라는 방법론도 마찬가지로 multistage 학습 방식을 도입했는데 captioning data로부터 pseudo-label을 생성하고 이렇게 얻은 region과 text에 대한 contrastive pretraining을 수행하는 방식으로 detection을 학습했다고 합니다. 이에 반해 저자가 제안하는 OWL-ViT는 학계에서 활용하는 OD 데이터셋을 엮어 end-to-end로 두 모달의 encoder 모두를 한 번에 학습시켰다는 장점이 있습니다. 최근 제안된 OVR-CNN이라는 방법론이 OVOD에서 OWL-ViT와 가장 직접 비교를 수행할만하다고 이야기하는데요, 전반적으로 image-text 모델을 fine-tuning하여 OVOD에 활용한다는 점은 동일합니다. 그러나 ResNet 대신 ViT를, Faster-RCNN 대신 DETR-like 모델을 사용한 점 등에서 차별점이 있다고 합니다.
저자가 이야기하는 open-vocabulary라 함은, 테스트에서 정말 학습 때 한 번도 보지 못한 물체가 등장하는 것은 아니라고 합니다. 어느 정도 중복이 있을 수 있고, 이렇게 학습 때 전혀 보지 못한 물체를 test 때 detect해야 하는 상황은 zero-shot이라고 칭하고 있습니다. 특정 데이터셋에 존재하는 클래스 중 일부를 학습 때 제외시켜놓고 학습한 뒤 제외해두었던 클래스로 평가하면 zero-shot, 거대 용량의 web data로 사전학습하고 특정 데이터셋에서 평가를 진행하면 겹치지 않는다고 보장할 수 없기에 open-vocabulary라 칭하는 것도 일부 있는 것 같습니다. 아니면 detector를 fine-tuning하는 과정에서 학계의 여러 데이터셋을 엮어 만든 데이터셋을 사용하는데, 이 때 학습과 추론 간 중복되거나 굉장히 유사한 클래스가 있을 수도 있어 아예 못 본 클래스라고 할 순 없기 때문인 것도 있는 것으로 보입니다. OVOD와 OWOD, Zero-shot 간 차이점이 머릿속에 명확하게 구분되지 않았는데 이번 기회에 정리할 수 있었습니다.
2.4 Image-Conditioned Detection
OVOD와 엮을 수 있는 task 중 하나가 image-conditioned detection이라고 합니다. 이름 그대로 영상 내 물체의 patch 자체를 쿼리로 주어 이게 무엇인지 one-shot 기반의 학습을 수행하고 이렇게 학습된 모델이 추론 때 방금 본 새로운 물체에 대해서도 강인하게 탐지해낼 수 있도록 하는 것이 목적입니다. 이는 one-shot object detection과도 동일한 것을 의미합니다. 이런 image-based object detection은 one-shot 학습을 수행할 때 물체 영상만 주고 물체가 무엇인지 알려주지 않는 open-world object detection으로도 바로 확장이 가능합니다. 정말 물체가 unique하거나 전문 용어로 표현되기 때문에 text로 기술하기 어렵다면 위와 같은 방법론이 효과적이겠죠. 저자가 이러한 task를 처음 제안한 것은 아니지만 저는 본 논문을 통해 task의 존재를 처음 알게 되었고, 우선 OWL-ViT에서는 이를 위한 별다른 학습 없이 거대 image-text 사전학습 성능에 기대어 수행하고 있다고 합니다.
드디어 방법론을 살펴보겠습니다.
3. Method
OWL-ViT 모델의 구조를 알아보겠습니다.
