안녕하세요. 이번 리뷰는 owod가 아닌 unsupervised clustering과 관련된 예전 논문을 리뷰합니다. 해당 논문은 unsupervised clustering을 deep learning으로 푼 초기 논문인데, 해당 방식 (unsupervised clustering)을 아이디어로 적용하고 싶어 읽어보았습니다. 예전 논문이기도 하고 deep learning을 적용한 초기의 논문이기도 하여, 논문이 간결하기도 하고, 어렵지는 않습니다. 금주 세미나에선 하나 정도 더 리뷰해야겠네요. 그럼, 리뷰 시작하겠습니다.
Introduction
CNN이 한정된 양의 데이터로 일반적인 능력을 보임에 훌륭하며, 해당 발전은 Fully-supervised ImageNet 데이터의 등장 이후 촉진되고 있습니다. 하지만 “Convnets and imagenet beyond accuracy: Explanations, bias detection, adversarial examples and model criticism” 논문에서는 SotA 분류기들이 그들의 구조가 훌륭함에도 불구하고 ImageNet 데이터에선 과소평가 되며 이들의 성능이 포화상태에 이르렀다고 판단되고 있다고 합니다. 그러면서도 ImageNet이 현재의 시점에선 백만장의 이미지밖에 안되며, 더 많은 데이터는 나날이 쏟아지고 있지만 이들을 활용하기 위해선 (Fully-supervised 방식을 위해) Annotation이 필요합니다. 물론 수십억, 수천억, 그 이상의 더 많은 양의 데이터들의 품질을 파악하고, 직접 Annotation을 해주면 모델의 성능이 더 좋아질 수 있습니다. 이는 data-driven의 DL에서는 관념처럼 받아들일 수 있는 문제지만, 실제로 그 정도의 주석을 다는 일은 불가능하겠죠. 전 세계 인구가 하나씩 주석을 달아도, 그 다음 날만 되도 그 만큼의 데이터가 생성되며 모델의 학습 속도는 이를 따라잡지 못할테니 말이죠. 우리는 이 문제를 해결하기 위한 Self-supervised, Semi-supervised, Unsupervised, Active Learning, Few-shot 등의 다양한 방법이 있음을 알고 있습니다. 저자는 이를 위해 Unsupervision의 clustering 방식으로 인터넷 수준의 대용량 데이터에서 학습할 수 있는 방법을 제안하고자 합니다.
위의 문단은 우리도 잘 아는 내용입니다. Unsupervised Learning에서는 클러스터링, 차원 축소, 밀도 추정 등의 고전적인 연구 등이 존재합니다. Local descriptor를 토대로 클러스터링을 하는 BoVW, 우리가 잘 아는 Unsupervised 방식이죠. 이들은 위 문단의 “주석이 필요하지 않으므로” 성공과 관심을 이끌었습니다. 하지만 적어도 이 시점 (2018년)까진 Unsupervised 방식이 End-to-End CNN에서 활용된 적은 거의 없었습니다. [핵심!] 클러스터링은 주로 고정된 Feature 위 분류를 위한 선형 모델 (Linear layer)을 위해 설계되었는데, 그들이 Feature와 동시에 학습 시 거의 작동하지 않는다는 점입니다. 예를 들어 CNN (Feature)과 k-means의 클러스터링을 동시에 학습 시 대부분의 Feature가 갑자기 0으로 수렴되어 버리며 그래서 클러스터는 하나의 집합으로 뭉쳐버리는 (Trivial-solution에 빠진다고 표현됩니다), 서로가 서로에게 악영향을 미칩니다.
저자는 위 문제를 타파하고 End-to-End CNN과 클러스터링을 묶어 학습하는 방식을 제안합니다. 모델 자체는 CNN과 클러스터링 (k-means)이 묶여 기존의 방식과 다르지 않습니다만, 앞선 문단의 Trivial-solution으로 왜 빠지는지 관찰하고, 이를 극복하는 두 방식을 제안합니다. k-means를 활용하긴 하지만, 저자는 단순화를 위해 이 방식을 채택했으며 다른 클러스터링 방식 (PIC, Power Iteration Clustering) 또한 잘 동작한다고도 언급합니다. 결국 End-to-End CNN을 통해 하고 싶은 일은 CNN을 Unsupervised 방식으로 학습하며 좋은 Feature를 추출하는 일이며 Self-supervised과 달리 도메인 지식이 필요하지도 않은 일이므로 실험 단에서 당시의 대표적인 CNN 모델인 AlexNet과 VGG 모델에 대해 ImageNet 분류 외에도 Flickr, YFCC100M의 다양한 데이터 셋에서도 좋은 성능을 보임을 언급합니다.