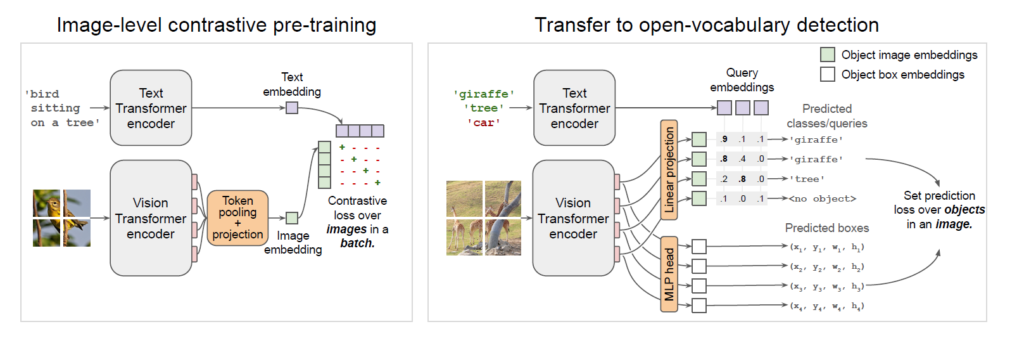
그림 1은 OWL-ViT의 전체 구조를 나타내고 있습니다. 왼쪽과 오른쪽 각각을 통틀어 2단계로 이루어져 있습니다. 왼쪽은 CLIP의 사전학습 방식과 동일하게 대용량 image-text 데이터로 image, text encoder를 사전학습하는 단계입니다. 이렇게 사전학습을 마쳤다면 오른쪽은 detection head를 붙이고 학계의 OD 데이터셋을 모으고 중복을 제거한 데이터 샘플들로 OD fine-tuning을 진행하는 것입니다. 이 모델을 통해 open-vocabulary 또는 few-shot 기반 추론이 모두 가능합니다. 큰 그림만 두고 보자면 아직은 굉장히 간단하네요.
3.1 Model
Architecture
OWL-ViT에서 image encoder는 ViT, text encoder는 Transformer 구조를 따라가는데, 아까도 말씀드렸듯 일부 변형이 존재합니다. 1단계 image-level 사전학습을 마치면 이를 detection에 활용하기 위해 image encoder에서 token pooling과 마지막 projection layer를 떼어내고, 분류를 위한 object 별 영상 embedding을 만들어줄 Linear projection layer를 붙입니다. 여기서 나오는 token의 개수가 영상 내에서 탐지할 수 있는 최대 객체의 개수와 같겠죠. 이 개수는 현존하는 학계의 OD 데이터셋 내 존재하는 영상 당 객체 개수(294)보다 더 큰 최소 576개로 정해져있기 때문에 detection에 있어 bottleneck이 되지 않는 상황입니다. 분류는 위와 같이 진행되고, bounding box 좌표를 찾기 위해 아까 얻은 token을 MLP에 태워줍니다. 그림 1의 오른쪽에서 모두 확인할 수 있습니다.
Open-Vocabulary Object Detection
기존 OD에서는 찾은 박스에 대한 분류를 수행하기 위해 클래스 토큰 embedding을 사용했습니다. 하지만 OVOD는 학습 때 전혀 보지 못한 물체에 대해서도 분류 할 수 있어야 하기 때문에 위와 같은 기존의 방식 대신 queries라고 하는 text embedding을 사용합니다. Queries는 클래스 이름 text 또는 물체에 대한 설명 text를, 사전학습을 마친 text encoder에 태워 얻을 수 있겠죠. 이 text들은 현실적으로 수백, 수천가지에 해당하는 것은 아니고, 학습 때는 못봤지만 추론하고자 하는 도메인에 속한 정해진 개수만큼의 집합이라고 생각하시면 됩니다. 원래 OD에선 train set과 test set에 존재하는 클래스들의 집합이 동일했지만, OVOD에선 test set에서 분류해야 할 클래스들이 일부 겹치거나 새로운 상황이라는 것입니다. 이에 대한 분류는 대용량 데이터 샘플들로 사전학습된 encoder의 힘을 빌리는 것이죠.
또한 OWL-ViT 구조 상 image encoder와 text encoder의 feature를 합치는 연산이 없습니다. 직관적으로는 최종 detection을 수행할 때 두 모달의 특성을 잘 살려줄 수 있는 fusion이 필수적일 것으로 생각되지만, inference 할 때 가지고 있는 모든 text query에 대한 영상과의 fusion 연산이 반복돼야 하기 때문에 이 과정에서 효율성이 크게 떨어져 제외했다고 합니다. 이와 같은 이유로, OWL-ViT에서 영상 feature는 image encoder에서 따로, 클래스 feature는 text encoder에서 따로 추출되고 분류 시에만 두 모달이 함께 사용됩니다. 이로 인해 표현력 측면에서 일부는 손해를 본다 할지라도, 효율성 관점에서 여러 개의 text query를 동시에 활용해야 할 때 발생할 수 있는 부담을 많이 줄이게 된 것이죠.
One- or Few-Shot Transfer
앞선 Related Works에서 image-conditioned OD도 수행할 수 있다는 말씀을 드렸었습니다. OWL-ViT 구조 상 두 모달의 feature를 합치는 연산이 없기 때문에, 분류를 수행할 때 text encoder에서 나온 feature를 쿼리로 두는 상황 뿐만 아니라 image feature를 쿼리로 두는 추론도 모델 구조 변형없이 가능하게 됩니다. Localization을 수행한 뒤 해당 박스의 클래스를 찾을 때 주어진 영상 feature들과 비교해서 가장 유사한 영상을 찾아내는 것이죠. 이는 text로 설명하기 복잡한 일부 물체들 또한 찾아낼 수 있다는 큰 확장성을 가져옵니다.
3.2 Training
앞서 모델 구조에 대해 이야기하였습니다. 이에 대해 간단히 정리하자면, image encoder는 ViT의 일부 변형, OD를 위한 DETR 변형 모델, text encoder는 Transformer를 사용하였음을 알 수 있었습니다. 위와 같은 구조로 각 모달에 대해 뽑은 feature 간 유사도를 구함으로써 OVOD를 수행하게 되는 것이었습니다.
본 절에서는 위와 같은 구조의 모델이 OVOD를 수행할 때 결국 대용량 데이터셋으로 사전학습된 표현력에 기댈 수 밖에 없게 된다 말씀드렸는데, 해당 사전학습이 어떻게 진행되는지 알아보겠습니다. 아래에 다시 그림 1을 가져와봤는데, 왼쪽 파트와 오른쪽 파트를 나눠 살펴보겠습니다.
Image-Level Contrastive Pre-Training
그림 1의 왼쪽 부분에 해당하는 Image-level contrastive pre-training 단계입니다. 각 encoder는 스크래치 레벨로부터 사전학습을 시작했고, 사전학습에 사용된 데이터셋은 LiT 방법론과 동일한 약 3.6억개 image-text 쌍(웹 데이터)입니다. 이 사전학습 단계는 패치 level의 feature가 아닌, text feature와 직접 contrastive learning을 수행할 image level의 feature가 필요하기 때문에 token pooling 과정을 적용해줍니다. 이 때 얻은 토큰들을 Global Average Pooling(GAP) 하는 방식 대신 Multihead Attention Pooling(MAP)을 사용하였고, 이는 출력된 토큰을 다시 입력으로 Multihead self attention을 취하여 aggregate한 값을 최종 image-level feature로 사용한다는 것입니다.
Text feature의 경우 사전학습 데이터셋에 존재하는 text들을 text encoder에 태워 얻은 마지막 토큰을 사용합니다. 결국 두 모달의 feature를 얻었다면 CLIP과 동일한 방식으로 contrastive learning을 수행해줍니다. 이렇게 약 3.6억개의 데이터셋으로 사전학습한 encoder 대신 CLIP의 image, text encoder를 활용할 때의 성능도 리포팅하고 있다고 합니다. 이러한 모델 구조에서 모델 전체 파라미터 중 detection head의 파라미터는 1.1%밖에 차지하지 않아 나머지 거의 모든 파라미터가 위 사전학습의 이점을 누려 해당 표현력을 지니고 있다는 것이 장점입니다.