Method
Preliminaries
음? LeNet이 소개된지도 한 20년이 넘은 시점인데, CNN의 과정을 소개합니다. 강조하고 싶은 점이 있는지 읽어보았는데, 정말 CNN에 대한 설명이네요. 다음 문단의 설명을 위해, 수식만 쓰고 넘어가겠습니다.
\min_{\theta, W} \frac{1}{N} \sum_{n=1}^{N} \mathcal{L} (g_W (f_{\theta}(x_{n})), y_{n}) \dots (1)\theta, \mathcal{L}, f, g_{W} 는 순서대로 파라미터, Loss (CE), CNN 레이어 (입력 영상 -> D-차원 벡터), FC 레이어 (D-차원 벡터 -> K-차원 벡터)입니다. 바로 다음으로 넘어갑시다.
Unsupervised learning by clustering
[핵심!] 만약 CNN의 \theta (파라미터)가 랜덤하게 초기화되었다면, f_{\theta} 는 Feature representation이 훌륭하지 않습니다. 하지만 AlexNet의 파라미터를 랜덤하게 초기화한 후 Freeze하고 마지막 FC만 학습한 다음 분류하면 12%의 정확도를 보입니다. 이는 랜덤하게 찍은 확률 (ImageNet: 1000개의 클래스)의 0.1% 보다 높은 정확도를 보이는데, 저자는 이를 “입력 신호 (영상)에 대한 CNN의 구조가 강력한 사전 정보를 보이는 이점 덕분”으로 봅니다. 우리는 Transformer (Attention is all you need)를 읽으며 Inductive bias에 대해 알게 되었을텐데, 이 Inductive bias를 가진 CNN의 커널 공간의 연산의 구조적인 이점이 분류에 도움이 됨을 언급합니다. 저자는 해당 CNN 구조로부터 나오는 약한 신호를 활용하여 CNN의 출력을 클러스터링 한 이후, 클러스터링 할당에 따른 pseudo label을 생성하여 CNN의 파라미터를 업데이트 하는 방식을 제안합니다 (그림 1).
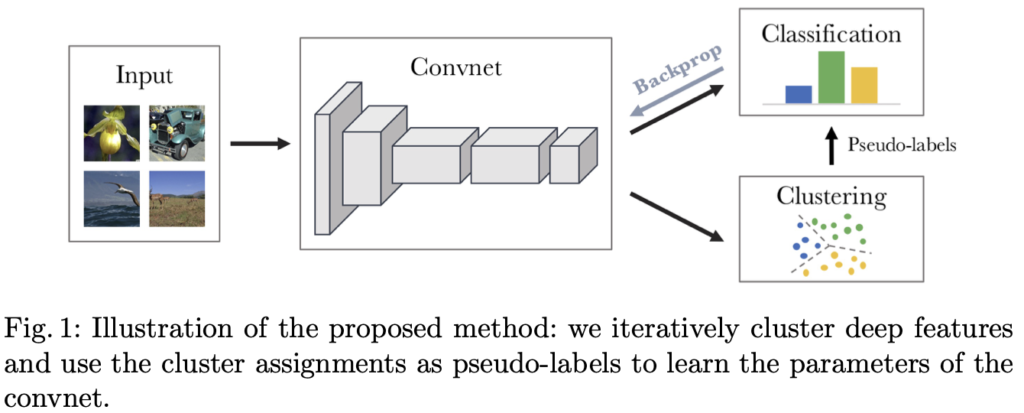
그림 1에서 보이는 바처럼, 굉장히 간단합니다. Convnet으로부터 (k-means) Clustering 한 후 (1), Clustering의 중심을 Pseudo-label로 명명하여 Classification을 합니다 (2). 이 때 Classification은 Pseudo-label에 대해 이루어지지, Real-label이 아닙니다 (현재 학습 방식이 Unsupervised를 가정하고 있음을 되짚어야 합니다). Classification의 결과로부터, Backprop을 통해 Convnet의 \theta 를 업데이트합니다 (3).