Training the Detector
Detection에 활용할 encoder들의 사전학습까지 마친 상태이고, 이제 OD에 대한 fine-tuning을 수행하는 단계입니다. 우선 구조 관점에서는, token pooling 및 projection layer가 떨어지고 DETR과 유사한 구조의 detector가 붙게 됩니다. 기존까지 사전학습된 image-text 표현력을 classification으로 끌어와 사용하는 연구는 많이 진행됐었습니다. OWL-ViT에서는 잘 연구되어있는 분류의 fine-tuning 방법론을 open-vocabulary로 확장하는 것이 목적이겠죠. 하지만 분류 학습 방식 자체는 closed-set OD와 유사하고 단지 새로운 클래스 이름들을 쿼리로 만들어 던진다는 점만 다릅니다. 결국 분류기는 영상 쿼리들과 텍스트 쿼리들 간의 유사도를 내뱉게 되는 것입니다.(그림 1, 우측 참조)
저자는 OVOD fine-tuning을 위해 DETR의 bipartite matching loss를 가져와 사용합니다. 그러나 본 연구에서 해결하고자 하는 detection의 컨셉이 long-tailed, open-vocabulary이기 때문에 이에 맞는 수정을 가해줍니다. 우선 image-level 사전학습에 이어 detection을 위한 사전학습을 진행해야 하는데, 이를 위한 데이터셋을 구축해야 합니다. 기본적으로 학계에 존재하는 데이터셋을 엮어냈고 엮는 과정에서 동일한 물체가 다른 클래스를 갖는 경우가 있었다고 합니다. 이게 서로 다른 데이터셋에 동일한 영상 내 동일한 물체가 서로 다른 클래스로 라벨링 되어있었다는 것을 의미하는것인지 정확히는 모르겠지만, 이렇게 multiple labels를 갖는 물체를 위해 softmax -> cross-entropy 대신 focal sigmoid -> cross-entropy loss를 사용했습니다.
모델 구조 부분을 정리하자면 … Transformer와 ViT를 각각 text, image encoder로 두고 image-level의 사전학습을 약 4억개의 쌍으로 먼저 수행했습니다. 이렇게 사전학습을 마친 encoder들에 대해 DETR과 유사한 방식으로 detector를 붙이고 학계 OD 데이터셋을 엮어 detection에 대한 사전학습을 수행한 것입니다.
이제 조금 더 디테일한 내용과 실험 결과를 아래에서 살펴보겠습니다.
4. Experiments
4.1 Model Details
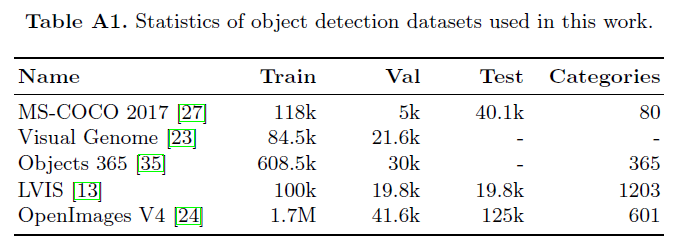
Image encoder는 ViT 구조이고, text encoder도 Transformer로 12 layers, hidden state dimension은 512, MLP는 2048차원, 헤드 개수는 8개로 설정했다고 합니다. Image-level 사전학습은 LiT와 동일한 36억개의 쌍으로 진행되었으며 이후 detector를 붙여 약 2백만 개의 detection 데이터 샘플들로 fine-tuning이 진행되었습니다. 약 2백만 개의 detection 데이터셋은 OpenImages V4 (OI), Objects 365 (O365), Visual Genome (VG)을 합치고 중복 제거 등의 전처리를 거쳐 구축되었습니다. 이후 평가는 COCO, LVIS, O365에 대해 이루어졌습니다. 각 데이터셋의 통계량은 위 표 A1에서 확인할 수 있습니다.
4.2 Open-Vocabulary Detection Performance
OVOD task가 학습 때 보지 못한, long-tailed 클래스에 대해 평가를 해야하는데 이러한 상황에서의 평가가 가장 용이한 데이터셋이 LVIS v1.0 val 셋이라고 합니다. 물론 다른 데이터셋에 대한 벤치마크도 수행하지만, 메인 성능 비교는 본 데이터셋으로 수행되는 것입니다. LVIS v1.0 val 데이터셋의 총 클래스 개수는 1,203개이므로 평가 때는 text encoder를 통해 1,203개의 text feature를 얻고 각 영상마다 비교를 해주게 되는 것입니다.
1,203개의 클래스 중 rare하다고 판단한 클래스는 detector fine-tuning 학습 셋에서 모두 제거되며 이러한 “zero-shot” 성능은 벤치마크 표에서 \text{AP}_{\text{rare}}^{\text{LVIS}}와 같이 표기됩니다. 이런 상황에서의 표현이 조금 조심스러울 수 있지만, 우선 메인 task가 detection이니 image-level 사전학습 때 설령 보았다 한들 detection을 위한 명시적 학습은 수행된 적이 없으니 zero-shot이라고 이야기하는 것으로 보입니다.
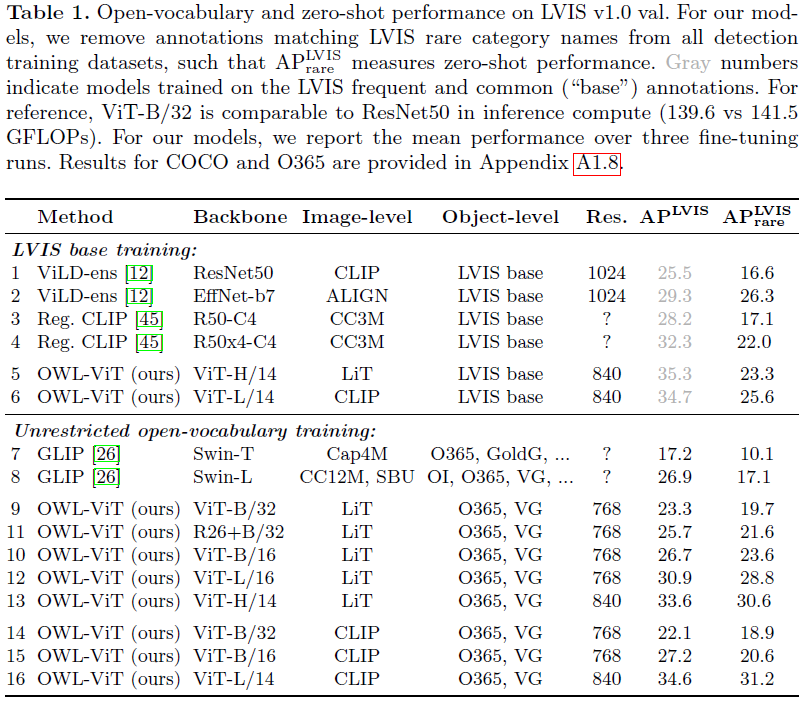
표 1을 통해 OVOD 메인 벤치마크 성능을 확인할 수 있습니다. 이를 해석하기 위해 알아야 할 지표가 여럿 있어 이에 대해 설명드리겠습니다. 우선 LVIS base training은 detector fine-tuning을 위해 LVIS 데이터셋만 활용했을 때를 의미합니다. 아래 쪽에 위치한 Unrestricted open-vocabulary training은, Object-level 열에서 볼 수 있듯 LVIS 대신 O365, VG로 fine-tuning을 수행했을 때의 성능입니다. 아래 쪽 성능이 더 높은 이유는, LVIS rare에 속하는 클래스가 O365 학습 셋에서는 꽤나 큰 비율을 차지하고 있어 제외시킬 수 없었고 이에 따라 “zero-shot”이 아니기 때문입니다. 그럼에도 OWL-ViT 구조의 open-vocabulary transfer ability를 평가하기 위해 진행한 실험이라고 합니다.
ViT-B/32가 연산량으로 따졌을 때 R50과 유사하다고 하며, CLIP ViT-L/14 백본을 가져와 public dataset에 대한 detector fine-tuning 후 측정한 \text{AP}_{\text{rare}}^{\text{LVIS}} 성능이 31.2%로 가장 좋은 것을 알 수 있습니다. 우선 다른 방법론들에 비해 대부분 높은 성능을 보여주고 있지만, detection task에 아직 익숙치 않고 개발 관점으로 접근해야하는 제 입장에서는 이 정도의 정량적 결과가 어떤 수준인지 잘 모르겠습니다. 추후 정성적 결과를 조금 더 참고해보아야겠네요.