Clustering에 대해서는, k-means를 활용하여 f_{\theta} 로 생성된 Feature에 대해 Manifold 내의 기하학적 위치에 따라 그룹화됩니다. 수식 (2)
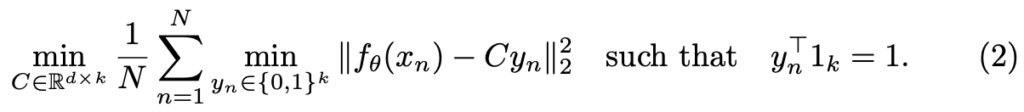
수식 (2)는 f_{\theta} 의 Feature map 차원 d와 Centroud 수 k의 행렬 \mathbb{R}^{d \times k} 에 대해 CNN Feature와 Cluster의 Pseudo-label로 지정될 y_{n} 간의 거리를 최소화하는 k-means 과정을 보입니다. 이 과정은 Clustering을 통해 C를 구하고 (1), C로부터 y_{n} 을 구한 이후 (2), Clustering 내의 Feature와 거리가 최소화되도록 학습합니다.
Avoiding trivial solutions
하지만 서론부에서 언급한 바와 같이 위 문단에서 방식한대로 학습 시에 Trivial solution에 빠질 수 있는데, (1) 클러스터링 시 모델 입장에서 최적의 결정 경계는 하나의 집합으로 분류 (클러스터링 간 분류를 하지 않아도 되니)하는 것이므로 학습이 진행됨에 따라 모든 Feature가 하나의 클러스터에 할당되고, 빈 클러스터가 생기는 상황입니다. – 저자는 이 문제를 풀고자 빈 클러스터의 중심을 주변 데이터가 있는 곳으로 옮긴 이후, 다시 클러스터를 할당하는 일입니다. 이 작업을 통해 빈 클러스터는 이전 (클러스터가 비어지게 되기 이전) 클러스터의 중심으로부터 가까운 데이터에 대해 다시 클러스터링을 진행하여 빈 클러스터를 채울 수 있습니다.
(2) 두 번째는 클래스 간 데이터 양의 불균형으로 인해, 데이터의 양이 많은 Major 클래스에만 할당되는 방향으로 Feature가 추출되는 문제입니다. – 간단한 방식으로, 저자는 각 클러스터에 할당된 데이터 개수의 역수 (데이터가 많을 수록 낮은)를 위 수식 (2)의 Loss에 곱합니다. \frac{1}{N} 의 N이 곧 클러스터의 데이터 수가 됩니다.
Experiments
논문의 Method까지, 이렇게 간단히 마쳐버렸네요. 예전 논문이여서인지 (그렇다한들 6년전이지만) 내용이 왜이리 짧게 느껴지는지, 아니면 대부분의 Self-supervised, Unsupervised, k-means와 같은 방식을 우리가 이미 잘 알고 있어서 그런지는 모르겠습니다. 서론부에서 언급한 바와 같이 저자는 AlexNet, VGG16에 대해 대규모의 데이터 셋에서 실험을 진행합니다. 평가 지표로는 Accuracy외에도 NMI (Normalized Mutual Information)을 사용합니다. NMI는 아래 수식으로 표현되며, I는 Mutual Informatioin, H는 Entropy로 클러스터에 할당된 두 A, B가 실제 레이블에 독립적이면 0, 종속적이면 1이 됩니다 (클러스터가 실제 레이블에 얼마나 종속적인지를 평가하는, 높을 수록 실제 레이블과 클러스터가 동일하다는 의미이니 좋습니다).