4.3 Few-Shot Image-Conditioned Detection Performance
앞서 여러 번 이야기했듯, 별다른 모델 구조의 변형 없이 text 쿼리 대신 image-derived query embedding을 던져 one-shot 또는 few-shot OD를 진행할 수 있습니다. Few-shot detection을 위해 새로운 물체에 대한 box 라벨을 요구하는 것은 아니고, 기존 detector에 영상을 주고 inference를 돌려 찾고자하는 물체와 유사한 위치에 쳐진 box를 선택해주게 됩니다. 이제 이 box를 새로운 test image에 쿼리로 던져 새로운 object를 찾는 것입니다.
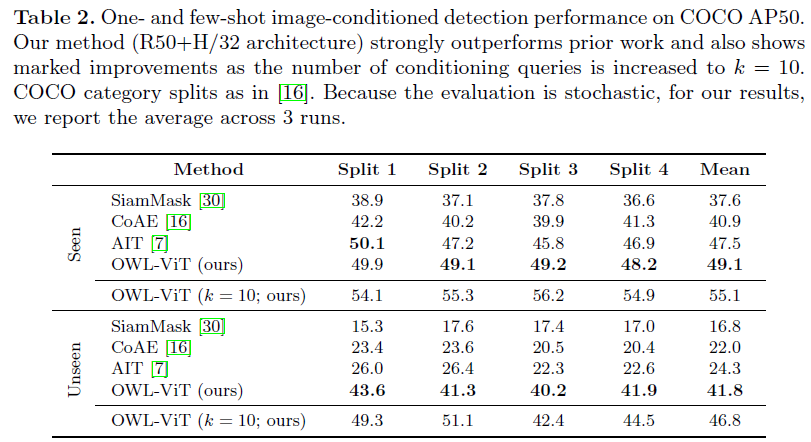
표 2는 One-, Few-shot image-conditioned OD 실험 성능입니다. 본 실험을 위해서 COCO로 detector를 fine-tuning 시켰고, 이 과정에서 평가 때 사용할 클래스들은 학습 때 제외시키게 됩니다. 특히 image와 text를 feature-level에서 합치지 않는게 이러한 one-, few-shot OD를 수행할 때 동시에 여러 패치 쿼리를 동시에 던질 수 있도록 해주는 장점을 만들어냅니다.
OWL-ViT가 image-conditioned OD를 위해 설계된 모델이 아님에도 불구하고 해당 task를 메인으로 수행하는 기존 방법론들보다 더욱 높은 성능을 보여주고 있습니다. Shot의 개수를 의미하는 k를 10으로 늘리면 큰 성능 향상이 있음을 알 수 있습니다. 결국 쿼리는 하나를 던져야 하기 때문에, 향상된 성능은 물체 주변 박스 10개를 샘플링해 각각 embedding으로 만든 뒤 평균 내어 사용한 결과입니다. 이에 대한 정성적 결과는 아래 그림 A2에서 볼 수 있는데, 쿼리로 준 영상 속 물체와 찾아야 하는 test 영상 속 물체의 각도나 조도가 달라도 꽤나 강인하게 잘 찾고있다는 점이 놀랍습니다.

5. Conclusion
우선 논문에는 위에서 언급한 실험 이외에 image-level 사전학습 스케일에 따른 모델 별 성능 비교, detector fine-tuning 시 고려할 수 있는 조건 또는 데이터셋 구성에 따른 성능 비교를 포함해 다양한 견해 및 실험결과, 정성적 결과를 보여주고 있으니 궁금하신 분들은 질문 또는 논문을 직접 찾아봐주시면 좋을 것 같습니다.
리뷰를 다 써두고 다시 쭉 읽다보니 느낀 것이 아직 이쪽 분야에 지식이 부족해 짧은 기간 안에 완성도 있는 리뷰를 작성하기 어려웠는데요, 앞으로 제가 연구하고자 하는 비디오 분야 task의 논문과 병렬적으로 follow-up 할 예정이니 다음번에는 조금 더 완성도 있는 글로 돌아와보겠습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
볼드친 부분의 문단에 대한 간단한 궁금증이 있는데,
(1) condition이 image crop patch면, 해당 patch (object)가 영상에 하나만 존재할 시에는 문제가 없나요? 문제가 없다면 하나에 대해선 detection한 이후, 동일 클래스의 다른 object들이 있는지 찾을 때만 이 patch를 활용하는 건가요?
(2) 아.. 본 논문의 방법이 OWL-ViT로 불리는 그 논문이네요. 자주 보면서도 논문 제목은 몰랐는데, 혹시 모델 학습시 사용한 3.6억개의 이미지-텍스트 데이터 쌍이 CLIP에 사용된 데이터 쌍과 동일하나요? 그냥.. 대용량 데이터 셋으로 사전학습 했다고 종종 들었었는데, CLIP과도 연관된 데이터 셋인지 궁금해서 물어봅니다..ㅎㅎ
(1)
저도 코드레벨로 OWL-ViT를 활용해본적이 아직 없어 확실하진 않지만, 우선 condition으로 던져주는 patch가 detection을 수행할 대상의 영상으로부터 올 수도 있고, 아예 다른 영상으로부터 올 수도 있는 것으로 보입니다. 영상에 찾고자 하는 물체가 하나 있어 condition으로 주면 당연히 찾을 것이고, 해당 물체 주변에 동일한 물체가 존재한다면 마찬가지로 찾을 수 있을 것입니다.
Image condition는 물체를 텍스트로 설명하기 어려워서 영상 자체를 던지고자 존재하기 때문에, 텍스트 수준으로 해당 클래스가 무엇에 속할지 분류까지는 하지 않는 것으로 보입니다.
(2)
두 데이터셋의 개수는 약 3.6억 개라고 언급되어있는데, 저도 그 부분이 궁금하여 찾아보니 나름 구글의 논문이라 contrastive learning 방식만 CLIP을 따랐을 뿐, 별도의 크롤링을 통해 사전학습 데이터셋을 직접 구축한 것으로 알고 있습니다. CLIP의 사전학습 encoder를 사용했을 때와 OWL-ViT의 encoder 간 성능을 비교하는 것으로 보아 둘은 동일한 데이터가 아닙니다.
좋은 리뷰 감사합니다.
데이터 셋에 대해서 질문이 있습니다. 이미지-텍스트 페어 쌍으로 사전학습을 진행할 거 같은데 text가 정확히 어떤 형태로 존재하는지 궁금합니다.
object text 쿼리로 정제되어 있지는 않는 거 같은데 caption 내에서 정확히 어떤 object 인지 구분하는 작업은 필요로 하지 않는 건가요?
또한 실제로 이미지에 있는 모든 객체를 대응되는 text caption이 다 설명할 수 없는 부분도 존재할 거 같은데 이러한 부분에 대해서는 어떻게 생각하시나요?
(1) 1차적인 image-text level의 사전학습 때에는 CLIP과 유사하게 caption을 사용해주게 되고, 다음으로 Object Detection을 위한 사전학습 때에는 학계의 Object Detection 데이터셋을 다 긁어모아 중복을 제거한 뒤 사용한다고 했으니 학계 데이터셋의 클래스 이름과 같은 명사일 것입니다.
(2) caption을 사용하는 단계는 image-text 레벨의 사전학습이기 때문에 별도로 object만 뽑아내지는 않고 있는 상황입니다.
(3) 대용량의 사전학습 데이터를 구축하다보니 사실 사람이 모두 정제하여 정확히 caption과 영상의 내용이 일치하는지, 부족한 부분은 없는지 확인하긴 어렵다고 생각합니다. 저도 이러한 사전학습 데이터셋 자체에 포함되어있는 noise를 줄인 후 사전학습을 진행하자는 연구가 존재하는지는 잘 모르겠지만, 사전학습을 마친 모델이 갖는 bias를 제거하려는 방법론들은 많이 연구되고 있는 것으로 알고 있습니다.
말씀해주신대로 모호한 물체를 찾긴 찾았지만 정확히 어떤 단어와 가장 유사한지 어려워하는 경우도 있을 것 같지만, 아무래도 약 3.6억 개의 image-text 쌍 및 약 2백만 개의 detection 데이터셋으로 학습을 마쳤기에 그러한 단어는 거의 없지않을까 생각됩니다.