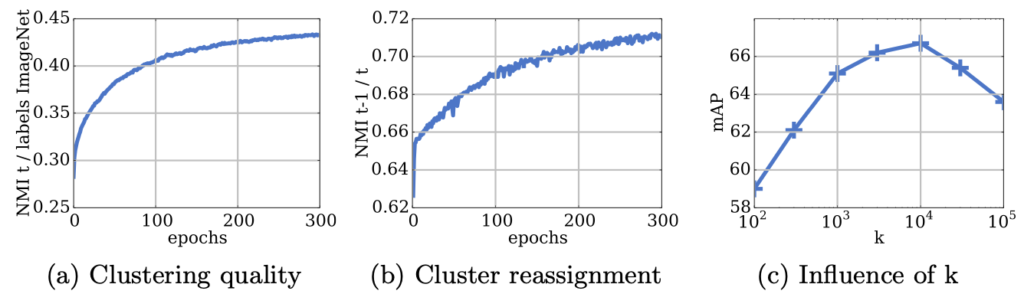
위 그림에서 (a)는 “Relation between clusters and labels”로, 학습 중 할당된 클러스터와 ImageNet 레이블 간의 NMI 값을 보입니다. 학습이 진행됨에 따라 종속성이 늘어나는 즉, Trivial solution에 빠지지 않고 좋은 클러스터를 이루게 됩니다.
(b)는 “Number of reassignments between epochs”로, 각 epoch마다 클러스터를 재할당하는데, 이 때 학습이 안정적인지를 봅니다. 학습이 진행됨에 따라 재할당이 줄어들고 (Y축은 t-1/t), 진폭이 여전히 안정한 모습을 보아 학습이 안정적으로 진행됩니다.
(c)는 “Choosing the number of clusters”로, k-means의 k에 따른 모델의 분할을 보입니다. K가 10000일 때 좋은 성능을 보이는데, 물론 ImageNet에 대해서이니 1000 이상이 되어야함이 당연해보입니다. (k를 지정하지 않는 방식은 없을까요?)

위 Table은 YFCC100M 데이터 셋에서 무작위 샘플링을 통해 클래스 간 불균형한 데이터 셋을 만든 이후 비교 분석한 결과입니다. 앞서 언급한 바와 같이 Clustering 방식은 클래스 간 불균형 시 성능이 크게 저하될 수 있으나, DeepCluster의 경우 클래스 간 불균형에도 Pascal VOC로 전이학습 한 결과에서 괜찮은 성능 (ImageNet과 비교 시)을 보입니다.
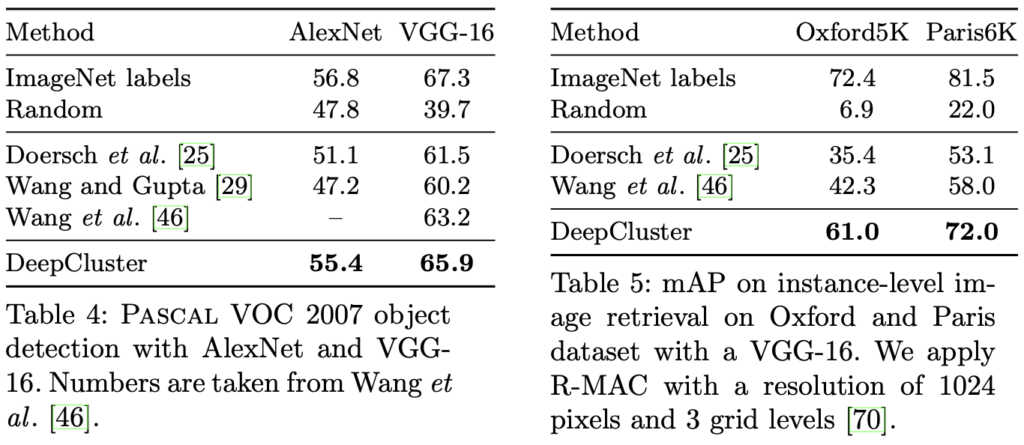
Table 4는 AlexNet이 아닌 VGG-16과 같은 더 깊은 신경망에서도 좋은 성능을 보일 수 있는지에 대해 (Pseudo-label을 통한 Backprop 시 신호가 약해질 수 있다는 가정에 대비하여), 오히려 VGG-16에서 더 좋은 성능을 보입니다. 신경망의 깊이와 상관 없이, 오히려 신경망이 깊어짐에 따라 오히려 DeepCluster가 더 효과적임을 언급합니다.
Table 5는 Instance-level의 Oxford5K와 Paris6K 데이터 셋에서의 Retrieval 결과로, DeepCluster가 좋은 성능을 보입니다. Class-level 뿐만 아니라 Instance-level에서도 DeepCluster가 좋은 성능을 보인다고 합니다. 이 점은 조금 신기하네요. 클러스터링 자체가 어찌보면 클러스터링과 그 중심이 중요한데, Instance-level에서도 좋은 성능을 보인다고 합니다.
주된 방법과 실험을 이로써 마쳤습니다. 사실 제가 본 논문을 읽으며 기대한 점은 “Unsupervised이니, 과연 k-means의 k를 정하지 않아도 될까”였는데, k는 정해야하나 보네요. 사실 정하지 않는게 이상하지만, 그래도 이 방법과 관련된 논문 하나 둘 정도는 더 읽어봐야겠네요. 리뷰 읽어주셔서 감사합니다.
리뷰 잘 읽었습니다.
결국 본 논문에서 소개하는 이런 clustering 기반 방법론들이 supervision signal을 위해 이곳저곳 연구들에 많이 사용될거란 생각이 듭니다. prototype도 동일한 원리인 거 같구요.
본 논문을 읽으신 이유가 궁금한데, OWOD 의 어떤 부분을 해결하시고자 읽으신건가요?
unknown? background? 를 하나의 cluster 로 묶어버리는 기존 연구들을 해결하고자?? 그와 관련해서 읽으신건가요?
리뷰 읽어주셔서 감사합니다.
해결하고자하는 문제는 owod에서 클러스터링 시 unknown에 대한 클래스 레이블이 하나만 존재하기 때문에, 이를 k개의 unknown 후보군들로 클러스터링하고자합니다.
리뷰 잘 읽었습니다.
헷갈리는 부분이 있는데 그렇다면 결국 CNN 구조는 랜덤 초기화를 하고 clustering 방식으로 pseudo label을 만들고 학습이 진행 되는건가요?? (ImageNet 사전학습이 아니라..?)
초기에 엉터리 값을 만들 수도 있을거 같아 K-means clustering이 잘 동작할지도 의문이 드네요.
그리고 저도 지금 하고 있는 연구에서 어떤 문제를 풀고 싶어서 해당 논문을 참고했는지 궁금하네요ㅋㅋ
리뷰 읽어주셔서 감사합니다.
CNN 구조를 랜덤 초기화하기 보단 실험에서는 ImageNet 또는 YFCC100M에서 사전학습된 가중치를 불러오는데, 이 때 몇 번째 레이어까지 불러오는지에 따른 비교 실험도 존재합니다. 해당 실험에 대한 내용도 보충해서 (아마 4.30 화요일 이내로) 써놓겠습니다.
어떤 문제를 풀고 싶은지에 대해선 권석준 연구원님의 질문에 대한 응답과 동일하게 “unknown에 대해 manifold 내에서 (MS-COCO 기준) 80개 + 1개의 unknown이 아닌 80개 + k개의 unknown으로 다루고자하는 시도”입니다.
안녕하세요, 이상인 연구원님. 좋은 리뷰 감사합니다.
읽다보니 experiment 부분의 NMI 수식에 대해서 궁금합니다. I가 나타내는 Mutual Information이 어떻게 연산되는지에 대한 더 추가적인 설명이 있나요? mutual information이 구체적으로 무엇을 의미하는지 더 자세히 알고 싶습니다.
감사합니다.
리뷰 읽어주셔서 감사합니다.
본 논문에서 직접적으로 언급되지는 않지만, Mtual Information이란 정보이론에서 나온 개념으로, 풀어 설명하자면 A에 대한 Uncertainty에서 B를 알고 난 이후 A에 대한 Uncertainty를 뺀 값, 즉 두 정보가 얼마나 관련되어 있는지에 대해 다루는 수학적 개념입니다.
안녕하세요 이상인 연구원님. 좋은 리뷰 감사합니다.
본 논문에서 제안하는 학습 방법이 cluster의 중심을 라벨로 가정하는 방법이라면 데이터에 따라 k-means 클러스터링에서 k값을 정하는 것이 중요할 거 같은데요, 논문에서는 각 데이터셋에 따른 k값을 어떻게 정하는지 궁금합니다.
그리고 experiment의 fig(c)에서는 imagenet을 사용하였는데 본래 데이터셋의 클래스보다 큰 k값에서 좋은 성능을 보이는 이유도 궁금합니다.
리뷰 읽어주셔서 감사합니다.
음, 기본적으로 k값은 데이터 셋의 클래스 개수 이상은 되어야된다고 생각합니다. 이 때 K는 실험적 결과인데 저자도 ImageNet에선 k=1000일 때의 성능이 좋을 것으로 기대했지만, k가 1000이 넘는 (k=10000의) over-segmentation 상황이 더 좋은 면을 보고 놀랐다고 합니다. 실험적 결과로 나왔으므로 저자가 이에 대한 추가적인 언급이나 고찰은 하지 않습니다.
안녕하세요 상인님, 좋은 리뷰 감사합니다.
질문이 3가지 있습니다!
1. “입력 신호 (영상)에 대한 CNN의 구조가 강력한 사전 정보를 보이는 이점 덕분”이라고 표현한 것이 흔히 알다시피 입력 영상이 가지고 있는 이미지의 공간적 특성을 CNN의 conv 구조를 통해 인접정보를 받아들이는 것이라고 보는 것이 맞나요?
2. 그리고 본 리뷰에서 언급하시는 신호의 강약과 전달 등이, backprop 시의 그래디언트 전달, vanishing과 같은 맥락인건가요?
3. 마지막으로 k-means가 아닌 DBSCAN을 통해 cluster 갯수인 k를 지정하지 않고, cluster 반경 크기인 eps와, 반경 내 포함될 최소 이웃 데이터 포인트의 개수인 min_samples 에 해당하는 하이퍼파라미터만 실험적으로 찾을 수 있다면, 상인님이 고려 중이신 k값을 지정하지 않으면서 수도라벨들을 정의하는 방안이 될 수도 있을까요? k-means 이외의 다른 clustering 방법론들에 대한 직접적인 언급은 없으셨던 것 같아서 혼자 고민해보다가 여쭤봅니다!
안녕하세요. 리뷰 읽어주셔서 감사합니다.
1. 넵. CNN의 Conv 구조 자체가 Kernel을 사용하기에, 해당 Kernel 내 정보들을 통합하여 볼 수 있는 그런 구조적인 이점입니다. 조금 더 나아가자면, ViT 논문에서 Inductive Bias에 대해 소개하는데 이 Inductive Bias가 CNN Conv의 구조적인 이점을 이야기하는 좋은 개념입니다. 임근택 연구원님의 ViT 논문 리뷰에서 Inductive Bias를 아주 기깔나게 설명하니, 직접 읽어 보시면 더 좋을듯 싶습니다.
2. 음, 이 Signal이란 개념이 그래디언트의 전달, Vanishing과 엮어 생각할 수 있습니다.만, 저는 이런 논문에서 언급하는 Signal이 마치 CNN에서 초기 레이어와 후기 레이어가 가진 정보와 같이, 딥러닝 모델이 가지는 정보량의 개념과 엮어 해석하고 있습니다. 이 정보량을 조금 더 구체적으로 본다면 재찬님이 말씀하시는 그래디언트의 전달로 볼 수도 있겠지만서요!
3. 음, 본 논문에서 K-means 이외의 Clustering 방법도 문제 없이 잘 작동한다고 말은 했지만, 실험에선 찾아보기 어려웠습니다 (음, 제가 공식 Release 버전의 논문을 읽어서 그런지 모르겠지만 아마 Appendix엔 있을 수도 있겠네요), 제가 고려중인 방법은 K가 없었으면 좋겠다이지만, 당장 Unsupervised라 하더라도 K자체를 정하지 않는 것은 쉽지 않습니다. 왜냐하면 Unsupervision이라고 한들 Clustering을 위한 Supervision이 없다는 의미이지, 아예 아무런 정보 없이 Clustering을 하기엔 초기 정보들이 학습 이전에는 Manifold 상 비슷하게 존재해있기 때문입니다. 음, 제가 아직 Unsupervision Clustering 논문을 몇 보지 못해서 제가 원하는 방법은 아직 잘 모르겠네요. 허허..